大语言模型长序列是近期研究的热点,如何训练超长序列的模型成为关注的重点。序列并行(SP)是一种将输入序列维度进行切分的技术,它已成为训练和推理更长序列的一种有效方法。近段时间,腾讯云在大模型序列并行领域取得重大突破,推出了创新的USP(Unified Sequence Parallel)技术。对比主流的DeepSpeed-Ulysses[1]和Ring-Attention[2]序列并行方式,USP在DiT场景下生图的性能提升最多24%,在LLAMA2-7B场景的性能提升最多2倍以上,为DiT和长序列场景提供强力支持。
融合创新,突破瓶颈
USP技术巧妙地结合了DeepSpeed-Ulysses和Ring-Attention两种先进的序列并行方法,创造性地提出了“2D混合序列并行”的概念。这种混合并行方式不仅继承了两种方法各自的优点,还克服了它们各自的局限性,堪称序列并行技术的集大成者。
DeepSpeed-Ulysses和Ring-Attention是当下较为成熟的两种序列并行技术。DeepSpeed-Ulysses利用All2All通信处理Q、K、V和O张量片段,将张量的并行切分从序列维度转为注意力头数维度,使每个注意力头的计算保持完整。Ring-Attention则采用嵌套双层循环,以块的方式协调通信和计算,通过点对点通信获取所需的K和V张量片段。
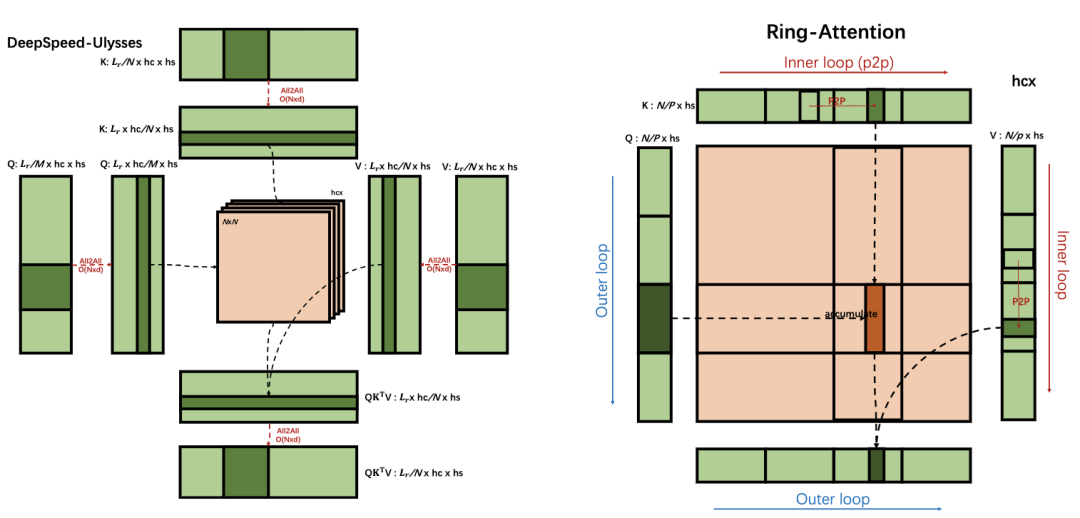
DeepSpeed-Ulysses和Ring-Attention的通信原理示意图
然而,这两种方法各有局限性:Ulysses的SP并行度受限于注意力头数量,Ring的计算效率因矩阵乘法细分而降低。为此,腾讯云团队提出了USP方法,将两种方法结合使用。
