TCP/IP协议
OSI七层参考模型分层包括物理层、数据链路层、网络层、传输层、会话层、表示层、应用层。
分层 | 关键字 | 设备 | 功能 |
|---|---|---|---|
应用层 | 计算机、上层数据、HTTP超文本传输协议、FTP文件传输协议、TFTP普通文本传送协议、SMTP邮件传输协议、SNMP网络管理协议、DNS域名系统、Finger、Whois域名查询服务、Gopher信息检索协议、Telent远程终端协议、IRC因特网中继会话、NNTP网络新闻传输协议 | 计算机 | 网络服务与最终用户的一个接口 |
表示层 | 数据的表示、安全、压缩,编码和解码、压缩解压缩、加密解密 | ||
会话层 | 建立、管理、中止会话 | ||
传输层 | 防火墙、TCP传输控制协议、UDP用户数据报协议、端口、数据段、差错校验 | 防火墙 | 定义传输数据的协议端口号,以及流控和差错校验 |
网络层 | 路由器、IP地址、数据包、ICMP网间控制报文协议、IGMP因特网组管理协议、IP互联网协议、RIP路由信息协议、ARP地址解析协议、RARP反向地址解析协议 | 路由器 | 进行逻辑地址寻址,实现不通网络之间的路径选择 |
数据链路层 | 交换机、以太网、MAC地址、差错校验 | 交换机 | 建立逻辑连接、进行硬件地址寻址、差错校验等功能 |
物理层 | 网卡、比特流 | 网卡、网线、光纤、IC卡、ID卡 | 建立、维护、断开物理连接 |
注意:
ARP协议在TCP/IP模型中属于IP层(网络层),在OSI模型中属于数据链路层。ARP协议即地址解析协议,是根据IP地址获取物理地址的一个TCP/IP协议。它可以解决同一个局域网内主机或路由器的IP地址和MAC地址的映射问题。
分层的优点:
1.促进标准化工作,允许各个供应商进行开发。
2.各层间相互独立,把网络操作分为复杂性单元。
3.灵活性好,某一层变化不会影响到别层,设计者可专心设计和开发模块功能。
4.各层间通过一个接口在相邻上下通信。
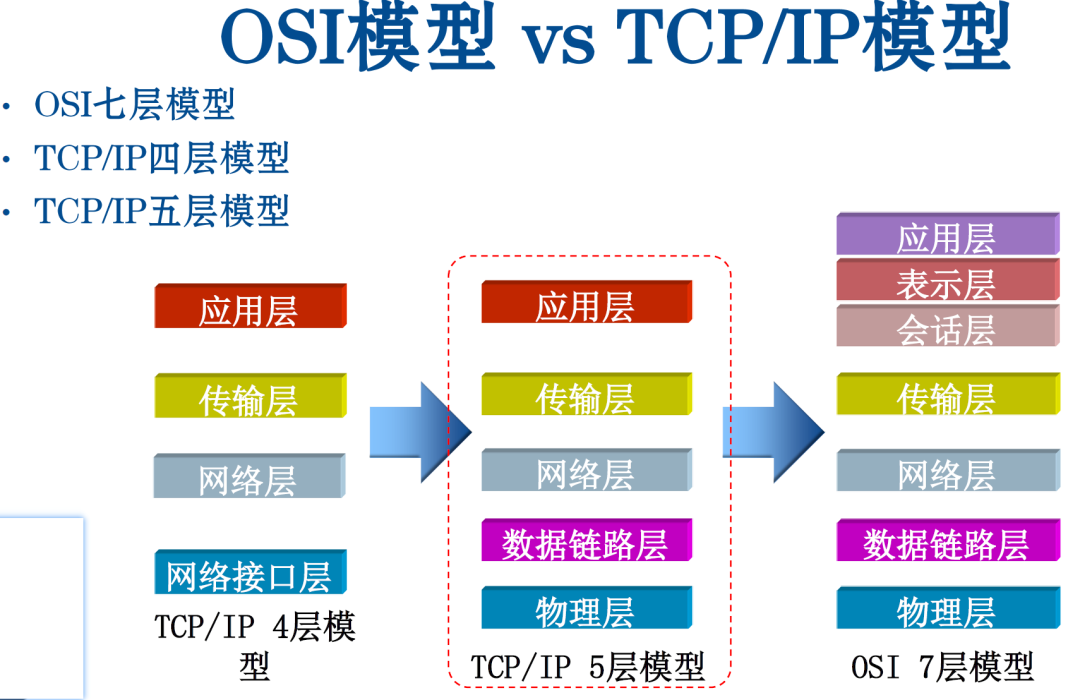
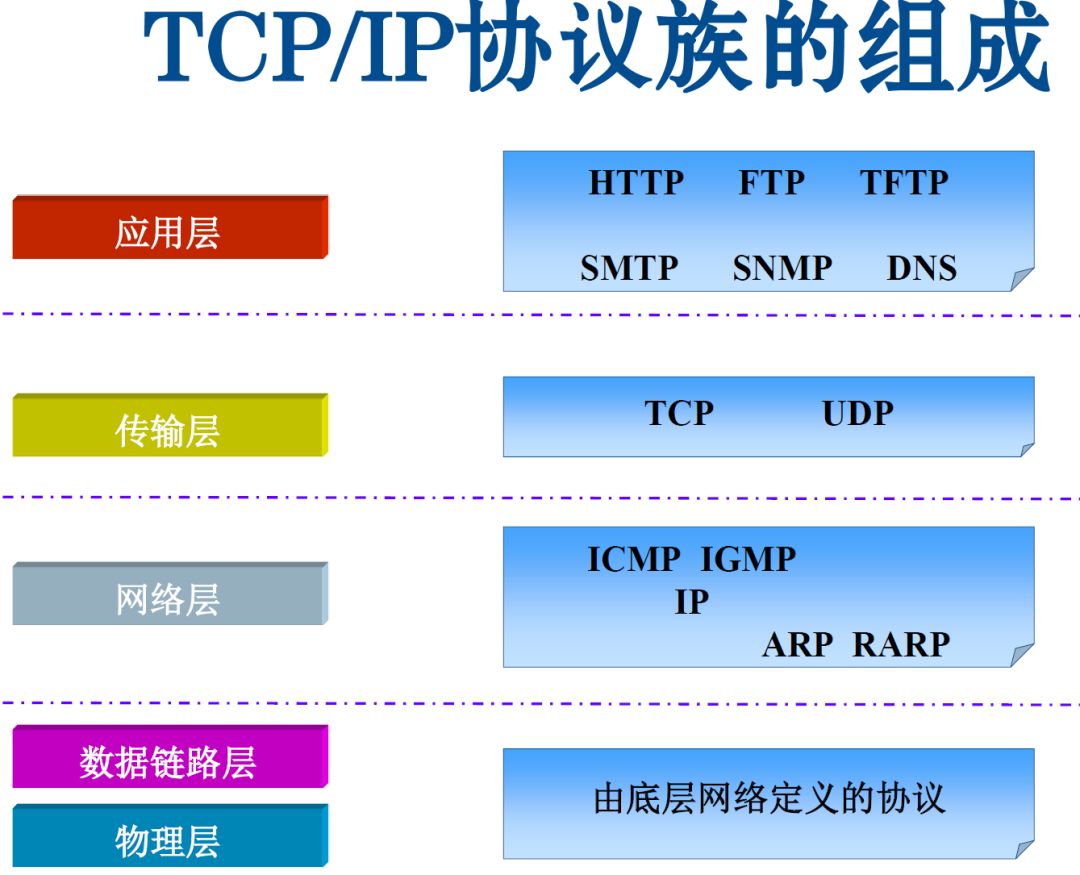
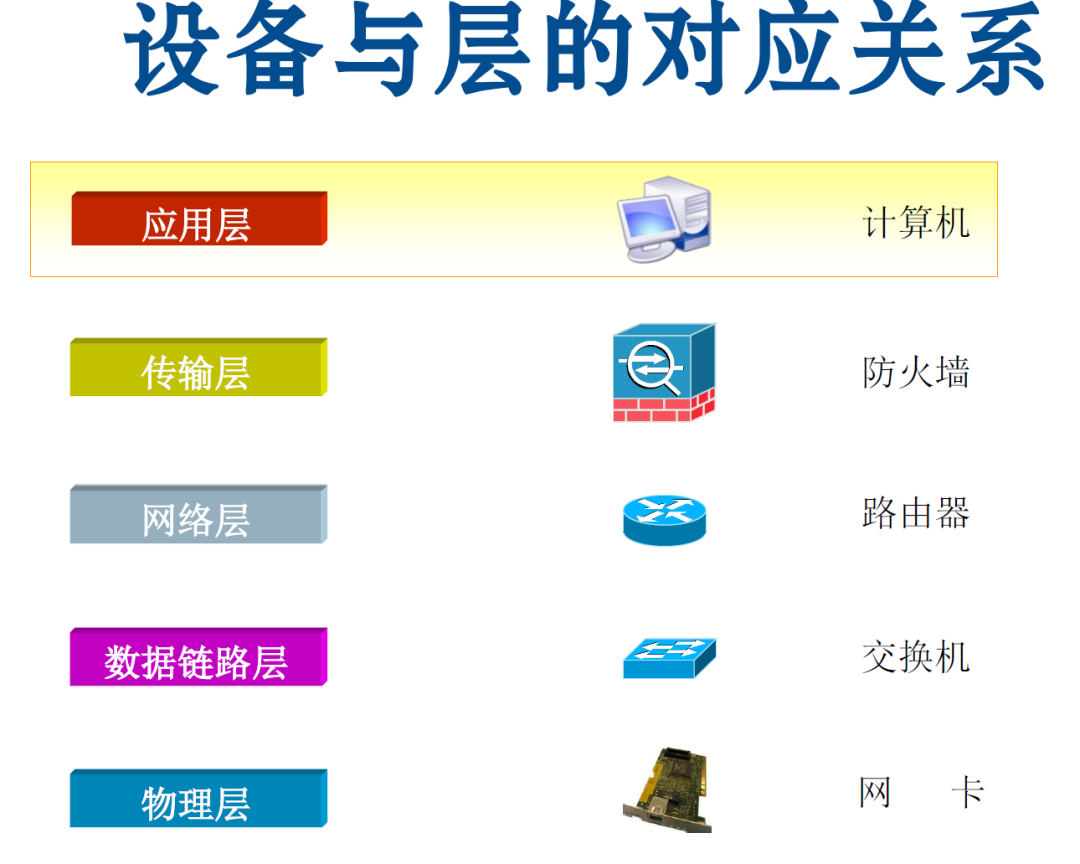
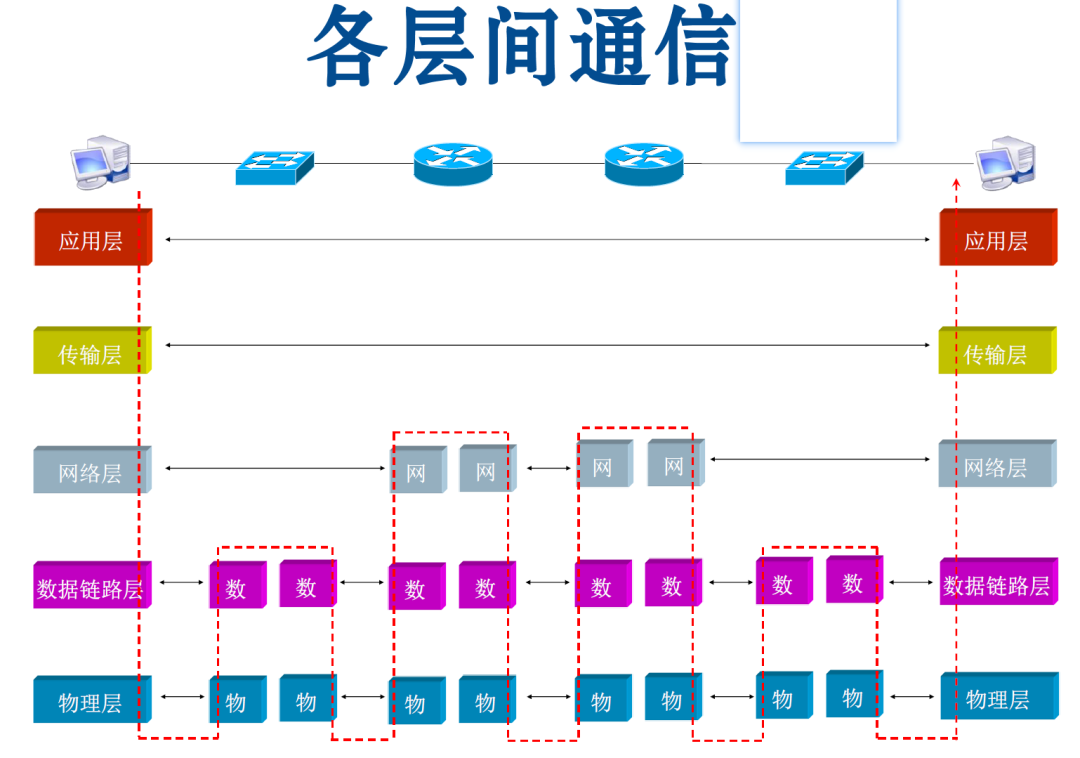
TCP/IP各层主要功能
第一层:网络接口层(物理层和数据链路层)
提供TCP/IP协议的数据结构和实际物理硬件之间的接口。
物理层的任务就是为它的上一层提供一个物理连接,以及它们的机械、电气、功能和过程特性。
数据链路层的主要功能是如何在不可靠的物理线路上进行数据的可靠传递。
第二层:网络层
对应OSI七层参考模型的网络层。本层包含IP协议、RIP协议(Routing Information Protocol,路由信息协议),负责数据的包装、寻址和路由。网络层负责在源地址和目的地址之间建立它们所使用的路由。这一层本身没有任何错误检测和修正机制,因此,网络层必须依赖于端对端的可靠传输服务。
第三层:传输层
对应于OSI七层参考模型的传输层,它提供两种端对端的通信服务。其中TCP协议(Transmission Control Protocol)提供可靠的数据流传输服务,UDP(Use Datagram Protocol)提供不可靠的用户数据报服务。
第四层:应用层
对应于OSI七层参考模型的应用层和表示层。因特网的应用层协议包括Finger、Whois、FTP(文件传输协议)、Gopher、HTTP(超文本传输协议)、Telent(远程终端协议)、SMTP(简单邮件发送协议)、IRC(因特网中继会话)、NNTP(网络新闻传输协议)等。
- 物理层安全
ID卡信息的读取和复制
ID卡的构造简单,根据设备的频段读取设备信息,然后根据读取的信息,重新写入到新卡中,ID卡因为没有存储和加密的功能,所以读出只是一串号码,把号码重新写入到新卡就可以完成复制。
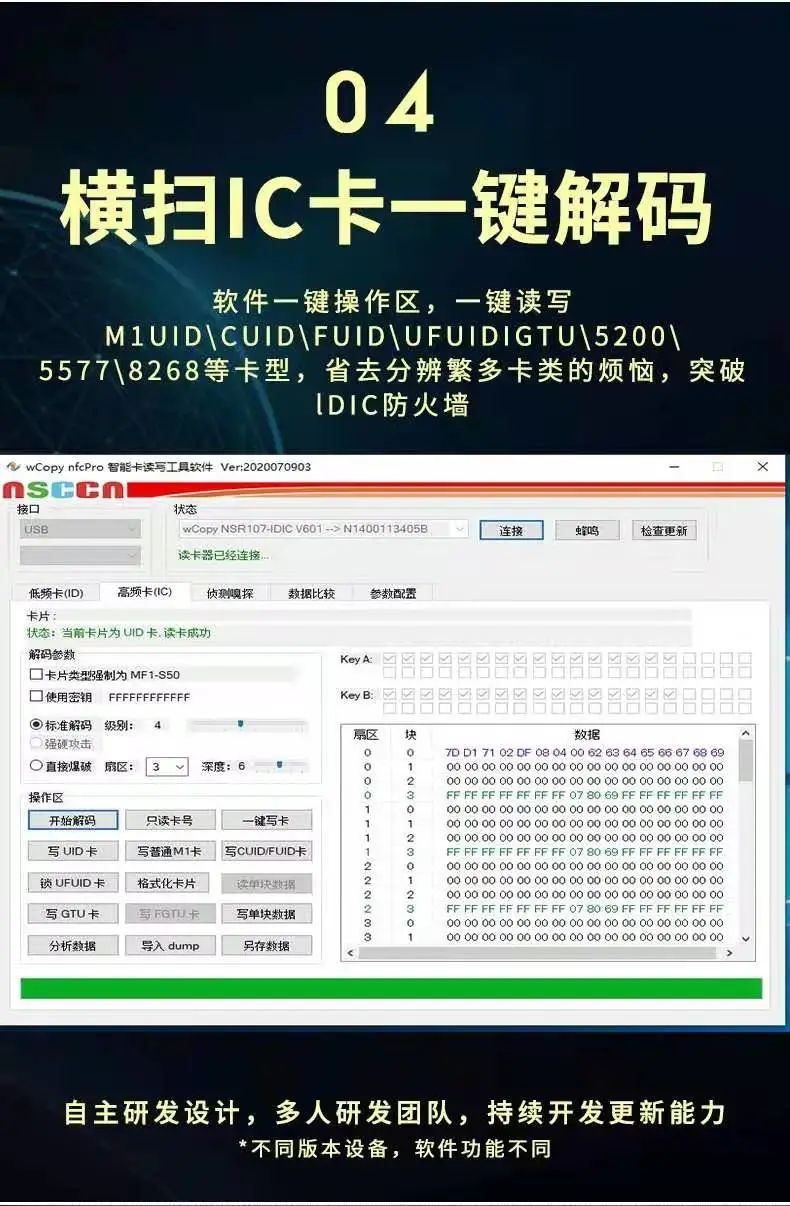
补充:
结合《GB-T 22239-2019 信息安全技术 网络安全等级保护基本要求》8.1安全通用要求中8.1.1安全物理环境要求:
物理位置选择要求防震、防风、防雨、避免设在顶层或地下室、防水和防潮;
物理访问控制要求配置电子门禁,控制、鉴别和记录进入的人员;
防盗窃和防破坏要求设备或主要部件固定并设置明显标识、通信线缆铺设在隐蔽安全处、设置机房防盗报警系统或专人值守的视频监控系统;
防雷击要求各机柜、设施和设备通过接地系统安全接地、采取措施防止感应雷;
防火要求设置火灾自动消防系统、机房及相关工作房间和辅助房应采用具有耐火等级的建筑材料;
防水和防潮要求防止雨水通过窗户、屋顶和墙壁渗透、防止水蒸气结露和地下积水的转移与渗透、安装对水敏感的检测仪表或元件;
防静电要求采用防静电地板或地面并采用必要的接地防静电措施、采取措施防止静电的产生;
温湿度控制要求设置温湿度自动调节措施;
电力供应要求在机房供电线路上配置稳压器和过电压防护设备、提供短期的备用电力供应、设置冗余或并行的电力电缆线路为计算机系统供电;
电磁防护要求电源线和通信线缆应隔离铺设,避免互相干扰、对关键设备实施电磁屏蔽。
2.数据链路层安全
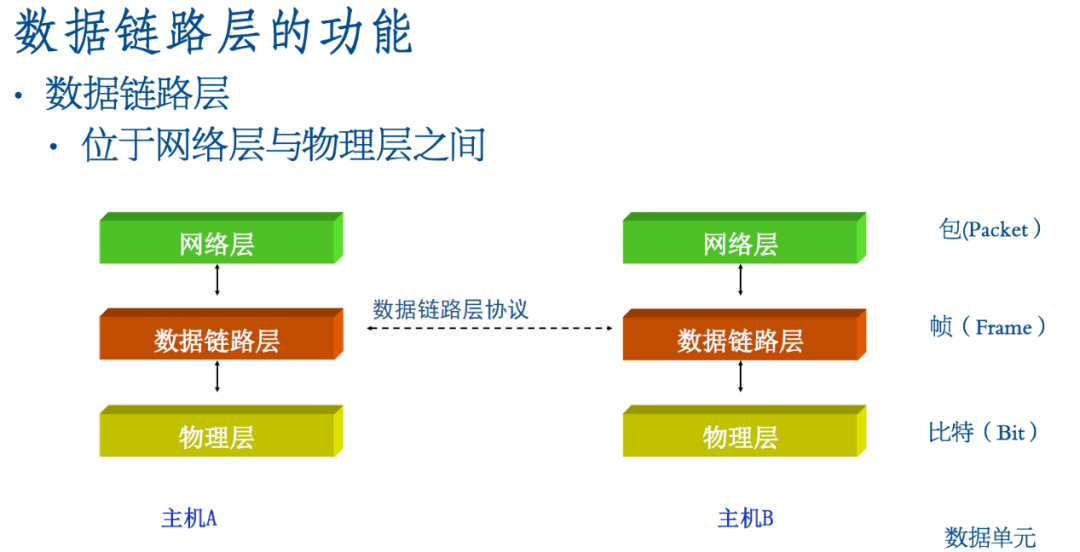
数据链路层的功能
交换机工作原理:
根据MAC地址表来转发数据帧
路由器工作原理:
根据路由表来转发数据包
MAC地址表不存在交换机本身的MAC地址
一个接口上可以支持多个MAC地址,一个MAC地址不支持多个接口同时使用。
MAC地址就是在网络接入层上使用的地址,通俗点说就是网卡的物理地址,现在的MAC地址一般都采用6字节48bit,前24位是生产厂家向IEEE申请的厂商地址。
比如我的MAC地址:
物理地址. . . . . . . . . . . . . : 66-A8-B2-A4-9A-6A
交换机以太网接口的工作模式:
1.单工:两个数据站之间只能沿单一方向传输数据,只能接收或只能发送,类似于麦克风和扬声器。
2.半双工:两个数据站之间可以双向数据传输,但不能同时进行,不能同时收发,类似于手机,只能拨出去或者接进来。
3.全双工:两个数据站之间可以双向同时进行数据传输,可以同时收发,类似于终端和路由器。
数据链路层安全
MAC地址泛洪
