
原文:https://zhuanlan.zhihu.com/Ehco-python
作者:Ehco
编辑:咸鱼
今天折腾啥呢?
上个月(201908)低价薅的华为云加上上次薅的腾讯云,手上已经有三台云服务器落灰了。
这玩意儿还不如 Kindle 呢,至少 Kindle 还能盖个泡面。

而由于备案相关的问题 个人小站一般不会托管在国内的服务器上(仅仅是我)

所以这台服务器很长时间以来只跑了:
- 微信公众号的后端项目
- 上学那会给女票做的小说网站(没有域名直接ip解析过去的 就没备案)

总觉得不能就这样浪费 那么做什么好呢?
写代码的怎么能没有点自己的 side project ? 我当然也不例外
我一直维护着一个叫『谜之屋』的开源项目:
https://github.com/Ehco1996/django-sspanel
所以我决定为这个项目搭一套的监控系统
这个系统主要分为3个部分:
- sentry (bug跟踪管理)
- prometheus (metrics / node数据监控)
- grafana (数据监控仪表盘)
所以这台服务器就又活了过来。

sentry
首先是sentry,谜之屋就有一些bug尚未解决

Sentry不仅仅能告诉你哪些代码片段出了问题,还能展示出完整的错误栈,帮你快速定位bug
举个例子「URLError」点进去是这样的

通过观察,我们发现是在调用支付宝api的时候发生了网络的错误,我们甚至能在右侧看到有多少用户遇上了这个错,包括:
- 他们用的系统是什么
- 浏览器是什么…
清楚了问题发生的原因和过程,我就可以很快的做出解决方案:
- 请求失败的时候 retry
- 用定时任务去处理失败的消息
prometheus
接着是prometheus(普罗米修斯),这个名字很酷炫有没有,实际上普罗米修斯的功能也很酷炫,我这里只做简单的展示:

普罗米修斯可以收集和管理不同server的metrics。
metrics 数据大概是这样的
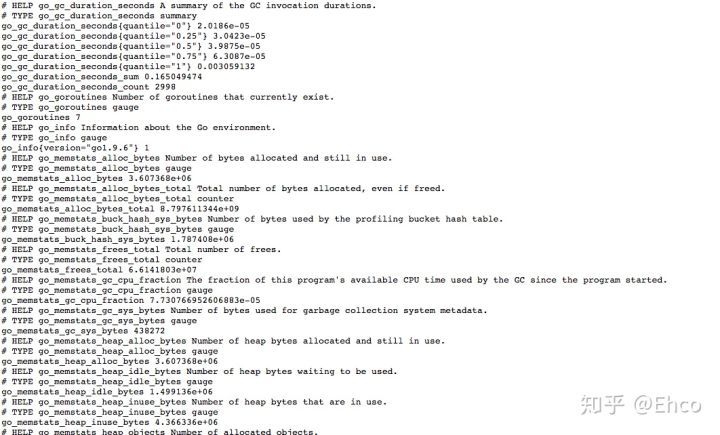
通过这些数据,我们就能查看得到这些node的:
- 健康状态
- 负载状态
- 错误信息
- 报警规则等等等
grafana
最后是 grafana,利用 prometheus是可以收集到很多的数据,但是没有一个图形化的展示,我们人类很难真的看出其中的某些变化。
grafana 就是来帮助我们解决这个问题,他提供了很多dashboard(也可以自己设计),来展示这些数据
比如我们来看一下谜之屋的 api server

可以清楚的看到 cpu 内存 网络 等重要指标的使用状态
谜之屋的访问量很小 所以只用了一台1核1g的vps在跑 不过可以看到,内存已经比较吃紧了
再来挑一个节点node观察一下

可以发现在夜里1点左右,内存的使用有了一次很夸张的增长,然后又迅速跌了下来.
凭借我的经验,这一定事发生了 「memory leak 内存泄露」,我上服务器一看,本来一直在跑的代码果然挂了,爆出了一个大大的 Memory Error.
下面我们来尝试找到发着这次内存爆炸增长的原因
首先是 cpu 的使用状况
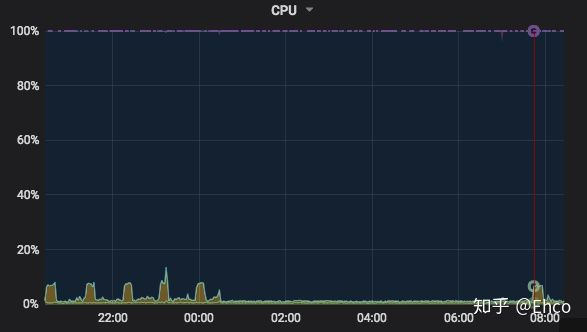
仔细观察一下图表,发现cpu的使用还算比较稳定,负载甚至连20%都没上个,那么问题基本不出在 cpu 上.
再看看网络相关?
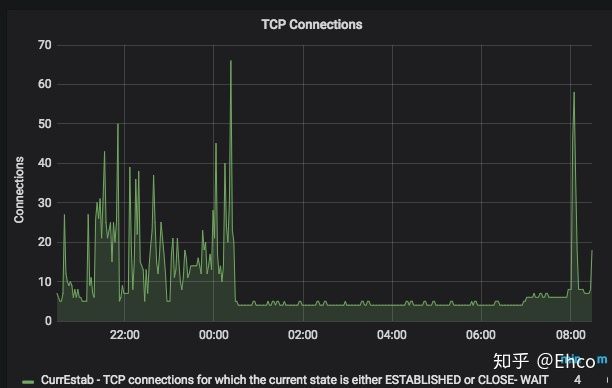
看了这个图之后,一下就明白了,在内存爆掉的那个时刻
- tcp 的连接数量有了一次猛增
- 伴随着socket用的内存也涨了上去

当新的连接不断的建立 旧的又不断开时,我这台只有500m内存的小vps自然撑不住挂了。
最后的发一波参考的安装文档:
sentry: https://docs.sentry.io/ prometheus: https://prometheus.io/docs/ grafana: http://docs.grafana.org/
PS: 推荐全部用docker安装,会减少很多麻烦。
如果安装有困难可以。。。等等,之后会出系列教程。
先预祝各位等等党大获全胜