本文分享了腾讯云某业务基于 DeepFlow 的可观测性实践。面对复杂的业务服务(800+)和多样的编程语言,腾讯云某业务团队选择了 DeepFlow 作为跨语言、无侵入的可观测技术。与其他技术(如 Hubble 和 Pixie)相比,DeepFlow 在数据指标、协议支持和扩展能力等方面表现优异,成为最佳选择。引入 DeepFlow 后,腾讯云通过与现有系统的集成,实现了统一的服务性能监控和高效的故障排查能力,显著提升了运维效率,甚至能主动发现业务隐藏的 Bug,防范于未然。
01
观测挑战
腾讯云某业务平台业务服务涉及范围广泛,包含超过 800 个不同服务。这些服务由不同的业务团队开发,使用了多种编程语言和技术栈(如 C++、PHP、Go),并且服务调用链路非常复杂。这种复杂性为平台的运维和故障排查带来了极大的挑战。

我们团队的任务是为客户高效交付这些服务,因此需要提供强大的可观测性工具。然而,由于业务涉及的团队众多,推行业务代码修改几乎不可能完成。因此,我们需要一种跨语言、无侵入的可观测技术。我们希望这项技术能解决我们如下的问题:
- 全局服务性能监控:目前各业务自行实现的监控系统仅限于各自的服务范围,缺少一个统一的服务性能监控平台,无法快速定位并分析服务请求的性能问题。例如,当某个服务响应变慢时,现有系统无法迅速指出具体的瓶颈和耗时情况。
- 丰富问题排查数据:目前问题排查主要依赖日志分析。当调用链很长或者日志信息不详细时,排查问题变得非常耗时且复杂。缺乏一个可观测平台来快速定位问题发生点,导致排查效率低下。
02
技术选型
在最初的技术选型阶段,我们考虑了以下几种方案:Hubble、Pixie 以及 DeepFlow。我们分别从软件架构及产品能力两个维度对比了组件,我们最终选择了 DeepFlow。
软件架构 | Cilium/Hubble | Pixie | DeepFlow |
|---|---|---|---|
CNI 依赖 | 依赖Cilium | 无 | 无 |
eBPF 依赖 | 依赖 eBPF | 依赖 eBPF | 仅调用链追踪、SSL/TLS 解密依赖 eBPF |
后端存储 | 使用 Prometheus 存储指标数据,不存储拓扑和日志数据 | 短期存储在 Node 节点,长期则需要将数据通过 OTel 格式发送出去 | 基于 ClickHouse 有完整的存储解决方案 |
