欢迎批评指正
DDD 强调领域模型要兼顾业务和技术两个视角。
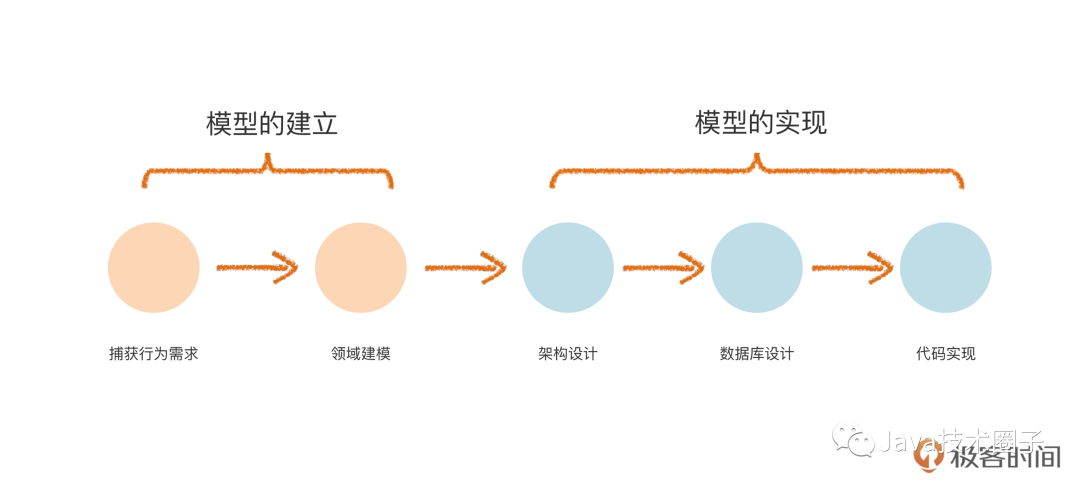
我们怎么用一套系统化的方法,抽丝剥茧、一步一步地把需求落实到代码呢?咱们看看下面这张图,它表示了领域驱动设计中的主要流程。
1
领域驱动设计主要的开发流程你可以看到,在整个开发流程中,首先是要捕获行为需求,也就是传统软件工程里的“获取需求”。这一步,我们要识别需求里有哪些流程、哪些功能,每个功能由什么人操作,会产生什么结果。
在传统软件工程中,这一步常用的方式是用例建模,也就是用 Use Case 来建模。在这套课程里面,我们会用 DDD 中比较流行的一种方法,叫做“事件风暴”。
接下来,我们就可以进行领域建模了,也就是通过建立领域模型,把需求里的主要业务知识描述清楚。DDD 的领域模型,大体上相当于传统软件工程中的分析模型。
基于领域模型,我们就可以做架构设计,包括进程间和进程内的架构。比如说微服务设计、中台设计都属于进程间架构。而 DDD 分层架构,通常说的是进程内架构。
然后就可以根据领域模型进行数据库设计,最后是代码实现。
这样,就形成了一个基于 DDD 的开发闭环。其实,在实践中,尤其是对敏捷软件开发来说,这些步骤不是线性的,而是反复迭代、互相穿插的。DDD 是以领域模型为核心的。所以,我们可以把上面说的步骤分成模型的建立和模型的实现两部分。模型的建立阶段,使用的都是业务术语,归根结底来自业务人员,业务人员不仅能听懂,而且负责评价建模的正确性。而模型的实现,则是业务人员不需要理解也不关注的,会包含技术实现方面的内容。这两者的边界很重要,我们在后面还会反复提到。总结
事件风暴
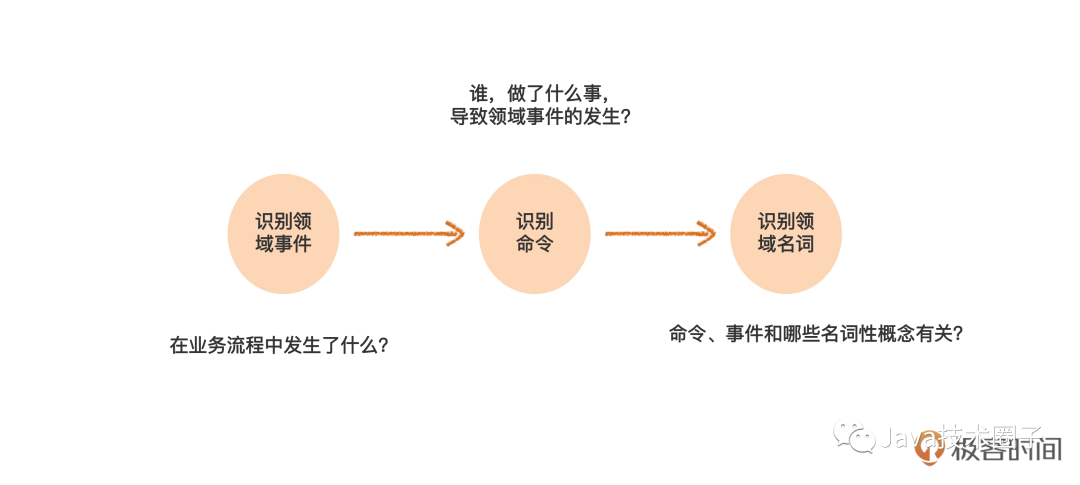
2
这里的第一步是识别领域事件,在这一步,我们要找到业务流程中发生了哪些事情;
第二步是识别命令,进一步说明是什么角色,做了什么操作,导致上述事情的发生;
