云原生数据库TDSQL-C作为腾讯云架构平台部核心数据库产品之一,致力于为云上ToB用户和公司自研业务提供集高性能、低成本、大存储、低延迟、秒级扩缩容、极速回档、Serverless化七大特性于一体的企业级数据库服务。本文将给大家分享《TDSQL-C (原CynosDB)容灾的实践和探索》,主要内容有以下三个方面:
1 云原生数据库和传统数据库的架构对比
2 MySQL数据库的容灾部署模型
3 TDSQL-C 异地容灾系统的实践
云原生数据库和传统数据库的架构对比
传统的MySQL数据库
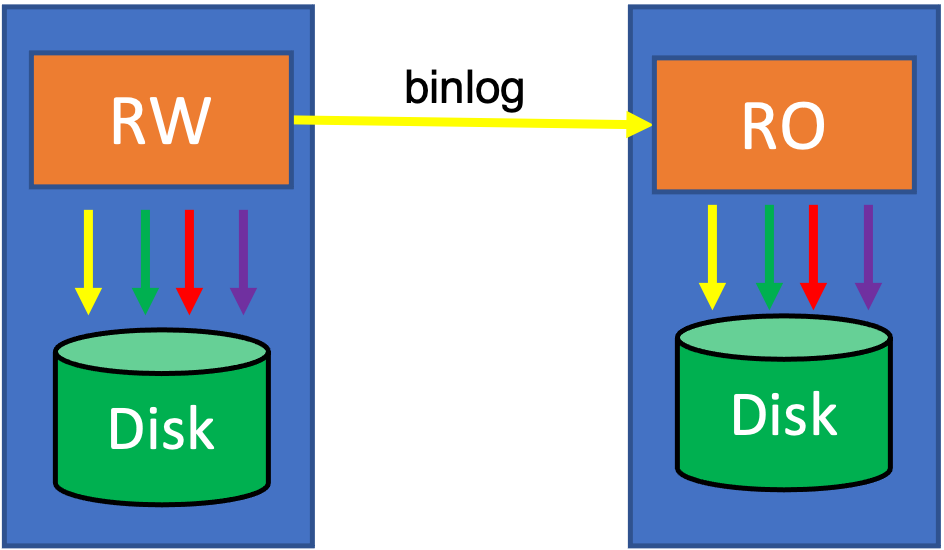
(传统的MySQL数据库架构)
传统的MySQL数据库架构概述:通过Binlog复制来保证数据的冗余,数据副本之间通过异步复制、半同步复制或强同步复制来保证数据的可靠性。传统MySQL的数据会存储在本地,一般包括数据文件、Redo日志文件、Binlog文件以及数据字典文件等,在通过Binlog同步到备库之后,备库同样需要把数据完全在本地再生成一份,所以传统MySQL数据库是一个非常重IO的服务。
基于Binlog复制和重IO这两个特点,导致传统MySQL产生许多已知的问题:
- 主从延迟不可控:Binlog同步到备机之后要回放大事务,主动延迟可达小时级别,甚至极端的情况下会到天级别。在这种主从延迟比较大的情况下,如果RW发生故障这个时候就要做取舍,是为了保证数据一致性等Relaylog回放完成,还是要保证可用性立即切换。即使Relaylog正常回放完成,也可能存在数据不一致的问题。
- 恢复耗时不可控:如果在运行过程中Crash了,在拉起的时候,由于需要回放Redo日志,Crash Recovery耗时也是不可控的。
- 扩展性较差:每次要扩展一个从节点的时候,都会需要把RW上面的数据通过备份导入到一个新节点上,然后再去追Binlog来扩展新节点,在数据量比较大的情况下,这个扩容耗时也是不可控的。
云原生数据库TDSQL-C
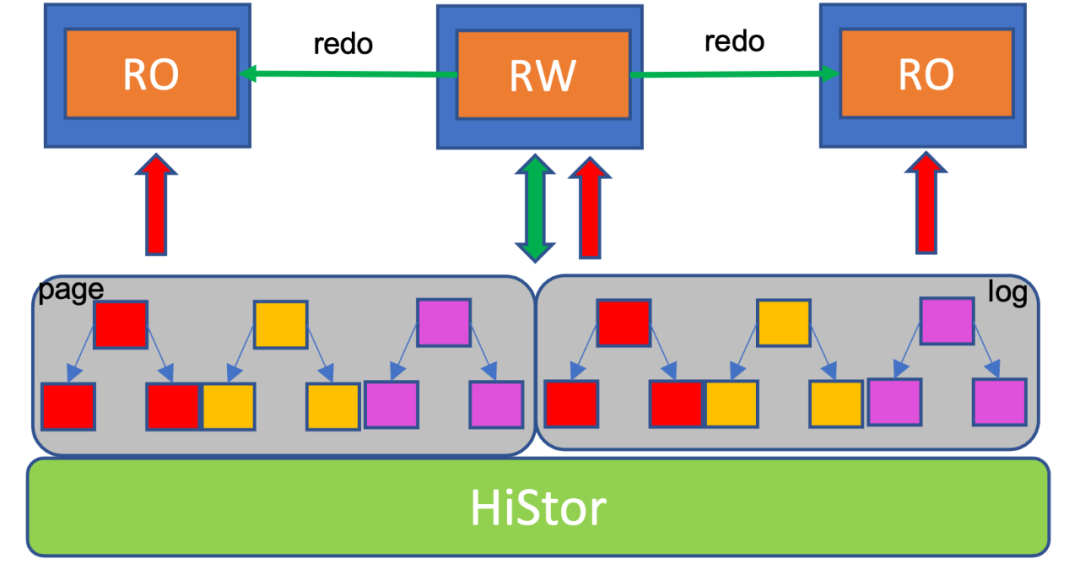
(云原生数据库TDSQL-C)
云原生数据库TDSQL-C架构概述:在设计的时候以日志即数据库为理念,通过Redo日志还原出所有的数据;存储计算分离,把计算层相关的无效IO进行下沉、卸载,把日志下沉到存储层,实现计算层完全无状态化;主从之间抛弃了原来传统数据库的Binlog复制,采用更加高效的物理复制。