数据标签 | 不支持自定义标签、开销大 | 支持 K8s 资源标签,开销大 | 支持 K8s 资源/K8s label 标签、开销低 |
从软件架构层面,我们优先选择了 DeepFlow,主要的考虑目前部署环境并不是全部都能满足 eBPF 采集所需要的内核;对于存储,我们是需要稳定且成熟的解决方案。
产品能力 | Cilium/Hubble | Pixie | DeepFlow | 说明 |
|---|---|---|---|---|
服务拓扑 | 有 | 有 | <mark>有(维度更丰富)</mark> | -- |
应用指标 | 有 | 有 | <mark>有(协议更丰富)</mark> | Hubble 支持 HTTP/DNS/Kafka协议; Pixie 支持常见的 HTTP/DNS/MySQL/Kafka 等协议; DeepFlow 支持的协议更丰富,也支持 WASM 插件自定义协议解析 |
应用调用日志 | 无 | <mark>有(含 HTTP Body)</mark> | 有 | Pixie 默认可查看 HTTP 协议的 body 信息 |
应用调用链追踪 | 无 | 无 | 有 | DeepFlow 既支持自动分布式追踪,也支持与已有 APM 的 Span 融合 |
网络指标 | 有 | 有 | <mark>有(指标更丰富)</mark> | Hubble 只有流量/包量统计; Pixie 比 Hubble 主要多了 TCP 重传的统计; DeepFlow 指标更丰富,还涉及时延、异常、性能的指标 |
网络路径拓扑 | 无 | 有 | <mark>有(维度更丰富)</mark> | -- |
网络流日志 | 有 | 无 | 有 | Hubble 可根据网络安全策略标记记录是否丢弃; DeepFlow 可给流增加更多的标签和指标 |
总结来说,我们也选择 DeepFlow 大概出于如下几点考虑:
- 丰富的数据指标:涵盖应用层的请求、错误、响应和数据包大小等指标,以及网络层的流量、TCP 建连时延和传输异常等指标。
- 广泛的协议支持:DeepFlow 系统默认支持大概十几种应用协议,对于应用常用的协议 HTTP 即支持 1/2 多个版本,也支持 TLS/SSL 加密的解析;对于 MySQL/Redis 等常见的协议不仅支持解析,也支持脱敏能力。