而第三步是识别领域名词,从领域事件和命令中找到名词性概念,为进一步的领域建模打下基础。这里每一步的具体做法和要点,我们后面都会详细介绍。
事件风暴的第一步:识别领域事件
所谓领域事件,就是在业务过程中,业务人员要关注的那些已经发生的事儿。比方说,对于电子商务系统,订单提交、商品签收等等,都是领域事件。实际上,领域事件表示的是,业务流程中每个操作步骤引发的结果。事件风暴的作者认为,从结果入手来梳理需求,比从操作入手,更容易把业务想清楚。事件风暴中的“事件”两个字就来源于领域事件。
从结果梳理
识别出领域事件和业务规则。
订单创建,订单下发(订单审单以后才能下发)
关于领域事件,我们还要注意下面这两点。
第一,不要把技术事件当成领域事件。领域事件一定要是领域专家所关注的,用的是业务术语。像数据库事务已回滚、缓存已命中之类的技术术语,不是领域事件,不在这个阶段讨论。
第二,查询功能不算领域事件,这部分内容详见CQRS。领域事件应该是对某样事物产生了影响,并被记录的事情。一般是某个事物的创建、修改和删除。还有一种情况是向其他人或者系统发消息,例如“通知邮件已发送”也算领域事件,因为接收方可能会通过进一步处理来影响某些事物。
事件风暴第二步:识别命令
所谓命令(command),就是引发领域事件的操作,我们可以通过分析领域事件得到。除了识别出命令本身以外,我们通常还要识别出谁执行的命令,以及为了执行命令我们要查询出什么数据。
谁,做了什么动作,造成了什么结果(增删改)
客户小二 人工审单 审单完成后订单下发
事件风暴第三步:识别领域名词
操作人 通过 某个命令 对领域名词 做了什么动作造成了什么领域事件
客户小二 人工审单 订单 订单下发
领域名词 订单
事件风暴是业务人员和技术人员一起协作,捕获行为需求、消化领域知识、形成统一语言的一种方法。这是就整体来说的。
必须没有歧义,比如技术说新建用户,业务说新增客户。对于业务来说,客户的物理实体是天然存在的没有创建一说,在这里更为合理。
