运维是企业业务系统从规划、设计、实施、交付到运维的最后一个步骤,也是重要的步骤。运维从横向、纵向分可以分为多个维度和层次,本文试图抛开这纷繁复杂的概念,讲述一个传统的企业级运维人员转型到云运维人员,尤其是软件定义存储的运维之间经历的沟沟坎坎。
在传统企业中,业务运维工程师(Operations) 主要负责监控、维护并确保整个业务系统的可靠性,同时提出对系统架构的优化要求、提升部署效率、优化资源利用率并提高整体的ROI。
随着云计算、大数据以及新兴的区块链等技术体系的迅猛发展,数据中心的扩容建设进入高峰期,云数据中心运维需求应运而生。传统的运维人员,以往接触的更多是硬件,如服务器、设备和风火水电;但是在云数据中心时代,运维人员已经从面向物理设备,转变为面向虚拟化、云的管理方式。
因此,云数据中心的运维对于传统的运维人员提出了新的能力要求——不仅要熟悉传统硬件设备,同时要掌握虚拟化、云系统的部署、监控和管理等运维能力。
本文选取云数据中心的其中一点,即软件定义存储(SDS)的运维为例,试述整个演进历程。
SDS即软件定义存储,最重要的是存储虚拟化,就是将存储硬件中的典型的存储控制器功能抽出来放到软件上来实现,这些功能包括卷管理、快照等。俗话说软件看开源,SDS看Ceph。Ceph是目前影响力最大的开源软件定义存储解决方案,其应用范围涵盖块存储、文件和对象存储,广泛被业界公司所采用。
Ceph运维工程师对于比传统运维人员既有相似点也有不同点,要做到能文能武,文能提笔写Ceph运维手册、预案手册等;武能挥手部署Ceph、进行预案演练、故障处理、集群扩容等。来保证Ceph整个集群的高可用性,确保数据不丢失,同时也进行一些常规故障的预案演练,保证出现故障后能够有序的进行故障恢复。
一般企业使用Ceph会经历几个关卡:硬件选型-->部署调优-->性能测试-->架构灾备设计-->部分业务上线测试-->运行维护(故障处理、预案演练等)。
首先在关卡一的时候就会遇到很多问题,由于Ceph初学者对Ceph各组件没有深入了解,导致选型产生困难,因为初学者不了解Ceph各组件对于内存、CPU、网络等等这些硬件的消耗是多少。所以下面我讲述一个真实的A公司传统企业运维人员转型运维Ceph SDS的历程。
本文主要说下硬件选型关卡。许多Ceph新手在测试环节以及预生产的时候会对硬件选型产生困扰,A公司运维小哥也遇到了硬件选型问题,根据Ceph官网推荐我简单概述为以下几点:CPU、内存、数据存储、网络、硬盘。
关卡一:硬件选型关
难度:四颗星
Ceph是一个开源分布式统一存储,同时支持块、对象、文件三种存储。可以根据自己的使用场景需求还制定和选择不同的硬件。Ceph的硬件选型需要根据你的环境和存储需求做出选型计划。硬件的类型、网络和集群设计,是你在Ceph集群设计前期需要考虑的一些关键因素。Ceph选型没有黄金法则,因为它依赖各种因素,比如预算、性能和容量、或者两种的结合、容错性、以及使用场景。下面简单分析下三种常见场景搭配。
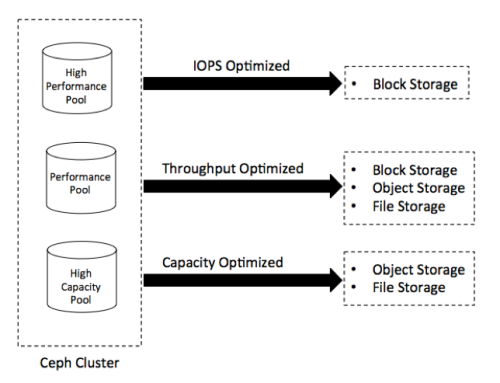
图1:三种存储场景类型
- 高性能场景:这种配置的类型亮点在于它在低TCO(ownership的总消耗)下每秒拥有最高的IOPS。典型的做法是使用包含了更快的SSD硬盘、PCIe SSD、NVMe做数据存储的高性能节点。通常用于块存储,但是也可以用在高IOPS的工作负载上。
- 通用场景:亮点在于高吞吐量和每吞吐量的低功耗。通用的做法是使用SSD和PCIe SSD做OSD日志盘,以及一个高带宽、物理隔离的双重网络。这种方法常用于块存储,如果你的应用场景需要高性能的对象存储和文件存储,也可以考虑使用。
- 大容量场景:亮点在于数据中心每TB存储的低成本,以及机架单元物理空间的低成本。也被称为经济存储、廉价存储、存档/长期存储。通用的做法是使用插满机械硬盘的密集服务器,一般是36到72,每个服务器4到6T的物理硬盘空间。通常用于低功耗、大存储容量的对象存储和文件存储。一个好的备选方案,是采用纠删码来最大化存储容量。
企业可以根据预算、性能/容量需求、使用场景自由地选择任意硬件。在存储集群和底层基础设施上,有完全控制权,这也避免了被厂商锁定的风险。另外,Ceph的一个优势是它支持异构硬件。当创建Ceph集群时,你可以混合硬件品牌。比如你可以混合使用来自不同厂家的硬件,比如HP、DELL等,混用现有的硬件可以大大降低成本。下面说一些常用的关于Ceph硬件选型的方法。
CPU
Ceph metadata server会动态的重新分配负载,它是CPU敏感性的,所以Metadata Server应该有比较好的处理器性能 (比如四核CPU).
