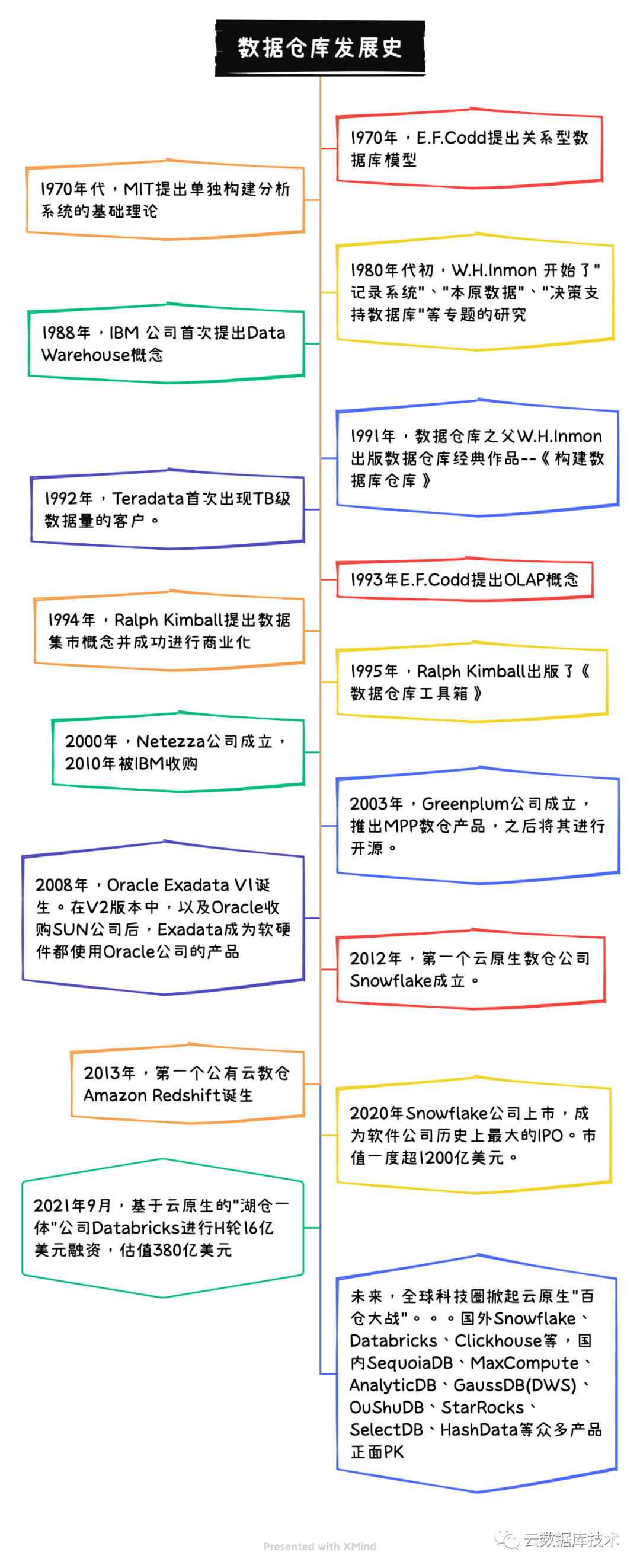
回顾数据仓库的发展历程,大致可以将其分为几个阶段:萌芽探索到全企业集成时代、企业数据集成时代、混乱时代--"数据仓库之父"间的论战、理论模型确认时代以及数据仓库产品百家争鸣时代。查看原文
数据仓库理论发展历程
上世纪70年代,IBM的E.F.Codd等人提出关系型数据库后,MIT的研究员提出单独构建分析系统的基础理论,新的理论试图将业务处理系统和分析系统分开,即将业务处理和分析处理分为不同层次,针对各自的特点采取不同的架构设计原则。他们认为这两种信息处理的方式具有较大差别,应使用不同的架构和设计。但受限于当时的技术能力,这个研究仅仅停留在理论层面。
到了80年代初,W.H.Inmon 开始了“记录系统”、“本原数据”、“决策支持数据库”等专题的研究。几乎同时,J. Martin在关于数据库分类的研究中,专指一种他称之为“第4类数据库”的“由用户驱动的计算环境”,为这种环境提供信息服务的是一种以“搜索和快速信息回收”为基本特征的数据库。这个定义已经和后来的数据仓库十分类似。
1988年,IBM 公司的研究员创造性地提出了一个新的概念--数据仓库(Data Warehouse)。到了1991年,数据仓库之父W.H.Inmon出版数据仓库经典作品--《构建数据库仓库》,标志着数据仓库概念的确立。书中指出,DW是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,并且是用于支持管理决策的数据集合。该书还提供了建立数据仓库的指导意见和基本原则,凭借着这本书,W.H.Inmon被称为数据仓库之父。
由于传统的关系型数据库已无法满足构建数据仓库的需求,在1993年Codd提出了多维数据库和多维分析的概念,即OLAP(On-Line Analysis Processing联机分析处理)。当时Codd认为OLTP(On- Line Transaction Processing 联机事务处理)已不能满足终端用户对数据库查询的需要,SQL对大数据库进行的简单查询也不能满足用户分析的需求。用户的决策分析需要对关系数据库进行大量计算才能得到结果,而查询的结果并不能满足决策者提出的需要。因此提出了多维数据库和多维分析的概念,即OLAP。
