1.前言
本文档主要介绍如何实时迁移AWS DynamoDB数据到腾讯云TcaplusDB。TcaplusDB是腾讯推出的一款全托管NoSQL数据库服务,专为游戏设计,立志于打造面向全球的精品云存储产品,提供高性能、低成本、易扩展、稳定、安全的存储服务。TcaplusDB与DynamoDB类似,数据模型采用的是KV和文档两种类型,以表为组织管理单位。相对DynamoDB表的schema-free模式,TcaplusDB采用的是schema架构,即需要用户提前定义好表的schema,但与传统关系型表结构定义相比,TcaplusDB支持更丰富的数据结构,如支持多层嵌套,满足多样化的数据定义需求。
DynamoDB对于海外用户应用广泛,作为AWS全托管的一款NoSQL数据库服务,能够满足大部分业务场景需要。为适配海外用户使用腾讯云产品的需要,依托DynamoDB完善的数据流机制和Lambda机制,可以实现业务不停服、数据实时迁移至腾讯云TcaplusDB的目标。
本文假定用户对DynamoDB的数据结构、数据类型、运作模式比较了解。如若有疑问,可以查阅详尽的DynamoDB官方文档了解相关内容。
2.迁移说明
2.1 Schema转换
从DynamoDB迁移到TcaplusDB需要考虑shema的转换问题,分两个场景:
- 场景一: DynamoDB表的字段是随意插入的,不同记录的字段可能不同。
- 场景二: DynamoDB表的字段是固定的,所有记录的字段都是相同的。
针对上述两个场景, 设计了相应的方案来解决schema迁移转换问题:
- 方案一: 针对场景一字段不明确的情况下,设计一种万能表schema, 即把DynamoDB的整条记录作为一个字段,以BLOB(字节数组)形式存储,同时把DynamoDB中的主键提取出来作为TcaplusDB的主键字段。
- 方案二: 针对场景二字段明确的情况下,可以满足无缝迁移,TcaplusDB表可以设计成同DynamoDB表一致的数据结构。
2.2 迁移架构
本文所涉及的数据迁移架构如下:

DynamoDB数据实时写入,通过添加Lambda触发器来捕获DynamoDB的数据变更事件(增,删,改),Lambda函数捕获到事件后对其进行解析,判断事件类型并生成对应的TcaplusDB数据记录,然后发送到腾讯云的Ckafka消息队列组件,最后通过添加一个腾讯云SCF函数来捕获Ckafka写入的数据并进行解析写入TcaplusDB。
- Ckafka:是腾讯云基于开源Kafka打造的一款分布式、高吞吐、高可扩展性的全托管消息服务,能够无缝与腾讯云内外产品进行打通,支持公网域名数据安全传输,方便其它云平台产品数据流传送至Ckafka;同时对内支持作为SCF的触发源进行消息主动消费,满足内部业务的需要。
