监控作为底层基础设施的一环,是保障生产环境服务稳定性不可或缺的一部分,线上问题从发现到定位再到解决,通过监控和告警手段可以有效地覆盖了「发现」和「定位」,甚至可以通过故障自愈等手段实现解决,服务开发和运维人员能及时有效地发现服务运行的异常,从而更有效率地排查和解决问题。
一个典型的监控(如白盒监控),通常会关注于目标服务的内部状态,例如:
- 单位时间接收到的请求数量
- 单位时间内请求的成功率/失败率
- 请求的平均处理耗时
白盒监控很好地描述了系统的内部状态,但缺少从外部角度看到的现象,比如:白盒监控只能看到已经接收的请求,并不能看到由于 DNS 故障导致没有发送成功的请求,而黑盒监控此时便可以作为补充手段,由探针(probe)程序来探测目标服务是否成功返回,更好地反馈系统的当前状态。
某日需要为服务搭建一个监控系统来采集应用埋点上报的指标,经过一番对比,最终选择了 Prometheus 来作为我们的业务监控,因为它具有以下优点:
- 支持 PromQL(一种查询语言),可以灵活地聚合指标数据
- 部署简单,只需要一个二进制文件就能跑起来,不需要依赖分布式存储
- Go 语言编写,组件更方便集成在同样是Go编写项目代码中
- 原生自带 WebUI,通过 PromQL 渲染时间序列到面板上
- 生态组件众多,Alertmanager,Pushgateway,Exporter……
Prometheus 的架构图如下:
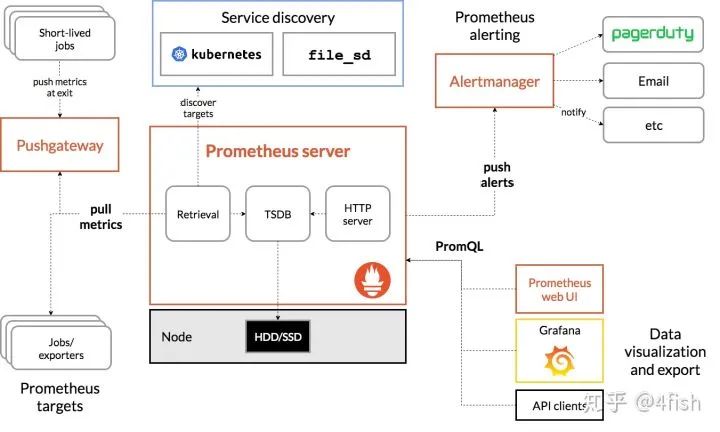
在上面流程中,Prometheus 通过配置文件中指定的服务发现方式来确定要拉取监控指标的目标(Target),接着从要拉取的目标(应用容器和Pushgateway)发起HTTP请求到特定的端点(Metric Path),将指标持久化至本身的TSDB中,TSDB最终会把内存中的时间序列压缩落到硬盘,除此之外,Prometheus 会定期通过 PromQL 计算设置好的告警规则,决定是否生成告警到 Alertmanager,后者接收到告警后会负责把通知发送到邮件或企业内部群聊中。
Prometheus 的指标名称只能由 ASCII 字符、数字、下划线以及冒号组成,而且有一套命名规范:
- 使用基础 Unit(如 seconds 而非 milliseconds)
- 指标名以 application namespace 作为前缀,如:
- process_cpu_seconds_total
- http_request_duration_seconds
- 用后缀来描述 Unit,如:
- http_request_duration_seconds
- node_memory_usage_bytes
- http_requests_total
- process_cpu_seconds_total
- foobar_build_info
Prometheus 提供了以下基本的指标类型:
- Counter:代表一种样本数据单调递增的指标,即只增不减,通常用来统计如服务的请求数,错误数等。
- Gauge:代表一种样本数据可以任意变化的指标,即可增可减,通常用来统计如服务的CPU使用值,内存占用值等。
- Histogram 和 Summary:用于表示一段时间内的数据采样和点分位图统计结果,通常用来统计请求耗时或响应大小等。
Prometheus 是基于时间序列存储的,首先了解一下什么是时间序列,时间序列的格式类似于(timestamp,value)这种格式,即一个时间点拥有一个对应值,例如生活中很常见的天气预报,如:[(14:00,27℃),(15:00,28℃),(16:00,26℃)],就是一个单维的时间序列,这种按照时间戳和值存放的序列也被称之为向量(vector)。

再来举另一个例子,如上图所示,假如有一个指标 http_requests,它的作用是统计每个时间段对应的总请求量是多少,这时候它即为上面提到的是一个单维矩阵,而当我们给这个指标加上一个维度:主机名,这时候这个指标的作用就变成了统计每个时间段各个主机名对应的请求量是多少,这时候这个矩阵区域就变成拥有多列向量(每一列对应一个主机名)的时间序列,当给这个时间序列再添加多个标签(key=value)时,这个矩阵就相应会变成一个多维矩阵。
每一组唯一的标签集合对应着一个唯一的向量(vector),也可叫做一个时间序列(Time Serie),当在某一个时间点来看它时,它是一个瞬时向量(Instant Vector),瞬时向量的时序只有一个时间点以及它对于的一个值,比如:今天 12:05:30 时服务器的 CPU 负载;而在一个时间段来看它时,它是一个范围向量(Range Vector),范围向量对于着一组时序数据,比如:今天11:00到12:00时服务器的CPU负载。
类似的,可以通过指标名和标签集来查询符合条件的时间序列:
http_requests{host="host1",service="web",code="200",env="test"}查询结果会是一个瞬时向量:
http_requests{host="host1",service="web",code="200",env="test"} 10
http_requests{host="host2",service="web",code="200",env="test"} 0
http_requests{host="host3",service="web",code="200",env="test"} 12而如果给这个条件加上一个时间参数,查询一段时间内的时间序列:
http_requests{host="host1",service="web",code="200",env="test"}[:5m]结果将会是一个范围向量:
http_requests{host="host1",service="web",code="200",env="test"} 0 4 6 8 10
http_requests{host="host2",service="web",code="200",env="test"} 0 0 0 0 0
http_requests{host="host3",service="web",code="200",env="test"} 0 2 5 9 12拥有了范围向量,我们是否可以针对这些时间序列进行一些聚合运算呢?没错,PromQL就是这么干的,比如我们要算最近5分钟的请求增长速率,就可以拿上面的范围向量加上聚合函数来做运算:
rate(http_requests{host="host1",service="web",code="200",env="test"}[:5m])比如要求最近5分钟请求的增长量,可以用以下的 PromQL:
increase(http_requests{host="host1",service="web",code="200",env="test"}[:5m])要计算过去10分钟内第90个百分位数:
histogram_quantile(0.9, rate(employee_age_bucket_bucket[10m]))在 Prometheus 中,一个指标(即拥有唯一的标签集的 metric)和一个(timestamp,value)组成了一个样本(sample),Prometheus 将采集的样本放到内存中,默认每隔2小时将数据压缩成一个 block,持久化到硬盘中,样本的数量越多,Prometheus占用的内存就越高,因此在实践中,一般不建议用区分度(cardinality)太高的标签,比如:用户IP,ID,URL地址等等,否则结果会造成时间序列数以指数级别增长(label数量相乘)。
除了控制样本数量和大小合理之外,还可以通过降低 storage.tsdb.min-block-duration 来加快数据落盘时间和增加 scrape interval 的值提高拉取间隔来控制 Prometheus 的占用内存。
通过声明配置文件中的 scrape_configs 来指定 Prometheus 在运行时需要拉取指标的目标,目标实例需要实现一个可以被 Prometheus 进行轮询的端点,而要实现一个这样的接口,可以用来给 Prometheus 提供监控样本数据的独立程序一般被称作为 Exporter,比如用来拉取操作系统指标的 Node Exporter,它会从操作系统上收集硬件指标,供 Prometheus 来拉取。
在开发环境,往往只需要部署一个 Prometheus 实例便可以满足数十万指标的收集。但在生产环境中,应用和服务实例数量众多,只部署一个 Prometheus 实例通常是不够的,比较好的做法是部署多个Prometheus实例,每个实例通过分区只拉取一部分指标,例如Prometheus Relabel配置中的hashmod功能,可以对拉取目标的地址进行hashmod,再将结果匹配自身ID的目标保留:
relabel_configs:
- source_labels: [__address__]
modulus: 3
target_label: __tmp_hash
action: hashmod
- source_labels: [__tmp_hash]
regex: $(PROM_ID)
action: keep或者说,我们想让每个 Prometheus 拉取一个集群的指标,一样可以用 Relabel 来完成:
relabel_configs:
- source_labels: ["__meta_consul_dc"]
regex: "dc1"
action: keep现在每个 Prometheus 都有各自的数据了,那么怎么把他们关联起来,建立一个全局的视图呢?官方提供了一个做法:联邦集群(federation),即把 Prometheuse Server 按照树状结构进行分层,根节点方向的 Prometheus 将查询叶子节点的 Prometheus 实例,再将指标聚合返回。
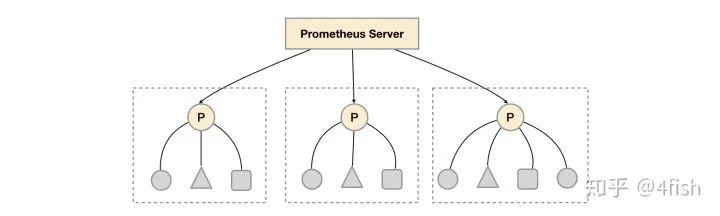
不过显然易见的时,使用联邦集群依然不能解决问题,首先单点问题依然存在,根节点挂了的话查询将会变得不可用,如果配置多个父节点的话又会造成数据冗余和抓取时机导致数据不一致等问题,而且叶子节点目标数量太多时,更加会容易使父节点压力增大以至打满宕机,除此之外规则配置管理也是个大麻烦。
还好社区出现了一个 Prometheus 的集群解决方案:Thanos,它提供了全局查询视图,可以从多台Prometheus查询和聚合数据,因为所有这些数据均可以从单个端点获取。

- Querier 收到一个请求时,它会向相关的 Sidecar 发送请求,并从他们的 Prometheus 服务器获取时间序列数据。
- 它将这些响应的数据聚合在一起,并对它们执行 PromQL 查询。它可以聚合不相交的数据也可以针对 Prometheus 的高可用组进行数据去重。
