6月20-25日,数据库国际顶会2021 ACM SIGMOD在西安举行。本届大会上,腾讯云数据库技术总监邱敏带来了主题为“腾讯云数据库技术演变之路”的演讲。
演讲视频
以下为演讲内容的文字实录:
数据库是三大基础软件之一。近年来,腾讯也在不断加强各类数据库产品的研发投入。企业级分布式数据库TDSQL是腾讯云数据库的代表性产品,同时具备OLTP、OLAP,以及混合OLTP和OLAP的HTAP能力。它包括以下几个系列的产品:
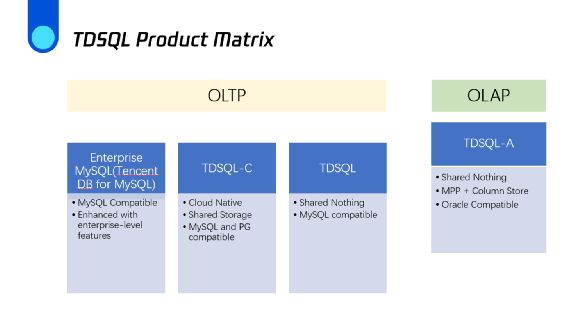
- 企业级MySQL即腾讯云数据库RDS系统(CDB),相对原生MySQL进行了大量内核级补丁修复、特性优化和企业级功能,包括SQL审计,数据库加密和防火墙等。
- 云原生数据库TDSQL-C,采用计算与存储分离架构的共享存储产品。包含两大兼容版本:即MySQL版与PostgreSQL版。
- 兼容MySQL的金融级分布式数据库TDSQL-D。其基于零共享架构,适合具有海量数据和事务交易场景使用。
- 分析型分布式数据库TDSQL-A。基于MPP架构,具备出色的HTAP能力,和自主研发的列存引擎,它还与Oracle高度兼容。
TDSQL产品广泛应用于不同领域,涵盖电子商务、政务、金融、社交网络、娱乐、视频等,在腾讯公司内则包括众所周知的王者荣耀、微笑支付等。目前,腾讯云数据库实例部署规模超过一百万个CPU内核,拥有超过100PB级存储规模。
由于今天时间有限,不能涵盖每一种产品。以下主要介绍云原生数据库TDSQL-C。
1
TDSQL-C架构体系优化
首先介绍TDSQL-C的体系架构。众所周知,云原生本质上是一套利用云基础设施来为客户提供具有成本效益和高度可用性的解决方案的技术体系和理念。云原生数据库也是如此。
首先,我们来看当前MySQL数据库架构存在哪些问题,以及为了构建云原生数据库我们必须解决哪些挑战。
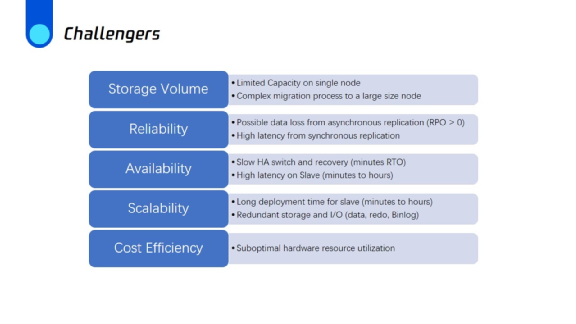
第一,假设在传统的MySQL集群中,每当一个节点加入集群时,它就必须创建完全相同数据的副本。一般来说,在本地存储中,部署从属实例时,数据库越大,启动实例所需的时间就越长。而且它增加了冗余存储消耗。这是没必要的,并且在某种程度上是浪费。举个例子,“一主三从”集群的 1TB容量数据库,将完全占据约4TB的存储空间。
第二,当单机磁盘存储容量达到上限时,就必须将数据库实例迁移到更大的节点,这个过程非常复杂也非常耗时。从可靠性和可用性方面来说,异步复制中可能发生数据丢失。同步复制安全性更高,但延迟也更高。此外,从HA切换恢复可能需要更长的时间,从DBA的角度来看,灾备发生HA的时候,这个时间点是不可控的。