- SCF: 类似Lambda, 是腾讯云提供的一款安全稳定、稳定高效、低成本的无服务器函数计算平台,满足用户无需买服务器资源即可随时随地运行代码的需要。目前已同内部其它云产品打通,方便用户集成使用。
DynamoDB数据流机制可以实现数据变更的动态捕获,支持的变更操作如下:
操作类型 | DynamoDB | TcaplusDB | 说明 |
|---|---|---|---|
插入 | INSERT | 对应Tcaplus.AddRecord | 插入一条记录,如果记录存在则报错 |
更新 | MODIFY | 对应Tcaplus.SetRecord/Tcaplus.FieldSetRecord | 更新一条记录(非主键字段),如果记录不存在则插入,存在则更新记录, 如果更新是部分字段则在TcaplusDB中对应的是FieldSetRecord接口 |
删除 | REMOVE | 对应Tcaplus.DeleteRecord | 删除一条记录 |
2.3 迁移成本
从上面架构来看,涉及AWS的部分主要是DynamoDB和Lambda, 涉及腾讯云的部分主要是Ckafka、SCF和TcaplusDB。 具体计费方式可查看对应产品的官网文档。
2.4 数据模型
DynamoDB的数据模型与TcaplusDB存在一些差异,下面从三个维度展开介绍。
2.4.1 数据类型
Aamazon DynamoDB | TencentCloud TcaplusDB | 备注 |
|---|---|---|
Number | 取决于TcaplusDB的整形取值范围,如uint8-64,int8-64, float,double | |
String | string | |
Boolean | bool | |
Null | 无显示的null值 | 如果值未传入,TcaplusDB会隐式把字段值赋予相应数据类型的默认值,如0,'' |
Binary | bytes | |
Sets | array | TcaplusDB 有repeated关键字表示数组类型,数组元素类型可以是字符串、数值、字节、结构体类型 |
Map | struct | 如果Map结构属性一致,直接定义成TcaplusDB的struct |
2.4.2 主键
DynamoDB主键由两部分组成: partition key和sort key, 前者用于分区,后者用于排序,支持只有partition key也支持两者的组合。DynamoDB主键可以无缝对应TcaplusDB的主键,在TcaplusDB中,支持最多四个字段作为联合主键,同时以主键的第一字段作为分区键。
