最近公司做服务配置检查,特别是zookeeper配置里面关于数据库、redis、域名的配置。刚好还没弄过XML解析,所以顺手封装了一个工具类。
XML文件解析分四类方式:「DOM解析」;「SAX解析」;「JDOM解析」;「DOM4J解析」。其中前两种属于基础方法,是官方提供的平台无关的解析方式;后两种属于扩展方法,它们是在基础的方法上扩展出来的,只适用于java平台。
权衡之后我先选择了「DOM解析」,因为文件不大(1万行),只是一次性的脚本,不存在性能方面的考虑。
语言我依然采用了Groovy模式,不能不说太好用了,之前讲过如何在两个小时内容从Java过渡到Groovy,有兴趣的同学可以去看看:从Java到Groovy的八级进化论。还有更多高级特性实践可以在公众号里面搜Groovy即可,包括在JMeter中支持Java(即Groovy)脚本。
xml文件内容(已删节);
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <root path="/xdfapp"> <zknode name="DCSS" value="38d9ab9f3e7b424324cea3e42fb1237f9e73bdb"> <zknode name="v1.0$"> <zknode name="unchange"> <zknode name="datadb.database" value="Export from zookeeper configuration group: [/xdfapp/DCSS] - [v1.0] - [unchange]."/> <zknode name="redis.host"/> <zknode name="db.host.w"/> <zknode name="datadb.password" value="127.0.0.1"/> <zknode name="datadb.host.r"/> <zknode name="db.host.r"/> <zknode name="datadb.host.w"/> </zknode> </zknode> </zknode> </root>
下面分享Demo:
package com.fun.ztest.groovyimport com.fun.base.bean.AbstractBean
import com.fun.base.exception.FailException
import com.fun.frame.SourceCode
import org.slf4j.Logger
import org.slf4j.LoggerFactory
import org.w3c.dom.Document
import org.w3c.dom.NamedNodeMap
import org.w3c.dom.Node
import org.w3c.dom.NodeList
import org.xml.sax.SAXExceptionimport javax.xml.parsers.DocumentBuilder
import javax.xml.parsers.DocumentBuilderFactory
import javax.xml.parsers.ParserConfigurationExceptionclass XMLUtil extends SourceCode {
private static Logger logger = LoggerFactory.getLogger(XMLUtil.class) public static void main(String[] args) { def xml = parseXml("/Users/fv/Downloads/dev.xml", "root") output(xml) } public static List<NodeInfo> parseXml(String path, String root) { NodeList nodes = parseRoot(path, root) return range(nodes.getLength()).mapToObj {x -> parseNode(nodes.item(x))}.collect() as List } public static NodeList parseRoot(String path, String root) { DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance() try { DocumentBuilder db = dbf.newDocumentBuilder() Document document = db.parse(new File(path)) NodeList bookList = document.getElementsByTagName(root) return bookList } catch (ParserConfigurationException e) { logger.error("解析配置错误!", e) } catch (IOException e) { logger.error("IO错误!", e) } catch (SAXException e) { logger.error("SAX错误!", e) } FailException.fail("解析文件:${path}中${root}节点出错!") } public static NodeInfo parseNode(Node node) { if (node.getNodeType() != node.ELEMENT_NODE) return null NodeInfo nodeInfo = new NodeInfo() NamedNodeMap attrs = node.getAttributes() List<Attr> nodeAttr = new ArrayList<>() range(attrs.getLength()).each { Node attr = attrs.item(it) String nodeName = attr.getNodeName() String nodeValue = attr.getNodeValue() Attr e = new Attr(nodeName, nodeValue) nodeAttr.add(e) } nodeInfo.arrts = nodeAttr short nodeType = node.getNodeType() if (nodeType != Node.ELEMENT_NODE) return nodeInfo NodeList childNodes = node.getChildNodes() List<NodeInfo> children = new ArrayList<>() childNodes.getLength() range(childNodes.getLength()).each {children.add(parseNode(childNodes.item(it)))} nodeInfo.children = children.findAll {it != null} return nodeInfo } static class NodeInfo extends AbstractBean { private static final long serialVersionUID = 568896512159847L List<Attr> arrts List<NodeInfo> children } static class Attr extends AbstractBean { private static final long serialVersionUID = -35484487563215649L String name String value public Attr(String name, String value) { this.name = name this.value = value } }}
控制台输出:
内容较多,分成了头尾两张。
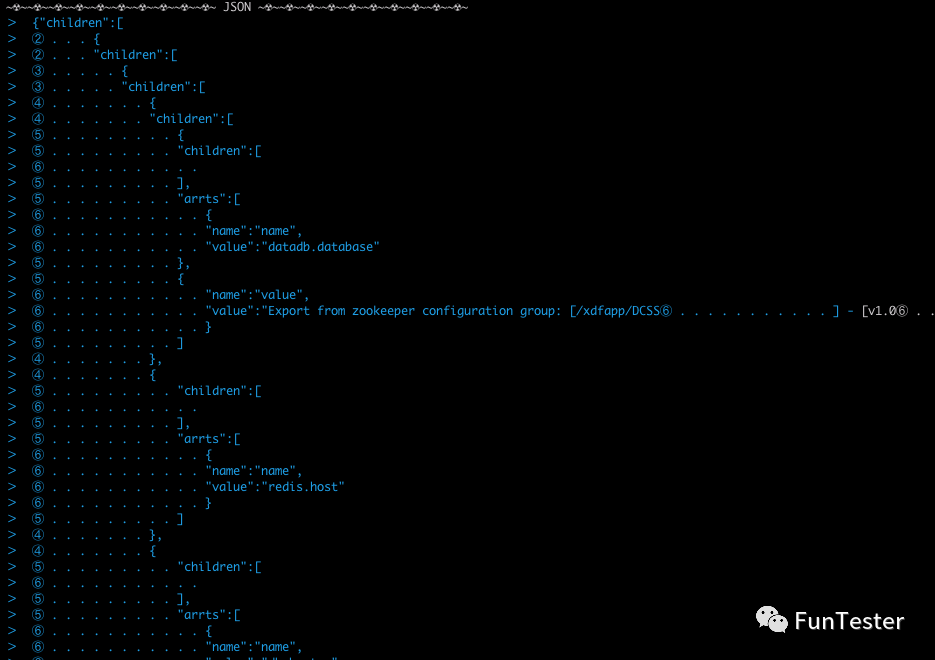
头部图片

尾部图片
公众号「FunTester」首发,原创分享爱好者,腾讯云和掘金社区首页推荐,知乎七级原创作者,欢迎关注、交流,禁止第三方擅自转载。