- 协议可扩展性强:目前只有 DeepFlow 支持通过 Wasm 插件自定义扩展应用协议,可以满足特定业务需求。
- 跨语言的全链路能力:目前也支持 DeepFlow 支持不插码形式的跨语言全链路追踪,此能力能加速我们问题定位能力。
DeepFlow 在丰富指标、广泛协议支持、强大扩展能力等方面的优异表现,以及对跨语言、无侵入监控的支持,最终成为腾讯云平台级可观测性的最佳技术选择。
03
数据融合
在引入 DeepFlow 之前,腾讯云已经拥有一套云端监控系统,主要用于管理 Prometheus 的指标数据,同时还配备了专门的日志产品来处理日志数据。作为第三方开源系统,DeepFlow 的引入需要与内部的云端监控系统和日志平台进行集成,才能为用户提供完整的产品体验和强大的可观测性功能。
- 指标数据:腾讯云内部服务的监控数据通过 Prometheus 格式的接口暴露。然而,DeepFlow 默认不提供
/metricsAPI。为了解决这一问题,我们对 DeepFlow 进行了改造,使其能够通过/metrics接口保留和暴露数据。 - 日志数据:我们主要将 DeepFlow 的 应用调用日志(l7_flow_log) 与 网络流日志(l4_flow_log) 落到磁盘文件中,然后由日志采集器在定时读取日志存到日志平台中。
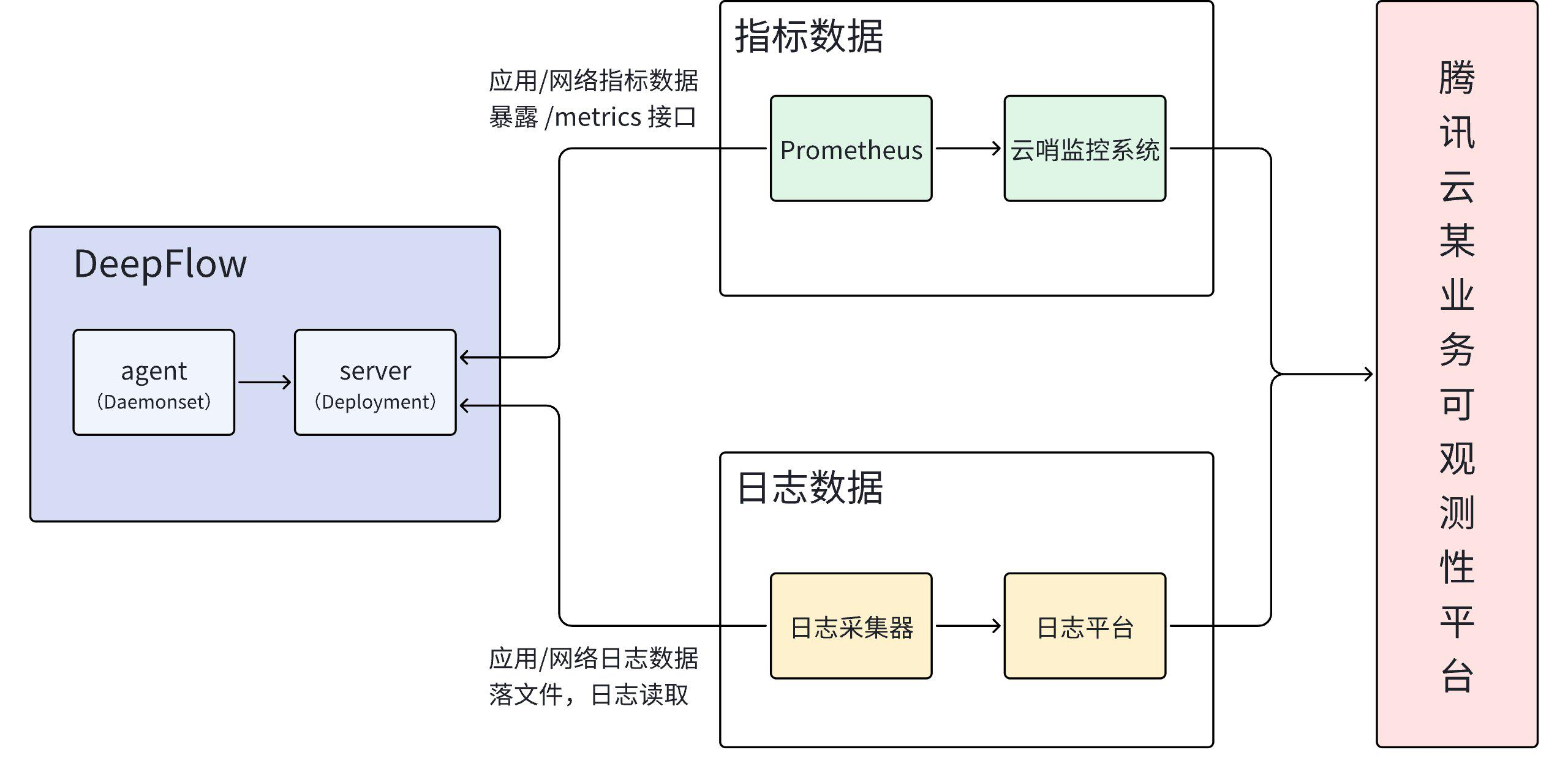
指标数据
尽管 DeepFlow 已经支持通过 Prometheus Remote Write 协议将指标数据主动推送给 Prometheus,但我们现有的 Prometheus 系统主要采用了拉取 (Pull)的方式来收集指标。为了适配这种拉取模型,我们需要在 DeepFlow 中进行一些调整。我们可以基于 DeepFlow 采集的应用调用日志 (l7_flow_log)和网络流日志 (l4_flow_log),重新计算出所需的指标。然后,通过实现 Prometheus 的标准 /metrics 接口,将这些指标以 Prometheus 期望的格式暴露出来。这样,Prometheus 就可以通过定期拉取 /metrics 接口,获取到 DeepFlow 的指标数据。暴露的指标如下:
- 应用指标量:请求数、平均响应时延
- 网络指标量:流量大小、包量大小、新建连接数、连接失败数、客户端重传、服务端重传、客户端零窗口、服务端零窗口

