5万人关注的大数据成神之路,不来了解一下吗?
5万人关注的大数据成神之路,真的不来了解一下吗?
5万人关注的大数据成神之路,确定真的不来了解一下吗?
欢迎您关注《大数据成神之路》

来源 | zh.ververica.com
作者 | 王治江(淘江)
该文为补发昨天的文章
一. 概述
本文讲述的shuffle概念范围如下图虚线框所示,从上游算子产出数据到下游算子消费数据的全部流程,基本可以划分成三个子模块:
- 上游写数据:算子产出的record序列化成buffer数据结构插入到sub partition队列;
- 网络传输:上下游可能调度部署到不同的container中,上游的数据需要经过网络传输到下游,涉及到数据拷贝和编解码流程;
- 下游读数据:从网络上接收到的buffer反序列化成record给op处理。
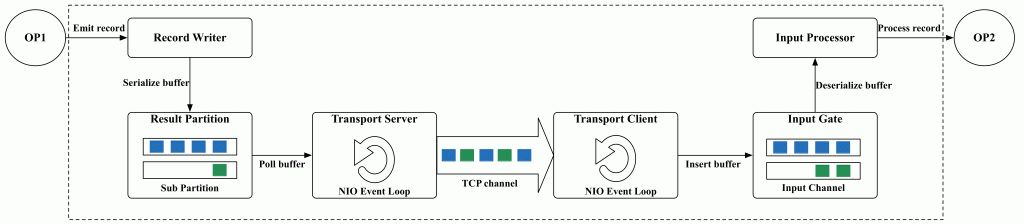
当job被调度开始运行后,除了算子内部的业务逻辑开销外,整个runtime引擎的运行时开销基本都在shuffle过程,其中涉及了数据序列化、编解码、内存拷贝和网络传输等复杂操作,因此可以说shuffle的整体性能决定了runtime引擎的性能。
Flink对于batch和streaming job的shuffle架构设计是统一的,从性能的角度我们设计实现了统一的网络流控机制,针对序列化和内存拷贝进行了优化。从batch job可用性角度,我们实现了external shuffle service以及重构了插件化的shuffle manager机制,在功能、性能和扩展性方面进行了全方位的提升,下面从三个主要方面分别具体介绍。
二. 新流控机制
Flink原有的网络传输机制是上游随机push,下游被动接收模式:
- 一个container容器通常部署多个task并发线程执行op的业务逻辑,不同task线程会复用同一个TCP channel进行网络数据传输,这样可以减少大规模场景下进程之间的网络连接数量;
- Flink定义一种buffer数据结构用来缓存上下游的输入和输出,不同op的输入和输出端都维护一个独立有限的local buffer pool,这样可以让上下游以pipelined模式并行运行的更平滑;
- 上游op产出的数据序列化写到flink buffer中,网络端的netty线程从partition queue中取走flink buffer拷贝到netty buffer中,flink buffer被回收到local buffer pool中继续给op复用,netty buffer最终写入到socket buffer后回收;
- 下游网络端netty线程从socket buffer中读取数据拷贝到netty buffer中,经过decode后向local buffer pool申请flink buffer进行数据拷贝,flink buffer插入到input channel队列,经过input processor反序列化成record给op消费,再被回收到local buffer pool中继续接收网络上的数据;
- 整个链路输入输出端的local buffer pool如果可以缓冲抵消上下游生产和消费的能力差异时,这种模式不会造成性能上的影响。