交换机中一张非常重要的表,叫做MAC地址表,这个表是一个硬件组成的表,主要是完成快速转发,CAM表有大小限制,越是高端的交换机表空间越大,但是作为接入交换机,表空间基本都在8K左右。交换机的一个原理是,接口下回自动学习并记录MAC地址,所以攻击者不断进行MAC地址刷新,充斥整个交换机的整个MAC地址表,导致交换机不得不进行数据广播,从而获取其他人的报文信息。
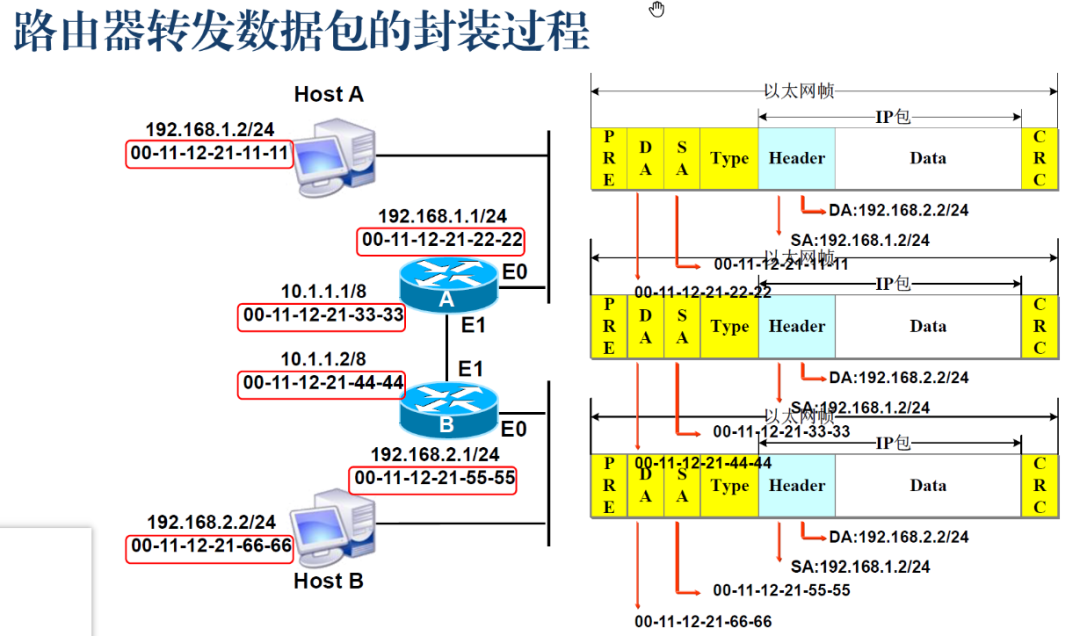
交换机转发原理
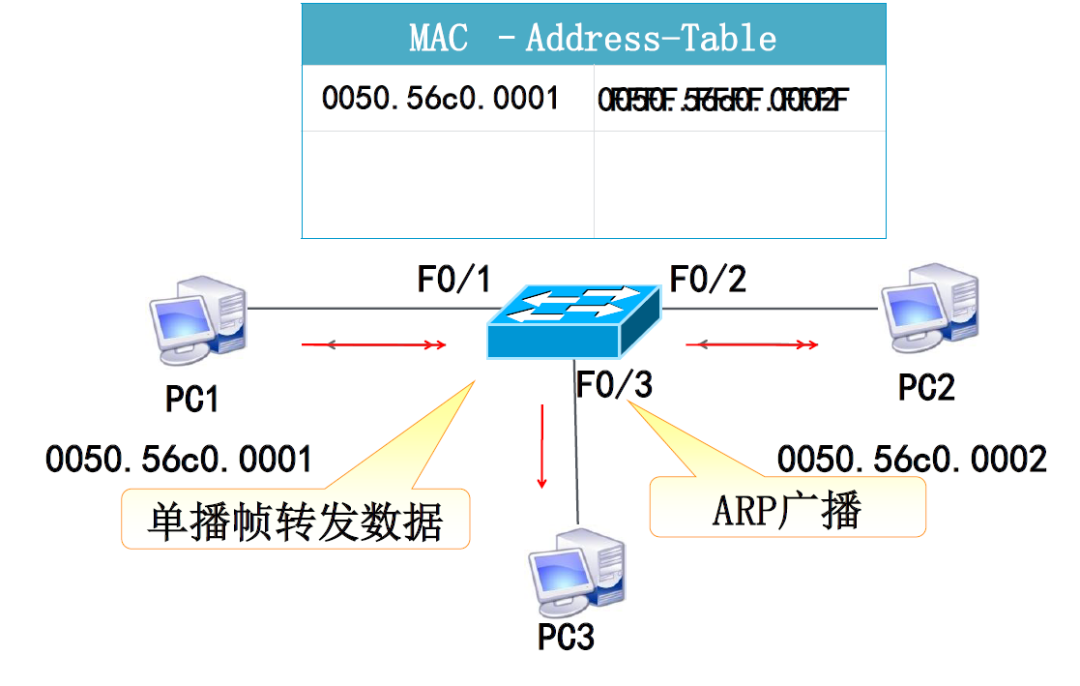
PC1与PC2通信
MAC地址泛洪防御
在公司的接入交换机上限定端口接入的数量,一台接入交换机可以允许一个端口有20个MAC地址,如果这个端口学习超过了20个MAC地址,就停止学习,后来的MAC地址将被丢弃。
交换机端口安全的作用
基于MAC地址限制、允许客户端流量
避免MAC地址扩散攻击
避免MAC地址欺骗攻击(主机使用虚假MAC地址发送非法数据)
3.网络层安全
IP地址
主机唯一的标识,保证主机间正常通信
一种网络编码,用来确定网路中一个节点
IP地址由32位二级制(32bit)组成
如图我的ip地址:
本地链接 IPv6 地址. . . . . . . . : fe80::c9c7:e029:1514:8af7%22
IPv4 地址 . . . . . . . . . . . . : 192.168.3.130
IP地址的组成
IP地址由两部分组成
网络部分(NETWORK)
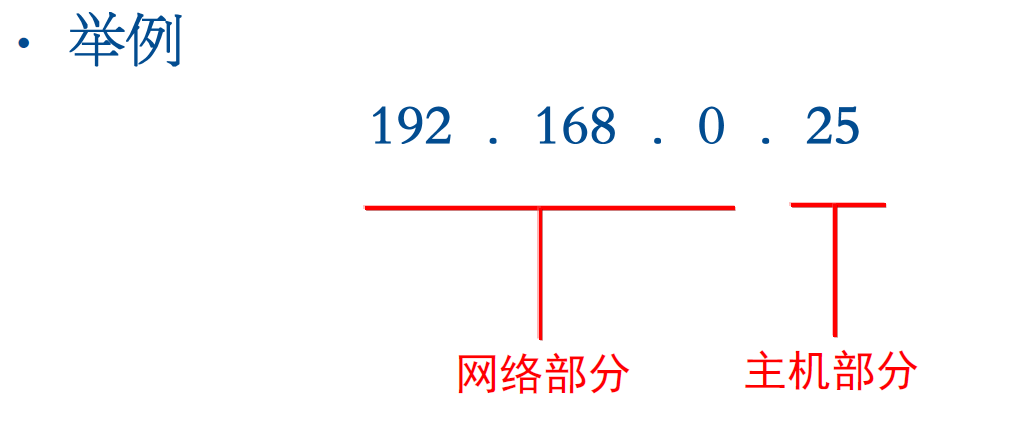
主机部分(HOST)
IP地址分为ABCDE五类
A类IP地址范围:1.0.0.0 – 126.255.255.255
其中包含私有地址:A类:10.0.0.0 – 10.255.255.255
B类IP地址范围:128.0.0.0 – 191.255.255.255
其中包含私有地址:B类:172.16.0.0 – 172.31.255.255
C类IP地址范围:192.0.0.0 – 223.255.255.255
其中包含私有地址:C类:192.168.0.0 – 192.168.255.255
D类IP地址范围:D类IP地址在历史上被叫做多播地址(multicast address),即组播地址。在以太网中,多播地址命名了一组应该在这个网络中应用接收到一个分组的站点。多播地址的最高位必须是“1110”,范围从224.0.0.0到239.255.255.255。
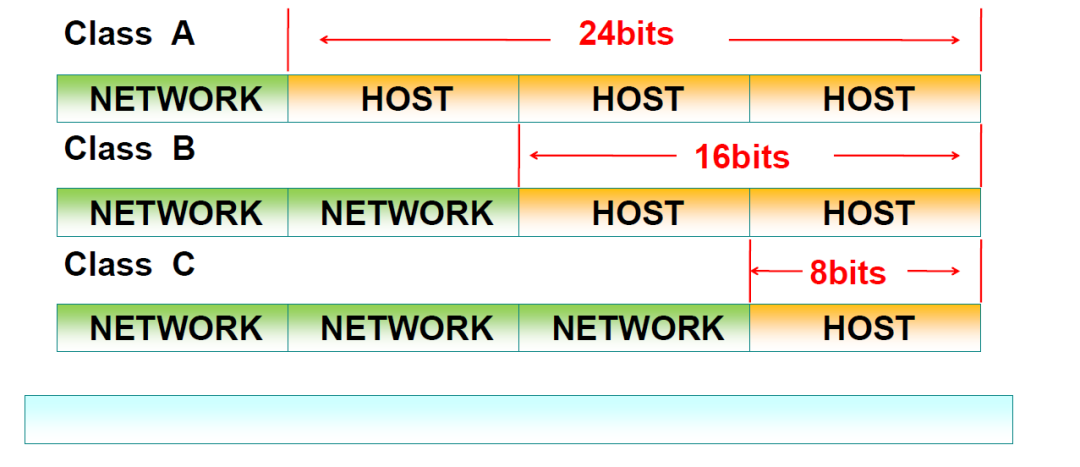
E类IP地址范围:E类IP地址中是以“11110”开头,E类IP地址都保留用于将来和实验使用。
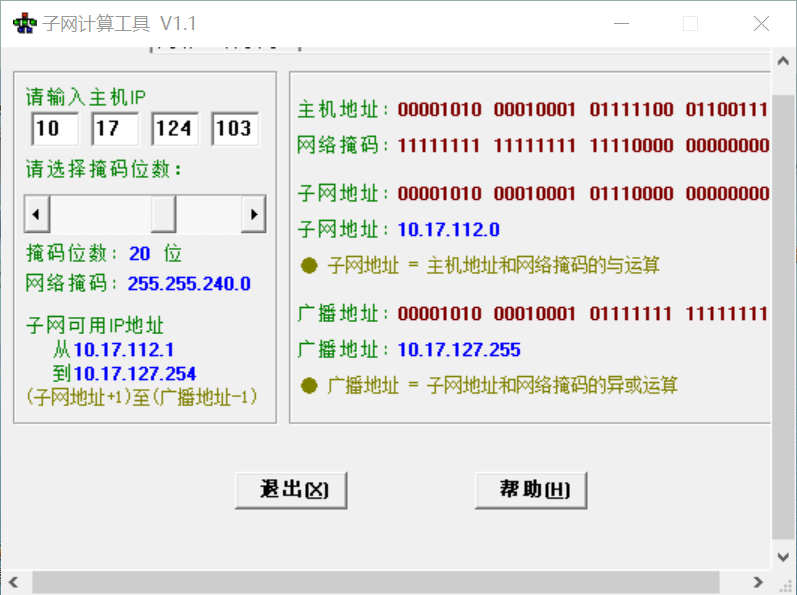
子网掩码:
用来确定IP的网络地址
32个二进制位
对应IP地址的网络部分用1表示
对应IP地址的主机部分用0表示
IP地址和子网掩码做逻辑“与”运算得到网络地址
0和任何数相与都等于0

1和任何数相与都等于任何数本身
A、B、C三类地址的默认子网掩码
A类:255.0.0.0
B类:255.255.0.0
C类:255.255.255.0
配置主机(路由器)的IP地址
网络测试工具:
ipconfig:
ipconfig——当使用ipconfig时不带任何参数选项,那么它为每个已经配置了的接口显示IP地址、子网掩码和缺省网关值。
ipconfig /all——当使用all选项时,ipconfig能为DNS和Windows服务器显示它已配置且所要使用的附加信息(如IP地址等),并且显示内置于本地网卡中的物理地址(MAC地址)。如果IP地址是从DHCP服务器租用的,ipconfig将显示DHCP服务器的IP地址和租用地址预计失效的日期。
ipconfig /release和ipconfig /renew——这是两个附加选项,只能在向DHCP服务器租用其IP地址的计算机上起作用。如果你输入ipconfig /release,那么所有接口的租用IP地址便重新交付给DHCP服务器(归还IP地址)。如果你输入ipconfig /renew,那么本地计算机便设法与DHCP服务器取得联系,并租用一个IP地址。请注意,大多数情况下网卡将被重新赋予和以前所赋予的相同的IP地址。
总的参数简介(也可以在DOS方式下输入 ipconfig /? 进行参数查询)
ipconfig /all:显示本机TCP/IP配置的详细信息;
ipconfig /release:DHCP客户端手工释放IP地址;
ipconfig /renew:DHCP客户端手工向服务器刷新请求;
ipconfig /flushdns:清除本地DNS缓存内容;
ipconfig /displaydns:显示本地DNS内容;
ipconfig /registerdns:DNS客户端手工向服务器进行注册;
ipconfig /showclassid:显示网络适配器的DHCP类别信息;
ipconfig /setclassid:设置网络适配器的DHCP类别。
ipconfig /renew “Local Area Connection”:更新“本地连接”适配器的由 DHCP 分配 IP 地址的配置
ipconfig /showclassid Local*:显示名称以 Local 开头的所有适配器的 DHCP 类别 ID
ipconfig /setclassid “Local Area Connection” TEST:将“本地连接”适配器的 DHCP 类别 ID 设置为 TEST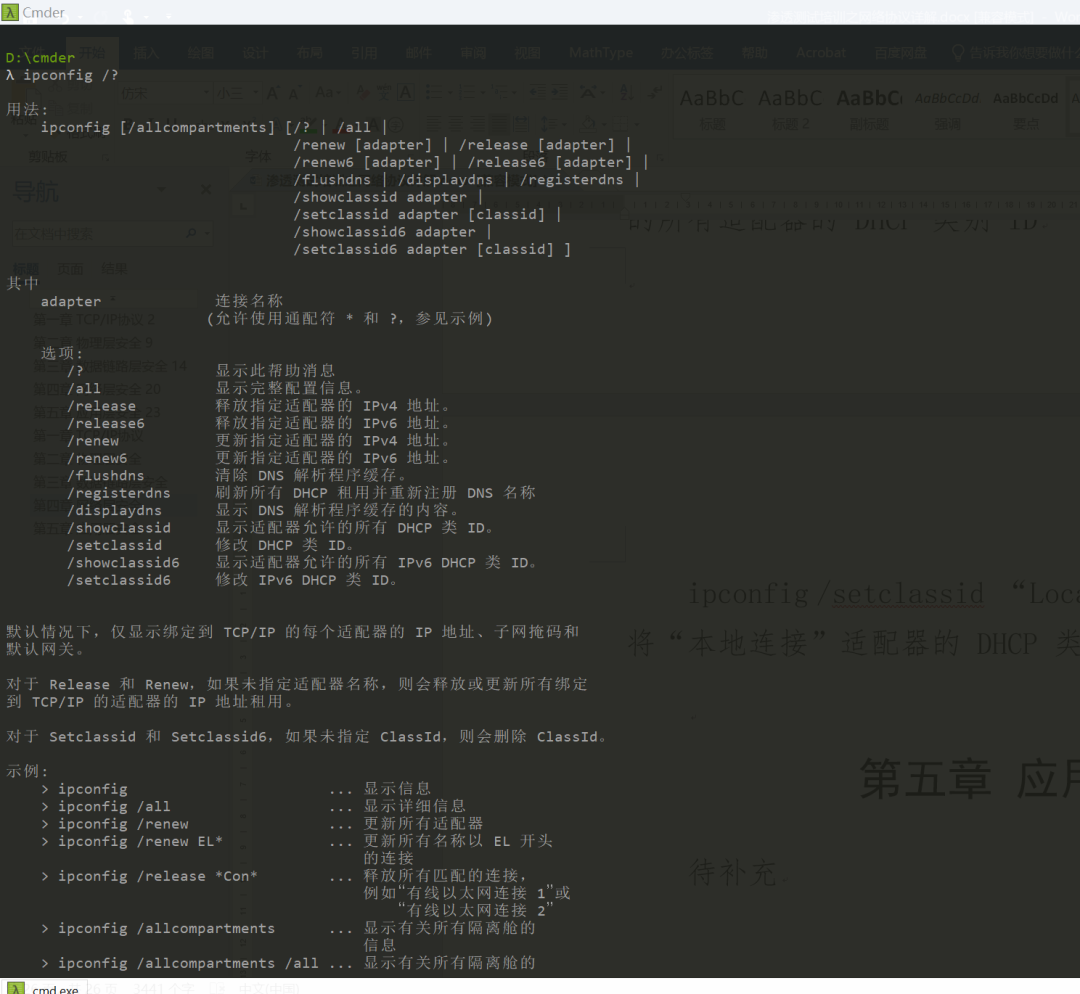
ping:
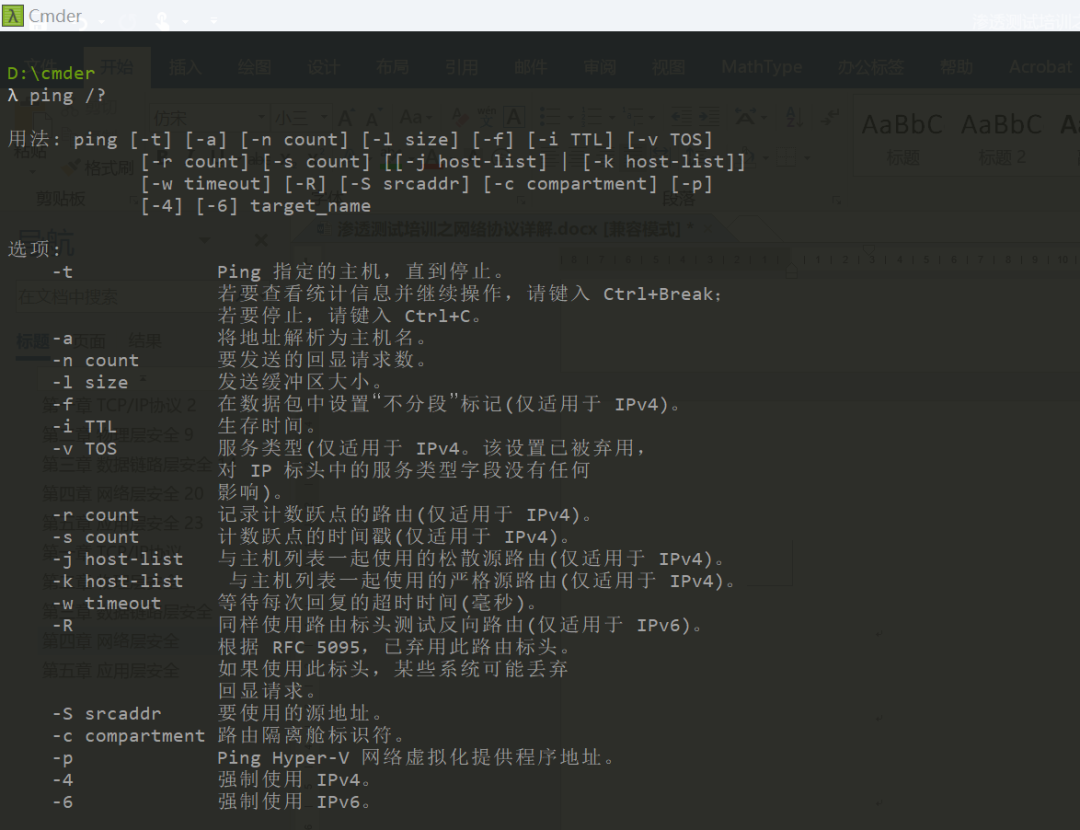
用法:
ping [-t] [-a] [-n count] [-l size] [-f] [-i TTL] [-v TOS]
[-r count] [-s count] [[-j host-list] | [-k host-list]]
[-w timeout] [-R] [-S srcaddr] [-c compartment] [-p]
[-4] [-6] target_name选项:
-t Ping 指定的主机,直到停止。
若要查看统计信息并继续操作,请键入 Ctrl+Break;
若要停止,请键入 Ctrl+C。
-a 将地址解析为主机名。
-n count 要发送的回显请求数。
-l size 发送缓冲区大小。
-f 在数据包中设置“不分段”标记(仅适用于 IPv4)。
