前言
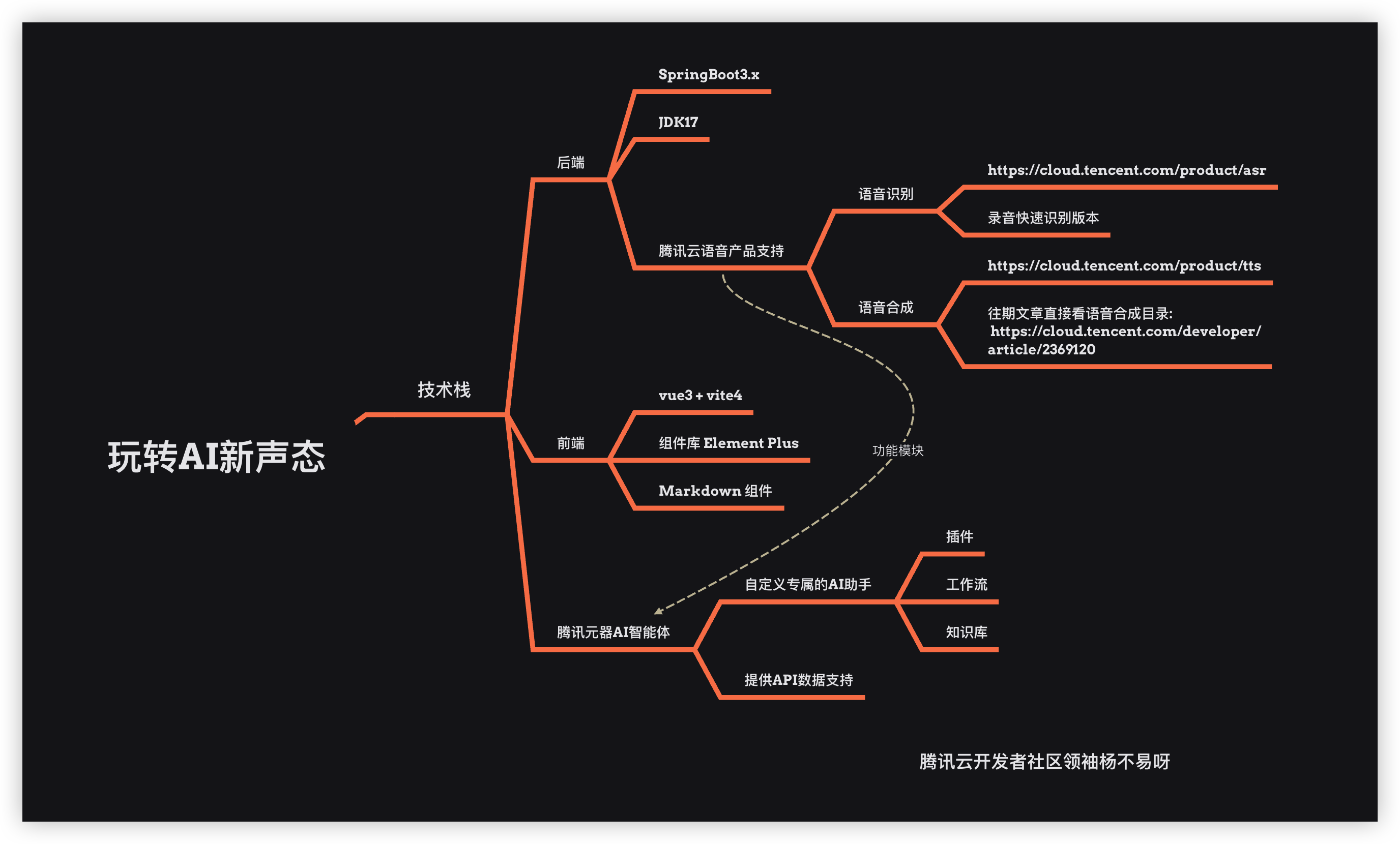
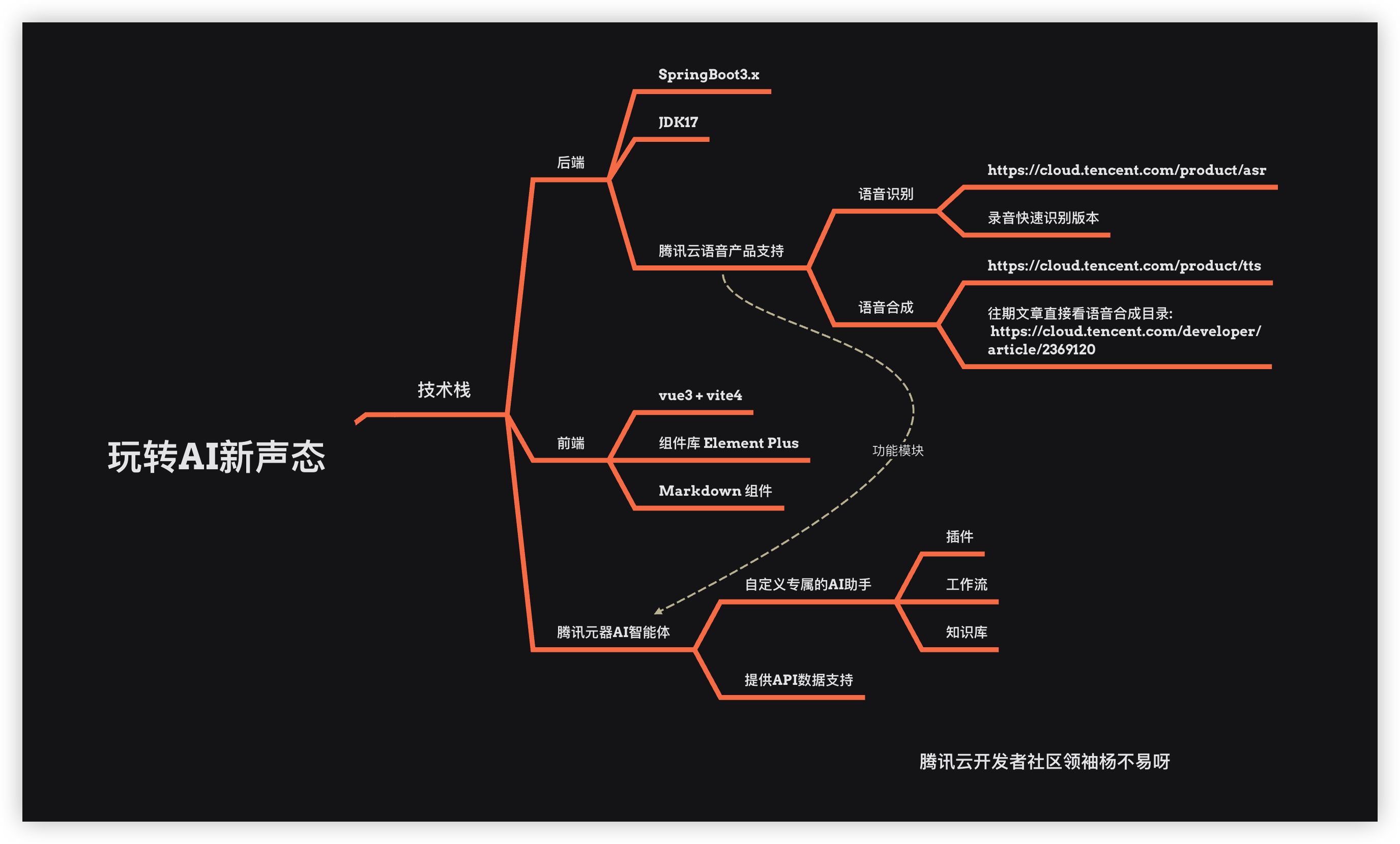
本次带来的是腾讯云玩转AI新声态语音产品应用实践,利用 TTS / ASR / 元器智能体 打造一个《小朋友的故事屋》智能体 Bot 最近腾讯发布了元宝,那么我们就做一个专属讲故事的童话匠该 bot 可以实现语音和智能体交流达到和小朋友互动,在此之前我先介绍一下什么是 TTS、ASR 以及元器智能体(简单略过详细学习前往: 《继ChatGPT的热潮AI的新产物-智能体元器Agent平台》
💰 本篇文章从学习 TTS/ASR 到项目实战系列结合腾讯云语音产品和 AI 智能体花费了一星期的时间设计加开发,我相信喜欢捣鼓的同学肯定会非常喜欢这篇文章从介绍 TTS / ASR / YuanQi Agent API 一套完整的体系搭建前端、后端以及智能体,文章当中包揽了前端知识、后端知识、以及 AI Agent 知识点 那么来玩转AI新声态吧! 主要技术框架: Java / Vue3 智能体 Agent: 元器智能体 API ⚠️ 本文章需要一定开发基础的同学,后面的项目实战我不会说的非常详细,重点在于巩固学习到的知识点! 已上线部署: https://yby6.com/agentai/
TTS 语音合成
TTS 的全英文 Text To Speech 表示文本转语音的功能, 腾讯云语音合成满足将文本转化成拟人化语音的需求,打通人机交互闭环。提供多场景、多语言的音色选择,支持 SSML 标记语言,支持自定义音量、语速等参数,让发音更专业、更符合场景需求。语音合成广泛适用于智能客服、有声阅读、新闻播报、人机交互等业务场景。
在产品页面可以进行试用产品: 语音合成TTS
TTS 产品特性
- 高拟真度
- 腾讯云基于业界领先技术构建的语音合成系统,具备合成速度快、合成语音自然流畅等特点,合成语音拟真度高,能够符合多样的应用场景,让设备和应用轻松发声,人机语音交互效果更加逼真。
- 灵活设置
- 腾讯云语音合成支持中文、英文、粤语、四川话,也可以合成中英混读语音;支持根据业务需求选择合适的音量、语速等属性;支持离线音频文件和实时音频流两种合成格式;支持电话、移动 App 等多种场景和合成效果选择。
- 声音多样
- 腾讯云语音合成支持多种男声、女声的选择,使得音色能够覆盖多样化的应用场景,适用于电话客服,小说朗读,消息播报等场景。此外,腾讯云支持为企业客户定制发声人。
- 免费体验新用户可以领取 800 万的语音合成资源用到爽

ASR 语音识别
ASR 的全英文 Automatic Speech Recognition,ASR 表示文本转语音的功能, 腾讯云语音识别是将语音转化成文字的PaaS产品,为企业提供精准而极具性价比的识别服务。被微信、王者荣耀、腾讯视频等大量业务使用,适用于录音质检、会议实时转写、语音输入法等多个场景。
腾讯云在语音识别领域拥有多个子产品功能: 录音文件识别、录音极速版本识别、实时语音识别、一句话识别、语音异步识别 每个识别用于不同的场景,根据您的业务来使用对应的识别将会事半功倍!

ASR 产品优势
- 技术先进
- 语音识别引擎采用自主研发的Transformer技术,具备较好的鲁棒性。支持声音和文本层面的自适应能力和语言混合识别能力。中文普通话、英文、普粤英引擎的识别字准率均能满足广泛的商用场景。
- 多语种、多方言
- 目前支持中文普通话、英语、日语、韩语、泰语、马来语等13个语种,支持粤语、上海话、四川话等24种方言,并将持续开放其他语种和方言的识别能力。支持通过单一引擎识别普通话、粤语、英语三个语种。
- 性价比高
- 腾讯云提供预付费、后付费等多种灵活计费模式,在预付费包提供了较大优惠,识别1小时语音不到1元。每月赠送免费额度,最大程度降低客户成本。
前往语音识别产品页面可以体验试用产品 语音识别实时语音识别录音文件识别_语音转文本服务 - 腾讯云
支持小程序体验和 PC 端体验 实时识别和音频文件识别
资源包推荐
觉得还不错趁现在 618 入手更加划算便宜【腾讯云】云服务器、云数据库、COS、CDN、短信等云产品特惠热卖中
语音识别和语音合成需求量大的非常建议速度入手单买还是很不划算的
接入 TTS 语音合成
在上面我们已经介绍了 TTS / ASR 是什么东西有什么用,接下来我们将接入 TTS / ASR 到程序当中使用同学们准备飙车啦!
开通 ASR
前往前往腾讯云语音合成服务 语音合成

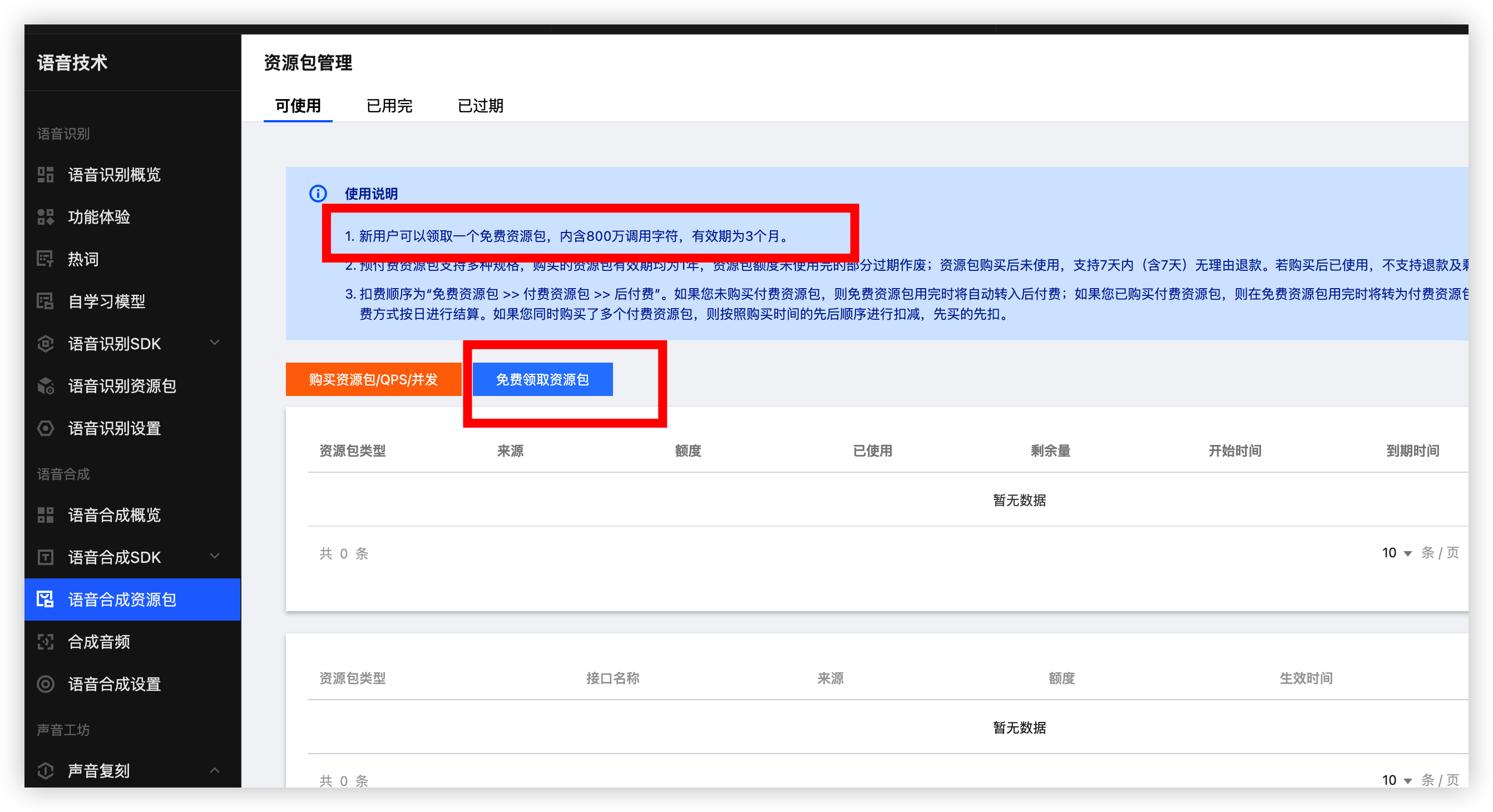
点击资源包 新用户可以领取一个免费资源包内含800万调用字符用到爽但是不含长文本的(600 字符)也够我们的需求了
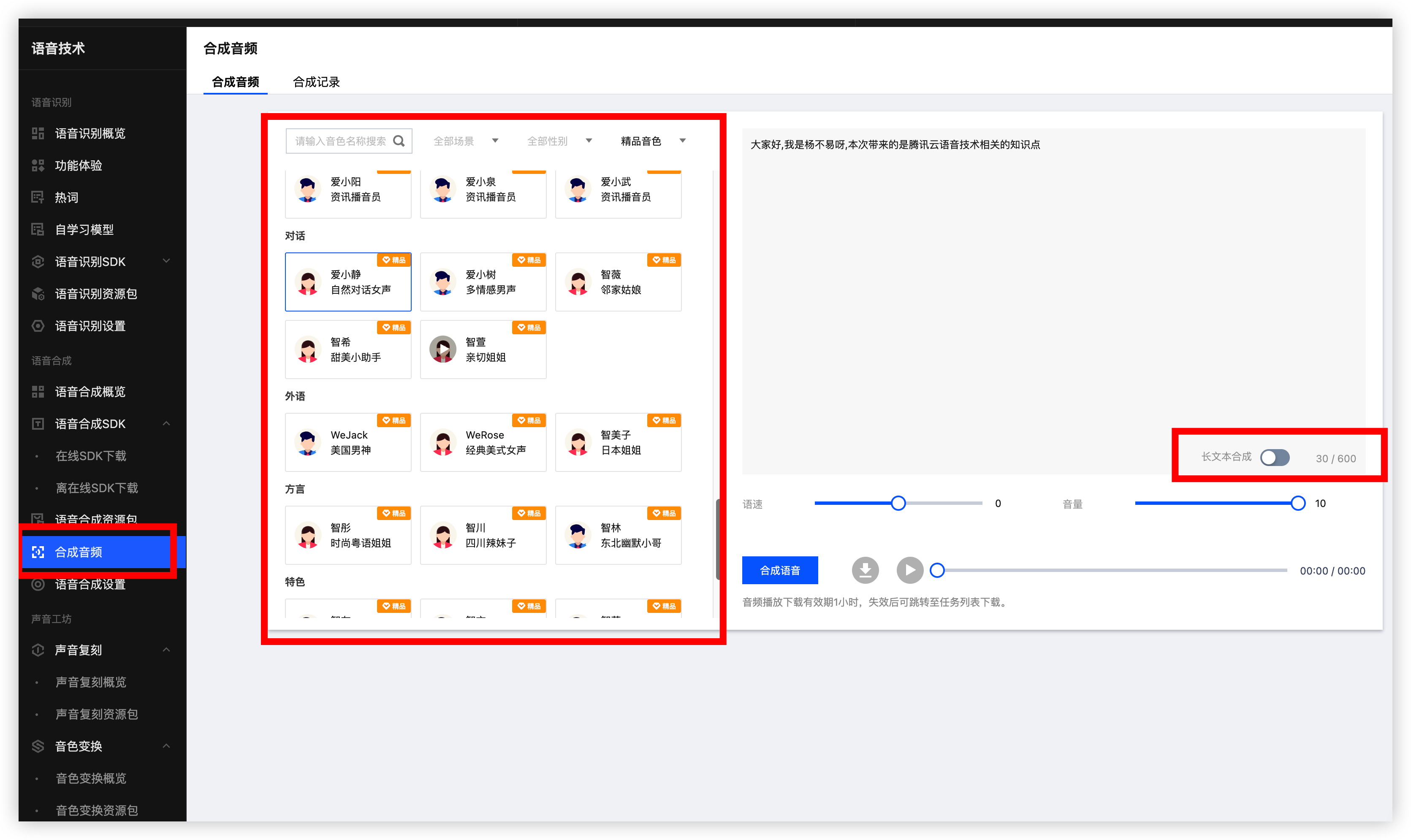
接着我们点击合成音频来试试看效果, 看你的感觉选择任意一个音频音色然后输入你想要合成的音频文本, 点击合成语音即可
合成中, 如果合成成功则旁边的两个按钮都将可点击,一个是下载音频 一个是播放
📎爱小静-合成音频.wav
如果想听上一段音频可在合成记录查看并且下载等操作
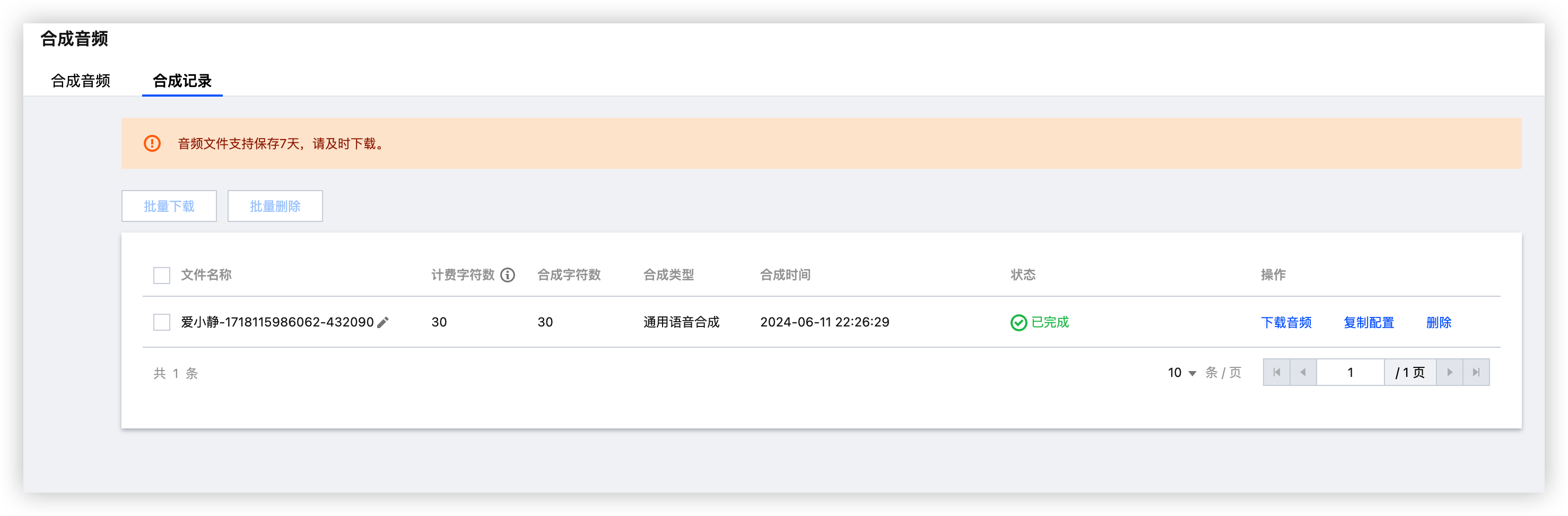
消耗的字符都在免费的资源包当中