Ceph OSD运行RADOS服务,需要通过CRUSH来计算数据的存放位置,replicate数据,以及维护Cluster Map的拷贝,因此OSD也需要合适的处理性能
Ceph Monitors 简单的维护了Cluster Map的主干信息所以这个是CPU不敏感的.
RAM内存
Metadata servers 以及Monitors 必须能够快速的提供数据,因此必须有充足的内存(至少每个进程1GB). OSD在日常操作时不需要过多的内存 (如每进程500MB);但是在执行恢复操作时,就需要大量的内存(如每进程每TB数据需要约1GB内存). Generally, 内存越多越好.
DataStorage数据存储
规划数据存储时要考虑成本和性能的权衡。同时OS操作,同时多个后台程序对单个驱动器进行读写 操作会显着降低性能。也有文件系统的限制考虑:BTRFS对于生产环境来说不是很稳定,但有能力记录journal和并行的写入数据,相对而言XFS和EXT4会好一点。
Network
建议每台机器最少两个千兆网卡,现在大多数机械硬盘都能达到大概 100MB/s 的吞吐量,网卡应该能处理所有 OSD 硬盘总吞吐量,所以推荐最少两个千兆网卡,分别用于公网(前端)和集群网络(后端)。集群网络(最好别连接到外网)用于处理由数据复制产生的额外负载,而且可防止拒绝服务攻击,拒绝服务攻击会干扰数据归置组,使之在 OSD 数据复制时不能回到 active + clean 状态。
一般生产环境会建议考虑部署万兆网卡。下面可以算一笔账,假设通过 1Gbps 网络复制 1TB 数据需要耗时 3 小时,而 3TB (典型配置)就需要 9 小时,相比之下,如果使用 10Gbps 复制时间可分别缩减到 20 分钟和 1 小时。所以一般使用Ceph都会上万兆网卡。
硬盘
Ceph集群的性能很大程度上取决于存储介质的有效选择。你应该在选择存储介质之前了解到集群的工作负载和性能需求。Ceph使用存储介质有两种方法:OSD日志盘和OSD数据盘。Ceph的每一次写操作分两步处理。当一个OSD接受请求写一个object,它首先会把object写到acting set中的OSD对应的日志盘,然后发送一个写确认给客户端。很快,日志数据会同步到数据盘。值得了解的是,在写性能上,副本也是一个重要因素。副本因素通常要在可靠性、性能和TCO之间平衡。通过这种方式,所有的集群性能围绕着OSD日志和数据盘了。
CephOSD 日志盘
如果你的工作环境是通用场景的需求,那么建议你使用SSD做日志盘。使用SSD,可以减少访问时间,降低写延迟,大幅提升吞吐量。使用SSD做日志盘,可以对每个物理SSD创建多个逻辑分区,每个SSD逻辑分区(日志),映射到一个OSD数据盘。通常10到20GB日志大小足以满足大多数场景。然而,如果你有一个更大的SSD,这时,不要忘记为OSD增加filestore的最大和最小的同步时间间隔。
根据上述,A公司运维小哥参考了社区官方建议(http://docs.ceph.com/docs/master/start/hardware-recommendations/)以及专业公司咨询(Intel、XSKY等)的方法综合考虑,最终他确定了一套适合自己当前环境场景的硬件来测试以及上线应用。下面贴出来A公司运维小哥根据自己场景需求选择的硬件配置。
设备 | 具体配置 | 数量 | 场景 |
|---|---|---|---|
CPU | Intel Xeon E5-2650 v3 | 2 | 热数据应用/虚拟化场景 |
内存 | 64GB DDR4 | 4 | |
OS盘 | 2.5英寸Intel S3500系列 SSD 240GB SSD | 2 | |
SSD盘 | Intel S3700 400G | 12 | |
万兆网卡 | intel 双口万兆(含多模模块) | 2 |
- 2.5英寸Intel S3500系列 SSD 240GB SSD
2SSD盘Intel S3700 400G12万兆网卡intel 双口万兆(含多模模块)2
图2:热数据应用以及虚拟化场景
本文是作者个人工作经验的总结,供Ceph初学者参考,请读者见仁见智。欲知后事,且听下文《从传统运维到云运维演进历程之软件定义存储(二)》,主要讲述了A公司运维小哥在硬件选型完毕之后开始部署Ceph遇到的一些问题以及解决办法。