-i TTL 生存时间。
-v TOS 服务类型(仅适用于 IPv4。该设置已被弃用,
对 IP 标头中的服务类型字段没有任何
影响)。
-r count 记录计数跃点的路由(仅适用于 IPv4)。
-s count 计数跃点的时间戳(仅适用于 IPv4)。
-j host-list 与主机列表一起使用的松散源路由(仅适用于 IPv4)。
-k host-list 与主机列表一起使用的严格源路由(仅适用于 IPv4)。
-w timeout 等待每次回复的超时时间(毫秒)。
-R 同样使用路由标头测试反向路由(仅适用于 IPv6)。
根据 RFC 5095,已弃用此路由标头。
如果使用此标头,某些系统可能丢弃
回显请求。
-S srcaddr 要使用的源地址。
-c compartment 路由隔离舱标识符。
-p Ping Hyper-V 网络虚拟化提供程序地址。
-4 强制使用 IPv4。
-6 强制使用 IPv6。
IP数据包结构
特殊IP地址
- 广播地址: 255.255.255.255 限制广播地址,这个地址不能被路由器转发。
- 环回地址: 127.0.0.1环回地址是主机用于向自身发送通信的一个特殊地址(也就是一个特殊的目的地址)。
可以这么说:同一台主机上的两项服务若使用环回地址而非分配的主机地址,就可以绕开TCP/IP协议栈的下层。(也就是说:不用再通过什么链路层,物理层,以太网传出去了,而是可以直接在自己的网络层,运输层进行处理了)
IPv4的环回地址为:127.0.0.0到127.255.255.255都是环回地址(只是有两个特殊的保留),此地址中的任何地址都不会出现在网络中。
网络号为127的地址根本就不是一个网络地址(因为产生的IP数据报就不会到达外部网络接口中,是不离开主机的包)
当操作系统初始化本机的TCP/IP协议栈时,设置协议栈本身的IP地址为127.0.0.1(保留地址),并注入路由表。当IP层接收到目的地址为127.0.0.1(准确的说是:网络号为127的IP)的数据包时,不调用网卡驱动进行二次封装,而是立即转发到本机IP层进行处理,由于不涉及底层操作。因此,ping 127.0.0.1一般作为测试本机TCP/IP协议栈正常与否的判断之一。
所以说:127.0.0.1是保留地址之一,只是被经常的使用,来检验本机TCP/IP协议栈而已。
- Localhost
localhost首先是一个域名(如同:www.baidu.com),也是本机地址,它可以被配置为任意的IP地址(也就是说,可以通过hosts这个文件进行更改的),不过通常情况下都指向:(如下)
IPv4:表示 127.0.0.1
IPv6:表示 [::1]
整个127.*网段通常被用作loopback网络接口的默认地址,按照惯例通常设置为127.0.0.1。我们当前这个主机上的这个地址,别人不能访问,即使访问,也是访问自己。因为每一台TCP/IP协议栈的设备基本上都有local/127.0.0.1。
- 本机地址
本机IP,我们可以理解为本机有三块网卡,一块网卡叫做loopback(虚拟网卡),一块叫做ethernet(有线网卡),一块叫做wlan(你的无线网卡)。
联网,网卡传输,受防火墙和网卡限制
用于本机和外部访问
- 组播地址: 224.0.0.1 组播地址,注意它和广播的区别。从224.0.0.0到239.255.255.255都是这样的地址。
224.0.0.1特指所有主机,224.0.0.2特指所有路由器。
- 169.254.x.x 如果你的主机使用了DHCP功能自动获得一个IP地址,那么当你的DHCP服务器发生故障,或响应时间太长而超出了一个系统规定的时间,Windows系统会为你分配一个这样的地址。
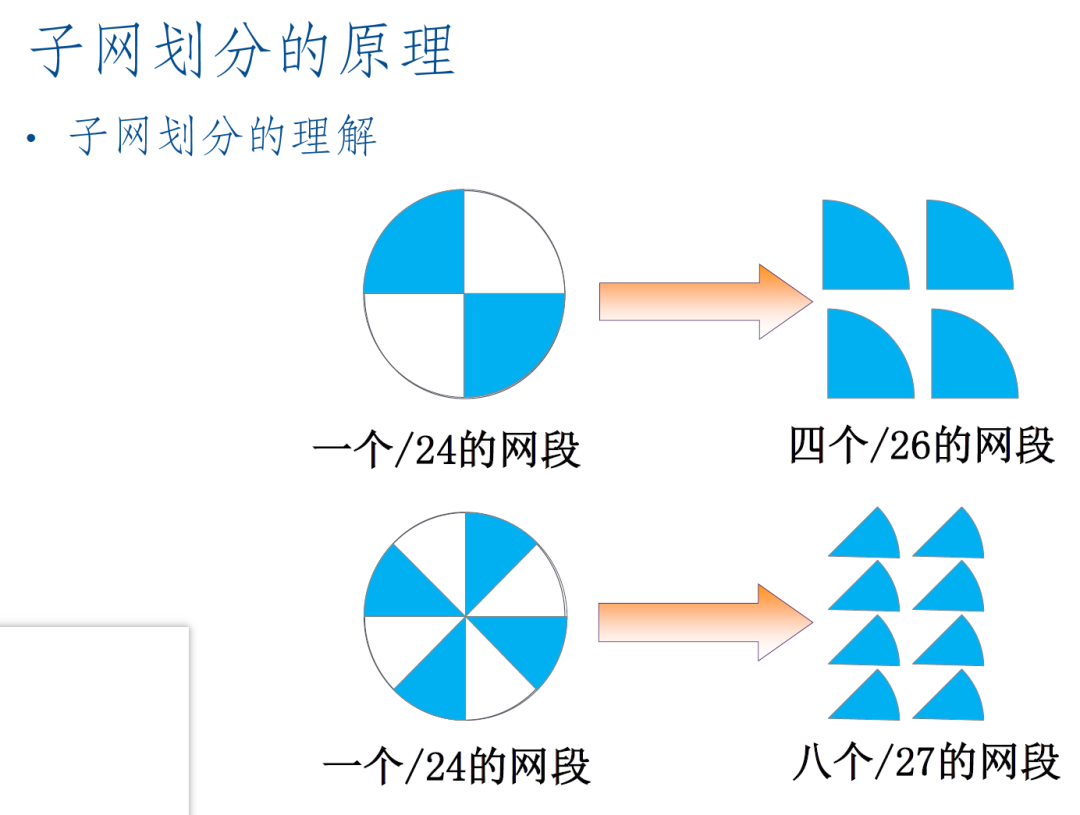
子网划分
有类网络就是指把IP地址能归结到A类、B类、C类IP。
例如:
IP地址为192.168.1.22 mask 255.255.255.0 那么这个IP属于C类IP地址。
IP地址为190.4.64.33 mask 255.255.0.0 那么这个IP属于B类IP地址(解释:B类IP从128~191,子网掩码是255.255.0.0)。
- A类地址:前8位是1~126的IP地址。它们的网络ID是前8位,主机ID是后24位。
- B类地址:前8位是128~191的IP地址。它们的网络ID是前16位,主机ID是后16位。
- C类地址:前8位是192~223的IP地址。他们的网络ID是前24位,主机ID是后8位。
- D类和E类地址:前8位是224~255之间的地址。D类用于组播,E类用于科学实验。
路由:
直连路由:路由器本身的接口产生的路由,叫做直连路由,但是需要路由器端口UP,协议正常才可以产生有效的直连路由。
静态路由:手工配置的路由,就是静态路由。
动态路由:通过路由协议自动获取的路由,叫做动态路由。
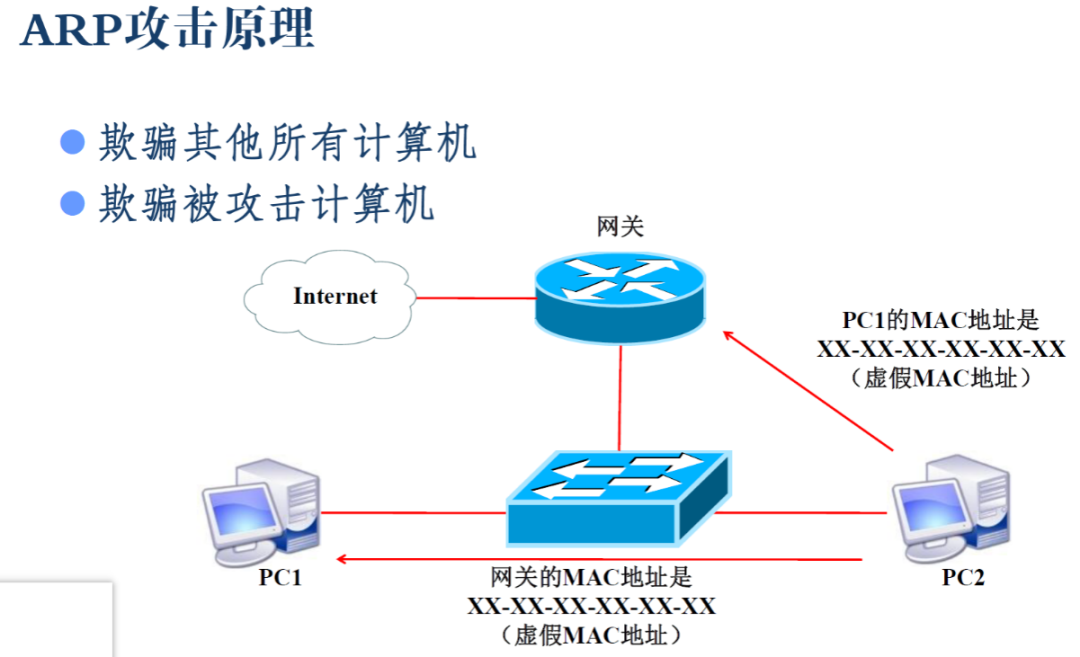
ARP攻击与ARP欺骗原理
ARP协议:
ARP相关命令:
显示和修改地址解析协议(ARP)使用的“IP 到物理”地址转换表。
ARP -s inet_addr eth_addr [if_addr]
ARP -d inet_addr [if_addr]
ARP -a [inet_addr] [-N if_addr] [-v]
-a 通过询问当前协议数据,显示当前 ARP 项。
如果指定 inet_addr,则只显示指定计算机
的 IP 地址和物理地址。如果不止一个网络
接口使用 ARP,则显示每个 ARP 表的项。
-g 与 -a 相同。
-v 在详细模式下显示当前 ARP 项。所有无效项
和环回接口上的项都将显示。
inet_addr 指定 Internet 地址。
-N if_addr 显示 if_addr 指定的网络接口的 ARP 项。
-d 删除 inet_addr 指定的主机。inet_addr 可
以是通配符 *,以删除所有主机。
-s 添加主机并且将 Internet 地址 inet_addr
与物理地址 eth_addr 相关联。物理地址是用
连字符分隔的 6 个十六进制字节。该项是永久的。
eth_addr 指定物理地址。
if_addr 如果存在,此项指定地址转换表应修改的接口
的 Internet 地址。如果不存在,则使用第一
个适用的接口。
示例:
> arp -s 157.55.85.212 00-aa-00-62-c6-09.... 添加静态项。