- TDSQL-C具有极致弹性能力。基于计算层无状态,可快速添加RO节点、只读节点。RO节点和RW节点共用存储池的一份数据,因此只需要找一个新的RS机器拉起新的计算节点。这个过程相比于传统数据库还要进行备份导出的形式,耗时大大降低。用运营数据来看,TDSQL-C添加一个RO节点可在20秒内完成。
- TDSQL-C的Serverless形态,实现了在完全不使用、没有流量的情况下,将计算节点暂停,减少计算层费用;在需要第一次连接的情况下,立即拉起,恢复时间小于2秒。
- 基于Redo复制,TDSQL-C避免了大事务产生的主从延迟问题。目前TDSQL-C主从延迟可以稳定在20ms以内,对于主从延迟有一定要求的业务,是一个很大的优势,甚至可以做到全局一致性。
- TDSQL-C的秒级Recovery,极速备份回档能力。传统的数据库是以Binlog做备份回档,TDSQL-C只需在存储层做快照就可以,快照备份秒级完成;回档是多个分片并行导入,可达GB级以上。
以上是云原生数据库TDSQL-C和传统MySQL数据库架构上的区别。
MySQL数据库的容灾部署模型
MySQL数据库常见的容灾部署模型,有以下两种:
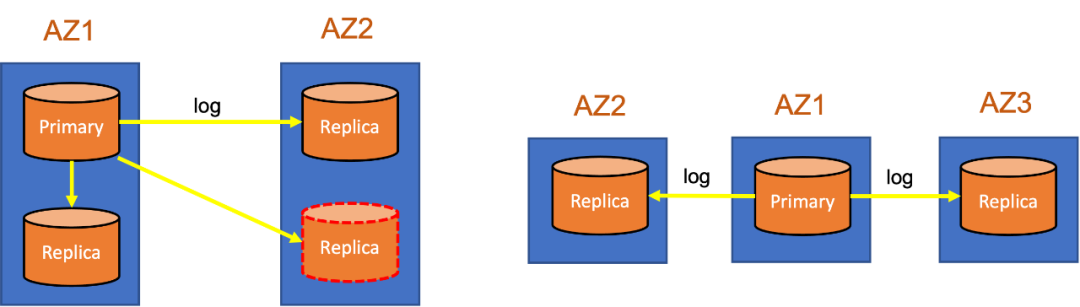
跨AZ部署(如上图):
- 一种是两AZ有三副本,其中AZ1有两副本,AZ2有一个副本;若是四个副本,那么AZ2会再多一个副本,以此保证AZ1挂了之后AZ2还能有足够多的副本。
- 另外一种是3个AZ,那么会把3个副本平均分布在每个AZ上。
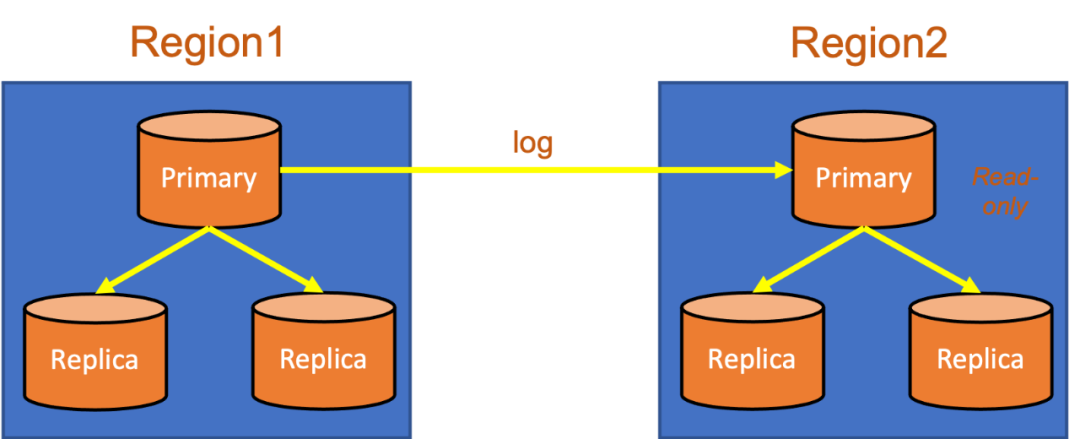
跨Region部署(如上图):
跨Region一般是以灾备实例的形态存在。备Region的Primary节点一般会设置为只读。在Region1出现异常的情况下,为了保证数据的一致性,需要人工决策是否切换,所以一般也不会自动切,而是选择手动切换。
在MySQL生态,跨AZ或者Region部署有以下几个特点:
- 一般采用两AZ或者三AZ部署方式;
- 数据以逻辑日志或者物理日志格式进行同步;
- Primary与Replica之间使用异步或者半同步方式连接;
- 数据一致性以及故障的发现和处理通过外围系统或者内置的一致性协议来保证;
TDSQL-C异地容灾系统的实践
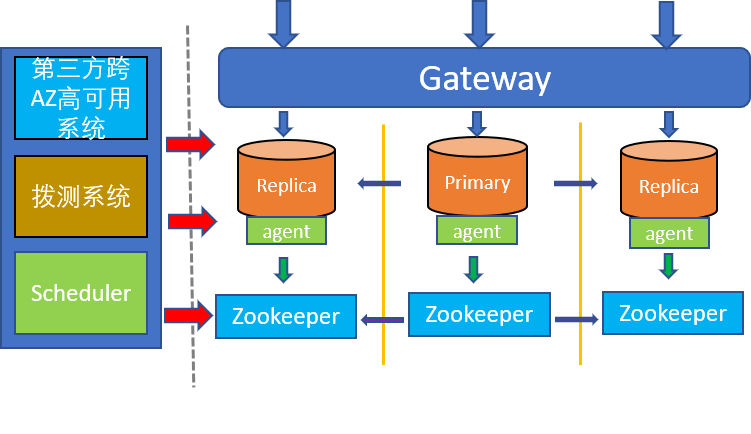
(TDSQL-C多维一体的容灾系统)
云原生数据库TDSQL-C在异地容灾能力构建上,近期推出了跨可用实例功能,支持跨AZ的手工和自动切换。下文将重点介绍容灾系统的实现原理和难点:
多维一体容灾系统概述:
● Agent与实例同机部署,负责采集实例状态,并定期上报给Scheduler。比如采集实例的主从状态(主从同步是否异常、主从同步的延迟);同时还会有MySQL进程的存活状态(正常、hang住、oom、crash等);另外还会对机器本身的硬件做检测(磁盘有坏块或者是内存、CPU异常等)。
● 通过心跳上报给Scheduler,Scheduler根据实例状态做出不同的故障决策,确定是否需要发起切换,以及是可用区内的切换还是跨可用区的切换。
● 另外,Scheduler通过ZK选主来保证自己的高可用。
故障切换步骤:
1. 当主可用区发生故障,ZK自动切换,Scheduler通过ZK重新选主;
2. Scheduler与发生故障AZ的Agent丢失心跳(心跳也是租约的一种方式,同时Agent与ZK本身也会定时续租);
3. Scheduler Double-check对应Agent的租约信息;
4. 等待Agent租约超时后,Scheduler发起故障切换;
跨AZ切换的挑战:
主要有两点,防双写和防误切。防双写是为了避免切换可用区后,原可用区仍然可读写,造成数据混乱。防误切则是为了避免产生跨AZ访问,导致业务访问延时增加。
防双写的策略是:
● ZK降级变成只读,Agent去续租的时候,会续租失败;
● Scheduler降级后会自动退出;
● Agent租约过期后,对数据库实例设置只读,防止旧实例有新的写入;
防误切的策略是:
● 引入第三方跨AZ系统,形成三级或多级租约系统
Agent除了与Scheduler、ZK续租,我们还引入了一个在腾讯内部广泛使用的第三方租约系统。在运营过程中,即使出现人为误操作或者软件Bug,导致Scheduler和ZK均不可用,系统仍然可通过与第三方高可用系统的续租防止大规模误切。
● 引入外围拨测系统,形成节点内外、长短链接全方位拨测机制
Agent本身是有拨测的,Agent的拨测是在本地节点内部的拨测,节点内部通过长链接进行拨测,然后定时采集。我们在外围引入拨测系统后,可采用短链接的形式对各个节点进行周期性探活。
● Scheduler根据拨测结果、各级租约状态作出故障决策
当出现故障的时候,Scheduler会根据租约信息、拨测信息,以及实例的状态信息,综合多方面、多维度信息做出故障决策,尽可能防止误切。
以上是腾讯云原生数据库TDSQL-C异地容灾系统的实践。
TDSQL-C全球数据库形态,敬请期待
TDSQL-C是计算存储分离的架构,这里主要介绍了计算层的容灾处理机制,而存储层的数据容灾则是依托于HiStor实现的(HiStor是腾讯云分布式块存储产品CBS的底层存储引擎),感兴趣可以查找下相关资料,不再赘述。最后,预告一下,TDSQL-C明年将推出基于Redo复制的全球数据库形态,敬请期待!