画模型图
识别出领域实体以后,画uml类图,理清一对一一对多关系,限制,泛化等诸多关系就可以完成领域建模了。
这里建模是一个很考验技能的操作,因为长期以来,开发人员都会被一个叫做sql优化的事情搞的很头疼,而如果建模技能很纯熟,画出的模型就可以单表代替多表联查,这样不仅sql执行效率很高,而且加索引和分库分表也会很方便。
这个过程完善约束,整理出业务词汇表
拆分模块
根据模型图里的交互,可以把相关性比较高的一组模型组合成一个模块。
数据库建表
DDD 主张要根据领域模型来进行数据库设计,保证数据库和领域模型的一致,从而保证数据库和业务需求以及代码的一致性。在进行数据库设计时,我们可以用物理数据模型图,也可以直接用建表语句,两者基本是等价的。为了直观,我们采用了图示的方法。对数据表、字段等等的命名,应该依据词汇表,以便保证统一语言。一般来说,领域模型中的实体映射为数据库中的表;领域模型中的属性,映射成表中的字段。同时还要根据需求补充更多的字段。模型中的一个一对多关联,可以映射成一个外键字段,以及一个外键约束。但基于云的应用一般不会真的建立外键约束,而外键的逻辑关系还是存在的。我们用虚线箭头表示这种逻辑上的外键关系,称为虚拟外键。对于多对多关联,我们必须增加一个关联表,其中包括了两个实体表各自的主键。另外,关联上的多重性决定了外键字段的非空约束。
也可能多个领域模型对应的是同一个表。
代码分层设计

3
变化的依赖稳定的,外部的依赖内部的。
domain 领域模型,用来封装领域数据和逻辑。这一层与领域模型直接对应,是整个系统的核心;
实际实现会有一些妥协,比如应用间传递的DTO放在这里,会把本来是业务层面的东西VO,DO也丢进来。
不做妥协就是写Builder,领域层自己用基本类型和领域层的基本对象构建出领域对象。灵活使用看各位的取舍。
application根据领域模型组合的业务编排,并且处理事务、日志等横切关注点