第三,计算与存储紧耦合可能导致硬件资源利用率不理想。例如可以想象如下场景,当磁盘即将打满时,但CPU使用率非常低。出于存储目的,必须迁移到更大容量的机器。更大的机器通常配有高端CPU资源。这意味着客户在大多数时候必须为CPU支付更多费用,这对于云的客户而言没有成本优势。
为了解决前述问题,我们要对数据库架构进行一些根本性改造,即具备全新架构的云原生数据库TDSQL-C (原CynosDB)。相同的地方是,它仍然是“一主多从”架构,支持一个读写节点、多个备库节点,备库节点最多可以扩展到15个读节点。但最大的变化是其实现了计算与存储分离,主节点和备节点共享一份存储。TDSQL-C主备之间和原生MySQL不同的是它使用Redo log进行主备数据同步——Redo log发送到备库之后只负责同步备库的Buffer Pool,其性能比原始方案有极大的提升。TDSQL-C同时实现了新的数据库概念,如日志即数据库。
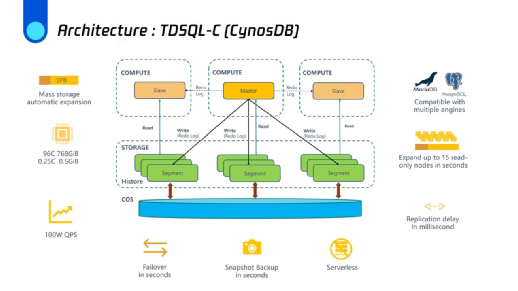
这使得计算层得以轻量化,对于实例启动和关闭以及集群扩容和缩容非常方便。
计算存储分离的架构,其好处是显而易见的:计算节点和存储节点可以单独扩容。在计算节点上,TDSQL-C可以支持灵活的资源配置,从低端的1/4核和0.5GB内存一直到96核和768GB内存。与其他优化一起,读写性能得到显著提高——TDSQL-C单体实例可支撑上P数据百万QPS。此外,对于备份的故障转移和快照,操作可以秒级完成,同时回档速度也是GB级的。
2
TDSQL-C的核心技术创新
以下介绍TDSQL-C关键技术突破。分为两部分,一部分是Serverless功能,另一部分是性能优化。
2.1 Serverless
第一个功能是计算存储分离。实际上,将存储层与计算层分离是弹性扩展和Serverless的第一步。
TDSQL-C计算和存储分离,但是计算节点的主备节点会共享存储,即Histor。和传统MySQL架构不同,它是一个可计算存储,体现在两点:主节点的计算节点会把产生的Redo日志下发到存储层,存储层会依赖于它的Base page以及所产生的Redo log来负责数据的持久化操作,存储层在收到Redo log后才会向计算层反馈信息,说明Redo log已经持久化,证明现在的事务已经结束,可以让业务逻辑继续进行。业务逻辑在进行的同时,存储层会异步处理Redo log。和传统的MySQL架构相比,不会有刷脏页带来的一些性能抖动问题。
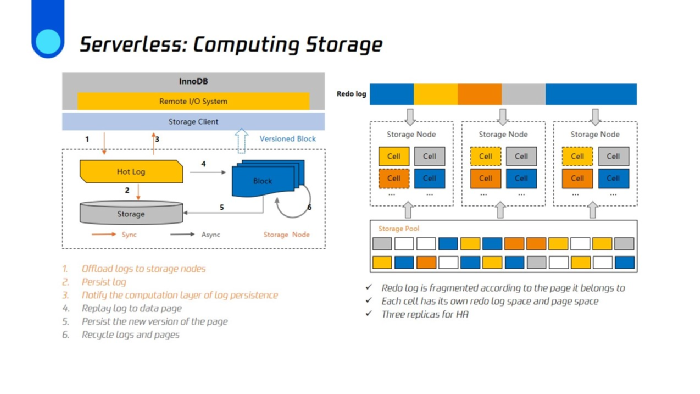
在Histor把数据持久化之后,会把之前Redo log所占的空间回收。而我们的存储也有以下特性:我们在把本地磁盘映射到网络盘时,是根据它的物理地址映射到底下存储空间的某一个cell中,所以它的日志是按照页面来进行分发,每一个cell里都有相应的数据页和Redo log。主节点和备节点共享存储数据,支持多数据版本。数据多版本是由Base page加上从计算层传递下来的Redo log生成的一个具有指定版本的数据来实现的。

