本文重点:
- 学会抓取文章评论
- 学会文本分词、制作词云
目录
🍑 一、抓取全部评论
🍞 1、找到评论接口
🍏 2、Python 获取评论
🏈 二、文本分词、词云制作
🍋 1、文本分析
🍐 2、生成词云
🏆 3、初步效果-模糊不清
⚽️ 4、最终效果-高清无马
🍑 一、抓取全部评论
吾的这篇文章,有 1022 次评论,一条条看,吾看不过来,于是想到 Python 词云,提取关键词,倒也是一桩趣事。

评论情况: {'android': 545 次, 'ios': 110 次, 'pc': 44 次, 'uniapp': 1 次}
一个小细节:给我评论的设备中,安卓苹果比是 5:1。
Building prefix dict from the default dictionary ... Loading model cost 0.361 seconds. Prefix dict has been built successfully.
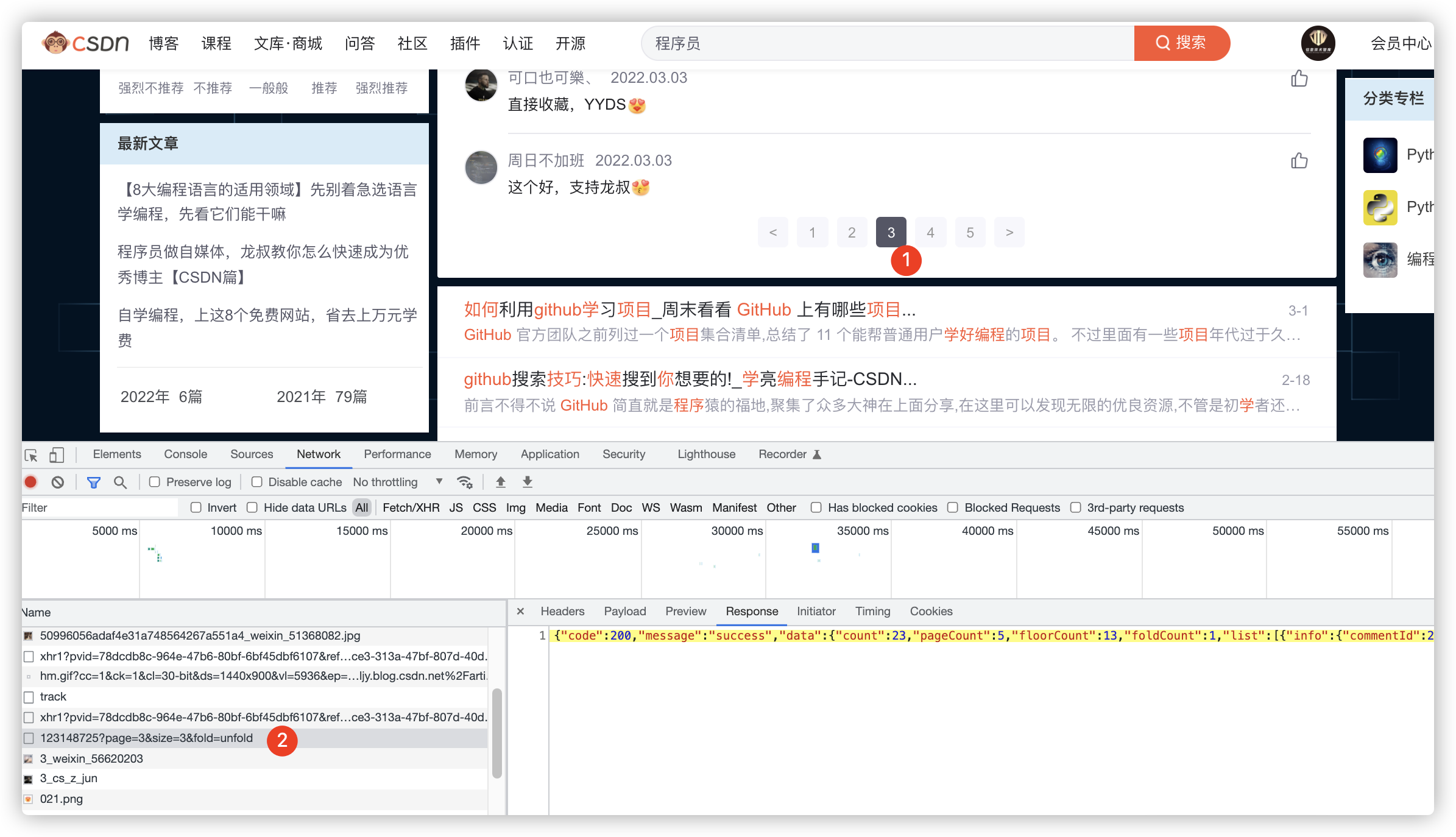
🍞 1、找到评论接口
- 打开 chrome 浏览器,开发者模式
- 点击评论列表(图标 1)
- 点击接口链接(图标 2)
- 查看 response 返回值(评论结果的 json 格式)
🍏 2、Python 获取评论
def get_comments(articleId): # 确定评论的页数 main_res = get_commentId(articleId,1) pageCount = json.loads(main_res)['data']['pageCount']
comment_list,comment_list2 = [],[]
source_analy = {}
for p in range(1,pageCount+1):
res = get_commentId(articleId, p)
try:
commentIds = json.loads(res)['data']['list']
for i in commentIds:
commentId = i['info']['commentId']
userName = i['info']['userName']
nickName = i['info']['nickName'] ## 获取用户名
source_dvs = i['info']['commentFromTypeResult']['key'] # 操作设备
content = i['info']['content']
comment_list.append([commentId, userName, nickName, source_dvs, content])
comment_list2.append("%s 丨 %s"%(userName, nickName))
if source_dvs not in source_analy.keys():
