
1 kube-proxy简述
1.1 kube-proxy简介
kube-proxy是Kubernetes的核心组件,部署在每个Node节点上,它是实现Kubernetes Service的通信与负载均衡机制的重要组件;kube-proxy负责为Pod创建代理服务,从apiserver获取所有server信息,并根据server信息创建代理服务,实现server到Pod的请求路由和转发,从而实现K8s层级的虚拟转发网络。
在k8s中,提供相同服务的一组pod可以抽象成一个service,通过service提供的统一入口对外提供服务,每个service都有一个虚拟IP地址(VIP)和端口号供客户端访问。kube-proxy存在于各个node节点上,主要用于Service功能的实现,具体来说,就是实现集群内的客户端pod访问service,或者是集群外的主机通过NodePort等方式访问service。在当前版本的k8s中,kube-proxy默认使用的是iptables模式,通过各个node节点上的iptables规则来实现service的负载均衡,但是随着service数量的增大,iptables模式由于线性查找匹配、全量更新等特点,其性能会显著下降。从k8s的1.8版本开始,kube-proxy引入了IPVS模式,IPVS模式与iptables同样基于Netfilter,但是采用的hash表,因此当service数量达到一定规模时,hash查表的速度优势就会显现出来,从而提高service的服务性能。
1.2 kube-proxy与Service关系
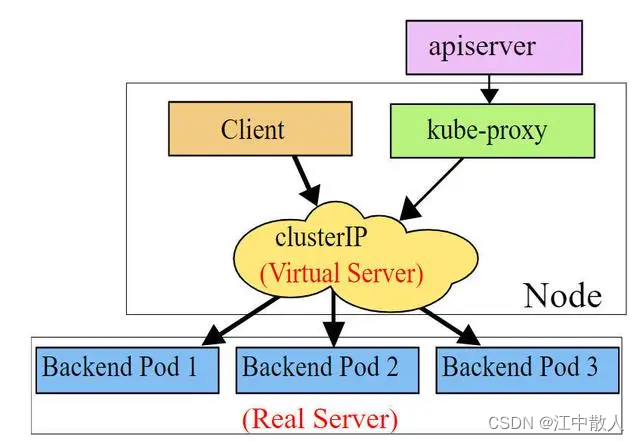
kube-proxy负责为Service提供cluster内部的服务发现和负载均衡,它运行在每个Node计算节点上,负责Pod网络代理, 它会定时从etcd服务获取到service信息来做相应的策略,维护网络规则和四层负载均衡工作。在K8s集群中微服务的负载均衡是由Kube-proxy实现的,它是K8s集群内部的负载均衡器,也是一个分布式代理服务器,在K8s的每个节点上都有一个,这一设计体现了它的伸缩性优势,需要访问服务的节点越多,提供负载均衡能力的Kube-proxy就越多,高可用节点也随之增多。
service是一组pod的服务抽象,相当于一组pod的LB,负责将请求分发给对应的pod。service会为这个LB提供一个IP,一般称为cluster IP。kube-proxy的作用主要是负责service的实现,具体来说,就是实现了内部从pod到service和外部的从node port向service的访问。
简单来说:
- kube-proxy其实就是管理service的访问入口,包括集群内Pod到Service的访问和集群外访问service。
- kube-proxy管理sevice的Endpoints,该service对外暴露一个Virtual IP,也成为Cluster IP,集群内通过访问这个Cluster IP:Port就能访问到集群内对应的serivce下的Pod。
- service是通过Selector选择的一组Pods的服务抽象,其实就是一个微服务,提供了服务的LB和反向代理的能力,而kube-proxy的主要作用就是负责service的实现。