USP将SP进程组分为正交的SP-Ring和SP-Ulysses两组,形成二维网格结构。它的算法流程包括:
1) 使用AlltoAll交换query、key、value;
2) 各组内进行独立的Ring-Attention计算;
3) AlltoAll通信使各组具有完整的Head Output结果。

Unified SP的算法流程
USP带来的好处是,它覆盖原来二者的能力,在没有能力损失的情况下带来了额外好处。USP避免了Ulysses SP并行度的限制,混合并行的通信模式更适合异构网络;在PCIe和多机多卡环境下,相比单独使用Ulysses或Ring都有明显加速效果。
4D并行:全方位优化
腾讯云团队在USP的基础上,进一步探索了SP+DP+TP+PP的4D并行最佳实践。这种4D并行策略考虑了数据并行(DP)、张量并行(TP)、流水线并行(PP)与序列并行(SP)之间的关系,为不同场景提供了优化方案:
1. DP和SP:优先使用DP,只有在批量大小不足时才考虑SP。
2. ZeRO和SP:SP应与ZeRO-1/2结合使用,也可考虑ZeRO-3和Offload技术。
3. TP和SP:在内存效率上,SP+ZeRO3可以达到与TP相似的序列长度;在通信效率上,SP优于TP。
4. TP和SP混合:在小规模集群上可带来速度提升,在大规模训练中可实现超长输入序列。
这种4D并行策略为不同规模和需求的模型训练提供了灵活的选择,进一步提升了性能和效率。SP,DP,ZeRO和TP的通信和内存开销总结如下表所示:
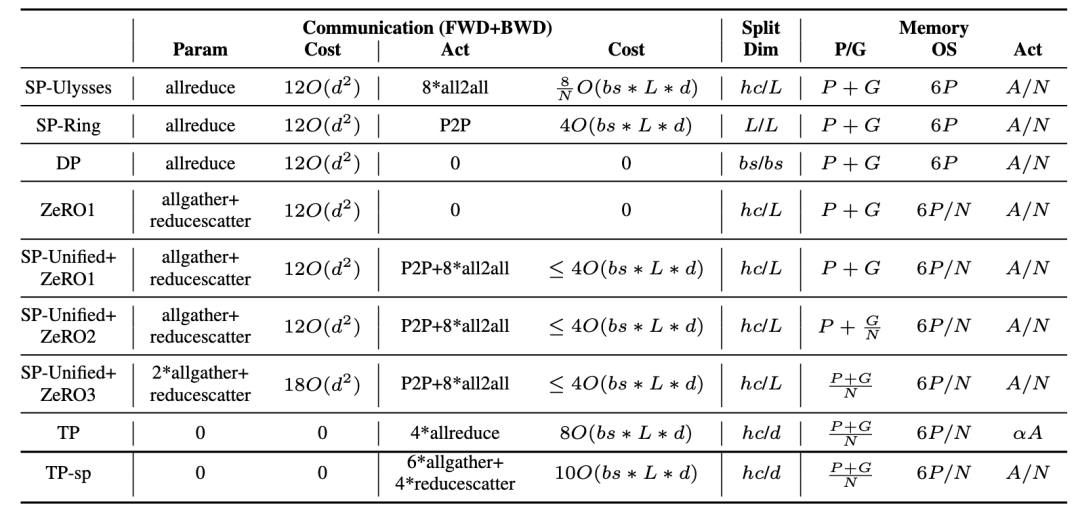