2.4.3 索引
DynamoDB的索引结构和TcaplusDB的有所区别,本文测试的TcaplusDB暂时不同步DynamoDB的全局索引和本地索引数据。后续待TcaplusDB分布式索引功能上线后再补充这一块的内容。
2.4.4 示例数据表
表信息项 | DynamoDB示例表 | TcaplusDB示例表 |
|---|---|---|
表名 | migrate_test | migrate_test |
主键 | "player_id":String,"player_time":Number | "player_id":string, "player_time":int64 |
Key类型 | "player_id": hash_key, "player_time": sort_key | n/a |
非主键字段 | "player_email":String, "game_server_id": Number, "is_online": Boolean, "pay": Map, "pay.pay_id": Number, "pay.amount":Number, "pay.method":Number | "player_email":string, "game_server_id": int32, "is_online": bool, "pay": struct, "pay.pay_id": int64, "pay.amount":uint64, "pay.method":int64 |
3.迁移准备
3.1 DynamoDB环境准备
假定用户已经有AWS账户并设置好Credentials,如果未设置请参考官方文档说明。
3.1.1 表创建
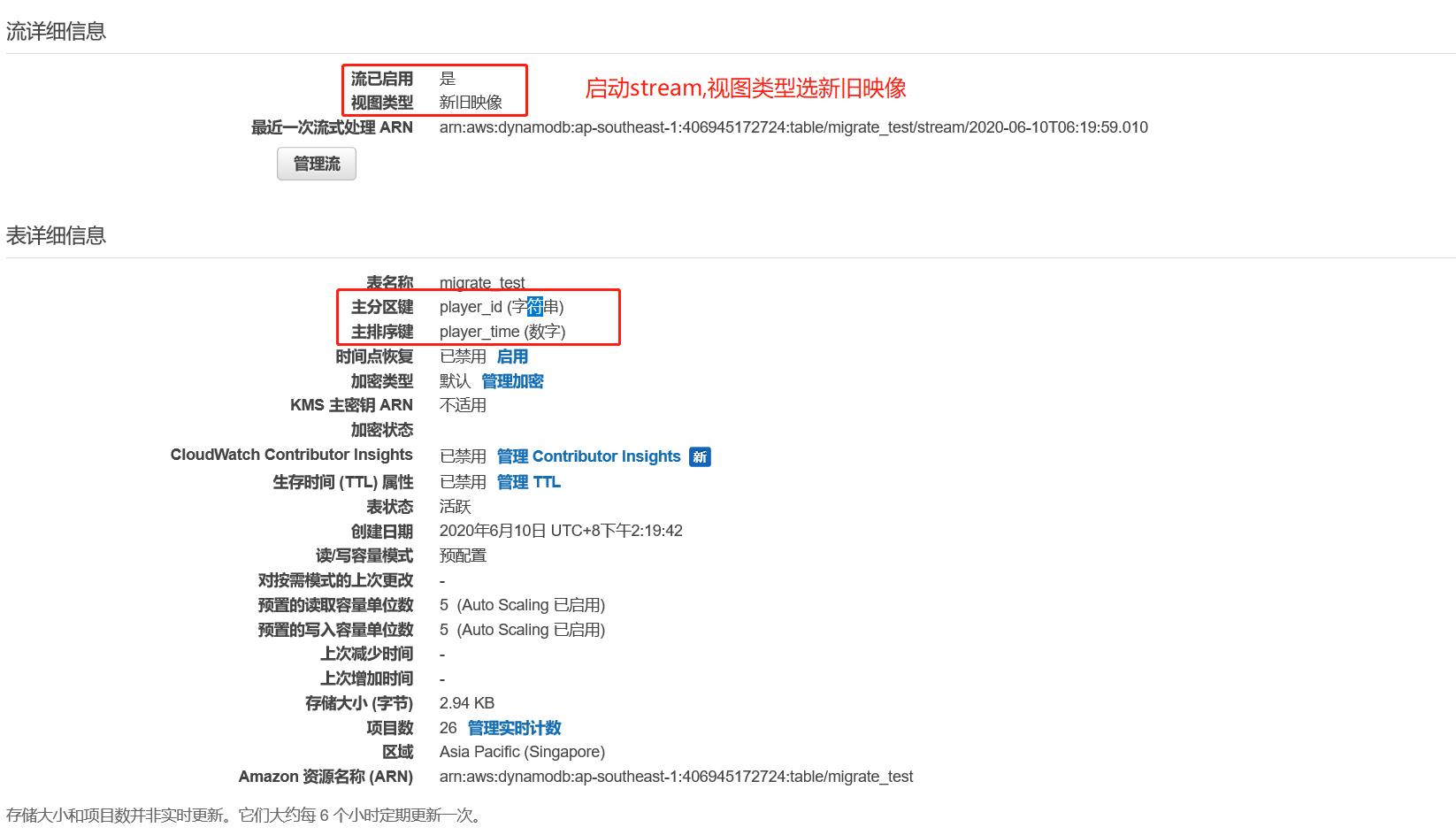
在DynamoDB控制台选定一个地域,如新加坡创建示例表migrate_test, 创建好后启动stream流,具体如下截图所示:
3.1.2 触发器创建
触发器创建的前提是需要提前创建Lambda函数,同时还涉及Lambda权限的配置,关于Lambda权限配置涉及AWS角色策略的创建。具体涉及步骤如下:
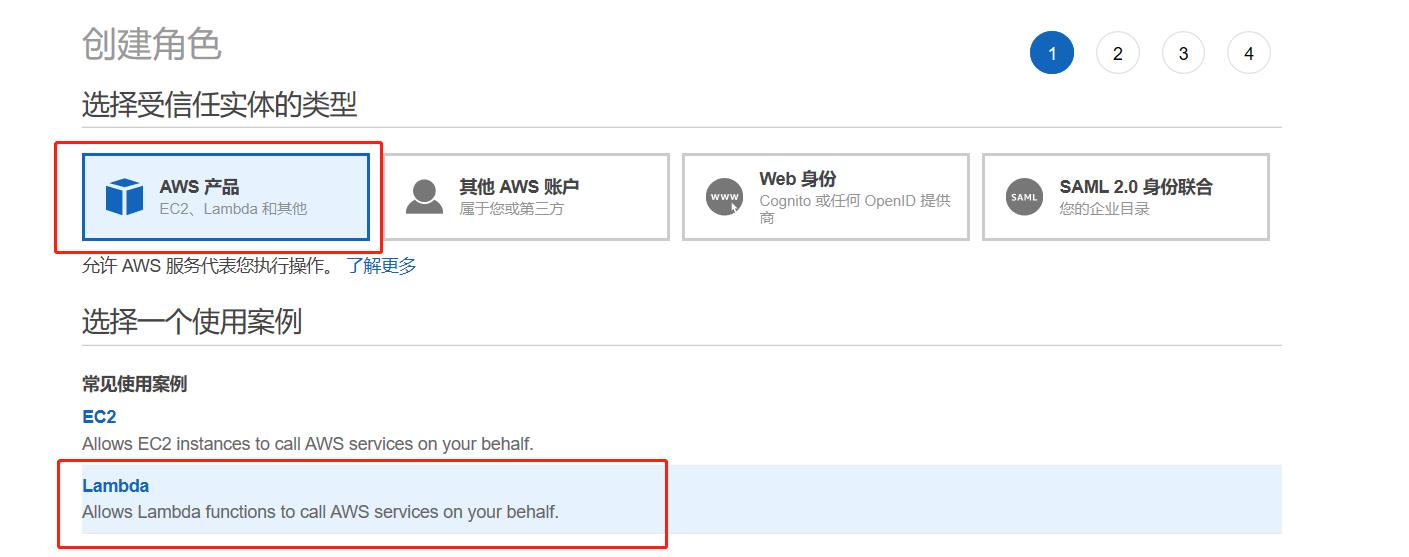
- Step1, 角色创建 进入角色控制台, 角色创建具体可参考官方文档, 具体创建示例如下:
选择角色所属产品,这里选择Lambda产品,如下所示:
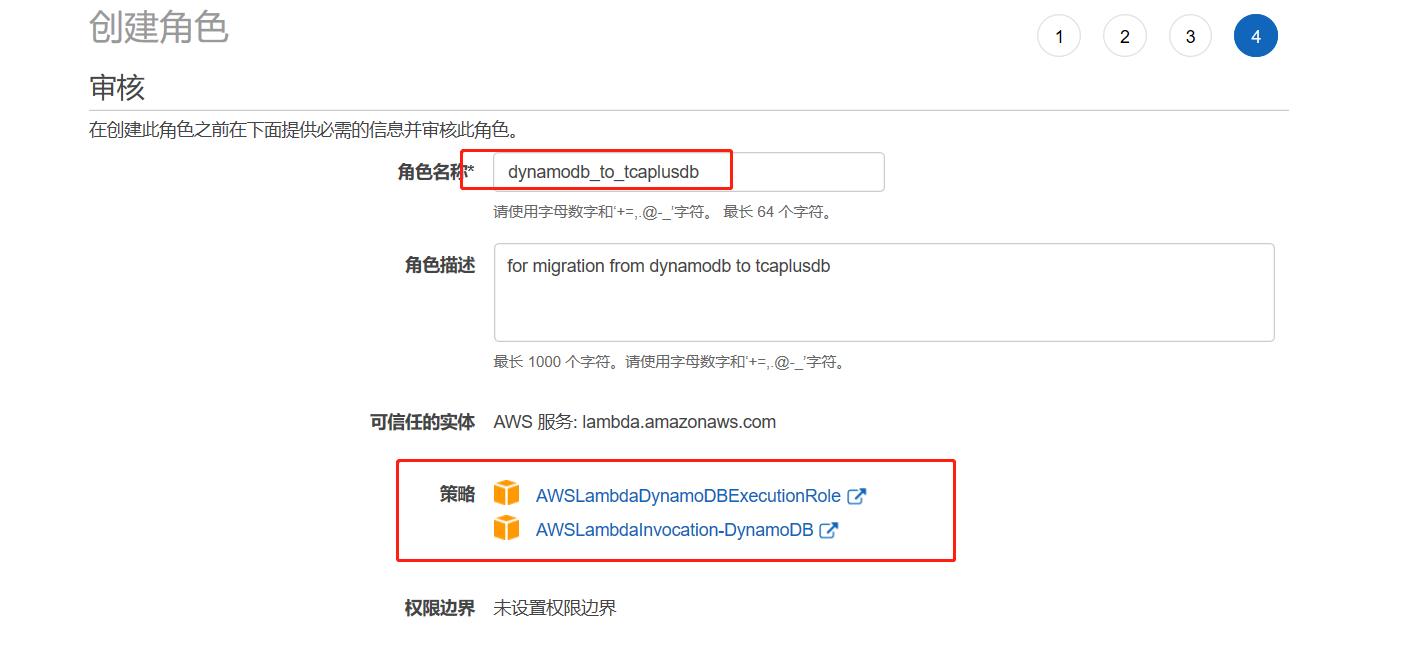
设置角色策略,关于Lambda需要的策略涉及两个:AWSLambdaDynamoDBExecutionRole和AWSLambdaInvocation-DynamoDB。具体如下:
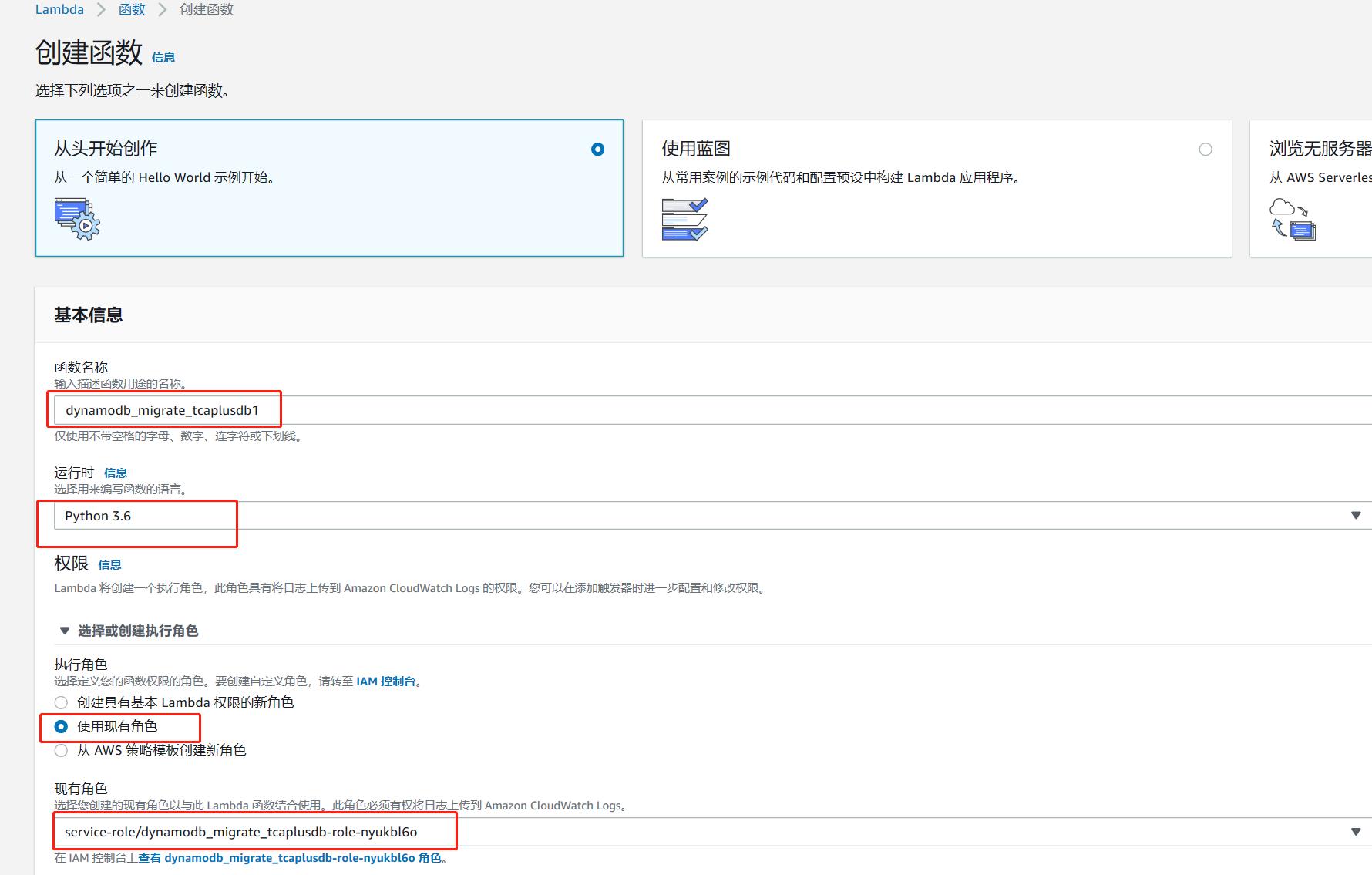
- Step2, Lambda函数创建 进入Lambda控制台创建一个Lambda函数,创建方法参考官方文档,具体创建示例如下:
创建一个基于Python3.6语言环境的函数,同时指定上一步为Lambda创建的角色,如下所示:
同时配置Lambda函数的环境变量,用于连接Ckafka需要,如下所示:
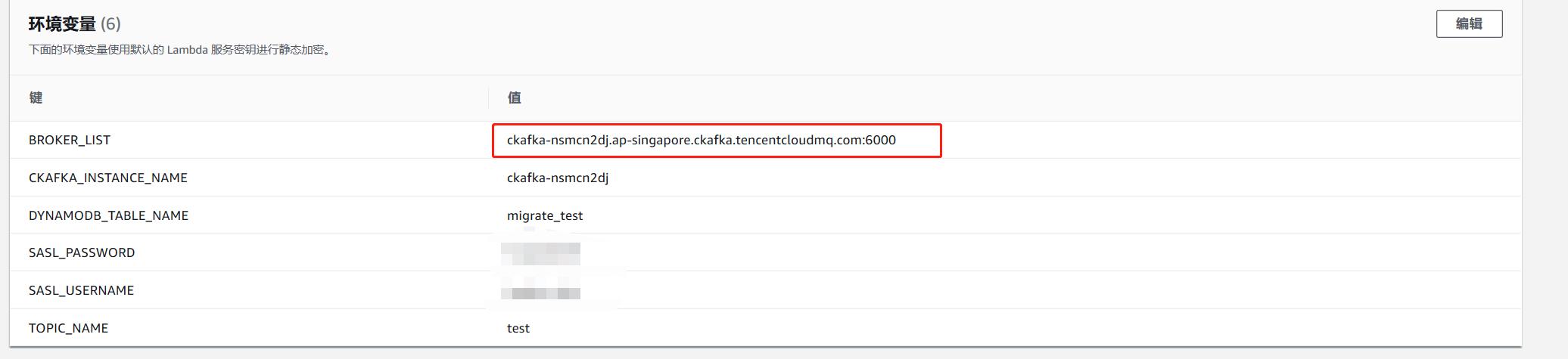
BROKER_LIST: 连接Ckafka集群的公网域名:端口
CKAFKA_INSTANCE_NAME: Ckafka实例ID
DYNAMODB_TABLE_NAME: DynamoDB表名
SASL_PASSWORD: SASL安全认证密码
SASL_USER: SASL安全认证用户
TOPIC_NAME: Ckafka topic名称- Step3, DynamoDB触发器创建 创建好Lambda函数后,在DynamoDB表控制台可以开始创建触发器。选择目标表,
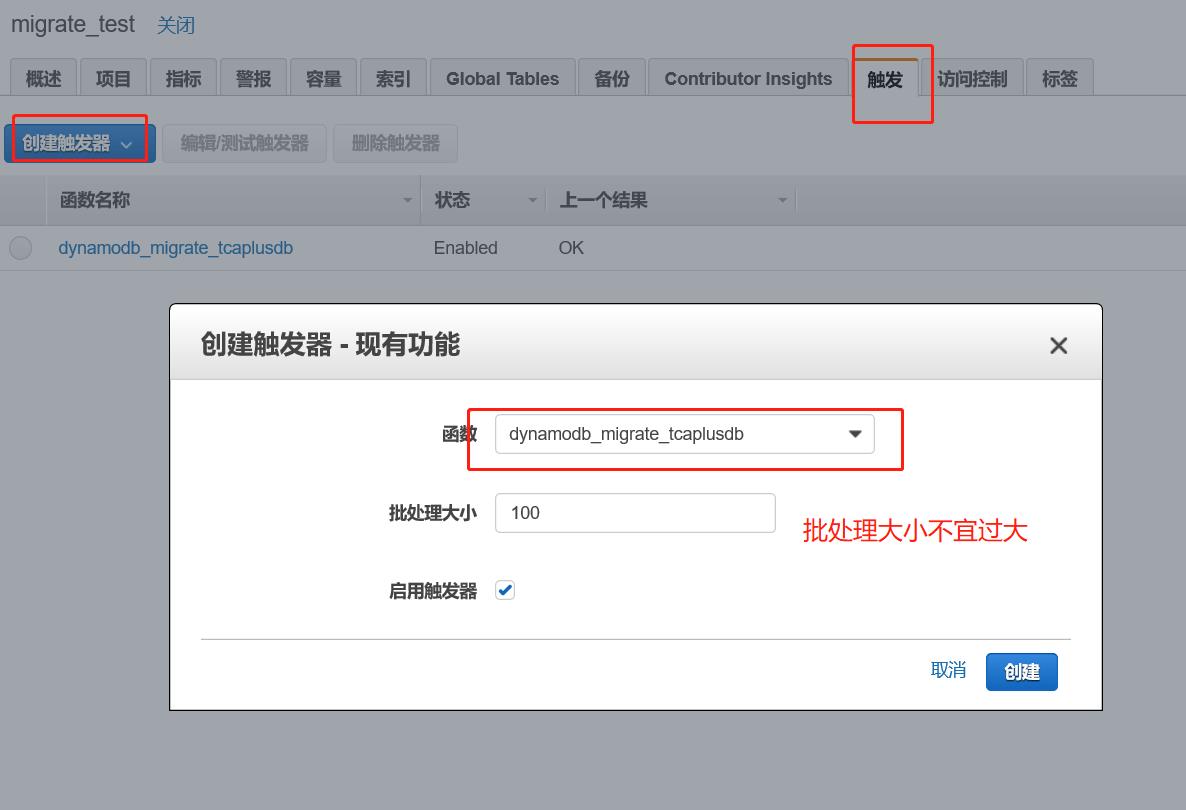
在创建触发器页面可以自动识别上述所创建的Lambda函数,同时设置批处理大小(注意:这个值设置不宜过大,和网络传输效率有关,过大容易丢包),并启动触发器。
3.2 TcaplusDB环境准备
假定用户已经有腾讯云账户并设置好Credentials, 如果未设置请参考官方文档说明。
3.2.1 TcaplusDB表创建
进入TcaplusDB控制台, 选择地域新加坡,和DynamoDB保持一致,避免数据跨地域同步。创建表过程请参考官方文档说明, 创建表之前需要先创建TcaplusDB集群和表格组。
- 表集群
集群协议选择
proto(Google Protobuf)。同时VPC网络选择Default-VPC, 子网选择Default-Subnet,如下所示:
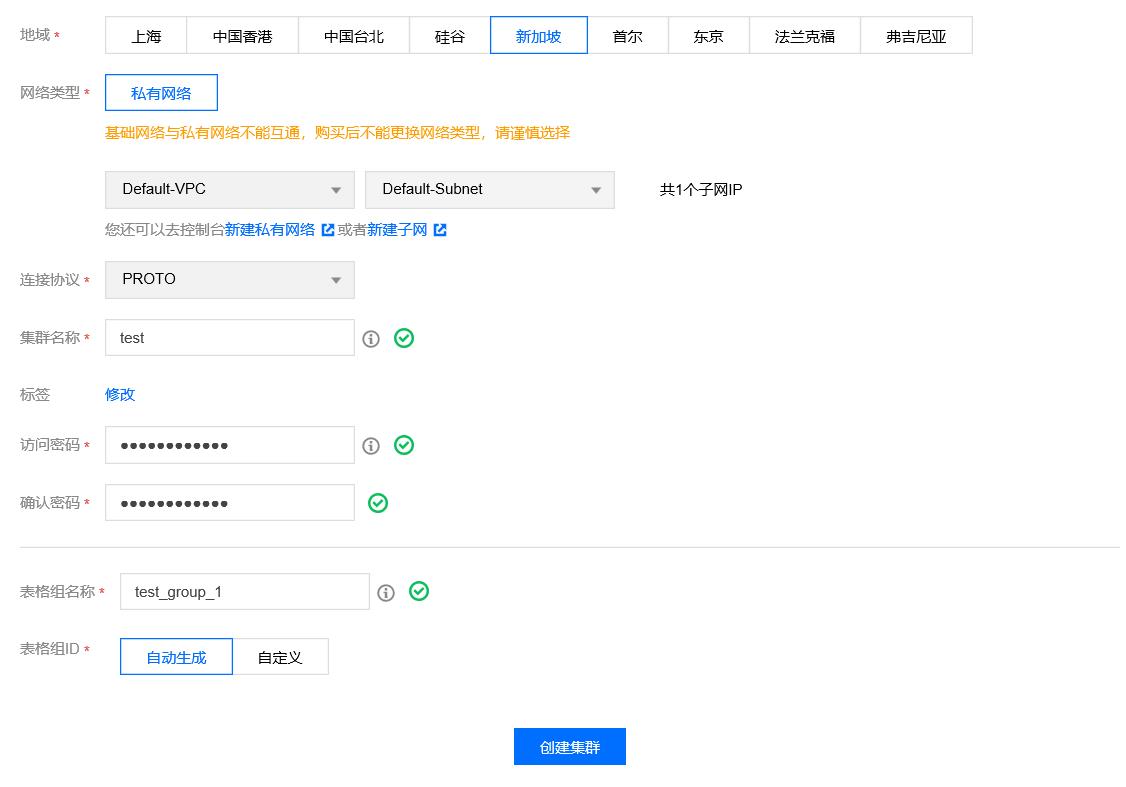
创建好后如下所示:

- 表创建 选择上述创建的集群和表格组,上传示例表schema文件,表定义文件名migrate_test.proto, 如下所示
syntax = "proto3"; // Specify the version of the protocol buffers languageimport "tcaplusservice.optionv1.proto"; // Use the public definitions of TcaplusDB by importing them.