- service另外一个重要作用是,一个服务后端的Pods可能会随着生存灭亡而发生IP的改变,service的出现,给服务提供了一个固定的IP,而无视后端Endpoint的变化。
举个例子,比如现在有podA,podB,podC和serviceAB。serviceAB是podA,podB的服务抽象(service)。那么kube-proxy的作用就是可以将pod(不管是podA,podB或者podC)向serviceAB的请求,进行转发到service所代表的一个具体pod(podA或者podB)上。请求的分配方法一是采用轮询方法进行分配。另外,kubernetes还提供了一种在node节点上暴露一个端口,从而提供从外部访问service的方式。比如这里使用这样的一个manifest来创建service:
apiVersion: v1
kind: Service
metadata:
labels:
name: mysql
role: service
name: mysql-service
spec:
ports:
- port: 3306
targetPort: 3306
nodePort: 30964
type: NodePort
selector:
mysql-service: "true"上面配置的含义是在node上暴露出30964端口。当访问node上的30964端口时,其请求会转发到service对应的cluster IP的3306端口,并进一步转发到pod的3306端口。
Service, Endpoints与Pod的关系:
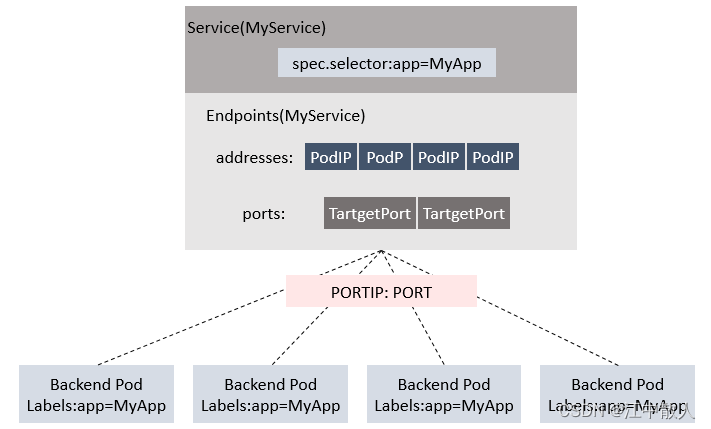
Kube-proxy进程获取每个Service的Endpoints,实现Service的负载均衡功能。
Service的负载均衡转发规则:
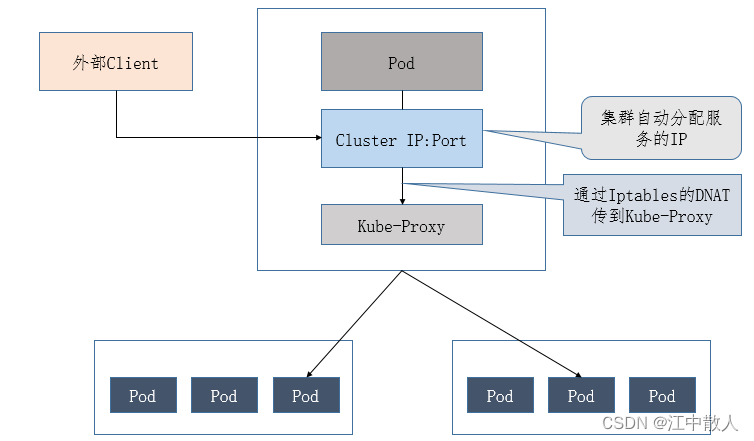
访问Service的请求,不论是Cluster IP+TargetPort的方式;还是用Node节点IP+NodePort的方式,都被Node节点的Iptables规则重定向到Kube-proxy监听Service服务代理端口。kube-proxy接收到Service的访问请求后,根据负载策略,转发到后端的Pod。
2 工作原理
2.1 kubernetes服务发现
Kubernetes提供了两种方式进行服务发现,即环境变量和DNS, 简单说明如下:
1) 环境变量
当你创建一个Pod的时候,kubelet会在该Pod中注入集群内所有Service的相关环境变量。需要注意: 要想一个Pod中注入某个Service的环境变量,则必须Service要先比该Pod创建。这一点,几乎使得这种方式进行服务发现不可用。比如,一个ServiceName为redis-master的Service,对应的ClusterIP:Port为172.16.50.11:6379,则其对应的环境变量为:
REDIS_MASTER_SERVICE_HOST=172.16.50.11
REDIS_MASTER_SERVICE_PORT=6379
REDIS_MASTER_PORT=tcp://172.16.50.11:6379
