作者:于乐,腾讯 CSIG 工程师
一、 方案描述
1.1 概述
在线教育是一种利用大数据、人工智能等新型互联网技术与传统教育行业相结合的新型教育方式。发展在线教育可以更好的构建网络化、数字化、个性化、终生化的教育体系,有利于构建“人人皆学、处处能学、实时可学”的学习型社会。
本文针对某知名在线教育平台在腾讯云流计算 Oceanus 的业务案例,介绍了其中可能存在的一些性能问题,并针对这种问题进行了参数调优相关的介绍。

1.2 方案架构
某知名在线教育平台在流计算 Oceanus 上主要有两个业务应用场景,其一:单表同步,使用 MySQL CDC 将 MySQL 数据取出存入 Elasticsearch;其二:双流 JOIN,两条 MySQL CDC 流 JOIN 后存入 Elasticsearch。本文主要针对这两种场景进行了一些实践,并指出可能存在的特殊场景以及参数调优思路。

涉及产品列表:
- 腾讯云流计算 Oceanus
- 腾讯云 MySQL 数据库
- 腾讯云 Elasticsearch
二、前置准备
2.1 创建私有网络 VPC
私有网络(VPC)是一块您在腾讯云上自定义的逻辑隔离网络空间,在构建 Oceanus、CKafka、COS、ClickHouse 集群等服务时选择的网络建议选择同一个 VPC,网络才能互通,否则需要使用对等连接、NAT 网关、VPN 等方式打通网络。私有网络 VPC 创建步骤请参考 帮助文档 。
2.2 创建流计算 Oceanus 集群
流计算 Oceanus 是大数据产品生态体系的实时化分析利器,是基于 Apache Flink 构建的具备一站开发、无缝连接、亚秒延时、低廉成本、安全稳定等特点的企业级实时大数据分析平台。流计算 Oceanus 以实现企业数据价值最大化为目标,加速企业实时化数字化的建设进程。
进入 Oceanus 控制台,点击左侧【计算资源】,单击左上角【新建集群】页面创建集群,选择地域、可用区、VPC、日志、存储,设置初始密码等,VPC 及子网使用刚刚创建好的网络。创建完后 Oceanus 的集群如下:
2.3 创建云数据库 MySQL
云数据库 MySQL(TencentDB for MySQL)是腾讯云基于开源数据库 MySQL 专业打造的高性能分布式数据存储服务,让用户能够在云中更轻松地设置、操作和扩展关系数据库。
- 登录 云数据库 TencentDB 控制台,单击【新建】,新建 MySQL 服务。注意网络选择需为上文创建的网络。
- 创建完 MySQL 服务后,点击进入 MySQL 实例,单击上方【数据库管理】>【参数设置】,确保
binlog_format = ROW以及binlog_row_image = FULL。

- 检查完参数后,单击右上角【登录】进入数据库,创建数据库和表用户接收数据。
2.4 创建 Elasticsearch 实例
腾讯云 Elasticsearch Service(ES)是基于开源引擎打造的云端全托管 ELK 服务,集成 X-Pack 特性、独有高性能自研内核、QQ 分词、集群巡检、一键升级等优势能力,引入极致性价比的腾讯自研星星海服务器。助您轻松管理和运维集群,高效构建日志分析、运维监控、信息检索、数据分析等业务。
进入 Elasticsearch Service 控制台,单击左侧【Elasticsearch 集群】,点击左上角【新建】,注意选择之前创建好的私有网络和子网,并设置账户和密码,具体操作请参考 帮助文档 。
三、场景一:单表同步
本场景使用 MySQL CDC 将数据从云数据库 MySQL 中取出后存入 ES,中间并无复杂的业务逻辑的计算。
3.1 Source 端参数配置
