👆点击“博文视点Broadview”,获取更多书讯

《云数据库架构》一书全面介绍了主流数据库的技术特点,结合业务场景讲解了数据库技术选型和数据库架构的最佳实践。下面我们摘取本书第1章中对阿里云RDS MySQL三节点企业版的重点内容,让读者先睹为快。


数据库的高可用是个悠久的话题,目前以最常见的主备模式为例, 它主要有异步和半同步两种方式,但这两种方式都有各自的缺陷。
异步在主库宕机后,最后更新的记录有可能没有推送到从库,从而引发数据丢失。
半同步虽然会保证最少有一个从库接收到binlog,但同样有丢失数据的可能(详情请翻阅半同步小结),同时半同步在从库不可用或网络有波动时,会严重影响写入效率。
综上所述,可以看到各个方案对于高可用的理论标准越来越高。尽管不要求做到100%的高可用,这些方案也都存在一些明显的问题。
总的来说,我们用冗余来保证故障容灾,同时又要在性能上和一致性上做权衡,必然要做出一些牺牲。
RDS三节点企业版,正是基于阿里巴巴丰富的业务场景实践,在社区MySQL的基础上,深入集成自研模块,打造出了一套完善可靠的高可用体系。

图 X-Paxos结构
RDS三节点企业版的核心是X-Paxos一致性协议。
阿里自研的X-Paxos不同于原生的Paxos协议,而是在其基础上实现了自动选主、日志同步、数据强一致、在线配置变更等功能。
原生的Paxos有三种角色:Proposer、Accepter和Learner。
而在X-Paxos中,节点的角色分为四类:Proposer、Accepter、Learner和Logger。
Follower是灾备节点,用于收集Leader发送的日志,并负责把达成多数派的日志回放到状态机。当Leader发生故障时,集群中的剩余节点会选一个新的Follower升级成Leader接受读写请求。
Logger是一种特殊类型的Follower,不对外提供服务。Logger做两件事:存储最新的日志用于Leader的多数派判定;选主阶段行使投票权。Logger不回放状态机,会定期清理老旧的日志,占用极少的计算和存储资源。因此,基于Leader/Follower/Logger的部署方式,三节点相比双节点高可用版,只额外增加很少的成本。
Learner没有投票权,不参加多数派的计算,仅从Leader同步已提交的日志,并回放到状态机。在实际使用中,我们把Learner作为只读副本,用于应用层的读写分离。此外,X-Paxos支持Learner和Follower之间的节点变更,基于这个功能可以实现故障节点的迁移和替换。
除了上述角色外,整个一致性协议的持久存储有两块:日志和状态机。
日志代表了对状态机的更新操作,状态机存放了外部业务读写的实际数据。
三节点企业版的状态机实现改造了MySQL原有事务提交的流程。原有提交顺序为 flush->sync->commit,三节点改变了commit阶段,把所有进入commit stage的事务会被统一推送到一个异步队列中,进入quorum决议的判定阶段,等待事务日志同步到多数节点上,满足quorum条件的事务才允许commit。
对于Follower节点。Leader会定期同步给Follower每一条日志的提交状态,达成多数派的日志会被分发给worker线程并行执行。
而对于Learner节点,它只会接收提交成功的日志。
以上介绍了企业版核心X-Paxos, 但只有X-Paxos是不够的, 我们需要一套完整可靠的高可用体系,所以阿里根据各种经验场景研发了高可用五大模块,如图所示。
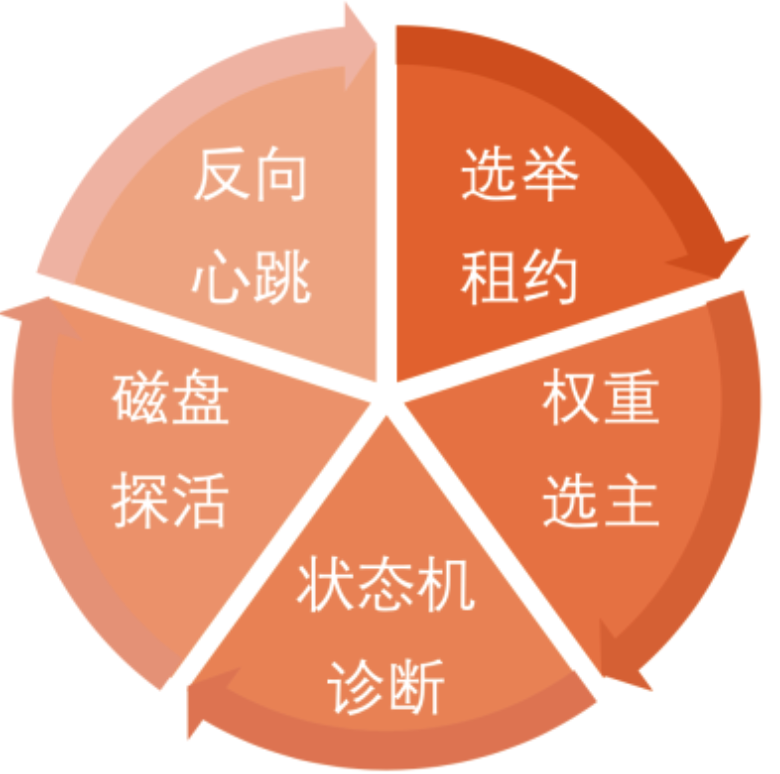
图 选举机制
1. 选举租约
X-Paxos在原理上是采用了unique proposer的Multi-Paxos方案,三节点的配置下,协议需要确保在同一时刻,只有一个Leader对外提供服务, 避免“活锁”问题出现。
一般来说,基于Paxos/Raft等一致性协议的选主,都会采用租约(lease)的方案。选主最大的问题是要避免“双主”出现。
如果当前Leader被网络隔离,其他节点在租约到期之后,会自动重新发起选主。
而那个被隔离的Leader,发送心跳时会发现多数派节点不再响应,从而续租失败,解除Leader的状态,这也避免了“双Leader”现象出现。
Follower约定在lease期间不发起新的选主,Leader先于Follower lease超时,从时序上最大程度上规避了“双主”问题的出现。
不过实际上,从一致性协议角度来说,老主降级流程即使由于各种原因略微延后,也不会造成正确性的问题。比如在Raft协议中,新主选出后,老主的term发起的提案是无法达成多数派的。
