《当人工智能遇上安全》系列博客将详细介绍人工智能与安全相关的论文、实践,并分享各种案例,涉及恶意代码检测、恶意请求识别、入侵检测、对抗样本等等。只想更好地帮助初学者,更加成体系的分享新知识。该系列文章会更加聚焦,更加学术,更加深入,也是作者的慢慢成长史。换专业确实挺难的,系统安全也是块硬骨头,但我也试试,看看自己未来四年究竟能将它学到什么程度,漫漫长征路,偏向虎山行。享受过程,一起加油~
前文讲解中文命名实体识别研究,并构建BiGRU-CRF模型实现。这篇文章简单讲解易学智能GPU搭建Keras环境的过程,并实现了LSTM文本分类的实验,本来想写Google Colab免费云,但其评价不太好(经常断网、时间限制、数据量小)。因此,选择一个评价较好的平台供大家学习(6块一小时),也希望大家推荐更好的平台,百度飞浆后续准备也学习下,希望这篇文章能解决自身电脑配置不足,需要GPU运行模型且服务器价格又不是太高的同学。
- 如果个人电脑足够使用的同学,则可以看看这篇文章的LSTM文本分类代码,下一篇文章我将详细对比。基础性文章,希望对您有所帮助。
作者作为网络安全的小白,分享一些自学基础教程给大家,主要是在线笔记,希望您们喜欢。同时,更希望您能与我一起操作和进步,后续将深入学习AI安全和系统安全知识并分享相关实验。总之,希望该系列文章对博友有所帮助,写文不易,大神们不喜勿喷,谢谢!如果文章对您有帮助,将是我创作的最大动力,点赞、评论、私聊均可,一起加油喔!
作者的github资源:
- https://github.com/eastmountyxz/AI-Security-Paper
- https://github.com/eastmountyxz/When-AI-meet-Security
一.搭建易学智能GPU平台
第一步,注册登录后,选择“控制台”->“新建主机”。
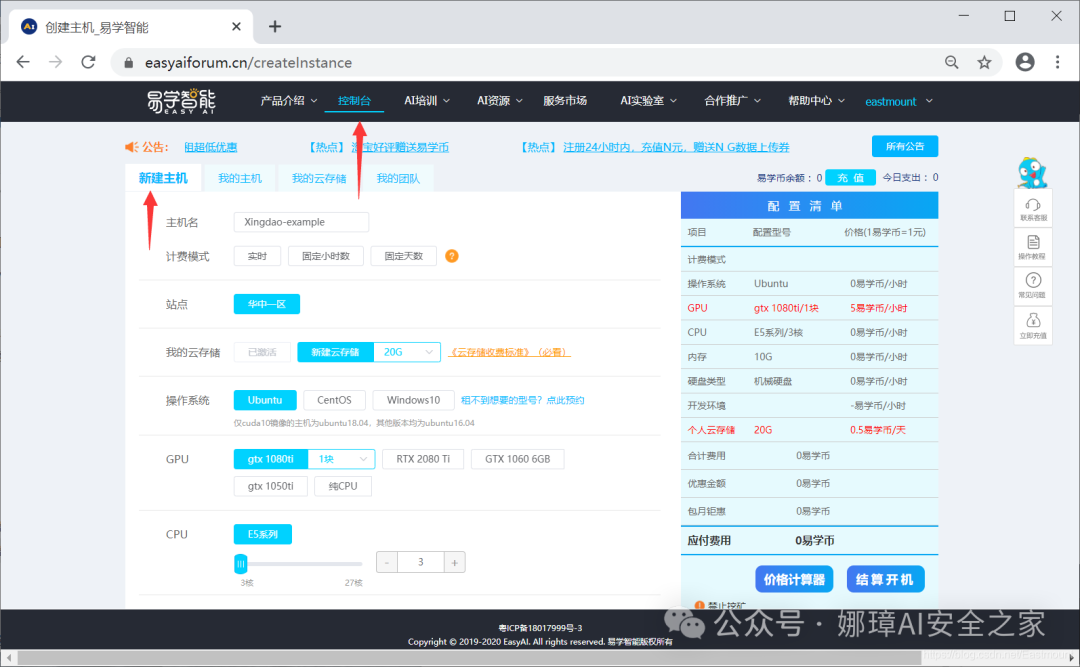
第二步,选择主机环境。 读者可以根据代码编写习惯选择,作者习惯Windows操作系统、选择gtx 1080tiGPU、开发环境为Python3.6、pytorch1.0和tf1.12。由于作者代码TensorFlow版本较低,读者可以选择TensorFlow2.0。
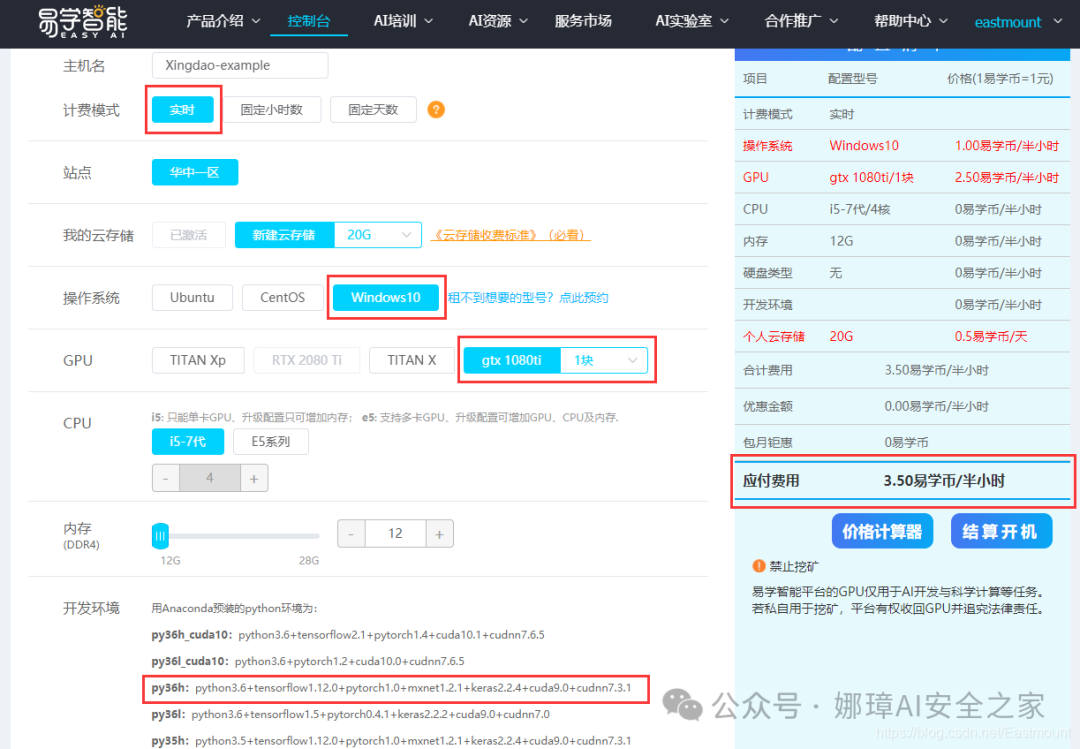
点击“结算开机”会提示相关内容,如下图所示。
- 创建Windows主机
- 创建Ubuntu主机
点击“确认开机”后支付金额并初始化。
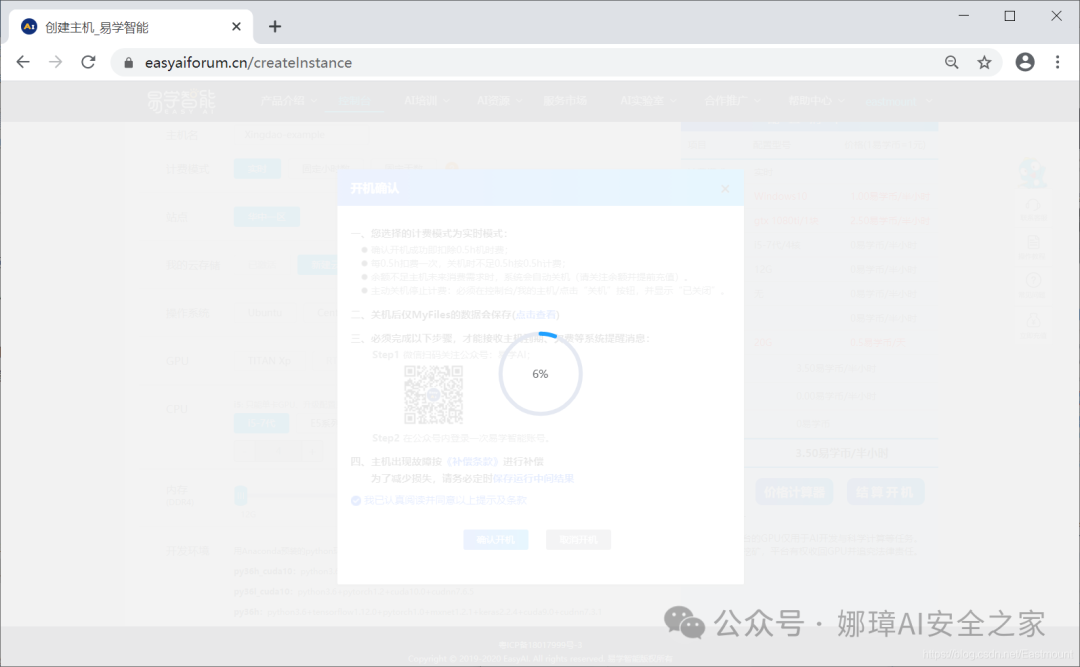
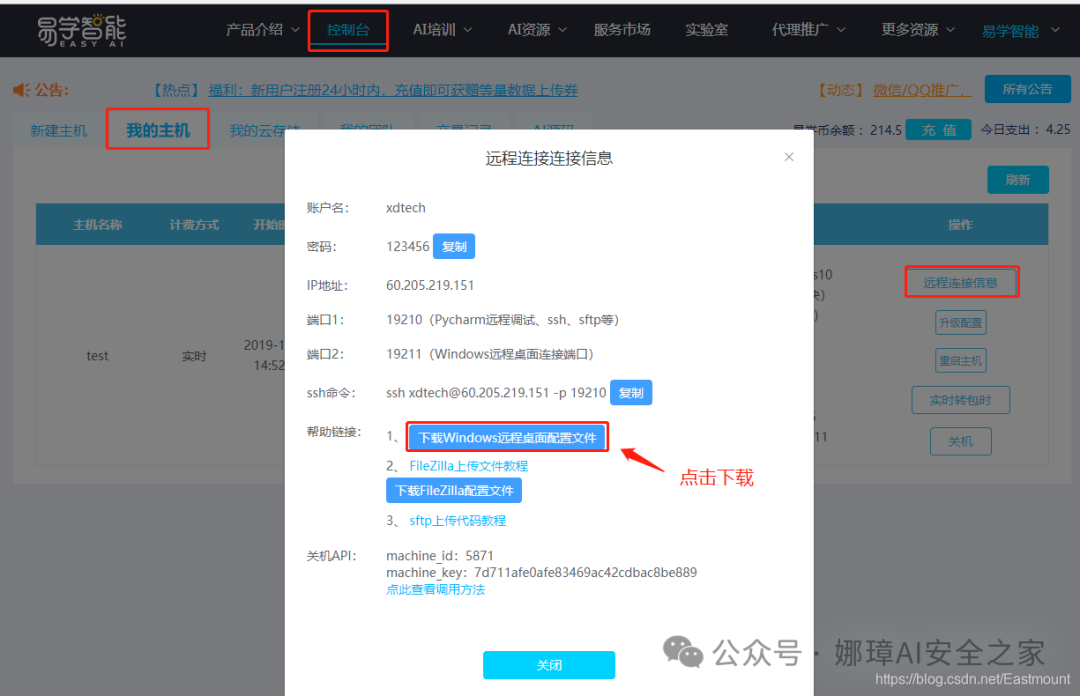
第三步,下载远程连接配置文件:控制台->我的主机->远程连接信息,点击下载。
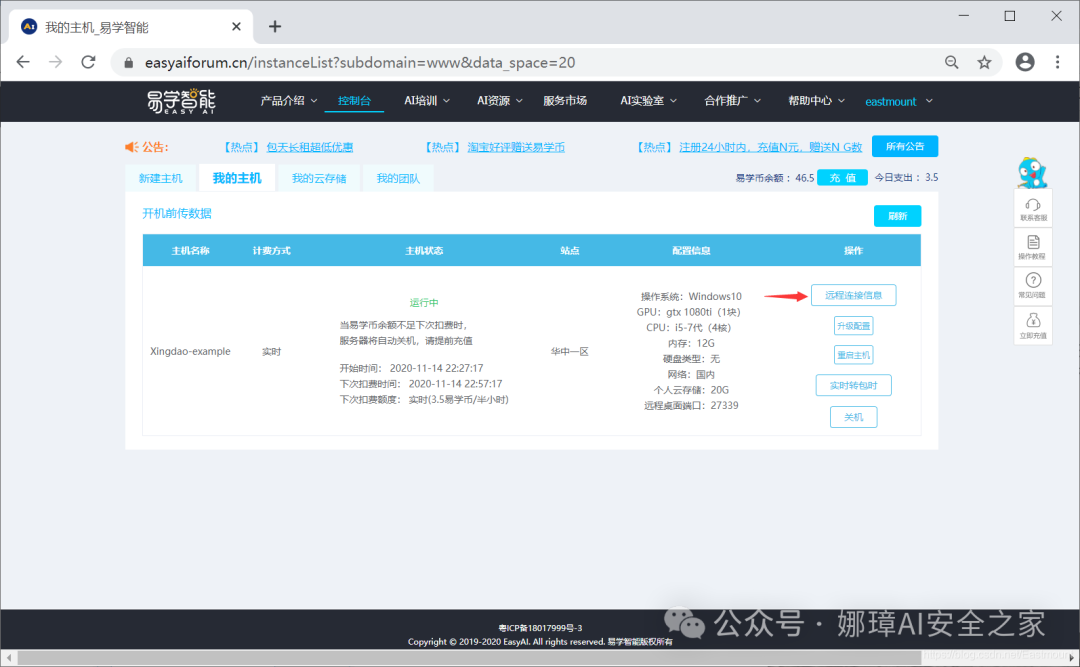
接着点击“下载Windows远程桌面配置文件”按钮,下图是官方提供的,大家写文章时也需要避免个人服务器账号泄露喔!
- 账号
- 密码
- IP地址
- 端口
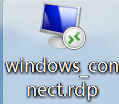
第四步,远程连接。双击windows_connect.rdp,输入密码。
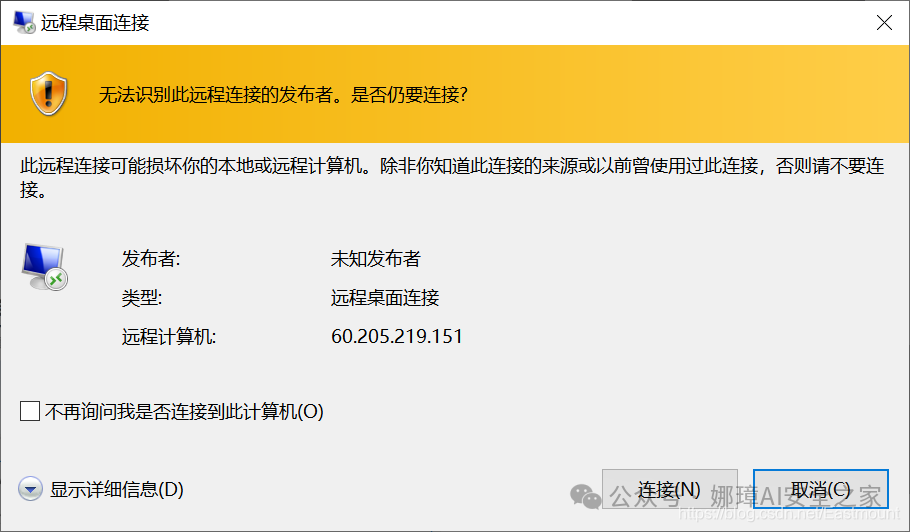
输入密码登录即可。
登录成功后进入Windows远程界面。
桌面如下图所示,运行代码的主要方式有命令行、Jupyter、PyCharm、Spyder等。
- 命令行,运行代码前请激活conda环境
- Windows使用Jupyter
- 使用PyCharm:在PyCharm中配置python解释器
- 使用Spyder:在Spyder中配置与使用python解释器
第五步,点击关机后停止计费,一定要点击“关机”按钮,切记。同时下次开机我们可以选择新的服务器型号和系统。

关机注意事项如下:

至此这个易学智能的服务云环境就介绍结束,下面我们开始讲解Python和深度学习的配置过程。
二.易学智能运行Python代码
第一步,激活Conda环境。
打开conda prompt(桌面有快捷方式),激活Conda环境。以使用py36h为例,打开anaconda prompt命令行,输入:
- activate py36h或conda activate py36h

第二步,直接打开Python3.7 IDLE编写代码即可。
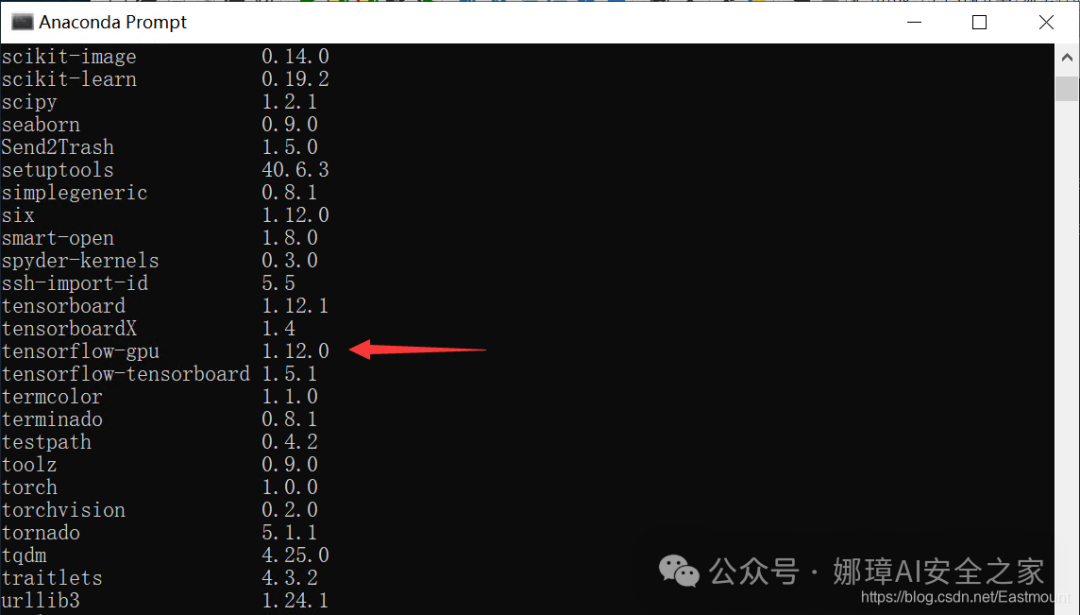
pip list可以查看已经配置的扩展包,注意TensorFlow安装的是GPU版本。
TensorFlow框架如下图所示:
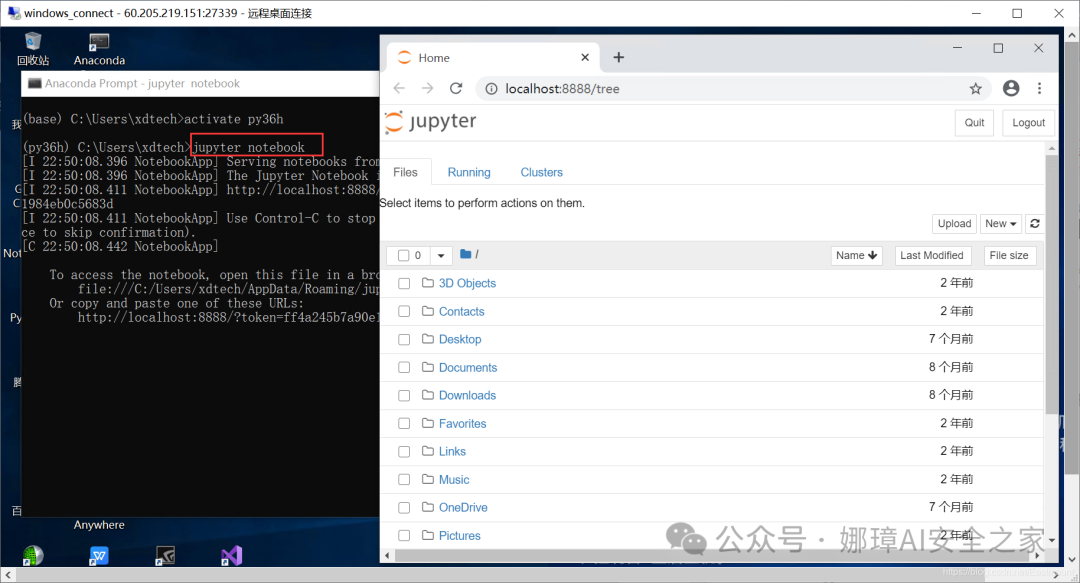
第三步,输入jupyter notebook打开Jupyter Notebook,如下图所示。 输入pip install pkg或conda install pkg可以安装扩展包。
第四步,利用Spyder编写代码。

首次打开需要初始化一段时间,接着运行结果如下图所示。

选择安装的环境“py36h”,然后安装Spyder,利用这个编写Python代码。

或者在终端中输入“spyer”打开。

同样读者可以直接使用PyCharm编写Python代码,它的常用扩展包也被成功安装了。