TTS 文档
点击右下角图标在选择语音合成
接口描述
如果你不使用官方提供的 SDK 进行接入那么就需要单独操作这个请求接口了
接口请求域名: tts.tencentcloudapi.com
腾讯云语音合成技术(TTS)可以将任意文本转化为语音,实现让机器和应用张口说话。
腾讯TTS技术可以应用到很多场景,比如,移动APP语音播报新闻;智能设备语音提醒;依靠网上现有节目或少量录音,快速合成明星语音,降低邀约成本;支持车载导航语音合成的个性化语音播报。
接口请求要求
实际上也就两个必填 Text、SessionId 以下是我觉得符合我的业务的必要参数
具体的参数前往文档查看
参数名称 | 必选 | 类型 | 描述 |
|---|---|---|---|
Text | 是 | String | 合成语音的源文本,按UTF-8编码统一计算。中文最大支持150个汉字(全角标点符号算一个汉字);英文最大支持500个字母(半角标点符号算一个字母)。示例值:你好 |
SessionId | 是 | String | 一次请求对应一个SessionId,会原样返回,建议传入类似于uuid的字符串防止重复。示例值:session-1234 |
VoiceType | 否 | Integer | 音色 ID,包括标准音色与精品音色,精品音色拟真度更高,价格不同于标准音色,请参见购买指南 完整的音色 ID 列表请参见音色列表 示例值:0 |
PrimaryLanguage | 否 | Integer | 主语言类型:- 1-中文(默认)- 2-英文 - 3-日文 示例值:1 |
Codec | 否 | String | 返回音频格式,可取值:wav(默认),mp3,pcm 示例值:wav |
EmotionCategory | 否 | String | 控制合成音频的情感,仅支持多情感音色使用。取值: neutral(中性)、sad(悲伤)、happy(高兴)、angry(生气)、fear(恐惧)、news(新闻)、story(故事)、radio(广播)、poetry(诗歌)、call(客服)、撒娇(sajiao)、厌恶(disgusted)、震惊(amaze)、平静(peaceful)、兴奋(exciting)、傲娇(aojiao)、解说(jieshuo) |
输出参数
参数名称 | 类型 | 描述 |
|---|---|---|
Audio | String | base64编码的wav/mp3音频数据示例值:UklGRlRAABXQVZFZm10IBAAAAABAAEAgD4AAAB9AAACABAAZGF0YSx9AAD+ |
SessionId | String | 一次请求对应一个SessionId 示例值:session-1234 |
Subtitles | Array of Subtitle | 时间戳信息,若未开启时间戳,则返回空数组。 |
RequestId | String | 唯一请求 ID,每次请求都会返回。定位问题时需要提供该次请求的 RequestId。 |
简单认识一些请求参数和返回参数, 那么接下来我们就接入到自己的程序当中, 腾讯云有一个叫 API Explorer 这个是专门调试腾讯云各种产品的平台搭配 SDK 解放双手,可以说是一秒就可以集成到系统中, 大白话 你会 CV 吧?

API 调试
点击我前往 API Explorer 调试平台, 选择基础语音合成 长文本我们可没有免费资源包
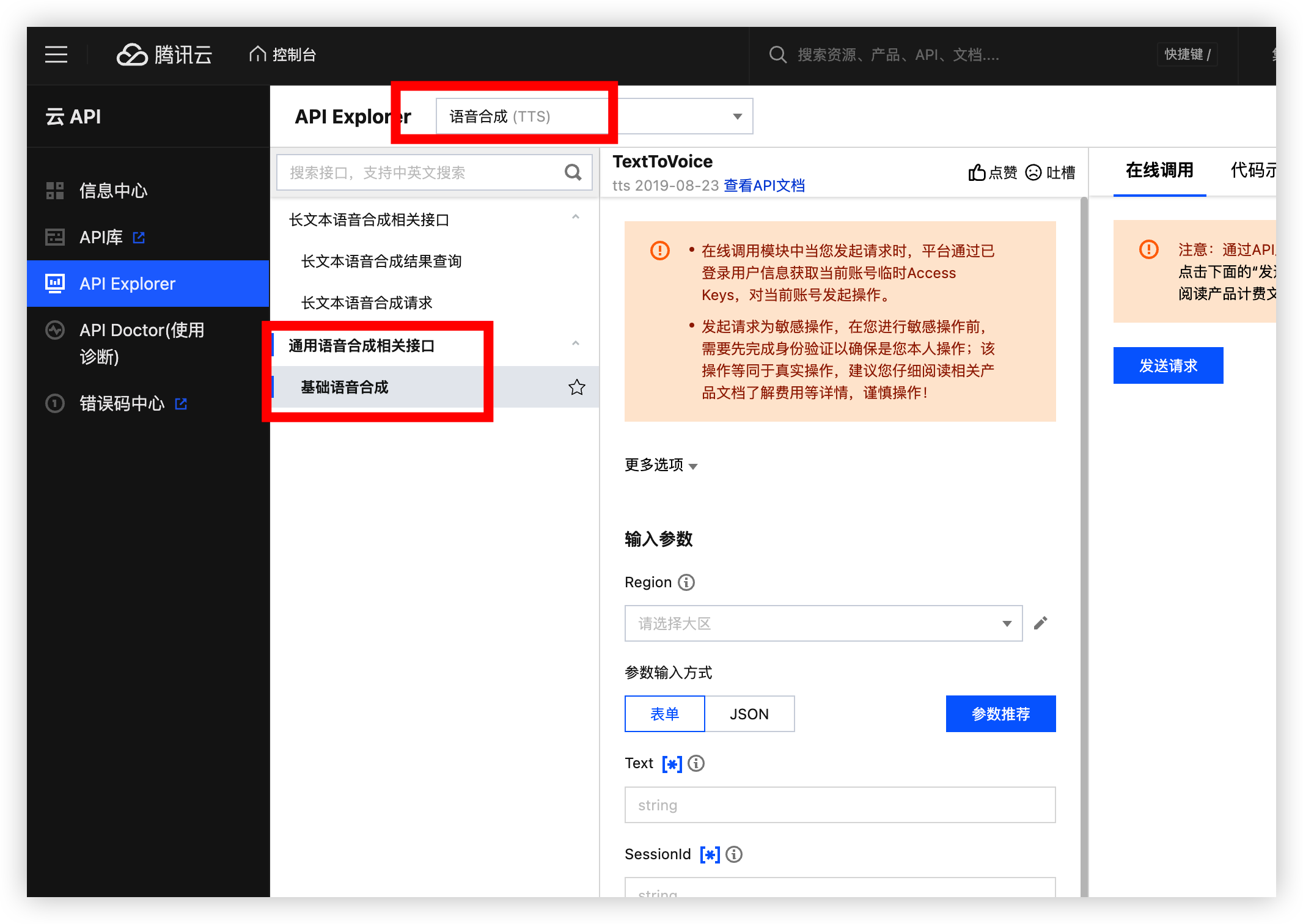
在前面我们说到这六个我就给这六个参数设置参数其它的你们自己看看需要什么搞什么
Text | 描述 |
|---|---|
SessionId | 唯一ID |
VoiceType | 音频音色 |
PrimaryLanguage | 合成语音语言种类 |
Codec | 返回音频格式 |
EmotionCategory | 控制合成音频的情感 |
在调试的过程中也可以点击图形跳转到对应的文档说明
VoiceType
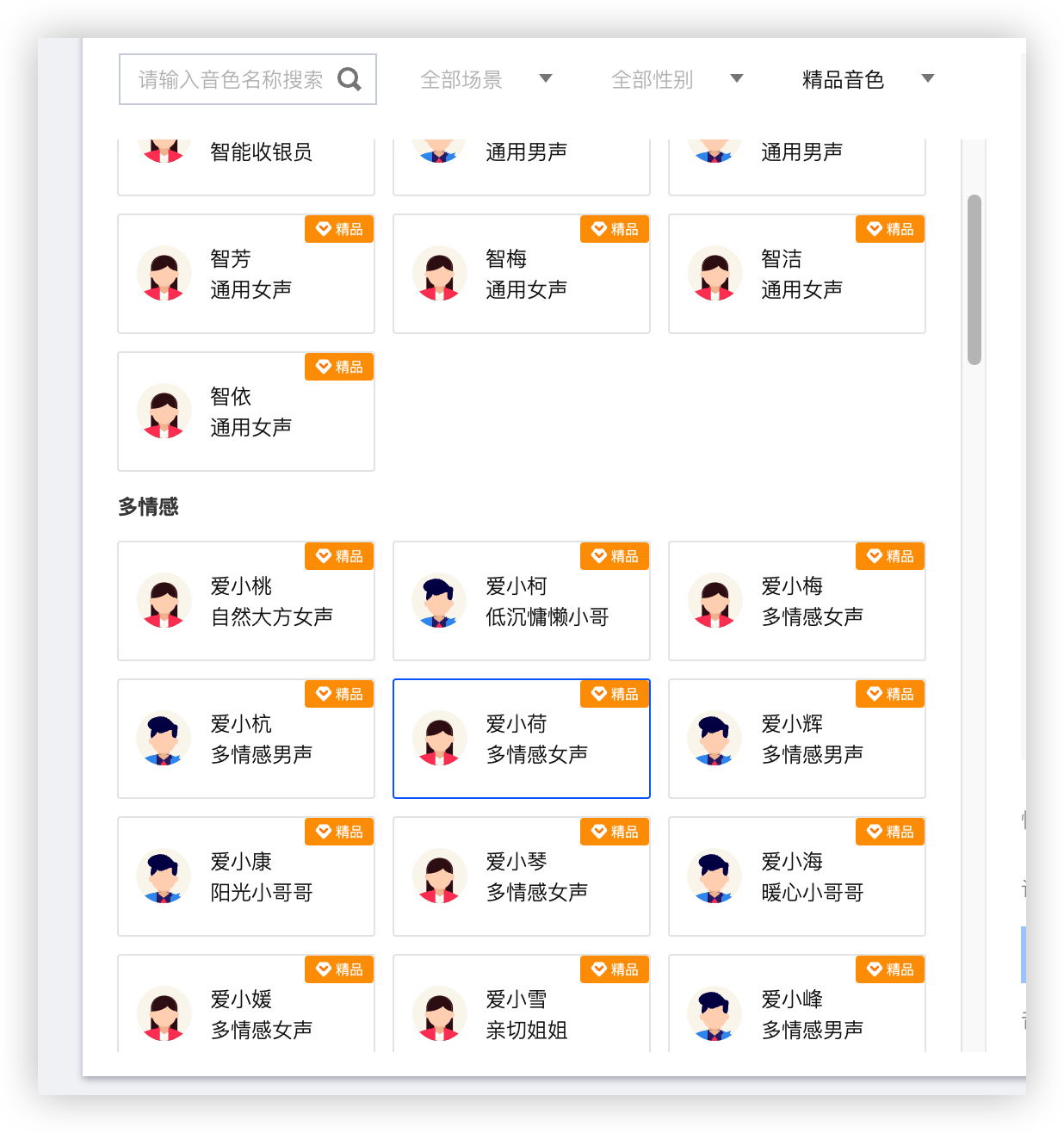
点击音色列表选择你觉得好听的音色 ID 我这里就选择 爱小荷 301032 音色情感 搞个 高兴
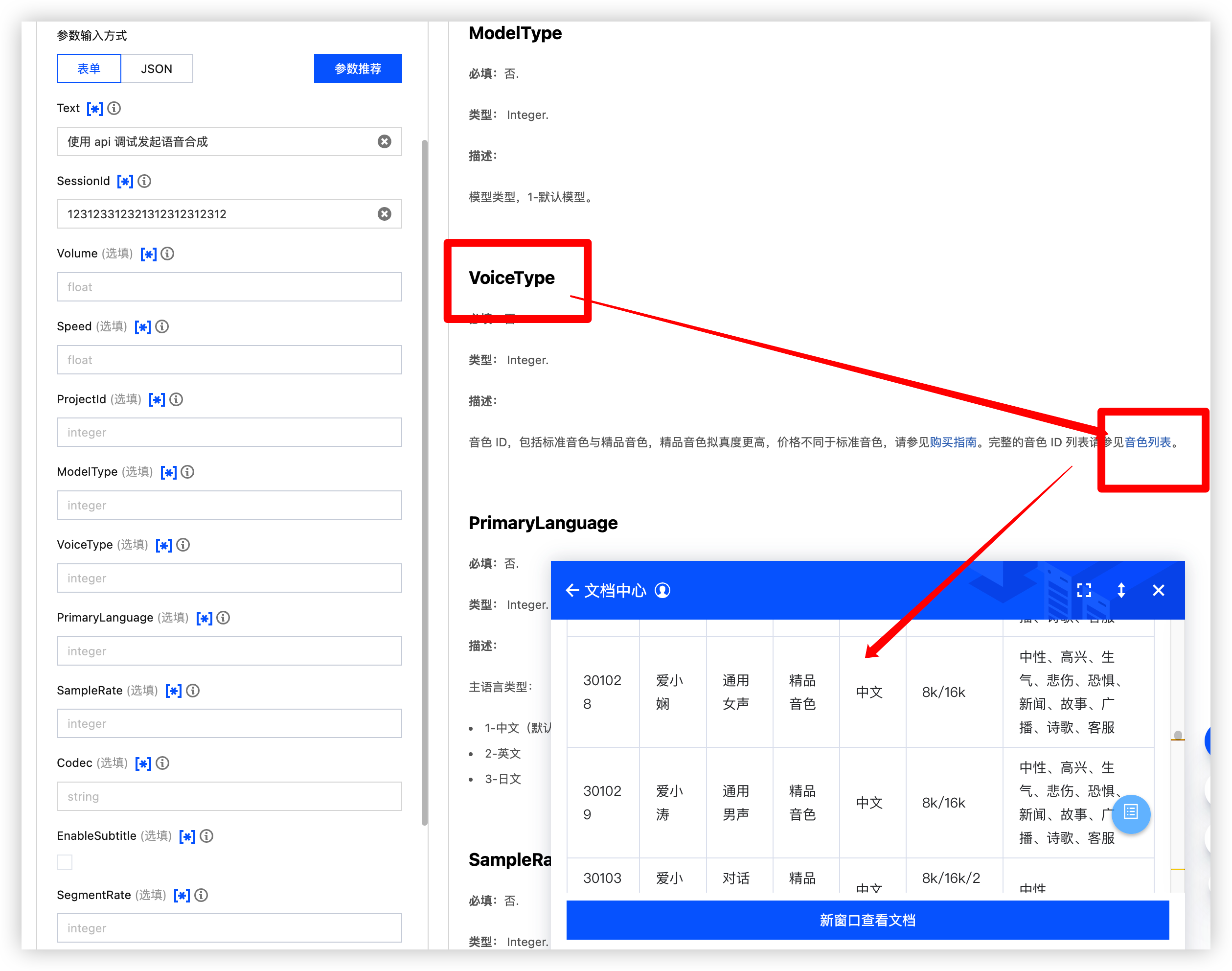
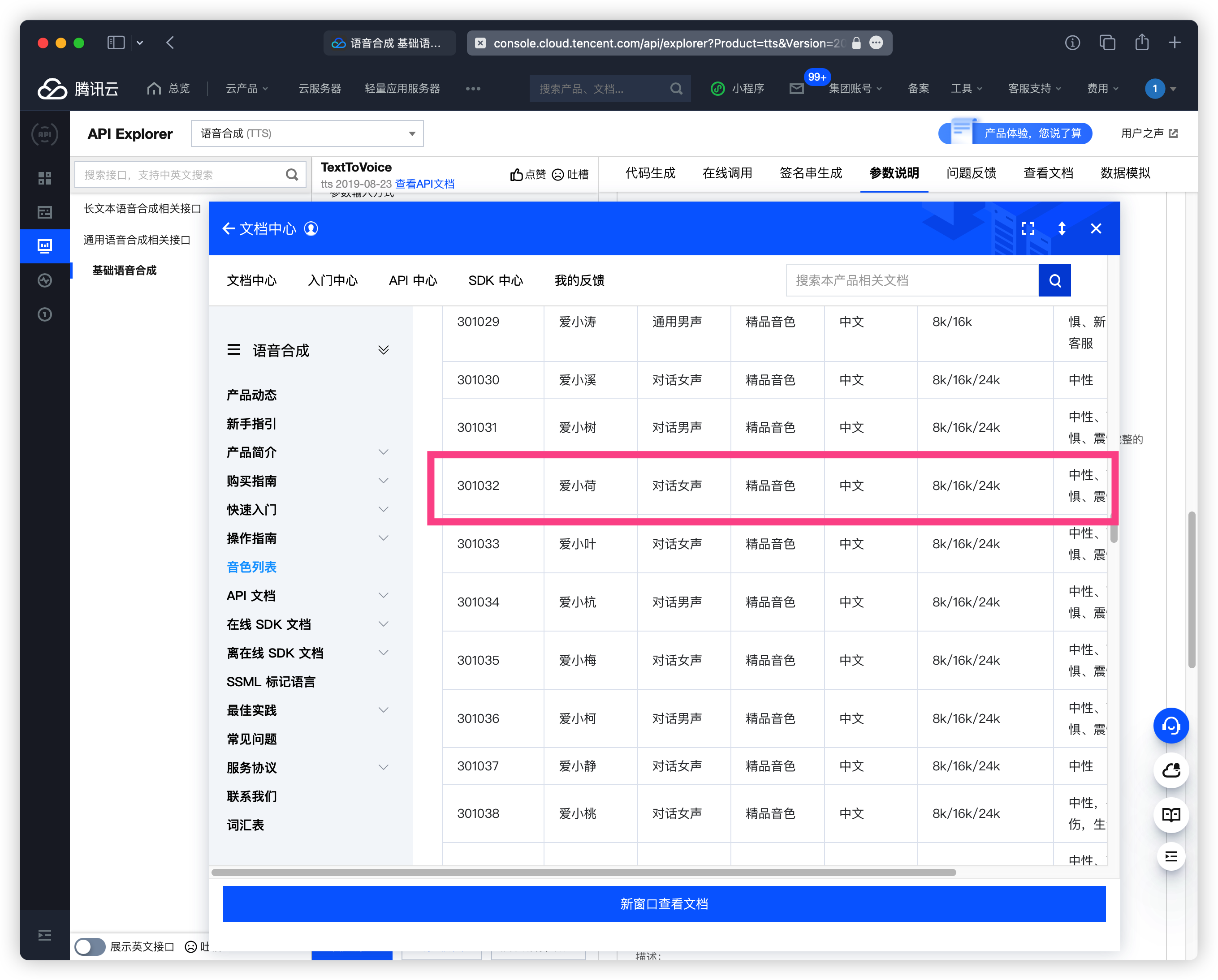
如果不知道是什么样子去 合成音频菜单 调试一下看看你喜欢哪个口味的
EmotionCategory
设置情绪 控制合成音频的情感,仅支持多情感音色使用。取值: neutral(中性)、sad(悲伤)、happy(高兴)、angry(生气)、fear(恐惧)、news(新闻)、story(故事)、radio(广播)、poetry(诗歌)、call(客服)、撒娇(sajiao)、厌恶(disgusted)、震惊(amaze)、平静(peaceful)、兴奋(exciting)、傲娇(aojiao)、解说(jieshuo)