message migrate_test { // Define a TcaplusDB table with message
// Specify the primary keys with the option tcaplusservice.tcaplus_primary_key // The primary key of a TcaplusDB table has a limit of 4 fields option(tcaplusservice.tcaplus_primary_key) = "player_id, player_time"; // Specify the primary key indexes with the option tcaplusservice.tcaplus_index option(tcaplusservice.tcaplus_index) = "index_1(player_id)"; // Value Types supported by TcaplusDB // int32, int64, uint32, uint64, sint32, sint64, bool, fixed64, sfixed64, double, fixed32, sfixed32, float, string, bytes // Nested Types Message // primary key fields string player_id = 1; int64 player_time = 2; string player_email = 3; // Ordinary fields int32 game_server_id = 4; bool is_online = 5; payment pay =6;}
message payment {
int64 pay_id = 1; uint64 amount = 2; int64 method = 3;
}
创建表过程如下:

3.3 Ckafka环境准备
进入Ckafka控制台, 在新加坡地域创建一个入门型实例即可,其它都选默认,创建实例如下所示:

创建好后,需要操作以下几步以满足公网访问需要:
- 添加路由策略
在集群实例基本信息页面,在接入方式栏选择添加路由策略,路由类型选择公网域名接入, 接入方式选择SASL_PLAINTEXT。具体如下:

- 添加用户