避免“双主”本质上是为了尽快的通知外部Client主库已经变化,从而及时进行链路切换。
2.权重选主
给协议中每个节点都增加一个权重值,高权重的节点大概率会优先发起选主投票。
这里请注意,是选优发起投票,但不一定当选。
权重选主主要应用在在三地五副本的场景下,在中心机房主库不可用时,我们希望优先切换到同城的另一个节点,来避免不必要的App跨城调用延迟。这样的设计既能保证高可用,也能保证高质量的服务,如下图所示。
图 权重选主
3.状态机诊断
在主备模式时,如果主节点有DDL或大事务,则会导致从节点延迟,同样的RDS三节点企业版也会遇到这样的情况。如果执行大事务或DDL,在Leader发送共识日志到Follower后,Leader节点会宕机,新选主的节点由于回放延迟,而使得服务不可用时间可能会滞后。
服务不可用时间充满了不确定性,那如何保证SLA呢?
故障有可恢复和不可恢复之分,通过我们观察,除了那种机器宕机、磁盘坏块这类彻底恢复不了的场景,大部分故障都是短期的。比如网络抖动,一般情况下网络架构也是冗余设计的,可能过一小段时间链路就重新正常了。比如主库OOM、Crash等场景,mysqld_safe会迅速的重新拉起实例。
恢复后的老主一定是没有延迟的,对于重启的场景来说,会有一个Crash Recovery的时间。这时,最小不可用时间就变成了一个数学问题——到底是新主追回放延迟的速度快,还是老主恢复正常的速度快?
因此,在三节点企业版中,我们做了一个状态机诊断和主动切换的功能。
在三节点企业版的内核中,通过状态机诊断接口,服务层有能力向协议层汇报当前状态机的健康状况,包括回放延迟、Crash Recovery、系统负载等状态。
当状态机健康状况影响服务可用性时,会尝试找一个更合适的节点主动切换出去。主动切换功能和权重选主也是深度整合的,在挑选节点的时候,也会考虑权重的信息。
最终,服务恢复可用后诊断逻辑会自动停止,避免在稳定Leader的情况下产生不必要的切换。
4.磁盘探活
数据库系统会遇到Disk Failure或者Data Corruption这样的问题。我们曾经遇到过这样的情况,磁盘故障导致IO卡住,Client完全无法写入新的数据。由于网络是连通状态,节点之前的选举租约可以正常维持,三节点自动容灾失效导致故障。
针对这类问题,我们实现了磁盘探活功能。对于本地盘,系统自动创建了一个iostate临时文件,定期向其中执行随机数据读写操作。对于云盘这类分布式存储,我们对接了底层的IO采样数据,定期来感知IO hang或者Slow IO的问题。探测失败次数达到某个阈值后,系统会第一时间断开协议层的网络监听端口,之后尝试重启实例。
5.反向心跳
在长时间的线上实践中,我们发现有些问题从节点内部视角发现不了,比如主库连接数被占满,open files limit配置不合理导致“Too many open files”报错……
对于这些场景,从选举租约、状态机、磁盘探活的角度,都无法正确检测故障,因此最好有一个能从App视角去建立连接、执行SQL、返回结果的全链路检测流程。因此,我们研发了Follower反向心跳的需求,即Follower通过SQL接口去主动探测Leader的可用性。
该设计有两个优势:首先是内核自封闭,借助三节点的其他非Leader节点,不依赖外部的HA agent进行选主判定,就不用再考虑HA agent本身的可用性问题;其次和内核逻辑深度整合,不破坏原有的选主逻辑。
总的来说,RDS三节点企业版是一套完善可靠的高可用数据库解决方案。通过多副本同步复制,确保数据强一致性,提供金融级的可靠性,为业务数据保驾护航。
李飞飞力荐
云计算已经成为承载数字化经济的基础设施,如同水电煤之于日常生活服务一样,用户并不关心资源的物理部署情况,只需随手取用。数据库作为传统IT服务、云计算以及数据驱动业务的核心系统,在快速地向云原生和云化服务的方向上转型,以往需要专业人员规划、部署、运维的数据库系统,如今成为唾手可得、按需取用、安全可靠、高性价比的服务,这一切得益于云原生技术助力数据库系统进化演进,通过对资源使用的分层解耦,打破物理机器资源使用限制,利用云计算资源池化的能力,构建出健壮、实时弹性伸缩、高可用的数据库服务。本书从数据库基本原理出发,讲述进化到云数据库的历程,并重点介绍了云数据库的选型、运维和最佳实践,深度凝聚了阿里云数据库服务团队十年来的技术积累,对数据库领域从业人员,无论是运维人员、应用人员还是研发人员都将大有裨益。
李飞飞
阿里云数据库产品事业部总裁 ACM杰出科学家
中国计算机协会大数据专家委员会副主任
达摩院数据库与存储实验室负责人