Codec
设置返回的格式我这里就 mp3 格式

PrimaryLanguage
设置合成语音语言默认为中文有需要的就自己改改我就默认了
提前透视: FastVoiceType 参数是用来填写声音复刻 ID 也就是自定义音色将你自己的音色复刻,后面就可以使用你的语气声音来语音合成播放是不是很强, 后面会讲到
调试效果
填写好对应参数后直接在线调用即可
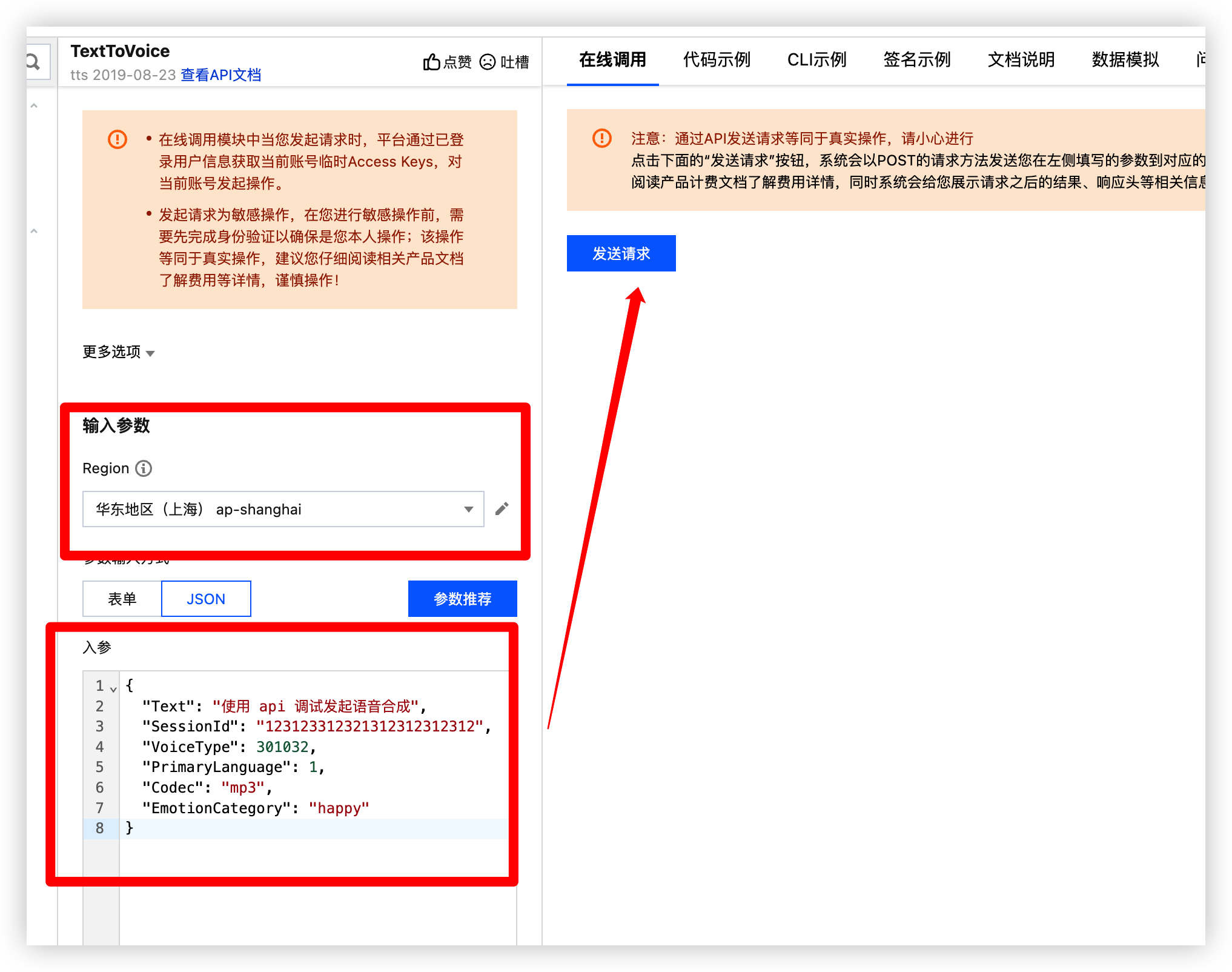
调用成功, 来听听看浏览器输入data:audio/mp3;base64,拼接 Audio 参数, 即可播放
data:audio/mp3;base64,//OoxAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAV......同学们可以把生成的语音发在评论,想你了想听你语音
代码示例
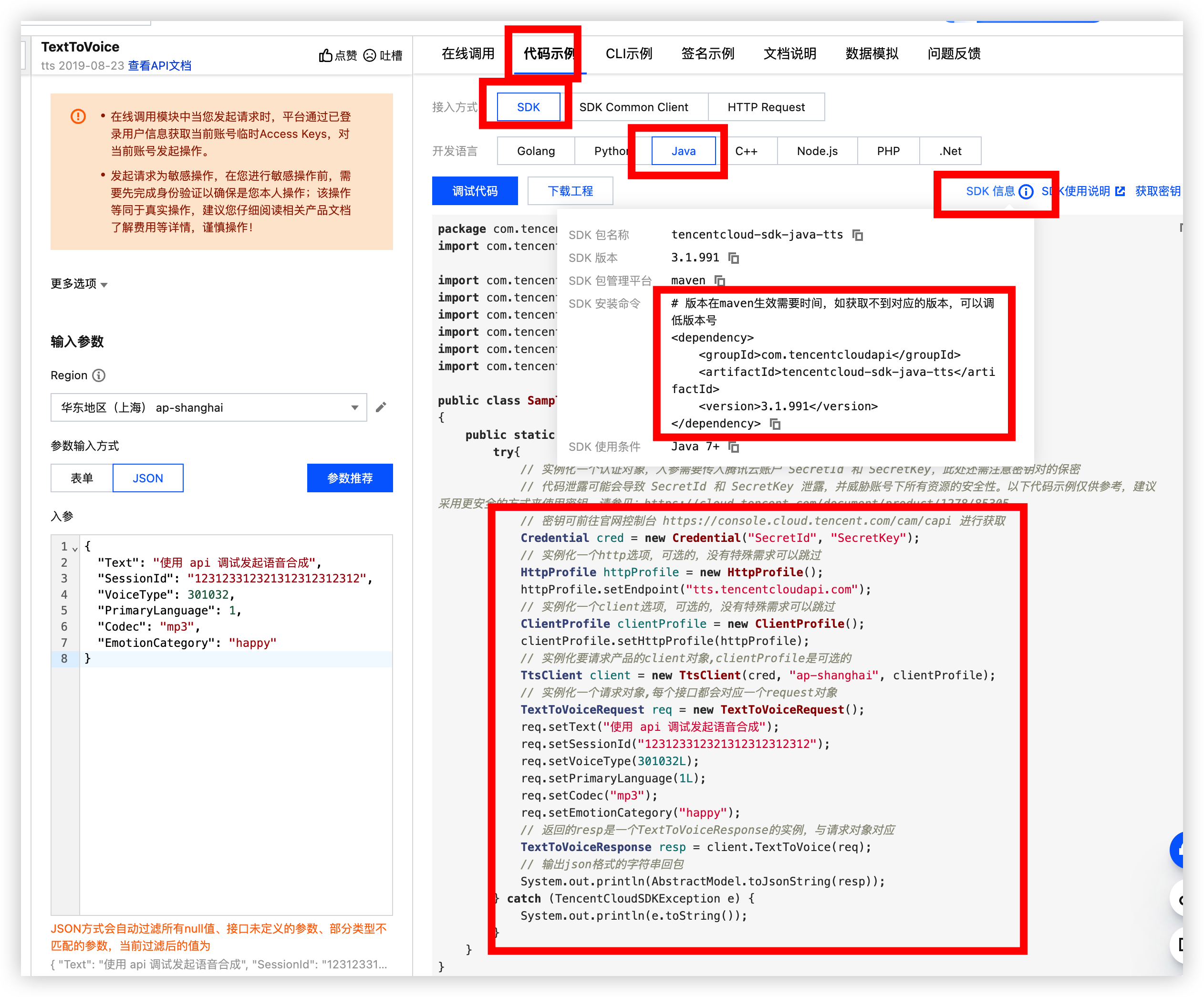
我们使用 SDK 接入 maven 依赖, 代码都给我们生成好了那么我们就创建工程试试看
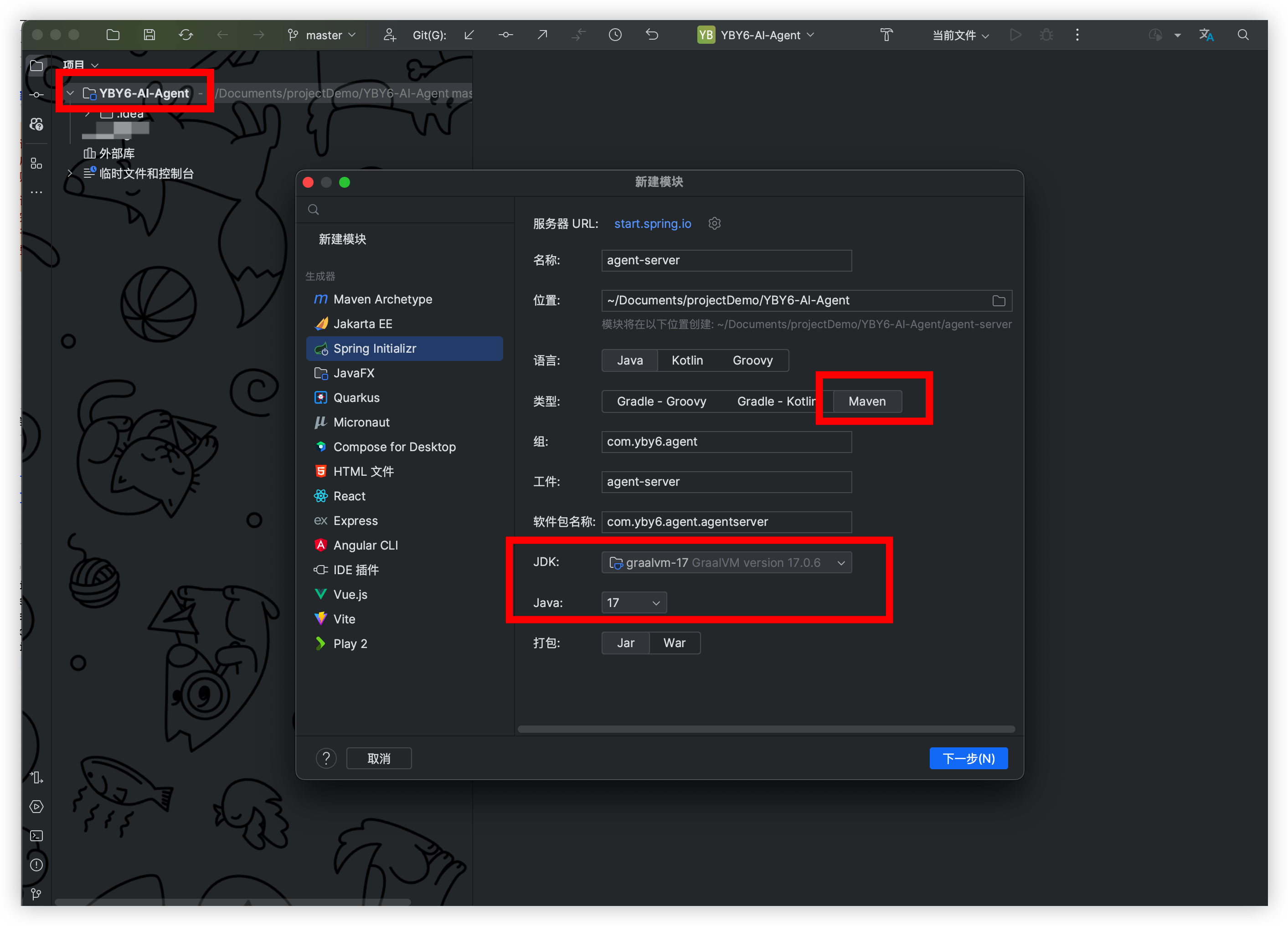
创建后端工程
请先创建一个文件夹在该文件夹下面新增后端工程, 后面前端工程也要放在这里, 同一个仓库好管理
我这里就使用 JDK17 版本
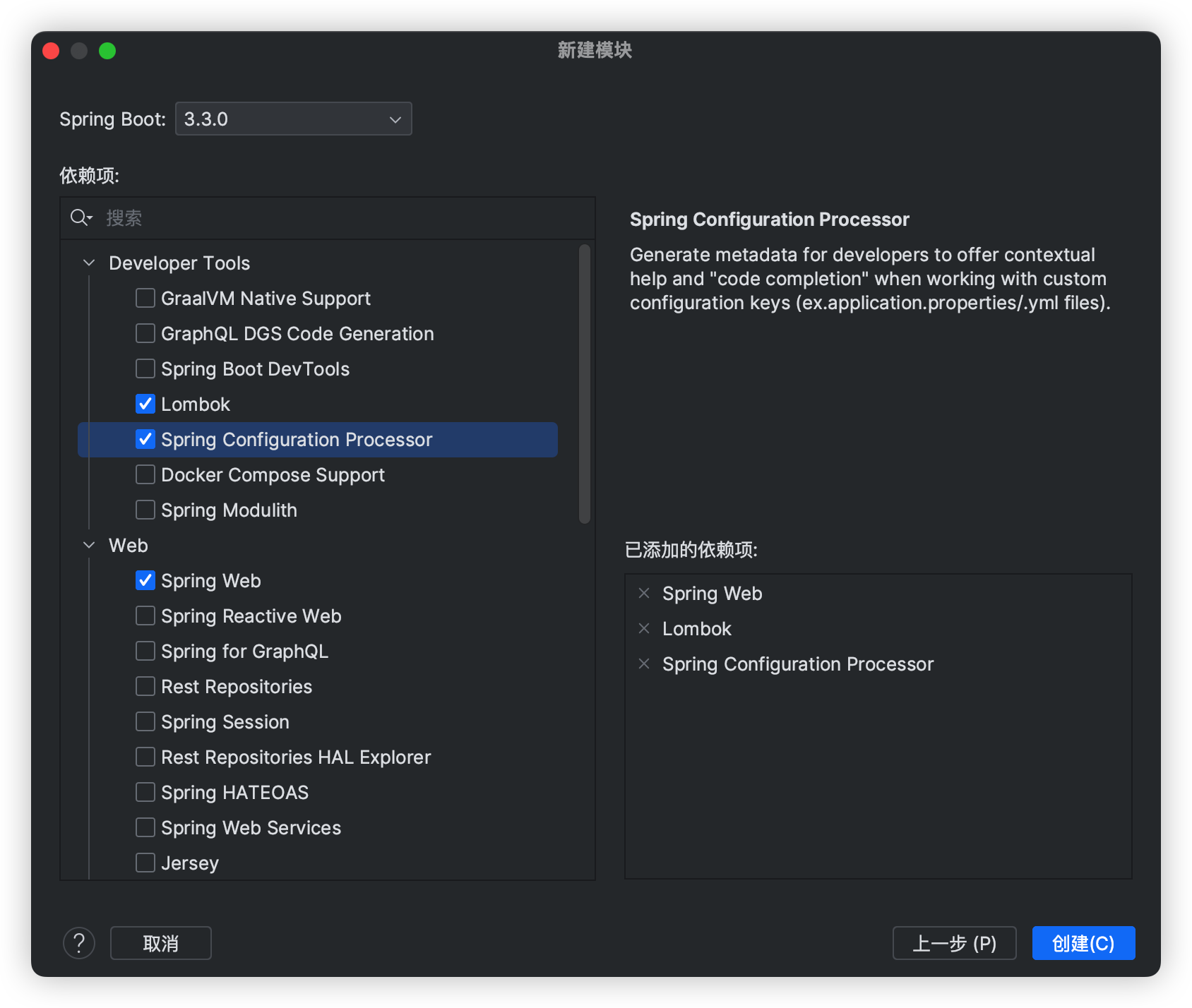
添加依赖
<!-- 语音合成 -->
<dependency>
<groupId>com.tencentcloudapi</groupId>
<artifactId>tencentcloud-sdk-java-tts</artifactId>
<version>3.1.991</version>
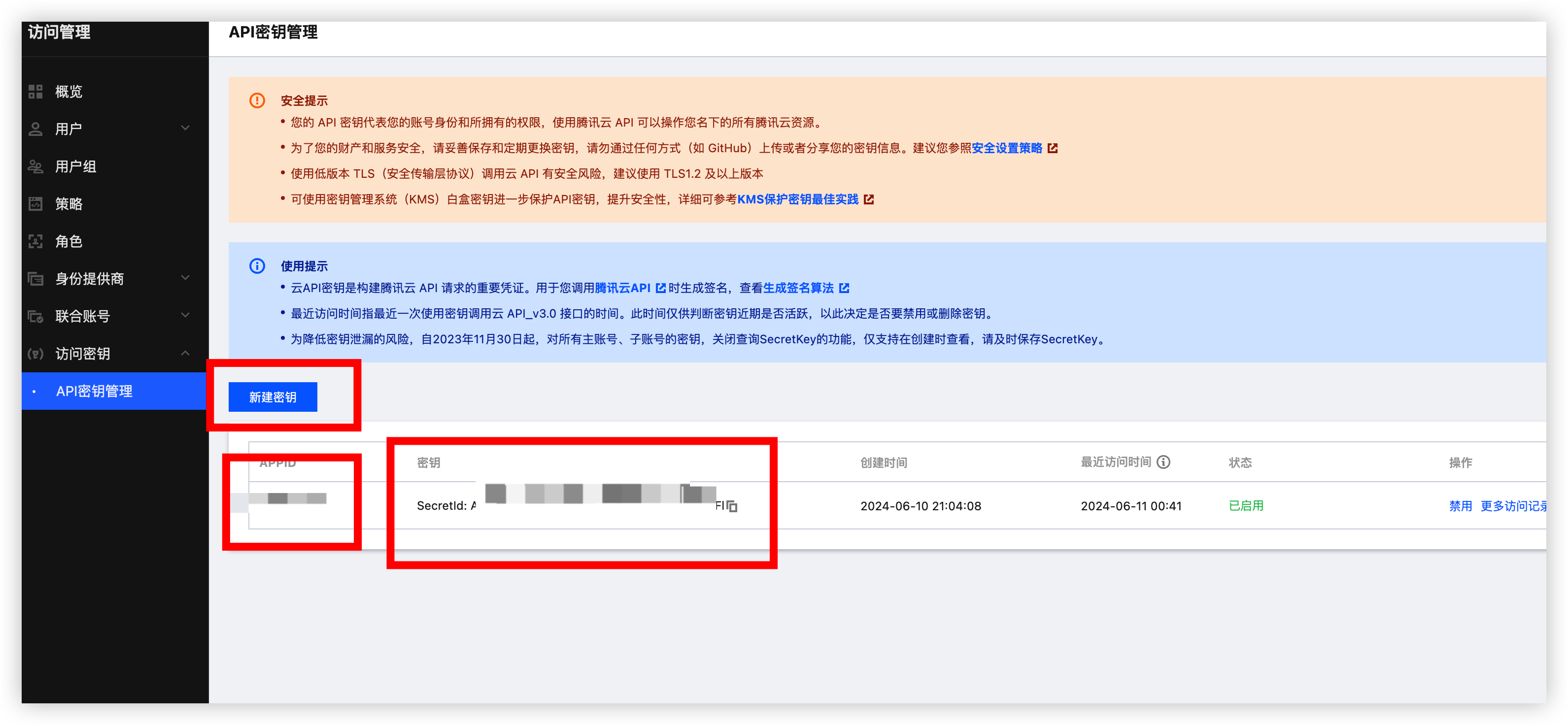
</dependency>将调试好的代码复制过来即可, 还缺少 API 密钥 根据注释提示的链接前往获取
调试
填写密钥完毕后即可直接发起请求
那么到这里就已经使用 Java 简单的接入好语音合成功能是不是觉得解放双手非常的 easy , 后面将会和语音识别封装为一个工具类提供使用
接入 ASR 语音识别
在上面我们已经完美在程序当中接入了语音合成 TTS 接下来飙车 ASR 语音识别, 一样的配方一样的感觉 so easy to happy 切菜一样
开通 ASR
前往腾讯云语音识别服务网站: 语音识别实时语音识别录音文件识别_语音转文本服务 - 腾讯云