在实例用户管理页面添加一个连接用户,如tcaplus_test, 如下所示:

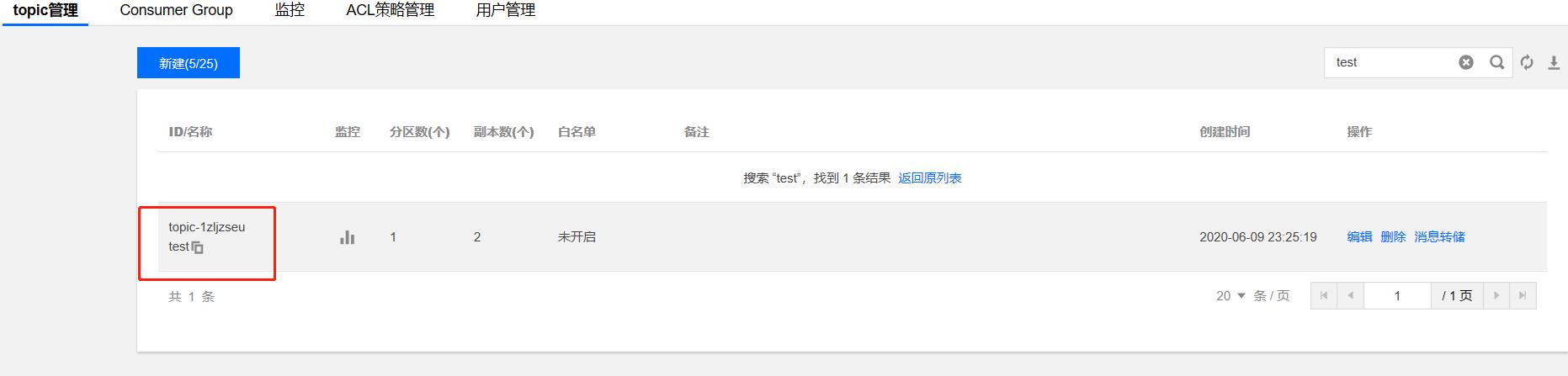
- 添加Topic
在实例topic管理页面增加一个topic, 如test, 如下所示:
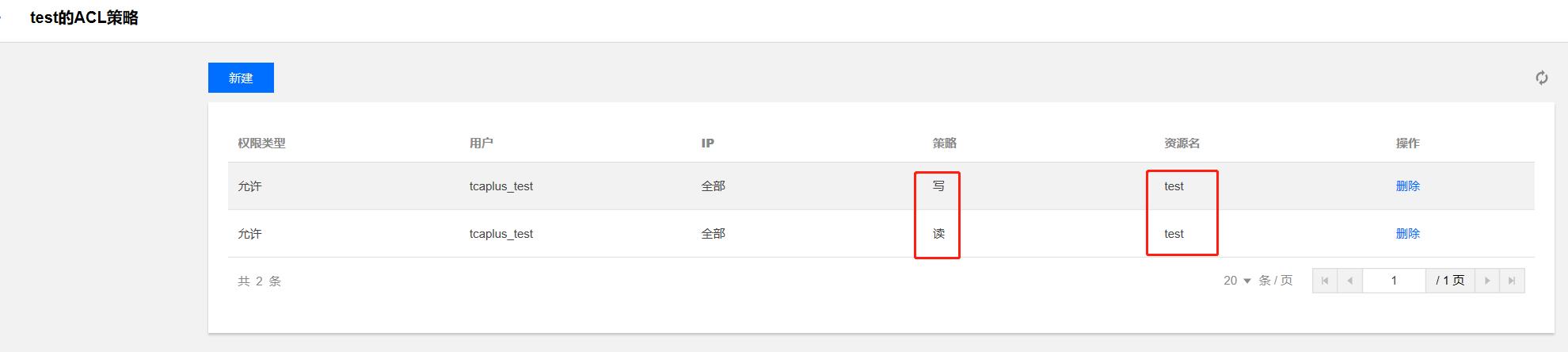
- 添加ACL策略
在实例ACL策略页面增加一个针对topic的ACL访问策略控制,控制外部用户和IP访问Ckafka对应topic的读写权限,具体如下所示:
3.4 SCF环境准备
进入SCF控制台, 在新加坡地域创建一个基于Python3.6的SCF函数。如下所示:
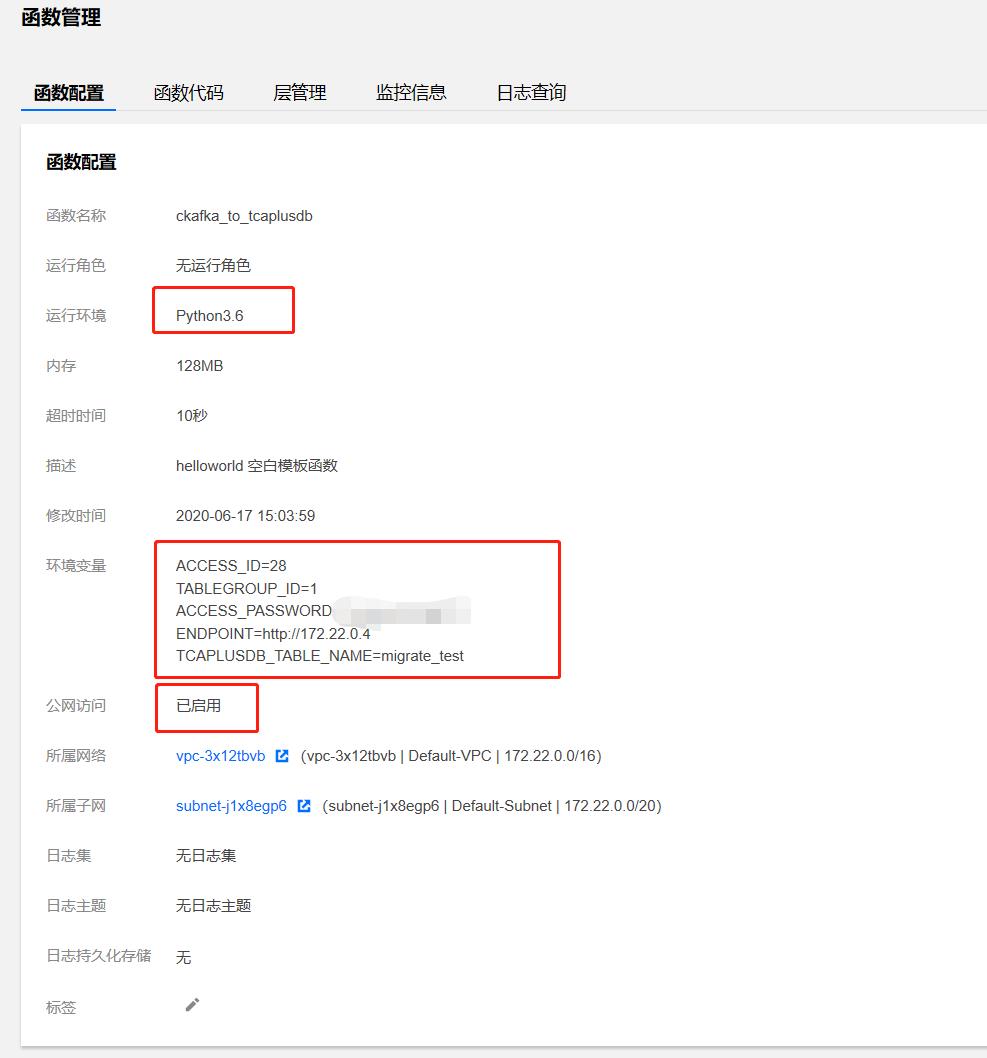
- 环境变量配置
SCF需要访问TcaplusDB,为避免代码硬编码TcaplusDB信息,这里把TcaplusDB表的连接信息设置成SCF的环境变量,方便动态修改,具体环境变量信息如上截图所示,包括几个方面:
+ ACCESS_ID: TcaplusDB表所在集群的接入ID
+ TABLEGROUP_ID: TcaplusDB表所在集群的表格组ID
+ ACCESS_PASSWORD: TcaplusDB表所在集群的访问密码
+ ENDPOINT:TcaplusDB表连接地址
+ TCAPLUSDB_TABLE_NAME:TcaplusDB表名
上述连接信息(ACCESS_ID, ACCESS_PASSWORD,ENDPOINT)获取请参考官方文档, 其它信息(TABLEGROUP_ID, TCAPLUSDB_TABLE_NAME)可参考官方文档。 - VPC私有网络设置
SCF与TcaplusDB网络需要在同个VPC,这里选择Default-VPC, 子网选择Default-Subnet即可。 - 触发器
目前SCF已经同Ckafka打通,可以实时捕获Ckafka的消息写入事件。在SCF的触发管理页面新增加一个关于Ckafka的触发器,如下所示:
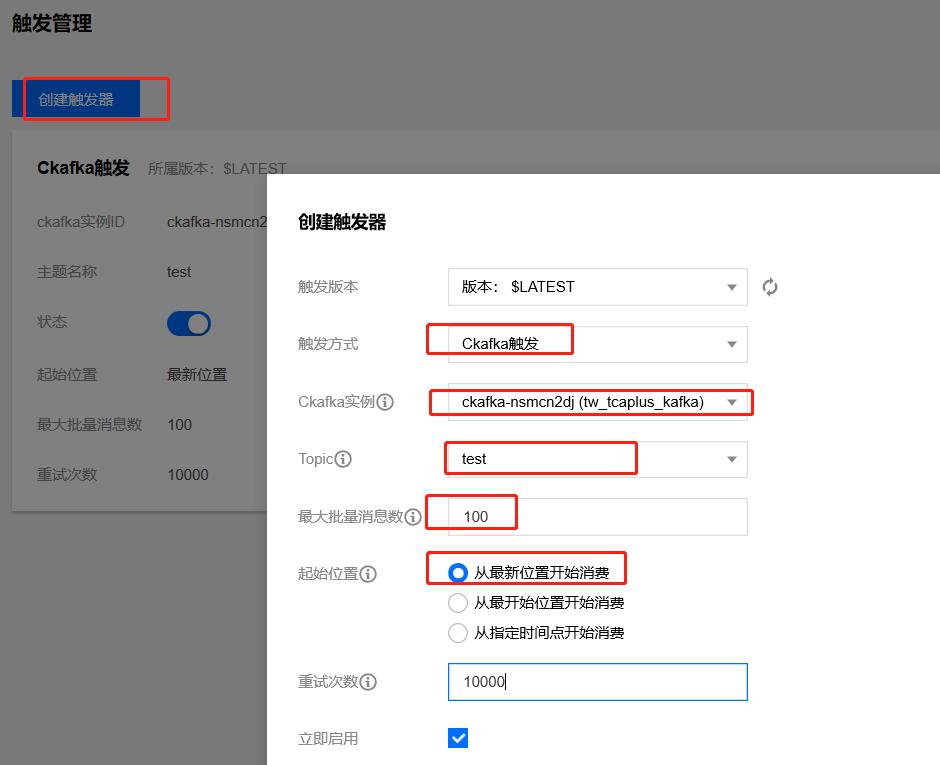
SCF会自动识别同地域所创建的Ckafka实例和实例对应的topic,直接选择即可。
4. 代码说明
这里的代码指Lambda和SCF的代码,为保证统一,用的同一个代码包(dynamodb_migrate_tcaplusdb.zip),代码目录结构如下:
.