1995年,Ralph Kimball出版了《数据仓库工具箱》,数据仓库行业进入少林和武当之争。Inmon主张建立数据仓库时采用自上而下方式,以关系型数据库的第3范式进行数据仓库模型设计,而Kimball则是主张自下而上的方式,力推数据集市(Data Market)建设。两位数据仓库领域的大咖为此吵得不可开交,他们的粉丝也纷纷站队,这种争吵直到Inmon推出新的BI架构CIF,把Kimball的数据集市包括了进来才算平息。

早期MPP时代的数仓
IBM DB2和Teradata是早期数仓理论的实践者,也是市场领导者。其中Teradata是MPP数仓最成功的商业产品,几乎是行业的天花板。诞生于1970年代末的Teradata公司,名称来源于Tera Bytes,TB数据的存储也展示了哪个年代创业者的雄心壮志。终于在1992年第一个TB 级的数据库在华尔街出现。1999年,客户拥有130TB的数据分布于176个节点。短短7年时间,Teradata客户的数据规模翻了176倍。
但进入新千年后,数据库巨头间的竞争进入白热化阶段,以Oracle Exadata为代表的一体机很快崭露头角。之后在Postgres基础上演变而来的Greenplum构建了开源的MPP架构数仓,也在市场中有很高的影响力。但真正让数仓焕然一新的是云计算时代的云原生数仓Snowflake。
一体机时代的数仓
新千年后,数仓进入一体机的快速发展时代,典型代表是Netezza、SAP HANA和Oracle Exadata。Netezza率先推出,后来被IBM收购。而Oracle Exadata为代表的一体机依然是今天Oracle公司的核心业务。2008年,Exadata V1诞生,由Oracle提供软件惠普提供硬件,这一代产品仅支持数据仓库和商务智能等OLAP工作。到了2009年9月,Exadata V2发布,采用了SUN的(此后MySQL也属于了Oracle),次年Oracle完成了SUN的收购。在V2版本中,Exadata存储节点中首次采用了Flash卡,从而可以同时支持OLAP和OLTP类型的负载。有了高性能产品的同时也有了极其昂贵的价格。
著名的Conor O'Mahony(DB2的市场经理)罗列了使用一台全机架系统(full-rack)Exdata V2所需的费用列表:
- $1,150,000 硬件价格
- $1,680,000 存储服务器的软件价格
- $369,600 存储服务器软件支持和维护费用(以22%计)
- $1,520,000 Oracle企业版软件价格($47.5k*8 servers*8 cores*0.5 Intel core factor)
- $736,000 Oracle RAC软件价格($23k*8 servers*8 cores*0.5 Intel core factor)
- $368,000 Oracle分区特性价格 ($11.5k*8 servers*8 cores*0.5 Intel core factor)
- $368,000 Oracle高级压缩(Advanced Compression) ($11.5k*8 servers*8 cores*0.5 Intel core factor)
- $160,000 Oracle企业管理器诊断包(推荐安装)
- $160,000 Oracle企业管理器调优包(推荐安装)
- $728,640 以上除去存储服务器软件的第一年软件维护支持价格(以22%计)

Oracle Exadata 一体机
如此昂贵的价格,对于一般企业显然无法接受。人们相信全新一代的数仓技术一定会在一个万众嘱目的情况下出现,像盖世英雄身披金甲圣衣,脚踏七彩祥云而来。
云计算时代的数仓
随着移动互联网、物联网的蓬勃发展,率先掀起数据库革命的是Google公司,他的三篇论文开启了大数据时代,之后言数仓、大数据必称Hadoop。但它的弊病也颇为明显,昂贵、不方便使用、难维护等问题始终无法很好的解决。直到计算机行业七彩祥云--云计算出现,为整个行业和人类生活带来巨大变化。而此时的数据仓库在变更的前夜显得异常安静,古语言:三年不鸣一鸣惊人,Snowflake 就是三年不飞一飞冲天的云计算时代云原生数仓产品。
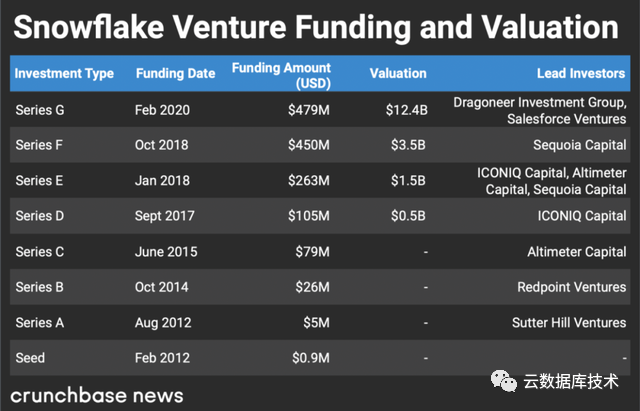
2012年,在Oracle公司工作十多年的2位程序员决心在云上建立一个数据仓库,于是诞生了Snowflake公司。它诞生的第一天,就有云计算的特点:存储与计算分离、按量付费、云中立。作为第一个基于云原生的数据仓库,Snowflake 敏锐的抓住从本地到上云的时代趋势,充分利用公有云强大基础设施能力,让用户更加轻松实现跨云平台、跨区域的方式移动数据。这种基于云原生、云中立、跨多云平台的云原生数据服务,为客户提供巨大数据价值的同时,极大降低了客户使用、维护、价格成本。
