项目简述
本文主要记录作为非web开发人员(本人),如何实现迅速部署自己的第一个SPA应用至星际文件系统 IPFS 作为入门web3.0 的第一个练习,拿我自身来说,前后端知识基本为0,我的基本流程如下:
- 选择合适的应用类型(SPA)
- 挑选简单模板并套用(H5+Bootstarp+原生javascript)
- 代码托管平台(Github)
- 白嫖免费部署服务:
- 传统方式:Githubpages
- PAAS(platform as a service)选择1: fleek (我的选择)
- PAAS(platform as a service)选择2: 4everland
- 第三方表单服务提供商formspree实现留言功能
- 通过github绑定fleek部署
- 下载IPFS客户端, 连接至fleek部署的节点
- 测试如果替换掉html的音频视频链接为IPFS的地址,在备份足够多的情况下,是否P2P加载更快
- 更新网页内容:只需git经典三步,add,commit,push即可,因为已经绑定fleek
- CI/CD:无
- 优化:没有框架,html页面有重复的部分,我个人目前用md自动转换为html,也符合日常需求
最终效果
- Githubpage: https://yaozeliang.github.io/resume/
- IPFS:https://ipfs.fleek.co/ipfs/QmUzk9oyUCzaXsf8jedVqLzRFi1rBxTRdKfExA2pzFJeBU
- CID(Content Identifier):QmddHLkhzHixGpTAGopDNJ8dF3i6UrdrsEiMwsDt2x52G5


挑选模板,修改,增加留言服务,push到github上
这是我挑选的模板链接: 点我预览,这款模板2017年上线,没有使用框架,ajax配合原生javascript,但是恰好符合我的目标,考虑到当前PAAS平台部署react,django等项目还不太成熟,我选择最简单的单页面应用
本着白嫖的原则,我们可以使用github提供的免费网页部署服务。但是只适合单页面应用,套任意的前端模板就行。首先简单修改模板,本地运行没问题后,经典三步推到github:
git add
git commit -m "First commit"
git push origin master接着可以迅速在文件所在的仓库中找到对应选项勾上,成为githubpage的项目后会自动寻找目录的index.html, 一般大家都是拿部署文档用,我这里因为有个人需求,想做的稍微美观些:

这时我们点击提示的url已经能看到部署成了,每次本地修改push后相当于重新部署了下,等待几分钟就可以看到变化,有一些延迟,不过对于免费的东西不能要求太多。不要忘了提前用remote add origin 挂载到相关的仓库就行,比如我这里的话就是resume
放在github上有个明显的好处,方便对接很多其他服务,比如关于留言的部分可以直接用免费的留言服务商formfree:

它的功能就是自动生成一个表单和地址,这样我们只要post到这个地址就行:

测试后留言功能没有问题,可以进行下一步了
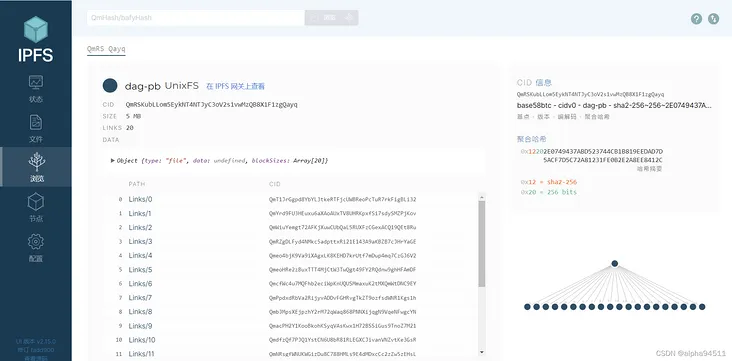
选择PAAS平台部署,下载IPFS客户端或者通过CLI查看媒体文件的ID和哈希
这里就可以看出github很方便,使用fleek不用注册,直接选择用github登录就行,然后挑选你要部署的仓库,后端选择IPFS就行了,目前fleek也支持一些主流框架,我还没有尝试,不过看到了gatsby,hugo,react,nodejs这些:



接下来就可以看到我们的结果了:https://ipfs.fleek.co/ipfs/QmUzk9oyUCzaXsf8jedVqLzRFi1rBxTRdKfExA2pzFJeBU 我们如果点击媒体的路径 https://ipfs.fleek.co/ipfs/QmUzk9oyUCzaXsf8jedVqLzRFi1rBxTRdKfExA2pzFJeBU/images就可以看到已经在IPFS上了:

下载IPFS的客户端打开后链接节点,利用刚才生成的哈希值QmUzk9oyUCzaXsf8jedVqLzRFi1rBxTRdKfExA2pzFJeBU可以直接查看到

接入节点后可以看到当前和我们连接的其他节点:

现在我看了下媒体文件的视频,已经不知道什么时候开始被分成很多份了,这是说其他节点已经备份了我这个文件的缓存吗?可以多研究下。
做个实验,我原来的html里路径引用的是本地video/xxx.mp4,如果我把路径替换为ipfs的,加载会更快吗?P2P?
原来的代码:
<a class="lightbox mfp-iframe" href="video/powerapps.mp4"title="Stock Management"></a>尝试替换为IPFS的链接,这样如果通过githubpage访问,加载的视频是引用的IPFS地址
<a class="lightbox mfp-iframe" href="https://ipfs.io/ipfs/Qmb6ZTkEPuy79rXo6WiPhiBkfiNmUFBaH4i1Dh6DYxhXK8filename=powerapps.mp4"title="Stock Management">
</a>在F12查看Network的加载速度,我先简单运行了10次,加载速度差的不多。但是第二天再运行发现还是略快一些,不过我可能本地有其他因素影响。
Merkle DAG默克尔树结构,
简单看了下,IPFS用到了merkle DAG默克尔树结构,部分用到有向图无循环拓扑排序,这个很巧,我最近刚好用拓扑排序解解决了工作中的一个实际问题:如何不使用entreprise版本实现Dremio的环境备份,用过Dremio的朋友肯定知道:Dremio付费功能
具体详情以后会再记录下,但是简化问题就是,我们从preprod上线到prod的时候,需要从数据源,pds,vds,reflection依次生成和preprod一样的数据集,但是你的sql查询会互相有依赖关系,比如select a from b,c 通过api获取到所有datasets的时候,需要先做排序,不然可能会出现生成 a在b,c之前的情况。 这种关系不是传统二叉树的层遍历,因为每个vds可能有多个父母,解决方法就是拓扑有向图排序,可以保证始终优先生成parent(s),用python为例,引用下别人的实现方法:

from collections import defaultdict####发现上面的代码有点问题(不知道是不是我的问题),所以我自己写了一个,同时也加深下对于拓扑的了解
class Graph:
# 构造函数
def init(self,vertices):
# 创建用处存储图中点之间关系的dict{v: [u, i]}(v,u,i都是点,表示边<v, u>, <v, i>):边集合
self.graph = defaultdict(list)
# 存储图中点的个数
self.V = vertices# 添加边 def add_edge(self,u,v): # 添加边<u, v> self.graph[u].append(v) # 获取一个存储图中所有点的状态:dict{key: Boolean} # 初始时全为False def set_keys_station(self): keyStation = {} key = list(self.graph.keys()) # 因为有些点,没有出边,所以在key中找不到,需要对图遍历找出没有出边的点 if len(key) < self.V: for i in key: for j in self.graph[i]: if j not in key: key.append(j) for ele in key: keyStation[ele] = False return keyStation # 拓扑排序 def topological_sort(self): # 拓扑序列 queue = [] # 点状态字典 station = self.set_keys_station() # 由于最坏情况下每一次循环都只能排序一个点,所以需要循环点的个数次 for i in range(self.V): # 循环点状态字典,elem:点 for elem in station: # 这里如果是已经排序好的点就不进行排序操作了 if not station[elem]: self.topological_sort_util(elem, queue, station) return queue # 对于点进行排序 def topological_sort_util(self, elem, queue, station): # 设置点的状态为True,表示已经排序完成 station[elem] = True # 循环查看该点是否有入边,如果存在入边,修改状态为False # 状态为True的点,相当于排序完成,其的边集合不需要扫描 for i in station: if elem in self.graph[i] and not station[i]: station[elem] = False # 如果没有入边,排序成功,添加到拓扑序列中 if station[elem]: queue.append(elem)g= Graph(6)
g.add_edge(5, 2);
g.add_edge(5, 0);
g.add_edge(4, 0);
g.add_edge(4, 1);
g.add_edge(2, 3);
g.add_edge(3, 1);print ("拓扑排序结果:")
print(g.topological_sort())
拓扑排序结果:
[5, 4, 2, 3, 1, 0]
IPFS的思路大概也是如此,通过不断寻址(CID)在节点间跳跃可以p2p的方式下载文件,实现了真正去中心化的网络,这可能也是作者自信的命名为星际文件系统的原因吧。。。至于能不能实现他的野心取代http协议,要看之后的生态发展了

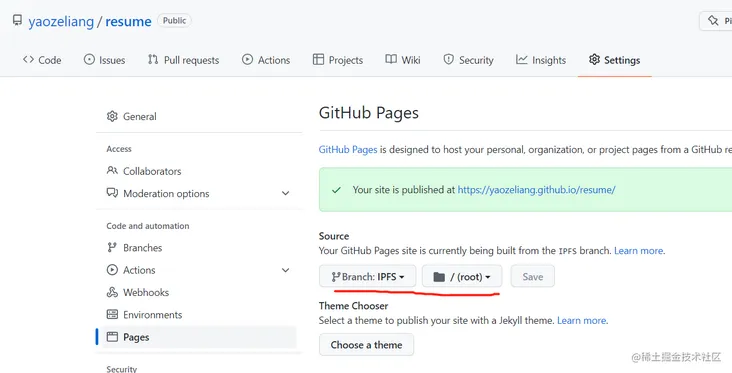
创建新的branch,使用IPFS当作图床
之前用ipfs的链接替换了一个视频,因为好奇我想看整体效果,新建了一个branch叫IPFS,在这个分支的话我替代了原有的a标签href链接到IPFS,这样修改后我可以删除很多其他文件:
master

