腾讯云数据库TDSQL与中国人民大学最新联合研究成果被SIGMOD 2022接收并将通过长文形式发表。SIGMOD是国际数据管理与数据库领域顶尖的学术会议之一,腾讯云数据库TDSQL论文已连续多年入选VLDB、SIGMOD、ICDE等国际顶级会议。
本次入选论文题目为:CompressDB: Enabling Efficient Compressed Data Direct Processing for Various Databases。论文针对压缩数据的直接操作与处理,提出一项新型数据库处理技术——CompressDB。本研究提出并实现了新型数据库技术,利用上下文无关文法来压缩数据,通过新的数据结构和算法设计实现对语法规则进行解析,CompressDB支持直接对压缩后的数据进行数据查询和操作,并且支持各种数据库系统。
SIGMOD评委对CompressDB的创新性给予了高度评价:在本文中,作者提出了一个支持直接对压缩数据进行更新和计算的系统CompressDB,是一个优秀的系统工作。其作为文件系统层实现,可以被现有的数据库系统直接使用,作者通过在其上运行一系列关系数据库和 NoSQL 数据库来证明了这一点。同时作者在实现中表明,启用CompressDB可以让数据库系统实现更高的吞吐量和更低的延迟,同时减少存储空间。
论文概述
在如今的数据管理系统中,处理大数据时直接在压缩数据上进行操作被证明是一种很成功的方式。这类系统展示了较大的压缩优势和性能提升。但是,当前此类系统只关注数据查询,而一个完整的大数据管理系统必须支持数据查询和数据操作。我们开发了一个新型存储引擎CompressDB。CompressDB 支持压缩数据上的直接数据处理,有以下优点:
第一,CompressDB 利用 context-free 语法来压缩数据,并且同时支持数据查询和数据操作。
第二,我们将CompressDB 集成到文件系统中,使很多数据库系统可以在不做任何改变的情况下使用CompressDB。
第三,我们将算子操作下推到存储层,使得可以直接在存储系统中执行数据查询和数据操作,而不需要把大数据转移到内存中,这提高了系统效率。
我们验证了 CompressDB 可以支持多种类型的数据库系统,包括 SQLite、LevelDB、MongoDB 和ClickHouse。我们用真实应用中的数据集测试了 CompressDB 在单机和分布式环境下的性能,这些数据集有不同的数据量大小、结构和内容。实验表明 CompressDB 平均带来 40% 的吞吐量提升和 44% 的延迟缩短,并实现 1.81 倍的压缩比。
研究动机
现代大数据系统面临指数级增长的数据量,并使用数据压缩来减少存储空间。为了避免频繁的压缩和解压缩操作的开销,现有的研究探索了直接对压缩数据执行大数据操作。这些系统在数据分析应用程序中表现出优秀的压缩效率和性能提升。由于大数据通常存储在磁盘中,我们的想法是基于规则在存储层对压缩数据进行随机更新。
现有技术的局限性
现有的压缩技术在只读的查询处理方面显示出巨大潜力,但功能完整的大数据系统必须同时支持数据的读和写。这就需要系统支持随机更新以及数据的插入和删除。现有的压缩技术并不支持在压缩数据上直接修改数据,因此每次修改时都必须解压缩和重新压缩相对较大的数据块,从而导致巨大的开销。
重要发现
本研究希望开发一种高效的技术来填补现有技术的不足,以支持直接对压缩数据进行更新、插入和删除,从而实现一个支持数据查询和数据操作的高效的大数据系统。这是一项具有挑战性的任务,因为现有的压缩技术大多仅针对压缩效率或读数据操作进行了优化。此外,现有技术的压缩数据结构不能修改。例如,一些压缩技术基于索引和后缀数组,其中压缩元素相互依赖,如果一小部分数据需要更新,则效率极低。
系统设计
本研究开发了一个新的存储引擎CompressDB,支持直接对压缩数据进行数据查询和数据操作,并且支持各种数据库系统。我们发现,如果基于规则的压缩方法的DAG(directed acyclic graph,有向无环图)深度被限制在较小的数值,那么这种压缩方法开销较小,并适用于数据操作。基于此,CompressDB采用基于规则的压缩技术并限制其规则生成深度。同时,CompressDB可以通过操作语法规则对数据进行实时压缩和操作。与之前基于规则的压缩方法相比,我们开发了一系列新的设计:在元素级别,我们提出了一种新的数据结构——数据洞(block hole)。在规则级别,我们为随机更新启用了有效的规则定位和规则拆分方案。在 DAG 级别,我们降低了规则的深度以提高效率。通过利用新的数据结构和算法设计,CompressDB无需解压即可高效处理数据。
