前 言 🍉 作者简介:半旧518,长跑型选手,立志坚持写10年博客,专注于java后端 ☕专栏简介:相当硬核,黑皮书《数据库系统概念》读书笔记,讲解: 1.数据库系统的基本概念(数据库设计过程、关系型数据库理论、数据库应用的设计与开发…) 2.大数据分析(大数据存储系统,键值存储,Nosql系统,MapReduce,Apache Spark,流数据和图数据库等…) 3.数据库系统的实现技术(数据存储结构,缓冲区管理,索引结构,查询执行算法,查询优化算法,事务的原子性、一致性、隔离型、持久性等基本概念,并发控制与故障恢复技术…) 4.并行和分布式数据库(集中式、客户-服务器、并行和分布式,基于云系统的计算机体系结构…) 5.更多数据库高级主题(LSM树及其变种、位图索引、空间索引、动态散列等索引结构的拓展,高级应用开发中的性能调整,应用程序移植和标准化,数据库与区块链等…) 🌰 文章简介:这篇文章将介绍大数据的动机、存储系统、MapReduce范式、代数运算、流数据、图数据库等,带你入门大数据
文章目录
- 1.动机
- 1.1 大数据的来源和使用
- 1.2 大数据查询
- 2.存储系统
- 2.1 分布式文件系统
- 2.2 分片
- 2.3 键值存储系统
- 2.4 并行数据库
- 2.5 复制和一致性
- 3.MapReduce范式
- 3.1 为什么要使用MapReduce
- 3.2 MapReduce是什么?
- 3.3 MapReduce示例:词汇统计
- 3.4 MapReduce任务的并行处理
- 3.5 Hadoop中的MapReduce
- 3.6 MapReduce上的SQL
- 4.超越MapReduce——代数运算
- 4.1 代数运算的动机
- 4.2 Spark中的代数运算
- 5.流数据
- 5.1 流数据的应用
- 5.2 流数据查询
- 5.3 流上的代数运算
- 6.图数据库
1.动机
1.1 大数据的来源和使用
随着计算机的飞速发展,网站产生了大量数据,数据规模远超传统数据库系统能够处理的规模,我们把具有量大,存储速度要求高,数据多样性丰富的特征的数据统称为大数据。

大数据的来源方方面面。比如社交软件,零售业交易数据,物联网设备。
大数据的应用可以帮助分析用户的偏好,精准推送内容、广告、商品等。
目前已经有几个系统用于存储和处理大数据,他们使用集群技术,集群中的机器使用术语节点(node)表示。
1.2 大数据查询
关系型数据库主要通过SQL进行查询,大数据查询受到其非常大的数据量/高速处理的需求驱动,选择余地更大。
构建能够扩展到大数据量/高速处理的数据管理系统需要并行存储和处理数据。构建一个支持SQL及诸如事务那样的其他数据库特性的关系型数据库,并同时通过大量机器上运行来支持非常高的性能,这不是一项简单的任务。这类应用可分为两类。
1.需要非常高的可扩展性的事务处理系统:事务处理系统支持大量短时间运行的查询和更新。
如果对支持关系数据库的所有特性的要求放松,那么被设计用于支持事务处理的数据库就很容易扩展到非常多的机器上。许多需要扩展到非常大的数据量/高速处理的事务处理应用可以在没有完整的数据库支持的情况下进行管理。
此类应用的数据访问的主要模式是使用关联的键存储数据,并使用该键检索数据。这样的存储系统称为键值存储系统。在前面的用户配置文件示例中,用户配置文件数据的键可以是用户的标识。有些应用在概念上需要连接,但通过应用程序代码或者视图的形式来实现连接。
例如,在社交网络应用中,当一个用户连接到系统时,系统应该向该用户显示来自其所有朋友的新贴子。如果有关贴子和朋友的数据是以关系形式来维护的,那么这就需要一个连接。反之,假设系统在键值存储中为每个用户维护一个对象,包括他们的朋友的信息以及这些朋友的贴子。应用程序可以通过受限找出用户的朋友集,然后查询每个朋友的数据对象来找到他们的贴子。以这种方式实现连接而不是在数据库中完成连接。另一种选择如下:每当用户u0发布贴子时,对于该用户的每个朋友ui,系统都会向代表ui的数据对象发送一条消息,并且将与该朋友关联的数据用新帖子的摘要进行更新。当用户ui检查更新时,提供朋友贴子摘要视图所需的所有数据可以在一个地方获得,并且可被快速检索。
这两种备选方案之间存在着权衡,比如,第一种备选方案在查询时代价高,第二种方式在存储和写入时代价高。但这两种方法都允许应用在不支持连接的情况下在键值存储系统中执行其任务。
