
世民说:
大海是我多年老友,六七年前我们因OpenStack而相识,然后一起北上创业。创业结束后,他加入了某大厂,成为一名运维骨干。他做事负责,为人靠谱;勤于学习,从OpenStack运维,到K8S和云原生应用运维,不断更新自己的技术栈;喜欢写代码,笃信“能用代码做的事情就不人工做”,经常说“嗨,你看看我新写的这个工具...”;还喜欢分享,写过不少技术文章,我们也常夜聊技术。技术一直在变,我们对技术的热情不变,我们的友情也不变。
作者说:
我在某大厂某事业部担任高级SRE工程师。写作本文的目的,一是督促自己加强学习和归纳总结,二是想给有意从事云原生运维行业的同学们一些生产案例和个人建议供参考,三是在岁末给老友的公众号添一把柴,它明年一定更火。
在当下这云原生时代,Kubernetes和Container已成为新IT基础设施。因此,熟悉这两种技术对于一名合格云原生运维是必不可少的,但这还远远不够。
在笔者的实际工作中,面临的主要技术挑战比如:K8S集群规模庞大,每个运维人员需要管理几十万核资源;业务逻辑复杂,业务模型类似淘宝双11定点秒杀,对资源的弹性要求非常高;业务涉及虚拟资产,因此对系统稳定性和安全性的要求非常高。
根据这几年运维K8S平台及云原生应用的经验,我再列举个人认为必须具备的六个运维技能,供大家参考。不当之处,敬请批评指正。
一、能从海量信息中快速准确定位目标
现在,K8S集群规模都比较大,动辄上千节点,而且集群越来越多。于是,一名运维人员可能需要管理上万K8S节点。而应用容器化后,单一机器上会跑更多程序,而程序多就意味着运维人员会收到更多告警。
但是,你收到的很多告警可能还是关于node的。比如一告警告诉我,某node上有一个进程因OOM被系统杀掉了,但是并没有告知具体是哪一个容器里面的进程。再比如,下面这个告警告诉我这个node上的连接跟踪表(conntrack表)被打爆了。
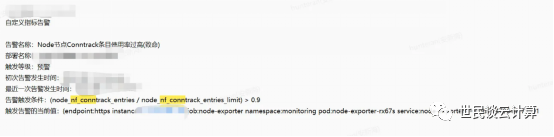
此类报警会告诉你K8S节点上发生了什么,但是并没有告知你是哪个pod出了问题。此时就需要一线运维具有快速定位能力。
以这个“conntrack表被打爆”情况为例,可通过查看/proc/net/nf_conntrack 得出哪个pod占用最高。为了提高查看效率,生产环境中我们制作了一个运维机器人,其功能之一就是快速查询一个指定node上连接数不正常的pod。
二、深入理解虚拟网络,能熟练网络抓包
过去几年,网络虚拟化技术更新迭代得很快,从OpenStack的openvswitch和Linux bridge直到K8S的Flannel和Calico等。真正搞过基础设施运维的人都知道,在生产环境中排查网络丢包问题一直是件非常困难的事情。
在我看来,要做好网络丢包排查,至少需要以下几点:
1、对虚拟网络中端到端流量的南北向和东西向的各个途经节点都非常熟悉。
2、了解 Linux 内核网络相关的基本概念,熟练掌握 ip netns等基础命令。
3、熟悉K8S主流网络模式的原理,勤于学习、研究和练习,根据日志等能快速定位到大概出问题的地方,做到有的放矢。
4、熟练掌握tcpdump 命令,能通过设置端口段、设置ip 段、排除某些端口等,快速抓取想要的网络包。
三、掌握一门编程语言,能开发工具
作为K8S使用者,一定要能看懂K8S源码,并且有能力编译调试代码。同时,还建议熟悉github上开源项目的协同开发流程。以下为笔者提交到社区的一个PR: https://github.com/kubernetes/kube-state-metrics/pull/1570/commits
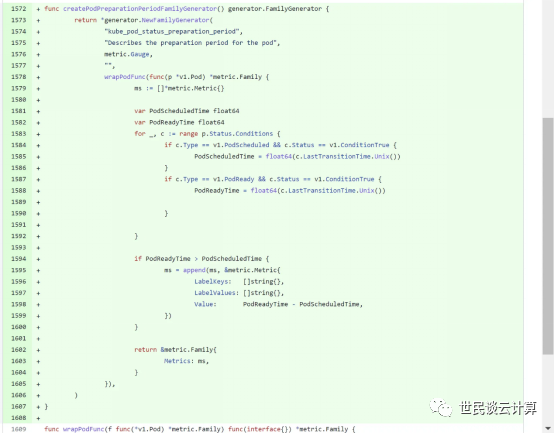
这段代码并不复杂。一方面,其作用是为K8S增加容器启动时间的指标监控;另一方面,通过这种社区代码提交,我们就能学习到完整的开源项目协同开发流程。
此外,在云原生运维场景中,运维人员能自己按需开发运维工具是一项非常重要的技能。该技能一方面能大大提升工作效率,还能提升运维工作的安全性。我们组基于企业微信开发过chatops了运维工具。下面举两个它的功能的示例。
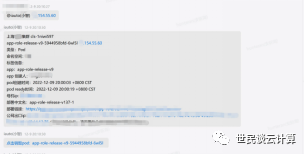