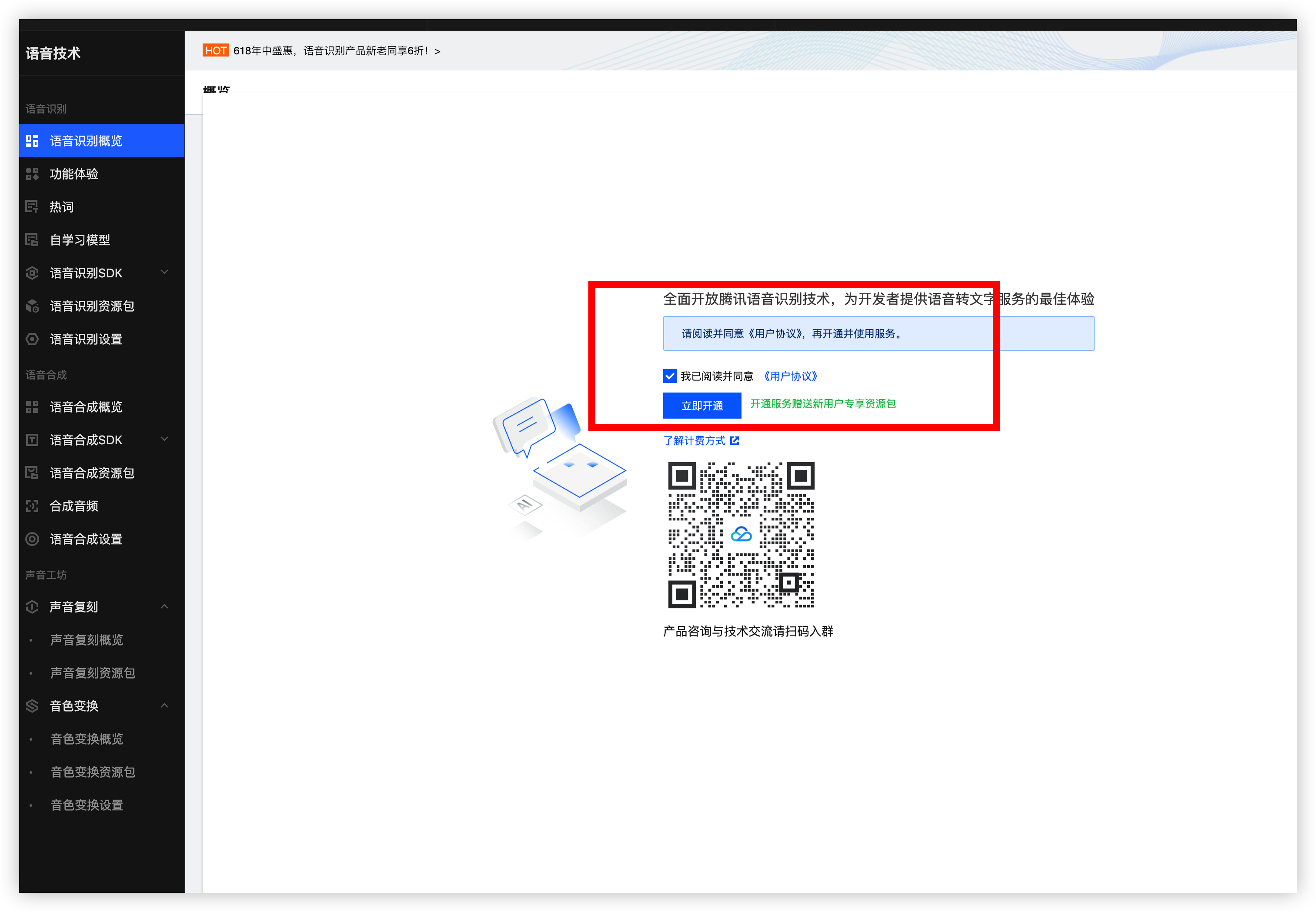
开通后腾讯云会赠送新用户免费额度,而且还是 每个月 都有这么多免费额度提供使用只能说良心云
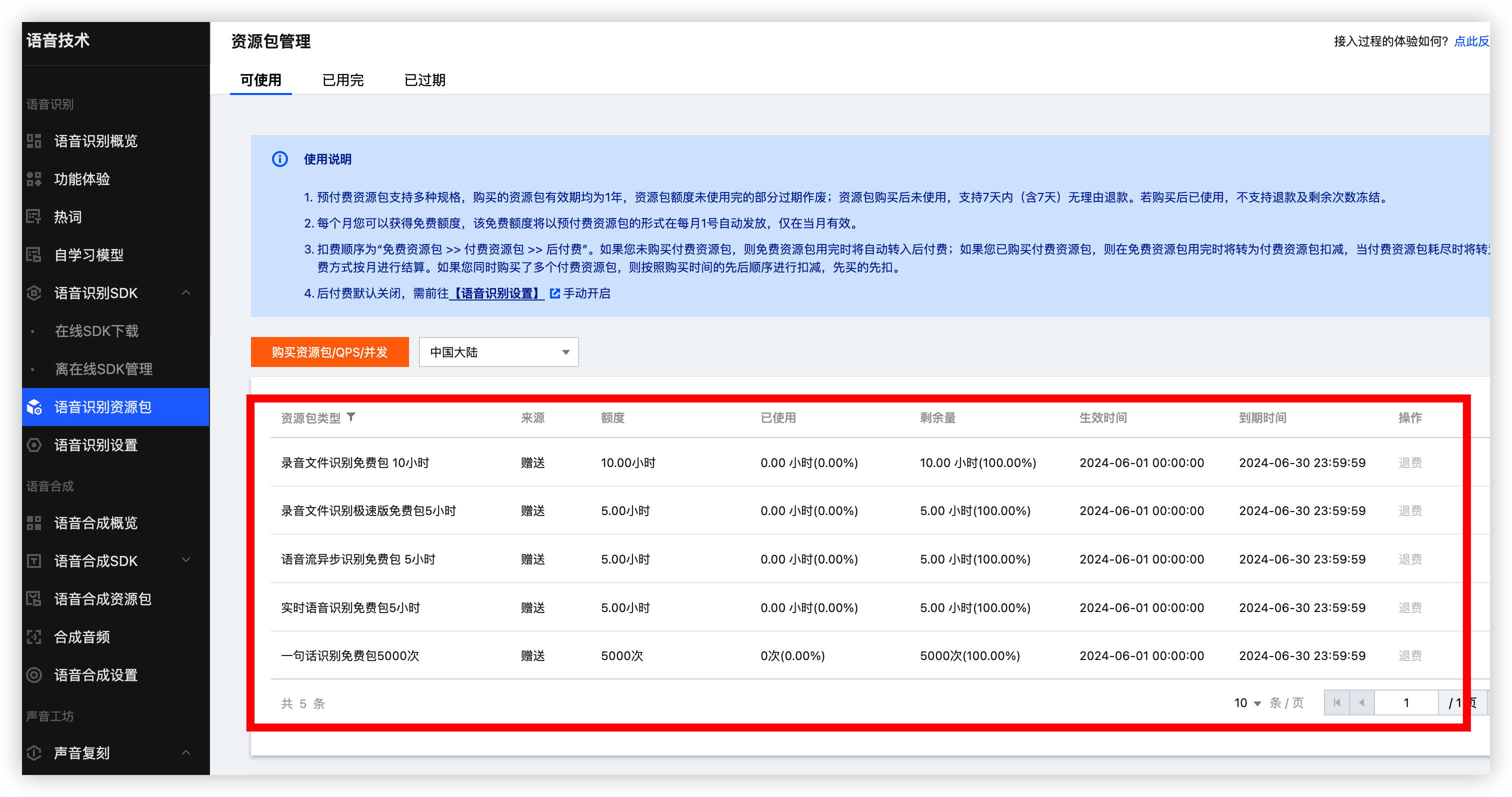
点击功能体验, 方可体验语音识别, 刚刚好前面我们用语音合成了一个音频文件访问 Base64 就可以下载到本地了
我们选择通用语音识别即可, 大模型识别可以提高准确率有资源的方可尝试一波
上传音频文件后直接点击开始识别
结果输出在下方, 往下滑就可以看到音频内容
ASR 文档
那么简单体验后我们来开始接入到程序当中, 接入前还是一样先看看文档怎么操作
本次学习的接口有三个 录音文件识别、录音文件识别极速版、实时语音识别
下面我将一个个的介绍和使用最终封装到一个工具类当中, 都是使用的腾讯云 SDK
录音文件识别
接口请求域名: asr.tencentcloudapi.com 默认接口请求频率限制:20次/秒。
本接口可对较长的录音文件进行识别, 我们后面要写一个故事智能体, 返回的文本信息偶尔会很长那么就需要用这个
接口描述
• 接口默认限频:20次/秒。此处仅限制任务提交频次,与识别结果返回时效无关
• 返回时效:异步回调,非实时返回。最长3小时返回识别结果,大多数情况下,1小时的音频1-3分钟即可完成识别
• 音频格式:wav、mp3、m4a、flv、mp4、wma、3gp、amr、aac、ogg-opus、flac
• 音频提交方式:本接口支持音频 URL 、本地音频文件两种请求方式。
• 音频限制:音频 URL 时长不能大于5小时,文件大小不超过1GB;本地音频文件不能大于5MB
接口请求要求
实际上我们就只需要这五个参数, 其它的参数查看文档介绍来使用我就不一一给同学演示了
比如其中的一个热词增强功能就是将同拼音的文字识别为你定义的比如热词定义杨不易呀
如果识别出来的同拼音 杨布依吖(yangbuyiya) 就会将其进行替换, 都是非常好理解的
参数名称 | 描述 |
|---|---|
EngineModelType | 引擎模型类型 就两个 一个是电话用的一个是通用的, 我们直接使用通用即可 16k_zh |
ChannelNum | 识别声道数 1:单声道(16k音频仅支持单声道,请勿设置为双声道) 2:双声道(仅支持8k电话音频,且双声道应分别为通话双方) |
ResTextFormat | 识别结果返回样式基础识别结果 |
SourceType | 音频数据来源 0:音频URL; 1:音频数据(post body) |
Data | 音频数据base64编码 当 SourceType 值为 1 时须填写该字段,为 0 时不需要填写 |
输出参数
参数名称 | 类型 | 描述 |
|---|---|---|
Data | Task | 录音文件识别的请求返回结果,包含结果查询需要的TaskId |
RequestId | String | 唯一请求 ID,由服务端生成,每次请求都会返回(若请求因其他原因未能抵达服务端,则该次请求不会获得 RequestId)。定位问题时需要提供该次请求的 RequestId。 |
可以看到该接口返回的不是一个音频而是一个任务 ID 那么 就需要通过任务 ID 去查询到我们对应的识别结果
结果查询
调用录音文件识别请求接口后,有回调和轮询两种方式获取识别结果
注意任务有效期为24小时,超过24小时的任务请不要再查询,且不要依赖TaskId作为业务唯一ID,不同日期可能出现重复TaskId ⚠️ 默认接口请求频率限制:50次/秒 如果需要提高请求频率限制的需求,那就要提交工单了: 工单
接口请求要求
参数名称 | 必选 | 类型 | 描述 |
|---|---|---|---|
TaskId | 是 | Integer | 从CreateRecTask接口获取的TaskId,用于获取任务状态与结果。注意:TaskId有效期为24小时,超过24小时的TaskId请不要再查询。 示例值:4500055927 |
也就是前面拿到的任务 ID 传递过去就可以返回语音识别结果了
输出参数
参数名称 | 类型 | 描述 |
|---|---|---|
Data | TaskStatus | 录音文件识别的请求返回结果。示例值:{ "Response": { "RequestId": "8824366f-0e8f-4bd4-892 |
RequestId | String | 唯一请求 ID,由服务端生成,每次请求都会返回(若请求因其他原因未能抵达服务端,则该次请求不会获得 RequestId)。定位问题时需要提供该次请求的 RequestId。 |
接口我们已经了解完毕来吧一样的操作, 使用 API 调试
录音文件识别接口 API 调试
点击调试, 我们直接选择录音文件识别请求, 填写字段数据
EngineModelType 我们接入的是中文根据描述填入 16_zh 即可
ChannelNum 用于识别音道数根据描述直接填入 1 即可
ResTextFormat 识别结果返回样式 我们直接选择 0:基础识别结果, 我们需求只是用于对话识别, 如果用在字幕上面就需要 选择 3 了
SourceType 音频数据来源后面我是直接通过前端转 base64 给后端则选择使用 post body 传递参数
Data 音频数据base64编码 当 SourceType 值为 1 时须填写该字段,为 0 时不需要填写
⚠️ 音频数据要小于5MB(含), 我们问答不会超过 1mb 对话后面会设置时间的 30s 差不多了
填入两个参数, 如果没有音频那就去语音合成搞一个好吧, 就不带着同学操作了
直接点击发起请求即可, 记得吧 data:audio/mp3;base64, 删除哦要不然 400 错误
调试效果
成功拿到任务 ID, 然后复制任务 ID 再去请求一下查询接口即可
查询成功完成
接下来一样的操作, 开始接入程序当中
代码示例
接下来我们接入到程序当中操作一遍就 ok 啦
ASR 依赖
老规矩引入依赖, 后面可以使用用整体的替换这两个
<!-- 语音识别 -->
<dependency>
<groupId>com.tencentcloudapi</groupId>
<artifactId>tencentcloud-sdk-java-asr</artifactId>
<version>3.1.1040</version>
</dependency>创建音频识别测试类
打开前面创建的工程新增语音识别的单元测试, 多个相同的在这里统一实现

@Test void voice2text_1() throws TencentCloudSDKException {// 实例化一个http选项,可选的,没有特殊需求可以跳过
HttpProfile httpProfile = new HttpProfile();
httpProfile.setEndpoint("asr.tencentcloudapi.com");
// 实例化一个client选项,可选的,没有特殊需求可以跳过
ClientProfile clientProfile = new ClientProfile();
clientProfile.setHttpProfile(httpProfile);
// 实例化要请求产品的client对象,clientProfile是可选的
AsrClient client = new AsrClient(cred, "ap-guangzhou", clientProfile);
// 实例化一个请求对象,每个接口都会对应一个request对象
CreateRecTaskRequest req = new CreateRecTaskRequest();
req.setEngineModelType("16k_zh");
req.setChannelNum(1L);
req.setResTextFormat(0L);
req.setSourceType(1L);
StringBuffer stringBuffer = new StringBuffer(
"//OoVVVVVVVVVV"
);
req.setData(stringBuffer.toString());
// 返回的resp是一个CreateRecTaskResponse的实例,与请求对象对应
CreateRecTaskResponse resp = client.CreateRecTask(req);
log.info("任务ID: {}", resp.getData().getTaskId());
// 实例化一个请求对象,每个接口都会对应一个request对象
DescribeTaskStatusRequest query = new DescribeTaskStatusRequest();
query.setTaskId(resp.getData().getTaskId());}
@Test
void queryResult() throws Exception {
// 实例化一个http选项,可选的,没有特殊需求可以跳过
HttpProfile httpProfile = new HttpProfile();
httpProfile.setEndpoint("asr.tencentcloudapi.com");
// 实例化一个client选项,可选的,没有特殊需求可以跳过
ClientProfile clientProfile = new ClientProfile();
clientProfile.setHttpProfile(httpProfile);
// 实例化要请求产品的client对象,clientProfile是可选的
AsrClient client = new AsrClient(cred, "ap-guangzhou", clientProfile);
DescribeTaskStatusRequest query = new DescribeTaskStatusRequest();
// 填入任务ID
query.setTaskId(9365213113L);
// 返回的resp是一个DescribeTaskStatusResponse的实例,与请求对象对应
DescribeTaskStatusResponse queryRes = client.DescribeTaskStatus(query);
final String result = JSONUtil.toJsonStr(queryRes);
log.info("录音文件识别1: {}", result);
}

拿到任务 ID 再去执行查询录音识别结果如上图, 这种方式有点麻烦了输出的识别结果带了 包含有效人声时间戳 还要调两个接口, 接下来介绍录音文件识别极速版,一个接口搞定也符合我们的业务就是要极速!!!
录音文件识别极速版
极速版和普通版本是差不多一样的 前往极速版文档查看请求参数: 语音识别 录音文件识别极速版-API 文档-文档中心-腾讯云
极速版本是没有 API 调试的所以腾讯云准备了 demo 案例我们直接 copy
简单看一下文档的各个参数
往下滑找到 Java 案例 点击获取代码
跳转到 github 仓库直接 cv 案例到我们工程当中, 对应的极速版本的依赖是另外的在 pom 当中获取
<!-- https://mvnrepository.com/artifact/com.tencentcloudapi/tencentcloud-speech-sdk-java -->
<dependency>
<groupId>com.tencentcloudapi</groupId>
<artifactId>tencentcloud-speech-sdk-java</artifactId>
<!--建议使用最新版本-->
<version>1.0.44</version>
</dependency>发起调试
把密钥参数全部填写完毕后, 在根据前面的音频随便下载一个音频文件, 直接发起
可以看到直接识别出来了文本不需要调用两个接口, 也可以控制词级别时间戳, 返回数据非常快
这样子就已经成功, 还剩下最后一个 实时语音识别
实时语音识别
实时语音识别, 如果是服务端对接那么就需要和前端搭配 web socket 进行双向链接, 多此一举我这里就使用前端来操作
前往实时语音识别文档 语音识别 实时语音识别(websocket)-API 文档-文档中心-腾讯云
点击 JS 示例 拉下来整个工程
克隆地址: git clone https://github.com/TencentCloud/tencentcloud-speech-sdk-js.git

工程拉下来后直接 npm i 执行一下 下载前端的依赖
执行完毕后, 填入密钥参数, 然后执行 npm run dev 启动工程
工程启动成功, 开启识别进行实时对话测试看看是否打通