2.需要非常高的扩展性且支持非关系数据的查询处理系统.。此类系统的典型示例是哪些被设计用来对网络服务器和其他应用程序产生的日志进行分析的系统。其他示例包括文档和知识的存储及索引系统,例如那些在网络上支持关键字搜索的系统。
许多此类应用所使用的数据存储在多个文件中。设计用于支持此类应用的系统受限需要能够存储大量的大型文件。其次,它必须能够支持对存储在这些文件中的数据进行查询。由于数据不一定是关系型的,因此为查询此类数据而设计的系统必须支持任意程序代码,而不仅仅支持关系代数或者SQL查询。
大数据应用通常需要处理大量的文本、图像和视频数据。本篇文章我们将介绍当前广泛使用的大数据查询技术,这些技术允许指定复杂的数据处理任务,同时使得任务能容易地并行化。让程序员不必关注这些复杂的低层问题。
2.存储系统
大数据上得应用具有极高的可扩展性要求,现在已经有许多用于大数据存储的系统。这些系统包括。
- 分布式文件系统。他们允许文件跨大量机器存储,同时允许使用传统的文件系统接口访问文件。分布式文件系统用于存储大型文件,还被用作能支持记录存储的系统的存储层。
- 跨多数据库分片。分片是指跨多个系统对记录进行划分的过程;换言之,记录在系统之间划分。分片的一个典型应用案例是跨数据库集合对不同用户对应的记录进行划分。每个数据库都是传统的集中式数据库,可能没有其他数据库的任何信息。客户机软件的工作是跟踪记录是如何划分的,并将每个查询发送给相应的数据库。
- 键值存储系统。它们允许基于键的方式来存储和检索记录。此外可能提供有限的查询工具。但是它们不是成熟的数据库系统,又被称为NoSQL系统,因为此类存储系统通常不支持SQL语言。
- 并行和分布式数据库。它们提供传统的数据库接口,但是跨多台机器存储数据,并且跨多台机器并行执行查询处理。
2.1 分布式文件系统
分布式文件系统(distritubuted file system,DFS)跨大量机器存储文件,同时为客户机提供单一的文件系统视图。与任何文件系统类似,它是一个由文件名和目录构成的系统,客户机不需要关注文件存储在哪里,这种分布式文件系统可以存储大量的数据,并支持非常大量的并发客户机。此类系统非常适合存储非结构化数据,如网页、网络服务器日志、图像等,这些非结构化数据被存储为大型文件。
DFS的一个里程碑系统是Google的GFS,基于GFS体系结构的Hadoop文件系统现在也得到了广泛的应用。
分布式系统可以将文件分块,跨机器划分存储。
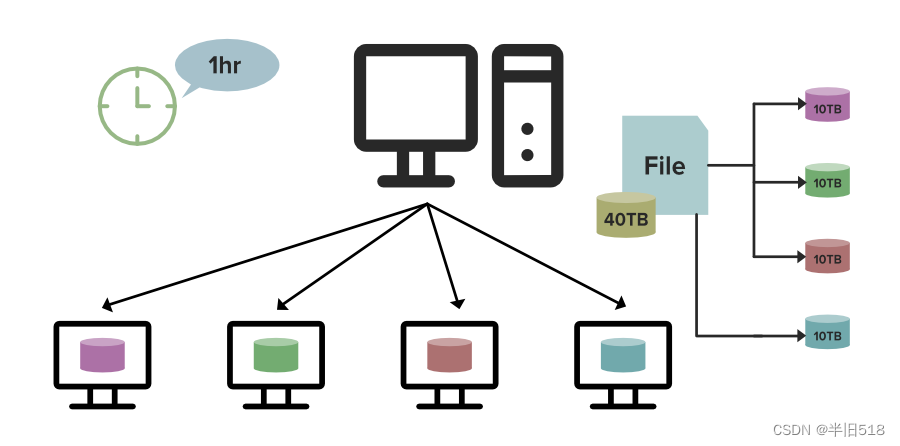
此外,每个文件库跨多台(通常是三台)机器进行复制,这样机器就不会因为故障导致文件无法访问。
下图显示了Hadoop文件系统的体系结构。HDFS的核心是一台运行在被称为名字节点(NameNode)的机器上的服务器,存储HDFS中数据块的机器被称为数据节点(DataNode)。
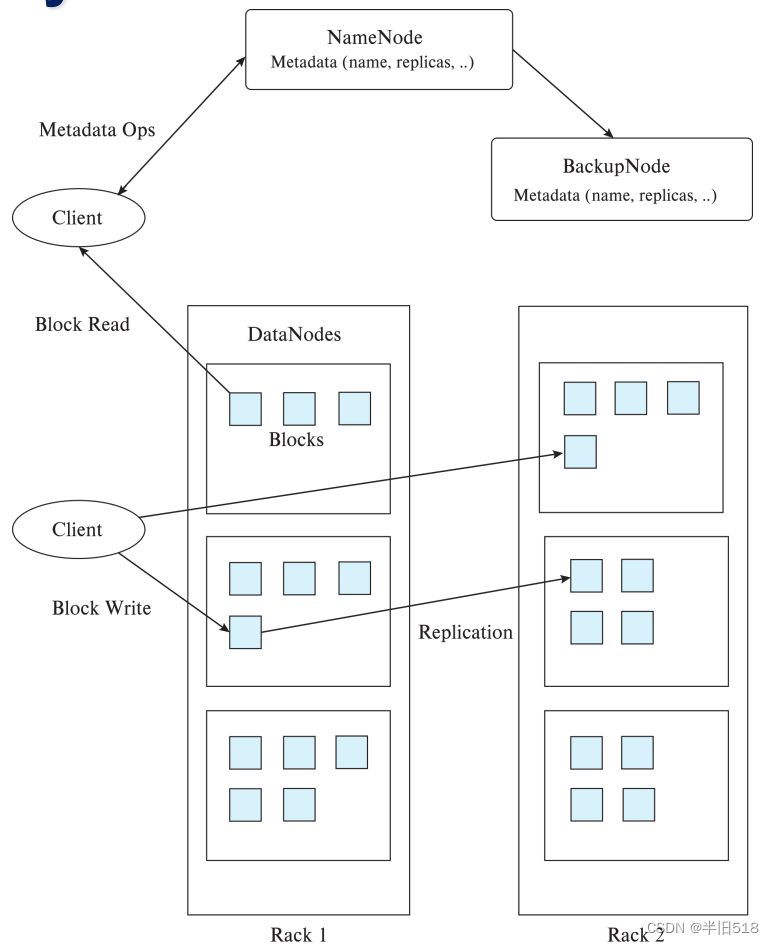
所有的系统请求都被发送到NameNode。
对于文件读取请求,HDFS服务器将返回文件中块的块标识列表以及包含在每个块的标识列表,然后从存储该块副本的其中一台机器中提取出每个块。
对于文件写入请求,HDFS服务器创建新的块标识,将每个块标识分配给多台(通常为三台)机器,并将块标识和机器分配返回给客户机。然后客户机将块标识和块数据发送给存储数据的指定机器。
可以通过HDFS文件系统API的程序来访问这些文件,这些API在诸如Java,Python等语言中都是可用的。
HDFS分布式文件系统也可以连接到机器的本地文件系统,这样就可以像访问存储在本地的文件那样访问HDFS中的文件。这需要向本地文件系统提供名字节点机器的地址和HDFS服务器侦听请求的端口。本地文件系统根据文件路径识别哪些文件访问是针对HDFS中的文件的,并向HDFS服务器发送相应的请求。
2.2 分片
单一数据库无法满足海量数据的存储、处理。如果已经采用了集中式数据库构建应用,需要扩展来处理更多用户,一种常用方式是跨多个数据库划分数据,并将用户的子集分配给每个数据库,这被称为分片(sharding)。
划分通常在一个或者多个属性上完成,这些属性被称为划分属性、划分键或分片键。用户被账户标识通常用作划分键。划分可以通过定义每个数据库处理的键的范围来完成,例如,1~10000划分给数据库A,10001~20000划分给数据库B。这种划分称为范围划分。还可以通过哈希函数进行哈希划分。