适配器 主动适配器例如Controller适配http请求,xxxService适配rpc请求,还有防腐层,做模型DTO2DO转换的
被动适配器如Repository 适配操作领域模型的数据库物理表。
这样就可以把领域模型与数据库解耦
Repository → dao→物理表
公共层
例如一些底层支持,日志,用于存放工具和框架。这一层对前面的各层进行支撑。
领域逻辑的识别过程
如果一个逻辑需要和领域专家讨论才能确认的,就是领域逻辑;如果领域专家根本不感兴趣的,多半就是应用逻辑。
界限上下文
一个应用或者模块内部,用聚合根交互。所谓聚合根就是指比如一个订单,包含多个子单,只暴露主单对外交互,子单通过对应主单才能获取,保证数据在编码的隔离。
工作中落地
第一种是新建系统。也就是说现在刚好有一个新项目,可能是要开发一个全新的系统,也可能是为现有系统新增或重写一个比较大的模块。这时候,领导希望保证质量,降低风险,觉得需要方法学的支持,因此要引入 DDD。对于比较大的项目,前期的总体规划和设计还是必要的。但要意识到,这时候产生的模型还是方向性的、粗粒度的,之后开发过程中要随着对问题理解的深入,不断演进。
第二种是改造现有系统。常见的情况是,某个对公司很有价值的系统,已经维护了很多年,系统架构和质量日益腐化,很难维护,不能满足快速变化的业务需求。这时候希望引入 DDD 对系统进行比较大的重构,使系统重新“焕发青春”。另一种情况是企业要进行服务化改造,把一些现有的单体应用拆分成微服务。
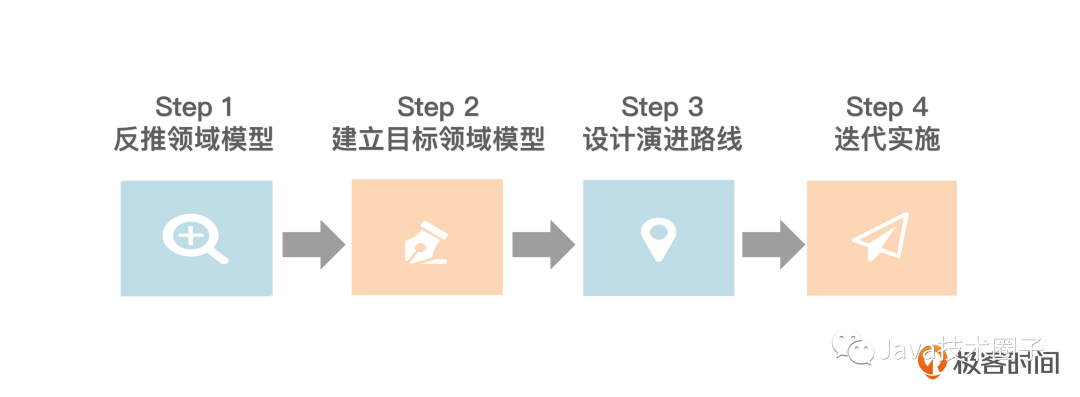
4
第一步是反推领域模型。新建系统的时候是从需求到模型,可以叫做正推。而由于现有系统已经存在了,所以我们做的第一步,反而是从系统现状中“反推”出当前的领域模型,目的是客观地反映出系统当前的领域知识和逻辑。这时候的模型往往有不少问题,比如不能正确反映领域知识、存在矛盾、冗余等。