下列代码可以查看软件版本信息:
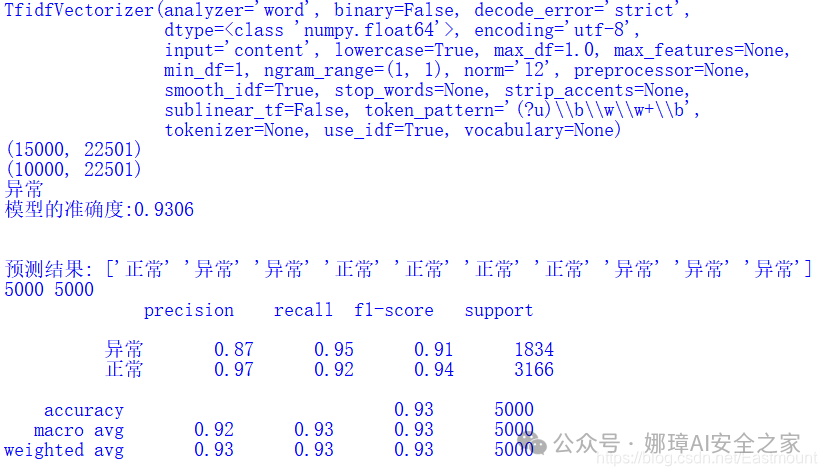
import tensorflow as tf print(tf.__version__)import torch as th
print(th.version)
import keras
print(keras.version)
输出结果如下图所示:
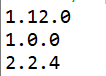
第五步,查看环境是否为GPU版本。
以tensorflow为例,运行下面python代码。
import tensorflow as tf
print(tf.version)import os
os.environ["CUDA_DEVICES_ORDER"] = "PCI_BUS_IS"
os.environ["CUDA_VISIBLE_DEVICES"] = "0"#sess = tf.Session()
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
a = tf.constant(1)
b = tf.constant(2)
print(sess.run(a+b))
from tensorflow.python.client import device_lib
print(device_lib.list_local_devices())
输出结果如下图所示,我们可以使用 “/device:CPU:0”,“/device:GPU:0”。
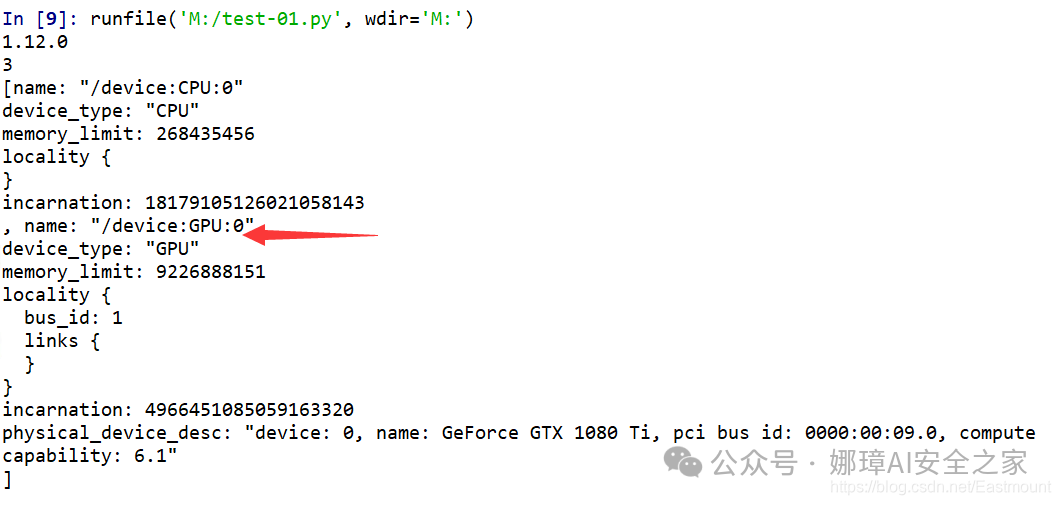
当作者在命令行中运行时,看到日志是GPU运行代码。
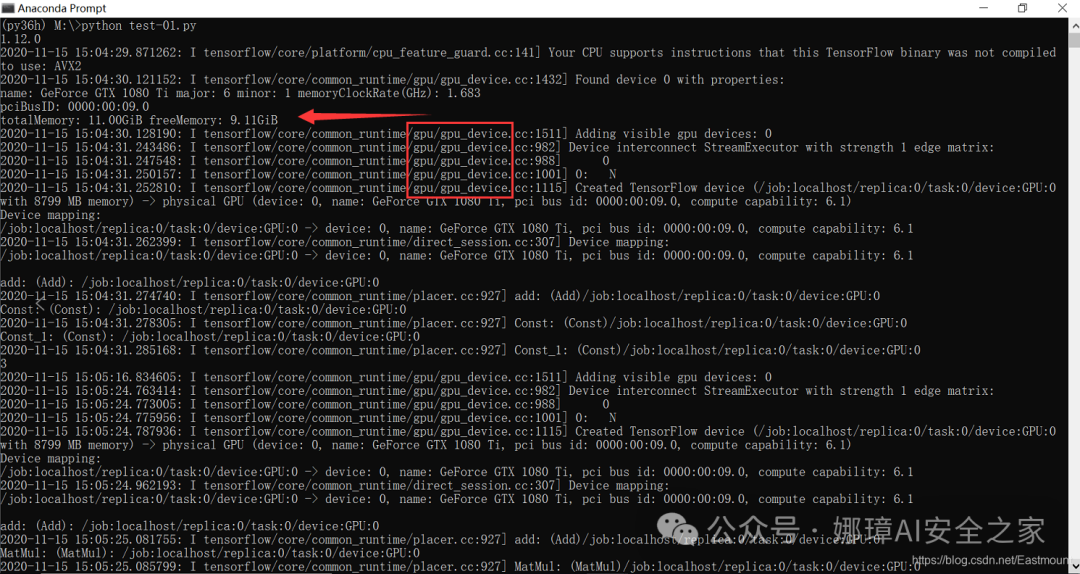
同样补充另一种设置设备的方式,核心代码如下所示:
import tensorflow as tf
with tf.Session(config=tf.ConfigProto(allow_soft_placement=True, log_device_placement=True)) as sess:
sess.run(init)
with tf.device('/device:GPU:0'):
for _ in range(3):
print(sess.run(state))第六步,下面简单运行Pyhton机器学习代码,这里作者选择之前的博客鸢尾花线性回归代码。
from sklearn.datasets import load_iris
import numpy as np
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt#获取花瓣的长和宽
hua = load_iris()
x = [n[0] for n in hua.data]
y = [n[1] for n in hua.data]x = np.array(x).reshape(len(x),1)
y = np.array(y).reshape(len(y),1)#线性回归分析
clf = LinearRegression()
clf.fit(x,y)
pre = clf.predict(x)
#可视化画图
plt.scatter(x,y,s=100)
plt.plot(x,pre,"r-",linewidth=4)
for idx, m in enumerate(x):
plt.plot([m,m],[y[idx],pre[idx]], 'g-')
plt.show()
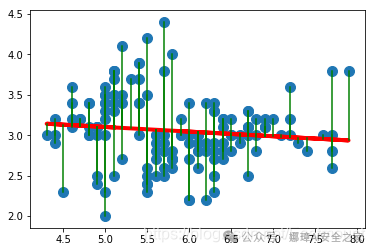
运行结果如下图所示:
第七步,代码文件上传。
你可能会想远程代码是不是需要发送到百度网盘或github,再下载运行,其实易学智能提供了一个上传文件的功能。界面如下图所示:
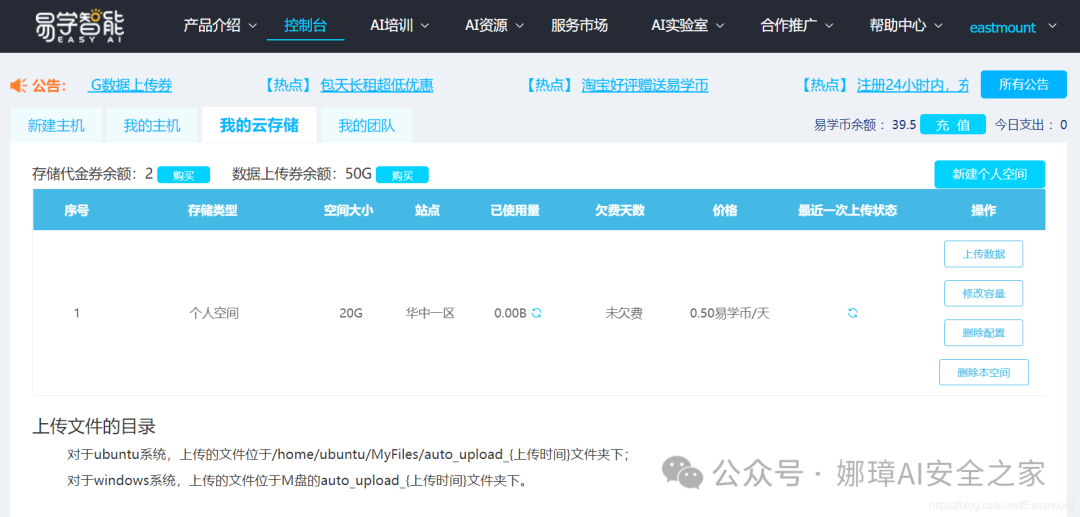
上传代码如下图所示,保存至“M盘/MyFiles”路径。

参考文献:
- http://wiki.jikexueyuan.com/project/tensorflow-zh/how_tos/using_gpu.html
- https://blog.csdn.net/qq_34022601/article/details/90449789
三.LSTM基础知识
在介绍LSTM模型之前,先分享循环神经网络知识。
1.RNN原理
循环神经网络英文是Recurrent Neural Networks,简称RNN。假设有一组数据data0、data1、data2、data3,使用同一个神经网络预测它们,得到对应的结果。如果数据之间是有关系的,比如做菜下料的前后步骤,英文单词的顺序,如何让数据之间的关联也被神经网络学习呢?这就要用到——RNN。
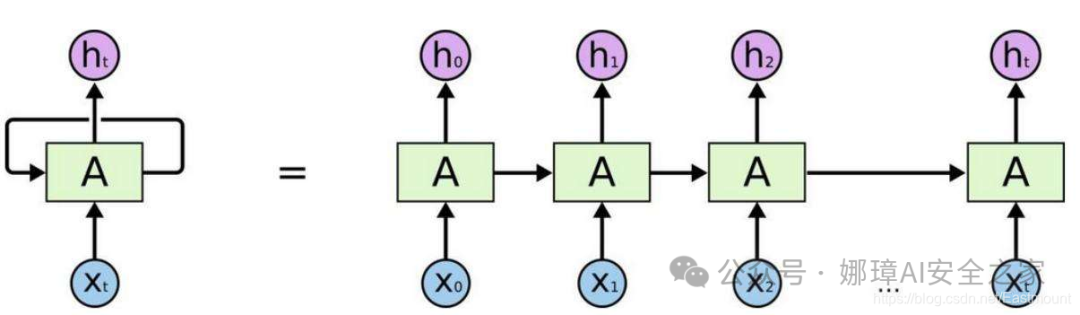
假设存在ABCD数字,需要预测下一个数字E,会根据前面ABCD顺序进行预测,这就称为记忆。预测之前,需要回顾以前的记忆有哪些,再加上这一步新的记忆点,最终输出output,循环神经网络(RNN)就利用了这样的原理。
首先,让我们想想人类是怎么分析事物之间的关联或顺序的。人类通常记住之前发生的事情,从而帮助我们后续的行为判断,那么是否能让计算机也记住之前发生的事情呢?