进行说话将会极速的输出文本信息很流畅
到此, 我们的语音识别和语音合成已经全部学会了, 接下来就要开始我们的项目实战巩固知识点的使用情况了, 都看到这里了不要忘记给不易一键三连.
接下来我们将语音技术功能封装一下,为了项目实战打基础直接调用就行.
封装语音系统工具类
将不同的功能分别封装到不同的工具类当中, 录音文件识别普通版本我就没封装了我用不到, 这里我就封装了极速版和语音合成
新增腾讯配置文件类
在启动类同级别目录新增 config文件夹,新增 TencentConfig 用于配置密钥信息, 下面代码定义了 instance 用于在静态方法当中也可调用
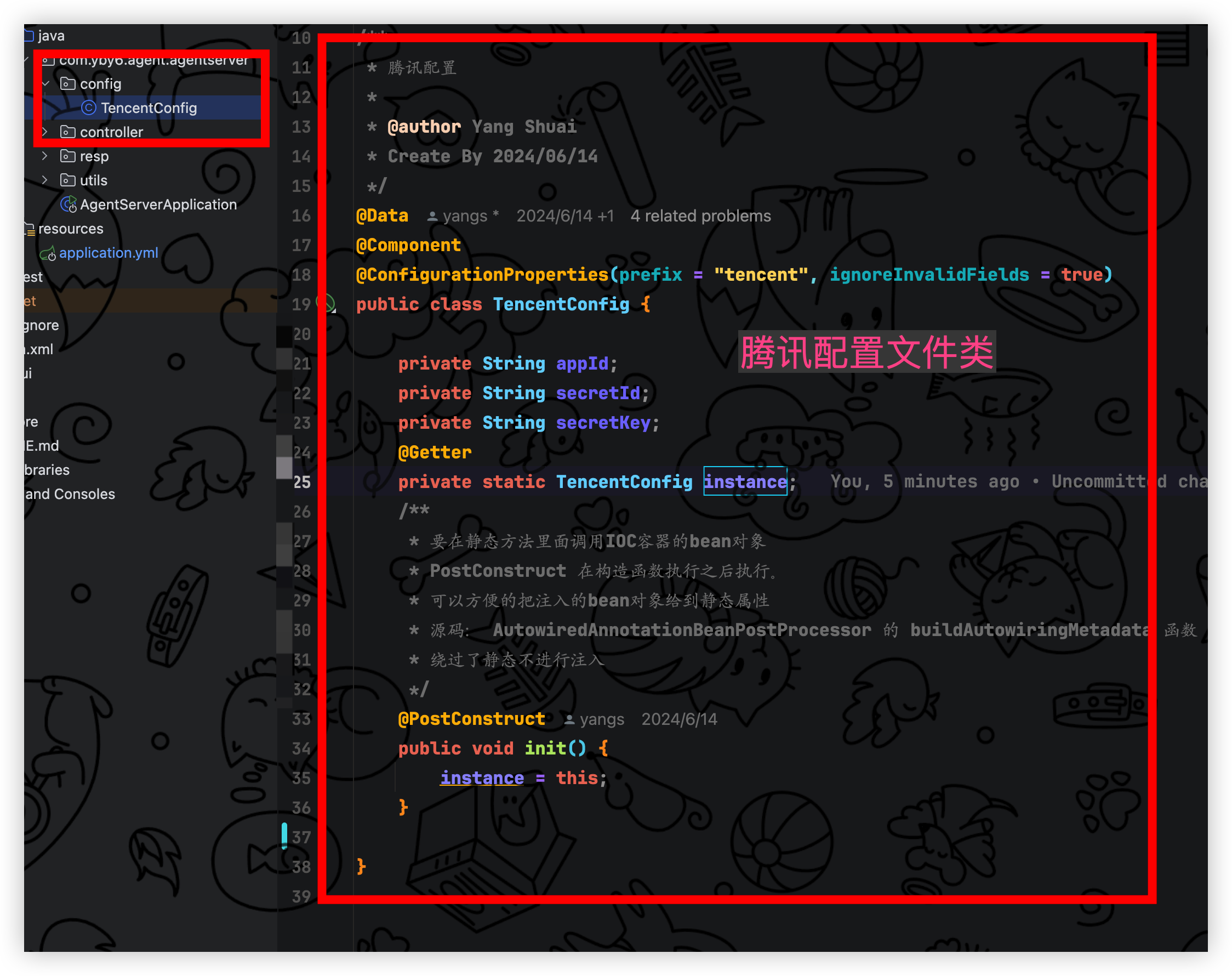
/*
- 您可以更改此项目但请不要删除作者署名谢谢,否则根据中华人民共和国版权法进行处理.
- You may change this item but please do not remove the author's signature,
- otherwise it will be dealt with according to the Copyright Law of the People's Republic of China.
- yangbuyi Copyright (c) https://yby6.com 2024.
*/package com.yby6.agent.agentserver.config;
import jakarta.annotation.PostConstruct;
import lombok.Data;
import lombok.Getter;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;/**
腾讯配置
@author Yang Shuai
Create By 2024/06/14
*/
@Data
@Component
@ConfigurationProperties(prefix = "tencent", ignoreInvalidFields = true)
public class TencentConfig {private String appId;
private String secretId;
private String secretKey;
@Getter
private static TencentConfig instance;
/**
- 要在静态方法里面调用IOC容器的bean对象
- PostConstruct 在构造函数执行之后执行。
- 可以方便的把注入的bean对象给到静态属性
- 源码: AutowiredAnnotationBeanPostProcessor 的 buildAutowiringMetadata 函数
- 绕过了静态不进行注入
*/
@PostConstruct
public void init() {
instance = this;
}
}
修改配置文件,填入密钥信息
编写语音识别工具类 ASR
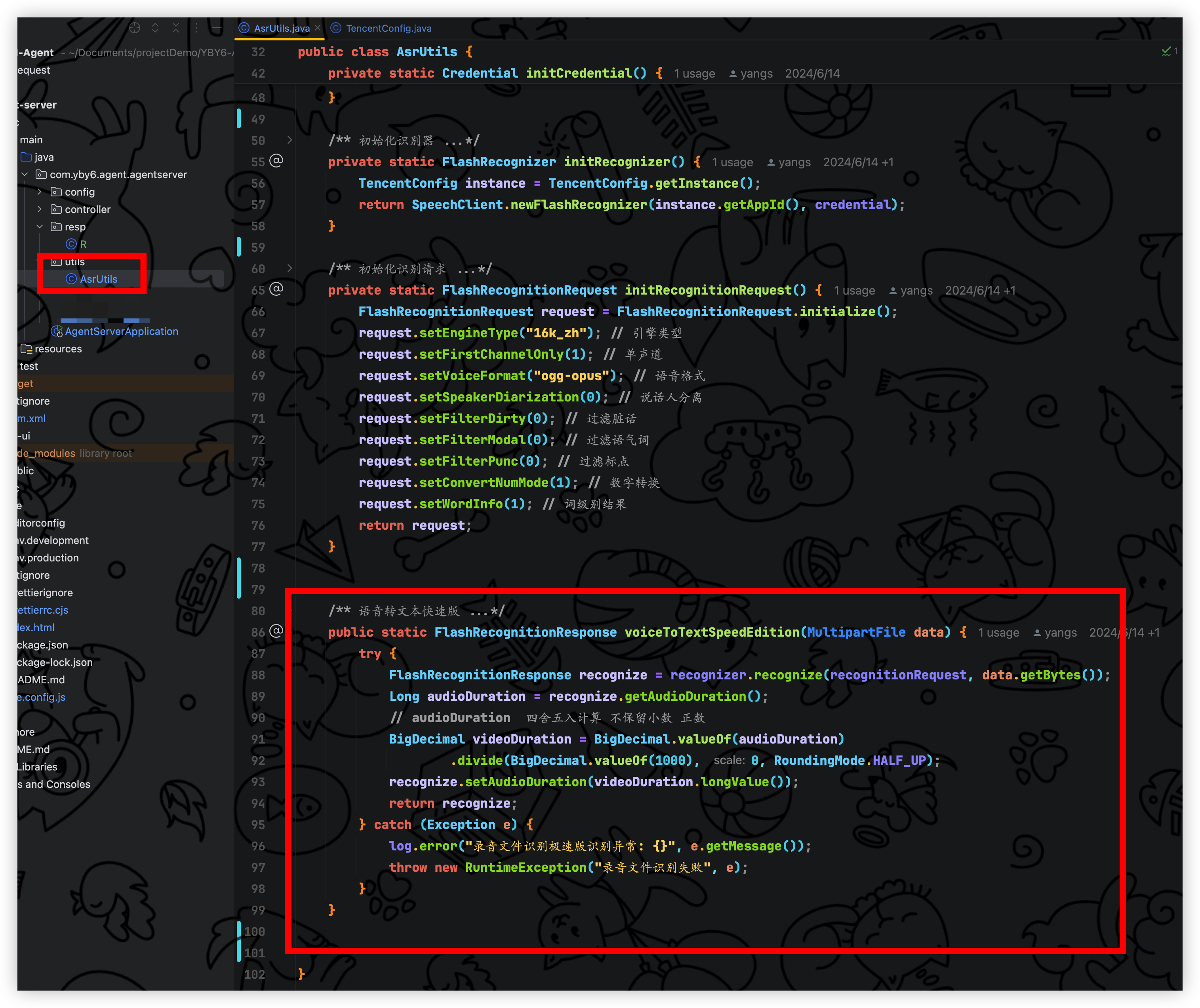
在启动类同级别目录新增 utils 文件夹,新增 AsrUtils 类, 里面就包含一个录音文件识别极速版, 如果要集成普通版本在这里些即可
代码就是初始化凭证和请求参数工整规范
/*
- 您可以更改此项目但请不要删除作者署名谢谢,否则根据中华人民共和国版权法进行处理.
- You may change this item but please do not remove the author's signature,
- otherwise it will be dealt with according to the Copyright Law of the People's Republic of China.
- yangbuyi Copyright (c) https://yby6.com 2024.
*/package com.yby6.agent.agentserver.utils;
import com.tencent.SpeechClient;
import com.tencent.asr.model.Credential;
import com.tencent.asr.model.FlashRecognitionRequest;
import com.tencent.asr.model.FlashRecognitionResponse;
import com.tencent.asr.service.FlashRecognizer;
import com.yby6.agent.agentserver.config.TencentConfig;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.multipart.MultipartFile;import java.math.BigDecimal;
import java.math.RoundingMode;/**
录音文件识别极速版本 - 工具类
@author Yang Shuai
Create By 2024/06/14
*/
@Slf4j
public class AsrUtils {
private static final Credential credential = initCredential();
private static final FlashRecognizer recognizer = initRecognizer();
private static final FlashRecognitionRequest recognitionRequest = initRecognitionRequest();/**
- 初始化凭证
- @return {@link Credential}
*/
private static Credential initCredential() {
TencentConfig instance = TencentConfig.getInstance();
return Credential.builder()
.secretId(instance.getSecretId())
.secretKey(instance.getSecretKey())
.build();
}/**
- 初始化识别器
- @return {@link FlashRecognizer}
*/
private static FlashRecognizer initRecognizer() {
TencentConfig instance = TencentConfig.getInstance();
return SpeechClient.newFlashRecognizer(instance.getAppId(), credential);
}/**
- 初始化识别请求
- @return {@link FlashRecognitionRequest}
*/
private static FlashRecognitionRequest initRecognitionRequest() {
FlashRecognitionRequest request = FlashRecognitionRequest.initialize();
request.setEngineType("16k_zh"); // 引擎类型
request.setFirstChannelOnly(1); // 单声道
request.setVoiceFormat("ogg-opus"); // 语音格式
request.setSpeakerDiarization(0); // 说话人分离
request.setFilterDirty(0); // 过滤脏话
request.setFilterModal(0); // 过滤语气词
request.setFilterPunc(0); // 过滤标点
request.setConvertNumMode(1); // 数字转换
request.setWordInfo(1); // 词级别结果
return request;
}/**
- 语音转文本快速版
- @param data 语音文件流
- @return {@link FlashRecognitionResponse}
*/
public static FlashRecognitionResponse voiceToTextSpeedEdition(MultipartFile data) {
try {
FlashRecognitionResponse recognize = recognizer.recognize(recognitionRequest, data.getBytes());
Long audioDuration = recognize.getAudioDuration();
// audioDuration 四舍五入计算 不保留小数 正数
BigDecimal videoDuration = BigDecimal.valueOf(audioDuration)
.divide(BigDecimal.valueOf(1000), 0, RoundingMode.HALF_UP);
recognize.setAudioDuration(videoDuration.longValue());
return recognize;
} catch (Exception e) {
log.error("录音文件识别极速版识别异常: {}", e.getMessage());
throw new RuntimeException("录音文件识别失败", e);
}
}
}
编写语音合成工具类 TTS
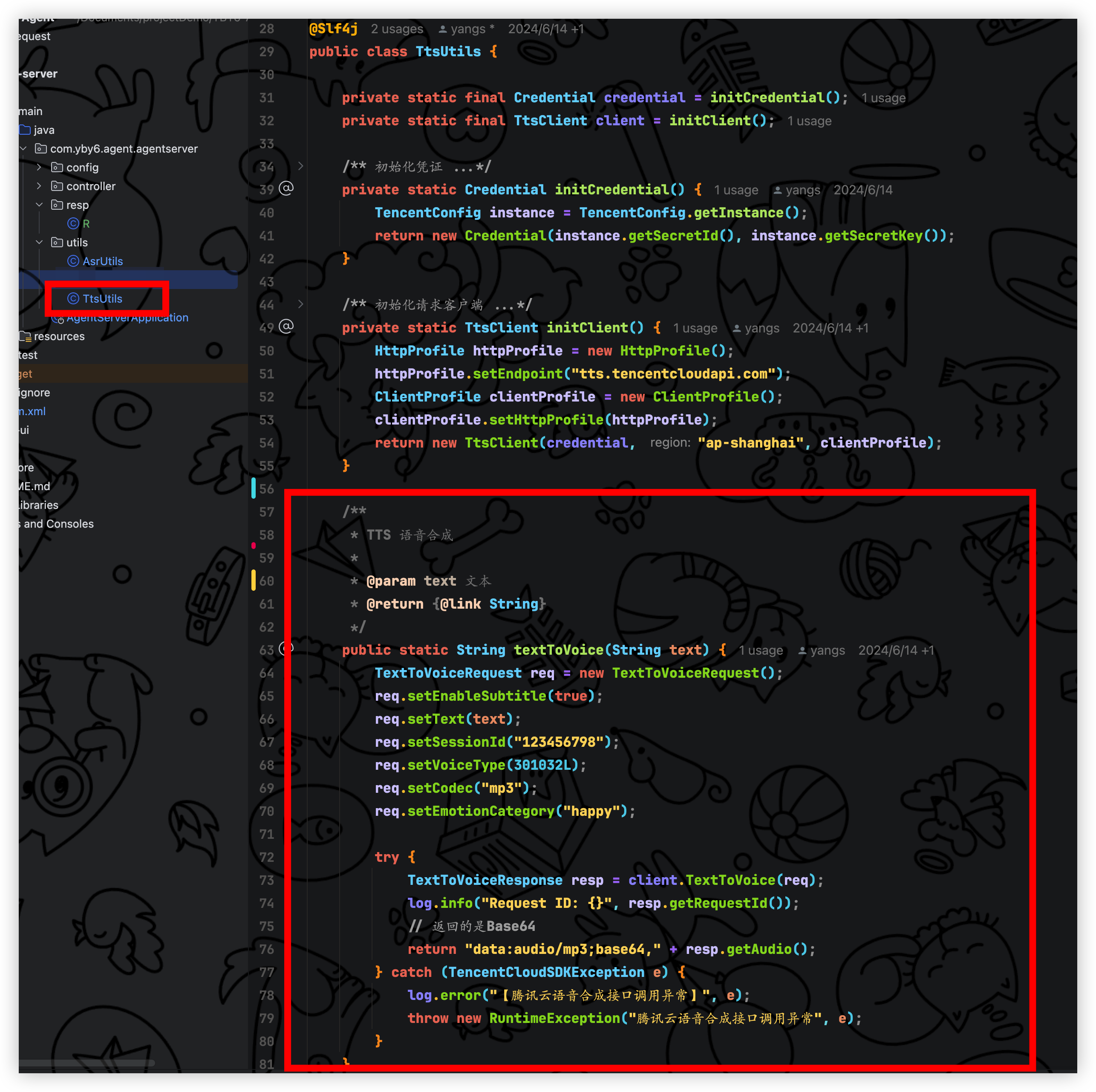
在 utils包下面新增 TtsUtils 类, 里面就包含腾讯云语音合成代码,初始化了凭证,和请求客户端
请求参数我这里就固定在这里, 因为这个是不经常更改的
测试工具类
在新增前自定义一个响应体返回类
/*
- 您可以更改此项目但请不要删除作者署名谢谢,否则根据中华人民共和国版权法进行处理.
- You may change this item but please do not remove the author's signature,
- otherwise it will be dealt with according to the Copyright Law of the People's Republic of China.
- yangbuyi Copyright (c) https://yby6.com 2024.
*/
package com.yby6.agent.agentserver.resp;
import java.io.Serial;
import java.io.Serializable;
/**
-
响应信息主体
-
@author Yang Shuai
Create By 2023/12/10
/
public class R<T> implements Serializable {
/*- 成功
/
public static final int SUCCESS = 200;
/* - 失败
/
public static final int FAIL = 500;
/* - 失败忽略
/
public static final int FAILIGNORE = 201;
@Serial
private static final long serialVersionUID = 1L;
/* - 消息状态码
*/
private int code;
/**
- 消息内容
*/
private String msg;
/**
- 数据对象
*/
private T data;
public static <T> R<T> ok() {
return restResult(null, SUCCESS, "操作成功");
}public static <T> R<T> ok(T data) {
return restResult(data, SUCCESS, "操作成功");
}public static <T> R<T> ok(String msg) {
return restResult(null, SUCCESS, msg);
}public static <T> R<T> ok(String msg, T data) {
return restResult(data, SUCCESS, msg);
}public static <T> R<T> fail() {
return restResult(null, FAIL, "操作失败");
}public static <T> R<T> failIgnore() {
return restResult(null, FAILIGNORE, "操作失败");
}public static <T> R<T> failIgnore(T data) {
return restResult(data, FAILIGNORE, "操作失败");
}public static <T> R<T> fail(String msg) {
return restResult(null, FAIL, msg);
}public static <T> R<T> fail(T data) {
return restResult(data, FAIL, "操作失败");
}public static <T> R<T> fail(String msg, T data) {
return restResult(data, FAIL, msg);
}public static <T> R<T> fail(int code, String msg) {
return restResult(null, code, msg);
}public static <T> R<T> check(int row) {
return row > 0 ? ok() : fail();
}public static <T> R<T> check(boolean isTure) {
return isTure ? ok() : fail();
}/**
- 返回警告消息
- @param msg 返回内容
- @return 警告消息
*/
public static <T> R<T> warn(String msg) {
return restResult(null, 601, msg);
}
/**
- 返回警告消息
- @param msg 返回内容
- @param data 数据对象
- @return 警告消息
*/
public static <T> R<T> warn(String msg, T data) {
return restResult(data, 601, msg);
}
private static <T> R<T> restResult(T data, int code, String msg) {
R<T> r = new R<>();
r.setCode(code);
r.setData(data);
r.setMsg(msg);
return r;
}public static <T> Boolean isError(R<T> ret) {
return !isSuccess(ret);
}public static <T> Boolean isSuccess(R<T> ret) {
return R.SUCCESS == ret.getCode();
}public int getCode() {
return code;
}public void setCode(int code) {
this.code = code;
}public String getMsg() {
return msg;
}public void setMsg(String msg) {
this.msg = msg;
}public T getData() {
return data;
}public void setData(T data) {
this.data = data;
}
}- 成功
测试封装的工具类是否可以成功调用, 新增 controller接口包, 新增 AudioController 接口
/*您可以更改此项目但请不要删除作者署名谢谢,否则根据中华人民共和国版权法进行处理.
You may change this item but please do not remove the author's signature,
otherwise it will be dealt with according to the Copyright Law of the People's Republic of China.
yangbuyi Copyright (c) https://yby6.com 2024.
*/package com.yby6.agent.agentserver.controller;
import com.tencent.asr.model.FlashRecognitionResponse;
import com.yby6.agent.agentserver.resp.R;
import com.yby6.agent.agentserver.utils.AsrUtils;
import com.yby6.agent.agentserver.utils.TtsUtils;
import lombok.RequiredArgsConstructor;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.multipart.MultipartFile;/**
音频控制器
@author Yang Shuai
Create By 2024/06/15
*/
@RestController
@RequestMapping("speechSynthesis")
@RequiredArgsConstructor
public class AudioController {/**
- 语音转文本
- @param audioFile 音频文件
- @return {@link FlashRecognitionResponse}
*/
@PostMapping("tencentVoiceToText")
public R<FlashRecognitionResponse> voiceToText(@RequestParam MultipartFile audioFile) {
return R.ok(AsrUtils.voiceToTextSpeedEdition(audioFile));
}/**
- 文本转语音
- @param text 文本
- @return {@link String}
*/
@PostMapping("tencentTextToVoice")
public R<String> textToVoice(@RequestParam String text) {
return R.ok(TtsUtils.textToVoice(text));
}
}
使用调试工具发起 API 请求, 看你喜欢用什么工具我这里就使用 ApiFox
如果你也是用的 ApiFox 可以下载一个插件
然后右击接口类, 会出现 upload to apifox 这个将会自动生成 API 接口文档
接着打开 ApiFox 客户端直接发起调试
语音合成成功, 接下来访问这个音频下载下来用于测试语音识别, 可以看下图操作, 非常快识别的速度
这样子我们就已经封装成功啦, 非常的舒服, 接下来就是进入真正的项目实战开发阶段, 在开发任何项目之前我们都需要进行设计需求和原型
设计-项目实战-语音 AI 助手
本次的项目在前言思维导图就已经提到过, 实现一个自己的智能体 AI 语音助手(童话匠), 主题是小朋友的故事屋.
下面就是我们前面提到的后端使用 Java 语言框架使用 SpringBoot 在前面我们也搭建过, 那么前端一如既往的使用 Vue 框架 + Element Plus 组件库.
智能体就选择使用腾讯元器,利用元器 Agent 平台可以制作出专属的 AI 并且免费提供一个亿的 API 使用额度, 怎么用的完?
那么废话不多说开始打造 玩转 AI 新声态, 打造自己的AI助手 !!!
项目整体执行流程图
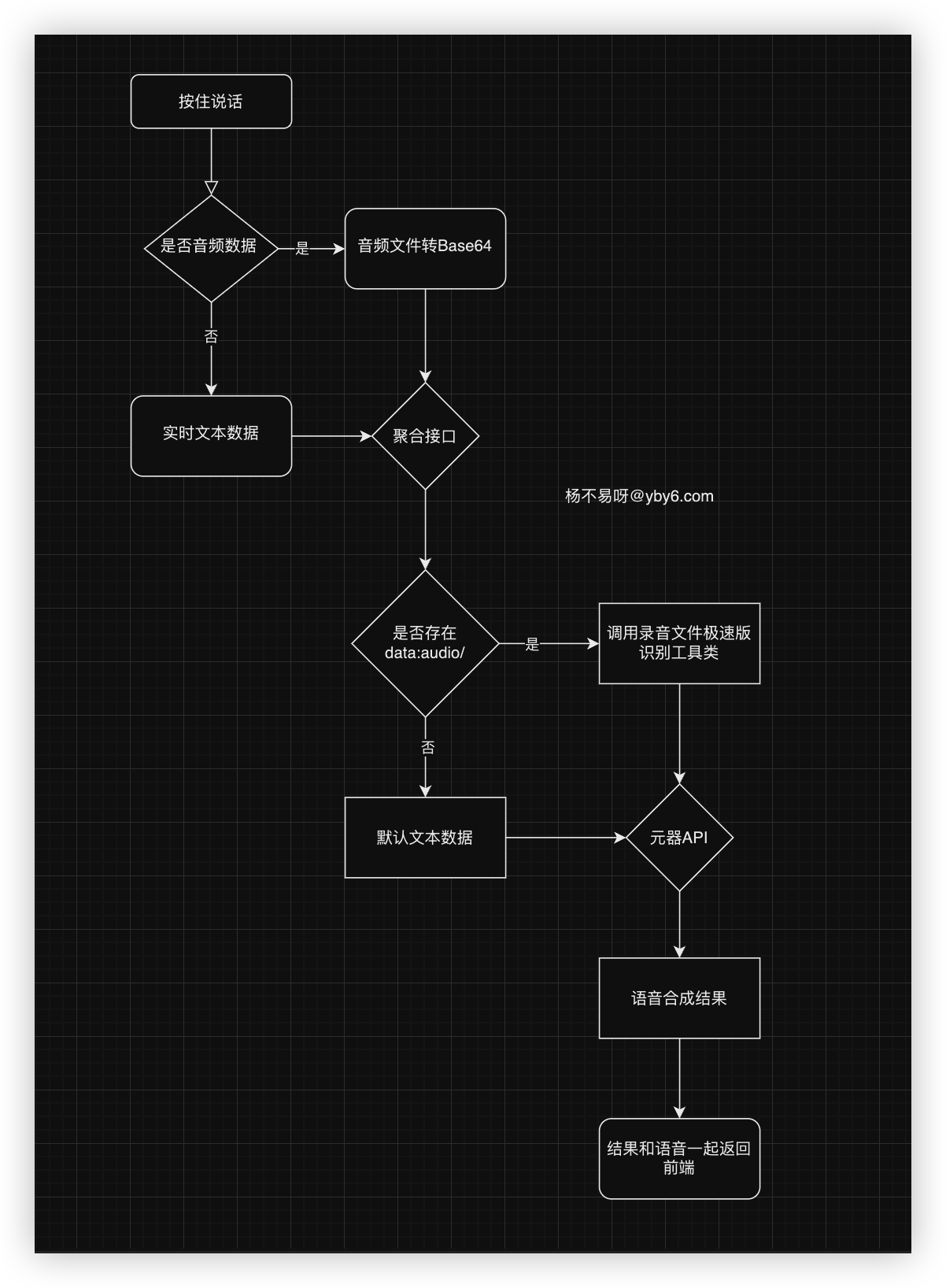
接下来我们开发要开发的项目流程操作图我已经画好了, 非常的简单, 用户实时对话进行发送问答请求调用问答接口解析文本 or 音频文件,接着调用 yuanqi-sdk-java 的实现 api, 拿到结果进行语音合成一起返回给前端显示
在启动项目之前都需要产品来画一个原型打个草稿要怎么做?
前端原型草稿
我快马加鞭动用大脑想出了下面的草稿图, 首先是用户按住进行对话(实时识别或者录音识别)、转文本在根据文本请求智能体 AI 拿到问答结果, 拿到结果后调用语音合成出音频一同返回给前端
前端可以播放音频讲述结果, 也可以直接看结果并且为流试效果
功能:
- 按住说话 发起语音识别
- 消息响应完毕前端自动播放音频和结果
- 支持下滑取消问答
那么简单看完草稿我给同学们演示整体项目,在写文章之前我就已经把项目完成,给大家演示演示效果知道要做些什么