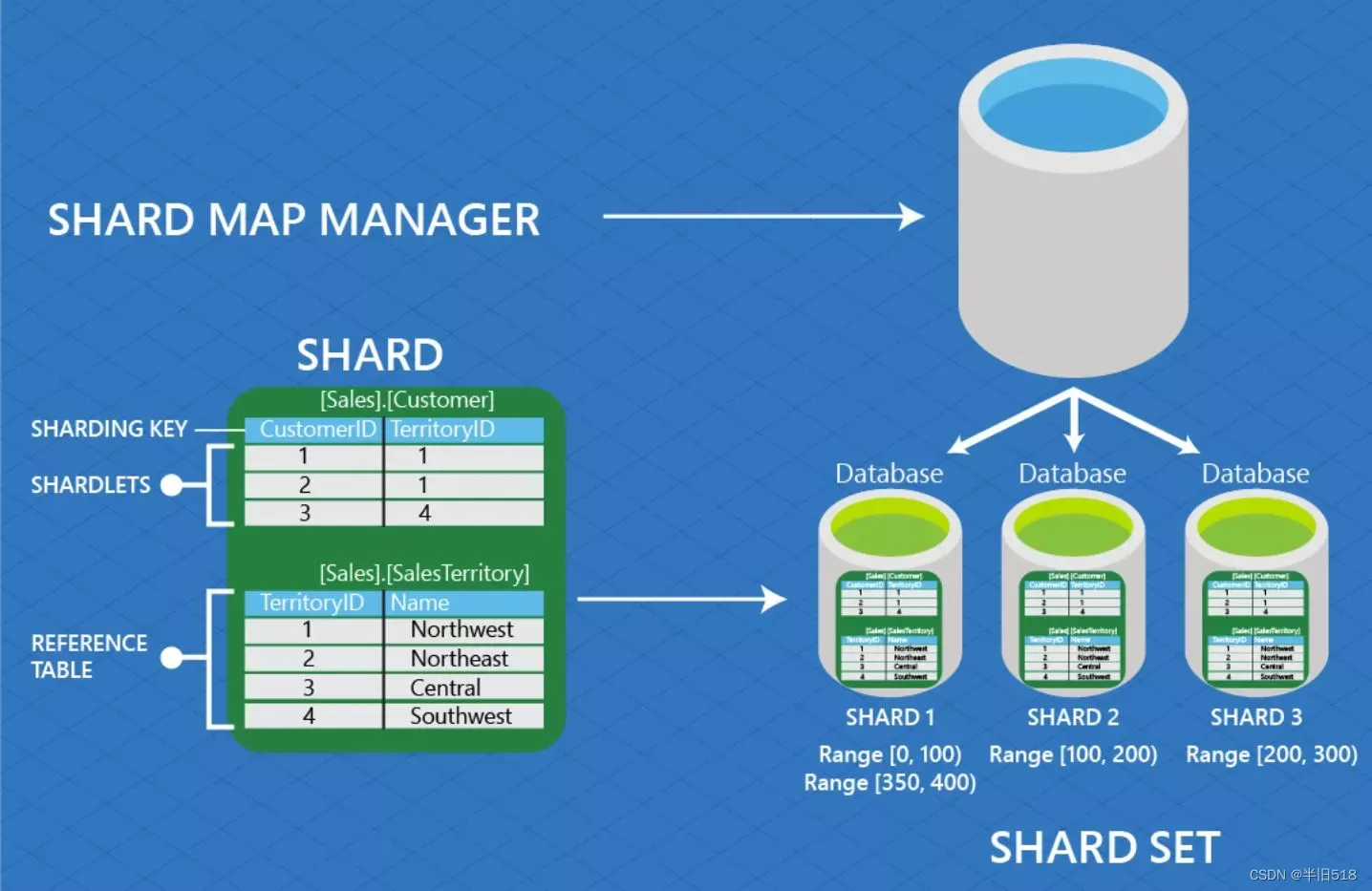
当在应用程序代码中进行分片时,应用程序必须跟踪哪个键存储在哪个数据库上,并且必须将查询路由到相应的数据库。无法用简单的方式来处理从多个数据库读取或者更新数据的查询,因为不可能提交跨所有数据库的单个查询。应用程序需要从多个数据库中读取数据并计算最终的查询结果。跨数据库更新会导致更多问题。除此之外,如果一个数据库过载,则必须将该数据库中的部分数据卸载到其他数据库…后续文章我们将讨论这些问题
2.3 键值存储系统
许多网络应用需要存储非常大量(数十亿或者极端情况下数万亿)但相对较小(几千字节到几兆字节)的记录。
理想情况下,应该使用大规模并行的关系数据库来存储此类数据,但是,构建可以跨大量机器并行运行同时支持诸如外码约束和事务那样的标准数据库特征的关系数据库系统并不容易。
键值存储系统提供了一种解决方案。
并行键值存储跨多台机器来存储划分键,并把更新和查找处理路由到正确的机器,它们还支持复制,确保数据的一致性。此外,它们还提供了在需要时向系统添加更多的机器的能力,并且确保负载在系统中的机器自动均衡。因此,当前并行键值存储相比分片得到了更广泛的应用。
广泛应用的键值存储包括Bigtable,HBase,Dynamo,MongoDB,Cassandra…
有些键值数据存储将存储中的值看做不可解释的字节序列,而不看其内容。但其他数据存储允许某种形式的结构或模式与每条记录相关联。有些键值存储系统要求所存储的数据遵循特定的数据表示,允许数据存储系统解释被存储的值,并基于所存储的值执行简单查询,这种数据存储被称为文档存储。
文档是一组键值(key-value)对。一个简单的文档例子如下:
{"site":"www.runoob.com", "name":"菜鸟教程"}MongoDB是一个代表,它接受JSON格式的值。
使用键值存储的一个重要动机是,通过将工作分布在由大量机器组成的集群(cluster),能够处理非常大量的数据及查询。但是键值存储通常不支持声明式查询(如SQL,因此它也被称为NoSQL系统),事务,这是为了支持高扩展性而采取的牺牲。
不过缺少上述支持会使应用程序开发变得更加复杂,许多键值存储系统已经发展到提供SQL,事务等了。
下面展示了通过JavaScript的shell接口(在安装配置了MongoDB的系统通过mongo命令打开)访问MongoDB文档存储,作为访问键值存储系统的API的一个实例。
show dbs // Shows available databases use sampledb // Use database sampledb, creating it if it does not exist db.createCollection("student") // Create a collection db.createCollection("instructor") show collections // Shows all collections in the databasedb.student.insert({ "id" : "00128", "name" : "Zhang",
"dept name" : "Comp. Sci.", "tot cred" : 102, "advisors" : ["45565"] })
db.student.insert({ "id" : "12345", "name" : "Shankar",
"dept name" : "Comp. Sci.", "tot cred" : 32, "advisors" : ["45565"] })
db.student.insert({ "id" : "19991", "name" : "Brandt",
"dept name" : "History", "tot cred" : 80, "advisors" : [] })
db.instructor.insert({ "id" : "45565", "name" : "Katz",
"dept name" : "Comp. Sci.", "salary" : 75000,
"advisees" : ["00128","12345"] })db.student.find() // Fetch all students in JSON format db.student.findOne({"ID": "00128"}) // Find