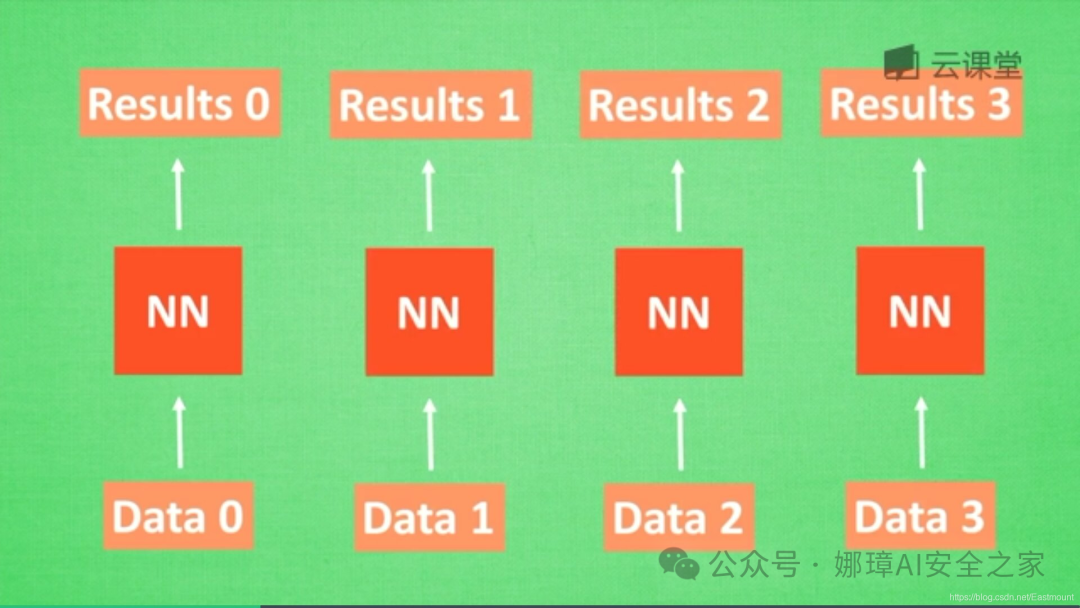
在分析data0时,我们把分析结果存入记忆Memory中,然后当分析data1时,神经网络(NN)会产生新的记忆,但此时新的记忆和老的记忆没有关联,如上图所示。在RNN中,我们会简单的把老记忆调用过来分析新记忆,如果继续分析更多的数据时,NN就会把之前的记忆全部累积起来。
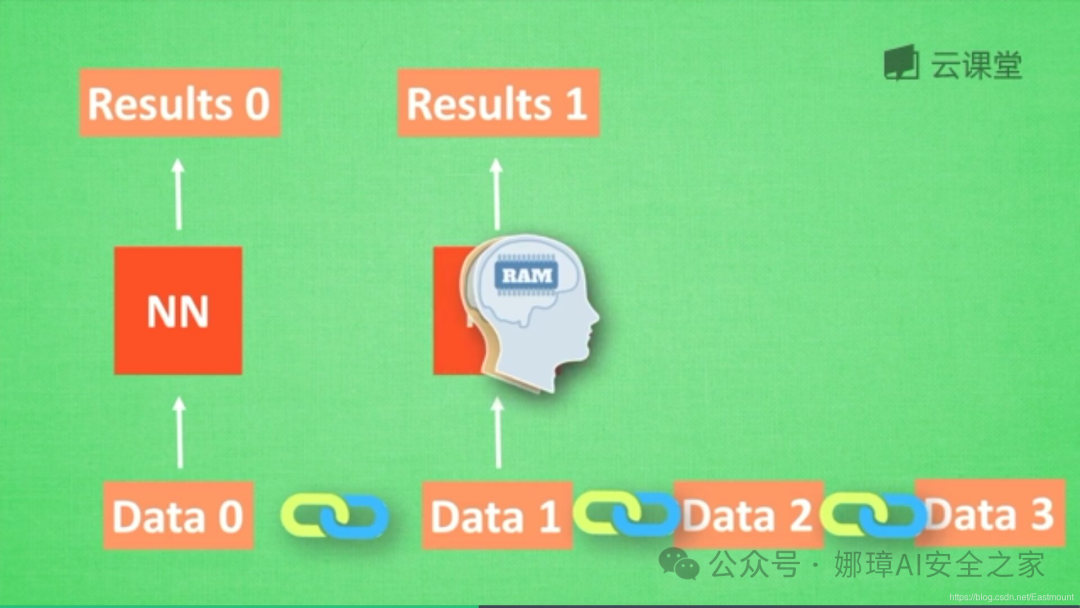
RNN结构如下图所示,按照时间点t-1、t、t+1,每个时刻有不同的x,每次计算会考虑上一步的state和这一步的x(t),再输出y值。在该数学形式中,每次RNN运行完之后都会产生s(t),当RNN要分析x(t+1)时,此刻的y(t+1)是由s(t)和s(t+1)共同创造的,s(t)可看作上一步的记忆。多个神经网络NN的累积就转换成了循环神经网络,其简化图如下图的左边所示。
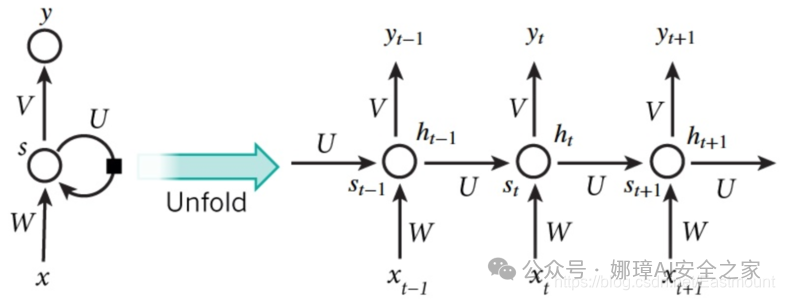
总之,只要你的数据是有顺序的,就可以使用RNN,比如人类说话的顺序,电话号码的顺序,图像像素排列的顺序,ABC字母的顺序等。在前面讲解CNN原理时,它可以看做是一个滤波器滑动扫描整幅图像,通过卷积加深神经网络对图像的理解。
而RNN也有同样的扫描效果,只不过是增加了时间顺序和记忆功能。RNN通过隐藏层周期性的连接,从而捕获序列化数据中的动态信息,提升预测结果。
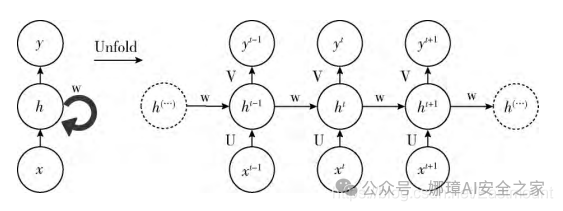
2.RNN应用
RNN常用于自然语言处理、机器翻译、语音识别、图像识别等领域,下面简单分享RNN相关应用所对应的结构。
RNN情感分析: 当分析一个人说话情感是积极的还是消极的,就用如下图所示的RNN结构,它有N个输入,1个输出,最后时间点的Y值代表最终的输出结果。
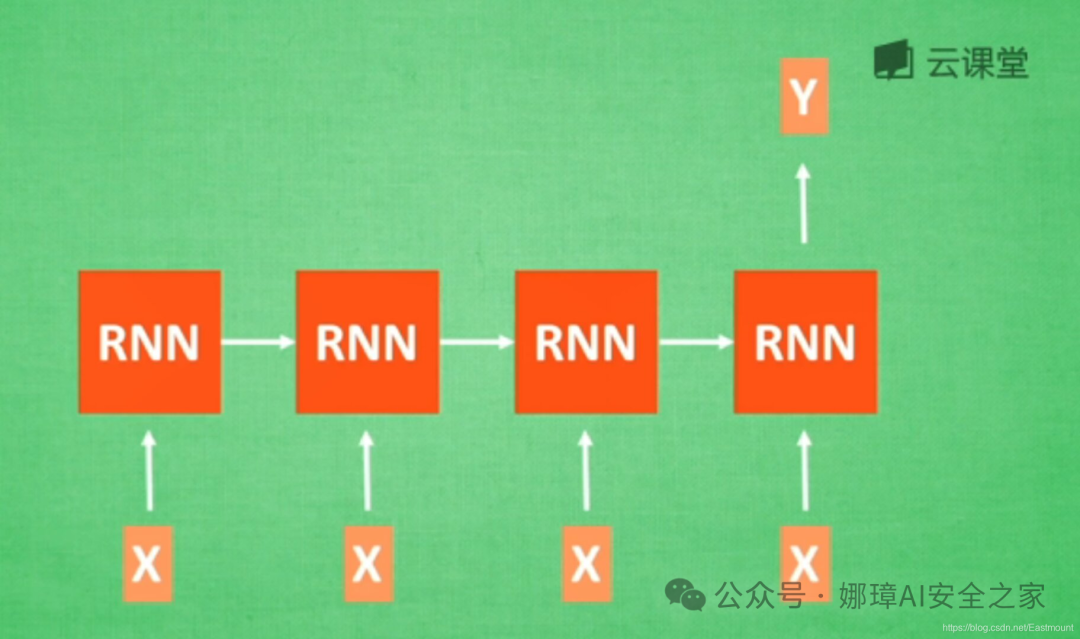
RNN图像识别: 此时有一张图片输入X,N张对应的输出。

RNN机器翻译: 输入和输出分别两个,对应的是中文和英文,如下图所示。
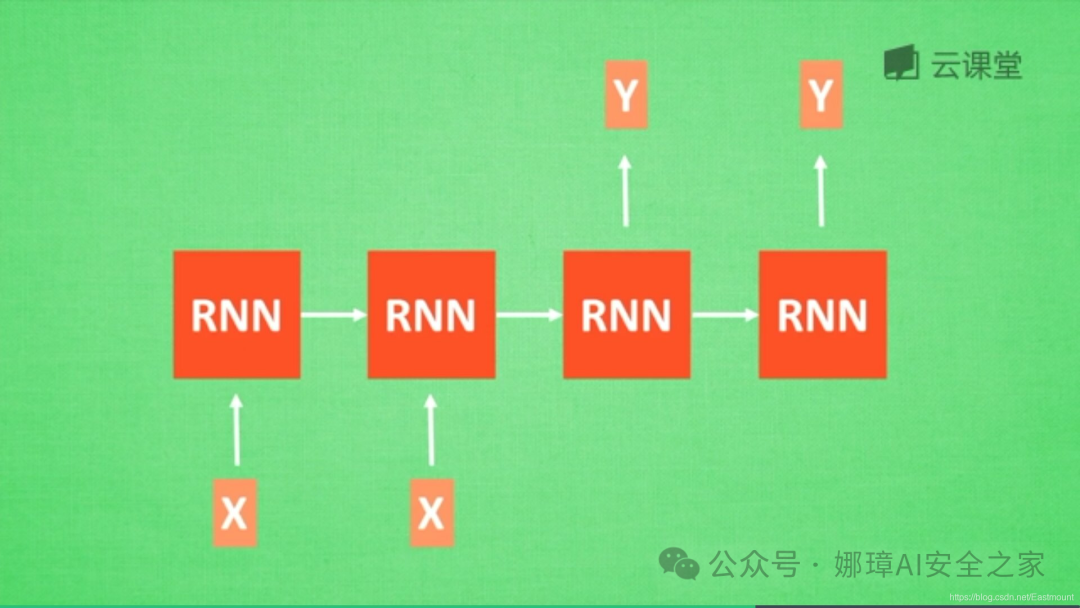
3.为什么引入LSTM
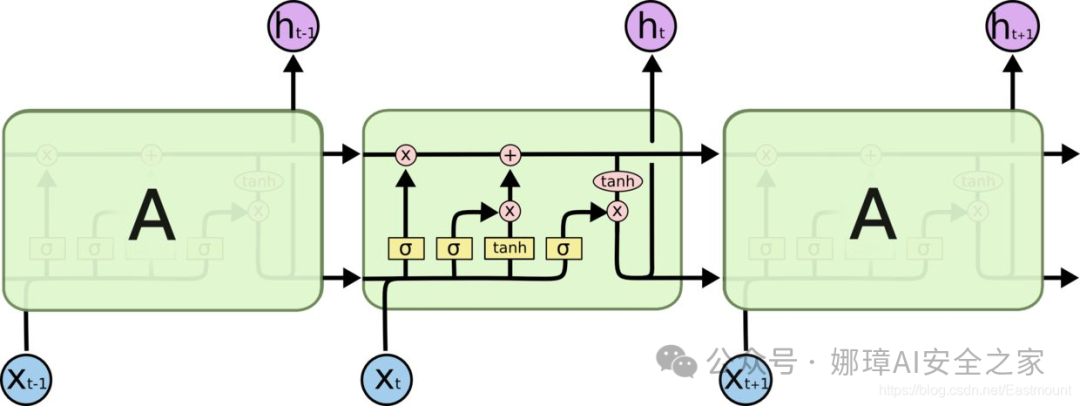
RNN是在有序的数据上进行学习的,RNN会像人一样对先前的数据发生记忆,但有时候也会像老爷爷一样忘记先前所说。为了解决RNN的这个弊端,提出了LTSM技术,它的英文全称是Long short-term memory,长短期记忆,也是当下最流行的RNN之一。
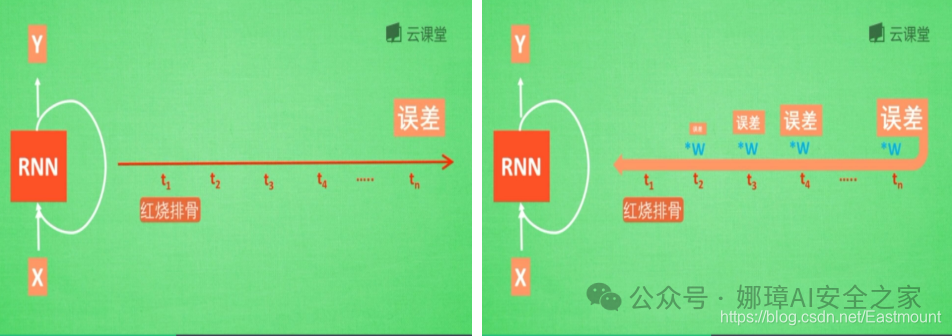
假设现在有一句话,如下图所示,RNN判断这句话是红烧排骨,这时需要学习,而“红烧排骨“在句子开头。

"红烧排骨"这个词需要经过长途跋涉才能抵达,要经过一系列得到误差,然后经过反向传递,它在每一步都会乘以一个权重w参数。如果乘以的权重是小于1的数,比如0.9,0.9会不断地乘以误差,最终这个值传递到初始值时,误差就消失了,这称为梯度消失或梯度离散。
反之,如果误差是一个很大的数,比如1.1,则这个RNN得到的值会很大,这称为梯度爆炸。
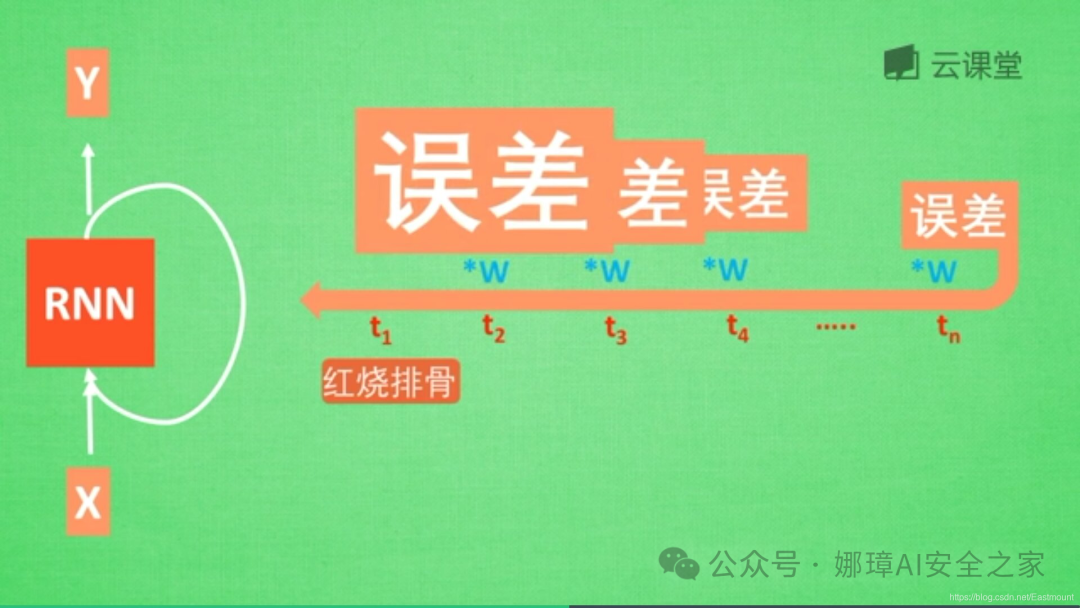
梯度消失或梯度爆炸:
在RNN中,如果你的State是一个很长的序列,假设反向传递的误差值是一个小于1的数,每次反向传递都会乘以这个数,0.9的n次方趋向于0,1.1的n次方趋向于无穷大,这就会造成梯度消失或梯度爆炸。
这也是RNN没有恢复记忆的原因,为了解决RNN梯度下降时遇到的梯度消失或梯度爆炸问题,引入了LSTM。
4.LSTM
LSTM是在普通的RNN上面做了一些改进,LSTM RNN多了三个控制器,即输入、输出、忘记控制器。左边多了个条主线,例如电影的主线剧情,而原本的RNN体系变成了分线剧情,并且三个控制器都在分线上。
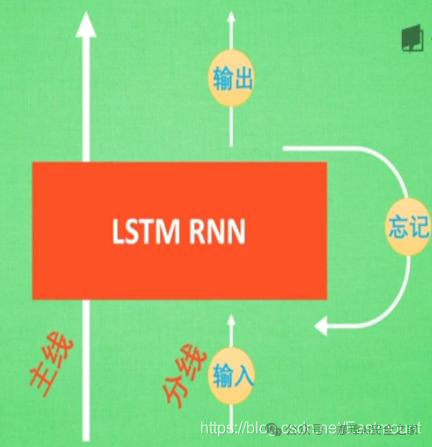
- 输入控制器(write gate): 在输入input时设置一个gate,gate的作用是判断要不要写入这个input到我们的内存Memory中,它相当于一个参数,也是可以被训练的,这个参数就是用来控制要不要记住当下这个点。
- 输出控制器(read gate): 在输出位置的gate,判断要不要读取现在的Memory。
- 忘记控制器(forget gate): 处理位置的忘记控制器,判断要不要忘记之前的Memory。
LSTM工作原理为:如果分线剧情对于最终结果十分重要,输入控制器会将这个分线剧情按重要程度写入主线剧情,再进行分析;如果分线剧情改变了我们之前的想法,那么忘记控制器会将某些主线剧情忘记,然后按比例替换新剧情,所以主线剧情的更新就取决于输入和忘记控制;最后的输出会基于主线剧情和分线剧情。
通过这三个gate能够很好地控制我们的RNN,基于这些控制机制,LSTM是延缓记忆的良药,从而带来更好的结果。
四.编写LSTM神经网络实现文本分类
这里使用的数据集为恶意请求URL和正常请求URL,它的分词效果不像传统的英文空格或中文Jieba分词,因为恶意请求如SQL注入、XSS攻击通常包括特殊的标点符号,因此使用N-gram分词的效果更好。更好的数据集应该是包含信息的流量请求信息,这里仅提供一个简单的案例分享。
