一直想努力向别人(甚至包括从事运维的人)解释清楚什么是运维,发现很难!
6月20号,在InfoQ高效运维群里面,对运维创业做了一次激烈的讨论,很自然地,过程中不可避免的谈到运维苦逼和运维无法产品化的问题,这是一些运维需要说服自己,证明自己价值的问题。对于本人来说,运维的价值不容置疑,只要我们运维人能自我认识突破,更体系化的站在业务角度看待运维价值问题,那我们就不是一个苦逼的成本部门。此时我自然的想到了【IT运营】,它带来的视界会更加开阔,能够帮助更好的重新认识运维。
一、运维是什么
运维从IT软件工程的阶段论来说,一般分为用户需求阶段、软件开发实现、软件测试和软件维护几个阶段。因此很多人就把运维粗暴地解读为运行+维护。不过庆幸的是,运维人自己已经认为我们不是简单的维护角色了。维护的角色是一种职能化的表述,意味着你是邮件工程师、服务器工程师、网络工程师等等。
其实运维对应的英语单词是Operations,而不是Maintenance。Operations有“操作、运营”的意思,一般会和IT一起出现,称之为IT Operations(IT运营),也就是我们现在说的运维,Maintenance只是一个维护的定位,早已退化。
二、什么是IT运营(运维)
显然从阶段论的角度来看运维,无法概括运维的全貌,所以自己一直和别人说运维就是IT运营,那什么是IT运营?以下是我做了一个产品通路的分解,然后分解出一条技术运营的主线。

当用户的需求被识别出来之后,这个时候必然会产生两种需求:一类是用户需求的功能性描述,一类是用户产品的技术实现描述。接下来从不同的需求出发,此时会产生产品运营和技术运营的要求。技术运营一定是基于技术产品和业务产品中的技术部分,包括基础平台产品(网络、机房、服务器、DNS)、应用产品(application、协议)。为了确保它们能够满足业务的目标,运维需要提供多种保障措施,比如说构建自动化平台(配置管理、调度平台、IT产品管理平台)和技术产品数据运营平台(监控、应用性能管理、能力管理等等)。以上的分解思路,可以解释运维是否需要构建大数据平台,且和产品大数据平台的差异点与边界。
IT运营和产品运营很多落脚点是类似的,也是一种持续改进和闭环的策略,讲产品的生命周期管理和优化,产品说,我是为了提供给用户更好的服务或者价值;技术运营(即运维)说,我也是为了提供给用户更好的服务或者价值。真的如此么?那我们在看看什么是用户的价值。
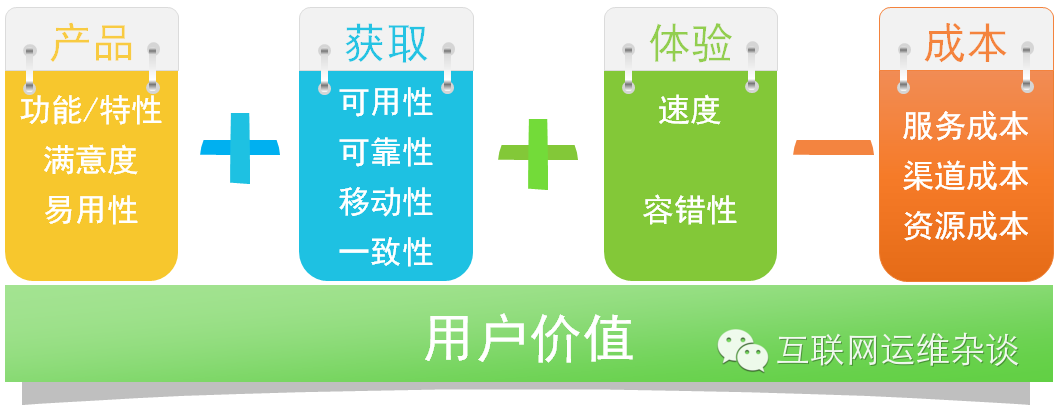
对于用户来说,一种更低成本更高质量的服务才是他们需要的,因此把用户价值分成多个维度的描述,有产品功能和特性需求侧的,有用户体验侧的,有成本方面的(如上图)。由此也可以看出很多的用户价值诉求都会转换成对软件产品技术的需求,这类技术需求实现之后,需要运营手段来保证和持续改进。
在业务互联网化的今天,用户获得同质服务的触点变得越来越多,如何让自家的业务脱颖而出,一方面考验产品运营能力,另外一个方面更是在考验技术运营的能力。在小米推出米聊后不久,腾讯就迅速推出微信,这是腾讯后台技术架构对业务的敏捷支持;在有相同功能的两个互联网产品选择下,你一定会选择那个访问快(速度),并且可用性高,易用性好的产品,特别是速度。在过去的工作中,可以列举很多IT运营能力不足而影响业务发展的例子。
Gartner早期还有一个关于IT价值的模型描述,会有稍稍不同,列出供参考:

在这个模型图里面,关于IT产生的价值指标也非常明确,完全的导向了业务价值,比如说经济性、质量、敏捷性、客户满意度和商业贡献度等等。