one matching student
db.student.remove({"dept name": "Comp. Sci."}) // Delete matching students db.student.drop() //
Drops the entire collection
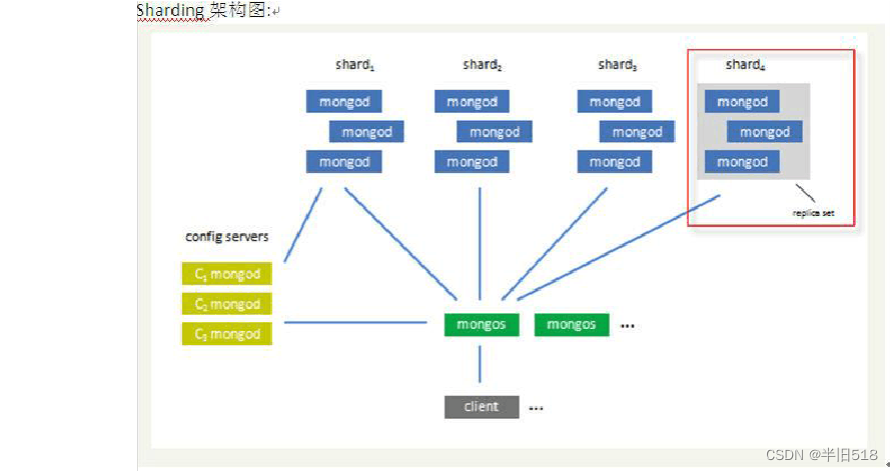
看上去还是蛮简单的。MongoDB的一个关键目标是支持扩展到非常大的数据规模和查询/更新负载,因此它支持并行处理,数据分片等。下图是一个MongoDB的分片集群的配置架构。
Bigtable是另一种键值存储,它要求数据值遵循一定的格式。Bigtable不支持完整的关系数据模型,而是为用户提供了简单的数据模型,使客户可以动态控制数据的分布和格式。
在Bigtable中,数据值(记录)可以有多个属性,属性名集合不是预先确定的,并且可以在不同的记录之间变化。因此,属性值的键在概念上由(记录标识,属性名)组成,
就Bigtable而言,每个属性值只是一个字符串。要获取记录的所有属性,可以使用范围查询,或者更加准确的说,使用仅包含记录标识的前缀匹配查询。为了更高效的检索所有属性,存储系统存储按键排序的条目,因此特定记录的所有属性值都聚集在一起。
据作者说,Bigtable是一个稀疏、分布式、持久化存储的多维有序映射表,其数据模型如下
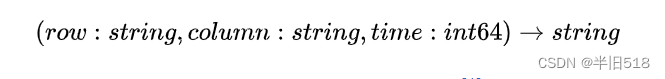
虽然Bigtable本身的记录标识只是一个字符串,但事实上,记录标识本身可以通过映射转变为层次结构的。
比如一个存储通过网络爬虫获得的页面的应用程序可以将如下URL
www.cs.yale.edu/people/silberschatz.html映射为
edu.yale.cs.www/people/silberschatz.html反转的原因是为了让同一个域名下的子域名网页能聚集在一起。
下图是一个典型的Bigtable存储结构。
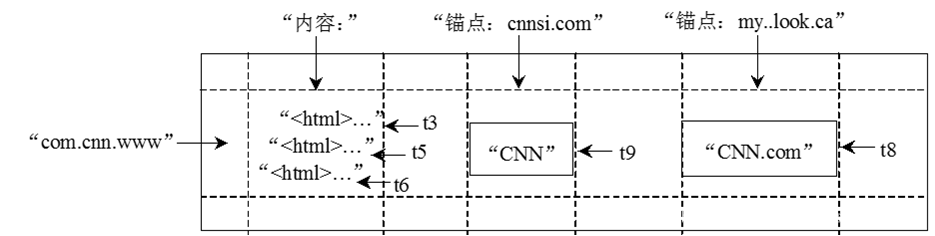
Bigtable不支持Json,但是可以把JSON映射到Bigtable的数据模型上。比如

可以被用标识为"22222"的Bigtable记录来表示,该记录具有多个属性名,如"name.firstname" “children[1].firstname”
此外,单个Bigtable实例可以为多个应用存储数据,每个应用有多个表,只需要简单地将应用名和表名作为记录标识的前缀即可。
许多数据存储系统允许存储数据项的多个版本,版本通常由时间戳来标识,但还可以由整数值来标识。一旦创建数据项的新版本,该整数值就递增。例如,Bigtable中,键实际上由三部分构成(记录标识,属性名,时间戳)。
Bigtable可以从Google上作为服务被访问到,其开源版本被Hbase广泛使用。
关于Bigtable的更多内容,可以参考文章:谷歌技术"三宝"之BigTable
2.4 并行数据库
并行数据库(parrallel database)是指在多台机器(统称为集群)上运行的数据库。它被设计用于跨多台机器存储数据,并使用多台机器处理大型查询。
并行数据库包含多个处理器,以提供数据库上的并行工作。旨在通过并行化各种操作(如加载数据、构建索引和评估查询)来提高性能,并行系统通过并行使用多个 CPU 和磁盘来提高处理和 I/O 速度。
让我们逐步讨论并行数据库的工作原理 -
步骤1− 并行处理将大型任务划分为许多较小的任务,并在多个CPU上同时执行较小的任务,从而更快地完成它。
步骤 2− 并行数据库系统背后的驱动力是必须查询 TB 量级的超大型数据库或每秒必须处理大量事务的应用程序的需求。
步骤3− 在并行处理中,许多操作是同时执行的,而不是串行处理,其中计算步骤是按顺序执行的。
下图展示了并行处理与单cpu处理的效率区别。
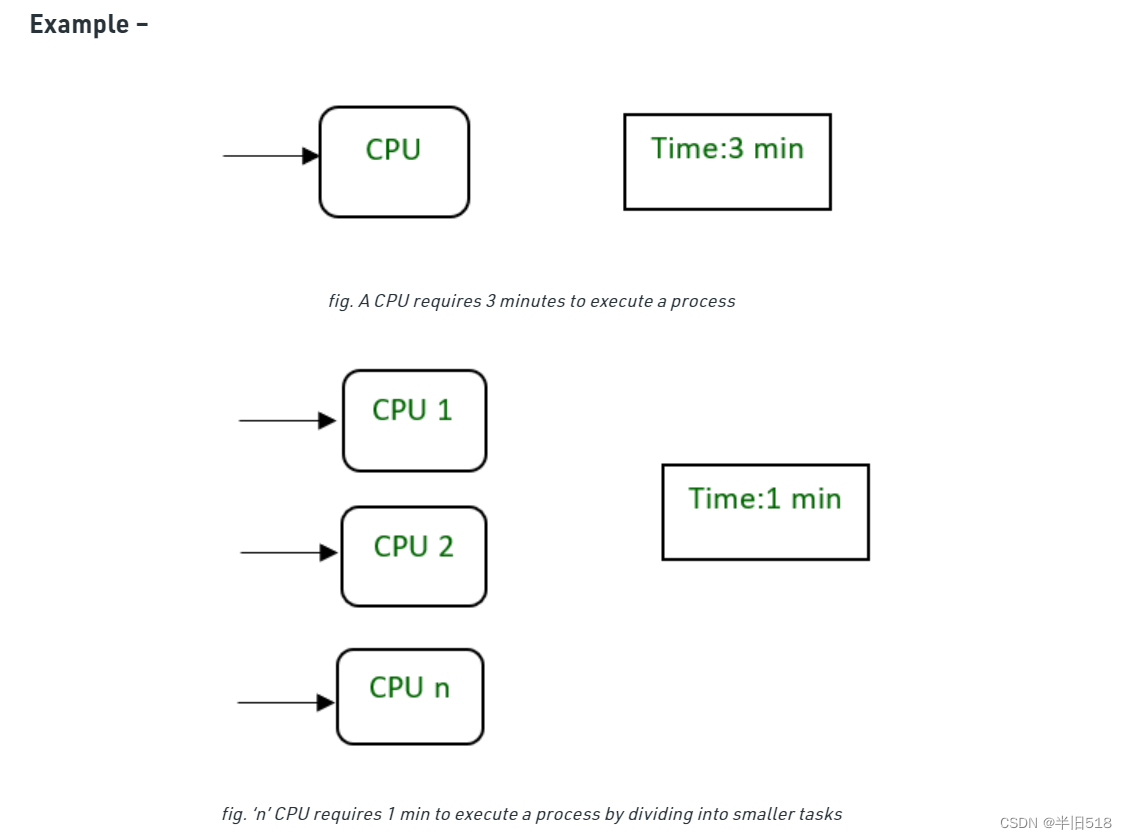
从程序员的角度看,并行数据库可以像在单台机器上运行的数据库一样使用。
并行数据库的一个问题就是系统的容错性较差,过去人们认为节点故障是个特例,并不经常出现,因此系统只提供事务级别的容错功能,如果在查询过程中节点发生故障,那么整个查询都要从头开始重新执行。