> arp -a .... 显示 ARP 表。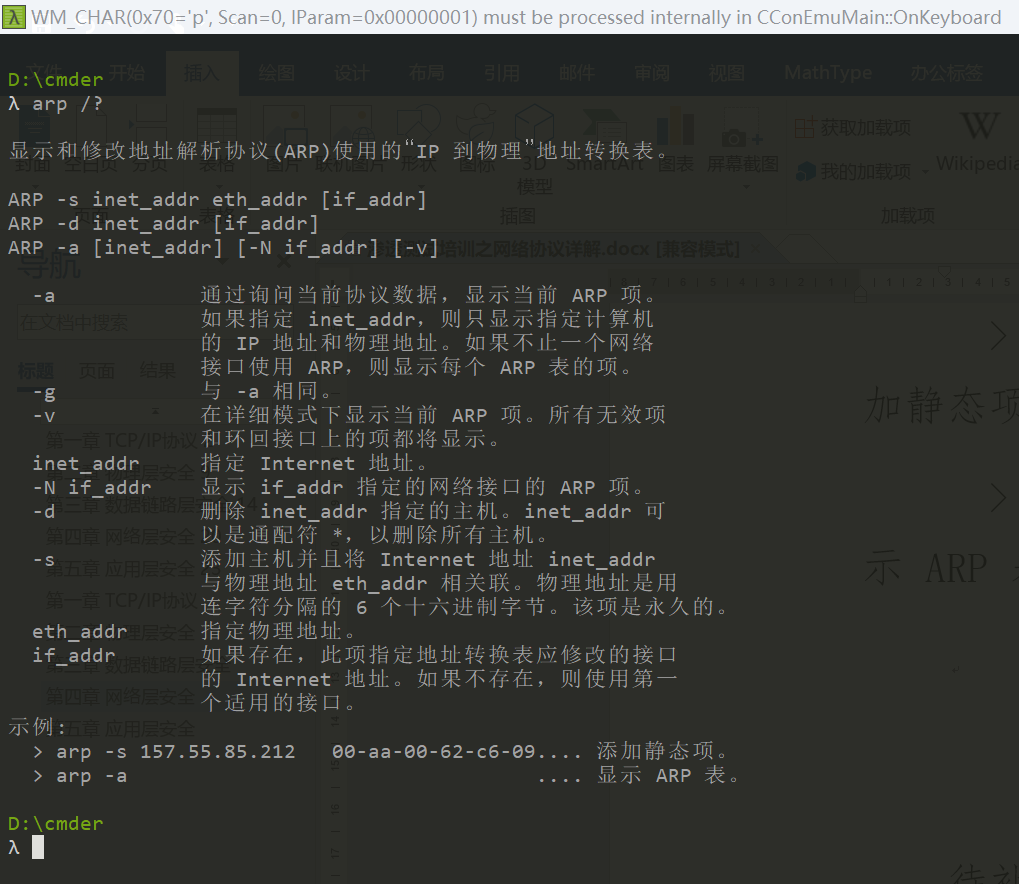
ARP攻击防御:
主机强行绑定MAC地址,交换机端口绑定MAC地址。
- 传输层安全
传输层的功能
1.提供面向连接或无连接的服务
2.维护连接状态
3.对应用层数据进行分段和封装
4.实现多路复用
5.可靠地传输数据
6.执行流量控制
三次握手:建立可靠连接
确认机制:应答接收
端口号:多路复用
序列号:丢失检测、乱序重排
完整性校验:差错检测
窗口机制:流量控制
TCP/IP协议族的传输层协议主要包括TCP和UDP
TCP是面向连接的可靠的传输层协议。它支持在并不可靠的网络上实现面向连接的可靠的数据传输。
UDP是无连接的传输协议,主要用于支持在较可靠的链路上的数据传输,或用于对延迟较敏感的应用。
TCP协议:
TCP是面向连接、可靠的进程到进程通信的协议
TCP提供全双工服务,即数据可在同一时间双向传输
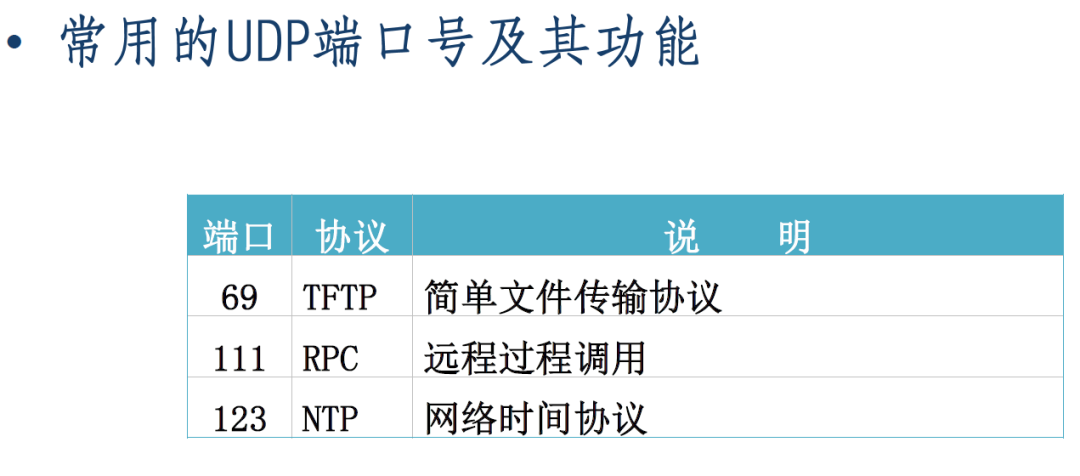
TCP和UDP通过端口号标识上层应用和服务。
TCP通过三次握手建立可靠连接
TCP通过【校验和】进行差错校验,通过序列号、确认和超时重传机制实现可靠传输,通过滑动窗口实现流量控制。
UDP实现简单,资源站用少,实时性强,适用于可靠性高的网络和延迟敏感的应用。
三次握手和四次挥手
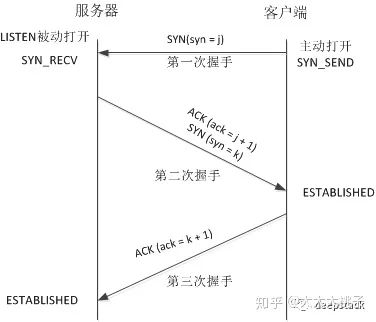
三次握手:握手是指的双方进行连接的操作。
为什么是三次握手
确认通信能力
我们要明白,如果需要进行通信,首先需要保证的是双方都具有发信和收信能力。在不知双方能力状态下进行的通信都是无法保证可靠性和通信效率的。那么通信双方如何确认对方的通信能力呢?
1.A请求B进行连接。(B已确认B的收信能力和A的发信能力)
2.B返回ACK相应。(A已确认双方的收发能力)
3.A返回ACK并建立连接。(B确认双方收发能力) 上面可以看到,至少是进行三次握手,才能确认双方能力。
防止产生脏数据连接
网络通信情况复杂,不可能保证每一消息都能正常到达其目的地。在TCP连接中,TTL的网络报文的生存时间一般都会比TCP的连接超时时间要长。这样就有可能出现一个问题。A在发送第一次连接请求时,可能网络拥塞,导致数据包未短时间内到达。到达超时时间后,A又发送了一次连接请求,这次正常进行连接。连接结束断开后,A的第一次连接请求到达B,B返回ack。如果是两次握手,A通过当前的状态,直接拒绝B的请求,但B会单方面认为连接已经建立,实际上并不是...
每一次握手到底是传输了什么?
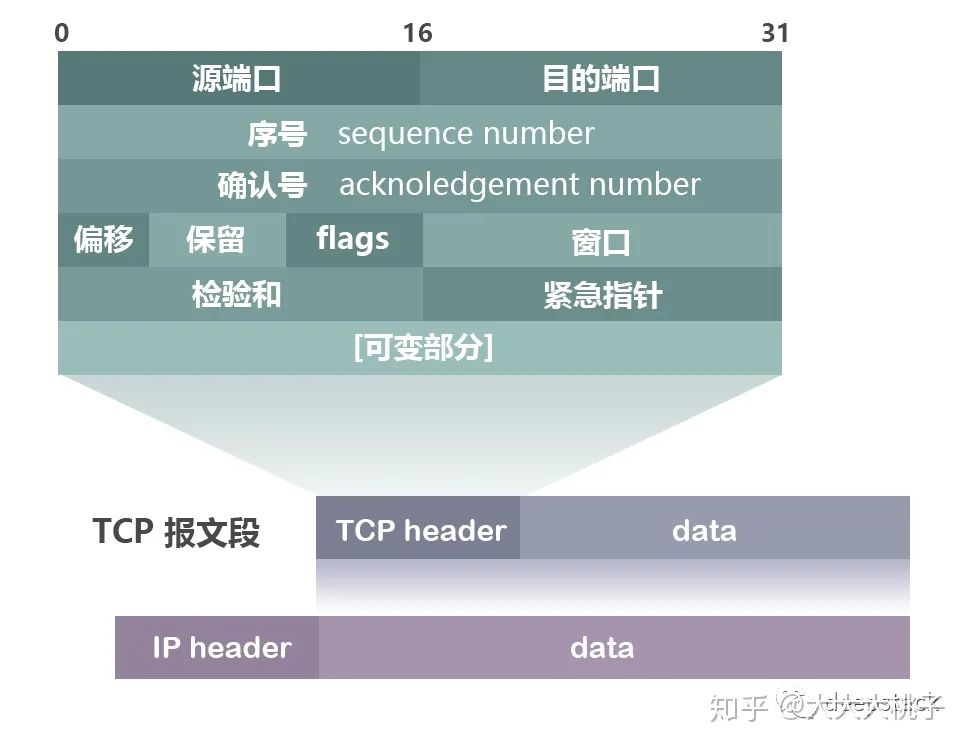
想知道除了ip和端口号,每次传输的信息是什么,我们首先得知道TCP传输信息的结构。
第一次握手:
首先会将TCP的header部分的控制位(上图的flags)中的SYN置为1。表示希望建立连接。
还有一个重要的数据,seq,即序号。这个东西是干嘛用的呢?这个涉及到TCP安全性和可靠性,与ack即确认号紧密相关。TCP在传输数据时,如果数据比较大,会进行拆分操作,将大数据拆成一个个小的数据包。序号就是在这个时候用的。我们必须要知道这个包的顺序是什么,才能把真正的数据在服务端还原。seq的顺序并不是从0或者1开始的,而是一个随机值。因为如果序号从1开始,那么整个通信的过程非常容易被预测。正因为是随机的,所以对方不知道你的seq,所以我们需要在开始收发数据之前,将seq先发送给对方。序号的初始值的传递就是通过SYN=1的操作传递的。
客户端此时处于同步状态,即可以建立连接。服务端处于监听状态。
第二次握手
标志位。因为已经收到了客户端的建立连接请求。所以必须要发送ack,以告知客户端自己已经收到消息。所以ACK的标志位要置为1,且SYN也是1,因为还未建立连接。
seq。同第一次握手一样,也是一个随机值(TCP为全双工,所以双方都需要保留seq方便处理数据包)。
ack。是对客户端发过来的序列号进行计算得到的。
服务端处于SYN接收状态。
第三次握手
标志位。此时只需要ACK=1。SYN已经不需要了,双方已经同步完seq等信息。
seq。可以说是第二次握手收到的ack。
ack。是对第二次握手收到的序列号进行计算得到的。用以告知已收到二次握手信息。
客户端处于连接建立状态,服务端收到信息之后也会进入连接建立状态,双方可以进行通信。
第四次挥手
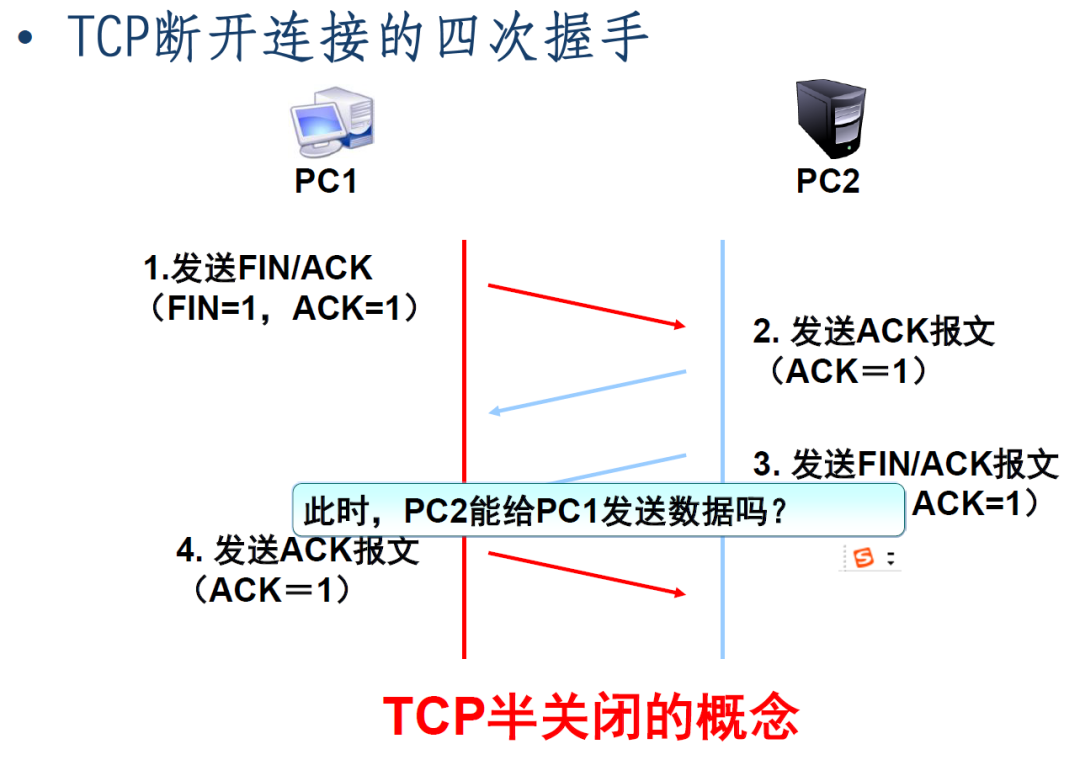
TCP连接在数据传输完成之后需要关闭,不然会一直占用系统资源。TCP的连接关闭需要四次通信才行,分手也是个麻烦事儿。
为什么四次才能断开连接呢?
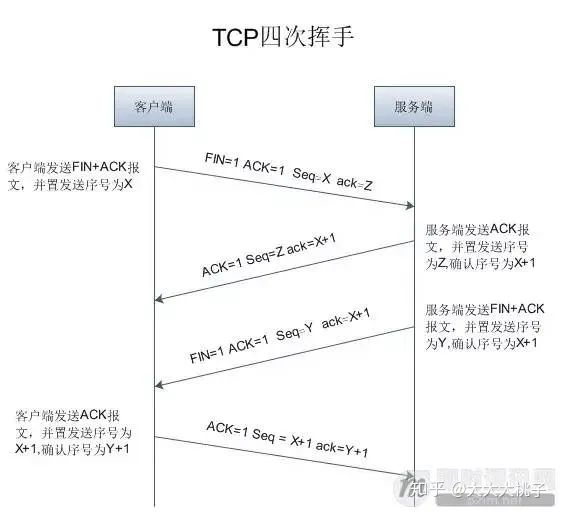
分手这件事情,两边都说明白,分别断开即可。但是想要确认对方都要断开,那么一次两次是不够的。
我们还是拿A、B来举例。假设A要主动断开和B的连接。
1.A发送断开请求。(需要等待B的回复,不然B未收到消息 就单方面的断开有点不负责任。超时重传)
2.B收到请求并回复A。(B收到请求后,很伤心,但是没有办法,只能断开连接,但是B是被动的接收断开,所以需要通知其应用程序做关闭准备)
3.B这边准备完了,通知A可以断开了。
4.A回复B,我收到消息了,断开连接吧。
请求发送的信息是什么?
关闭由哪方开始?
答案是哪边都可以,无论是客户端还是服务器端,都可以主动发起关闭请求。发起关闭请求的前提是数据发送完毕,不一定非得等待对方确认完成。
第一次挥手
假设客户端发起关闭请求。那么客户端发完消息后,会进入FIN_WAIT阶段。此处已经无法再发送应用程序消息,只能处理关闭相关信息。
第二次挥手
服务端收到第一次挥手消息后,返回收到消息的ack。服务端会进入CLOSE_WAIT阶段。这个阶段是等待关闭阶段,通知应用程序发送剩余数据,处理现场信息,关闭相应资源。
第三次挥手
你应该有点好奇为什么第三次挥手和第二次挥手都是同一个服务。第二次主要是一个ack响应,第三次主要是一个服务端关闭通知消息。两者目的不同。等到三次挥手完毕,那么服务端会进入LAST_ACK状态,即等待最后客户端(主动发起关闭的一方)的ack确认。
第四次挥手
第四次挥手是主动发起关闭的一方A,对被动关闭一方B的FIN消息的确认。第四次信息发送完成后,A会进入TIME_WAIT阶段,而不是直接删除套接字。具体原因我们在下面讲。收到第四次挥手信息后,B会直接进行关闭操作。
为什么会有TIME_WAIT?