├── kafka
├── kafka_python-2.0.1.dist-info
├── config.py
├── config.pyc
├── dynamodb_migrate_tcaplusdb.zip
├── index.py
├── lambda_function.py
├── setup.cfg
└── tcaplusdb
├── init.py
├── http_client.py
├── log.py
├── tcaplusdb_rest_client.py
└── tcaplusdb_rest_exception.py整体代码下载地址: dynamodb_migrate_tcaplusdb.zip。
4.1 依赖说明
4.1.1 kafka依赖
Lambda为将数据发送至Ckafka,需要依赖kafka-python的包,直接用如下命令安装:
mkdir dynamodb-tcaplus-migration-realtime
cd dynamodb-tcaplus-migration-realtime
pip install kafka-python==1.0.0 -t .4.1.2 TcaplusDB依赖
TcaplusDB连接需要依赖Python RESTful SDK API。 参考代码包中的tcaplusdb目录。
4.1.3 配置依赖
连接配置依赖,需要配置Lambda和SCF的环境变量信息,参考代码包中的配置文件config.py,具体内容如下:
#AWS Lambda Function Properties
#替换已申请的Ckafka接入的公网域名
BROKER_LIST="ckafka-instance.ap-use.ckafka.tencentcloudmq.com:6000"
#替换Ckafka Topic名称
TOPIC_NAME="test"
#替换Ckafka实例名
CKAFKA_INSTANCE_NAME="ckafka-instance"
#替换用户名
SASL_USERNAME="xxx"
#替换用户密码
SASL_PASSWORD="xxx"#Dynamodb主键字段
DYNAMODB_PRIMARY_KEY = [{"NAME":"player_id","TYPE": "S"},{"NAME":"player_time","TYPE": "N"}]
#Dynamodb表名
DYNAMODB_TABLE_NAME="migrate_test"#TencentCloud SCF Properties
#TcaplusDB集群连接地址,IPV4
ENDPOINT ="http://xxx.xxx.xxx.xxx"#TcaplusDB集群接入ID
ACCESS_ID=28#TcaplusDB集群连接密码
ACCESS_PASSWORD="test"
#TcaplusDB表所在表格组ID
TABLEGROUP_ID=1
#TcaplusDB表名
TCAPLUSDB_TABLE_NAME="migrate_test"
4.1 Lambda代码说明
Lambda代码主要处理捕获DynamoDB数据变更事件,针对不同的事件类型,封装数据成TcaplusDB的记录格式,并写入Ckafka。参考代码包中的lambda_function.py。