功能1:在内网中,在企业微信聊天框中,向机器人输入一个容器IP,就能立即输出相应容器的详细信息,并可进行容器销毁、隔离等操作。
功能2: 通过机器人快速查询集群资源大盘信息。
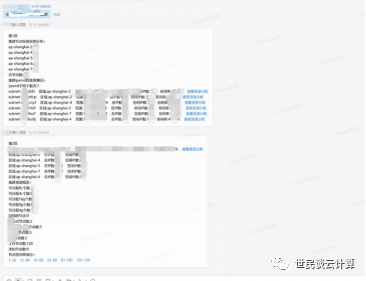
实际上,该机器人功能还有很多。依靠它,我们基本实现了非办公时间能依靠chatops进行日常运维操作和紧急运维操作。
四、熟悉Linux内核网络参数调优
容器环境下,一台宿主机上的所有容器内的应用都共享同一个宿主机内核。内核参数(node维度、pod维度等)的设置对容器和应用程序的稳定性和系统安全性有着重要影响。因此,运维人员需要非常熟悉网络类内核参数的含义和设置方案。
举一个例子。同样是将配置项net.ipv4.tcp_timestamps的值设为1,在Linux 3.x内核和5.x内核中会产生不同效果。设置该参数值为1后,Linux 3.x 内核版本的机器发出的TCP包中会添加时间戳,而且时间戳是递增的;Linux 5.x内核的机器发出的TCP包在添加时间戳的基础上还添加了随机因子,因此时间戳不是的递增的(具体可参考https://elixir.bootlin.com/linux/v5.4.119/source/net/core/secure_seq.c#L118)。这种实现差异,就会导致一个节点发出的网络包达到另一个节点后被内核丢弃,从而造成非常诡异的网络丢包现象。
五、掌握Prometheus优化和Grafana报表制作
Prometheus 和Grafana的组合,已经取代了 Nagios和Zabbix等传统监控系统的地位。Prometheus不仅查询性能好,而且还能存储大量数据。
但是,如果线上环境规模比较大,可能运行着成千上万的容器,所带来的代价是Prometheus 会消耗非常多的内存,这经常会导致它所在的机器产生OOM。另外Prometheus仅存数值型数数据,但是实际的监控往往要求采集各种结构化、半结构化甚至无结构化的数据。
因此,通过优化Prometheus的部署及PromQL 查询语句,来提高数据查询性能和降低内存占用就变得很重要了。下面罗列几个笔者在工作中遇到的优化点:
1、优化大型Prometheus集群的水平扩展性,确保其能按需扩缩容。
2、利用 Prometheus的记录规则(Recording Rule)功能对常见且大量使用的指标进行优化。
3、充分优化 PromQL语句,以降低查询对内存的占用。
4、熟练使用Grafana,并结合Prometheus+MySQL做出效率更高的图表。
六、能进行海量云资源规划和全链路观测
云原生技术使得应用的横向扩缩容变得更加简单,在有效降低成本的同时也对云资源的规划能力提出了更高的要求。
以笔者所在的部门为例,周期性地在某个特定时间点,都会有海量人员涌入。针对此类场景,往往需要我们根据历史数据,结合当前情况为各组件预留出足够资源。
1、为服务构建全链路观测能力,并想各种办法降低平均修复时间(MTTR)。
2、熟练掌握云资源的计费细则,比如包年包月资源如何降低成本,按量付费资源如何避免爆账单。
3、有规划、设计和管理公有云多region大型VPC的能力。
4、了解各大公有云厂商的常见产品以及不同厂商同类产品的横向纵向对比情况。
写在最后
一是,给想转型的传统运维的两点个人建议:
1、熟练徒手搭建K8S集群,并通过更换不同的网络插件加强对虚拟网络的理解。
2、提升英语水平,至少能满足这两个要求:一是能把自己遇到的问题在英语论坛或者英语搜索引擎中搜索出来,二是有能在类似stackoverflow论坛发帖或者回帖能力。
二是,给有志这个职业方向的学生们几点个人建议:
1、买一个支持openwrt的路由器。基于这种路由器能实现很多有趣的功能,能做到边玩边学。比如将路由器放在宿舍里,接一个摄像头,每当宿舍有人开门时候,发送一条通知到手机。
2、在日常坚持使用ubuntu或centos等Linux操作系统。
3、学会使用Git,可尝试用它做为自己的笔记本,记录自己工作学习中的点点滴滴。
4、学会Go和Python等语言,并结合K8S进行编程实践,比如开发一个管理K8S资源的小型网站。
5、购买公有云厂商的学生套餐,学习在云上做程序开发。
6、考取一门或几门公有云大厂的证书。