这种重启任务的策略使得并行数据库难以在拥有数以千个节点的集群上处理较长的查询,因为在这类集群中节点的故障经常发生。基于这种分析,并行数据库只适合于资源需求相对固定的应用程序。
在发生故障的情况下重新启动查询不再可行,因为在重新执行查询时很可能再次发生故障。后面我们将介绍MapReduce系统中,开发了避免完全重启的技术,只需要对故障机器上得计算进行重做。然而,这些技术带来了巨大的开销。考虑到跨越成千上万个节点的计算只在一些非常大的应用中才需要,即使在今天,大多数并行的关系数据库系统都以运行在数十至数百台机器上得应用为目标,在故障出现时只需要重新启动查询。
2.5 复制和一致性
复制是保证数据可用性的关键。
复制要求对数据项的任何更新都必须应用于数据项的所有副本,只要包含副本的所有机器都已经启动并相互连接,更新很简单。
然而机器故障确实会发生,这里有两个关键问题
- 如何确保在多台计算机上更新数据的事务原子执行,如果尽管发生了故障,但是事务更新过的所有数据项都已成功更新,或者所有数据项都已还原回原始值,就称该事务为原子的。
- 当数据项的某些副本位于发生故障的机器上时,如何对已经被复制的数据项执行更新。这里的一个关键问题是要求一致性。也就是说,一个数据项的所有活跃副本都具有相同的值,并且每次读取都会看到该数据项的最新版本。
后续文章我们将详细探讨解决方案。
分布式系统中,一致性和可用性往往是需要进行权衡的。如果网络故障时,为了保证可用,分区两边的处理可以继续,那就是分区容忍的。(那不就不一致了吗)
可用性: 基本可用是指分布式系统在出现不可预知故障的时候,允许损失部分可用性——但请注意,这绝不等价于系统不可用,以下两个就是“基本可用”的典型例子。 1.响应时间上的损失:正常情况下,一个在线搜索引擎需要0.5秒内返回给用户相应的查询结果,但由于出现异常(比如系统部分机房发生断电或断网故障),查询结果的响应时间增加到了1~2秒。 2.功能上的损失:正常情况下,在一个电子商务网站上进行购物,消费者几乎能够顺利地完成每一笔订单,但是在一些节日大促购物高峰的时候,由于消费者的购物行为激增,为了保护购物系统的稳定性,部分消费者可能会被引导到一个降级页面。 弱状态也称为软状态,和硬状态相对,是指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据听不的过程存在延时。
3.MapReduce范式
熟悉函数式编程的宝子们应该熟悉MapReduce的思想,MapReduce范式对并行处理中的一种常见情况进行了建模,它应用map()函数和reduce()函数为并行提供支持。
3.1 为什么要使用MapReduce
考虑一个场景,编写一个程序统计文件中出现的单词及其频次。如果文件和单词的数量不多,问题还不算复杂,如果将上述问题扩展到一个拥有数万个文件的环境中,每个文件都包含数十至数百兆的数据,按顺序处理如此大量的数据是不可行的。你可以自己编写并行程序来扩展上述方案,最后整合每台机器的计算结果进行本地计数,不过你需要考虑好怎么利用“管道系统”来协调作业,处理故障。
不过,你的程序可能还不能够复用。费那劲造轮子干嘛。MapReduce来救你了。
3.2 MapReduce是什么?
MapReduce是一种分布式计算框架 ,以一种可靠的,具有容错能力的方式并行地处理上TB级别的海量数据集。主要用于搜索领域,解决海量数据的计算问题。
看看MapReduce做什么? Map()负责把一个大的block块进行切片并计算。 Reduce() 负责把Map()切片的数据进行汇总、计算。
3.3 MapReduce示例:词汇统计
现在使用MapReduce基于伪代码来实现词汇统计,并通过这个例子进一步理解Map()和Reduce()函数。

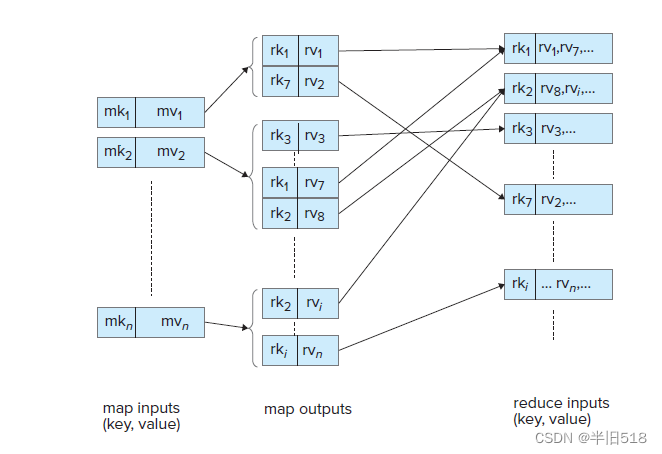
上面的map()函数会记录所有出现的词汇,将其计数设置为1,输出(word,count)对传递给reduce函数,而reduce函数则对数据重新进行分组或者排序,以便将具有特定键的所有记录收集到一起。最后通过增加计数整合词汇计数列表。
其详细过程可以参考下图(Mapreduce作业中的键值流),其中m表示map,r表示reduce,k表示key,v表示value.
3.4 MapReduce任务的并行处理
上面的例子其实并没有关注并行处理的问题,下面我们分析下它的并行处理时会做什么?