再来说到存储,Prometheus 查询的高可用可以通过水平扩展+统一查询视图的方式解决,那么存储的高可用要怎么解决呢?在 Prometheus 的设计中,数据是以本地存储的方式进行持久化的,虽然本地持久化方便,当也会带来一些麻烦,比如节点挂了或者 Prometheus 被调度到其他节点上,就会意味着原节点上的监控数据在查询接口中丢失,本地存储导致了 Prometheus 无法弹性扩展,为此 Prometheus 提供了 Remote Read 和 Remote Write 功能,支持把 Prometheus 的时间序列远程写入到远端存储中,查询时可以从远端存储中读取数据。
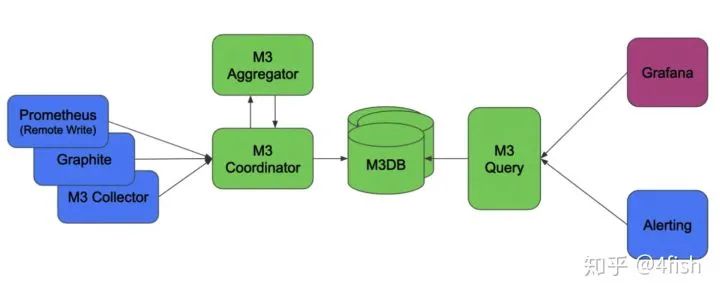
其中一个例子中就是M3DB,M3DB是一个分布式的时间序列数据库,它提供了Prometheus的远程读写接口,当一个时间序列写入到M3DB集群后会按照分片(Shard)和复制(Replication Factor)参数把数据复制到集群的其他节点上,实现存储高可用。除了M3DB外,Prometheus目前还支持InfluxDB、OpenTSDB等作为远程写的端点。
解决了 Prometheus 的高可用,再来关注一下 Prometheus 如何对监控目标进行采集,当监控节点数量较小时,可以通过 Static Config 将目标主机列表写到 Prometheus 的拉取配置中,但如果目标节点一多的话这种方式管理便有很大问题了,而且在生产环境中,服务实例的IP通常不是固定的,这时候用静态配置就没办法对目标节点进行有效管理,这时候 Prometheus 提供的服务发现功能便可以有效解决监控节点状态变化的问题,在这种模式下,Prometheus 会到注册中心监听查询节点列表,定期对节点进行指标的拉取。
如果对服务发现有更灵活的需求,Prometheus 也支持基于文件的服务发现功能,这时候我们可以从多个注册中心中获取节点列表,再通过自己的需求进行过滤,最终写入到文件,这时候 Prometheus 检测到文件变化后便能动态地替换监控节点,再去拉取目标了。
前面看到 Prometheus 都是以拉模式定期对目标节点进行抓取的,那假如有一种情况是一些任务节点还没来得及被拉取就运行完退出了,这时候监控数据就会丢失,为了应对这种情况,Prometheus 提供了一个工具:Pushgateway,用来接收来自服务的主动上报,它适用于那些短暂存活的批量任务来将指标推送并暂存到自身上,借着再由Prometheus 来拉取自身,以防止指标还没来得及被 Prometheus 拉取便退出。
除此以外 Pushgateway 也适用于在 Prometheus 与应用节点运行在异构网络或被防火墙隔绝时,无法主动拉取节点的问题,在这种情况下应用节点可以通过使用Pushgateway的域名将指标推送到Pushgateway实例上,Prometheus就可以拉取同网络下的Pushgateway 节点了,另外配置拉取 Pushgateway 时要注意一个问题:Prometheus 会把每个指标赋予 job 和instance标签,当Prometheus拉取Pushgateway时,job和instance则可能分别是Pushgateway和Pushgateway主机的ip,当pushgateway上报的指标中也包含job和instance标签时,Prometheus会把冲突的标签重命名为exported_job和exported_instance,如果需要覆盖这两个标签的话,需要在Prometheus中配置honor_labels: true。
Pushgateway可以替代拉模型来作为指标的收集方案,但在这种模式下会带来许多负面影响:
Pushgateway 被设计为一个监控指标的缓存,这意味着它不会主动过期服务上报的指标,这种情况在服务一直运行的时候不会有问题,但当服务被重新调度或销毁时,Pushgateway 依然会保留着之前节点上报的指标。而且,假如多个 Pushgateway 运行在LB下,会造成一个监控指标有可能出现在多个 Pushgateway 的实例上,造成数据重复多份,需要在代理层加入一致性哈希路由来解决。
在拉模式下,Prometheus可以更容易的查看监控目标实例的健康状态,并且可以快速定位故障,但在推模式下,由于不会对客户端进行主动探测,因此对目标实例的健康状态也变得一无所知。
最后再来聊一下Alertmanager,简单说 Alertmanager 是与 Prometheus 分离的告警组件,主要接收 Promethues 发送过来的告警事件,然后对告警进行去重,分组,抑制和发送,在实际中可以搭配 webhook 把告警通知发送到企业微信或钉钉上,其架构图如下:

最后的最后再来尝试一下用 Kubernetes 来搭建一套 Prometheus 的监控系统,关于Kubernetes 也是摸爬滚打折腾了一周才清楚怎么使用的,虽然 Promehteus 已经有官方的 Operator 了,但是为了学习都用手动编写 yaml 文件,整个完成下来发现还是挺方便的,而且只需要用几个实例就可以完成收集监控200+服务数千个实例的业务指标。