SP,DP,ZeRO和TP的通信和内存开销对比
灵活适配,广泛应用
腾讯云团队在LLAMA3-8B模型场景的测试结果显示,采用USP 4D并行后,模型训练的MFU (Model FLOPs Utilization) 显著超过Megatron-LM原生的最佳实现。这意味着客户可以用更低的成本训练或微调自己的模型。
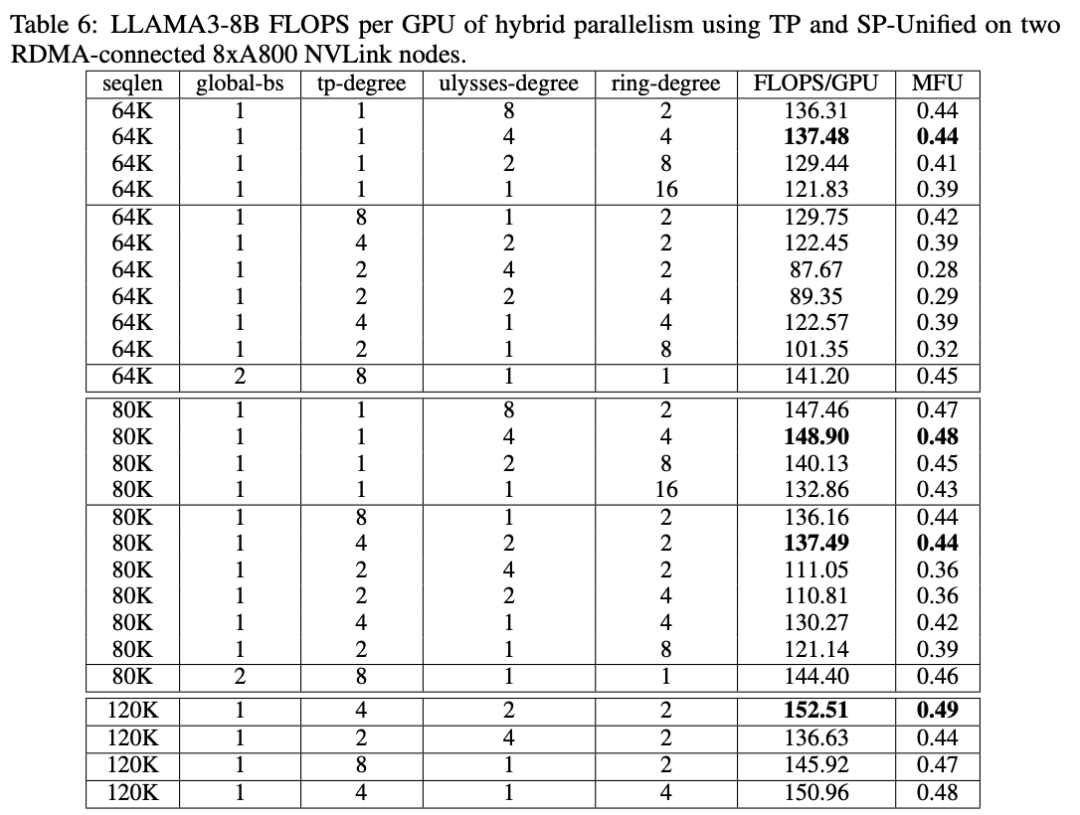
不同4D并行并行策略和对应的训练性能
此外,USP不仅适用于语言模型训练,在基于DiT架构的模型推理领域同样表现出色。以Pixart-Alpha模型为例,采用USP后,图片生成的延迟大幅降低,相比Ring-Attention最多提升24%,即使在高分辨率图片生成场景,性能提升依然显著。
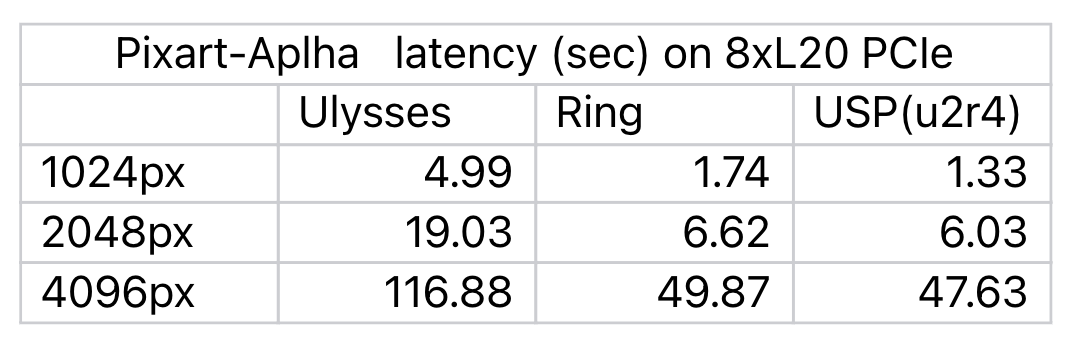
采用不同通信策略的Pixart-Alpha模型的生图速度(单位:秒)
扩展性强,潜力无限
随着GPU数量的增加、集群规模的扩大,USP的优势愈发明显。当训练Llama2-7B时,在16卡、32卡(序列并行维度为16或者32的场景下)的大规模训练场景中,USP的性能可以达到Ring-Attention的2倍以上,USP有望为大规模的模型训练和模型推理带来更高性能。
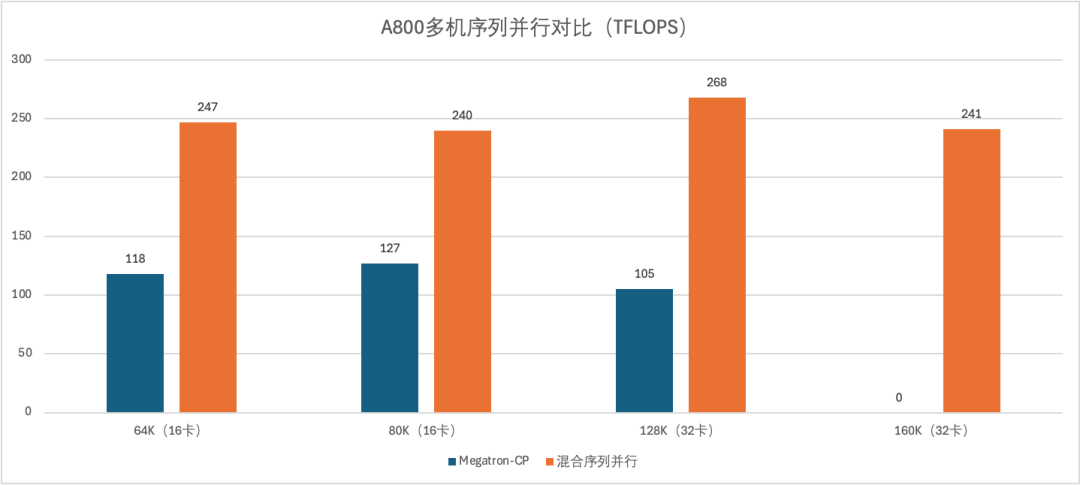
A800多机序列并行对比(单位:TFLOPS)
腾讯云:引领AI革命
腾讯云TACO的USP并行方法对开源社区做出了贡献。一些后续的杰出开源工作,如华为MindSpeed项目[3]和上海人工智能实验室LoongTrain项目[4],均参考了USP序列并行的部分思路。
作为AI领域的领军者,腾讯云始终致力于突破技术边界,为客户提供最先进、最高效的AI解决方案。搭载USP技术的TACO加速套件将于近期登陆腾讯云高性能应用服务HAI。如果您想探索TACO加速套件的更多应用可能,欢迎点击原文留下您的联系方式。未来已来,智能无限。让我们共同期待TACO加速带来更多惊喜和可能。
[1]Jacobs, Sam Ade, et al. "Deepspeed ulysses: System optimizations for enabling training of extreme long sequence transformer models." arXiv preprint arXiv:2309.14509 (2023).
[2]Liu, Hao, Matei Zaharia, and Pieter Abbeel. "Ring attention with blockwise transformers for near-infinite context." arXiv preprint arXiv:2310.01889 (2023).
[3]docs/features/hybrid-context-parallel.md · Ascend/MindSpeed - Gitee.com
[4]Gu, Diandian, et al. "LoongTrain: Efficient Training of Long-Sequence LLMs with Head-Context Parallelism." arXiv preprint arXiv:2406.18485 (2024).