_
_
_
_
原文链接:
https://medium.com/swlh/hadoop-evolution-decade2-ca46e5514713
作者:Arun C Murthy
Cloudera 现任CPO,
原Hortonworks联合创始人
译者:刘岩
Cloudera 解决方案工程师
_
_
_
_

理解Cloudera Data Platform的一个核心的关键点,是需要从架构层面上,通过对比Hadoop的上一个十年,来使大家明白我们重铸和演进的产品到底代表了什么。最近这几个月,我一直在致力于向我们的客户演示CDP,同时也收到非常多的,令人兴奋的反馈。
通过这些反馈,我们看到有一部分客户初期会很自然的把CDP理解为仅仅是一个“合并发行版”(Cloudera与Hortonworks在2019年完成合并,合并前各自拥有大数据平台产品CDH以及HDP)。
在某种程度上,这样理解没有问题。合并之后我们的确要做出一些选择,例如是只选一个,类似Ranger/Sentry,或者是并存, 例如Hive-LLAP/Impala 以及 Atlas/Navigator。但是,选择某些组件然合并成CDP发行版,并不是我们真正要做的事情。 我们看到有些人,例如:Andrew Brust 看到了我们真正要做的事情,但普遍层面客户对当前和未来的理解不是很充分。
所以我觉得我有必要,通过图表的形式,来更好的展示社区会把生态群带往何处。
从哲理的角度上讲,我们先花一点时间回顾一下我之前的一篇相关博客(译者注:Hadoop已死,Hadoop长存)。对我个人而言,Hadoop是一个实现了下述哲理的,现代化的,用于管理和分析数据的架构:
将存储,计算,安全和治理进行了软件层面的解耦。
通过普通商用基础设施构建超大规模的分布式系统。
利用开源来取得开放的标准和社区级的支持。
持续的在每个层面上进行独立的演进和创新。
第零个十年
_
数据中心里的Hadoop
在上一个十年,基于当时的技术可用性和约束的前提下,社区交付了一个拥有以下几个关键特点的数据平台。
00
亲和式的计算和存储设计 – 这是因为高带宽的网络在当时是非常昂贵的,同时用于数据缓冲的内存及SSD产品也都是非常昂贵的。
01
通过资源管理(Yarn)在超过5000个节点的大规模,多租户的集群的共享资源上同时执行数百万个批处理任务,以及为新生的数据服务,例如Hive-LLAP,Impala,HBASE提供多租户的服务。
02
软件是可以被公开下载并使用在共享资源上的。
03
在企业自有的数据中心里,可以使用例如网络边界安全和物理访问控制作为安全层面的核心。在很多案例里,客户发现这些简单的安全配置是足够的,同时也支持更复杂的,更可靠的安全机制。