4.2 SCF代码说明
主入口为index.main_handle函数,处理从Ckafka消费数据并解析保存到TcaplusDB。参考代码包中的index.py。
5. 迁移演示
在上述工作都准备OK后,可以开始在DynamoDB插入数据进行演示。这里使用boto3工具进行数据操作,下面只模拟插入数据操作,其他类似,大家可自行在DynamoDB去更新和删除数据,看后端的数据流情况。
5.1 插入数据演示
代码如下:
import boto3
table = boto3.resource('dynamodb').Table('migrate_test')
playerId="128"
playerTime=1591372738
response = table.put_item(
Item={
'player_id': playerId,
'player_time': playerTime,
'pay': {
'amount': 100,
'pay_id': 102,
'method': 3
},
'player_email':'wql@123.com',
'is_online': True,
'game_server_id': 112
}
)
print(response)
执行上述代码后,会在migrate_test插入一条数据,可以从DynamoDB控制台查看数据是否插入成功,如果插入有问题,请检查AWS Credentials设置、表是否创建OK。
然后观察Lambda函数捕获情况,Lambda目前已同CloudWatch打通,即所捕获的所有事件都会有CloudWatch日志体现。具体如下所示:
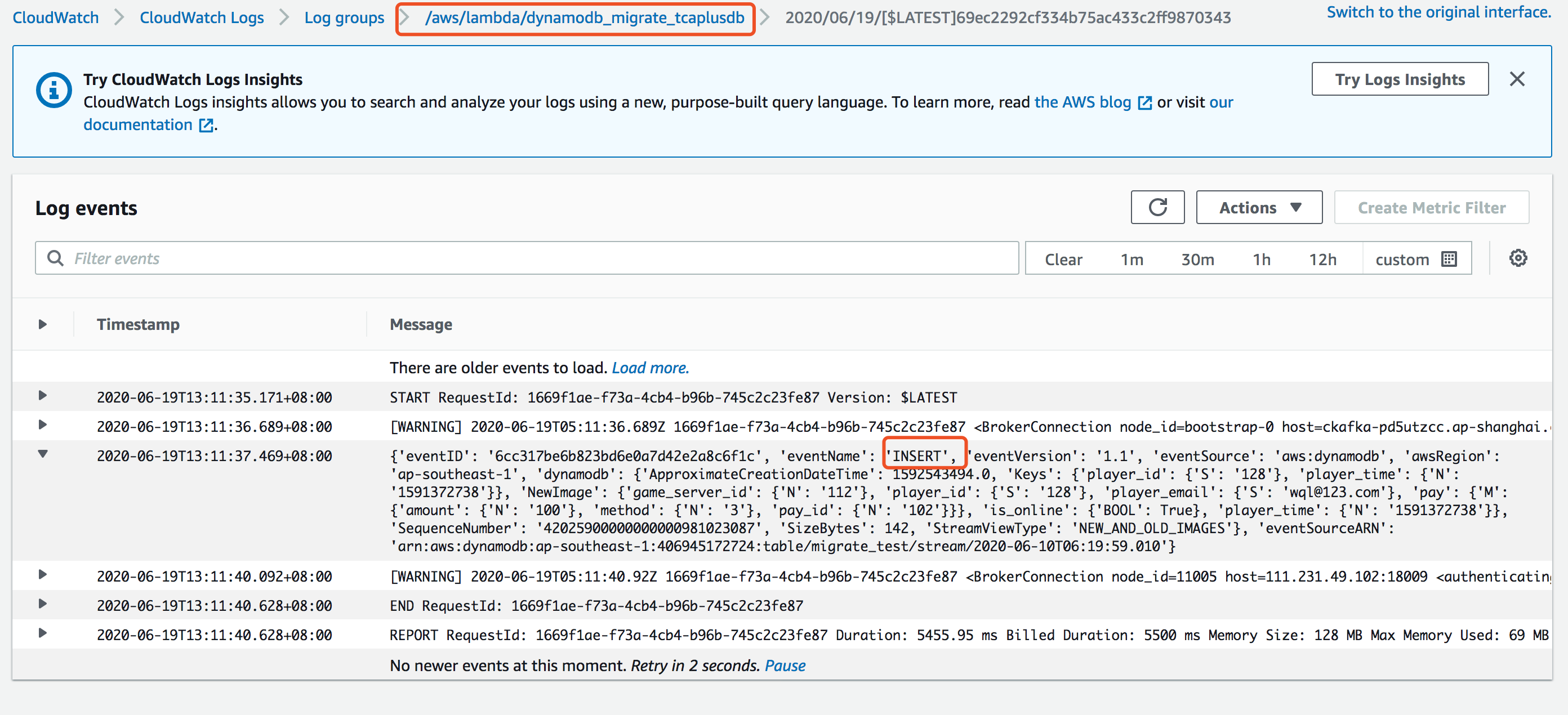
从上述图,我们可以看到,捕获了一个INSERT事件,事件中的Record数据和上述我们插入的保持一致。接下来,看下Ckafka的接收情况:
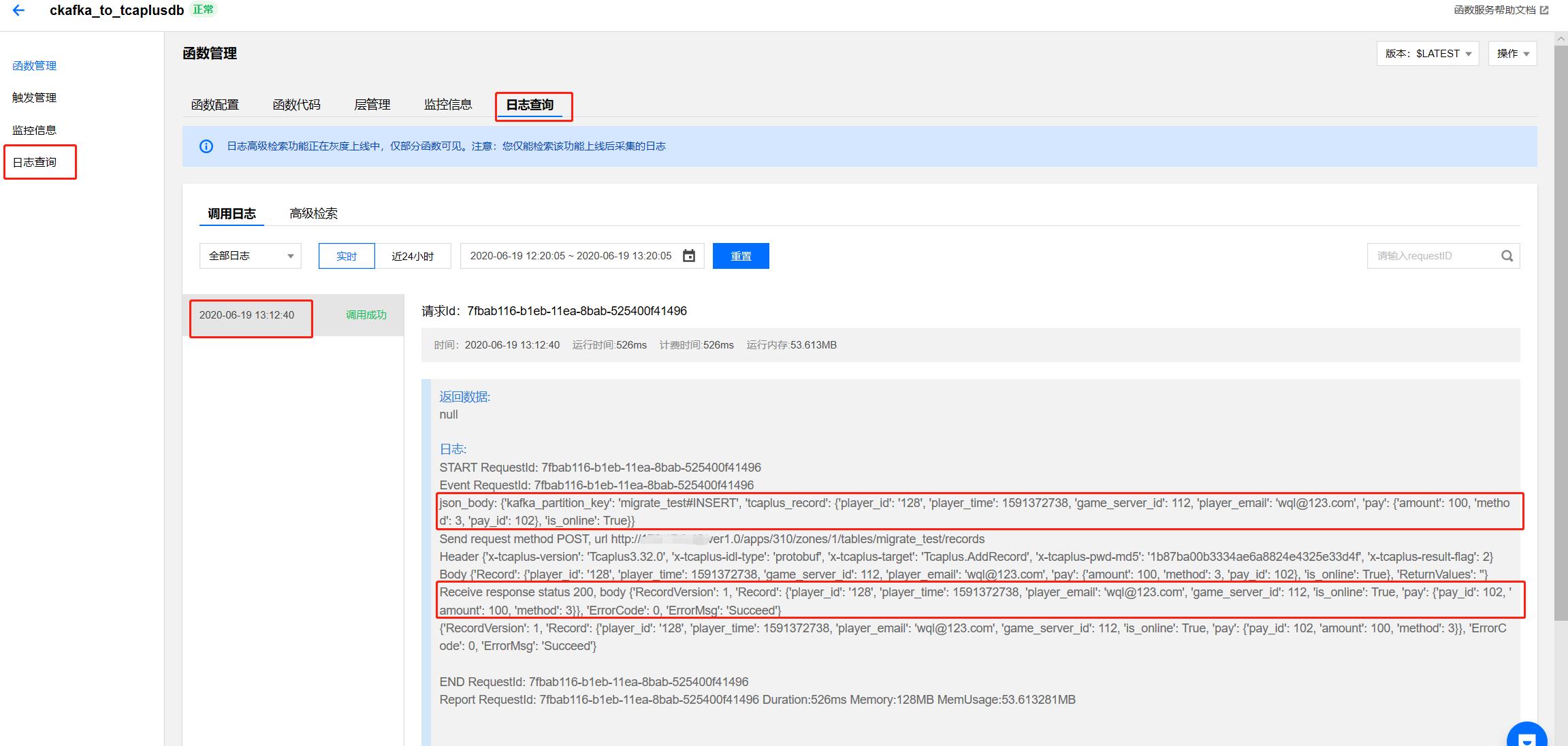
从上图可以看出,Ckafka也收到了来自Lambda函数所发送的数据,并发送一个Post类型的Http RESTful请求给TcaplusDB,插入一条数据并返回插入成功Response。为检查TcaplusDB数据是否有真的插入,这里用到一个tcaplus_client工具,下载地址: tcaplus_client。tcaplus_client工具使用说明请参考文档: Tcaplus_client使用说明.pdf 。注意:工具需要与TcaplusDB表所在的VPC保持一致,即用户需要申请一台CVM机器来执行tcaplus_client命令,CVM VPC需要与TcaplusDB集群保持一致。具体查看数据命令如下:
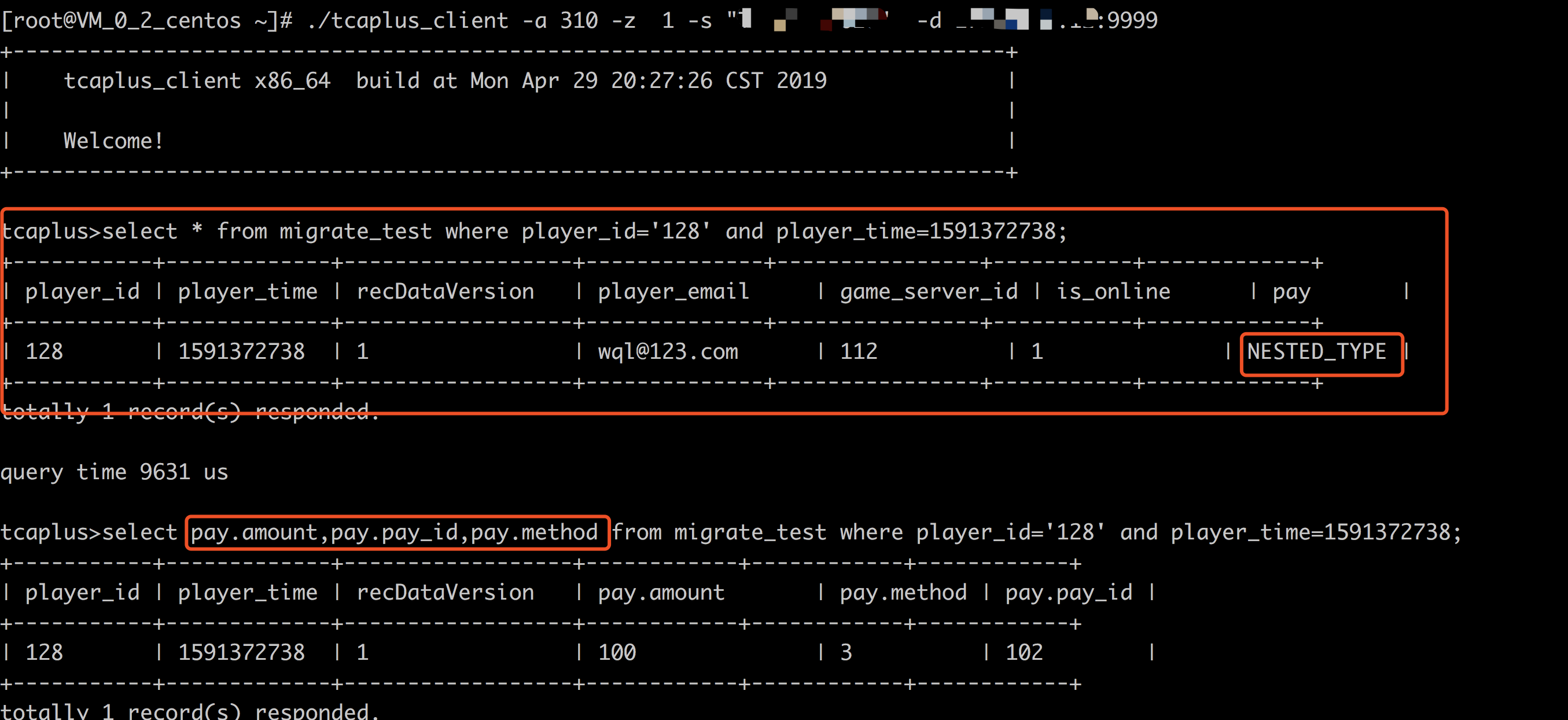
从上面截图可以看出,TcaplusDB也实时写入了数据,说明整个流程跑通。
6. 总结
本文介绍了如何实时增量迁移DynamoDB数据到TcaplusDB,下一阶段计划介绍如何全量离线迁移DynamoDB数据到TcaplusDB。对于TcaplusDB来说,未来也会走社区路线,把腾讯NoSQL在游戏行业的应用经验赋能给业界。如若有任何疑问,欢迎咨询: ballenwen@tencent.com