核心代码主要处理的逻辑部分:
- 应用请求数由
l7_flow_log中type = session + request组成 - 应用响应时延仅计算
l7_flow_log中type = session的数据(如果需要合并分开的 request 和 response 计算响应时延,资源消耗过大),同时仅计算平均响应时延(也是为了减少数据量) - DeepFlow 中标签是非常丰富的,但是为了控制 Prometheus 采集数据量(目前单个 Node 单次采集大概有 30M 左右的数据),因此对标签做了一些取舍,仅保留了对我们来说最重要的 Tag:
- K8s 相关的:pod_cluster、pod_ns、pod_group、auto_instance
- 协议相关的:protocol、l7_protocol、type、status(应用指标量)、code(应用指标量)

日志数据
我们在原先 server/ingester/ingester/exporter/exporter.go 的能力之上进行了扩展,支持 l4_flow_log 和 l7_flow_log(request_log)写入本地日志文件的能力,然后由我们自己的日志平台再来采集日志文件:

结合业务的实际情况,我们参考 OTel Exporter 的代码,对 L7FlowLog 结构体中的部分字段进行了额外的转换:

由于 DeepFlow 默认采集了整个平台的数据,数据量还是非常大的,全量采集一天能有接近 T 级别,因此我们也做了一系列的优化来降低数据存储的压力:
- JSON 中的 Key 我们尽量用少量的字母来代替,以降低日志文件的体积,不过代码中的变量名我们没有做修改:

- 结合业务需求,我们增加了一些采样配置能力,包括:
- 对于 response_status = Unknown 的数据不采集
- 对于高延时的数据一定采集,延时阈值可以配置
- 对于 response_status = Error 的数据一定采集
- 调用日志(l7_flow_log)的采样率可以支持分协议设置,例如 HTTP 协议保留全部,因为通过 HTTP 请求可以看到完整的调用链。但对于 DNS、MySQL 等协议可以设置不同的采样率从而降低数据量
- 流日志(l4_flow_log)的采样率和调用日志的采样率分离,可以分别设置不同的值
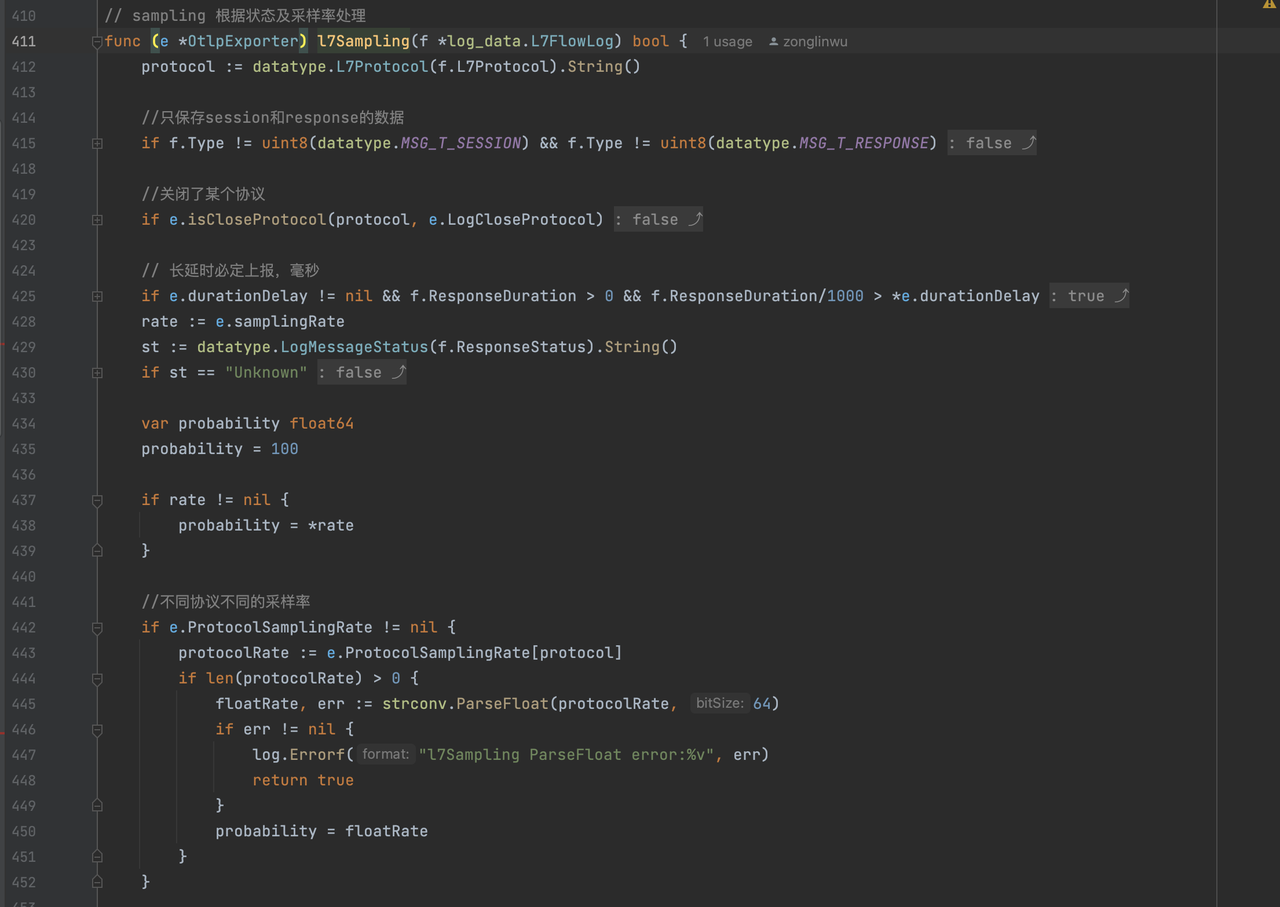
- 因为deepflow 采集的是全量数据,所以这里面就包括了很多的健康探测的数据,我们也增加了这方面的过滤:

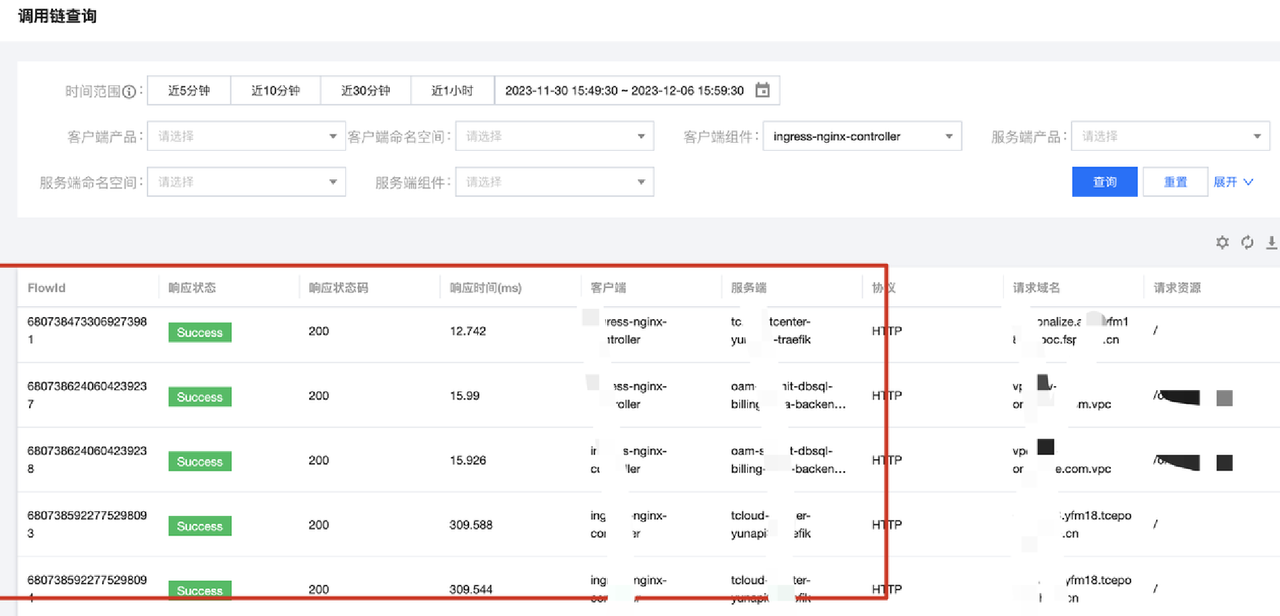
最终调用日志、流日志相关的产品效果图见下:
04
实战案例
引入 DeepFlow 后,我们业务上线过程调用关系清晰,关联应用不必靠猜了;对于各种应用添加了平台级别的 RED 指标量,详情且统一的调用日志可快速定位到 endpoint 的问题。DeepFlow 上线后,还发现了不少旁路隐藏的 Bug(功能使用不多,重启又恢复等情况)下面分享一些实战案例。
分钟级解前端 404 错误

