前言
关于活体检测,我们知道活体检测技术包括静态活体检测与动态活体检测。
与动态活体检测不同,静态活体检测是指判断静态图片是真实客户行为还是二次翻拍,用户不需要通过唇语或摇头眨眼等动作来识别。一般应用在防攻击不高的场景中。而动态活体检测是指通过指示用户做出指定动作动作(读数,眨眼,左右摇头等),验证用户是否为真实活体本人在执行当前的操作。
人脸静态活体检测 在使用中遇到报错的情况先看官网文档错误码类型。如下图:
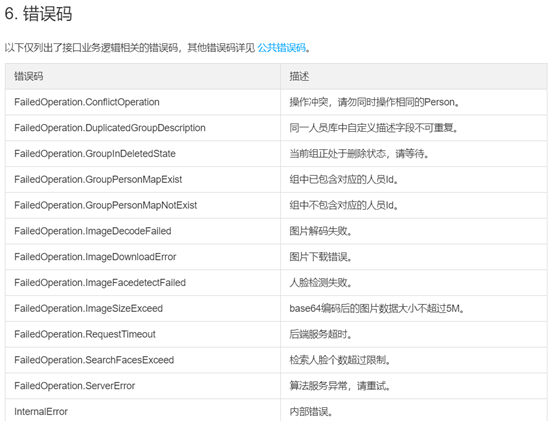
有些报错类型,根据英文意思,自己是能定位原因并解决的。
如:ImageFacedetectFaid,顾名思义,就是人脸检测失败了。为什么会人脸检测失败呢?
一般是因为:
- 照片质量太低,过曝、过暗,色差大,甚至中没有人脸。
- 人脸被遮挡,旋转过多
我会在后续文章中着重讨论下图片中有人脸但是没被检测的情况吧,这里还是不详细展开了。强行回归主题!!

人脸静态活体检测常见问题解析
最近关于人脸识别子产品的静态活体检测遇到有用户反映接口调用后返回值为0的问题。如果遇到上传图片有人脸但是返回非活体的话,我们可以思考以下问题:
a) 图片的宽高比是接近于3:4么?
b) 图片是否是被编辑过,例如编辑过亮度对比度等,或者添加了水印什么的。

是不是要求的条件还蛮苛刻的?
是。
为什么这样子要求呢,难道就不能任意尺寸的照片做活体检测么?
不能。
其实是因为,在日常线上应用中,真人活体样本(正样本)与非真人直接拍摄的样本(负样本)存在着特征区别。负样本中,翻拍样本会经过一个或多个播放设备进行翻拍,(不同手机的摄像头)和不同播放设备(不同手机/电脑/平板等)会呈现出不同特征的边框、反光、摩尔纹;而静态卡片(身份证、打印照片)在翻拍时也会呈现色彩分辨率/对比度与正常样本有明显差异。
基于这样一个原理,静默活体采用深度学习技术,训练一个深层卷积神经网络来学习这些正/负样本的特征。我们的深度神经网络包括卷积、池化、非线性激活、softmax等操作。样本方面,除了腾讯自有的海量真人样本数据外,引擎实验室还从线上业务中采集了全量的攻击视频,并基于不同角度/位置,结合不同播放设备进行大批量的模拟,提供给引擎最大量的训练样本。
正是有上述技术原理,用户无需做任何动作,机器也能从视频中的图像特征来有效区分样本是否为攻击视频,从而保证了平台的安全稳定性。
所以现在应该明白了为什么宽高的尺寸比不能是任意的了。

要是还没明白,那就直接记住吧。
参考官方文档可知:
与动态活体检测的区别是:静态活体检测中,用户不需要通过唇语或摇头眨眼等动作来识别。
如果对活体检测有更高安全性要求,请使用人脸核身·云智慧眼产品。
如果是安全要求级别较高的支付或者政务类用途使用的话,请使用人脸核身·云智慧眼产品。。
产品文档链接:https://cloud.tencent.com/document/product/1007/31002
附加信息:
人脸静态活体检测的计费如下图:
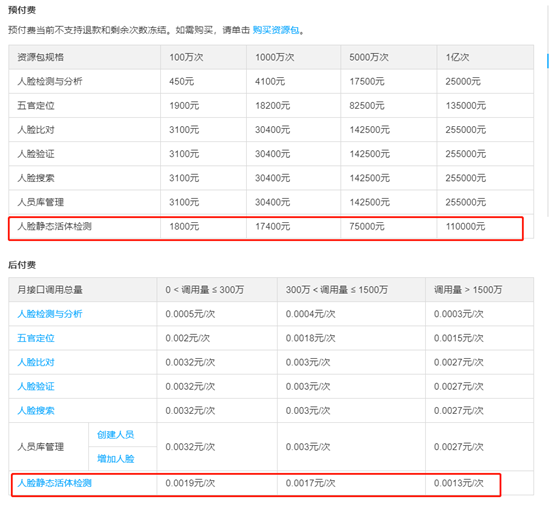
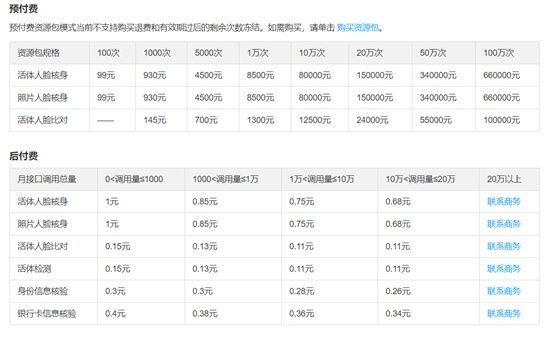
而人脸核身就明显贵了一点,效果当然也好些。
下回再见!
(结束得很是猝不及防有没有)