恶意请求URL检测
目前大多数网站检测方式是通过建立URL黑白名单的数据库匹配进行排查,虽然具有一定的检测效果,但有一定滞后性,不能够对没有记录在案的URL进行识别。而基于机器学习,从 URL特征、域名特征、Web特征的关联分析,使恶意URL识别具有高准确率,并具有学习推断的能力。一些开源工具如Phinn提供了另一个角度的检测方法,如果一个页面看起来非常像Google的登录页面,那么这个页面就应该托管在Google域名。Phinn使用了机器学习领域中的卷积神经网络算法来生成和训练一个自定义的Chrome扩展,这个 Chrome扩展可以将用户浏览器中呈现的页面与真正的登录页面进行视觉相似度分析,以此来识别出恶意URL(钓鱼网站)。
1.N-gram分词
该部分代码基本步骤为:
- 读取随机URL请求数据集
- 利用get_ngrams自定义函数实现n-gram分词处理,比如 www.foo.com/1 会转换为 [‘www’,‘ww.’,‘w.f’,‘.fo’,‘foo’,‘oo.’,‘o.c’,‘.co’,‘com’,‘om/’,‘m/1’] 的向量
- 分词结果分别存入3个数据集,由于原始数据集的恶意样本和正常样本以及随机顺序,这里前10000行数据集为训练集,中间5000行为测试集,最后5000行为验证集
fenci_data.py
# coding: utf-8
import pandas as pd
import jieba
import time
import csv
from sklearn.feature_extraction.text import TfidfVectorizer
#----------------------------------自定义函数 N-Gram处理--------------------------------
tokenizer function, this will make 3 grams of each query
www.foo.com/1 转换为 ['www','ww.','w.f','.fo','foo','oo.','o.c','.co','com','om/','m/1']
def get_ngrams(query):
tempQuery = str(query)
ngrams = []
for i in range(0, len(tempQuery)-3+1):
ngrams.append(tempQuery[i:i+3])
return ngrams
#----------------------------------主函数 读取文件及预处理-------------------------------
if name == 'main':
# 使用csv.DictReader读取文件中的信息
file = "all_data_url_random.csv"
with open(file, "r", encoding="UTF-8") as f:
reader = csv.DictReader(f)
labels = []
contents = []
for row in reader:
# 数据元素获取
labels.append(row['label'])
contents.append(row['content'])
print(labels[:10])
print(contents[:10])
#文件写入
#数据划分 前10000-训练集 中间5000-测试集 后5000-验证集
ctrain = open("all_data_url_random_fenci_train.csv", "a+", newline='', encoding='gb18030')
writer1 = csv.writer(ctrain)
writer1.writerow(["label","fenci"])
ctest = open("all_data_url_random_fenci_test.csv", "a+", newline='', encoding='gb18030')
writer2 = csv.writer(ctest)
writer2.writerow(["label","fenci"])
cval = open("all_data_url_random_fenci_val.csv", "a+", newline='', encoding='gb18030')
writer3 = csv.writer(cval)
writer3.writerow(["label","fenci"])
n = 0
while n < len(contents):
res = get_ngrams(contents[n])
#print(res)
final = ' '.join(res)
tlist = []
tlist.append(labels[n])
tlist.append(final)
if n<10000:
writer1.writerow(tlist) #训练集
elif n>=10000 and n<15000:
writer2.writerow(tlist) #测试集
elif n>=15000:
writer3.writerow(tlist) #验证集
n = n + 1