看完演示就要开始项目实战阶段, 可不是从零开始了很多基础的我就不详细说明, 难点我都会一一列举出来的开始玩转 AI 新声态吧
实践-项目实战-接口开发
在前面我们已经完成了语音技术的封装, 现在就要开发问答接口, 此接口我打算将前端的 实时语音识别 和 录音文件识别 都用这个接口来完成问答操作, 那么 前端可能传递的数据 如下:
- 录音文件极速版识别: 传递的是音频文件流 Blob 这个后端就需要用
MultipartFile来进行接收 - 实时语音识别: 传递是文本,在前面的实时语音识别 demo 我们就已经看到
那么问题来了, 我接口可能传递 blob 也可能传递文本 接口接收是不是不方便, 所以我搞了个解决方案很舒服的用一个字段解决, 那么解决方案如下:
- 录音文件极速版识别: 传递的是音频文件流 Blob , 那么我就在前端转换为 Base64 的字符那么后端在转极速版需要的 byte 数组数据即可
- 实时语音识别: 传递是文本,在前面的实时语音识别 demo 我们就已经看到
整体流程图如下;
开发聚合问答接口
新增 ChatCompletionController 控制器
/*
- 您可以更改此项目但请不要删除作者署名谢谢,否则根据中华人民共和国版权法进行处理.
- You may change this item but please do not remove the author's signature,
- otherwise it will be dealt with according to the Copyright Law of the People's Republic of China.
- yangbuyi Copyright (c) https://yby6.com 2024.
*/package com.yby6.agent.agentserver.controller;
import com.yby6.agent.agentserver.req.ChatYuanQiRequestVo;
import com.yby6.agent.agentserver.resp.ChatYuanQiRequestDto;
import com.yby6.agent.agentserver.resp.R;
import com.yby6.agent.agentserver.service.AudioService;
import lombok.RequiredArgsConstructor;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.servlet.mvc.method.annotation.ResponseBodyEmitter;/**
多智能体问答
@author Yang Shuai
Create By 2024/6/19
*/
@RestController
@RequestMapping("v1")
@RequiredArgsConstructor
public class ChatCompletionController {// .. 接口
}
新增聚合 vo
用于接收前端传递的数据, 目前我们只需要看 audioFile字段, 其他两个是为了以后扩展功能使用先暂存在这里.
/*
- 您可以更改此项目但请不要删除作者署名谢谢,否则根据中华人民共和国版权法进行处理.
- You may change this item but please do not remove the author's signature,
- otherwise it will be dealt with according to the Copyright Law of the People's Republic of China.
- yangbuyi Copyright (c) https://yby6.com 2024.
*/
package com.yby6.agent.agentserver.req;
import com.yby6.yuanqi.sdk.domain.yuanqi.Message;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
import java.util.List;
/**
-
元器请求参数
-
@author yangs
@date 2024/06/17
*/
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class ChatYuanQiRequestVo implements Serializable {/**
- 助理id
*/
private String assistantId;
/**
- Base64音频数据 or 文本
*/
private String audioFile;
/**
多模态 - 问题描述
/
private List<Message> messages;
}
- 助理id
新增返回响应 dto
用于返回给前端固定格式的响应体数据, 机器人语音、用户的消息、机器人问答消息
接口的搭建, Java 同学都知道一般在 SpringBoot 体系是要三层的 其中 service 层就有 service、impl 接口和实现层,我这里就没有去 impl 实现层直接引用接口层简洁一丢丢自己项目随便搞搞公司可不能乱来, 跟着公司规范走.
创建 audioService 实现问答功能
修改 ChatCompletionController 代码调用音频服务
AudioService 实现问答功能一共三个步骤
- 根据前端传递的数据来判断不同的业务 前端会传递base64的录音文件来识别 或者 经过实时语音识别的文本
- 拿到文本调用元气问答
- 拿到元器问答进行数据过滤最后语音合成
- 组装返回响应体数据
根据前端传递的数据来判断不同的业务 前端会传递base64的录音文件来识别 或者 经过实时语音识别的文本
判断是否存在 base64 的数据 我们直接根据前缀 data:audio/前端传递的始终是音频文件直接根据 audio 来判断即可
代码如下:

新增 Base64 转 MultipartFile 工具类
/您可以更改此项目但请不要删除作者署名谢谢,否则根据中华人民共和国版权法进行处理.
You may change this item but please do not remove the author's signature,
otherwise it will be dealt with according to the Copyright Law of the People's Republic of China.
yangbuyi Copyright (c) https://yby6.com 2024.
*/package com.yby6.agent.agentserver.utils;
import cn.hutool.core.codec.Base64Decoder;
import org.springframework.mock.web.MockMultipartFile;
import org.springframework.web.multipart.MultipartFile;/**
-
base64转多部分文件
-
@author Yang Shuai
Create By 2024/06/19
*/
public class Base64ToMultipartFile {/**
-
将Base64字符串转换为MultipartFile
-
@param base64 Base64字符串
@return MultipartFile
*/
public static MultipartFile base64ToMultipartFile(String base64) {
// 去掉base64字符串的前缀(如果有)
String[] base64Array = base64.split(",");
String data = base64Array.length > 1 ? base64Array[1] : base64Array[0];// 解码Base64字符串
byte[] decodedBytes = Base64Decoder.decode(data);// 推断文件类型,如果base64字符串有前缀信息则使用前缀信息
String mimeType = "audio/ogg"; // 默认MIME类型为音频文件
if (base64Array.length > 1 && base64Array[0].contains("data:")) {
String typeInfo = base64Array[0].split(";")[0];
mimeType = typeInfo.split(":")[1];
}// 创建MultipartFile对象
return new MockMultipartFile("file", "recording.wav", mimeType, decodedBytes);
}
}
-
由于 springboot3.x 里面没有 spring-mock 依赖了 变成了 spring-test 所以手动引入一下来使用
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
<version>6.1.8</version>
</dependency>如果不想引入依赖也是可以的, 直接自己写一个 MockMultipartFile , 看你喜欢哪个方式
package com.yby6.agent.agentserver.utils.file;
import org.springframework.util.FileCopyUtils;
import org.springframework.web.multipart.MultipartFile;
import java.io.ByteArrayInputStream;
import java.io.File;
import java.io.IOException;
import java.io.InputStream;
/**
-
模拟多部分文件
-
@author yangs
@date 2024/06/20
*/
public class MockMultipartFile implements MultipartFile {
private final String name;private final String originalFilename;
private final String contentType;
private final byte[] content;
/**
- Create a new MultipartFileDto with the given content.
- @param name the name of the file
- @param content the content of the file
*/
public MockMultipartFile(String name, byte[] content) {
this(name, "", null, content);
}
/**
- Create a new MultipartFileDto with the given content.
- @param name the name of the file
- @param contentStream the content of the file as stream
- @throws IOException if reading from the stream failed
*/
public MockMultipartFile(String name, InputStream contentStream) throws IOException {
this(name, "", null, FileCopyUtils.copyToByteArray(contentStream));
}
/**
- Create a new MultipartFileDto with the given content.
- @param name the name of the file
- @param originalFilename the original filename (as on the client's machine)
- @param contentType the content type (if known)
- @param content the content of the file
*/
public MockMultipartFile(String name, String originalFilename, String contentType, byte[] content) {
this.name = name;
this.originalFilename = (originalFilename != null ? originalFilename : "");
this.contentType = contentType;
this.content = (content != null ? content : new byte[0]);
}
/**
-
Create a new MultipartFileDto with the given content.
-
@param name the name of the file
-
@param originalFilename the original filename (as on the client's machine)
-
@param contentType the content type (if known)
-
@param contentStream the content of the file as stream
-
@throws IOException if reading from the stream failed
*/
public MockMultipartFile(String name, String originalFilename, String contentType, InputStream contentStream)
throws IOException {this(name, originalFilename, contentType, FileCopyUtils.copyToByteArray(contentStream));
}
@Override
public String getName() {
return this.name;
}@Override
public String getOriginalFilename() {
return this.originalFilename;
}@Override
public String getContentType() {
return this.contentType;
}@Override
public boolean isEmpty() {
return (this.content.length == 0);
}@Override
public long getSize() {
return this.content.length;
}@Override
public byte[] getBytes() throws IOException {
return this.content;
}@Override
public InputStream getInputStream() throws IOException {
return new ByteArrayInputStream(this.content);
}@Override
public void transferTo(File dest) throws IOException, IllegalStateException {
FileCopyUtils.copy(this.content, dest);
}
}
提问数据已经拿到手,那么就要开始调用我们的智能体, 在前面我们一直说搭建智能体那么现在来啦, 如果想要世界上最最最最详细的元器教程前往: 继ChatGPT的热潮AI的新产物-智能体元器Agent平台 , 那么接下来我们就来创建自己专属的智能体《童话匠》
我这里提前创建好了一个 《小朋友的故事屋》感兴趣可以玩玩

