背景
近些年,视频直播应用蓬勃发展,带宽也是日渐新高,腾讯云旗下的视频云直播为斗鱼、快手、虎牙、龙珠、CNTV广大的企业客户提供了很大的支持,在行业内起到了引领的作用。
视频云直播中,常见的流程是,客户侧应用推流到视频云上行接入服务,另一种情形是客户侧提供直播流源,视频云进行回源拉流,并最终通过CDN分发

而这里针对第二种情形,介绍直播源站系统(又称三级源)的功能和设计,三级源的核心功能即从客户源站获取直播流,并最终交由CDN分发出去。
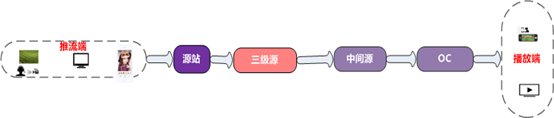
架构介绍
我们主要完成了直播常见协议,rtmp、flv、hls的回源和转封装,同时还针对特定客户做了私有协议的分发。也可以支持多种协议的推流和转推。
系统内部架构如下,source_server负责从上一层获取数据,并给下一层提供拉取的功能,master负责调度工作。另外还有配置服务,预热服务等。
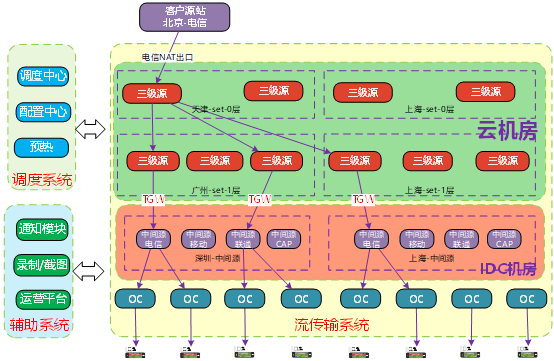
那么设计一个这样的三级源需要注意哪些呢,首先客户关心的最重要的是服务的稳定性,其次对于直播来说播放质量也很重要,其次功能和价格也是要考虑的。那么对应到我们的设计标准就是, 可用性,质量,功能和成本
可用性
首先,在调度策略上,具备负载均衡和过载保护的基本功能。通过一致性hash,使负载更均匀,其次通过过载保护,防止局部过热。
其次是容灾。回源链路上,每一层都需要有容灾。首先是源站的容灾,我们采取主备流的方式保证链路的可靠性,对于有多个源站的客户,尤其重要。
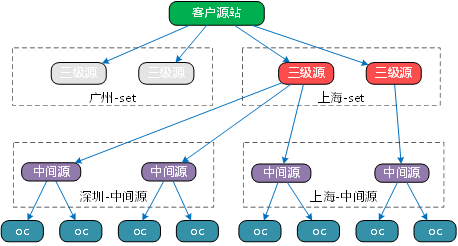
采用备用回源的重要性在于,源站可能是没有cache或者cache不足以抵消切换带来的损失 , 另一方面还要保障不重复,因为在切换时会获取到cache,所以当更新tcp回源链接时,要保存上一次的session,并将新获取的数据和上一次作比较,来判断是丢弃还是存下来。这一机制保障了尽可能减少每一层向下一层提供脏数据的可能性。
同理,其它每一层也有容灾的策略,如0层自身故障,1层会切换到其它0层机器进行回源。
除了针对单点的故障容灾,我们采取异地部署来防止单个区域的故障.
当容灾失效时,会采用柔性策略。我们对不同用户不同频道做了分级,当因某种原因出现系统资源瓶颈时,采取降级服务。
我们对不同的用户划分到不同的集群,同时在集群内甚至单个机器上对赛事房间做了重点保护。
流的质量
除了保证服务高可用外,流本身的质量也至关重要。由于回源客户原站用的是外网,我们通过双层结构来解决最后一公里问题,让回源机器更接近源站的部署,减少外网传输带来的影响。
容错性方面,对于flv转hls的情形,在分布式系统里面,重要的问题是,不同机器切出来的ts分片的一致性,以及ts切片与m3u8索引的一致性。我们根据时间戳统一了切片规则,而对于时间戳跳变的情形需要根据跳变的程度来做相应的兼容处理,这样保证了不同的机器切出来的ts也是一致的。另一方面通过1层到0层的收敛,来尽可能确保同一时间只有一台机器在切片。第一个是强一致的,第二个是弱一致的,若出现因内网故障导致1层在一定时间段回源到0层备用机器,可能会导致最终不同CDN边缘节点拿到的m3u8有延迟(解决办法,播放器播放时采用长连接获取ts或缓存cdn ip,不切换cdn边缘节点;另一个是切片发送ts序列时延迟一个,用延迟抵消404的可能)
低延迟
低延迟有两个含义,一个是播放端和推流断的绝对时间延迟,一个是播放端从开始拉流到看到第一帧画面的延迟。
优化主要体现在,通过减少外网传输时跨网跨地域的场景降低网络延迟。
设置gop缓存,保障每一层首次传输时从关键帧开始下发,目的是保障首个用户的快速启动。
优化内核参数,加快传输速度。
成本
从技术角度,直播业务带来的成本无非是两个,机器和带宽。
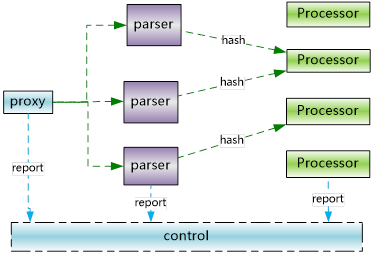
在机器成本上我们改进了线程结构,采取了proxy->parser->processor的结构。三者之间传输的是每一次拉流请求的socket和上下文信息,传输的方式是无锁队列。同一个频道会落到同一个processor上,让cpu使用更均衡。
proxy负责接收新的拉流请求,然后随机投递到parser的任务队列。parser负责读取请求数据并解析,根据streamid一致性hash到对应的processor。processor负责回源拉取数据并写socket发送给client。这里值得注意的是,直播这种业务有很大量的数据传输,所以尽量减少内存的拷贝尤为重要,我们让不同线程之间传递socket和上下文,而不是具体的消息内容。每一个线程内部通过微线程实现异步化。优化后我们的瓶颈是带宽了
在带宽成本上,我们要对机房部署进行合理的选择,比如是不是可以放在更便宜的OC或EC机房。另外,通过回源收敛降低外网回源的带宽。这里客户的成本也是我们需要考虑的,我们采取的结构很好的收敛了回源路径,对于强烈要求只回源一路的客户,我们也可以满足其要求。