#文件关闭
ctrain.close()
ctest.close()
cval.close()</code></pre></div></div><p>输出结果如下图所示,包括训练集、测试集和验证集。</p><figure class=""><div class="rno-markdown-img-url" style="text-align:center"><div class="rno-markdown-img-url-inner" style="width:auto"><div style="width:100%"><img src="https://cdn.static.attains.cn/app/developer-bbs/upload/1722944790541824860.png" /></div></div></div></figure><figure class=""><hr/></figure><h3 id="c18pt" name="2.LSTM%E6%9E%84%E5%BB%BA">2.LSTM构建</h3><p>该部分包括两个Python文件,具体如下:</p><ul class="ul-level-0"><li>LSTM_data.py:构建LSTM模型,实现恶意请求分类功能</li><li>load_pj.py:算法评价模型,自定义计算分类的Precision、Recall和F-measure</li></ul><p>LSTM_data.py
具体任务包括六个步骤,代码中包括详细的注释,如下:
- 第一步,读取数据
- 第二步,进行OneHotEncoder()编码,可以采用TF-IDF、Word2Vec等方法
- 第三步,使用Tokenizer对词组进行编码,将数据转换为固定长度的词序列
- 第四步,建立LSTM模型,模型如下图所示
- 第五步,设置flag开关进行模型训练和模型预测,模型评估调用 load_pj.py 实现,通弄湿绘制热力图
- 第六步,验证算法进行验证集的测试

# coding=utf-8
By:Eastmount CSDN 2020-11-15
import pickle
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import metrics
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
from keras.models import Model
from keras.layers import LSTM, Activation, Dense, Dropout, Input, Embedding
from keras.optimizers import RMSprop
from keras.preprocessing.text import Tokenizer
from keras.preprocessing import sequence
from keras.callbacks import EarlyStopping
from keras.models import load_model
from load_pj import classification_pj
import time
start = time.clock()
#---------------------------------------第一步 数据读取------------------------------------
#读取测数据集
train_df = pd.read_csv("all_data_url_random_fenci_train.csv")
val_df = pd.read_csv("all_data_url_random_fenci_val.csv")
test_df = pd.read_csv("all_data_url_random_fenci_test.csv")
print(train_df.head())
#解决中文显示问题
plt.rcParams['font.sans-serif'] = ['KaiTi'] # 指定默认字体 SimHei黑体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'
#---------------------------------第二步 OneHotEncoder()编码---------------------------------
#对数据集的标签数据进行编码
train_y = train_df.label
print("Label:")
print(train_y[:10])
val_y = val_df.label
test_y = test_df.label
le = LabelEncoder()
train_y = le.fit_transform(train_y).reshape(-1,1)
print("LabelEncoder")
print(train_y[:10])
print(len(train_y))
val_y = le.transform(val_y).reshape(-1,1)
test_y = le.transform(test_y).reshape(-1,1)
对数据集的标签数据进行one-hot编码