2.1 反压的产生和影响
实际job运行过程中,经常会看到整个链路上下游的inqueue和outqueue队列全部塞满buffer造成反压,尤其在追数据和负载不均衡的场景下。
- 如上图所示,当下游输入端local buffer pool中的资源耗尽时,网络端的netty线程无法申请到flink buffer来拷贝接收到的数据,为了避免把数据spill到磁盘,出于内存资源的保护而被迫临时关闭channel通道上的read操作。但由于TCP channel是被多个op共享的,一旦关闭会导致所有其它的正常op都不能接收上游的数据;
- TCP自身的流控机制使下游client端ack的advertise window逐渐减小到0,导致上游server不再继续发送网络数据,最终socket send buffer被逐渐塞满;
- 上游的netty buffer由于不能写入到socket send buffer,导致netty buffer水位线逐渐上升,当到达阈值后netty线程不再从partition队列中取flink buffer,这样flink buffer不能被及时回收导致local buffer pool资源最终耗尽;
- 上游op由于拿不到flink buffer无法继续输出数据被block停止工作,这样一层层反压直到整个拓扑的source节点。
反压虽然是很难避免的,但现有的流控机制加剧了反压的影响:
- 由于进程间的TCP共享复用,一个task线程的瓶颈会导致整条链路上所有task线程都不能接收数据,影响整体tps;
- 一旦数据传输通道临时关闭,checkpoint barrier也无法在网络上传输,checkpoint长期做不出来,一旦发生failover需要回放大量的历史数据;
- 除了输入输出端的flink buffer被耗尽,还会额外占用netty内部的buffer资源以及通道关闭前接收到的临时buffer overhead,在大规模场景下容易出现oom不稳定因素。
2.2 Credit-based流控机制
通过上面分析可以看出,上下游信息不对称导致上游按照数据产出驱动盲目的向下游推送,当下游没有能力接收新数据时而被迫关闭了数据通道。因此需要一种上层更细粒度的流控机制,能够让复用同一个物理通道的所有逻辑链路互不影响进行数据传输。
我们借助了credit思想让下游随时反馈自己的接收能力,这样上游可以有针对性的选择有能力的下游发送对应的数据,即之前的上游盲目push模式变成了下游基于credit的pull模式。
- 如下图所示,上游定义了backlog概念表示sub partition中已经缓存的待发送buffer数量,相当于生产者的库存情况,这个信息作为payload随着现有的数据协议传输给下游,因此这部分的overhead可以忽略;
- 下游定义了credit概念表示每个input channel上可用的空闲buffer数量,每个input channel都会独占有限个exclusive buffer,所有input channel共享同一个local buffer pool用来申请floating buffer,这种buffer类型的区分可以保证每个input既有最基本的资源保证不会资源抢占导致的死锁,又可以根据backlog合理的抢占全局floating资源。
- 下游的credit应该尽量及时增量反馈,避免上游因为等待credit而延时发送数据。下游也会尽量每次申请比backlog多一些overhead的credit,可以保证上游新产出的数据不需要等待credit反馈而延时。新定义的credit反馈协议数据量很小,和正常的数据传输相比在网络带宽不是瓶颈的前提下,空间占用基本可以忽略。

2.3 实际线上效果
新流控机制在某条链路出现反压的场景下,可以保证共享物理通道的其它链路正常传输数据。我们用双11大屏的一个典型业务验证job整体throughput提升了20%(如下图),对于这种keyby类型的上下游all-to-all模式,性能的提升比例取决于反压后的数据分布情况。对于one-to-one模式的job,我们实验验证在出现反压场景下的性能提升可以达到1倍以上。