第二个功能是通过细粒度的资源统计,实现客户只需按实际使用计费,不使用不收费。过去,随着数据规模不断增加,即使之后删除数据,数据实际规模已大大缩小,但是已用空间不会减小,客户仍需要为未使用空间资源买单。为了准确计算空间使用量,我们利用三个链表分别管理不同使用状态的extent: 完全占用,部分占用和未占用。只有完全占用和部分占用的extent才会被添加到空间使用计算规则中,从而帮助客户节省成本。此外,TDSQL-C在分配空间的时候以1兆为单位进行分配,根据是否占用决定实际的计费存储量。当资源无需被使用时,我们会将其回收到资源池,以便用于其它目的。所以从用户的角度出发,降低了用户的计费存储量。后续我们还会继续优化,真正做到页级别的使用计费。
2.2 TDSQL-C的性能优化
- 二级缓存
我们在存储架构中引入了一个非常重要的功能,称为二级缓存。此前,我们做了很多努力来优化读取性能和写入性能,但实际上,由计算和存储分离带来的远程I/O不容忽视。最初,存储层次结构中只有两层,其中内存始终是缓存频繁访问数据的第一优先级。当缓存未命中时, 我们必须依靠远程I/O来读取数据并缓存到buffer pool中。如果buffer pool已满,则从中选择记录淘汰并加入新读取数据。
在TDSQL-C中,我们在远程存储和Buffer Pool之间实现了二级缓存层,它使用本地存储介质。为了提升性能,可以使用SSD或NVM存储设备作为二级缓存的介质。从Buffer Pool中淘汰的页面缓存在该层——实际上并不是淘汰,而是把从Buffer Pool移出的数据缓存到本地的SSD存储或者AEP存储。下次访问该数据时,满足一定的条件下,可以直接从本地读取,这样就可以最大限度降低网络I/O的消耗。
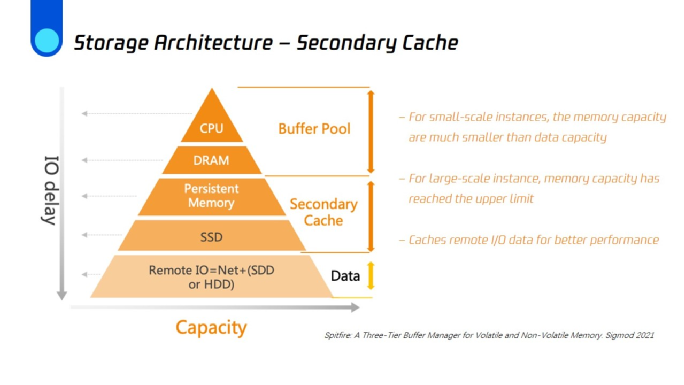
这项工作是今年SIGMOD收录论文《Spitfire:A Three-Tier Buffer Manager for Volatile and Non-Volatile Memory》思想的工程实践。
- 自动的无感知备份以及秒级回档
备份和恢复对于确保数据安全非常重要。由于架构优势,我们还可以在存储层非常快速地进行备份和恢复。在备份中TDSQL-C实现了两个突破:一个是无感知备份,计算层没有察觉。备份和恢复可以在每个单元并行完成。我们有一种机制来确保可以为备份制作全局快照。第二是极速回档。在我们的实验中,备份只需几秒钟即可完成,数据可以以GB级别的速度回档,速度非常快。
通过这些架构升级和优化,我们可以看到TDSQL-C自发布以来经历了快速增长。过去十二个月的实例数量增加近34倍。TDSQL-C适用于来自不同领域的许多客户,包括电子商务,金融,视频等。所以目前的结果非常喜人。当然,我们还有很多事情要做,还有很长的路要走,将来肯定会遇到很多挑战。