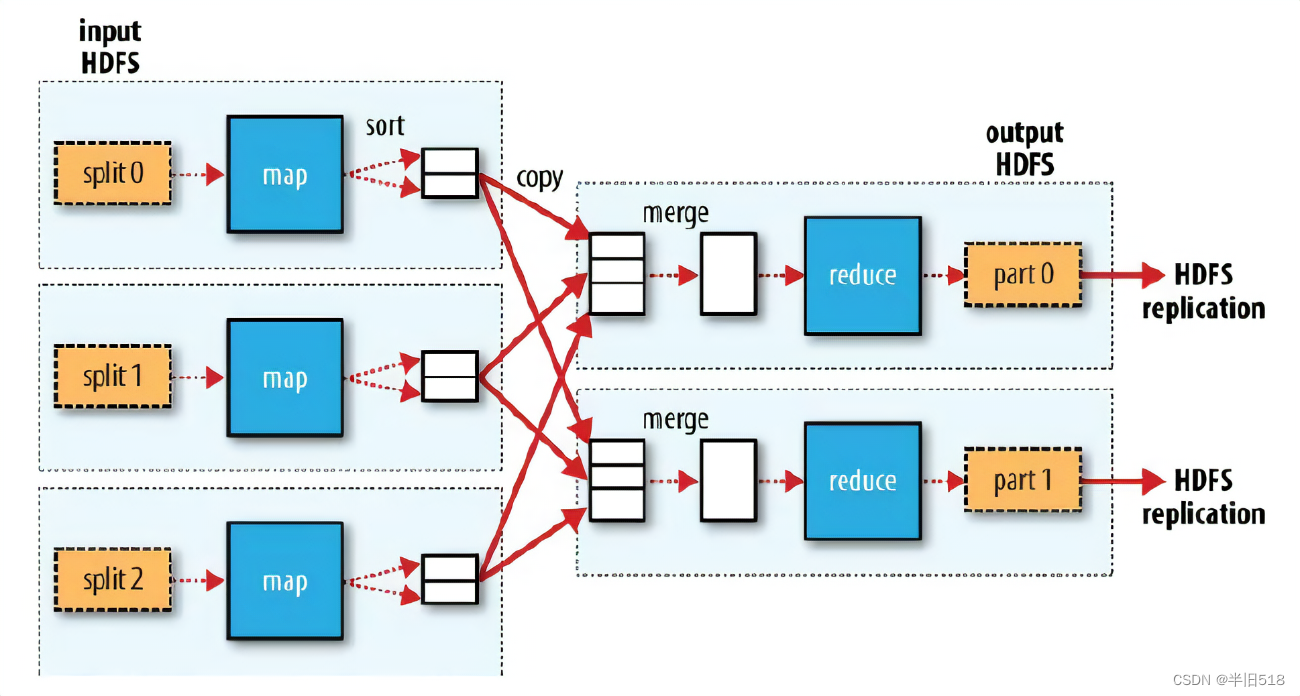
- 1.第一步对输入的数据进行切片,每个切片分配一个map()任务,map()对其中的数据进行计算,对每个数据用键值对的形式记录,然后输出到环形缓冲区(图中sort的位置)。
- 2.map()中输出的数据在环形缓冲区内进行快排,每个环形缓冲区默认大小100M,当数据达到80M时(默认),把数据输出到磁盘上。形成很多个内部有序整体无序的小文件。
- 3.框架把磁盘中的小文件传到Reduce()中来,然后进行归并排序,最终输出。
可以看到,MapReduce系统在多台机器上并行执行map()函数,每个map任务处理部分数据,reduce()函数也在多台机器上并行执行,每个reduce任务处理reduce键的一个子集(注意,对reduce函数的特定调用仍然是针对单个reduce键的)
值得关注的是,文件的输入输出会借助Hadoop分布式文件系统(HDFS)实现输入输出的并行化。除了HDFS,MapReduce还可以支持适配各种大数据存储系统,如HBASE,MongoDB,Amazon Dynamo。当然,生产中也会应用复制技术 ,通常是三台,来保证即使一些机器发生故障,也可以从存有故障机器数据副本的其他机器获得数据。
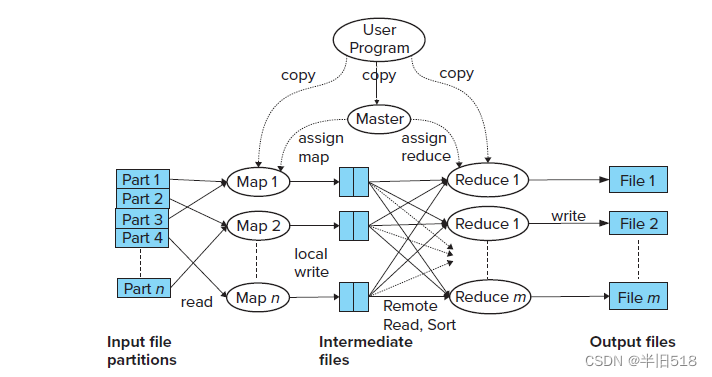
下图展示了并行处理的更多细节,供参考。
3.5 Hadoop中的MapReduce
Hadoop是一个开源的大数据框架,是一个分布式计算的解决方案。Hadoop的两个核心解决了数据存储问题(HDFS分布式文件系统)和分布式计算问题(MapRe-duce)。

Hadoop项目提供了用Java语言编写的、广泛使用的MapReduce开源实现。我们使用Java API来概述它的主要特性。它也提供了Python和C++语言实现的MapReduce API。
java通过继承Mapper和Reducer类,就可以重写map()和reduce()方法。除了reduce()方法,Hadoop还允许程序员定义combine()方法,它可以在执行map()方法的节点上执行部分reduce操作。使用combine的一个好处是他减少了必须通过网络发生的数据量:运行map任务的每个节点在网络上为每个词汇只发送一个条目,而不是多个条目。
Hadoop中的单个M apReduce步骤执行一个map方法和一个reduce方法,一个程序可以有多个MapReduce步骤。每个步骤的reduce()输出被写入(分布式)文件系统,并在后面的步骤中被读出。Hadoop还允许程序员控制为一项作业并行运行的map和reduce任务的数量。
下面显示了前面词汇统计的Hadoop的java实现。
public class WordCount {public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> { // 每个词的初始频次设置为1 private final static IntWritable one = new IntWritable(1); // 定义输出参数:Text,文本类型 private Text word = new Text(); // 重写map方法 // key,输入键:LongWritable,长整型 // value,输入值:Text,文本 public void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException { String line = value.toString(); // StringTokenizer,将文本分解为词 StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); // 将单词-频次的键值对写入context,one表示频次为1 context.write(word, one); } } } public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> { // 重写reduce方法 // key,输入键:Text,词,values,一个频次的列表 public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; // 将频次的列表累加 for (IntWritable val : values) { sum += val.get(); } context.write(key, new IntWritable(sum)); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = new Job(conf, "wordcount"); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setMapperClass(Map.class); job.setReducerClass(Reduce.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true); }
}
3.6 MapReduce上的SQL
MapReduce的许多应用都是为了使用不容易用SQL表示的计算来并行处理大量的非关系数据库。比如,计算“倒排索引”(这是网络搜索引擎高效回答关键字查询的关键)和计算Google的PageRank。
关系运算可以使用map和reduce步骤来实现,不过这对于程序员来说非常麻烦,使用SQL会更加简洁。不过为了提高效率,新一代的系统已经被开发出来了,允许使用SQL语言(或变体)编写的查询在存储在文件系统中的数据上并行执行。比如Apache Hive和由Microsoft开发的Scope,以及Apache Pig。使用这些系统在MapReduce框架(如Hadoop)上编写查询比直接使用MapReduce范式编写的查询要多得多。
下图是企业中一种常见的大数据分析平台部署框架,Hive和Pig用于报表中心,Hive用于分析报表,Pig用于报表中数据的转换工作。
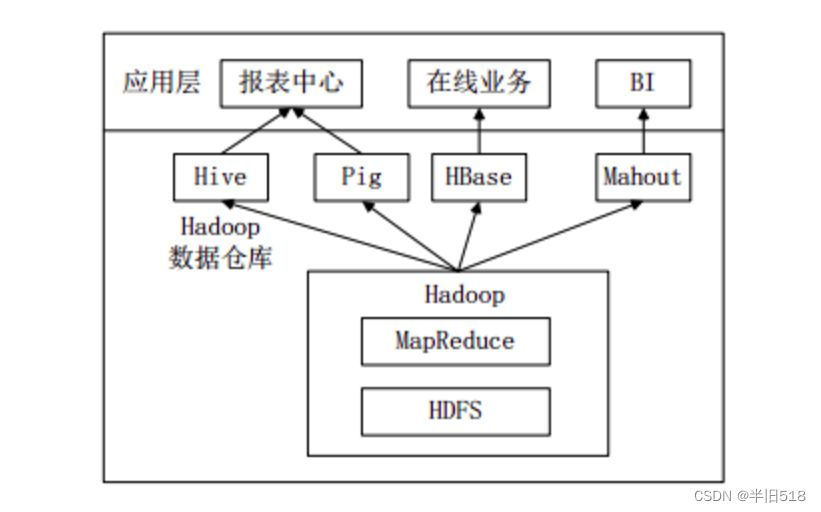