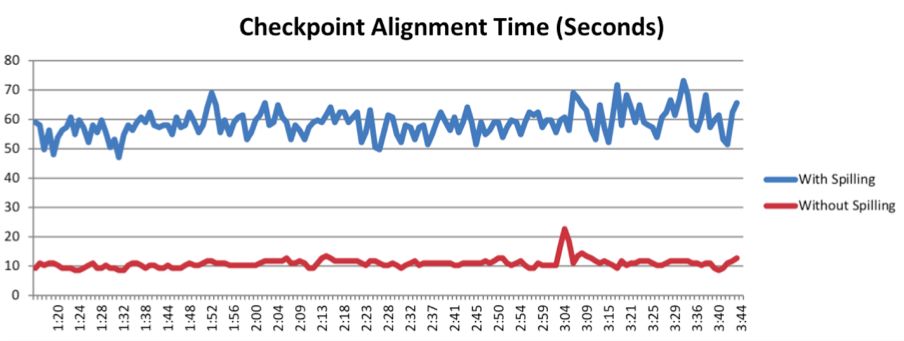
新流控机制保证上游发送的数据都是下游能正常接收的,这样数据不再堵塞在网络层,即netty buffer以及socket buffer中不再残留数据,相当于整体上in-flighting buffer比之前少了,这对于checkpoint的barrier对齐是有好处的。另外,基于新机制下每个input channel都有exclusive buffer而不会造成资源死锁,我们可以在下游接收端有倾向性的选择不同channel优先读取,这样可以保证barrier尽快对齐而触发checkpoint流程,如下图所示checkpoint对齐事件比之前明显快了几倍,这对于线上job的稳定性是至关重要的。
此外,基于新流控机制还可以针对很多场景做优化,比如对于非keyby的rebalance模式,上游采用round-robin方式轮询向不同下游产出数据,这种看似rebalance的做法在实际运行过程中往往会带来负载不均衡而触发反压,因为不同record的处理开销不同,以及不同下游task的物理环境load也不同。通过backlog的概念,上游产出数据不再按照简单的round-robin,而是参考不同partition中的backlog大小,backlog越大说明库存压力越大,反映下游的处理能力不足,优先向backlog小的partition中产出数据,这种优化对于很多业务场景下带来的收益非常大。新流控机制已经贡献回社区1.5版本,参考[1]。
三. 序列化和内存拷贝优化
如开篇所列,整个shuffle过程涉及最多的就是数据序列化和内存拷贝,在op业务逻辑很轻的情况下,这部分开销占整体比例是最大的,往往也是整个runtime的瓶颈所在,下面分别介绍这两部分的优化。
3.1 Broadcast序列化优化
Broadcast模式指上游同一份数据传输给下游所有的并发task节点,这种模式使用的场景也比较多,比如hash-join中build source端的数据就是通过broadcast分发的。
Flink为每个sub partition单独创建一个serializer,每个serializer内部维护两个临时ByteBuffer,一个用来存储record序列化后的长度信息,一个用来存储序列化后的数据信息。op产出的record先序列化到两个临时ByteBuffer中,再从local buffer pool中申请flink buffer进行长度和数据信息拷贝,最后插入到sub partition队列中。这种实现主要有两个问题:
- 假设有n个sub partition对应n个并发下游,broadcast模式下同样的数据要经过n次序列化转化,再经过n次数据拷贝,当sub partition数量多时这个开销很大;
- Serializer数量和sub partition数量成正比,每个serializer内部又需要维护两个临时数组,尤其当record size比较大时,存储数据的临时数组膨胀会比较大,这部分内存overhead当sub partition数量多时不可忽视,容易产生oom。
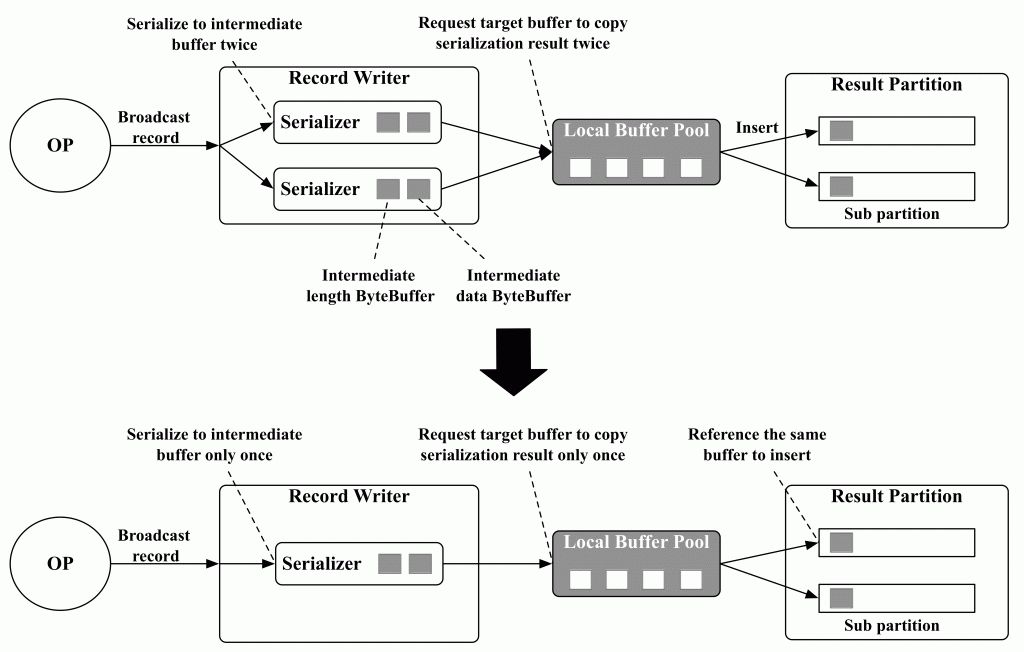
一次序列化拷贝
针对上述问题,如上图我们从两个方面进行了优化:
- 保留一个serializer服务于所有的sub partition,这样大量减少了serializer内部临时内存的overhead,serializer本身是无状态的;
- Broadcast场景下数据只序列化一次,序列化后的临时结果只拷贝到一个flink buffer中,这个buffer会被插入到所有的sub partition队列中,通过增加引用计数控制buffer的回收。
这样上游数据产出的开销降低到了原来的1/n,极大的提升了broadcast的整体性能,这部分工作正在贡献回社区。
3.2 网络内存零拷贝
如前面流控中提到的,整个shuffle流程上下游网络端flink buffer各会经历两次数据拷贝:
- 上游flink buffer插入到partition队列后,先拷贝到netty ByteBuffer中,再拷贝到socket send buffer中;
- 下游从socket read buffer先拷贝到netty ByteBuffer中,再拷贝到flink buffer中。
Netty自身ByteBuffer pool的管理导致进程direct memory的使用无法准确评估,在socket channel数量特别多的场景下,进程的maxDirectMemory配置不合理很容易出现oom造成failover,因此我们打算让netty直接使用flink buffer,屏蔽掉netty内部的ByteBuffer使用。
- Flink的buffer数据结构从原有的heap bytes改用off-heap direct memory实现,并且继承自netty内部的ByteBuffer;
- 上游netty线程从partition队列取出buffer直接写入到socket send buffer中,下游netty线程从socket read buffer直接申请local buffer pool接收数据,不再经过中间的netty buffer拷贝。
经过上述优化,进程的direct memory使用大大降低了,从之前的默认320m配置调整为80m,整体的tps和稳定性都有了提高。