- 经济性。包含了投入成本、产出效率和生产率。
- 质量。包含了可用性、相应时间,交易速度等等。
- 敏捷性。IT对于业务变化的适应性和调整的速率,一个好的IT业务架构应该能够适应业务的变化,从而快速对市场相应决策。
- 客户满意度。可以各个渠道收集客户的意见,比如说appstore,产品论坛,客服,CRM渠道等等。
- 商业贡献度。提供更多的商业价值,比如说更大的市场份额,更多的用户获取,更高的市场占有率。
说这么多,是想改变大家对运维的一个错误认识----运维是成本部门,而非收益部门。在一个分散式的x86的复杂架构环境中,如果没有运维部门的统一规划和管理,等于一个乐队少了指挥,其技术建设、管理和运营肯定会陷入混乱,最终影响的是使用我们产品的用户。
三、什么是IT运营管理
IT运营管理,IT Operations Management(ITOM),其中最经典的描述是还来自于Gartner的经典解释。Gartner从一个更全局、更宏观的视野来分析了ITOM的组成及其趋势。Gartner每年会发布多个领域的hype cycle的报告,hype clye是一种分析方法,把一个领域涉及的技术从诞生、发展、成熟等多个过程在一张图中描述出来,并且预估它未来会爆发的时间表。从图中的组成部分,可以看到IT运营的全貌,会涉及到ITOM的多个方面,2013年的报告内容如下(来自于Chuck Henry的一篇PPT分享)。

横坐标不解释了,大家可以自己查查英语单词,加深一下印象,另外不同的形状标示着未来爆发的时间周期。比如说ITIL处于幻灭期,它的再次爆发至少要5到10年。
从这个PPT页面中,你可以看到很多个方向,比如说DevOps、ITIL、APM、IT能力管理、配置管理、CMDB等等,你能说它们和你运维无关么?其实做过互联网运维的人都或多或少的知道上面图形中术语的意思,因为很多都和我们日常的工作相关,有些是在执行ITIL的过程中接触到的,比如说IT service catalog、CMDB;有些是在DevOps实践中接触到的,比如Application Release Automation,当然全局的DevOps会包含更多哈;有些是我们在做数据分析的时候接触到的,比如说Service-Level Reporting tool,Capacity Planning and Management。
这么多方向如要落地实施,一定是运维部门主导建设的,或许大家已经这么干了,此时你难道还说运维就是一个苦逼打杂的,运维没有价值的?ITOM可以帮我们更全面的去看待运维。不过切忌照搬哈。
四、IT运营的目标衡量
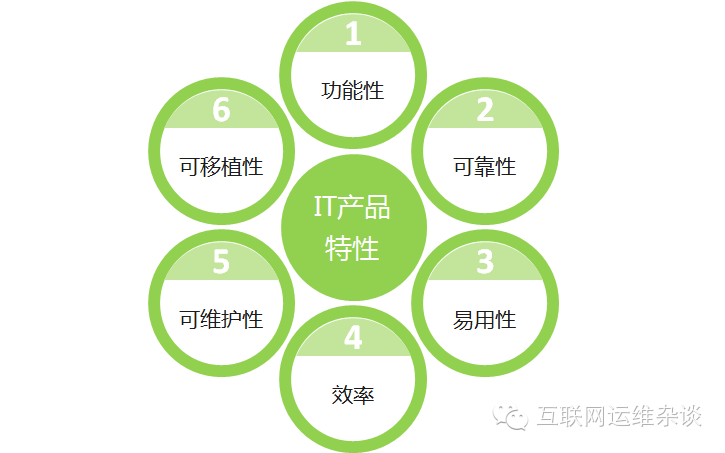
IT运营对象是技术产品,它的特性决定了IT运营的要求和策略的不同,归纳总结有如下:
1、功能性
软件提供的功能是否满足了用户需要?这个地方还有很多个维度可以衡量里面有是否提供了正确的功能(适合性)、适合用户需求的功能(正确性)、安全的功能(安全性)等等。
2、可靠性
软件的运行是否可靠的?可以通过可用性指标来衡量,可用性的指标在上一篇文章结合故障有谈到过如何计算。典型的两个很衡量维度就是容错性和可恢复性。前者将对故障的容错处理能力(要么不出故障),后者对出现故障之后的恢复能力(出故障后,要么快速恢复)。
3、易用性
易用性是一种产品化的能力,可以体现在产品是否能够被用户快速理解的,能够易于使用的,且操作友好的。不要让用户拿到一个产品之后,自己捉摸该如何操作,对于某个核心功能来说,操作的深度很深。操作友好就体现着相同的产品功能下,设计的不同,给用户带来的操作复杂度是完全不同的。同是红包功能,微信红包、QQ红包、支付宝红包给用户带来的易用性完全不同。