第二步是建立目标领域模型。根据当前系统的痛点、问题以及业务需求,就可以建立目标领域模型,作为改进的方向。建立目标领域模型,一定要有明确的“时间点”。
第三步是设计演进路线。有了当前模型和目标模型,就可以分析两者之间的差距。跨越这个差距的过程就是改进的过程。设计演进路线最大的问题就是怎么保证可行性。一般要把改进过程化整为零,迭代实施,并且还要兼顾日常的业务需。
第四步是迭代实施。最好基于敏捷软件开发方法,小步快跑地实施。在这个过程中,必然会对之前建立的目标领域模型进行反馈,不断改进。同时还要不断评估开发现状,保证不偏离目标。
在一个相对独立的模块往往称为“精益切片”。精益切片的难度、范围、风险要适中,最好在 3 个月内形成最小闭环。
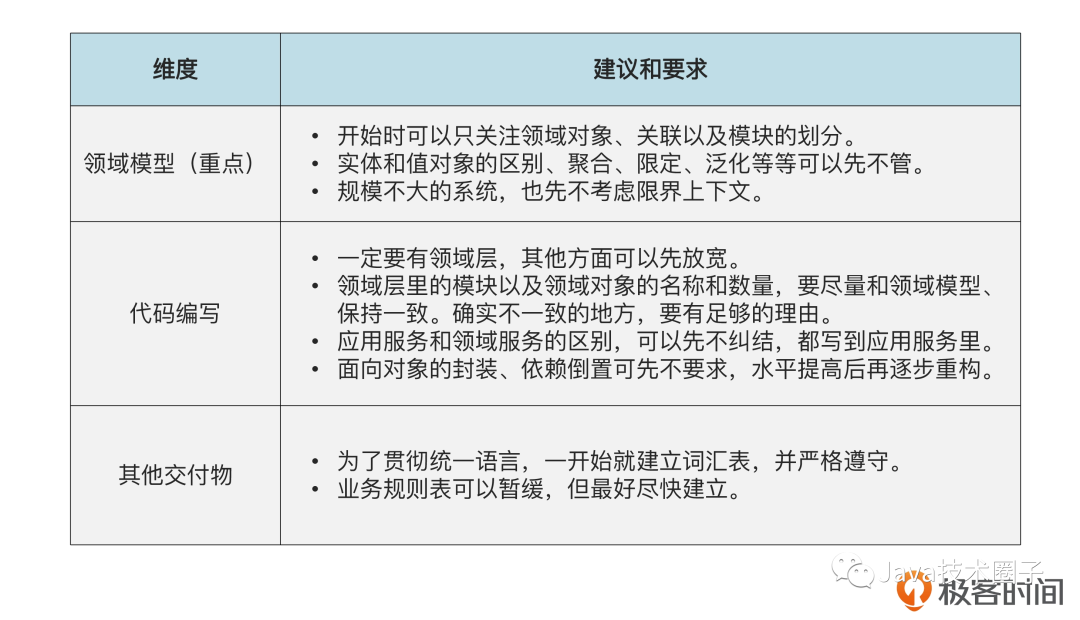
DDD 的知识点还是比较多的,而且其中有一些理解起来有一定难度。如果在推广过程中,一下子就让所有人掌握所有知识点,往往会造成很多误解,导致动作走形,影响推广效果。所以,一开始可以聚焦在 DDD 最核心的问题上,暂时省略其他要点,推行一个“低配版”的 DDD。等到大家掌握了基本技能,需要更深层次的运用时,再引入其他知识点。那么在开始的时候,哪些可以省略,哪些不能省略呢?我梳理了一张表,供你参考。
5
衡量团队DDD水平
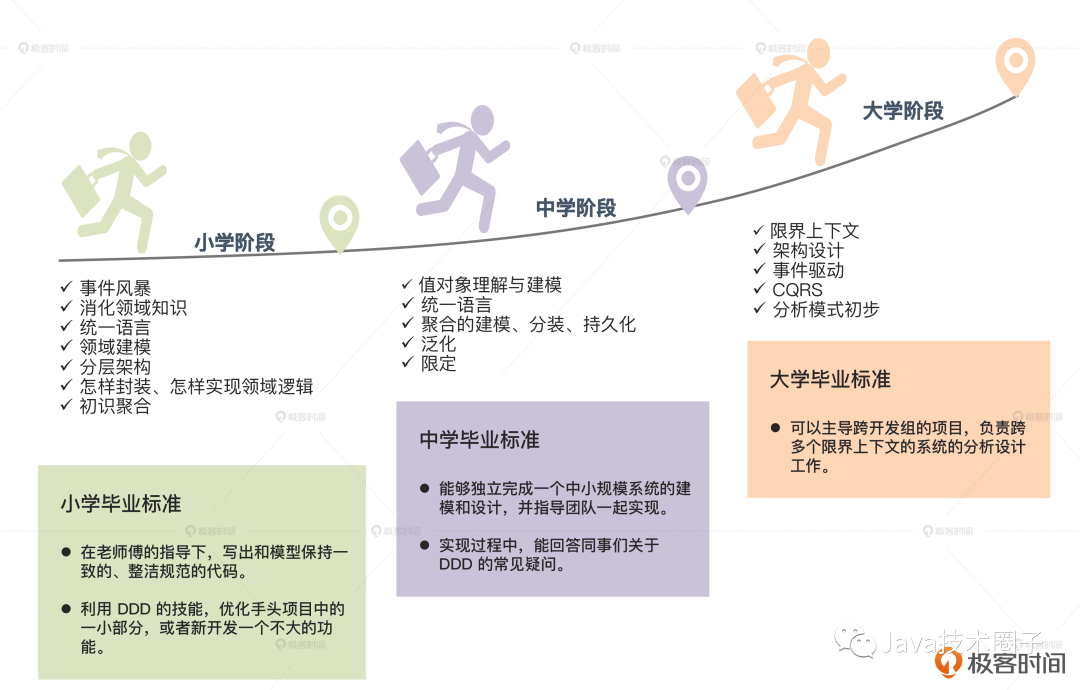
6
其他补充
其实对于DDD来说,是否使用充血模型,只是形式上的区别,关键在于一定要有识别出领域对象,和业务专家统一语言,这样就能无障碍沟通,然后慢慢把这个领域模型推广到整个系统,推广过程调用到外部服务,就会遇到适配层,过了适配层另一个应用就可以用到界限上下文,聚合根。这个过程中对项目代码重新分层,完成业务系统的改造,用更抽象的方法,解耦项目,拥抱变化的需求,沉淀统一的服务能力。主要讲了一些概念性的,落地可以看cola框架
CQRS
就是读服务与其他会产生数据变动的命令区分开。可以专门维护一个用于读的表,或者构筑一级二级缓存实现。