REDIS_MASTER_PORT_6379_TCP=tcp://172.16.50.11:6379
REDIS_MASTER_PORT_6379_TCP_PROTO=tcp
REDIS_MASTER_PORT_6379_TCP_PORT=6379
REDIS_MASTER_PORT_6379_TCP_ADDR=172.16.50.112) DNS
这是k8s官方强烈推荐的方式!!! 可以通过cluster add-on方式轻松的创建KubeDNS来对集群内的Service进行服务发现。
2.2 kubernetes发布(暴露)服务
kubernetes原生的,一个Service的ServiceType决定了其发布服务的方式:
- ClusterIP:这是k8s默认的ServiceType。通过集群内的ClusterIP在内部发布服务;
- NodePort:这种方式是常用的,用来对集群外暴露Service,你可以通过访问集群内的每个NodeIP:NodePort的方式,访问到对应Service后端的Endpoint。
- LoadBalancer: 这也是用来对集群外暴露服务的,不同的是这需要Cloud Provider的支持,比如AWS等。
- ExternalName:这个也是在集群内发布服务用的,需要借助KubeDNS(version >= 1.7)的支持,就是用KubeDNS将该service和ExternalName做一个Map,KubeDNS返回一个CNAME记录。
2.3 kube-proxy三种代理模式
kube-proxy当前实现了三种代理模式:userspace, iptables, ipvs。其中userspace mode是v1.0及之前版本的默认模式,从v1.1版本中开始增加了iptables mode,在v1.2版本中正式替代userspace模式成为默认模式。也就是说kubernetes在v1.2版本之前是默认模式, v1.2版本之后默认模式是iptables。
2.3.1 UserSpace
UserSpace 是让 Kube-Proxy 在用户空间监听一个端口,所有的 Service 都转发到这个端口,然后 Kube-Proxy 在内部应用层对其进行转发。
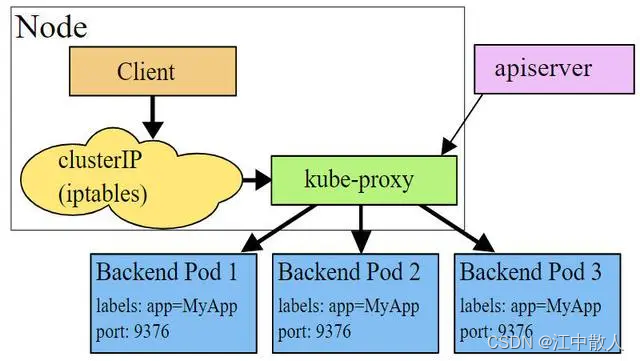
Kube-Proxy 会为每个 Service 随机监听一个端口 (Proxy Port),并增加一条 IPtables 规则。
从客户端到 ClusterIP:Port 的报文都会被重定向到 Proxy Port,Kube-Proxy 收到报文后,通过 Round Robin (轮询) 或者 Session Affinity(会话亲和力,即同一 Client IP 都走同一链路给同一 Pod 服务)分发给对应的 Pod。
这种方式最大的缺点显然就是 UserSpace 会造成所有报文都走一遍用户态,造成整体性能下降,这种方在 Kubernetes 1.2 以后已经不再使用了。
2.3.2 Iptables
IPtables 方式完全由 IPtables 来实现,这种方式直接使用 IPtables 来做用户态入口,而真正提供服务的是内核的 Netilter。
Kube-Proxy 只作为 Controller,这也是目前默认的方式。