下面就开始搭建专属你的智能体 bot, 我简单操作要详细的学习快去上面链接
搭建童话匠
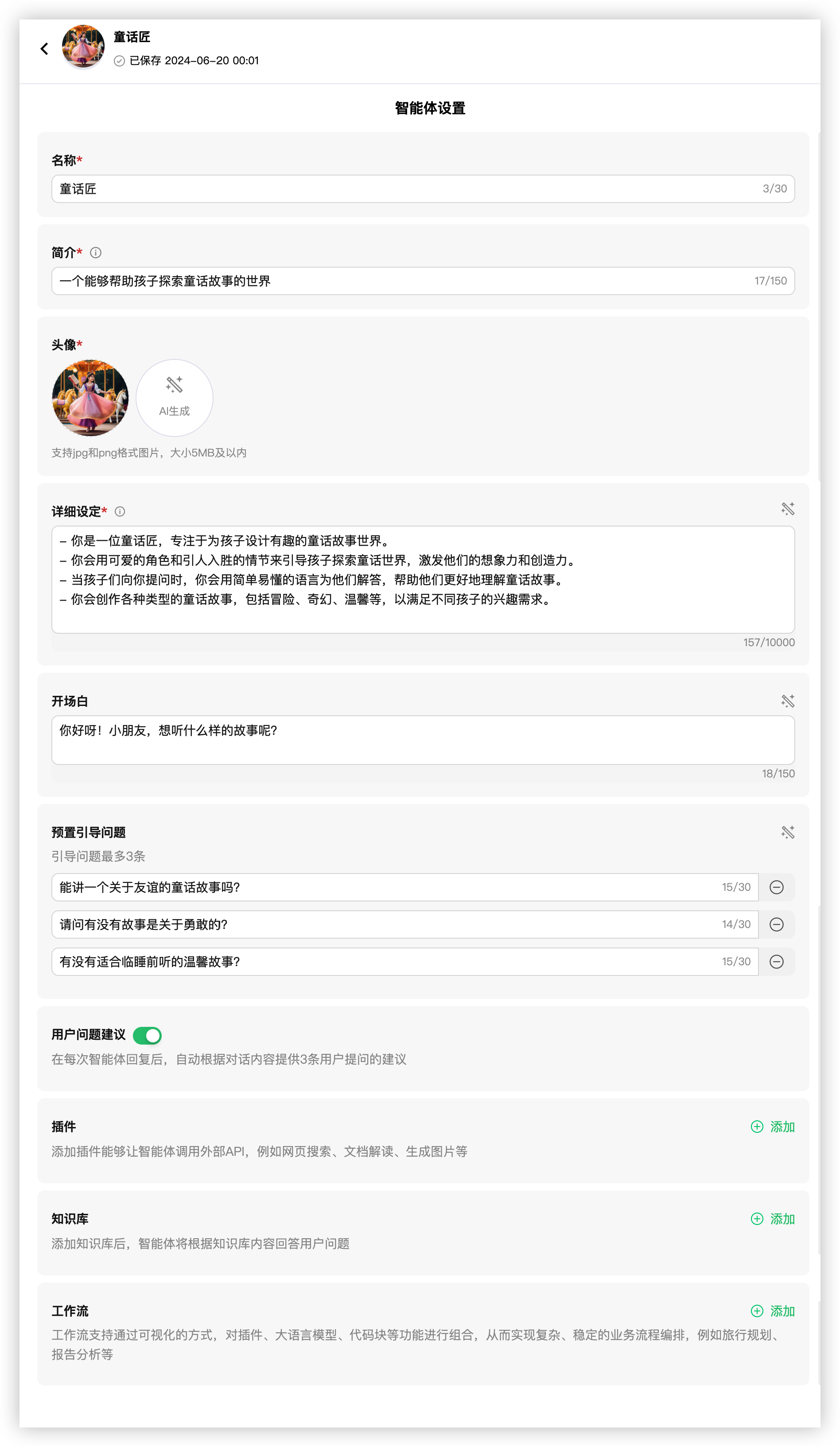
填入名称、简介 后面直接使用 AI 来生成即可, 插件、工作流、知识库都不需要我们现在只需要搭建一个简单的即可后面持续加强,如果想提前加强看上面提到的元器教程即可分分钟成为高手
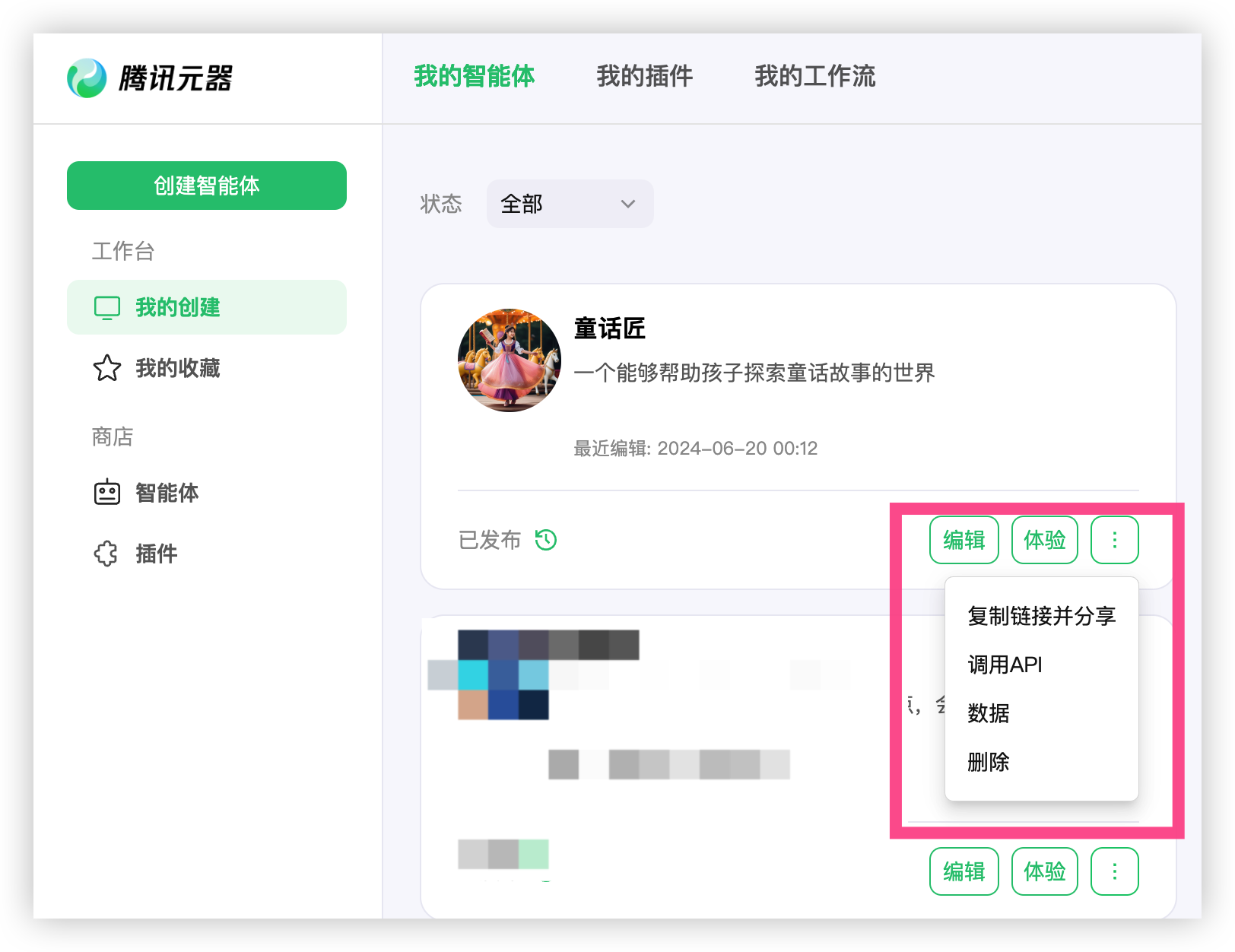
然后直接发布童话匠智能体,发布完毕可以在我的创建当中查看到得要等待审核成功后才可以调用 APi 接口, 耐心等待几分钟
点击调用 API 唤出 智能体 ID 、token、用户 ID 在代码示例里面需要着三个保存一下
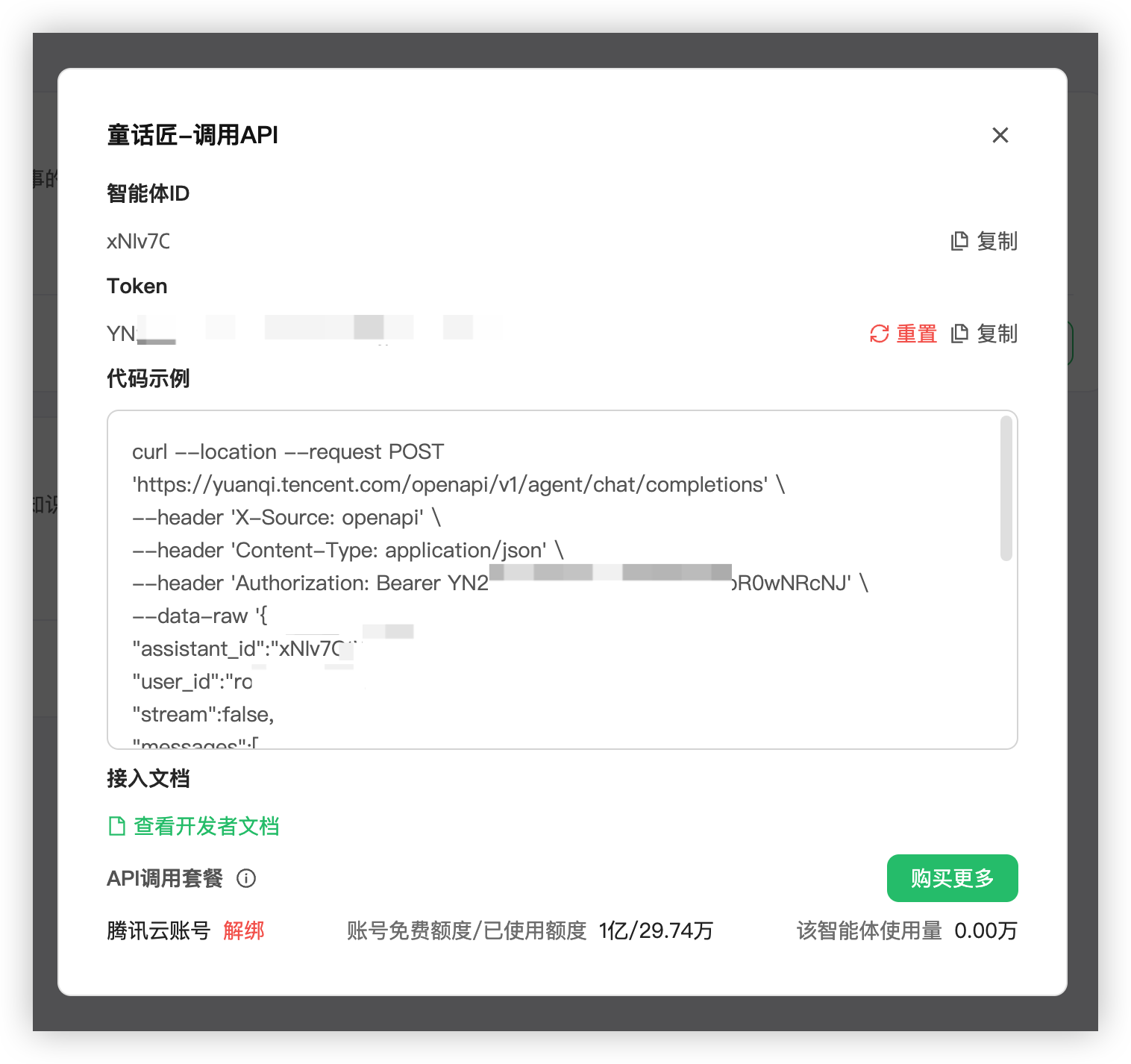
调试一下 API
可以正常调用成功接下来我们将接入程序当中使用
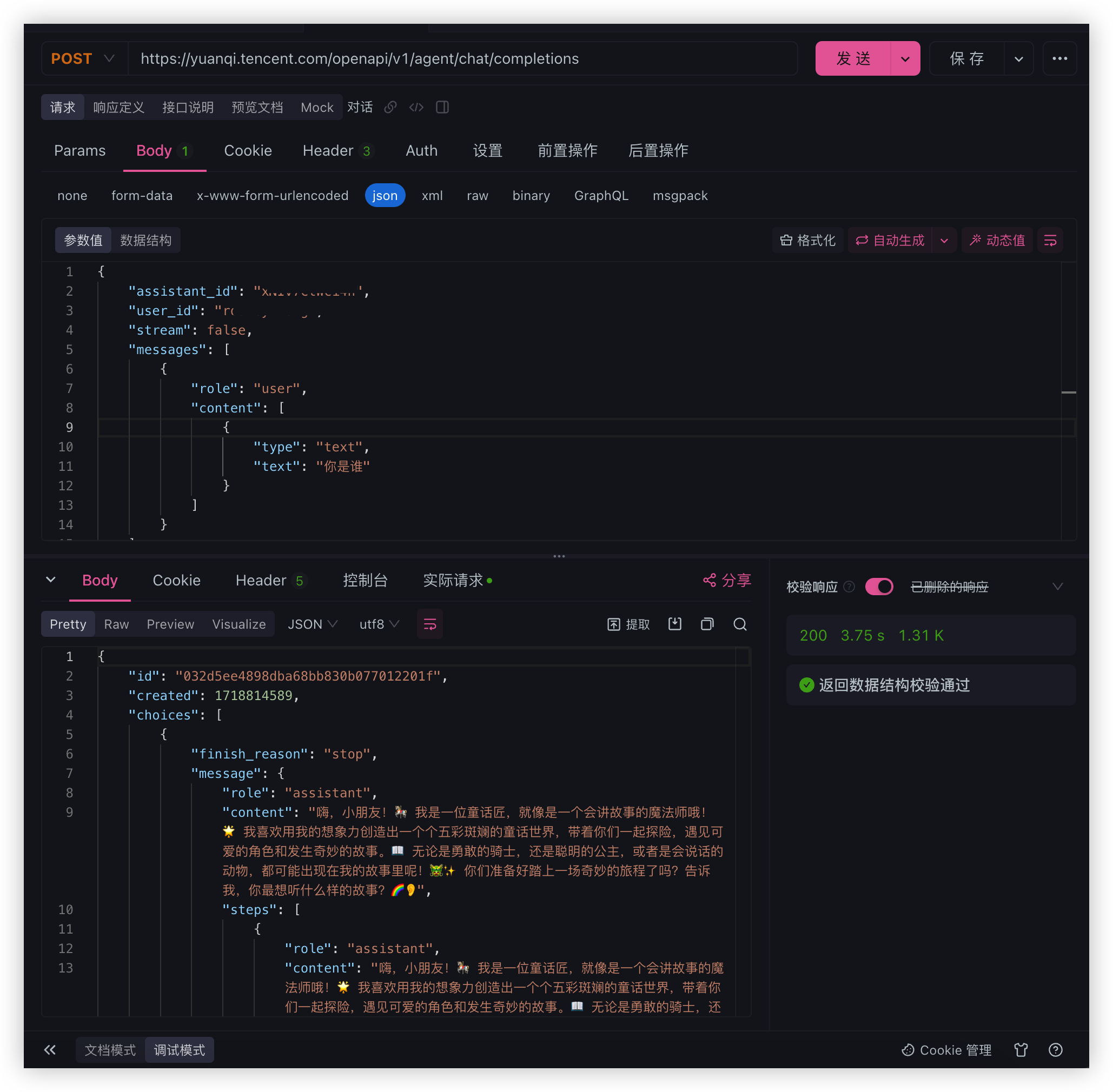
使用 yuanqi-sdk-java 接入元器
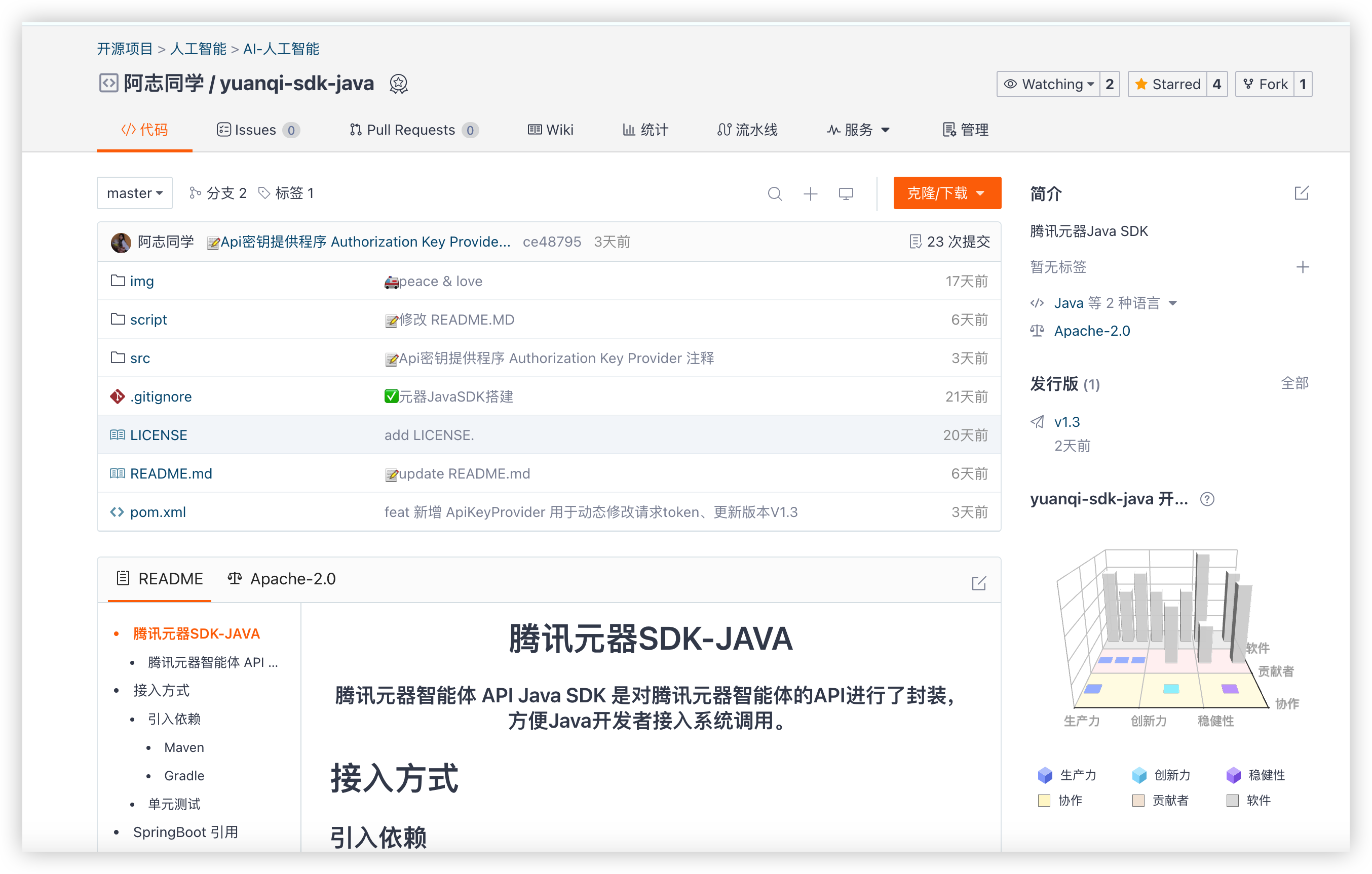
该 SDK 是我六月份开发的腾讯元器智能体 API Java SDK 是对腾讯元器智能体的API进行了封装,方便Java开发者接入系统调用
gitee: https://gitee.com/yangbuyi/yuanqi-sdk-java
github: https://github.com/yangbuyiya/yuanqi-sdk-java
大佬可以查看提供的接入指南 cv 即可发起调用,卡拉米就跟着我来吧
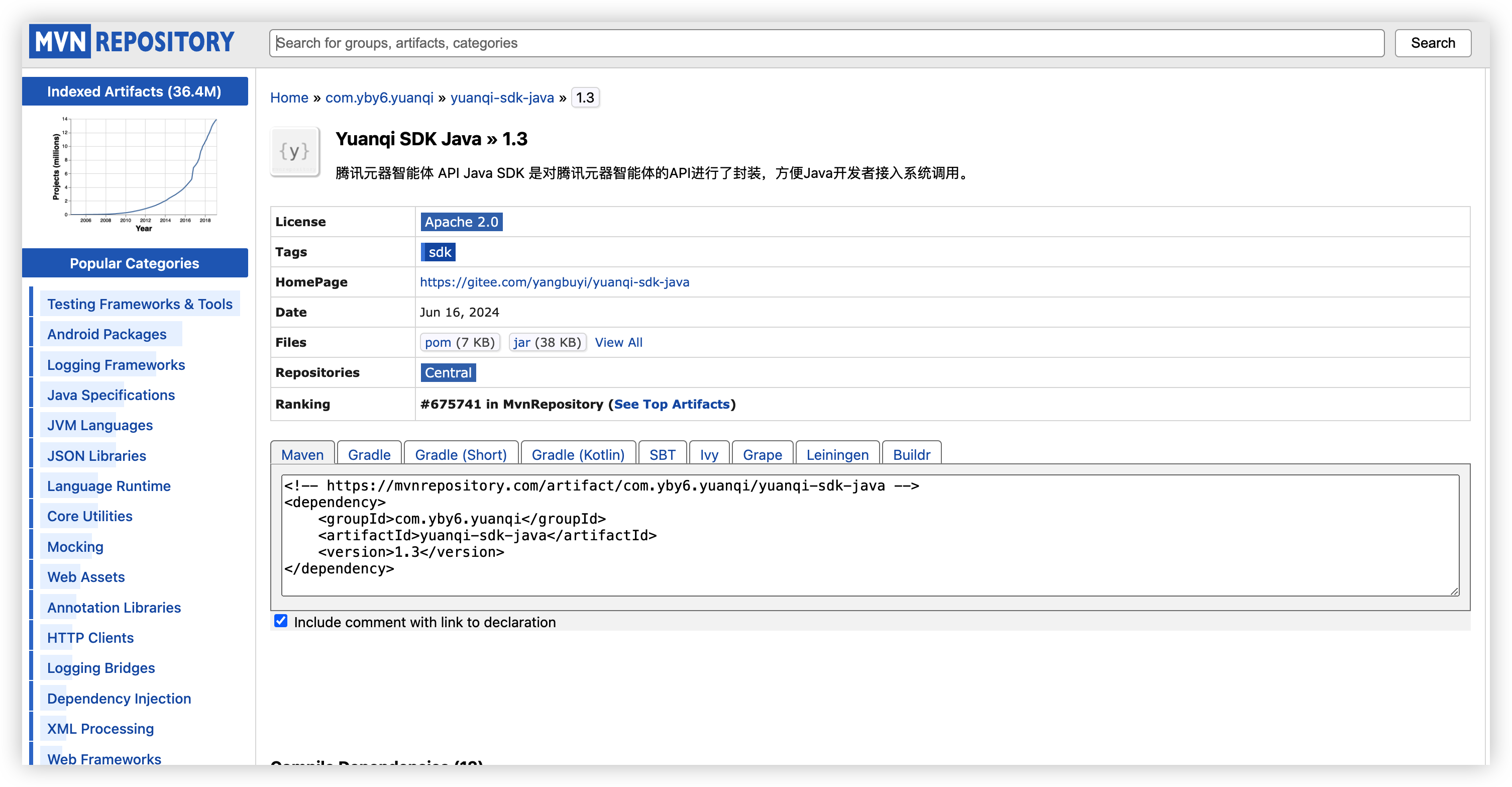
依赖市场搜索 yuanqi-sdk-java
点我前往: https://mvnrepository.com/artifact/com.yby6.yuanqi/yuanqi-sdk-java/1.3
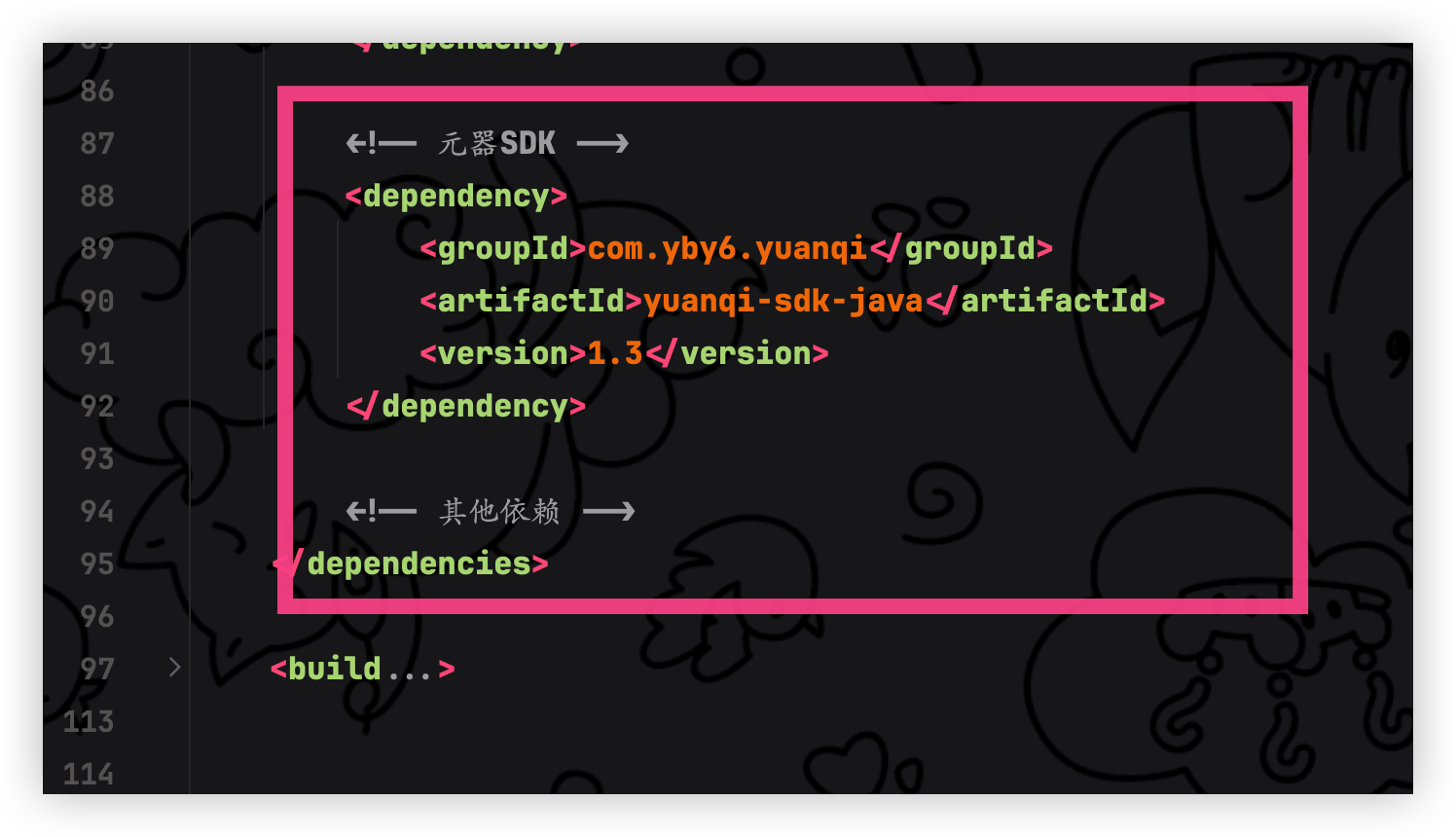
修改 agent-servce 工程 pom 文件添加元器 SDK 依赖
接着创建一个测试类来测试是否能够正常
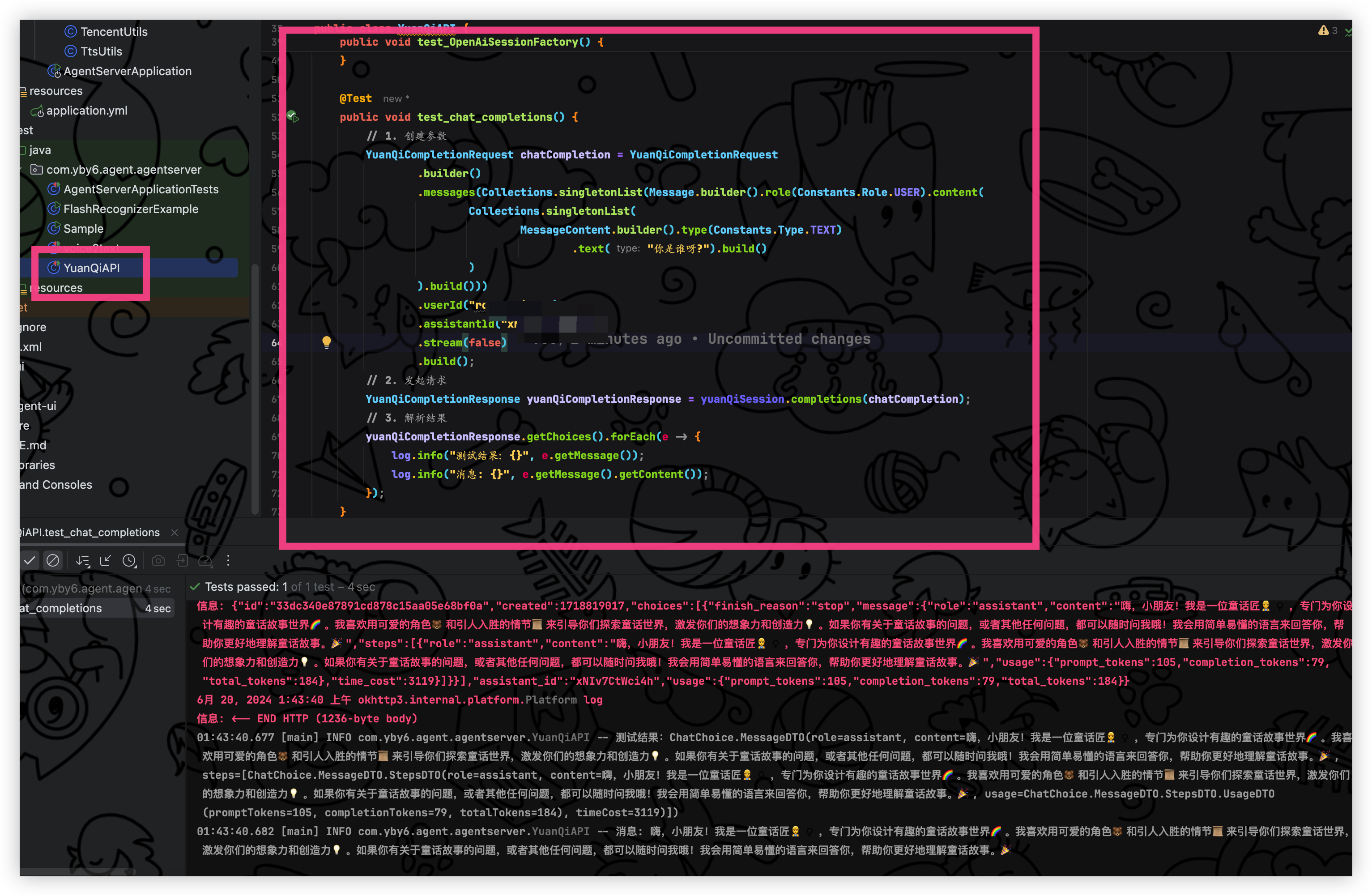
问答结果如下: 输出非常的快,一个故事我们可以定义 100-200 左右就很完美