还是那句话,网络并不是一个理想世界,任何异常情况都有可能发生。为了保证TCP连接能够正常关闭,主动发起关闭方不能直接删除套接字,而是需要经过一段时间等待。这个时间一般是2MSL(Maxumun Segment Lifetime 最大报文生存时间)。原因如下
确认被动关闭方能够正常进入关闭状态。假设B未收到A最后的一个ack,会再次发送FIN消息(第三次挥手),如果A已经CLOSE了,那么B就会一直重试发送。所以A必须要进行一段时间的等待。
防止失效请求。假设A关闭了此次连接,又重新在原来的端口号上开启了新的连接。原来在网络上发送的一些包(已失效但未超过ttl)到来之后,无法进行区分是否是正常的包,导致数据混乱。
举个例子来证明没有TIME_WAIT的情况。
1.A断开了,并且删除了套接字。
2.B没有收到A的最后一次ack,导致FIN重发。
3.A重新开启了新的套接字新的连接,但是这个套接字和之前删除的套接字拥有相同的端口号。
4.B后来重发的FIN会错误的跑到新的套接字,导致A开始执行断开操作。
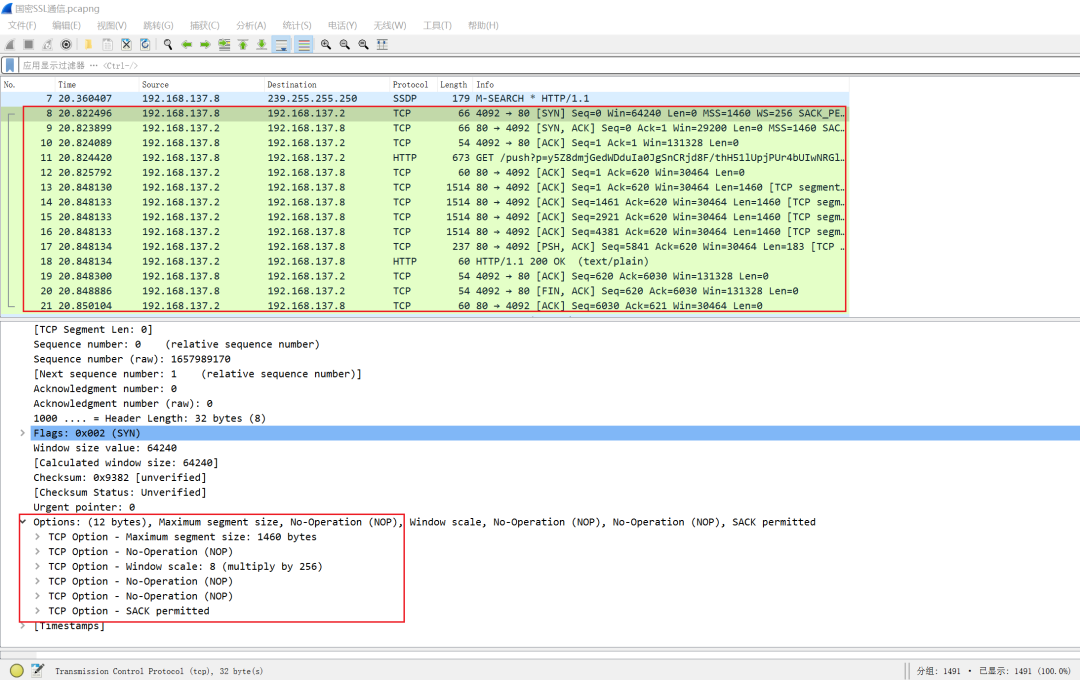
所以TIME_WAIT也是为了防止上面的误删除。
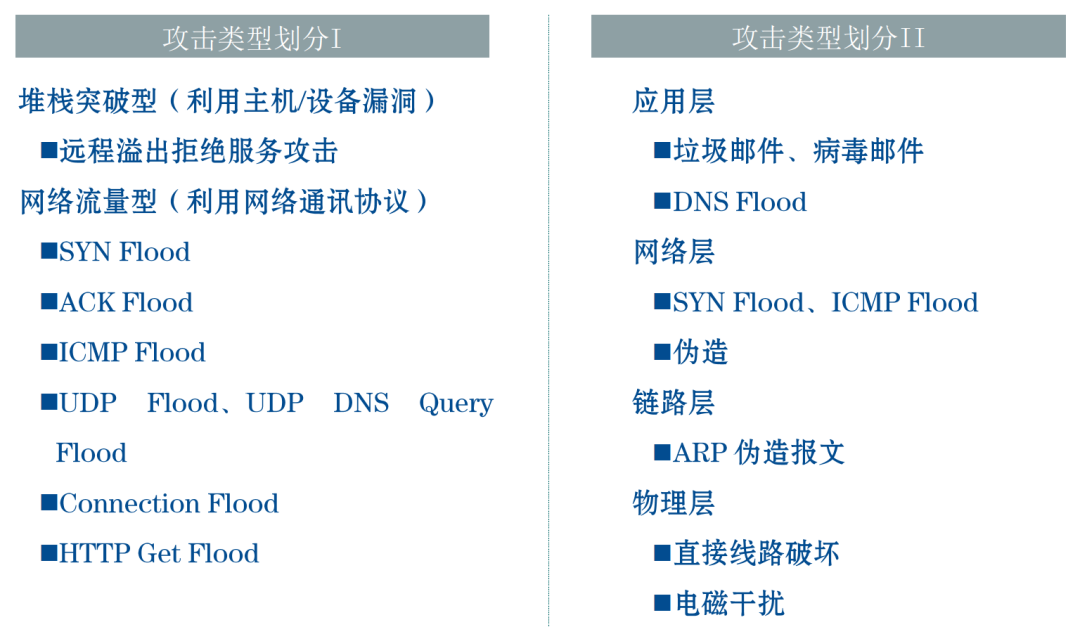
DDOS 分布式拒绝服务
DDOS 是什么
举例来说,我开了一家餐厅,正常情况下,最多可以容纳30个人同时进餐。你直接走进餐厅,找一张桌子坐下点餐,马上就可以吃到东西。
很不幸,我得罪了一个流氓。他派出300个人同时涌进餐厅。这些人看上去跟正常的顾客一样,每个都说"赶快上餐"。但是,餐厅的容量只有30个人,根本不可能同时满足这么多的点餐需求,加上他们把门口都堵死了,里三层外三层,正常用餐的客人根本进不来,实际上就把餐厅瘫痪了。
这就是 DDOS 攻击,它在短时间内发起大量请求,耗尽服务器的资源,无法响应正常的访问,造成网站实质下线。
DDOS 里面的 DOS 是 denial of service(停止服务)的缩写,表示这种攻击的目的,就是使得服务中断。最前面的那个 D 是 distributed (分布式),表示攻击不是来自一个地方,而是来自四面八方,因此更难防。你关了前门,他从后门进来;你关了后门,他从窗口跳起来。
DDOS 的种类
DDOS 不是一种攻击,而是一大类攻击的总称。它有几十种类型,新的攻击方法还在不断发明出来。网站运行的各个环节,都可以是攻击目标。只要把一个环节攻破,使得整个流程跑不起来,就达到了瘫痪服务的目的。
其中,比较常见的一种攻击是 cc 攻击。它就是简单粗暴地送来大量正常的请求,超出服务器的最大承受量,导致宕机。我遭遇的就是 cc 攻击,最多的时候全世界大概20多个 IP 地址轮流发出请求,每个地址的请求量在每秒200次~300次。我看访问日志的时候,就觉得那些请求像洪水一样涌来,一眨眼就是一大堆,几分钟的时间,日志文件的体积就大了100MB。说实话,这只能算小攻击,但是我的个人网站没有任何防护,服务器还是跟其他人共享的,这种流量一来立刻就下线了。
备份网站:
防范 DDOS 的第一步,就是你要有一个备份网站,或者最低限度有一个临时主页。生产服务器万一下线了,可以立刻切换到备份网站,不至于毫无办法。
HTTP 请求的拦截
如果恶意请求有特征,对付起来很简单:直接拦截它就行了。
HTTP 请求的特征一般有两种:IP 地址和 User Agent 字段。比如,恶意请求都是从某个 IP 段发出的,那么把这个 IP 段封掉就行了。或者,它们的 User Agent 字段有特征(包含某个特定的词语),那就把带有这个词语的请求拦截。
拦截可以在三个层次做。
(1)专用硬件
Web 服务器的前面可以架设硬件防火墙,专门过滤请求。这种效果最好,但是价格也最贵。
(2)本机防火墙
操作系统都带有软件防火墙,Linux 服务器一般使用 iptables。比如,拦截 IP 地址1.2.3.4的请求,可以执行下面的命令。
$ iptables -A INPUT -s 1.2.3.4 -j DROP
(3)Web 服务器
Web 服务器也可以过滤请求。拦截 IP 地址1.2.3.4,nginx 的写法如下。
location / {
deny 1.2.3.4;
}
Apache 的写法是在.htaccess文件里面,加上下面一段。
<RequireAll>
Require all granted
Require not ip 1.2.3.4
</RequireAll>
如果想要更精确的控制(比如自动识别并拦截那些频繁请求的 IP 地址),就要用到 WAF。
Web 服务器的拦截非常消耗性能,尤其是 Apache。稍微大一点的攻击,这种方法就没用了。带宽扩容
上一节的 HTTP 拦截有一个前提,就是请求必须有特征。但是,真正的 DDOS 攻击是没有特征的,它的请求看上去跟正常请求一样,而且来自不同的 IP 地址,所以没法拦截。这就是为什么 DDOS 特别难防的原因。
当然,这样的 DDOS 攻击的成本不低,普通的网站不会有这种待遇。不过,真要遇到了该怎么办呢,有没有根本性的防范方法呢?
答案很简单,就是设法把这些请求都消化掉。30个人的餐厅来了300人,那就想办法把餐厅扩大(比如临时再租一个门面,并请一些厨师),让300个人都能坐下,那么就不影响正常的用户了。对于网站来说,就是在短时间内急剧扩容,提供几倍或几十倍的带宽,顶住大流量的请求。这就是为什么云服务商可以提供防护产品,因为他们有大量冗余带宽,可以用来消化 DDOS 攻击。
一个朋友传授了一个方法,给我留下深刻印象。某云服务商承诺,每个主机保 5G 流量以下的攻击,他们就一口气买了5个。网站架设在其中一个主机上面,但是不暴露给用户,其他主机都是镜像,用来面对用户,DNS 会把访问量均匀分配到这四台镜像服务器。一旦出现攻击,这种架构就可以防住 20G 的流量,如果有更大的攻击,那就买更多的临时主机,不断扩容镜像。
CDN:
CDN 指的是网站的静态内容分发到多个服务器,用户就近访问,提高速度。因此,CDN 也是带宽扩容的一种方法,可以用来防御 DDOS 攻击。
网站内容存放在源服务器,CDN 上面是内容的缓存。用户只允许访问 CDN,如果内容不在 CDN 上,CDN 再向源服务器发出请求。这样的话,只要 CDN 够大,就可以抵御很大的攻击。不过,这种方法有一个前提,网站的大部分内容必须可以静态缓存。对于动态内容为主的网站(比如论坛),就要想别的办法,尽量减少用户对动态数据的请求。
上一节提到的镜像服务器,本质就是自己搭建一个微型 CDN。各大云服务商提供的高防 IP,背后也是这样做的:网站域名指向高防 IP,它提供一个缓冲层,清洗流量,并对源服务器的内容进行缓存。
这里有一个关键点,一旦上了 CDN,千万不要泄露源服务器的 IP 地址,否则攻击者可以绕过 CDN 直接攻击源服务器,前面的努力都白费。
防护措施是,源服务器前面有 CDN。如果攻击域名,CDN 可以挡住;如果直接攻击源服务器,我买了弹性 IP ,可以动态挂载主机实例,受到攻击就换一个地址。
分布式拒绝服务(DDoS:Distributed Denial of Service)攻击指借助于客户/服务器技术,将多个计算机联合起来作为攻击平台,对一个或多个目标发动DDoS攻击,从而成倍地提高拒绝服务攻击的威力。
通常,攻击者将攻击程序通过代理程序安装在网络上的各个“肉鸡”上,代理程序收到指令时就发动攻击。
随着网络技术发展,DDOS攻击也在不断进化,攻击成本越来越低,而攻击力度却成倍加大,使得DDOS更加难以防范。比如反射型DDoS攻击就是相对高阶的攻击方式。攻击者并不直接攻击目标服务IP,而是通过伪造被攻击者的IP向全球特殊的服务器发请求报文,这些特殊的服务器会将数倍于请求报文的数据包发送到那个被攻击的IP(目标服务IP)。
DDOS攻击让人望而生畏,它可以直接导致网站宕机、服务器瘫痪,对网站乃至企业造成严重损失。而且DDOS很难防范,可以说目前没有根治之法,只能尽量提升自身“抗压能力”来缓解攻击,比如购买高防服务。
DDOS攻击应对策略
1.定期检查服务器漏洞
定期检查服务器软件安全漏洞,是确保服务器安全的最基本措施。无论是操作系统(Windows或linux),还是网站常用应用软件(mysql、Apache、nginx、FTP等),服务器运维人员要特别关注这些软件的最新漏洞动态,出现高危漏洞要及时打补丁修补。
2.隐藏服务器真实IP
通过CDN节点中转加速服务,可以有效的隐藏网站服务器的真实IP地址。CDN服务根据网站具体情况进行选择,对于普通的中小企业站点或个人站点可以先使用免费的CDN服务,比如百度云加速、七牛CDN等,待网站流量提升了,需求高了之后,再考虑付费的CDN服务。
其次,防止服务器对外传送信息泄漏IP地址,最常见的情况是,服务器不要使用发送邮件功能,因为邮件头会泄漏服务器的IP地址。如果非要发送邮件,可以通过第三方代理(例如sendcloud)发送,这样对外显示的IP是代理的IP地址。
3.关闭不必要的服务或端口
这也是服务器运维人员最常用的做法。在服务器防火墙中,只开启使用的端口,比如网站web服务的80端口、数据库的3306端口、SSH服务的22端口等。关闭不必要的服务或端口,在路由器上过滤假IP。
4.购买高防提高承受能力
该措施是通过购买高防的盾机,提高服务器的带宽等资源,来提升自身的承受攻击能力。一些知名IDC服务商都有相应的服务提供,比如阿里云、腾讯云等。但该方案成本预算较高,对于普通中小企业甚至个人站长并不合适,且不被攻击时造成服务器资源闲置,所以这里不过多阐述。
5.限制SYN/ICMP流量
用户应在路由器上配置SYN/ICMP的最大流量来限制SYN/ICMP封包所能占有的最高频宽,这样,当出现大量的超过所限定的SYN/ICMP流量时,说明不是正常的网络访问,而是有黑客入侵。早期通过限制SYN/ICMP流量是最好的防范DOS的方法,虽然目前该方法对于DdoS效果不太明显了,不过仍然能够起到一定的作用。
6.网站请求IP过滤
除了服务器之外,网站程序本身安全性能也需要提升。以小编自己的个人博客为例,使用蝉知系统做的。系统安全机制里的过滤功能,通过限制单位时间内的POST请求、404页面等访问操作,来过滤掉次数过多的异常行为。虽然这对DDOS攻击没有明显的改善效果,但也在一定程度上减轻小带宽的恶意攻击。
延伸:Slow Http DoS(慢速拒绝服务攻击)漏洞
漏洞名称 | Slow Http DoS(慢速拒绝服务攻击)漏洞 |
|---|---|
漏洞地址 | http://127.0.0.1:8888 |
漏洞等级 | 高危 |
漏洞描述 | Slow Http DoS(慢速拒绝服务攻击)漏洞。 |
漏洞成因 | Web 服务器容易受到 Slow HTTP DoS(慢速拒绝服务攻击)的攻击。Slowloris 和 Slow HTTP POST DoS 攻击依赖于以下事实:根据设计,HTTP 协议要求服务器必须先完整接收请求,然后才可处理请求。如果 HTTP 请求不完整,或者传输速率极低,服务器会保持其资源忙于等待剩下的数据。如果服务器使过多资源保持忙碌,则会产生拒绝服务。一台计算机可以关闭另一台机器的 Web 服务器,仅需最小的带宽,而且对不相关服务和端口产生的不利影响很小。 |
漏洞危害 | 慢速拒绝服务攻击漏洞,影响应用系统的可用性。 |
修复方案 | 通用修复方案1.设置合适的 timeout 时间(Apache 已默认启用了 reqtimeout 模块),规定了 Header 发送的时间以及频率和 Body 发送的时间以及频率。2.增大 MaxClients(MaxRequestWorkers):增加最大的连接数。根据官方文档,两个参数是一回事,版本不同,MaxRequestWorkers was called MaxClients before version 2.3.13. The old name is still supported。3.默认安装的 Apache 存在 Slow Attack 的威胁,原因就是虽然设置的 timeoute,但是最大连接数不够,如果攻击的请求频率足够大,仍然会占满 Apache 的所有连接。具体修复方案1. WebSphere1)限制 HTTP 数据的大小 在WebSphere Application Server 中进行如下设置:任何单个 HTTP 头的默认最大大小为 32768 字节。可以将它设置为不同的值。HTTP 头的默认最大数量为 50。可以将它设置为不同的限制值。另一种常见的 DOS 攻击是发送一个请求,这个请求会导致一个长期运行的 GET 请求。WebSphere Application Server Plug-in 中的 ServerIOTimeoutRetry 属性可限制任何请求的重试数量。这可以降低这种长期运行的请求的影响。设置限制任何请求正文的最大大小。详见参考链接。2)设置keepalive参数打开ibm http server安装目录,打开文件夹conf,打开文件httpd.conf,查找KeepAlive值,改ON为OFF,其默认为ON。这个值说明是否保持客户端与HTTP SERVER的连接,如果设置为ON,则请求数到达MaxKeepAliveRequests设定值时请求将排队,导致响应变慢。2. Weblogic1)在配置管理界面中的协议->一般信息下设置 完成消息超时时间小于400。2)在配置管理界面中的协议->HTTP下设置 POST 超时、持续时间、最大 POST 大小为安全值范围。3. Nginx1)通过调整$request_method,配置服务器接受http包的操作限制;2)在保证业务不受影响的前提下,调整client_max_body_size, client_body_buffer_size, client_header_buffer_size,large_client_header_buffersclient_body_timeout, client_header_timeout的值,必要时可以适当的增加;3)对于会话或者相同的ip地址,可以使用HttpLimitReqModule and HttpLimitZoneModule参数去限制请求量或者并发连接数;4)根据CPU和负载的大小,来配置worker_processes 和 worker_connections的值,公式是:max_clients = worker_processes * worker_connections。4. Apache建议使用mod_reqtimeout和mod_qos两个模块相互配合来防护。1)mod_reqtimeout用于控制每个连接上请求发送的速率。配置例如:#请求头部分,设置超时时间初始为10秒,并在收到客户端发送的数据后,每接收到500字节数据就将超时时间延长1秒,但最长不超过40秒。可以防护slowloris型的慢速攻击。RequestReadTimeout header=10-40,minrate=500 #请求正文部分,设置超时时间初始为10秒,并在收到客户端发送的数据后,每接收到500字节数据就将超时时间延长1秒,但最长不超过40秒。可以防护slow message body型的慢速攻击。RequestReadTimeout body=10-40,minrate=500 需注意,对于HTTPS站点,需要把初始超时时间上调,比如调整到20秒。2)mod_qos用于控制并发连接数。配置例如:当服务器并发连接数超过600时,关闭keepaliveQS_SrvMaxConnClose 600限制每个源IP最大并发连接数为50QS_SrvMaxConnPerIP 50 这两个数值可以根据服务器的性能调整。5. IHS服务器请您先安装最新补丁包,然后启用·mod_reqtimeout·模块,在配置文件中加入:LoadModule reqtimeout_module modules/mod_reqtimeout.so为mod_reqtimeout模块添加配置:<IfModule mod_reqtimeout.c>RequestReadTimeout header=10-40,MinRate=500 body=10-40,MinRate=500</IfModule>对于HTTPS站点,建议header=20-40,MinRate=500。参见:http://www-01.ibm.com/support/docview.wss?uid=swg216521656. F5负载均衡F5负载均衡设备有相应的防护模块,如无购买可参考附件中的详细配置过程。关于F5的慢速攻击防护配置,请参考以下链接:https://support.f5.com/kb/en-us/solutions/public/10000/200/sol10260.htmlhttps://devcentral.f5.com/articles/mitigating-slow-http-post-dDoS-attacks-with-irules-ndash-follow-up7. Tomcat1)设置Tomcat /server.xml文件 connectiontimeout 值,默认为20000ms,修改为2000ms(Tomcat 自身安全漏洞)。2)设置AJAX的全局timeout时间(默认为30000ms) $.ajaxSetup({timeout:8000})。 |
测试过程 | python torshammer.py -t 127.0.0.1 -p 8888 -r 256不运行脚本,网站迅速打开,运行脚本后,网站拒绝服务无法打开,停止运行脚本后,网站可以迅速打开,从而判断应用系统存在慢速拒绝服务攻击漏洞。 |
复测情况 | 已修复python torshammer.py -t 127.0.0.1 -p 8888 -r 256刷新一次浏览器,正常请求是36ms左右。现在connectiontimeout设置了2000,执行torshammer -r 512的攻击,刷新浏览器,实际请求需要5秒钟现在connectiontimeout设置了2000,执行torshammer -r 256的攻击,刷新浏览器,实际请求需求40ms左右,几乎没影响 |
测试人员 | 利刃信安二狗子 18808883389 |
4.应用层安全
DHCP服务:
DHCP(Dynamic Host Configuration Protocol,动态主机配置协议)通常被应用在大型的局域网环境中,主要作用是集中的管理、分配IP地址,使网络环境中的主机动态地获得IP地址、Gateway地址、DNS服务器地址等信息,并能够提升地址的使用率。DHCP协议是基于UDP层之上的应用,DHCP Client将采用知名端口号68,DHCP Server采用知名端口67。
DNS:
DNS是一种典型的C/S结构,由Client向指定的DNS Server发出DNS请求报文,Server收到该请求报文之后,会回给Client一个应答报文,满足Client的域名解析要求。
在本地域的DNS Server上查询一个不存在的主机的信息时候该怎么办呢?在DNS域名解析系统中,提出了两种解析域名的方式,分别是:
递归解析方式
递归模式:
DNS服务器收到一个域名解析请求时,如果所要检索的资源记录不在本地,DNS服务器将和自己的上一层服务器交互,获得最终的答案,并将其返回给客户。
迭代解析方式
迭代模式:
DNS服务器收到解析请求,首先在本地的数据库中查找是否有相应的资源记录,如果没有,则向客户提供另外一个DNS服务器的地址,客户负责把解析请求发送给新的DNS服务器地址。
图解Http:
使用HTTP协议访问Web

你知道当我们在网页浏览器(Web browser)的地址栏中输入URL时,Web页面是如何呈现的吗?