在我们测试环境中,访问某个业务时,直接返回了 404 错误。在以往,我们尝试查找相关的 Pod 日志,但由于错误信息中没有明确指出具体的服务,我们不得不拿着出错的 URL,逐个询问各个业务团队,以确认应该查看后端的哪个服务,这个过程快的话可能一个小时内能搞定,慢的话可能要持续半天。
接下来,我们又尝试在服务器上抓包,希望通过网络请求和响应的信息来定位问题。这个过程是非常耗人耗时,抓取的报文数非常庞大,分析时还需要非常小心核对报文内容来确定服务端 IP,找到 IP 也无法快速确认后端对应的服务。

在 引入 DeepFlow 后,这一切就变得简单了,直接在调用日志中过滤请求的前端服务(tcloud-tcenter-console-web)的 404 异常,就轻松的找到了报错的 URL 的 404 是 x.x.200.19 IP 返回的。

根据子网划分的规则可知,这个并不是我们平台在使用的 IP,且这个 IP 并不能通过前端访问到。因此怀疑是不是域名解析出了问题,又查看了 DNS 解析日志,域名解析没有问题。

服务端的 IP 并不是我们预期的后端业务服务,又怀疑是不是设置了代理导致未走到预期后端业务,使用 echo $http_proxy 查看了果然设置了代理,到此问题已经定位到根因,与测试人员沟通需要删除设置的代理。
对比以往的办法和 DeepFlow 引入后的表现,我们发现要快速准确地定位出错的服务,仅仅依靠传统的日志查询和抓包方式是不够的,是需要通过业务零侵扰的方式补齐平台级别的应用性能监控能力。
主动暴露业务隐藏 Bug
通过构建的平台服务性能监控的 Dashboard(利用 DeepFlow 的 RED 指标与调用日志观测腾讯云所有业务服务)发现 **-cr-**服务 Redis 协议统计到大量的服务端错误,这里引起了我们的注意,需要深入分析此问题。

通过 DeepFlow 调用日志可看到详细的响应异常信息-WRONGPASS invalid username-password pair or user is disabled.。从异常信息可知是因为 Redis 的密码修改了,但是业务代码中的密码没有修改导致业务服务无法与 Redis 通信。

为什么这个 Bug 一直没被发现,且业务还能一直正常跑着?因为 Redis 存放的是配置信息,而这些配置信息还在配置中心也存了一份,业务服务每次启动都会先去和配置中心做配置同步,后续才会持续与 Redis 同步配置信息。一系列连锁反应,导致最终掩盖了问题的根源:
- 业务代码中未对错误捕获,因此未记录到任何错误日志
- 配置更新并不频繁,出问题次数少,对偶发问题难以有精力查找
- 重启就能快速恢复正常,对业务影响度少,未引起重视
05
未来规划
通过引入 DeepFlow,我们显著提升了腾讯云平台的可观测性和问题排查效率。借助其丰富的指标、协议支持和无侵入的全链路追踪能力,我们不仅能够快速定位性能瓶颈,还能主动暴露潜在的业务问题。接下来我们还将进一步融合 DeepFlow 数据:
- 利用 Wasm 插件解析业务层异常,更精准发现业务层的错误
- 利用 Wasm 插件解析全局 request-id,解决跨线程调用链追踪断路问题
06
什么是 DeepFlow
DeepFlow 是云杉网络开发的一款可观测性产品,旨在为复杂的云原生及 AI 应用提供深度可观测性。DeepFlow 基于 eBPF 实现了应用性能指标、分布式追踪、持续性能剖析等观测信号的零侵扰(Zero Code)采集,并结合智能标签(SmartEncoding)技术实现了所有观测信号的全栈(Full Stack)关联和高效存取。使用 DeepFlow,可以让云原生及 AI 应用自动具有深度可观测性,从而消除开发者不断插桩的沉重负担,并为 DevOps/SRE 团队提供从代码到基础设施的监控及诊断能力。
GitHub 地址:https://github.com/deepflowio/deepflow
访问 DeepFlow Demo,体验零插桩、全覆盖、全关联的可观测性。