3
TDSQL-C未来探索规划
展望未来,数据库技术的发展方向将继续由业务驱动的需求来定义。
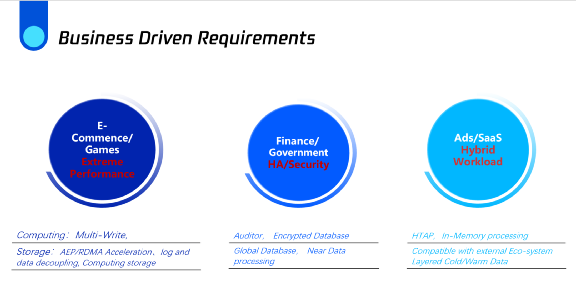
例如,电子商务和游戏行业需要极端的性能。为了满足这个要求,也许我们可以依靠一些技术,如多重写入来实现高可用性吞吐量,并且还可以在存储层考虑硬件加速来让I/O得以加速。
对于更关注高可用性和安全性的金融和政府应用,我们将开发SQL审计,数据库加密和全球数据同步、就近访问等功能。在Ads和SaaS领域,它涉及大量的混合架构能力要求。为了解决此问题,我们或将引入HTAP和执行计划缓存等。我们可能也要采用外部生态系统来支持不同的工作流。我们也可以考虑冷热数据分离等技术探索。
下面大致介绍一些我们未来将探索的技术。
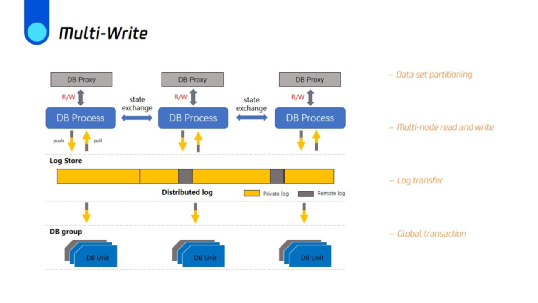
第一个是多点写入。到目前为止,我们在扩展读取吞吐量方面做了很多努力。但是单点写入的问题仍然存在,这在某些情况下可能会成为系统瓶颈。
我们有一些正在探索的想法。例如,用于全局处理日志相关逻辑(如数据一致性)的专用日志服务器,从而不需要在主节点和从节点之间传输日志。同时,我们可以依靠逻辑分区的概念来进行无冲突的多点写入。存储层中的数据可以被物理分区,也可以不被物理分区。
第二是HTAP。传统的T+1解决方案是通过ETL通道连接TP系统和AP系统,对于某些实时应用来说可能不是一个很好的解决方案。许多产品正在构建HTAP功能。我们还创建了一个基于列式存储引擎来加速分析查询。

屏幕左侧是传统的解决方案,其中系统以单个R/O节点部署。查询基于行存或列存引擎中执行,完全由Proxy通过手动指定的连接字符串或一些非常简单的启发式规则来确定,在许多情况下可能会导致一些不正确的查询路线选择。该解决方案的另一个问题是整个查询必须完全在基于行或列的引擎上处理,它不能结合两种引擎的优点。
因此,为了支持精细的执行计划控制,我们需要在MySQL实例中构建一个列存引擎,作为对查询计划树中物理操作的增强。优化器将决定执行计划的哪一部分应该下发到列存引擎执行,并将执行的中间结果转换为行存格式返回给行存引擎。
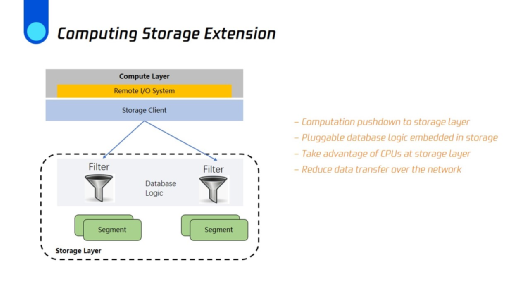
第三个,可计算存储功能扩展。最初,我们在存储层实现了redo log回放的数据库逻辑,但我们可以做更多的扩展。比如通过将部分SQL计算下推到存储层,我们可以提前将一些不符合谓词条件的数据在存储层过滤掉,减少网络传输和数据格式转换的开销,减少计算层CPU的使用,类似的功能还包括聚合操作下推。为了做到这一点,我们需要定义内部协议将SQL计算操作下发到存储层,存储层将中间结果(intermediate result)传回到计算层。这个项目也还有很多工作要去开展。
- End -
更多精彩

↓↓神秘惊喜点这儿