文章目录
- 做不好关联分析的原因
- 在数据模型层面解决关联
- 给业务人员看的懂的数据结构
- 多级关联表
- 自关联表
- 互关联表
- 重复关联表
- 结语
- 润乾报表资料
事物都是普遍联系的,很难有一个独立的事物不和其它发生关联,数据表也一样,很多有业务意义的查询都会涉及多个数据表的关联
数据分析以及 BI 类软件通常会提供自助查询功能,有些软件还能支持关联查询,但实际使用的大多数还是单表的,也就是我们常说的宽表,而提供的自助关联查询功能则很少被业务人员使用,这是几乎所有 BI 类软件的软肋,无论大牌小众,一试一个准 这里有个测试报告看看:国内主流 BI 产品关联分析能力对比
为什么明明BI软件提供了关联查询,业务人员却不用呢,因为不会用,简单的关联,BI能对付,复杂一些的,BI软件表现出来的连自己的工程师都看着晕,让用户自己去做关联就更不可能了,于是只能做一个宽表给用户用
宽表的局限性其实很明显,数据冗余,维护麻烦这些就不说了,单单是:只能基于宽表现有的关联做分析,用户分析需求超出范围,或者有变化,就得技术人员修改或者重新做宽表这一条,就足够把用户和BI厂商都压垮了,用户不自由,啥也得厂商帮忙,今天想做的分析,可能得一周以后才能做;厂商更不乐意,每一次修改和重做,都是人工成本,可是自己产品提供的自助关联又不好用,也只能任用户摆布了
做不好关联分析的原因
那么,BI软件提供的自助关联哪里不好用呢?答案是简单的还勉强可以,复杂的都搞不了
简单的每个表之间只关联一次的情况,业务人员可能还能理解,可以用,比如
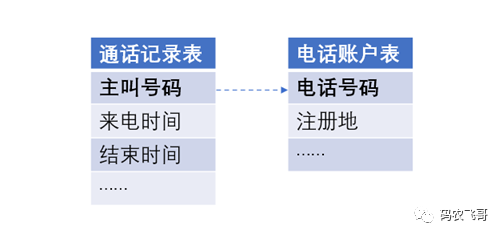
我们要查询:北京号码的拨打记录
这时候只需要通话记录表和电话账户表关联一次就可以,从通话记录表中查询账户表中注册地是北京的号码的所有拨打记录
但实际分析中,要查询的情况远比这个要复杂,有很多重复关联、相互关联、自关联的,这些情况,就算是技术人员也得花挺长时间才能捋顺,更别说业务人员了,我们来继续看
重复关联
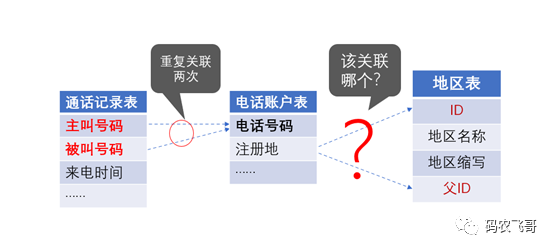
我们要查询:北京号码打给上海号码的通话记录
这就需要把通话记录表和电话帐户表做两次关联,分别使用通话记录表的主叫号码和被叫号码关联,才能分别取出主叫号码注册地和被叫号码注册地。首先要把同一个电话帐户表关联两次,这就有相当一部分软件根本不支持了;其次,还要分别取出两次注册地字段,要分清楚是用主叫号码关联出来的还是用被叫号码关联出来的,这就要给电话帐户表起不同的别名来区分(SQL 就是这么干的),这个概念又会让非专业人员感觉很糊涂