-- Source 端配置,从云数据库 MySQL 读取数据 'connector' = 'mysql-cdc', -- 固定值 'mysql-cdc' 'hostname' = 'xx.xx.xx.xx', -- 数据库的 IP 'port' = '3306', -- 数据库的访问端口 'username' = 'root', -- 数据库访问的用户名(需要提供 SHOW DATABASES、REPLICATION SLAVE、REPLICATION CLIENT、SELECT 和 RELOAD 权限) 'password' = 'xxxxxxxxxxxxxx', -- 数据库访问的密码 'database-name' = 'xxxx', -- 需要同步的数据库 'table-name' = 'xxxx' -- 需要同步的数据表名Source 端重要参数或可选参数说明
scan.incremental.snapshot.enabled:增量快照。开启此参数必须保证 MySQL 表有主键,开启此配置后可以开启多并行度读取 MySQL 数据,相对应的还需调大【作业参数】里面的【算子默认并行度】,并配置server-id为一个范围,例如 5100-5110,则可以开启 10 个并行度同时读取 MySQL 表的数据。此参数默认开启。server-id:server-id在任务启动时会注册到 MySQL 服务端,相同 MySQL 实例内不允许 server-id 重复,因此不同任务里配置的 CREATE TABLE 不管表是相同还是不同,都必须要有不同的 server-id,server-id 建议配置一个范围,例如 5100-5110,这个范围可以支持任务扩展到 10 个并发。server-time-zone:例如Asia/Shanghai,该参数控制了 MySQL 中的 TIMESTAMP 类型如何转成 STRING 类型。debezium.database.history.store.only.monitored.tables.ddl:如果 MySQL 实例表非常多并且经常发生 schema 变更,那么增加这个配置项可以减少状态大小,注意正则模糊匹配表的场景不要使用这个配置项。
特殊场景优化
- 如果MySQL CDC 同步的表数量较大(千万或亿级),建议: (1) 增加全量同步时的并发度,亿级推荐 10 以上。 (2) 需要设置 scan.incremental.snapshot.chunk.size 到更大的值,例如 1 亿数据量推荐设置为 30000。
- 如果使用正则模糊匹配多表时,建议增加 JobManager 的 CU 数到 2CU。
3.2 Sink 端参数配置
-- Sink 端配置,将数据写入 ES 'connector' = 'elasticsearch-7', -- 输出到 Elasticsearch 7 'username' = 'elastic', -- 选填 用户名 'password' = 'xxxxxxxx', -- 选填 密码 'hosts' = 'http://xx.xx.xx.xx:9200', -- Elasticsearch 的连接地址 'index' = 'xxxxxxxx', -- Elasticsearch 的 Index 名 'document-id.key-delimiter' = '$', -- 可选参数, 复合主键的连接字符 (默认是 _ 符号, 例如 key1_key2_key3) 'failure-handler' = 'ignore', -- 可选的错误处理。