5.1 系统设计
图1展示了CompressDB 的系统结构。CompressDB由三大模块组成:1)数据结构模块,2)压缩模块,3)运算模块。这三个模块支持基于CompressDB的数据库系统。数据结构模块为压缩模块和运算模块提供必要的数据结构,包括三种:blockHashTable表示数据内容到块位置的映射关系,blockRefCount记录块被引用次数,blockHole是更新操作引起的存储空洞。压缩模块支持文件系统中的分层压缩,可应用于各种基于块的文件系统。操作模块可以将用户操作下推到文件系统。
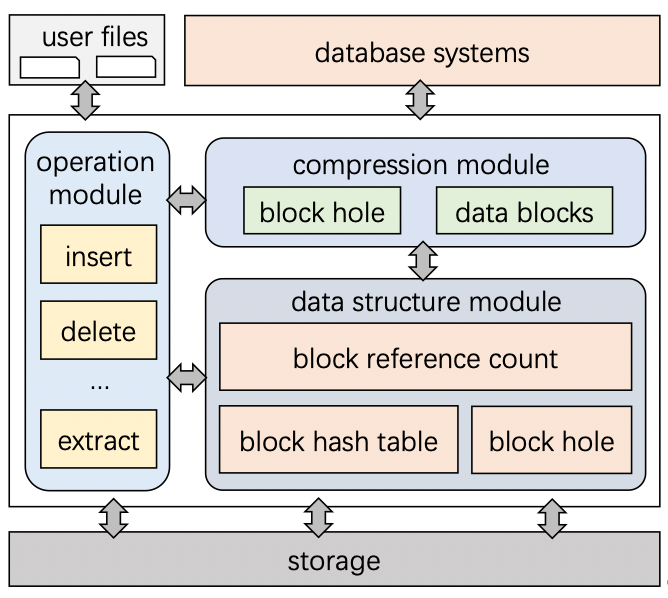
图 : CompressDB系统结构
5.2 操作下推
为了降低数据传输成本,本研究将算子操作下推到存储层。算子下推是指数据处理直接发生在文件系统层(较低的软件层),使处理操作发生在更接近数据的地方。基于这种技术,CompressDB可以显著减少对磁盘的数据访问量,并加速所有上层数据库应用程序。
5.3 与数据库系统的交互
为了使CompressDB能够支持各种数据库,本研究在文件系统中开发CompressDB。在文件系统层,CompressDB 可以处理读取和写入等系统调用,因为它们可以通过“提取”“替换”“添加”等操作实现。因此,CompressDB 可以支持在文件系统上运行的不同类型的数据库系统(例如,SQLite、MySQL、MongoDB 等)。这些数据库系统依赖于 CompressDB 提供的系统调用。因此,CompressDB 可以支持数据库系统的各种数据类型(例如,整数、浮点数、字符串等)和操作(例如,连接、选择、插入等)。此外,我们为CompressDB开发了一些文件系统不支持的操作,例如“插入”和“删除”。因为这些操作没有对应的POSIX接口,我们提供了一组单独的 API,可以有效地使用。
5.4 适用性
CompressDB是一个存储引擎,主要应用是支持各种数据库系统,而无需修改代码。用户唯一需要做的就是将系统存储目录设置为 CompressDB 的存储目录。通常来说,CompressDB 适用于有大量冗余数据,并需要进行数据分析和操作的数据库系统。对于其他应用场景,它可能仍然有效,但尚未验证。
主要成果和贡献
为了验证 CompressDB 的性能,本研究使用CompressDB支持多个数据库系统,包括 SQLite、LevelDB、MongoDB和ClickHouse。本研究分别在单节点和集群环境中,使用多个具有不同尺寸、结构和内容的真实数据集来评估性能。集群环境中的实验使用五节点集群和一种高性能网络分布式文件系统MooseFS。MooseFS 在集群中传输数据并提供对数据的高吞吐量访问。与 MooseFS 的原始版本相比,CompressDB平均带来了 40% 的吞吐量提升、44% 的延迟减少和 1.81 的压缩比,这证明了本研究的有效性。本研究做出以下主要贡献:
• 本研究直接在压缩数据上开发高效的数据操作,例如插入、删除和更新。除了随机访问,本研究还支持数据查询和数据操作。
• 本研究开发了CompressDB,这是一种集成到文件系统中的存储引擎。CompressDB可以无缝支持各种数据库系统,而无需修改数据库。
• 本研究将数据算子操作下推到存储系统,避免了内存和磁盘之间不必要的数据移动,从而提高了压缩数据的处理效率。
本次研究成果面向的领域
本研究成果面向同时支持数据查询和数据操作的大数据管理系统。CompressDB提供的压缩能力使数据管理系统能够存储较大的数据量,同时支持压缩数据上高效的数据查询和操作。存储效率和数据查询、操作效率在当今大数据时代是至关重要的性能指标,CompressDB可以帮助现有的数据库系统同时提升这些指标的性能。
福利来啦!为帮助广大数据库爱好者更加详细地了解本篇论文内容,我们邀请到了中国人民大学副教授、博士生导师、腾讯犀牛鸟基金获得者张峰老师来到直播间深度解读。6 月 21 日 15:00,一起来直播间学习吧!
扫描海报二维码或点击阅读原文,即刻报名参会!

﹀
﹀
﹀
-- 更多精彩 --

三篇论文入选国际顶会SIGMOD,厉害了腾讯云数据库

TDSQL两篇论文入选SIGMOD,产学研结合助力国产数据库生态建设
↓↓点击阅读原文,立即预约直播