source_analy[source_dvs] = 1
else:
source_analy[source_dvs] = source_analy[source_dvs] + 1
# print(source_analy)
except:
print('本页失败!')
print('评论数:' + str(len(comment_list)))
return source_analy, comment_list, comment_list2
🏈 二、文本分词、词云制作
🍋 1、文本分析
西红柿采用的是 结巴 分词, 和 wordcloud。
# -- coding:utf8 --
import jieba
import wordcloud代码实现:
seg_list = jieba.cut(comments, cut_all=False) # 精确模式
word = ' '.join(seg_list)🍐 2、生成词云
背景图 西红柿采用的是 心形图片
pic = mpimg.imread('/Users/pray/Downloads/aixin.jpeg')完整代码::
def word_cloud(articleId):
source_analy, comment_list, comment_list2 = get_comments(articleId)
print("评论情况:", source_analy)
comments = ''
for one in comment_list:
comment = one[4]
if 'face' not in comment:
comments = comments + comment
seg_list = jieba.cut(comments, cut_all=False) # 精确模式
word = ' '.join(seg_list)
pic = mpimg.imread('/Users/pray/Downloads/aixin.jpeg')
wc = wordcloud.WordCloud(mask=pic, font_path='/Library/Fonts/Songti.ttc', width=1000, height=500,
background_color='white').generate(word)
🏆 3、初步效果-模糊不清

西红柿发现文字模糊、图像曲线边缘不清晰的问题。
于是,指定分辨率,高清整起来。
# 保存
plt.savefig('xin300.png', dpi=300) #指定分辨率保存⚽️ 4、最终效果-高清无马

原来粉丝评论最多的词是:不错、厉害、收藏了、支持、好
谢谢你们,我爱粉丝,粉丝爱我。
🍟 Python 理论基础:全网最全丨 Python 快速入门专栏
🍇 Python 练习应用:全网最黑丨 Python 黑科技专栏