可选择 'fail' (抛出异常)、'ignore'(忽略任何错误)、'retry-rejected'(重试) 'sink.flush-on-checkpoint' = 'true', -- 可选参数, 快照时不允许批量写入(flush), 默认为 true 'sink.bulk-flush.max-actions' = '42', -- 可选参数, 每批次最多的条数 'sink.bulk-flush.max-size' = '42 mb', -- 可选参数, 每批次的累计最大大小 (只支持 mb) 'sink.bulk-flush.interval' = '1000', -- 可选参数, 批量写入的间隔 (ms) 'connection.max-retry-timeout' = '300', -- 每次请求的最大超时时间 (ms) 'format' = 'json' -- 输出数据格式, 目前只支持 'json'Sink 端重要参数或可选参数说明
sink.flush-on-checkpoint:Flink 进行快照时,是否等待现有记录完全写入 Elasticsearch 。如果设置为false,则可能造成恢复时部分数据丢失或者重复等异常情况,但快照速度会提升。默认为true。sink.bulk-flush.max-actions:批量写入的最大条数。设置为 0 则禁用批量功能。默认为1000。sink.bulk-flush.max-size:批量写入缓存的最大容量,必须以 mb 为单位。设置为 0 则禁用批量功能。默认为2mb。sink.bulk-flush.interval:批量写入的刷新周期。设置为 0 则禁用批量功能。默认为1s。
性能测试 Source 端数据读取量大导致 Sink 端写入繁忙,从而引起反压问题导致作业不断重启,建议:适当调整sink.bulk-flush.max-actions、sink.bulk-flush.max-size和sink.bulk-flush.interval这三个参数的值。默认情况下:
sink.bulk-flush.max-actions = 1000
sink.bulk-flush.max-size = 2mb
sink.bulk-flush.interval = 1000ms
针对 MySQL CDC 单表写入到 ES 这种场景,我们对sink.bulk-flush.interval参数做了简单的性能测试,包括吞吐量和写入 ES 延时。用户可以参考这些数据,根据自己实际业务情况做相应的调参。
测试条件:
- Elasticsearch:16核64G, 3个20GB SSD云硬盘 x 1
- MySQL 版本:MySQL 5.7
- 数据流入量级:每秒 40000 条
- 作业中的参数
sink.bulk-flush.max-actions和sink.bulk-flush.max-size保持默认值
测试结果:
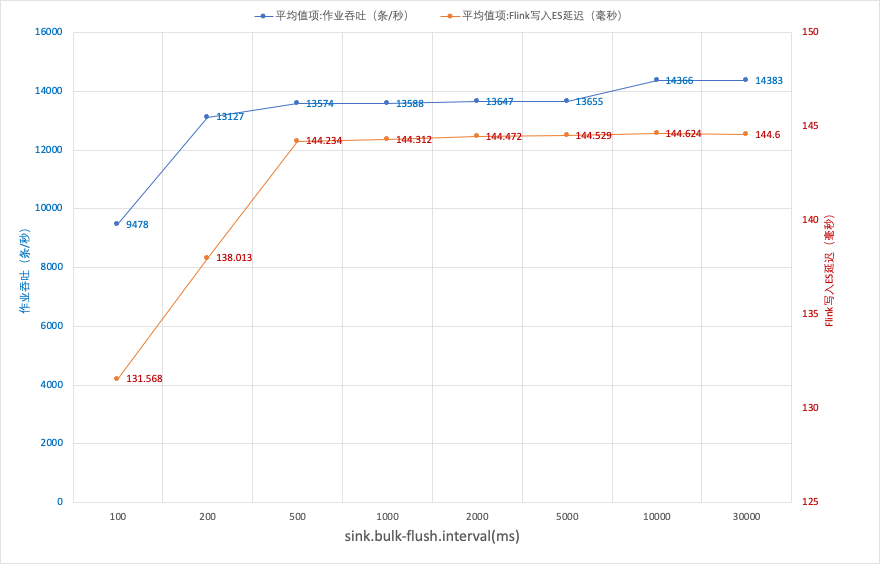
并行度为 1:
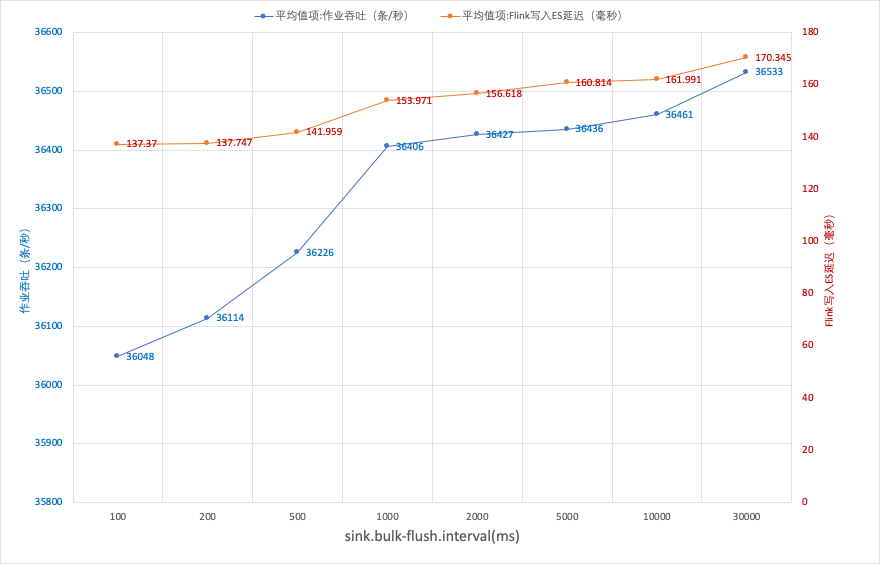
并行度为 4:
结论:
sink.bulk-flush.max-actions的默认值是1000条,sink.bulk-flush.max-size的默认值是2mb,sink.bulk-flush.interval默认1s,这三个满足满足任意一条即触发 ES 写操作。- 如果作业流量比较大,
sink.bulk-flush.max-actions或者sink.bulk-flush.max-size会优先触发,此时调大sink.bulk-flush.interval的值,对写入 ES 的吞吐和延迟几乎没有影响。 - 如果作业流量比较小,
sink.bulk-flush.interval会优先触发,此时sink.bulk-flush.interval的大小会影响写入 ES 的延迟。 - ES 的