ohe = OneHotEncoder()
train_y = ohe.fit_transform(train_y).toarray()
val_y = ohe.transform(val_y).toarray()
test_y = ohe.transform(test_y).toarray()
print("OneHotEncoder:")
print(train_y[:10])
#-------------------------------第三步 使用Tokenizer对词组进行编码-------------------------------
#使用Tokenizer对词组进行编码
#当我们创建了一个Tokenizer对象后,使用该对象的fit_on_texts()函数,以空格去识别每个词
#可以将输入的文本中的每个词编号,编号是根据词频的,词频越大,编号越小
max_words = 5000
max_len = 600
tok = Tokenizer(num_words=max_words) #使用的最大词语数为5000
tok.fit_on_texts(train_df.fenci)
print(tok)
#保存训练好的Tokenizer和导入
with open('tok.pickle', 'wb') as handle:
pickle.dump(tok, handle, protocol=pickle.HIGHEST_PROTOCOL)
loading
with open('tok.pickle', 'rb') as handle:
tok = pickle.load(handle)
#使用word_index属性可以看到每次词对应的编码
#使用word_counts属性可以看到每个词对应的频数
for ii,iterm in enumerate(tok.word_index.items()):
if ii < 10:
print(iterm)
else:
break
print("===================")
for ii,iterm in enumerate(tok.word_counts.items()):
if ii < 10:
print(iterm)
else:
break
#使用tok.texts_to_sequences()将数据转化为序列
#使用sequence.pad_sequences()将每个序列调整为相同的长度
#对每个词编码之后,每句语料中的每个词就可以用对应的编码表示,即每条语料可以转变成一个向量了
train_seq = tok.texts_to_sequences(train_df.fenci)
val_seq = tok.texts_to_sequences(val_df.fenci)
test_seq = tok.texts_to_sequences(test_df.fenci)
#将每个序列调整为相同的长度
train_seq_mat = sequence.pad_sequences(train_seq,maxlen=max_len)
val_seq_mat = sequence.pad_sequences(val_seq,maxlen=max_len)
test_seq_mat = sequence.pad_sequences(test_seq,maxlen=max_len)
print(train_seq_mat.shape) #(10000, 600)
print(val_seq_mat.shape) #(5000, 600)
print(test_seq_mat.shape) #(5000, 600)
print(train_seq_mat[:2])
#-------------------------------第四步 建立LSTM模型并训练-------------------------------
定义LSTM模型
inputs = Input(name='inputs',shape=[max_len])
Embedding(词汇表大小,batch大小,每个新闻的词长)
layer = Embedding(max_words+1, 128, input_length=max_len)(inputs)
layer = LSTM(128)(layer)
layer = Dense(128, activation="relu", name="FC1")(layer)
layer = Dropout(0.3)(layer)
layer = Dense(2, activation="softmax", name="FC2")(layer)
model = Model(inputs=inputs, outputs=layer)
model.summary()
model.compile(loss="categorical_crossentropy",
optimizer=RMSprop(),
metrics=["accuracy"])
增加判断 防止再次训练
flag = "train"
if flag == "train":
print("模型训练")
#模型训练
model_fit = model.fit(train_seq_mat, train_y, batch_size=128, epochs=10,