IPFS

单就我这个简单应用来说,只要保留原始的html就够了,我的css,js,image,video这些都放在了IPFS上来引用,目前不知道是不是那些连接到我这个node的其他peer能不能有一部分缓存和备份,有待探索,现在我在仓库的设置里选择IPFS这个分支来部署:
成功后我看了下加载速度(network/waterfull),的确是比原来快了点,具体原因目前我还不太清楚,有一个小技巧是在你没有配置网关的情况下,所有的根目录前面都是https://ipfs.io,比如这里:
<script src="https://ipfs.io/ipfs/QmNXRFREw7waGtKW9uBUze3PkR9E12HeeAQSkZQSiFUJqo?filename=bootstrap.min.js"></script>
<script src="https://ipfs.io/ipfs/QmVf6WVGG3XYMa4hqArswuK9XAXscm1GQXzREWak4Agn1h?filename=page-transition.js"></script>
<script src="https://ipfs.io/ipfs/QmPG8uTXJmYYBxSR44pv5EfQkHxfcLs1MT5vYpXArugGys?filename=imagesloaded.pkgd.min.js"></script>
<script src="https://ipfs.io/ipfs/QmQ3ZKx2Lu1D8JR7ra1kpXDz7rVRpE8hjZYrXPPDe4mVxM?filename=validator.js"></script>
<script src="https://ipfs.io/ipfs/QmepiCNNLC52DSbKdotnav8H8XNdtxQN82xygcTPyCVQV2?filename=jquery.shuffle.min.js"></script>
<script src="https://ipfs.io/ipfs/Qmbtz6ZPeeBEnVeez78MGr5NVtnH5tkhP5ijv2KvtZyg6b?filename=masonry.pkgd.min.js"></script>
<script src="https://ipfs.io/ipfs/QmdB8FAW9LYHy7B2p5JVhyeSMVSG9uwm8cEGMMYGBEjFAe?filename=owl.carousel.min.js"></script>
<script src="https://ipfs.io/ipfs/QmSpUo5gEuMXFksbhc1iJbWDHispwbjyCsq79vze2rYuMr?filename=jquery.magnific-popup.min.js"></script>
<script src="https://ipfs.io/ipfs/QmQg9VfdpNi3zPRHSzU39zURPgQKBCWLcgYFwdCHwdu9pN?filename=jquery.hoverdir.js"></script>
<script src="https://ipfs.io/ipfs/QmWSGkNuDeDd23J9rgKMgDs2yAmnospcKkWKNR9RMSS5L6?filename=main.js"></script>很明显,cid的末尾可以传递个参数filename,这个是可选的,如果去掉是没有问题的,但是带上会更明显些,可以知道引用的到底是哪个js,还有就是既然https://ipfs.io/ipfs/ 重复了,也可以考虑在head用base标签,这样一个引用会简单些
<script src="QmWSGkNuDeDd23J9rgKMgDs2yAmnospcKkWKNR9RMSS5L6?filename=main.js"></script>ENS 域名及个人优化,Valine评论插件互动
其实,通过fleek部署在IPFS后对于css和js的引用就不用折腾了,我的工作流就是markdown写文章,转化为html,更新git,然后fleek因为绑定了对应仓库会自动更新。至于优化方面,我个人是展示为目的,希望结合一些我的技能。所以肯定不会把它集成到Gatasby或者Hugo一样的博客框架,对我来说django是个不错的选择
至于域名,目前是git自动给的,我选择尝试了以太坊的ENS域名,这样可以在fleek的部署选项中把ens域名加上,每次更新是由fleek自动更新你的ens,产生的gas费用不用个人承担
- ENS 域名官网:https://app.ens.domains/
- 我的ENS域名:yaozelinag.eth
因为我选择了ENS的域名,所以在etherscan以太坊的主网上你可以轻松的查到我的公钥https://etherscan.io/enslooku...:

有个好处是ENS和你的以太坊地址绑定,所以现在有人要打赏我一杯咖啡,与其给他一个冗长的地址,不如换成更有标识性的名字:yaozeliang.eth (比较适用于WEB3.0的人,我还是喜欢微信!)
至于和访问者互动,我用了纯前端的插件valine,比较不错,个人体验效果很好,推荐
最终效果:
当前域名:https://yaozeliang.eth.link/
主页(背景图片随机)

简历页面

介绍页面
项目展示

文章分享

个人收藏

互动评论 (Valine和表单)

简单总结
- githubpage要求必须是public的仓库,如果有朋友也需要类似的模板,欢迎0元购。。。
- 个人感觉IPFS缺陷还是集中在性能和数据优化,接口问题
- 个人网络需要NAT配置
- IPFS 有go语言支持