我们这个例子实际上已经简化了,通常电话帐户表中并不会直接存储北京、上海这种级别的地点,而是会用一个地点编号去和地区表关联,从地区表中才能再取出这个地点编号对应的地点所在的省级区域(甚至可能再分几级)。那么上述关联过程中,这个地区表也会跟随着被关联两次,也要起别名才能区分。如果地区再分级了(这其实是常有的事),被跟随关联两次的表就更多,关联表稍多时,连技术人员都要小心仔细才能搞得清,业务人员基本上就没可能理清楚了
相互关联
我们要查询:女经理手下的男员工
人事系统里员工表,还有部门表。员工表中有所属部门的字段与部门表关联,部门会有经理,而经理也是个员工,部门表中的经理字段会再和员工表关联。这就发生互相关联的情况,转圈了
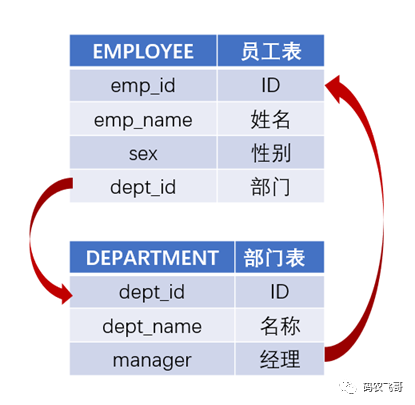
要查女经理手下的男员工,自己想想 SQL 会写成啥样吧。员工表关联到部门表获取部门经理,然后再转回来再和员工表关联获取经理的性别,员工表出现两次,又要起别名,这样才能区分出从员工表中取出来的性别字段是待查员工的还是其经理的
这样的关联,不仅业务人员搞不了,就连很多BI软件本身都做不好这样的查询,工具都不支持,让业务人员怎么做?
自关联
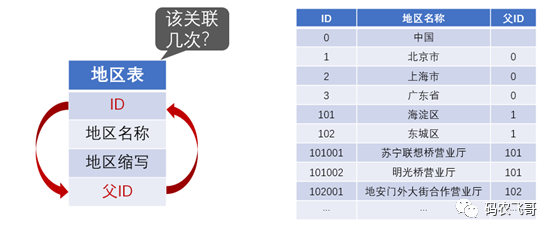
互相关联到极端情况,还会变成自我关联了
比如前面说过地区可能分级,而分级的地区表很可能并不会做成多个表,而是只有一个表,用一个字段表示其上级地区(编号),这是很常见的数据结构设计,但这也意味着地区表会和自己关联。从最低层的营业所(或基站)走到省级区域,可能会有三五级之多,这个表也就要被重复关联三五次,起上三五个别名才分得清,你说业务人员晕不晕?
造成这些难题的根本原因是,SQL 对于 JOIN 的定义过于简单了,用来描述复杂的关联场景时,就会很难理解,容易犯晕,就像用加法来描述乘法一样,而直接原因是BI厂商们也并没有在数据模型层面针对这个难题进行优化封装,只是简单的把表对业务人员做了可视,把难题丢给了没有技术能力的业务人员,结果可想而知,难题更难了
在数据模型层面解决关联
仔细看过前面那个测试报告就会发现,润乾报表的DQL引擎,可以很好的解决这个难题