因此,第一代Hadoop的部署,看起来是下面这样的:

图:第一代Hadoop的部署形态
这个部署形态带来的最大问题是升级的复杂程度。大型的,共享式的集群和简装软件意味着升级是一个很痛苦的事情。例如,每个租户都需要在同一个时间节点升级,这带来的影响是非常广泛的。企业在协调数百个租户和数千个应用下的升级投入是非常的高的,亲和式的架构没有存储和计算独立升级的设计。
第一个十年
_
云中的Hadoop
紧接着是云服务厂商,通过下面的这个架构,来实现了公有云Hadoop第一代标志性架构:
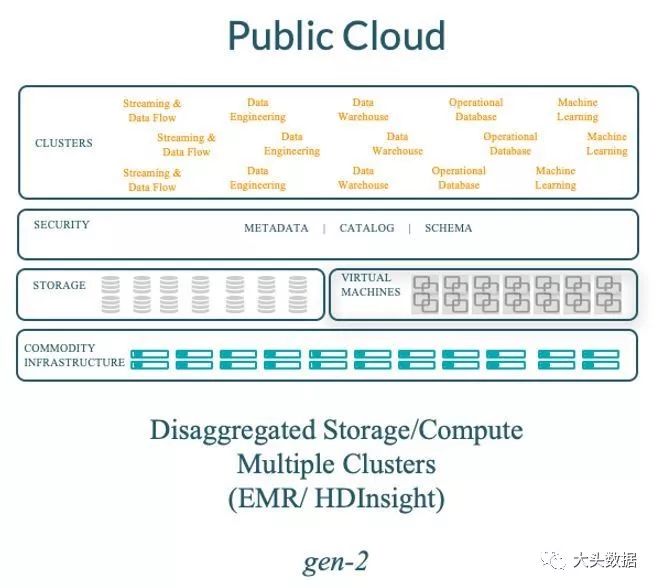
图:第二代Hadoop的在云中的部署形态
利用了云对象存储来与计算进行了解耦。社区通过HCFS API构建了S3接口和WASB接口。
使用VMs来快速部署大量短暂性的Hadoop的计算集群。但是,频繁的启动和关闭VMs(每次通常是10分钟)所带来的额外开销是一个很大成本问题。
在临时性的Hadoop集群应用场景下,并没有很好的管理常驻的元数据和安全策略等这些必要的服务。因此也导致了需要这些服务的集群,不得不采用费用高昂的常驻性集群部署方式。
第二个十年
_
由Hadoop 驱动的数据云
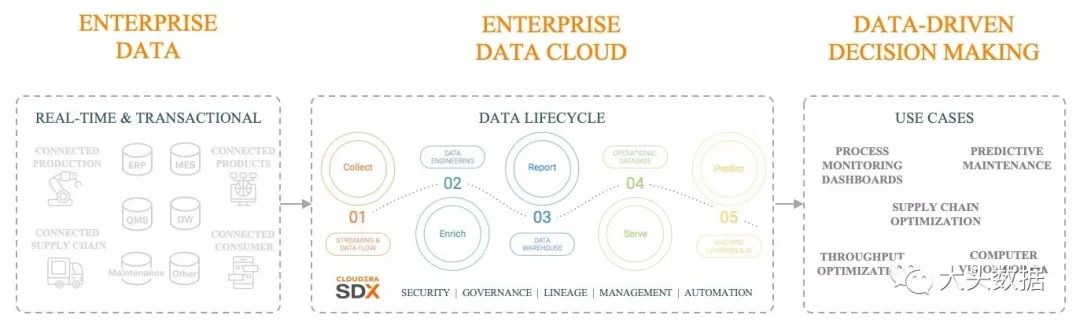
在上一个十年结束的时刻,我们需要从最底层去重新思考Hadoop,并不是仅仅为了满足公有云的场景,还要包括企业自有的数据中心。同时,也需要更加的关注有哪些浮现的技术会推动Hadoop的下一个十年的演进。
云的体验基本上界定了用户需要简单易用的,自助服务式的,按需且可弹性付费的软件以及应用程序服务。
解耦计算和存储现在当前的技术下在公有云和私有云中都是可行的,这确实提高了工作负载的性能。
容器及Kubernetes无疑是一个已经标准化的,更加灵活和敏捷的操作环境。
随着实时计算,分析和机器学习的融入,这些横跨数据生命周期的业务能力已经被认为是实现企业数据驱动转型的必要条件。
(点击查看大图)
在上述的背景下,我们重新定位了下一个十年的平台:
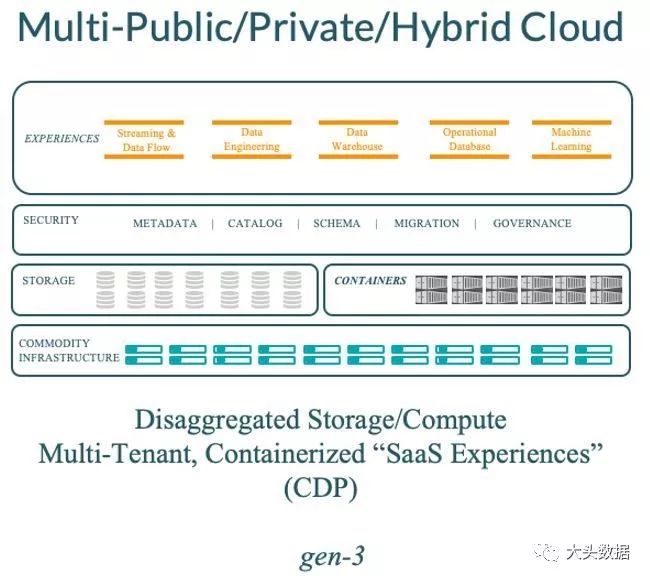
图:第三代Hadoop的部署形态
解耦存储,元数据,安全,治理以及计算。并且,通过更多的利用RAM和SSD来Cache数据,即便在存储和计算分离的场景下,依然是可以提供交互级的性能的。
软件会以服务的形态存在,而不是一个自包装的形态。通过容器(Container)和编排(Kubernates)技术来实现一个新的多租户方案,每一个租户可以隔离在私有的,独立的服务中(例如,每个租户自己的数据仓库)。