▊《云数据库架构》
朱明 等 著
- 引领云数据库技术,详解9大云数据库引擎,5大行业技术选型!
- 阿里云数据库产品事业部总裁、达摩院数据库与存储实验室负责人李飞飞力荐
“阿里云数字新基建系列”包括5本书,涉及Kubernetes、混合云架构、云数据库、CDN原理与流媒体技术、云服务器运维(Windows),囊括了领先的云技术知识与阿里云技术团队独到的实践经验,是国内IT技术图书又一重磅作品。
数据库技术,被称为“计算机三驾马车”之一,几十年来,持续支持着全球亿万数字业务的运行,而云计算的出现,赋予了数据库新的能力。云数据库按引擎能力,可以分为关系型数据库、非关系型数据库、数据仓库和分布式新型数据库。本书从技术原理入手,讲解各种数据库的特点,分析不同场景的架构选型和数据库优化,继而展开到云数据库的迁移、云数据库的运维工作,期望能帮助读者了解和掌握云数据库相关知识与技能。

(京东满100减50,快快扫码抢购吧!)
如果喜欢本文欢迎 在看丨留言丨分享至朋友圈 三连
热文推荐
用Python直观查看贵州茅台股票交易数据
书单 | 11月新书速递!Apache Pulsar首著来啦
Serverless:微服务架构的终极模式
详解阿里开源分布式事务框架Seata▼点击阅读原文,查看本书详情~