validation_data=(val_seq_mat,val_y),
callbacks=[EarlyStopping(monitor='val_loss',min_delta=0.0001)] #当val-loss不再提升时停止训练
)
#保存模型
model.save('my_model.h5')
del model # deletes the existing model
#计算时间
elapsed = (time.clock() - start)
print("Time used:", elapsed)
else:
print("模型预测")
# 导入已经训练好的模型
model = load_model('my_model.h5')
#--------------------------------------第五步 预测及评估--------------------------------
#对测试集进行预测
test_pre = model.predict(test_seq_mat)
#评价预测效果,计算混淆矩阵 参数顺序
confm = metrics.confusion_matrix(np.argmax(test_y,axis=1),np.argmax(test_pre,axis=1))
print(confm)
#混淆矩阵可视化
Labname = ['正常', '异常']
print(metrics.classification_report(np.argmax(test_y,axis=1),np.argmax(test_pre,axis=1)))
classification_pj(np.argmax(test_pre,axis=1),np.argmax(test_y,axis=1))
plt.figure(figsize=(8,8))
sns.heatmap(confm.T, square=True, annot=True,
fmt='d', cbar=False, linewidths=.6,
cmap="YlGnBu")
plt.xlabel('True label',size = 14)
plt.ylabel('Predicted label', size = 14)
plt.xticks(np.arange(2)+0.8, Labname, size = 12)
plt.yticks(np.arange(2)+0.4, Labname, size = 12)
plt.show()
#--------------------------------------第六步 验证算法--------------------------------
#使用tok对验证数据集重新预处理,并使用训练好的模型进行预测
val_seq = tok.texts_to_sequences(val_df.fenci)
#将每个序列调整为相同的长度
val_seq_mat = sequence.pad_sequences(val_seq,maxlen=max_len)
#对验证集进行预测
val_pre = model.predict(val_seq_mat)
print(metrics.classification_report(np.argmax(val_y,axis=1),np.argmax(val_pre,axis=1)))
classification_pj(np.argmax(val_pre,axis=1),np.argmax(val_y,axis=1))
#计算时间
elapsed = (time.clock() - start)
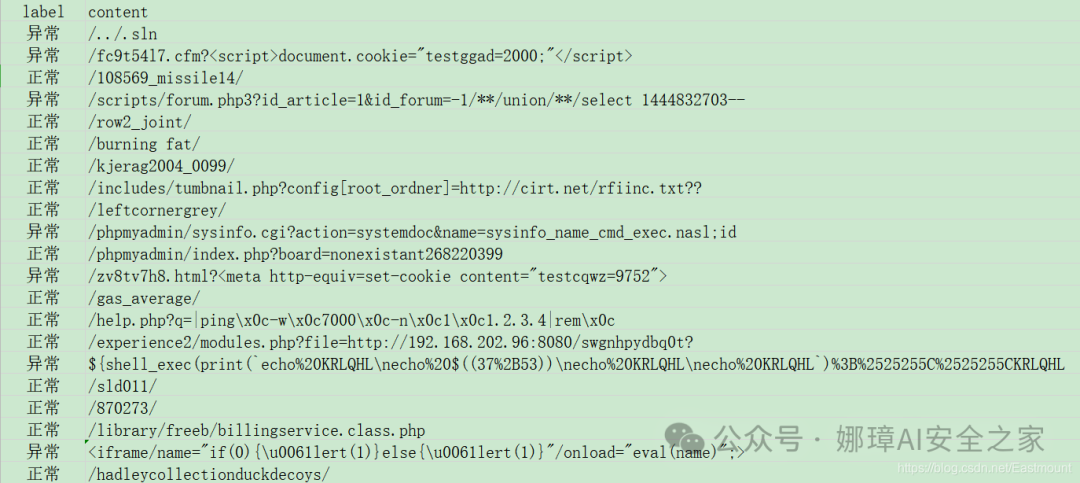
print("Time used:", elapsed)</code></pre></div></div><p>输出的部分结果如下图所示:</p><div class="rno-markdown-code"><div class="rno-markdown-code-toolbar"><div class="rno-markdown-code-toolbar-info"><div class="rno-markdown-code-toolbar-item is-type"><span class="is-m-hidden">代码语言:</span>javascript</div></div><div class="rno-markdown-code-toolbar-opt"><div class="rno-markdown-code-toolbar-copy"><i class="icon-copy"></i><span class="is-m-hidden">复制</span></div></div></div><div class="developer-code-block"><pre class="prism-token token line-numbers language-javascript"><code class="language-javascript" style="margin-left:0"> label fenci
0 异常 /.. ../ ./. /.s .sl sln
1 异常 /fc fc9 c9t 9t5 t54 54l 4l7 l7. 7.c .cf cfm fm...