Web页面当然不能凭空显示出来。根据Web浏览器地址栏中指定的URL,Web浏览器从Web服务器端获取文件资源(resource)等信息,从而显示出Web页面。

像这种通过发送请求获取服务器资源的Web浏览器等,都可称为客户端(client)。
Web使用一种名为HTTP(HyperText Transfer Protocol,超文本传输协议)的协议作为规范,完成从客户端到服务器端等一系列运作流程。而协议是指规则的约定。可以说,Web是建立在HTTP协议上通信的。
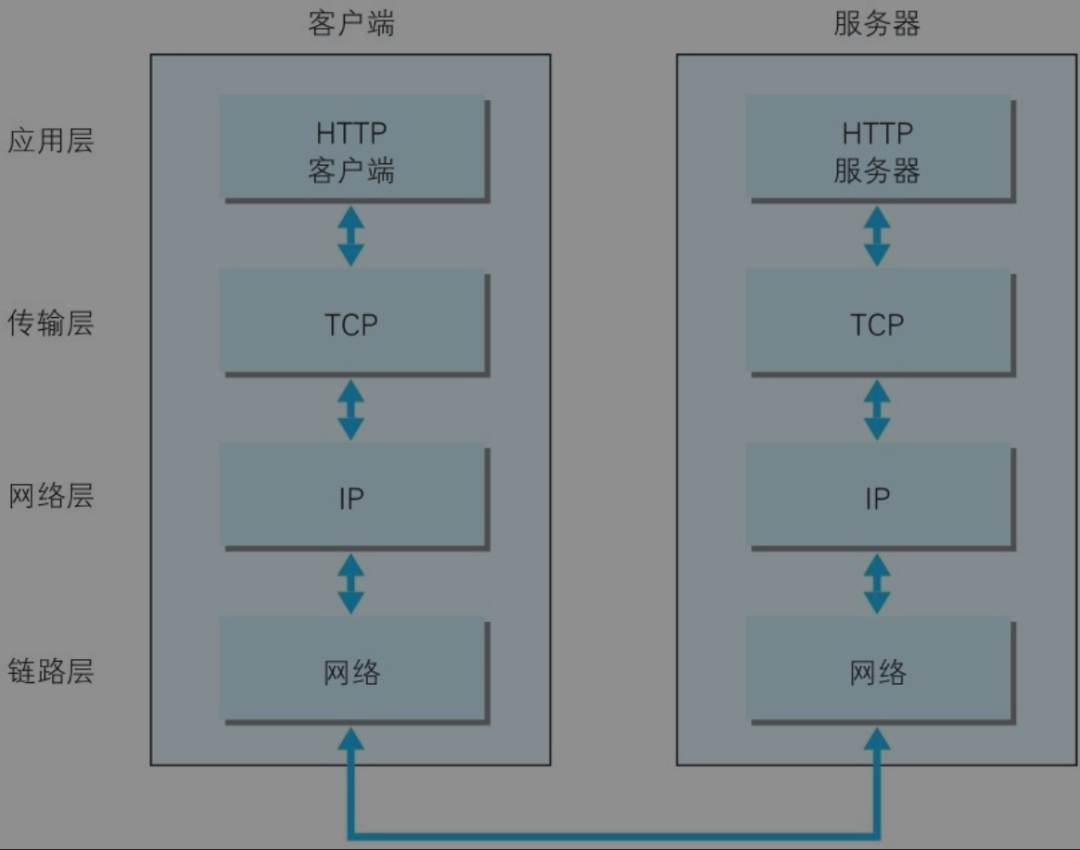
TCP/IP通信传输流
利用TCP/IP协议族进行网络通信时,会通过分层顺序与对方进行通信。发送端从应用层往下走,接收端则往应用层往上走。
我们用HTTP举例来说明,首先作为发送端的客户端在应用层(HTTP协议)发出一个想看某个Web页面的HTTP请求。
接着,为了传输方便,在传输层(TCP协议)把从应用层处收到的数据(HTTP请求报文)进行分割,并在各个报文上打上标记序号及端口号后转发给网络层。
在网络层(IP协议),增加作为通信目的地的MAC地址后转发给链路层。这样一来,发往网络的通信请求就准备齐全了。
接收端的服务器在链路层接收到数据,按序往上层发送,一直到应用层。当传输到应用层,才能算真正接收到由客户端发送过来的HTTP请求。
发送端在层与层之间传输数据时,每经过一层时必定会被打上一个该层所属的首部信息。反之,接收端在层与层传输数据时,每经过一层时会把对应的首部消去。
这种把数据信息包装起来的做法称为封装(encapsulate)。
与URI(统一资源标识符)相比,我们更熟悉URL(Uniform Resource Locator,统一资源定位符)。URL正是使用Web浏览器等访问Web页面时需要输入的网页地址。
URI是Uniform Resource Identifier的缩写。RFC2396分别对这3个单词进行了如下定义。
Uniform
规定统一的格式可方便处理多种不同类型的资源,而不用根据上下文环境来识别资源指定的访问方式。另外,加入新增的协议方案(如http:或ftp:)也更容易。
Resource
资源的定义是“可标识的任何东西”。不仅是文档文件,图像或服务(例如当天的天气预报)等能够区别于其他类型的,全都可作为资源。另外,资源不仅可以是单一的,也可以是多数的集合体。
Identifier
表示可标识的对象。也称为标识符。
综上所述,URI就是由某个协议方案表示的资源的定位标识符。协议方案是指访问资源所使用的协议类型名称。
采用HTTP协议时,协议方案就是http。除此之外,还有ftp、mailto、telnet、file等。标准的URI协议方案有30种左右,由隶属于国际互联网资源管理的非营利社团ICANN(Internet Corporation forAssigned Names and Numbers,互联网名称与数字地址分配机构)的IANA(Internet AssignedNumbers Authority,互联网号码分配局)管理颁布。
IANA - Uniform Resource Identifier (URI) SCHEMES(统一资源标识符方案)
http://www.iana.org/assignments/uri-schemesURI
用字符串标识某一互联网资源,而URL表示资源的地点(互联网上所处的位置)。
可见URL是URI的子集。
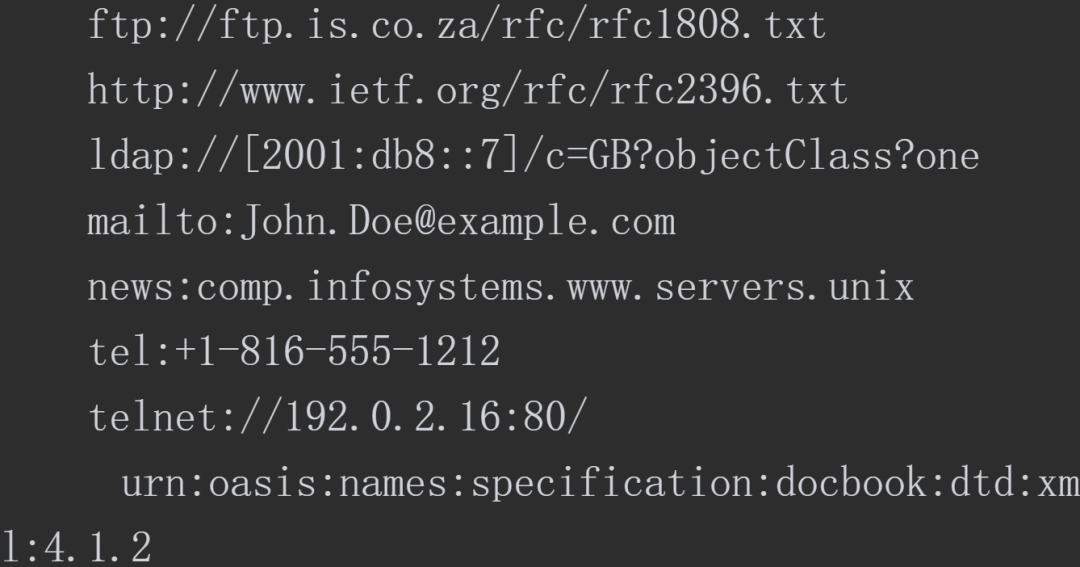
“RFC3986:统一资源标识符(URI)通用语法”中列举了几种URI例子,如下所示。

表示指定的URI,要使用涵盖全部必要信息的绝对URI、绝对URL以及相对URL。相对URL,是指从浏览器中基本URI处指定的URL,形如 /image/logo.gif。
协议方案名
使用http:或https:等协议方案名获取访问资源时要指定协议类型。不区分字母大小写,最后附一个冒号(:)。
也可使用data:或javascript:这类指定数据或脚本程序的方案名。
登录信息(认证)
指定用户名和密码作为从服务器端获取资源时必要的登录信息(身份认证)。此项是可选项。
服务器地址
使用绝对URI必须指定待访问的服务器地址。地址可以是类似hackr.jp这种DNS可解析的名称,或是192.168.1.1这类IPv4地址名,还可以是[0:0:0:0:0:0:0:1]这样用方括号括起来的IPv6地址名。
服务器端口号
指定服务器连接的网络端口号。此项也是可选项,若用户省略则自动使用默认端口号。
带层次的文件路径
指定服务器上的文件路径来定位特指的资源。这与UNIX系统的文件目录结构相似。
查询字符串
针对已指定的文件路径内的资源,可以使用查询字符串传入任意参数。此项可选。
片段标识符
使用片段标识符通常可标记出已获取资源中的子资源(文档内的某个位置)。但在RFC中并没有明确规定其使用方法。该项也为可选项。
HTTP协议通信通过请求和响应的交换达成通信
HTTP协议规定,请求从客户端发出,最后服务器端响应该请求并返回。换句话说,肯定是先从客户端开始建立通信的,服务器端在没有接收到请求之前不会发送响应。
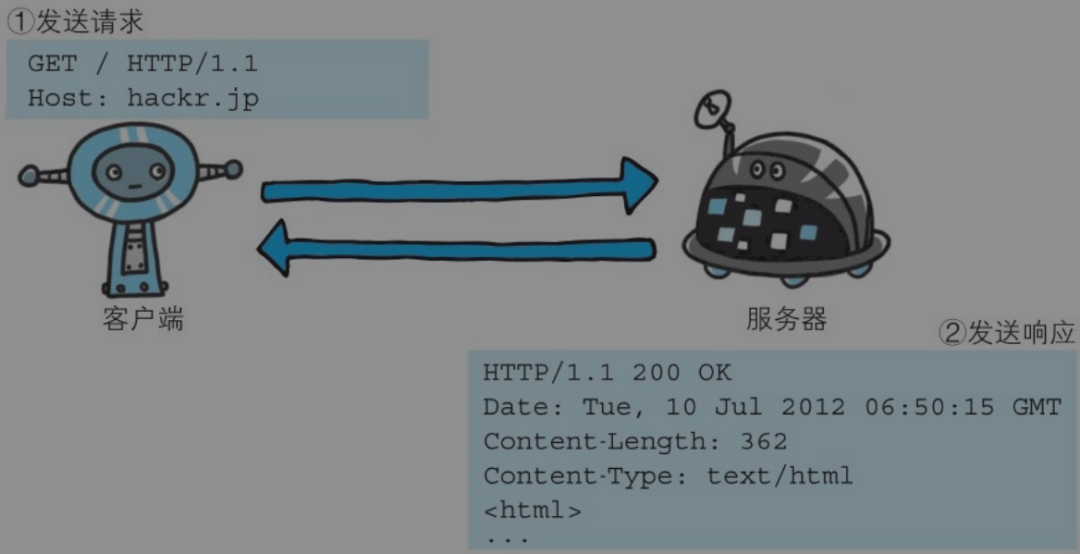
下面则是从客户端发送给某个HTTP服务器端的请求报文中的内容。
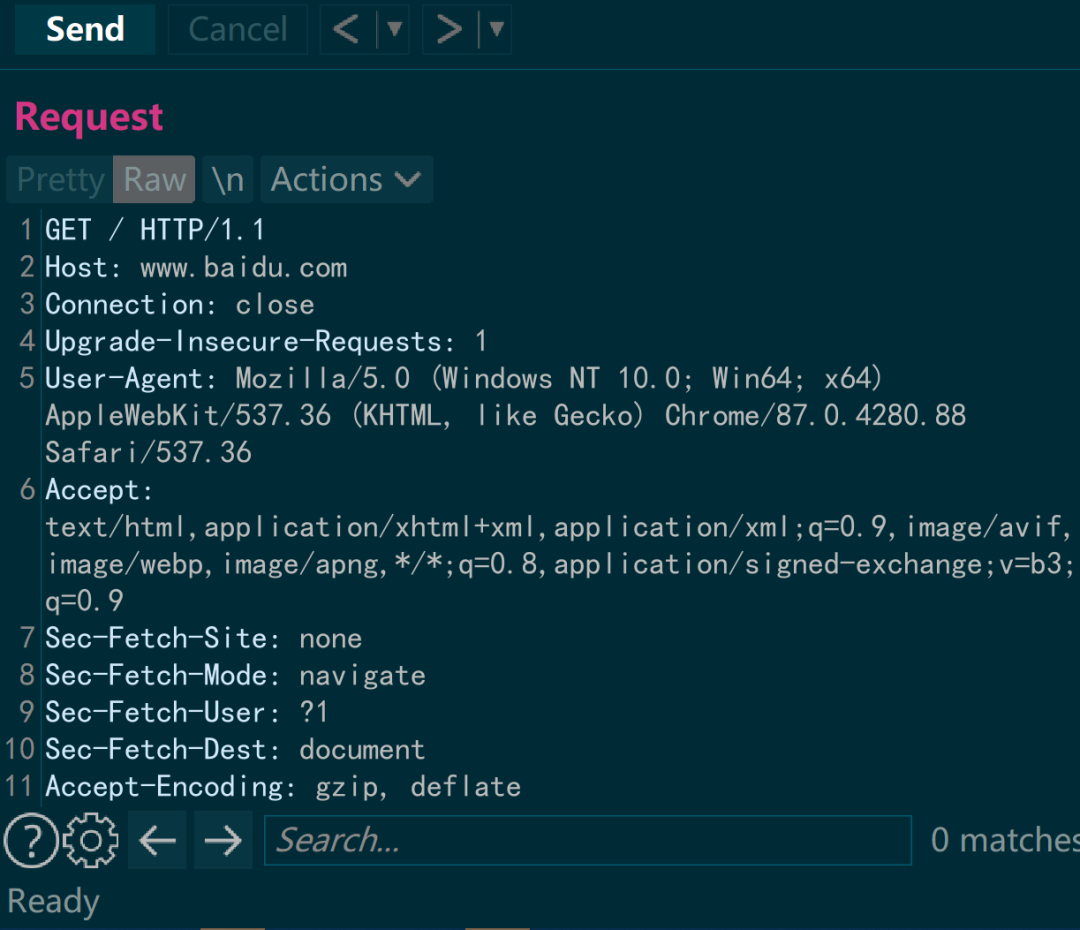
GET / HTTP/1.1
Host: www.baidu.com
Connection: close
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Sec-Fetch-Site: none
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9起始行开头的GET表示请求访问服务器的类型,称为方法(method)。随后的字符串/index.html指明了请求访问的资源对象,也叫做请求URI(request-URI)。最后的HTTP/1.1,即HTTP的版本号,用来提示客户端使用的HTTP协议功能。
综合来看,这段请求内容的意思是:请求访问百度HTTP服务器上的/index.html页面资源。
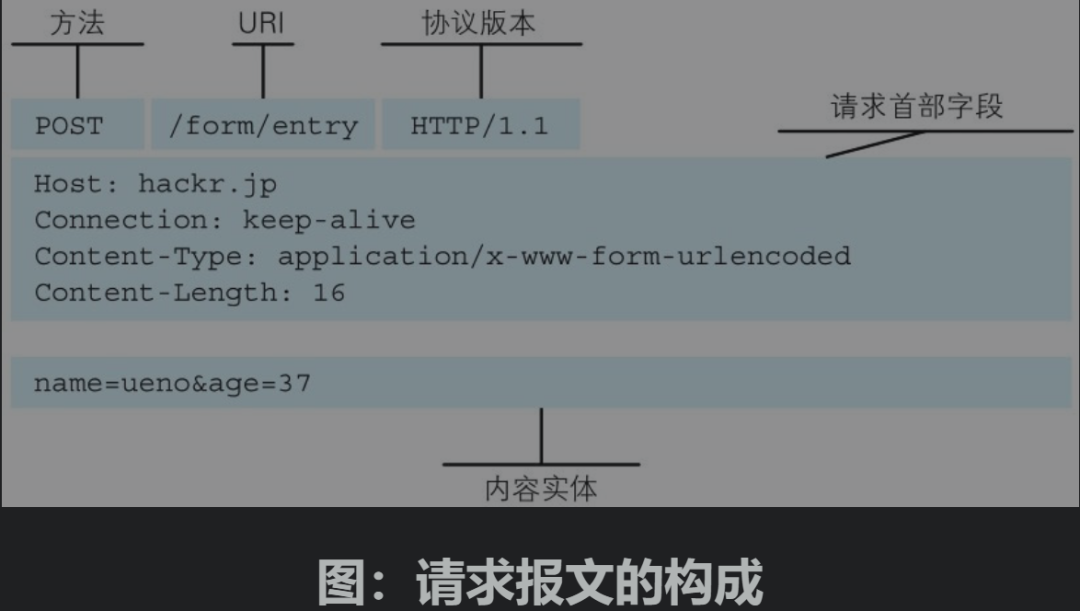
请求报文是由请求方法、请求URI、协议版本、可选的请求首部字段和内容实体构成的。
接收到请求的服务器,会将请求内容的处理结果以响应的形式返回。
在起始行开头的HTTP/1.1表示服务器对应的HTTP版本。
紧挨着的200 OK表示请求的处理结果的状态码(statuscode)和原因短语(reason-phrase)。下一行显示了创建响应的日期时间,是首部字段(header field)内的一个属性。
接着以一空行分隔,之后的内容称为资源实体的主体(entitybody)。
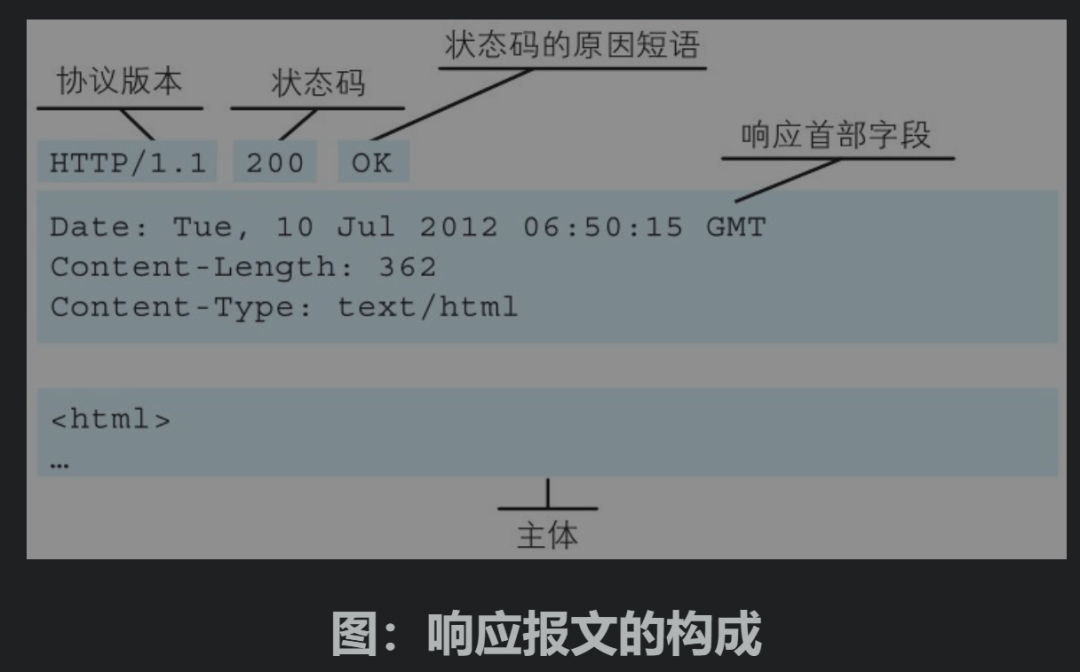
响应报文基本上由协议版本、状态码(表示请求成功或失败的数字代码)、用以解释状态码的原因短语、可选的响应首部字段以及实体主体构成。
告知服务器意图的HTTP方法
下面,我们介绍HTTP/1.1中可使用的方法。
GET:获取资源
GET方法用来请求访问已被URI识别的资源。指定的资源经服务器端解析后返回响应内容。也就是说,如果请求的资源是文本,那就保持原样返回;如果是像CGI(Common GatewayInterface,通用网关接口)那样的程序,则返回经过执行后的输出结果。
POST:传输实体主体
POST方法用来传输实体的主体。
虽然用GET方法也可以传输实体的主体,但一般不用GET方法进行传输,而是用POST方法。虽说POST的功能与GET很相似,但POST的主要目的并不是获取响应的主体内容。
PUT:传输文件
PUT方法用来传输文件。就像FTP协议的文件上传一样,要求在请求报文的主体中包含文件内容,然后保存到请求URI指定的位置。
但是,鉴于HTTP/1.1的PUT方法自身不带验证机制,任何人都可以上传文件,存在安全性问题,因此一般的Web网站不使用该方法。若配合Web应用程序的验证机制,或架构设计采用REST(Representational State Transfer,表征状态转移)标准的同类Web网站,就可能会开放使用PUT方法。
HEAD:获得报文首部
HEAD方法和GET方法一样,只是不返回报文主体部分。用于确认URI的有效性及资源更新的日期时间等。
DELETE:删除文件
DELETE方法用来删除文件,是与PUT相反的方法。DELETE方法按请求URI删除指定的资源。
但是,HTTP/1.1的DELETE方法本身和PUT方法一样不带验证机制,所以一般的Web网站也不使用DELETE方法。当配合Web应用程序的验证机制,或遵守REST标准时还是有可能会开放使用的。
OPTIONS:询问支持的方法
OPTIONS方法用来查询针对请求URI指定的资源支持的方法。
TRACE:追踪路径
TRACE方法是让Web服务器端将之前的请求通信环回给客户端的方法。
发送请求时,在Max-Forwards首部字段中填入数值,每经过一个服务器端就将该数字减1,当数值刚好减到0时,就停止继续传输,最后接收到请求的服务器端则返回状态码200 OK的响应。
客户端通过TRACE方法可以查询发送出去的请求是怎样被加工修改/篡改的。这是因为,请求想要连接到源目标服务器可能会通过代理中转,TRACE方法就是用来确认连接过程中发生的一系列操作。
但是,TRACE方法本来就不怎么常用,再加上它容易引发XST(Cross-Site Tracing,跨站追踪)攻击,通常就更不会用到了。
CONNECT:要求用隧道协议连接代理
CONNECT方法要求在与代理服务器通信时建立隧道,实现用隧道协议进行TCP通信。主要使用SSL(Secure SocketsLayer,安全套接层)和TLS(Transport Layer Security,传输层安全)协议把通信内容加密后经网络隧道传输。
HTTP报文
用于HTTP协议交互的信息被称为HTTP报文。请求端(客户端)的HTTP报文叫做请求报文,响应端(服务器端)的叫做响应报文。HTTP报文本身是由多行(用CR+LF作换行符)数据构成的字符串文本。
HTTP报文大致可分为报文首部和报文主体两块。两者由最初出现的空行(CR+LF)来划分。通常,并不一定要有报文主体。
请求报文和响应报文的首部内容由以下数据组成。
请求行
包含用于请求的方法,请求URI和HTTP版本。
状态行
包含表明响应结果的状态码,原因短语和HTTP版本。
首部字段
包含表示请求和响应的各种条件和属性的各类首部。一般有4种首部,分别是:通用首部、请求首部、响应首部和实体首部。
其他
可能包含HTTP的RFC里未定义的首部(Cookie等)。
状态码告知从服务器端返回的请求结果
