选自Github
机器之心编译
今日,中科院计算所研究员徐君在微博上宣布「中科院计算所开源了 Easy Machine Learning 系统,其通过交互式图形化界面让机器学习应用开发变得简单快捷,系统集成了数据处理、模型训练、性能评估、结果复用、任务克隆、ETL 等多种功能,此外系统中还提供了丰富的应用案例,欢迎大家下载使用。」在此文章中,机器之心对开源的 Easy Machine Learning 系统进行了介绍。
GitHub 项目地址:https://github.com/ICT-BDA/EasyML
什么是 Easy ML 系统?
机器学习算法已然成为诸多大数据应用中不可或缺的核心组件。然而,由于机器学习算法很难,尤其是在分布式平台比如 Hadoop 和 Sparks 上,机器学习的全部潜能远远没有发挥出来。关键障碍不仅来自算法本身的实现,还常常来自涵盖多步操作和不同算法的实际应用过程。
我们的平台 Easy Machine Learning 提供了一个通用的数据流系统,可以降低将机器学习算法应用于实际任务的难度。在该系统中,一个学习任务被构造为一个有向非循环图(DAG/directed acyclic graph),其中每个节点表征一步操作(即机器学习算法),每一条边表征从一个节点到后一个即节点的数据流。任务可被人工定义,或根据现有任务/模板进行克隆。在把任务提交到云端之后,每个节点将根据 DAG 自动执行。图形用户界面被实现,从而可使用户以拖拉的方式创建、配置、提交和监督一项任务。该系统的优点有:
1. 降低定义和执行机器学习任务的门槛; 2. 共享和再利用算法的实现、 job DAG 以及试验结果; 3. 在一个任务中无缝整合单机算法和分布式算法。
该系统包含三个主要组件:
- 一个分布式的机器学习库,不仅能实现流行的机器学习算法,也能实现数据预处理/后处理、数据格式转变、特征生成、表现评估等算法。这些算法主要是基于 Spark 实现的。
- 一个基于 GUI 的机器学习开发环境系统,能让用户以拖放的方式创造、安装、提交、监控、共享他们的机器学习流程。机器学习库中所有的算法都可在此开发环境系统中获得并安装,它们是构建机器学习任务的主要基础。

- 执行任务的云服务。我们基于开源的 Hadoop 和 Spark 大数据平台建立了该服务。为了建立一个平台,我们在 Docker 上组织了服务器集群。从 GUI 上接受一个 DAG 任务之后,在所有的独立数据源准备好时,每个节点将会自动安排运行。对应节点的算法将会依据实现在 Linux、Spark 或者 Map-Reduce\cite 上自动安排运行。

如何参与我们的项目?
pull 整个项目,并准备好必需的环境和开发工具。按照 https://github.com/ICT-BDA/EasyML/blob/master/QuickStart.md 这里的步骤,你可以在你的计算机中创建我们的系统。
怎样使用 Easy ML 开发环境?
在运行 Easy ML 之后,你能使用我们官方账号 bdaict@hotmail.com、密码 bdaict 登录 http://localhost:18080/EMLStudio.html。为了最佳的用户体验,我们建议使用 Chrome 浏览器。

正如下图所示,用户可以根据左边菜单的选择算法和数据集创建一个机器学习任务(一个数据流 DAG)。用户可以点击选择在 Program 和 Data 菜单项下面的算法和数据集,同样也可以点击 Job 菜单项选择现存的任务,并复制和做一些必要的修改。用户同样可以在右边的菜单修改任务信息和每一个结点的参数值。任务中的结点可以对应于单机 Linux 程序或在 Spark、Hadoop Map-Reduce 上运行的分布式程序。
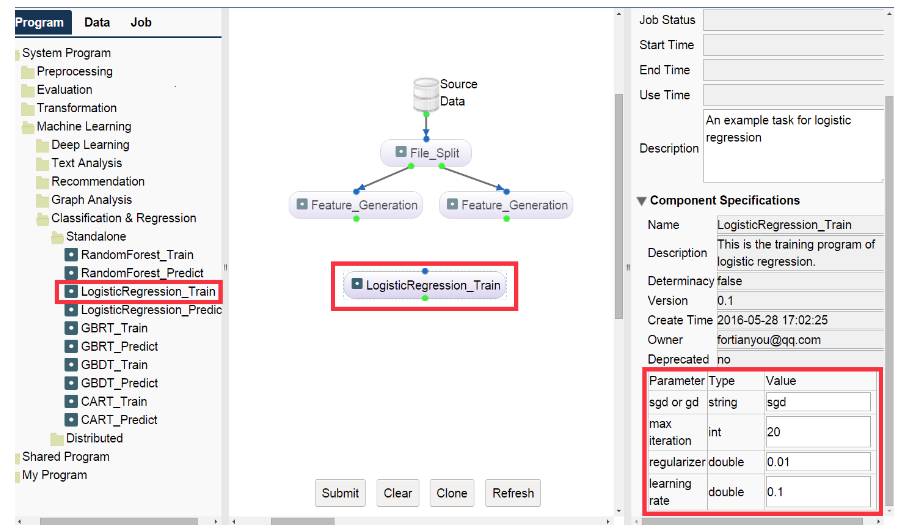
在点击了 submit 按钮后,该任务被提交给云端运行。每个节点的状态由不同的颜色表示,如下图所示:

用户可以右键点击完成的执行节点上 green output port 按钮来预览输出数据。也可以从每个完成的执行节点的右键菜单中检查 stdout 和 stderr 日志。用户可以通过右键单击相应的输出端口来检查节点的输出。执行时打印的标准输出和标准错误信息可通过右键单击相应节点并选择菜单中 Show STDOUT/Show STDERR 的方式进行检查。

在结束后(无论成功与否),任务可以被继续修改,再次提交并运行,如下图所示。我们的系统指挥安排受影响的节点来运行。不受影响的节点输出直接重用,以节省运行时间和系统资源。
用户可以上传自己的算法包和数据集来建立自己的任务,并分享给他人。通过点击 upload program 按钮,弹出窗口允许用户指定算法包的必要信息,包括名称、类别、描述和命令行特征字符串等,如下图所示。其中最重要的在于使用预定格式编写特征字符串。它定义了节点的输入端口、输出端口和参数设置。我们在面板中开发了一个工具来帮助用户编写命令行字符串模式。通过点击 upload data 按钮,用户可以用与上传算法包相似的方式上传数据集。

致谢
以下人员对 EasyML 项目的开发做出了贡献。
- 徐君,中国科学院计算技术研究所. 主页:http://www.bigdatalab.ac.cn/~junxu
- Xiaohui Yan,华为技术公司
- Xinjie Chen,中国科学院计算技术研究所
- Zhaohui Li,中国科学院计算技术研究所
- Tianyou Guo,中国科学院计算技术研究所
- Jianpeng Hou,中国科学院计算技术研究所
- Ping Li,中国科学院计算技术研究所
- 程学旗,中国科学院计算技术研究所. 主页:http://www.bigdatalab.ac.cn/~cxq/
论文:使用数据流简化机器学习流程(Ease the Process of Machine Learning with Dataflow)

论文地址:http://203.187.160.132:9011/www.bigdatalab.ac.cn/c3pr90ntc0td/~junxu/publications/CIKM2016_BDADemo.pdf
机器学习算法已经变成许多大数据应用的关键部分。然而机器学习的全部潜力还远远没有被释放出来,因为通常使用机器学习算法是很困难的,尤其是在 Hadoop 和 Spark 这样的分布式平台上。最主要的障碍不仅仅来源于实现算法本身,也是因为将它们应用到实际应用中通常需要很多步骤和不同的算法。在本演示中,我们提出一种通用的基于数据流的系统(general-purpose dataflow-based system),可用于简化机器学习算法的实际应用。在这个系统里,学习任务被形式化为一个有向非循环图(DAG/directed acyclic graph),其中每一个节点(node)代表一个运算(比如机器学习算法),并且每个边(edge)代表数据从一个节点流向其后继节点。我们实现了一个图形用户界面,可以让用户通过拖放的方法去创建、配置、提交和监控一个任务。这个系统的优点包括:1)降低定义和执行机器学习任务的难度;2)共享和复用算法、任务数据流 DAG 和(中间)实验结果;3)把单机使用的算法和分布式算法集成到一个任务中。这个系统是一个机器学习服务,可以通过网络进行访问。

本文为机器之心编译,转载请联系本公众号获得授权。