refresh interval参数影响数据在 ES 集群中可以查询的时延,比如 Kibana 可以查看到数据的时延在0~sink.bulk-flush.interval(如果bulk-flush优先触发)+ ES refresh interval区间。 sink.bulk-flush.interval不建议小于500ms。- 单并行度的时候,通过调节参数,对 ES 的吞吐量不再有影响的时候,增大作业的并行度后,ES 的吞吐有明显的提升。
建议:
sink.bulk-flush.max-actions和sink.bulk-flush.max-size通常保持默认值即可,这两个条件满足其一,数据就会提交写入请求。sink.bulk-flush.interval:定时提交数据的间隔,设置太小,ES 的吞吐量会变小,建议改值不小于500ms。sink.bulk-flush.max-actions = 1该设置表示每来一条数据就立即写入 ES,这会导致整个作业的吞吐降低,以本次的测试场景,吞吐最高只能到达 400条/秒,同时写入 ES 的平均延迟会增大到 1.5s,不建议该值设置太小。- 当作业中的参数对吞吐的影响极小的时候,可以通过增大作业的并行度来提高写入 ES 的吞吐。
- 当并行度提高到一定的程度的时候,ES 的吞吐不再有变,此时可以检查一下 ES 的的写入性能。
四、场景二:双流 JOIN
这里总结一下双流 JOIN 常见的问题以及优化点。
SET 语句
- (一定要提前设置,避免状态不兼容导致无法恢复)如果存在多流 JOIN 或 GROUP BY,需要设置 SQL 状态保留时间(TTL),例如 :
SET execution.min-idle-state-retention = '5 h'SET execution.max-idle-state-retention = '6 h' - 如果快照时间较久(例如上述 JOIN 场景),需要调大快照过期时间到至少 30 min,例如:
SET CHECKPOINT_TIMEOUT = '30 min' - 建议启用 Mini-Batch 功能以获取更好的性能(可能会导致较大延迟,请谨慎设置):
SET table.exec.mini-batch.enabled = trueSET table.exec.mini-batch.size = 5000SET table.exec.mini-batch.allow-latency = 200 ms
高级参数
- 如果作业快照较大,建议延长快照周期为至少 30 min
- 设置增量快照:
state.backend.incremental: true - 建议调大作业重启阈值:
restart-strategy.fixed-delay.attempts: 10000 - 建议调大快照失败的容忍次数:
execution.checkpointing.tolerable-failed-checkpoints: 5 - 如果事件面板经常出现 TaskManager 异常退出事件,且错误信息包含 OOMKilled,则可以尝试设置如下参数,且提高 TaskManager 的规格为 2CU 或提升并行度:
taskmanager.memory.jvm-overhead.fraction: 0.3。
总结
本文分析了某知名在线教育平台在流计算 Oceanus 上的两种业务场景:MySQL 单表同步到 Elasticsearch;两条 MySQL CDC 流 Regular JOIN。此外,本文还对两种场景的一些重要参数或可选参数进行了讲解,并对可能存在的特殊场景提供了参数调优思路。更多 Oceanus 最佳实践以及入门指引参见我们的 专栏文章,最后欢迎大家猛戳 一元购 试用 Oceanus,机不可失时不再来:)
扫码加入 流计算 Oceanus 产品交流群👇

流计算 Oceanus 限量秒杀专享活动火爆进行中↓↓

扫码关注「腾讯云大数据」,了解腾讯云流计算 Oceanus 更多信息~
腾讯云大数据

长按二维码 关注我们