Kube-Proxy 的 IPtables 方式也是支持 Round Robin 和 Session Affinity 特性。
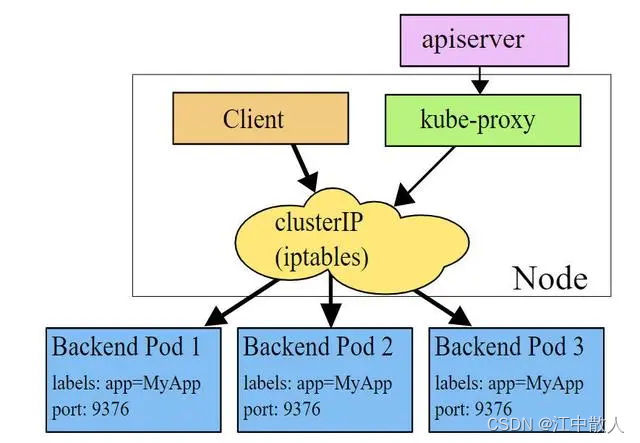
Kube-Proxy 监听 Kubernetes Master 增加和删除 Service 以及 Endpoint 的消息。对于每一个 Service,Kube Proxy 创建相应的 IPtables 规则,并将发送到 Service Cluster IP 的流量转发到 Service 后端提供服务的 Pod 的相应端口上。
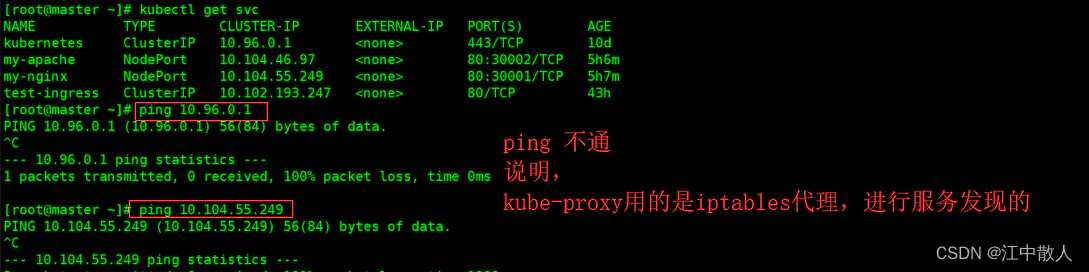
注: 虽然可以通过 Service 的 Cluster IP 和服务端口访问到后端 Pod 提供的服务,但该 Cluster IP 是 Ping 不通的。其原因是 Cluster IP 只是 IPtables 中的规则,并不对应到一个任何网络设备。但IPVS 模式的 Cluster IP 是可以 Ping 通的。
2.3.3 IPVS
Kubernetes 从 1.8 开始增加了 IPVS 支持,IPVS 相对 IPtables 效率会更高一些。
使用 IPVS 模式需要在运行 Kube-Proxy 的节点上安装 ipvsadm、ipset 工具包和加载 ip_vs 内核模块。
当 Kube-Proxy 以 IPVS 代理模式启动时,Kube-Proxy 将验证节点上是否安装了 IPVS 模块,如果未安装,则 Kube-Proxy 将回退到 IPtables 代理模式。
这种模式,Kube-Proxy 会监视 Kubernetes Service 对象 和 Endpoints,调用 Netlink 接口以相应地创建 IPVS 规则并定期与 Kubernetes Service 对象 和 Endpoints 对象同步 IPVS 规则,以确保 IPVS 状态与期望一致。访问服务时,流量将被重定向到其中一个后端 Pod。
与 IPtables 类似,IPVS 基于 Netfilter 的 Hook 功能,但使用哈希表作为底层数据结构并在内核空间中工作。这意味着 IPVS 可以更快地重定向流量,并且在同步代理规则时具有更好的性能。此外,IPVS 为负载均衡算法提供了更多选项,例如:rr (轮询调度)、lc (最小连接数)、dh (目标哈希)、sh (源哈希)、sed (最短期望延迟)、nq(不排队调度)等。
注: IPVS 是 LVS 项目的一部分,是一款运行在 Linux Kernel 当中的 4 层负载均衡器,性能异常优秀。使用调优后的内核,可以轻松处理每秒 10 万次以上的转发请求。
目前在中大型互联网项目中,IPVS 被广泛的用于承接网站入口处的流量。
参考链接
kube-proxy · Kubernetes指南
kubernetes核心组件kube-proxy - 努力乄小白 - 博客园
kube-proxy三种工作模式
kube-proxy 详解_IT小菜鸟@的博客-CSDN博客_kube-proxy
kubernetes网络 - kube-proxy详解 - 刘达的博客
Kube-Proxy简述
解析从外部访问Kubernetes集群中应用的几种方法_Linux云服务器_云网牛站