Snowflake产品上的成功同时也取得资本市场的巨大成功。2020年9月16日,在纽交所成功IPO,股神巴菲特斥几亿美元入股,交易首日股价翻倍市值达到704亿美元,成为史上规模最大的软件IPO,之后市值一度最高突破1200亿美元,俨然成为资本市场的宠儿。
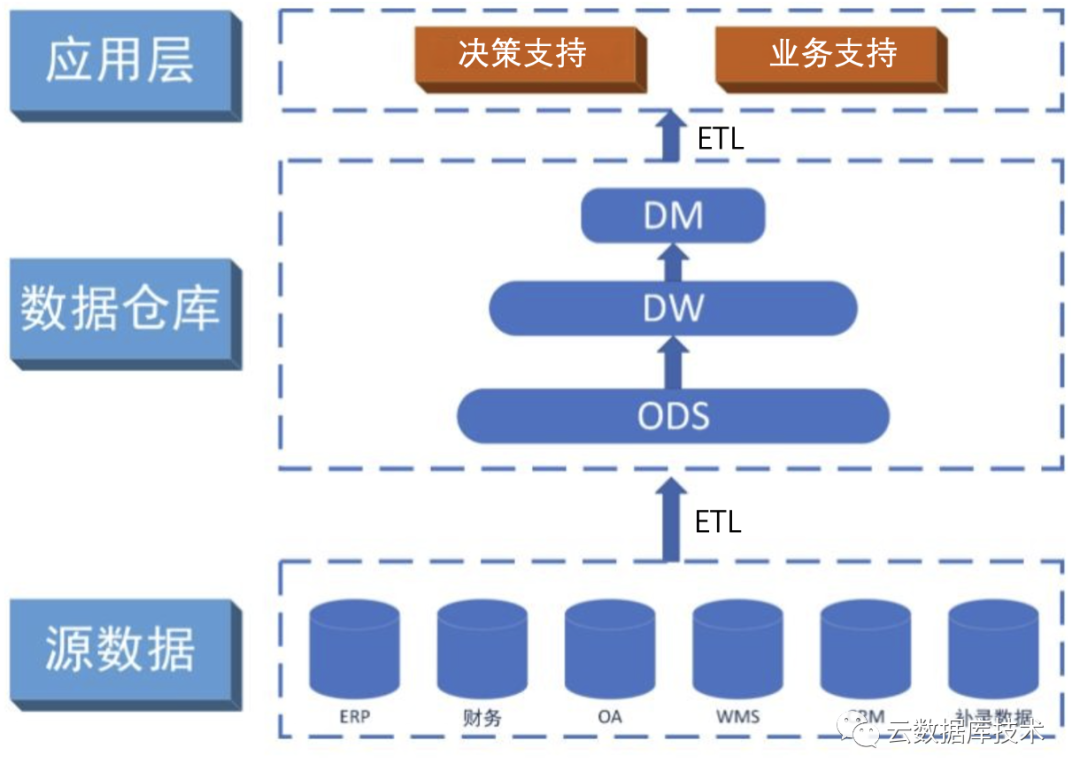
数据仓库和数据库关系
广义的数据仓库并不是一项技术,也不是一个产品,而是一种数据处理过程。数据仓库的数据来源有多种,业务系统、日志、互联网、系统运行参数等等,这些数据可以在数据仓库中进行汇合,然后通过统一的建模,加工成服务与数据分析的数据模型,最终辅助企业分析决策。
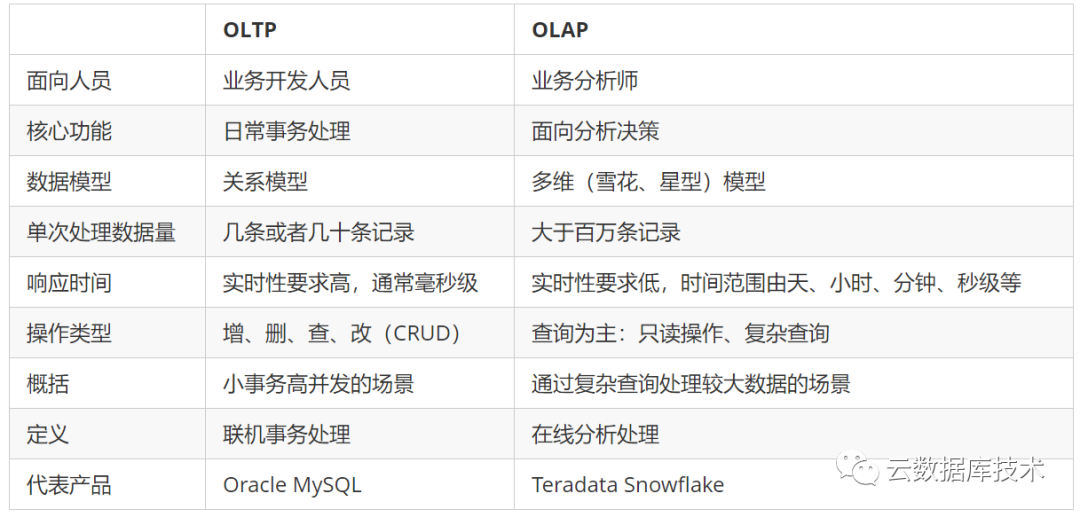
那如何构建数据仓库呢?常见的是使用OLAP数据库(如近年流行Clickhouse)存储数据,通过数据建模、ETL、数据可视化等一系列操作,这一过程被称为构建数据仓库。由于数据仓库基于OLAP产品,是做在线分析处理,这是与数据库的本质区别。另外,既然是数据仓库就要加工数据,加工数据会耗时间,所以加工数据在实际的应用中又分为批处理和实时处理。而传统的数据库是为了解决事务存在的,他们的区别如下。
总结和展望
数据仓库是80~90年代提出的概念,互联网企业为了解决更大数据量的管理问题,掀起了大数据技术新浪潮,大数据已经跳出了数仓定义领域,未来再专题阐述。随着2020年云原生数仓Snowflake上市并取得巨大的成功,大家开始趋向把数据仓库、大数据、数据湖、云存储的技术全面融合,全世界掀起了云原生数据仓库和湖仓一体的热潮,国际上Databricks、Clickhouse已经正面PK,国内有SequoiaDB、MaxCompute,AnalyticDB,GaussDB(DWS),OuShuDB、StarRocks、SelectDB、HashData等不下数十款产品,还有很多类似HTAP新品在路上,未来必将迎来百仓大战的腥风血雨。
数据仓库发展史