为了部署 Prometheus 实例,需要声明 Prometheus 的 StatefulSet,Pod 中包括了三个容器,分别是 Prometheus 以及绑定的 Thanos Sidecar,最后再加入一个 watch 容器,来监听 prometheus 配置文件的变化,当修改 ConfigMap 时就可以自动调用Prometheus 的 Reload API 完成配置加载,这里按照之前提到的数据分区的方式,在Prometheus 启动前加入一个环境变量 PROM_ID,作为 Relabel 时 hashmod 的标识,而 POD_NAME 用作 Thanos Sidecar 给 Prometheus 指定的 external_labels.replica 来使用:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: prometheus
labels:
app: prometheus
spec:
serviceName: "prometheus"
updateStrategy:
type: RollingUpdate
replicas: 3
selector:
matchLabels:
app: prometheus
template:
metadata:
labels:
app: prometheus
thanos-store-api: "true"
spec:
serviceAccountName: prometheus
volumes:
- name: prometheus-config
configMap:
name: prometheus-config
- name: prometheus-data
hostPath:
path: /data/prometheus
- name: prometheus-config-shared
emptyDir: {}
containers:
- name: prometheus
image: prom/prometheus:v2.11.1
args:
- --config.file=/etc/prometheus-shared/prometheus.yml
- --web.enable-lifecycle
- --storage.tsdb.path=/data/prometheus
- --storage.tsdb.retention=2w
- --storage.tsdb.min-block-duration=2h
- --storage.tsdb.max-block-duration=2h
- --web.enable-admin-api
ports:
- name: http
containerPort: 9090
volumeMounts:
- name: prometheus-config-shared
mountPath: /etc/prometheus-shared
- name: prometheus-data
mountPath: /data/prometheus
livenessProbe:
httpGet:
path: /-/healthy
port: http
- name: watch
image: watch
args: ["-v", "-t", "-p=/etc/prometheus-shared", "curl", "-X", "POST", "--fail", "-o", "-", "-sS", "http://localhost:9090/-/reload"]
volumeMounts:
- name: prometheus-config-shared
mountPath: /etc/prometheus-shared
- name: thanos
image: improbable/thanos:v0.6.0
command: ["/bin/sh", "-c"]
args:
- PROM_ID=`echo $POD_NAME| rev | cut -d '-' -f1` /bin/thanos sidecar
--prometheus.url=http://localhost:9090
--reloader.config-file=/etc/prometheus/prometheus.yml.tmpl
--reloader.config-envsubst-file=/etc/prometheus-shared/prometheus.yml
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
ports:
- name: http-sidecar
containerPort: 10902
- name: grpc
containerPort: 10901
volumeMounts:
- name: prometheus-config
mountPath: /etc/prometheus
- name: prometheus-config-shared
mountPath: /etc/prometheus-shared因为 Prometheus 默认是没办法访问 Kubernetes 中的集群资源的,因此需要为之分配RBAC:
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: prometheus
namespace: default
labels:
app: prometheus
rules:
- apiGroups: [""]
resources: ["services", "pods", "nodes", "nodes/proxy", "endpoints"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["configmaps"]
verbs: ["create"]
- apiGroups: [""]