状态码的职责是当客户端向服务器端发送请求时,描述返回的请求结果。借助状态码,用户可以知道服务器端是正常处理了请求,还是出现了错误。
状态码如200 OK,以3位数字和原因短语组成。
数字中的第一位指定了响应类别,后两位无分类。响应类别有以下5种。
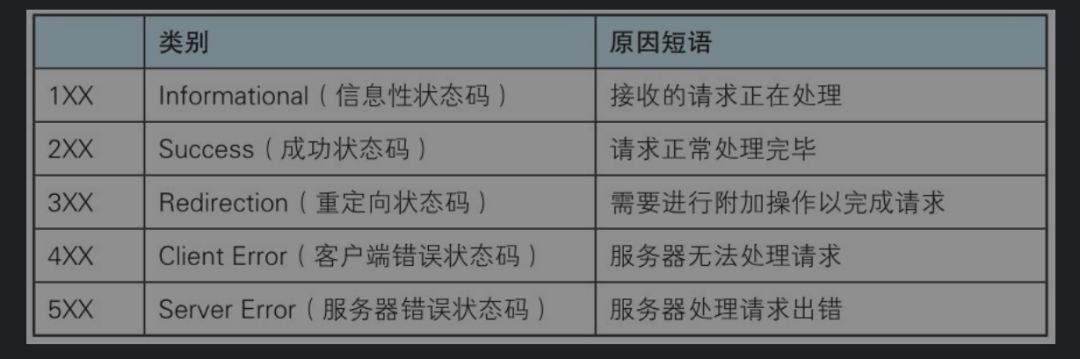
2XX成功
2XX的响应结果表明请求被正常处理了。
200 OK
表示从客户端发来的请求在服务器端被正常处理了。
在响应报文内,随状态码一起返回的信息会因方法的不同而发生改变。比如,使用GET方法时,对应请求资源的实体会作为响应返回;而使用HEAD方法时,对应请求资源的实体主体不随报文首部作为响应返回(即在响应中只返回首部,不会返回实体的主体部分)。
201 Created
成功请求并创建了新的资源,该请求已经被实现,而且有一个新的资源已经依据请求的需要而建立,且其 URI 已经随Location 头信息返回。
204 No Content
该状态码代表服务器接收的请求已成功处理,但在返回的响应报文中不含实体的主体部分。另外,也不允许返回任何实体的主体。比如,当从浏览器发出请求处理后,返回204响应,那么浏览器显示的页面不发生更新。
一般在只需要从客户端往服务器发送信息,而对客户端不需要发送新信息内容的情况下使用。
206 Partial Content
该状态码表示客户端进行了范围请求,而服务器成功执行了这部分的GET请求。响应报文中包含由Content-Range指定范围的实体内容。
3XX重定向
3XX响应结果表明浏览器需要执行某些特殊的处理以正确处理请求。
301 Moved Permanently
永久性重定向。该状态码表示请求的资源已被分配了新的URI,以后应使用资源现在所指的URI。也就是说,如果已经把资源对应的URI保存为书签了,这时应该按Location首部字段提示的URI重新保存。
像下方给出的请求URI,当指定资源路径的最后忘记添加斜杠“/”,就会产生301状态码。
302 Found
临时性重定向。该状态码表示请求的资源已被分配了新的URI,希望用户(本次)能使用新的URI访问。
和301 Moved Permanently状态码相似,但302状态码代表的资源不是被永久移动,只是临时性质的。换句话说,已移动的资源对应的URI将来还有可能发生改变。比如,用户把URI保存成书签,但不会像301状态码出现时那样去更新书签,而是仍旧保留返回302状态码的页面对应的URI。
303 See Other
该状态码表示由于请求对应的资源存在着另一个URI,应使用GET方法定向获取请求的资源。
303状态码和302 Found状态码有着相同的功能,但303状态码明确表示客户端应当采用GET方法获取资源,这点与302状态码有区别。
比如,当使用POST方法访问CGI程序,其执行后的处理结果是希望客户端能以GET方法重定向到另一个URI上去时,返回303状态码。虽然302 Found状态码也可以实现相同的功能,但这里使用303状态码是最理想的。
当301、302、303响应状态码返回时,几乎所有的浏览器都会把POST改成GET,并删除请求报文内的主体,之后请求会自动再次发送。
301、302标准是禁止将POST方法改变成GET方法的,但实际使用时大家都会这么做。
304 Not Modified
该状态码表示客户端发送附带条件的请求[插图]时,服务器端允许请求访问资源,但因发生请求未满足条件的情况后,直接返回304 Not Modified(服务器端资源未改变,可直接使用客户端未过期的缓存)。304状态码返回时,不包含任何响应的主体部分。304虽然被划分在3XX类别中,但是和重定向没有关系。
307 Temporary Redirect
临时重定向。该状态码与302 Found有着相同的含义。尽管302标准禁止POST变换成GET,但实际使用时大家并不遵守。
307会遵照浏览器标准,不会从POST变成GET。但是,对于处理响应时的行为,每种浏览器有可能出现不同的情况。
4XX客户端错误
4XX的响应结果表明客户端是发生错误的原因所在。
400 Bad Request
该状态码表示请求报文中存在语法错误。当错误发生时,需修改请求的内容后再次发送请求。另外,浏览器会像200 OK一样对待该状态码。
401 Unauthorized
该状态码表示发送的请求需要有通过HTTP认证(BASIC认证、DIGEST认证)的认证信息。另外若之前已进行过1次请求,则表示用户认证失败。
返回含有401的响应必须包含一个适用于被请求资源的WWW-Authenticate首部用以质询(challenge)用户信息。当浏览器初次接收到401响应,会弹出认证用的对话窗口。
403 Forbidden
该状态码表明对请求资源的访问被服务器拒绝了。服务器端没有必要给出拒绝的详细理由,但如果想作说明的话,可以在实体的主体部分对原因进行描述,这样就能让用户看到了。
未获得文件系统的访问授权,访问权限出现某些问题(从未授权的发送源IP地址试图访问)等列举的情况都可能是发生403的原因。
404 Not Found
该状态码表明服务器上无法找到请求的资源。除此之外,也可以在服务器端拒绝请求且不想说明理由时使用。
405 Method Not Allowed
请求行中指定的请求方法不能被用于请求相应的资源。该响应必须返回一个Allow 头信息用以表示出当前资源能够接受的请求方法的列表。
鉴于 PUT,DELETE 方法会对服务器上的资源进行写操作,因而绝大部分的网页服务器都不支持或者在默认配置下不允许上述请求方法,对于此类请求均会返回405错误。
5XX服务器错误
5XX的响应结果表明服务器本身发生错误。
500 Internal Server Error
该状态码表明服务器端在执行请求时发生了错误。也有可能是Web应用存在的bug或某些临时的故障。
502 Bad Gateway
服务器作为网关或代理,从上游服务器收到无效响应。
503 Service Unavailable
该状态码表明服务器暂时处于超负载或正在进行停机维护,现在无法处理请求。如果事先得知解除以上状况需要的时间,最好写入Retry-After首部字段再返回给客户端。
状态码和状况的不一致
不少返回的状态码响应都是错误的,但是用户可能察觉不到这点。比如Web应用程序内部发生错误,状态码依然返回200 OK,这种情况也经常遇到。
HTTP报文首部
HTTP协议的请求和响应报文中必定包含HTTP首部。首部内容为客户端和服务器分别处理请求和响应提供所需要的信息。对于客户端用户来说,这些信息中的大部分内容都无须亲自查看。
报文首部由几个字段构成。
HTTP请求报文
在请求中,HTTP报文由方法、URI、HTTP版本、HTTP首部字段等部分构成。
HTTP响应报文
在响应中,HTTP报文由HTTP版本、状态码(数字和原因短语)、HTTP首部字段3部分构成。
在报文众多的字段当中,HTTP首部字段包含的信息最为丰富。首部字段同时存在于请求和响应报文内,并涵盖HTTP报文相关的内容信息。
因HTTP版本或扩展规范的变化,首部字段可支持的字段内容略有不同。本书主要涉及HTTP/1.1及常用的首部字段。
HTTP首部字段传递重要信息
HTTP首部字段是构成HTTP报文的要素之一。在客户端与服务器之间以HTTP协议进行通信的过程中,无论是请求还是响应都会使用首部字段,它能起到传递额外重要信息的作用。
使用首部字段是为了给浏览器和服务器提供报文主体大小、所使用的语言、认证信息等内容。
HTTP首部字段结构
HTTP首部字段是由首部字段名和字段值构成的,中间用冒号“:”分隔。
4种HTTP首部字段类型
通用首部字段(General Header Fields)
请求报文和响应报文两方都会使用的首部。
通用首部字段是指,请求报文和响应报文双方都会使用的首部。
Cache-Control
通过指定首部字段Cache-Control的指令,就能操作缓存的工作机制。
Connection
Connection首部字段具备如下两个作用。
●控制不再转发给代理的首部字段
●管理持久连接
Date
首部字段Date表明创建HTTP报文的日期和时间。
Transfer-Encoding
首部字段Transfer-Encoding规定了传输报文主体时采用的编码方式。
HTTP/1.1的传输编码方式仅对分块传输编码有效。
Upgrade
首部字段Upgrade用于检测HTTP协议及其他协议是否可使用更高的版本进行通信,其参数值可以用来指定一个完全不同的通信协议。
请求首部字段(Request Header Fields)
从客户端向服务器端发送请求报文时使用的首部。补充了请求的附加内容、客户端信息、响应内容相关优先级等信息。
请求首部字段是从客户端往服务器端发送请求报文中所使用的字段,用于补充请求的附加信息、客户端信息、对响应内容相关的优先级等内容。
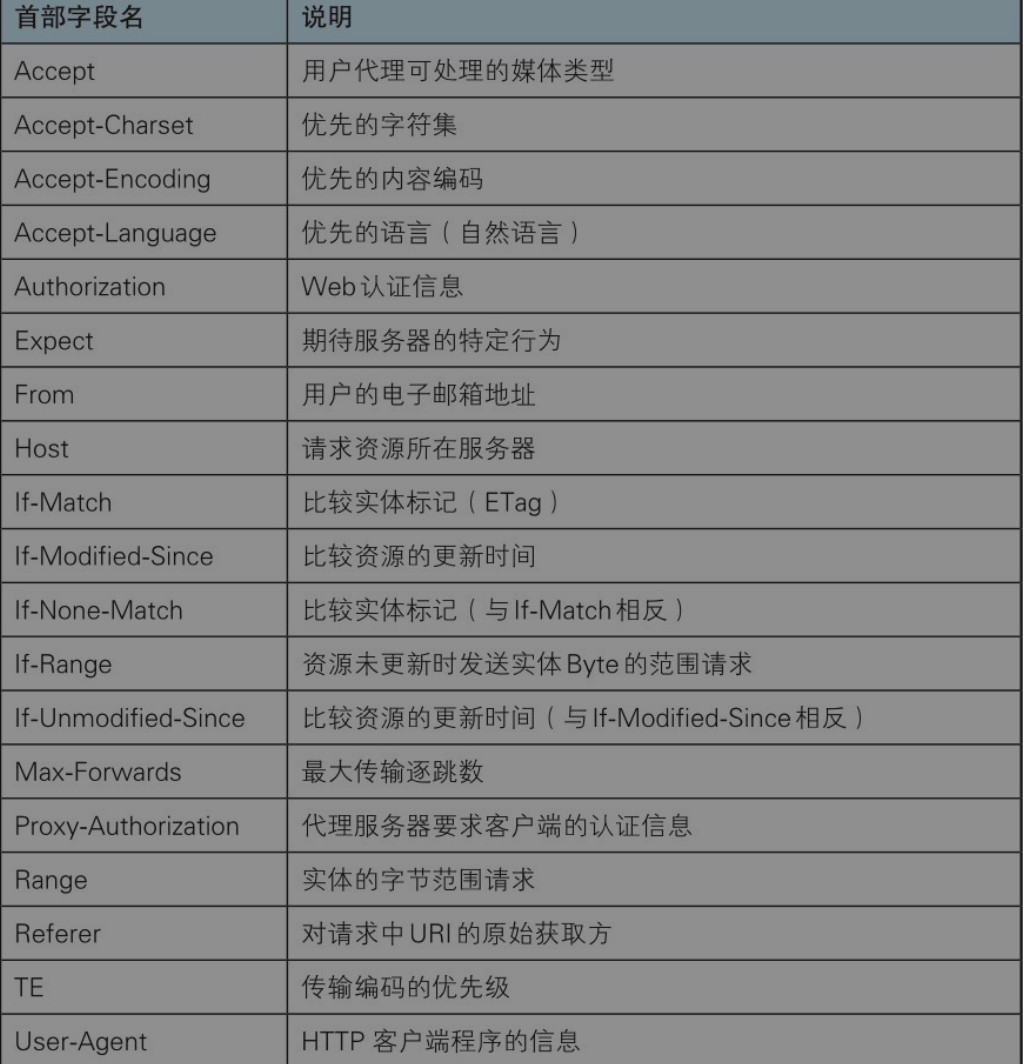
Accept
Accept首部字段可通知服务器,用户代理能够处理的媒体类型及媒体类型的相对优先级。可使用type/subtype这种形式,一次指定多种媒体类型。
文本文件
text/html, text/plain, text/css ...
application/xhtml+xml, application/xml ...
图片文件
image/jpeg, image/gif, image/png ...
视频文件
video/mpeg, video/quicktime ...
应用程序使用的二进制文件
application/octet-stream, application/zip ...
比如,如果浏览器不支持PNG图片的显示,那Accept就不指定image/png,而指定可处理的image/gif和image/jpeg等图片类型。
若想要给显示的媒体类型增加优先级,则使用q=来额外表示权重值,用分号(;)进行分隔。权重值q的范围是0~1(可精确到小数点后3位),且1为最大值。不指定权重q值时,默认权重为q=1.0。
Accept-Charset
Accept-Charset首部字段可用来通知服务器用户代理支持的字符集及字符集的相对优先顺序。另外,可一次性指定多种字符集。与首部字段Accept相同的是可用权重q值来表示相对优先级。
该首部字段应用于内容协商机制的服务器驱动协商。
Accept-Encoding
Accept-Encoding首部字段用来告知服务器用户代理支持的内容编码及内容编码的优先级顺序。可一次性指定多种内容编码。
下面试举出几个内容编码的例子。
Gzip
由文件压缩程序gzip(GNU zip)生成的编码格式(RFC1952),采用Lempel-Ziv算法(LZ77)及32位循环冗余校验(Cyclic Redundancy Check,通称CRC)。
Accept-Language