4、效率
体现在面向用户的产品交付速度和内部IT支撑服务的响应速度。前者效率体现者用户等待新功能/新特性需要付出的时间成本;后者体现在内部IT支持需要付出的时间成本,在业务量出现增长的情况下,我们需要多少时间能够把支撑的资源提供到位。效率维度基本上都是DevOps自动化解决方案的范畴。
5、可维护性
可监控性。对于一个复杂架构,是否具备可监控的能力,它是一种能够帮助你快速发现故障,快速定位故障直至恢复故障的能力。
可变更性。架构的变更能力非常重要,如果一个架构引入变更就需要对用户服务产生中断或者影响的话,说明这个架构是有不足的或者变更方案设计是不足的。
容错性。是一种容错的能力,特别是一些非期望错误的容错能力,这个在前期的设计准则中需要考虑到一些不可靠性的设定,比如说网络不可靠、硬件不可靠等等。同时对于一些未知的错误,提供自动的降级服务或者容错服务能力。
如何实现可监控性?个人觉得首先要有一个监控平台,其次监控平台需要有采集一切数据的能力,且能自动分析数据的关联,最后才是通过数据实现端到端的监控能力。
可变更性和容错性,是在架构设计和实现的阶段,就要考虑后续对运维友好,设计和实现一个弹性可扩展服务架构对运维来说非常重要,数据解耦和服务解耦是优先要考虑的原则。举个例子,对于一个用户注册的功能来说,可以有URI和域名两种实现方案来区分服务,显然前者的区分对运维不友好,当因为容量的问题,要实现注册核心业务分离的时候,需要在七层代理服务上按照URI进行服务转发,而采用域名的解决方案,则简单许多,DNS指向修改即可。
6、可移植性
是IT产品的可迁移性,一则就涉及到IT技术产品的选型问题,当你选择的IT技术产品开源和公共化程度越高,迁移的成本就越低。公有云服务很多都是基于开源协议的实现,就是一个典型的例子,确保用户的技术产品能够无缝切入到公有云;
其次要考虑云端的服务迁移能力,包含了公有云之间的迁移能力(显然目前不具备)和私有IT环境向云端服务迁移的能力。
有了这些特性维度,基本上就有了IT运营的数据体系,做好IT运营,就是不断去挖掘技术产品所产生的日志和数据,去衡量IT技术产品的现状以及未来的运营优化的方向。不过要注意的是在可维护性里面不仅仅是度量这么简单,还有自动化平台建设来满足可变更性的要求,它的直接衡量指标就是之前提到的变更延时。
很多时候,我们会担心运维做久了,特别是运维被琐事和故障所牵绕的情况下,会忘了我们还能做什么,更是忘了我们其实是从IT运营而来,从IT运营的角度看运维,特别是和ITOM结合起来去看运维,带来的感觉又完全不同:
第一、平时运维的工作层面到底还有多少提炼和认识不够的地方(以ITOM为对标)?同样是做应用性能管理APM,代码级性能管理是不是唯一的方法,结合互联网还有哪些实践,他们之间的互补又在哪儿?能力管理的必要性是在哪儿?如何建设能力管理系统,从能力管理的三个层次来看,他们的成本和收益是什么样的?我把这些概括为运维的内在思考。
第二、不断去思考运维带来的业务价值。从之前的讨论中都可以看到运维的最终价值点,它们都有一个业务价值的通用描述,我们是否有结合自己的业务仔细思考过,提炼过?我把这些又概括为运维的外在思考。
当我们把其内在和外在都思考清楚了,其实也就是把运维的某方面思考清楚了,此时我们结合行业的特点去做运维,提炼最佳实践,是不是意味着运维更有价值了?
注:这篇文章还可以谈谈IT运营的方法和策略,但是限于篇幅,不作深入展开!