resources: ["configmaps"]
resourceNames: ["prometheus-config"]
verbs: ["get", "update", "delete"]
- nonResourceURLs: ["/metrics"]
verbs: ["get"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: prometheus
namespace: default
labels:
app: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: default
roleRef:
kind: ClusterRole
name: prometheus
apiGroup: ""接着 Thanos Querier 的部署比较简单,需要在启动时指定 store 的参数为dnssrv+thanos-store-gateway.default.svc来发现Sidecar:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: thanos-query
name: thanos-query
spec:
replicas: 2
selector:
matchLabels:
app: thanos-query
minReadySeconds: 5
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
template:
metadata:
labels:
app: thanos-query
spec:
containers:
- args:
- query
- --log.level=debug
- --query.timeout=2m
- --query.max-concurrent=20
- --query.replica-label=replica
- --query.auto-downsampling
- --store=dnssrv+thanos-store-gateway.default.svc
- --store.sd-dns-interval=30s
image: improbable/thanos:v0.6.0
name: thanos-query
ports:
- containerPort: 10902
name: http
- containerPort: 10901
name: grpc
livenessProbe:
httpGet:
path: /-/healthy
port: http
---
apiVersion: v1
kind: Service
metadata:
labels:
app: thanos-query
name: thanos-query
spec:
type: LoadBalancer
ports:
- name: http
port: 10901
targetPort: http
selector:
app: thanos-query
---
apiVersion: v1
kind: Service
metadata:
labels:
thanos-store-api: "true"
name: thanos-store-gateway
spec:
type: ClusterIP
clusterIP: None
ports:
- name: grpc
port: 10901
targetPort: grpc
selector:
thanos-store-api: "true"
部署Thanos Ruler:apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: thanos-rule
name: thanos-rule
spec:
replicas: 1
selector:
matchLabels:
app: thanos-rule
template:
metadata:
labels:
labels:
app: thanos-rule
spec:
containers:
- name: thanos-rule
image: improbable/thanos:v0.6.0
args:
- rule
- --web.route-prefix=/rule
- --web.external-prefix=/rule
- --log.level=debug
- --eval-interval=15s
- --rule-file=/etc/rules/thanos-rule.yml
- --query=dnssrv+thanos-query.default.svc
- --alertmanagers.url=dns+http://alertmanager.default
ports:
- containerPort: 10902
name: http
volumeMounts:
- name: thanos-rule-config
mountPath: /etc/rules
volumes:
- name: thanos-rule-config
configMap:
name: thanos-rule-config部署 Pushgateway:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: pushgateway
name: pushgateway