首部字段Accept-Language用来告知服务器用户代理能够处理的自然语言集(指中文或英文等),以及自然语言集的相对优先级。可一次指定多种自然语言集。
和Accept首部字段一样,按权重值q来表示相对优先级。在上述图例中,客户端在服务器有中文版资源的情况下,会请求其返回中文版对应的响应,没有中文版时,则请求返回英文版响应。
Authorization
首部字段Authorization是用来告知服务器,用户代理的认证信息(证书值)。通常,想要通过服务器认证的用户代理会在接收到返回的401状态码响应后,把首部字段Authorization加入请求中。共用缓存在接收到含有Authorization首部字段的请求时的操作处理会略有差异。
Host
首部字段Host会告知服务器,请求的资源所处的互联网主机名和端口号。Host首部字段在HTTP/1.1规范内是唯一一个必须被包含在请求内的首部字段。
首部字段Host和以单台服务器分配多个域名的虚拟主机的工作机制有很密切的关联,这是首部字段Host必须存在的意义。
请求被发送至服务器时,请求中的主机名会用IP地址直接替换解决。但如果这时,相同的IP地址下部署运行着多个域名,那么服务器就会无法理解究竟是哪个域名对应的请求。因此,就需要使用首部字段Host来明确指出请求的主机名。若服务器未设定主机名,那直接发送一个空值即可。
Referer
首部字段Referer会告知服务器请求的原始资源的URI。
客户端一般都会发送Referer首部字段给服务器。但当直接在浏览器的地址栏输入URI,或出于安全性的考虑时,也可以不发送该首部字段。
因为原始资源的URI中的查询字符串可能含有ID和密码等保密信息,要是写进Referer转发给其他服务器,则有可能导致保密信息的泄露。
注意:Referer的正确的拼写应该是Referrer,但不知为何,大家一直沿用这个错误的拼写。
User-Agent
首部字段User-Agent会将创建请求的浏览器和用户代理名称等信息传达给服务器。
由网络爬虫发起请求时,有可能会在字段内添加爬虫作者的电子邮件地址。此外,如果请求经过代理,那么中间也很可能被添加上代理服务器的名称。
响应首部字段(Response Header Fields)
从服务器端向客户端返回响应报文时使用的首部。补充了响应的附加内容,也会要求客户端附加额外的内容信息。
响应首部字段是由服务器端向客户端返回响应报文中所使用的字段,用于补充响应的附加信息、服务器信息,以及对客户端的附加要求等信息。
Location
使用首部字段Location可以将响应接收方引导至某个与请求URI位置不同的资源。
基本上,该字段会配合3xx:Redirection的响应,提供重定向的URI。
几乎所有的浏览器在接收到包含首部字段Location的响应后,都会强制性地尝试对已提示的重定向资源的访问。
Server
首部字段Server告知客户端当前服务器上安装的HTTP服务器应用程序的信息。不单单会标出服务器上的软件应用名称,还有可能包括版本号和安装时启用的可选项。
实体首部字段(Entity Header Fields)
针对请求报文和响应报文的实体部分使用的首部。补充了资源内容更新时间等与实体有关的信息。
实体首部字段是包含在请求报文和响应报文中的实体部分所使用的首部,用于补充内容的更新时间等与实体相关的信息。
Allow
首部字段Allow用于通知客户端能够支持Request-URI指定资源的所有HTTP方法。当服务器接收到不支持的HTTP方法时,会以状态码405 Method Not Allowed作为响应返回。与此同时,还会把所有能支持的HTTP方法写入首部字段Allow后返回。
Content-Encoding
首部字段Content-Encoding会告知客户端服务器对实体的主体部分选用的内容编码方式。内容编码是指在不丢失实体信息的前提下所进行的压缩。
Content-Language
首部字段Content-Language会告知客户端,实体主体使用的自然语言(指中文或英文等语言)。
Content-Length
首部字段Content-Length表明了实体主体部分的大小(单位是字节)。对实体主体进行内容编码传输时,不能再使用Content-Length首部字段。
Content-Type
首部字段Content-Type说明了实体主体内对象的媒体类型。和首部字段Accept一样,字段值用type/subtype形式赋值。
Last-Modified
首部字段Last-Modified指明资源最终修改的时间。一般来说,这个值就是Request-URI指定资源被修改的时间。但类似使用CGI脚本进行动态数据处理时,该值有可能会变成数据最终修改时的时间。
其他首部字段
HTTP首部字段是可以自行扩展的。所以在Web服务器和浏览器的应用上,会出现各种非标准的首部字段。
X-Frame-Options
首部字段X-Frame-Options属于HTTP响应首部,用于控制网站内容在其他Web网站的Frame标签内的显示问题。其主要目的是为了防止点击劫持(clickjacking)攻击。
首部字段X-Frame-Options有以下两个可指定的字段值。
DENY:拒绝
SAMEORIGIN:仅同源域名下的页面(Top-level-browsing-context)匹配时许可。(比如,当指定http://hackr.jp/sample.html页面为SAMEORIGIN时,那么hackr.jp上所有页面的frame都被允许可加载该页面,而example.com等其他域名的页面就不行了)

能在所有的Web服务器端预先设定好X-Frame-Options字段值是最理想的状态。
X-XSS-Protection
首部字段X-XSS-Protection属于HTTP响应首部,它是针对跨站脚本攻击(XSS)的一种对策,用于控制浏览器XSS防护机制的开关。
首部字段X-XSS-Protection可指定的字段值如下。
● 0 :将XSS过滤设置成无效状态
● 1 :将XSS过滤设置成有效状态
HTTP+加密+认证+完整性保护=HTTPS
HTTP加上加密处理和认证以及完整性保护后即是HTTPS
如果在HTTP协议通信过程中使用未经加密的明文,比如在Web页面中输入信用卡号,如果这条通信线路遭到窃听,那么信用卡号就暴露了。
另外,对于HTTP来说,服务器也好,客户端也好,都是没有办法确认通信方的。因为很有可能并不是和原本预想的通信方在实际通信。并且还需要考虑到接收到的报文在通信途中已经遭到篡改这一可能性。
为了统一解决上述这些问题,需要在HTTP上再加入加密处理和认证等机制。我们把添加了加密及认证机制的HTTP称为HTTPS(HTTP Secure)。
经常会在Web的登录页面和购物结算界面等使用HTTPS通信。使用HTTPS通信时,不再用http://,而是改用https://。另外,当浏览器访问HTTPS通信有效的Web网站时,浏览器的地址栏内会出现一个带锁的标记。对HTTPS的显示方式会因浏览器的不同而有所改变。
HTTPS是身披SSL外壳的HTTP
HTTPS并非是应用层的一种新协议。只是HTTP通信接口部分用SSL(Secure Socket Layer)和TLS(Transport LayerSecurity)协议代替而已。
通常,HTTP直接和TCP通信。当使用SSL时,则演变成先和SSL通信,再由SSL和TCP通信了。简言之,所谓HTTPS,其实就是身披SSL协议这层外壳的HTTP。
在采用SSL后,HTTP就拥有了HTTPS的加密、证书和完整性保护这些功能。
SSL是独立于HTTP的协议,所以不光是HTTP协议,其他运行在应用层的SMTP和Telnet等协议均可配合SSL协议使用。可以说SSL是当今世界上应用最为广泛的网络安全技术。
HTTPS的安全通信机制
为了更好地理解HTTPS,我们来观察一下HTTPS的通信步骤。
步骤1:客户端通过发送Client Hello报文开始SSL通信。报文中包含客户端支持的SSL的指定版本、加密组件(Cipher Suite)列表(所使用的加密算法及密钥长度等)。
步骤2:服务器可进行SSL通信时,会以Server Hello报文作为应答。和客户端一样,在报文中包含SSL版本以及加密组件。服务器的加密组件内容是从接收到的客户端加密组件内筛选出来的。
步骤3:之后服务器发送Certificate报文。报文中包含公开密钥证书。
步骤4:最后服务器发送Server Hello Done报文通知客户端,最初阶段的SSL握手协商部分结束。
步骤5: SSL第一次握手结束之后,客户端以Client KeyExchange报文作为回应。报文中包含通信加密中使用的一种被称为Pre-master secret的随机密码串。该报文已用步骤3中的公开密钥进行加密。
步骤6:接着客户端继续发送Change Cipher Spec报文。该报文会提示服务器,在此报文之后的通信会采用Pre-master secret密钥加密。
步骤7:客户端发送Finished报文。该报文包含连接至今全部报文的整体校验值。这次握手协商是否能够成功,要以服务器是否能够正确解密该报文作为判定标准。
步骤8:服务器同样发送Change Cipher Spec报文。
步骤9:服务器同样发送Finished报文。
步骤10:服务器和客户端的Finished报文交换完毕之后,SSL连接就算建立完成。当然,通信会受到SSL的保护。从此处开始进行应用层协议的通信,即发送HTTP请求。
步骤11:应用层协议通信,即发送HTTP响应。
步骤12:最后由客户端断开连接。断开连接时,发送close_notify报文。上图做了一些省略,这步之后再发送TCP FIN报文来关闭与TCP的通信。
在以上流程中,应用层发送数据时会附加一种叫做MAC(Message Authentication Code)的报文摘要。MAC能够查知报文是否遭到篡改,从而保护报文的完整性。
为什么不一直使用HTTPS
既然HTTPS那么安全可靠,那为何所有的Web网站不一直使用HTTPS?
其中一个原因是,因为与纯文本通信相比,加密通信会消耗更多的CPU及内存资源。如果每次通信都加密,会消耗相当多的资源,平摊到一台计算机上时,能够处理的请求数量必定也会随之减少。
因此,如果是非敏感信息则使用HTTP通信,只有在包含个人信息等敏感数据时,才利用HTTPS加密通信。
特别是每当那些访问量较多的Web网站在进行加密处理时,它们所承担着的负载不容小觑。在进行加密处理时,并非对所有内容都进行加密处理,而是仅在那些需要信息隐藏时才会加密,以节约资源。
除此之外,想要节约购买证书的开销也是原因之一。
要进行HTTPS通信,证书是必不可少的。而使用的证书必须向认证机构(CA)购买。证书价格可能会根据不同的认证机构略有不同。
那些购买证书并不合算的服务以及一些个人网站,可能只会选择采用HTTP的通信方式。
更多内容参考:《图解HTTP》
https://weread.qq.com/web/reader/3da32b505dd9f43da9a1aca