四. Shuffle架构改造
上面介绍的一系列优化对于streaming和batch job都是适用的,尤其对于streaming job目前的shuffle系统优势很明显,但对于batch job的场景还有很多局限性:
- Streaming job上下游以pipelined方式并行运行,batch job往往分stage串行运行,上游运行结束后再启动下游拉数据,上游产出的数据会持久化输出到本地文件。由于上游的container进程承担了shuffle service服务,即使上游op运行结束,在数据没有完全传输到下游前,container资源依然不能回收,如果这部分资源不能用于调度下游节点,会造成资源上的浪费;
- Flink batch job只支持一种文件输出格式,即每个sub partition单独生成一个文件,当sub partition数量特别多,单个partition数据量又特别小的场景下,一是造成file handle数量不可控,二是对磁盘io的读写不友好,性能比较低。
针对上述两个问题,我们对shuffle提出了两方面改造,一是实现了external shuffle service把shuffle服务和运行op的container进程解耦,二是定义了插件化的shuffle manager interface,在保留flink现有实现的基础上,扩展了新的文件存储格式。
4.1 External Shuffle Service
External shuffle service可以运行在flink框架外的任何container容器中,比如yarn模式下的NodeManager进程中,这样每台机器部署一个shuffle service统一服务于这台服务器上所有job的数据传输,对本地磁盘的读取可以更合理高效的全局控制。
我们从flink内置的internal shuffle service中提取了网络层的相关组件,主要包括result partition manager和transport layer,封装到external shuffle service中,上面提到的流控机制以及网络内存拷贝等优化同样收益于external shuffle service。
- 上游result partition通过内置shuffle service与远程external shuffle service进行通信,把shuffle相关信息注册给result partition manager;
- 下游input gate也通过内置shuffle service与远程external shuffle service通信请求partitoin数据,result partition manager根据上游注册的shuffle信息可以正确解析文件格式,并按照credit流控模式向下游发送数据。

基于external shuffle service运行的batch job,上游结束后container资源可以立刻回收,资源利用率更加合理,external shuffle service根据磁盘类型和负载,合理控制读取充分发挥硬件性能。
4.2 插件化Shuffle Manager
为了解决flink batch job单一文件存储格式的局限性,我们定义了shuffle manager interface支持可扩展的上下游shuffle读写模式。job拓扑支持在边上设置不同的shuffle manager实现,来定义每条边的上下游之间如何shuffle数据。shuffle manager有三个功能接口:
- getResultPartitionWriter用来定义上游如何写数据,即描述输出文件的存储格式,同时result partition自己决定是否需要注册到shuffle service中,让shuffle service理解输出文件进行数据传输;
- getResultPartitionLocation用来定义上游的输出地址,job master在调度下游时会把这个信息携带给下游描述中,这样下游就可以按照这个地址请求上游的输出数据;
- getInputGateReader用来定义下游如何读取上游的数据。

基于上述interface,我们在上游新实现了一种sort-merge输出格式,即所有sub partition数据会先写到一个文件中,最终再merge成有限个文件,通过index文件索引来识别读取不同sub partition的数据。这种模式在某些场景下的表现会优于flink原有的单partition文件形式,也作为线上默认使用的模式。整体的重构工作也正在贡献回社区。
五. 展望
未来Flink shuffle工作在流上会追求更高的极致性能,如何用更少的资源跑出最好的效果,在批上充分利用现有流上积累的优势,更好的充分利用和发挥硬件的性能以及架构的统一。