spec:
replicas: 15
selector:
matchLabels:
app: pushgateway
template:
metadata:
labels:
app: pushgateway
spec:
containers:
- image: prom/pushgateway:v1.0.0
name: pushgateway
ports:
- containerPort: 9091
name: http
resources:
limits:
memory: 1Gi
requests:
memory: 512Mi
---
apiVersion: v1
kind: Service
metadata:
labels:
app: pushgateway
name: pushgateway
spec:
type: LoadBalancer
ports:
- name: http
port: 9091
targetPort: http
selector:
app: pushgateway部署 Alertmanager:
apiVersion: apps/v1
kind: Deployment
metadata:
name: alertmanager
spec:
replicas: 3
selector:
matchLabels:
app: alertmanager
template:
metadata:
name: alertmanager
labels:
app: alertmanager
spec:
containers:
- name: alertmanager
image: prom/alertmanager:latest
args:
- --web.route-prefix=/alertmanager
- --config.file=/etc/alertmanager/config.yml
- --storage.path=/alertmanager
- --cluster.listen-address=0.0.0.0:8001
- --cluster.peer=alertmanager-peers.default:8001
ports:
- name: alertmanager
containerPort: 9093
volumeMounts:
- name: alertmanager-config
mountPath: /etc/alertmanager
- name: alertmanager
mountPath: /alertmanager
volumes:
- name: alertmanager-config
configMap:
name: alertmanager-config
- name: alertmanager
emptyDir: {}
---
apiVersion: v1
kind: Service
metadata:
labels:
name: alertmanager-peers
name: alertmanager-peers
spec:
type: ClusterIP
clusterIP: None
selector:
app: alertmanager
ports:
- name: alertmanager
protocol: TCP
port: 9093
targetPort: 9093最后部署一下 ingress,大功告成:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: pushgateway-ingress
annotations:
kubernetes.io/ingress.class: "nginx"
nginx.ingress.kubernetes.io/upstream-hash-by: "$request_uri"
nginx.ingress.kubernetes.io/ssl-redirect: "false"
spec:
rules:
- host: $(DOMAIN)
http:
paths:
- backend:
serviceName: pushgateway
servicePort: 9091
path: /metrics
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: prometheus-ingress
annotations:
kubernetes.io/ingress.class: "nginx"
spec:
rules:
- host: $(DOMAIN)
http:
paths:
- backend:
serviceName: thanos-query
servicePort: 10901
path: /
- backend:
serviceName: alertmanager
servicePort: 9093
path: /alertmanager
- backend:
serviceName: thanos-rule
servicePort: 10092
path: /rule
- backend:
serviceName: grafana
servicePort: 3000
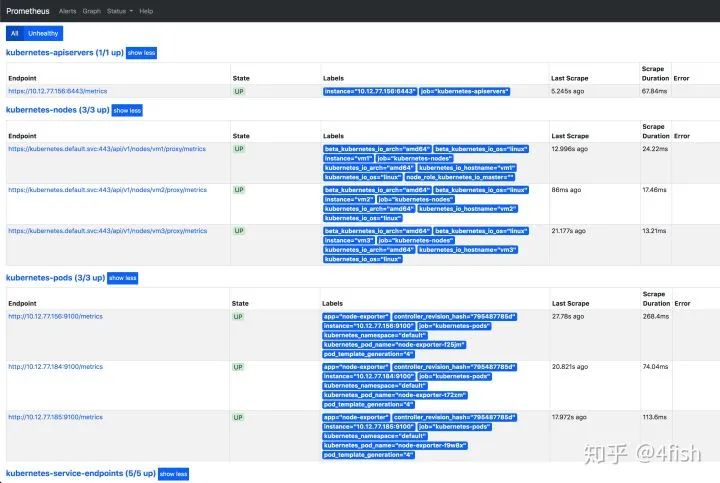
path: /grafana访问 Prometheus 地址,监控节点状态正常:
来源:https://zhuanlan.zhihu.com/p/101184971