什么是hive hive是一个构建在Hadoop上的数据仓库工具(框架)。 可以将结构化的数据文件映射成一张数据表,并可以使用类sql的方式来对这样的数据文件进行读,写以及管理(包括元数据)。 这套HIVE SQL 简称HQL。hive的执行引擎可以是MR、spark、tez。
4.超越MapReduce——代数运算
4.1 代数运算的动机
关系运算可以通过map和reduce步骤的序列来表示,但这样的方式来表示任务可能会相当麻烦。
例如,如果程序员需要计算两个输入的连接,他们应该能够将其表示为单个代数运算,而不必通过map和reduce函数间接的表示出来。访问诸如joins之类的函数可以大大简化程序员的工作。这比直接使用map和reduce更有效,即使是在程序员不必直接编写MapReduce代码的数据仓库(如hive)中,也会更好。
因此,新一代并行数据处理系统增加了对其他关系运算(如joins)的支持,并支持数据分析的各种其他运算。例如,机器模型可以被建模为运算符,这些运算符以训练记录集合作为输入并输出学习模型。数据处理通常设计多个步骤,这些步骤可以建模为序列(流水线)或运算符树。
这些运算的一种统一框架是将它们视为代数运算(algebraic operation),将一个或多个数据集作为输入并输出一个或多个数据集。关系运算的输入必须是原子类型数据,代数运算的输入则支持更复杂的表达式。
有许多框架支持复杂数据上的代数运算,目前最广泛的是Apache Tez和Apache Spark。Tez提供了系统实现者的低级别的API,并非是为了程序员直接使用设计,不展开。
4.2 Spark中的代数运算
Apache Spark是一个广泛使用的并行数据处理系统,支持各种代数运算。数据可以从各种存储系统输入或输出至这些存储系统。
关系数据库使用关系作为数据表示的主要抽象,Spark使用一种称为弹性分布式数据集(Resilient Distributed Dataset,RDD)的表示,它是可以跨多台机器存储的记录的集合。属于分布式distributed 是只存储在不同机器上的记录,而弹性Resilient 是指故障恢复能力:即使其中一台机器发生故障,也可以从存储记录的其他机器中检索出数据。
对开发者而言,RDD可以看作是Spark的一个对象,它本身运行于内存中,如读文件是一个RDD,对文件计算是一个RDD,结果集也是一个RDD ,不同的分片、 数据之间的依赖 、key-value类型的map数据都可以看做RDD。
Spark中的运算符接受一个或者多个RDD作为输入,其输出是一个RDD。存储在RDD中的记录类型不是预先定义的,可以是应用想要的任何类型。Spark还支持被称作DataSet的关系数据表示。
Spark为Java,Scala和Python提供了API,我们对Spark的介绍是基于Java API的。
下面展示使用Spark在Java中编写词汇统计应用,该程序使用RDD数据表示形式,被称为JavaRDD,它用一个尖括号<>指定记录类型。另外JavaPairRDD用于支持结构化数据类型。尽管可以使用任意用户自定义的数据类型,但预定义的数据类型仍然被广泛使用。预定义的数据类型有Tuple2(存储2个属性),Tuple3(存储3个属性),Tuple4(存储4个属性)

下面图片很好的解释了上面程序的内容。

使用spark处理数据的第一步是将数据从输入表示形式转换为RDD的表现形式,这是由spark.read.textfile()函数完成的,它的输入中的每一行创建一个记录。请注意,输入可以是一个文件或者具有多个文件的目录,在多个节点上运行的spark系统实际上会跨多台机器划分RDD。
仅看代码,用户根本体会不到数据在背后是并行计算。从图中能看出数据分布在不同分区(也可以理解不同机器上),数据经过flapMap、map和reduceByKey算子在不同RDD的分区中流转。(这些算子就是上面所说对RDD进行计算的函数)
理解如何实现并行处理的关键是弄明白以下内容:
- RDD可以划分并存储在多台机器上;
- 每种运算可以在多台机器上、在机器上可用的RDD划分上并行执行。可以首先对运算的输入进行重新划分,以便在并行执行操作之前将相关记录放到同一台机器上。例如,
reduceByKey将重新划分输入的RDD,使属于同一组的所有记录集中在但台机器上,不同组的记录可能再不同的机器上。
Spark的另一个重要特性是代数运算不需要在函数调用是立刻计算,尽管代码看上去似乎是这么做的。相反,上面展示的代码实际上创建了一颗运算树。这些运算不会一经定义就立刻执行,而是在后面savaASTextFile()执行时强制要求对树进行运算。其他函数比如collect()也有类似的作用,熟悉函数式编程的朋友应该不难理解这一点。
延迟计算(lazy evaluation)的优点是可以在计算时重写树,使得结果更快。
如果一种运算的结果作为不止其他一种运算的输入,这些操作可以形成一个有向无环图(Directed Asyclic Graph,DAG)
RDD很适合应用于诸如文本数据那样的特定数据类型,Spark支持的另一种DataSet类型则支持处理结构化数据。DataSet类型与广泛使用的Requet,ORC和Avro文件格式能够很好的契合。
下面代码说明Spark如何读取和处理Requet格式的数据。


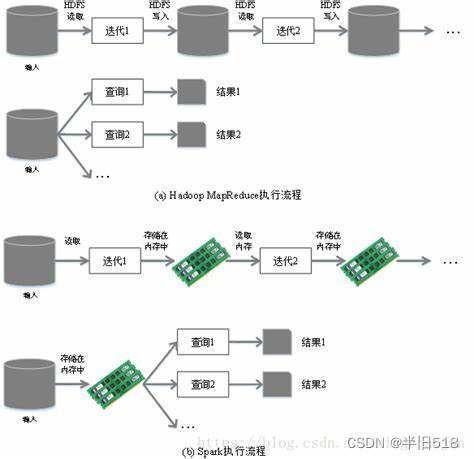
HDFS,Hadoop,Hive和Spark 1.HDFS扮演者数据统一管理的角色,会统一管理100台服务器上的存储空间 2.HDFS中引入了一个MapReduce模块,MapReduce模块实际上是提供了一个任务并行的框架 3.Hadoop中采用HDFS来处理存储,MapRecude来处理计算。 4. 为了能够在大数据上使用SQL来处理数据,Hive应用而生。Hive实际上是在Hadoop上进行结构化数据处理的一个解决方案,目的是能让用户通过编写SQL来处理数据。 5.spark经常用来和Hadoop进行对比,更为精确的说是和Hadoop里面的MapReduce对比,因为Spark本身也是一个计算框架。Spark和MapReduce不同主要是Spak是基于内存的计算,而MapRecude是基于磁盘的计算,所以Spark的卖点就是快
5.流数据
5.1 流数据的应用