2 正常 /10 108 085 856 569 69_ 9_m mi mis iss ssi si...
3 异常 /sc scr cri rip ipt pts ts/ s/f /fo for oru ru...
4 正常 /ro row ow2 w2 2_j _jo joi oin int nt/
LabelEncoder
[[0]
[0]
[1]
[0]
[1]
[1]
[1]
[1]
[1]
[0]]
10000
OneHotEncoder:
[[1. 0.]
[1. 0.]
[0. 1.]
[1. 0.]
[0. 1.]
[0. 1.]
[0. 1.]
[0. 1.]
[0. 1.]
[1. 0.]]
<keras_preprocessing.text.Tokenizer object at 0x00000208C5644C50>
('s', 7660)
('sl', 362)
('sln', 1)
('fc', 53)
('fc9', 4)
('c9t', 2)
('9t5', 2)
('t54', 3)
('54l', 2)
('4l7', 8)
(10000, 600)
(5000, 600)
(5000, 600)
[[ 0 0 0 ... 0 4 199]
[ 0 0 0 ... 17 19 24]]
训练过程如下所示:
代码语言:javascript复制Train on 10000 samples, validate on 5000 samples
Epoch 1/10
10000/10000 [==============================] - 250s 25ms/step - loss: 0.2590 - accuracy: 0.9102 - val_loss: 0.1295 - val_accuracy: 0.9626
Epoch 2/10
10000/10000 [==============================] - 248s 25ms/step - loss: 0.1783 - accuracy: 0.9616 - val_loss: 0.1642 - val_accuracy: 0.9366
Time used: 502.5310856
3.实验评估
当实验训练结束后,将flag变量设置为“test”进行测试,评估代码如下:
代码语言:javascript复制# -*- coding: utf-8 -*-
"""
author: Eastmount CSDN 2020-11-15
"""
import os
#评价指标 参数顺序
def classification_pj(pre, y_test):
# 正确率 Precision = 正确识别的个体总数 /识别出的个体总数
# 召回率 Recall = 正确识别的个体总数 / 测试集中存在的个体总数
# F值 F-measure = 正确率 * 召回率 * 2 / (正确率 + 召回率)
YC_A, YC_B = 0,0 #预测 bad good
ZQ_A, ZQ_B = 0,0 #正确
CZ_A, CZ_B = 0,0 #存在
#0-good 1-bad 同时计算防止类标变化
i = 0
while i<len(pre):
z = int(y_test[i]) #真实
y = int(pre[i]) #预测
if z==0:
CZ_A += 1
elif z==1:
CZ_B += 1
if y==0:
YC_A += 1
elif y==1:
YC_B += 1
if z==y and z==0 and y==0:
ZQ_A += 1
elif z==y and z==1 and y==1:
ZQ_B += 1
i = i + 1
# 结果输出
print(YC_A, YC_B, ZQ_A, ZQ_B,CZ_A, CZ_B)
P_A = ZQ_A * 1.0 / (YC_A + 0.1)
P_B = ZQ_B * 1.0 / (YC_B + 0.1)
print("Precision 0:{:.4f}".format(P_A))
print("Precision 1:{:.4f}".format(P_B))
print("Avg_precision:{:.4f}".format((P_A + P_B)/2))
R_A = ZQ_A * 1.0 / (CZ_A + 0.1)
R_B = ZQ_B * 1.0 / (CZ_B + 0.1)
print("Recall 0:{:.4f}".format(R_A))
print("Recall 1:{:.4f}".format(R_B))
print("Avg_recall:{:.4f}".format((R_A + R_B)/2))
F_A = 2 * P_A * R_A / (P_A + R_A)
F_B = 2 * P_B * R_B / (P_B + R_B)
print("F-measure 0:{:.4f}".format(F_A))
print("F-measure 1:{:.4f}".format(F_B))
print("Avg_fmeasure:{:.4f}".format((F_A + F_B)/2))
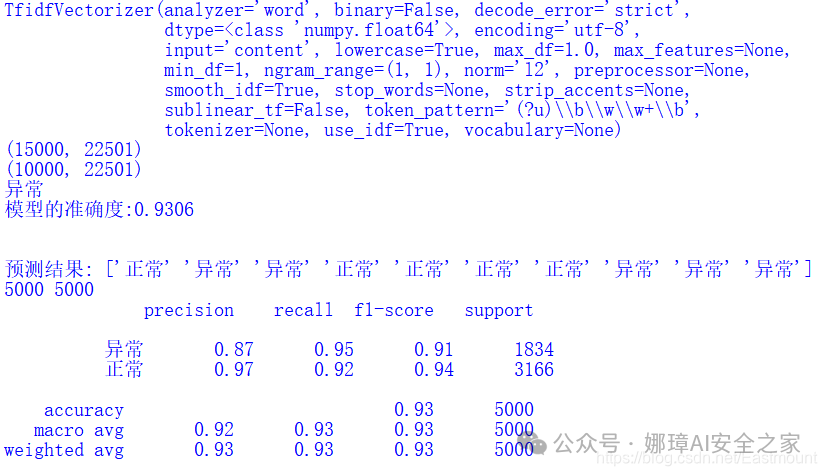
print("")</code></pre></div></div><p>输出结果如下图所示:</p><ul class="ul-level-0"><li>F值为0.9488</li><li>P值为0.9533</li><li>R值为0.9450</li></ul><div class="rno-markdown-code"><div class="rno-markdown-code-toolbar"><div class="rno-markdown-code-toolbar-info"><div class="rno-markdown-code-toolbar-item is-type"><span class="is-m-hidden">代码语言:</span>javascript</div></div><div class="rno-markdown-code-toolbar-opt"><div class="rno-markdown-code-toolbar-copy"><i class="icon-copy"></i><span class="is-m-hidden">复制</span></div></div></div><div class="developer-code-block"><pre class="prism-token token line-numbers language-javascript"><code class="language-javascript" style="margin-left:0">模型预测
[[1758 164]
[ 76 3002]]
precision recall f1-score support
0 0.96 0.91 0.94 1922
1 0.95 0.98 0.96 3078
accuracy 0.95 5000
macro avg 0.95 0.94 0.95 5000
weighted avg 0.95 0.95 0.95 5000
1834 3166 1758 3002 1922 3078
Precision 0:0.9585
Precision 1:0.9482
Avg_precision:0.9533
Recall 0:0.9146
Recall 1:0.9753
Avg_recall:0.9450
F-measure 0:0.9361
F-measure 1:0.9615
Avg_fmeasure:0.9488

当然你还可以和机器学习算法进行对比喔!前一篇文章作者不是详细讲解了机器学习的对比实验吗?比如决策树的运行结果如下图所示:
- F值为0.93
注意:大家可以直接在易学智能平台的PyCharm运行代码,也可以在自己搭建的环境运行。
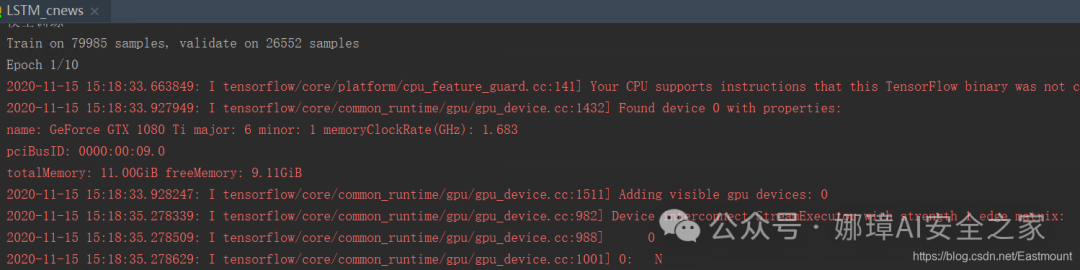
如果是GPU环境需要增加一些核心代码:
- ailed to create cublas handle: CUBLAS_STATUS_ALLOC_FAILED
- failed to allocate 9.90G (10630043904 bytes) from device: CUDA_ERROR_OUT_OF_MEMORY: out of memory
增加下面代码:
代码语言:javascript复制import os
os.environ["CUDA_DEVICES_ORDER"] = "PCI_BUS_IS"
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
#指定了每个GPU进程中使用显存的上限,0.9表示可以使用GPU 90%的资源进行训练
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.9)
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options))
"""
#TensorFlow2.0
gpus = tf.config.experimental.list_physical_devices('GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu,True)
"""
五.总结
写到这里,这篇文章就结束了,下一篇文章比较硬核,直接撰写代码详细对比CNN、LSTM、BiLSTM和BiLSTM+Attention文本分类实验。希望对您有所帮助,同时文章中不足或错误的地方,欢迎读者提出。这些实验都是我在做论文研究或项目评价常见的一些问题,希望读者带着这些问题,结合自己的需求进行深入的思考,更希望大家能学以致用。最后如果文章对您有帮助,请点赞、评论、收藏,这将是我分享最大的动力。github下载代码,记得关注点赞喔!
最后,作为人工智能的菜鸟,我希望自己能不断进步并深入,后续将它应用于图像识别、网络安全、对抗样本等领域,指导大家撰写简单的学术论文,一起加油!感谢这些年遇到很多以前进步的博友,共勉~

2020年新开的“娜璋AI安全之家”,主要围绕Python大数据分析、网络空间安全、人工智能、Web渗透及攻防技术进行讲解,同时分享CCF、SCI、南核北核论文的算法实现。娜璋之家会更加系统,并重构作者的所有文章,从零讲解Python和安全,写了近十多年文章,真心想把自己所学所感所做分享出来,还请各位多多指教,真诚邀请您的关注!谢谢。
(By:Eastmount 2024-03-12 夜于火星)