在混合云中具有超强的安全机制可以使得企业不在需要在混合云中部署企业防火墙。增强对数据数据隐私和新强制法案的关注,并且将其反映在数据血缘,数据治理,数据迁移和横跨完整数据生命周期的各类应用层面上。
这个全新的架构也引出了很多优点:
更加易于管理:解耦后的架构拆分了存储,计算和元数据层。(虽然在企业内部的数据中心对于还停留在上一代的基础设施设备可能亲和式的部署更有效率)。
更易于使用:因为更加的突出了服务而不是独立软件,因此更关注在适应不同用户的体验,例如Warehousing,Machine Learning,Streaming等等业务。
更快的部署:通过Containers和Kubernetes来极大的加速部署和简化诸如 Warehousing,Machine Learning,Streaming等各类业务的管理。
更强安全和治理:通过SDX触及整个数据生命周期进而更好的完成数据驱动决策的制定
由于现有的部分客户已经被要求尽可能地提高可管理能力,提供更健壮的多租户和隔离能力以及更好的安全及治理能力。
因此,这些企业在理解了上述CDP的优点之后非常的兴奋,并不仅仅是因为CDP公有云版本,还包括了今年下半年我们要推出的CDP私有云版本(译者注:CDP公有云/私有云版本 与 CDP数据中心版本完全不同)。CDP的市场空间以及推出时间在我看来都是非常好的。我们的时间掐算的非常准确。
总结
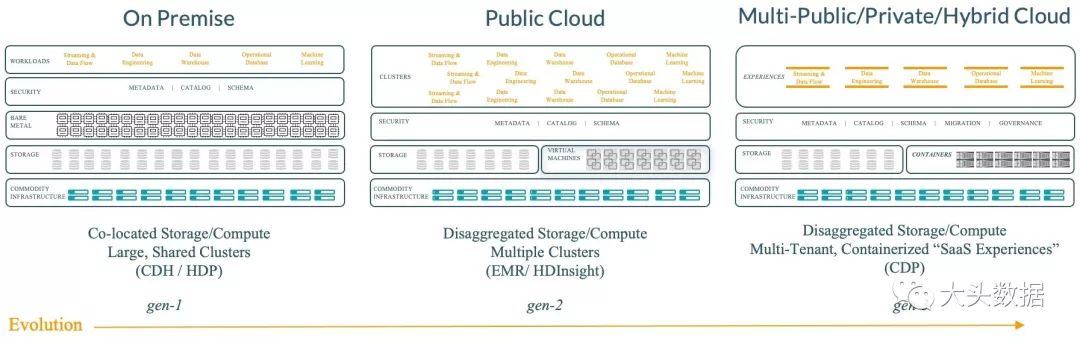
让我们快速回顾一下基于Hadoop的数据架构演进:
(点击查看大图)
当我们进入到第二个十年期时,这里我们提供了一个架构变化的点对点对比,也期望通过这个对比来展示随着基础设施能力的提高,以及容器技术的多样化能力,Hadoop如何在一个混合环境中管理数据和工作负载。

我个人,可以说非常激动的见证了平台如何演变至更贴近下一个十年的实质业务需求的。CDP是面向云的数据架构。它提供了拥有一致的安全及治理能力的数据平台来帮助企业更好的对生命周期内的数据进行控制。并且不要忘了,它依旧是100%基于Hadoop的哲理。
我对这一个十年的,由Hadoop驱动的数据云非常有信心,并且希望可以再次超越它。
* I don’t disagree with Bezos on the Day One philosophy, I just can’t help but start the count at 0! ?
*我并不是不同意Bezos的Day One哲学,我只是不能控制我自己从0开始算起!
(译者注:0在计算机领域里标记开始,自然界更多的用1来标记开始,大概的意思是,IT男都习惯用0表示第一章。)