许多应用程序中需要在连续到达的数据上持续的执行查询,术语流数据是指以连续方式到达的数据。

常见的流数据有:股票市场的交易,电子商务中的购买行为,传感器的实施监测数据,网络的实时数据,社交媒体(诸如Twitter需要从用户哪里获得连续的消息流)
5.2 流数据查询
与流数据相反,存储在数据库中的数据有时被称为静态数据(data-at-rest),与存储的数据相比,流是无限的,也就是说,从概念上将流永远不会结束。只有在看到流的所有元组之后才能输出结果的查询永远无法输出任何结果。例如,询问流中元组个数的查询永远不会给出最终的结果。
处理流的无限特性的一种方式是在流上定义窗口(window),流上的每个窗口包含具有特定时间戳范围或特定数量的元组。查询可以针对一个或多个窗口,而不是整个流。
另一种选择是输出流中某个特定点的正确结果,但随着更多元组的到达输出会更新,比如计数查询。
基于上面两种选择,有好几种查询数据的方法。
- 连续查询。即实时对数据库执行插入、更新或删除,可使用SQL,这对用户希望看到所有插入的应用有优势,但如果输入率过高,使用者将会被这种大量更新所淹没。
- 流式查询语言。通过扩展SQL或者关系代数来定义查询语言。这些语言在语言层将流数据与存储的关系分开,并要求在执行关系运算之前应用窗口操作。有些流不能保证元组具有递增的时间戳,这样的流将包含标点(punctuation),标点定时发出来决定聚集结果何时完成。
- 流上的代数运算符。编写对输入元组执行的运算符(用户自定义函数)。元组由输入路由到运算符,运算符的每个输出可以路由到另外一个运算符,系统输出或存储在数据库中。运算符可以跨被处理的元组来维护内部状态,从而允许它们对输入数据进行聚集。它们还可以用来在数据库中持久的存储数据。这种方式得到广泛应用。
- 模式匹配。编写模式,匹配时执行动作,这种系统被称为复杂时间处理系统(Complex Event Processing,CEP)。流行的CEP有Oracle Event processing,FlinkCEP等
许多流系统将数据存在内存中,并不提供持久性保证。许多应用采用Lambada architecture,其中输入数据的一个副本被提供给流处理系统,另一个副本则保存在数据库中存储和后续处理。
然而,流媒体系统和数据库系统是分离的,从而导致以下问题。
- 查询可能需要用不同的语言编写两次,一次用于流处理系统,一次用于数据库系统。
- 流式查询可能无法有效地访问存储的数据。
支持带持久性存储的流式查询和跨流和存储数据的查询系统可以避免这些问题。
5.3 流上的代数运算
虽然对流式数据的SQL查询非常有用,但在许多应用中SQL查询并不是很适合,通过流处理的代数运算方法,可以为实现代数运算提供用户自定义的代码。
要执行运算,就必须把输入元组路由给运算符,运算符必须路由给使用者,这种容错的元组路由可以由Apache Storm和Kafka等实现。
元组路由在逻辑上是通过构建一个以操作符为节点的有向无环图来实现的。流处理系统的入口是数据源,从数据源作为入口把元组注入流处理系统。流处理系统的出口是数据接收节点,通过数据接收退出的元组可以存储在文件中或者以别的方式输出。图中间的节点是运算符,边则是元组流。
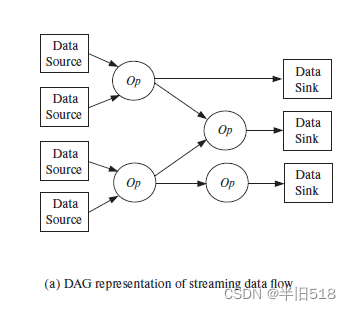
实现流处理的一种思路就是把图指定为系统配置的一部分,当系统开始处理元组时读取该图,Storm就是这么处理的。
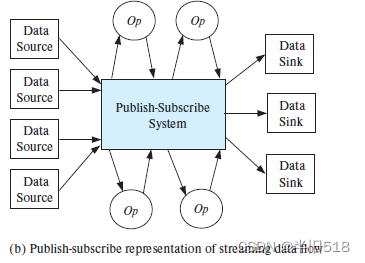
另外一种方式是发布-订阅系统(publish-subcribe,也称为pub-sub系统),订阅者订阅特定的主题,发布者以文档或其他形式发布带有关联主题的数据,所有主题订阅者都会收到对应的副本。这种方式可以动态的增删运算符,较为灵活,kafka 采用的就是这种模式。
接下来讨论如何将流数据源作为此类运算的输入。因为流数据是源源不断的,可能会有无限的输入,为了解决这个问题,Spark允许将流数据分解为离散化流,其中特定时间窗口的流数据被视为代数运算的输入,就像处理文件或者关系那样进行处理。
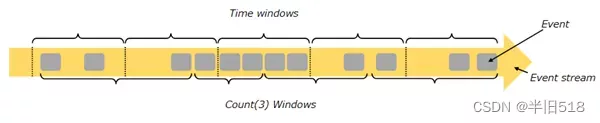
但这样需要提前对流数据进行离散化。诸如Storm和Flink支持流式运算,它们将流作为输入并输出另一个流。这对于诸如映射或者选择关系那样的运算很简单,每个输出元组从输入元组继承一个时间戳。在整个流被处理完之前,关系聚集运算和reduce操作可能无法产生任何技术处。为了支持这些操作,Flink支持一种将流分解为窗口的窗口操作,聚集在每个窗口内计算并在窗口完成后输出。需要注意的是输出被视为流,其中元组时具有基于窗口结束点的时间戳。
下图是flink使用时间窗口的窗口划分示意。
关于Flink,您可以参考博客,全面解析流处理框架Flink
6.图数据库
对于道路网络等图类型的数据,可以采用图数据库存储。
图数据库提供了许多额外的特性。
- 允许将关系标识为节点或边,提供定义这种关系的特殊语法
- 允许设计可以轻松表示路径查询的查询语言
- 为此类查询提供高效实现
- 为图可视化等其他特性提供支持
Neo4j是广泛使用的图数据库,它是一种集中式数据库(截止至2018年)。因此,Neo4j并不支持处理非常大的图,诸如社交网络就是这种非常庞大的图的实例。
有两种常用的并行图处理方法用于处理复杂大图。
- map-reduce和代数框架,图可以作为关系存储在并行存储系统中,跨多台机器进行划分,使用map-reduce程序,代数框架或并行关系数据库来实现跨多个节点并行处理。这种方法在许多应用中很有效,但当执行遍历图中长路径的迭代计算时,这些方法非常低效,因为他们通常每次迭代都要去读取整张图。
- 批量同步处理框架。用于图算法的批量同步处理(Bulk Synchronous Processing,BSP)框架将图算法制定以迭代方式操作的顶点相关联的计算。这里的图通常存储在内存中,顶点是跨多台机器进行划分的,最重要的是,不必在每次迭代中读取图。
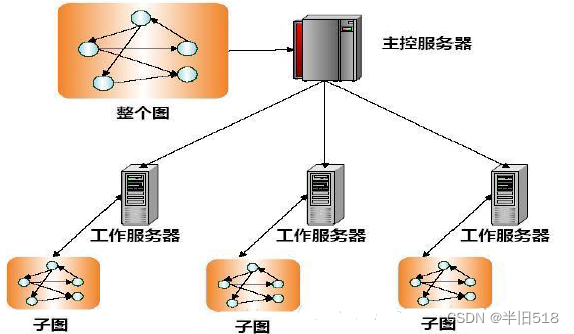
BSP已经被Pregel系统所普及,Giraph系统是基于Pregel的开源版本。Apache GraphX支持大图上的图计算。
博客:Pregel(图计算)技术原理 ,提供了更多图计算的介绍。