由技术人员先定义好各种关联关系的DQL元数据,这个元数据,不同于宽表
它预先定义好了各种关联关系,但并没有做实际关联,当用户在前端拖拽分析的时候,才实时生成关联查询,不需要像宽表一样预先关联,占用数据库资源
它的关联关系只要数据表本身结构不变,就不用修改元数据,不需要像宽表一样总得重新生成

DQL 换个思路看待表间关联,允许把外键表的字段当成字段的属性使用,支持无限层级,这样就很好地解决了关联问题。页面端也很好表达,按层展开即可,有多少层都没关系

想更详细了解DQL是怎么解决关联难题的,可以参看:
自助关联分析方案
给业务人员看的懂的数据结构
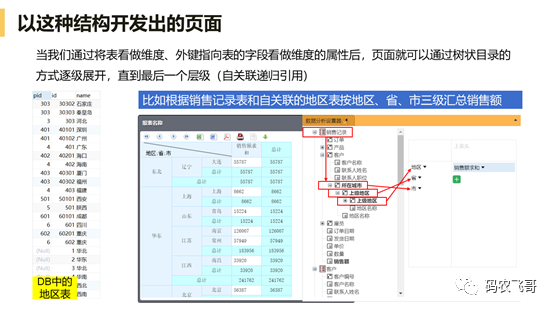
在后端设置好元数据,经过润乾DQL引擎的解析,业务人员看到的就是能清晰理解的树状目录数据了
多级关联表
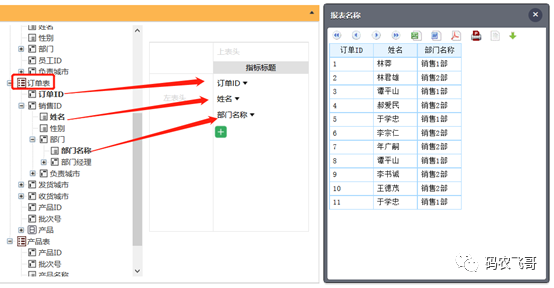
逐层展开后看到多级关联表,可以随意选用各级字段:
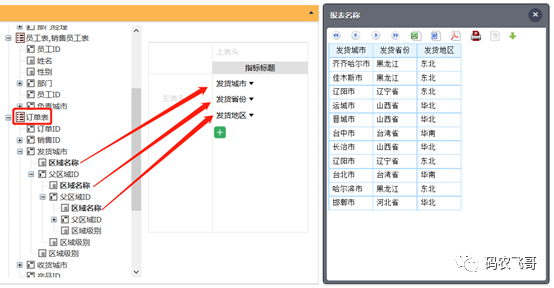
自关联表
订单表的发货城市关联到区域表,之后用父区域可以一直展开,第一次展开父区域是发货省份,再继续展开父区域是发货地区:
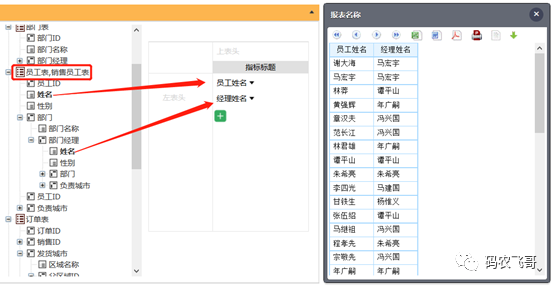
互关联表
员工表里的部门字段展开到部门表,部门表中的部门经理字段又展开回到员工表,这个第三层的员工表,代表的是部门经理这种特殊员工:
重复关联表
订单表里的发货城市、收货城市都关联到区域表,能分别展开,自然的也就分别代表收、发货的相关信息:
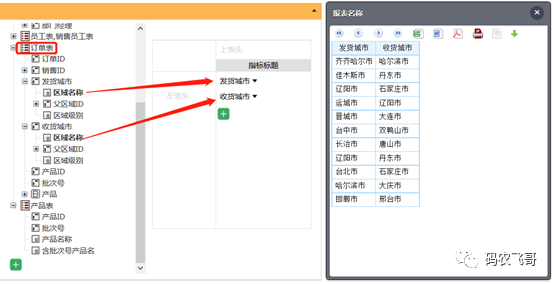
可以看出,我们前面列举的难题,到这里都轻松化解了,业务人员再也不必去理解复杂的表间关系了,看着前台一目了然的数据,直接拖拽分析,后端引擎就做好关联查询了
DQL还支持同维关联、主子关联、多字段关联等更多关联需求,还能够自动选用汇总数据以及支持跨数据库的多维分析
结语
大部分的BI多维分析,可能一张宽表、一个cube就搞定了,但是占少部分的复杂关联分析,才是更考验一个产品是否强大的地方,用一个能解决关联分析的BI工具,不仅可以节省自己的技术人员成本投入,更可以让用户使用体验更好
还要说一句,润乾的DQL是可以免费用的哈,参考:
润乾开源免费 BI 商业规则