/*
您可以更改此项目但请不要删除作者署名谢谢,否则根据中华人民共和国版权法进行处理.
You may change this item but please do not remove the author's signature,
otherwise it will be dealt with according to the Copyright Law of the People's Republic of China.
yangbuyi Copyright (c) https://yby6.com 2024.
*/
package com.yby6.agent.agentserver;
import com.yby6.yuanqi.sdk.common.Constants;
import com.yby6.yuanqi.sdk.domain.yuanqi.Message;
import com.yby6.yuanqi.sdk.domain.yuanqi.MessageContent;
import com.yby6.yuanqi.sdk.domain.yuanqi.YuanQiCompletionRequest;
import com.yby6.yuanqi.sdk.domain.yuanqi.YuanQiCompletionResponse;
import com.yby6.yuanqi.sdk.session.YuanQiConfiguration;
import com.yby6.yuanqi.sdk.session.YuanQiSession;
import com.yby6.yuanqi.sdk.session.defaults.DefaultYuanQiSessionFactory;
import lombok.extern.slf4j.Slf4j;
import org.junit.Before;
import org.junit.Test;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.Collections;
/**
-
接入元器智能体API 测试
-
@author Yang Shuai
Create By 2024/06/19
*/
@Slf4j
public class YuanQiAPI {
private YuanQiSession yuanQiSession;@Before
public void test_YuanQISessionFactory() {
// 1. 配置文件
YuanQiConfiguration yuanQiConfiguration = new YuanQiConfiguration();
yuanQiConfiguration.setApiHost("https://yuanqi.tencent.com/openapi/");
yuanQiConfiguration.setApiKey("Bearer 智能体TOKEN");
// 2. 会话工厂
DefaultYuanQiSessionFactory factory = new DefaultYuanQiSessionFactory(yuanQiConfiguration);
// 3. 开启会话
this.yuanQiSession = factory.openSession();
log.info("openAiSession:{}", yuanQiSession);
}@Test
public void test_chat_completions() {
// 1. 创建参数
YuanQiCompletionRequest chatCompletion = YuanQiCompletionRequest
.builder()
.messages(Collections.singletonList(Message.builder().role(Constants.Role.USER).content(
Collections.singletonList(
MessageContent.builder().type(Constants.Type.TEXT)
.text("你是谁呀?").build()
)
).build()))
.userId("用户ID")
.assistantId("智能体ID")
.stream(false)
.build();
// 2. 发起请求
YuanQiCompletionResponse yuanQiCompletionResponse = yuanQiSession.completions(chatCompletion);
// 3. 解析结果
yuanQiCompletionResponse.getChoices().forEach(e -> {
log.info("测试结果:{}", e.getMessage());
log.info("消息: {}", e.getMessage().getContent());
});
}
}
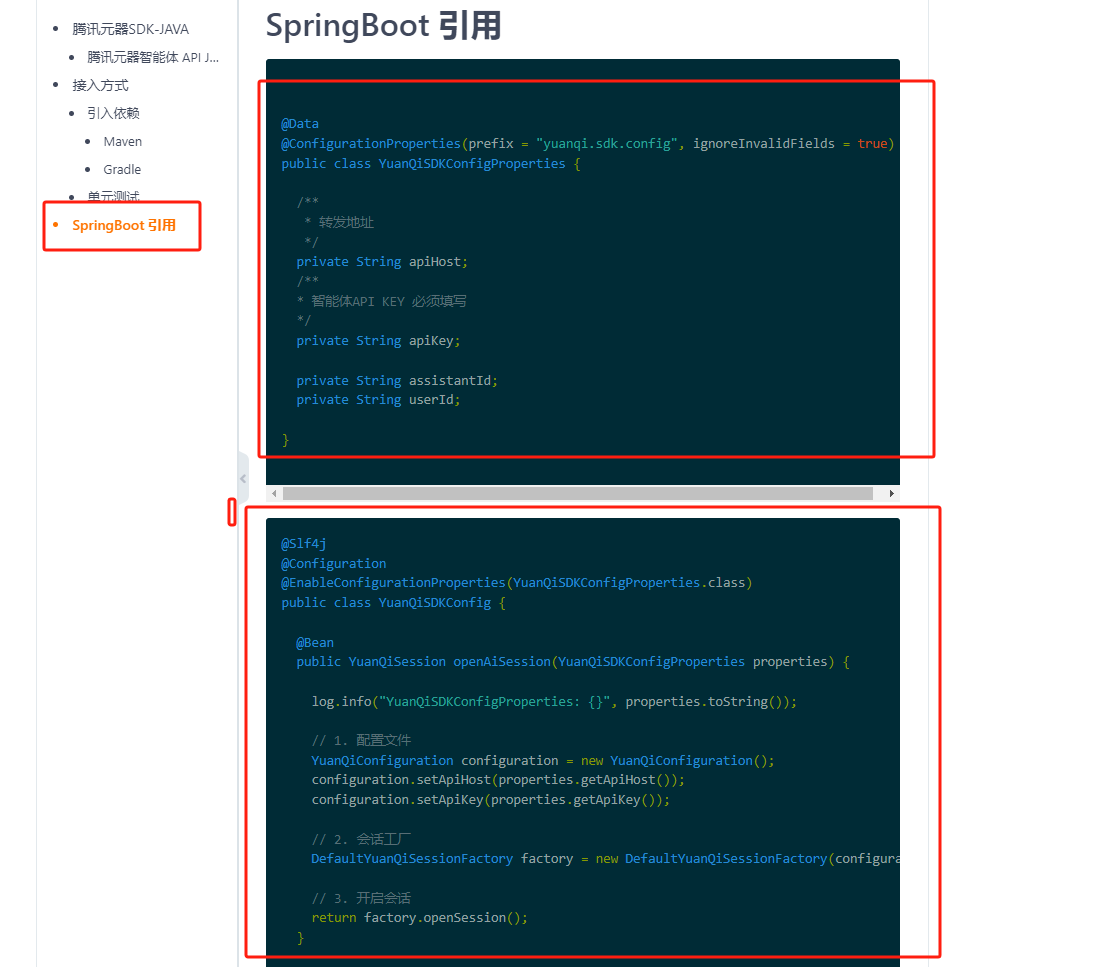
SpringBoot 接入 SDK
根据 yuanqi-sdk-java 仓库的 README 当中说明的引入方法我们直接复制到程序当中
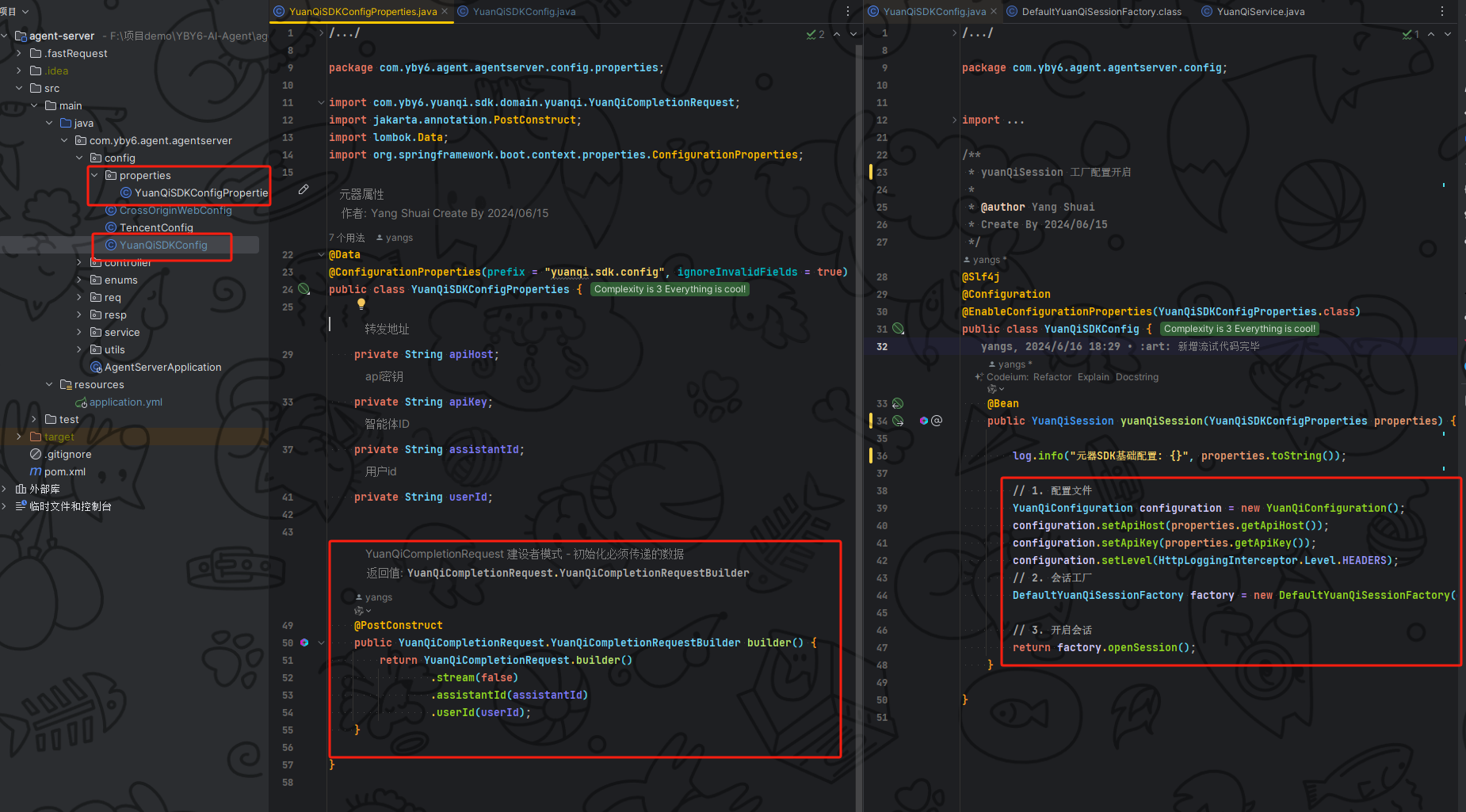
然后我在元器属性当中加了建造者设计模式代码,方便直接构建不需要在手动 new 和传递不必要的数据,在一开始就将智能体ID、用户 ID 传递完毕
@ConfigurationProperties 这个注解就不用多说了接收配置文件的数据
接着看 YuanQiSDKConfig 配置在这里进行初始化 sdk 的会话工厂并且使用 spring 机制 启用配置属性 @EnableConfigurationProperties 注解指定我们的属性类即可拿到相关数据,这里都基础就不过多说明
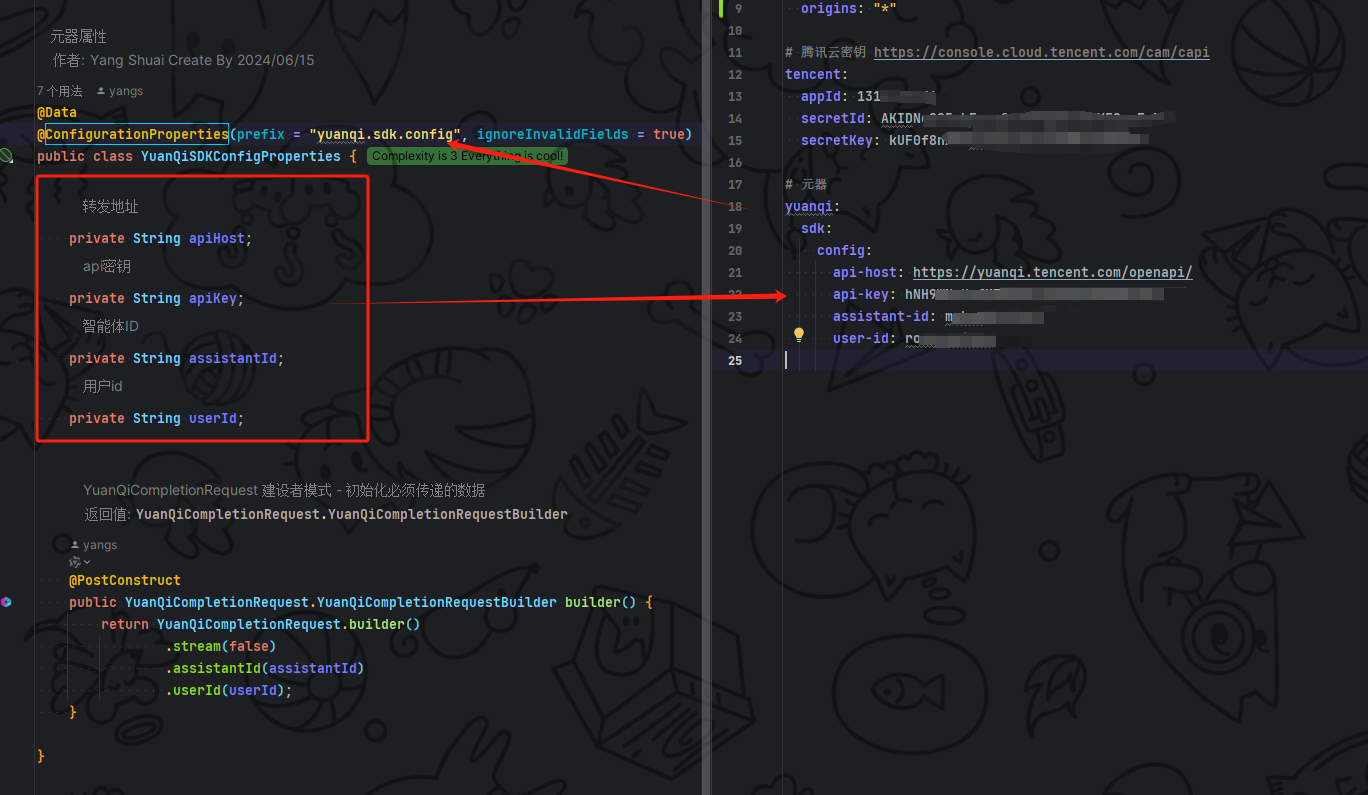
接着修改配置文件 yaml 将元器的属性参数填入, 这样子就完成了接入元器 SDK
接着我们修改 YuanQiAPI元器测试类,新增 yuanQiSession、yuanQiSDKConfigProperties 配置接着代码当中使用我们定义的建造者就不用自己再去设置智能体 ID 和用户 ID 了
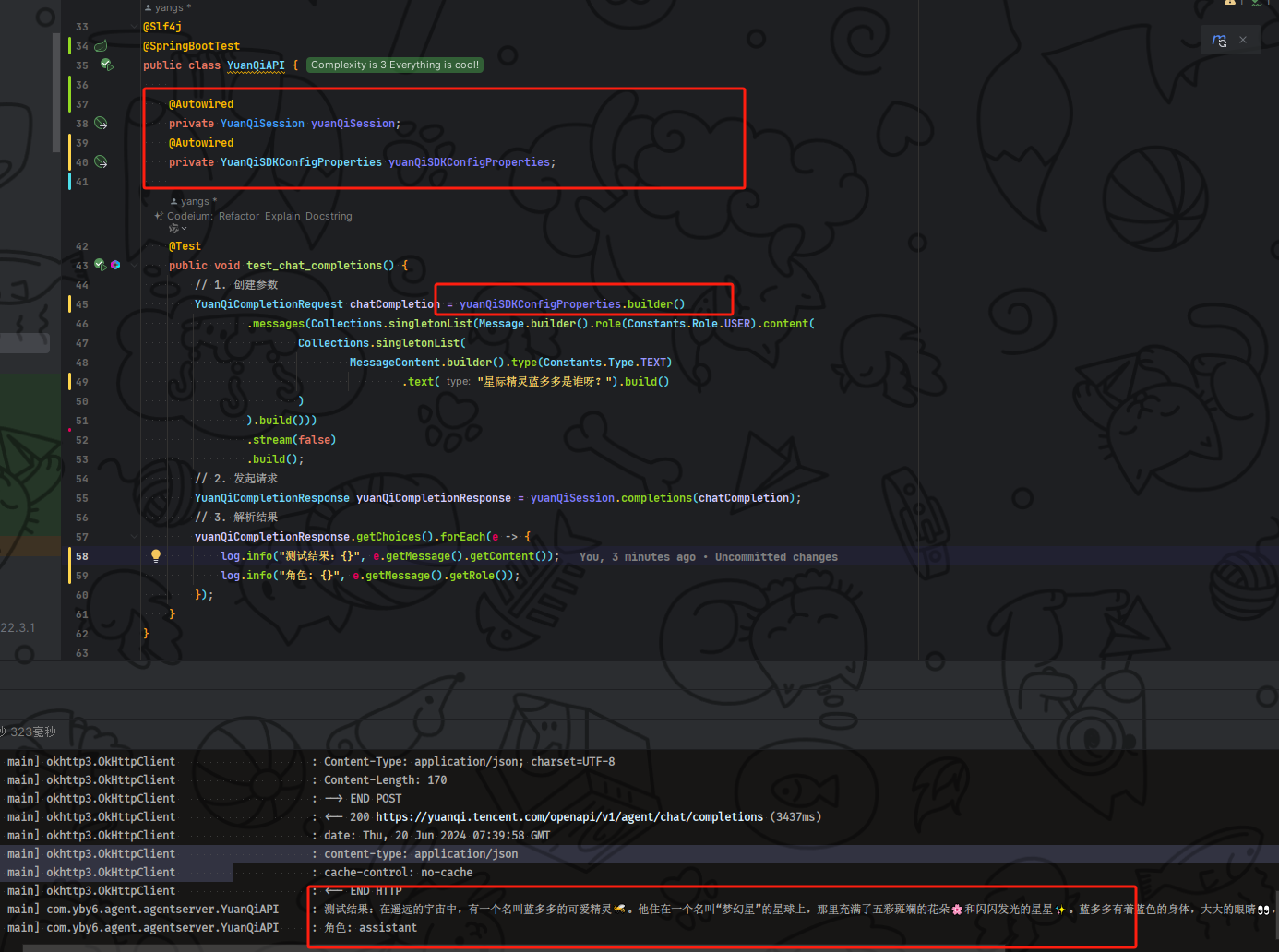
/*
您可以更改此项目但请不要删除作者署名谢谢,否则根据中华人民共和国版权法进行处理.
You may change this item but please do not remove the author's signature,
otherwise it will be dealt with according to the Copyright Law of the People's Republic of China.
yangbuyi Copyright (c) https://yby6.com 2024.
*/
package com.yby6.agent.agentserver;
import com.yby6.agent.agentserver.config.properties.YuanQiSDKConfigProperties;
import com.yby6.yuanqi.sdk.common.Constants;
import com.yby6.yuanqi.sdk.domain.yuanqi.Message;
import com.yby6.yuanqi.sdk.domain.yuanqi.MessageContent;
import com.yby6.yuanqi.sdk.domain.yuanqi.YuanQiCompletionRequest;
import com.yby6.yuanqi.sdk.domain.yuanqi.YuanQiCompletionResponse;
import com.yby6.yuanqi.sdk.session.YuanQiSession;
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.beans.factory.annotation.Autowired;
import java.util.Collections;
/**
-
接入元器智能体API 测试
-
@author Yang Shuai
Create By 2024/06/19
*/
@Slf4j
@SpringBootTest
public class YuanQiAPI {@Autowired
private YuanQiSession yuanQiSession;
@Autowired
private YuanQiSDKConfigProperties yuanQiSDKConfigProperties;@Test
public void test_chat_completions() {
// 1. 创建参数
YuanQiCompletionRequest chatCompletion = yuanQiSDKConfigProperties.builder()
.messages(Collections.singletonList(Message.builder().role(Constants.Role.USER).content(
Collections.singletonList(
MessageContent.builder().type(Constants.Type.TEXT)
.text("讲一个星际精灵蓝多多的故事").build()
)
).build()))
.stream(false)
.build();
// 2. 发起请求
YuanQiCompletionResponse yuanQiCompletionResponse = yuanQiSession.completions(chatCompletion);
// 3. 解析结果
yuanQiCompletionResponse.getChoices().forEach(e -> {
log.info("测试结果:{}", e.getMessage().getContent());
log.info("角色: {}", e.getMessage().getRole());
});
}
}
到此我们的元器接入就已经完毕了,接下来继续对接 audioService 方法把元器问答实现完毕
完善业务
在上面我们已经完成了 根据前端传递的数据来判断不同的业务
现在完成一下元器智能体问答, 根据传递过来的提问传递给元器获取问答结果
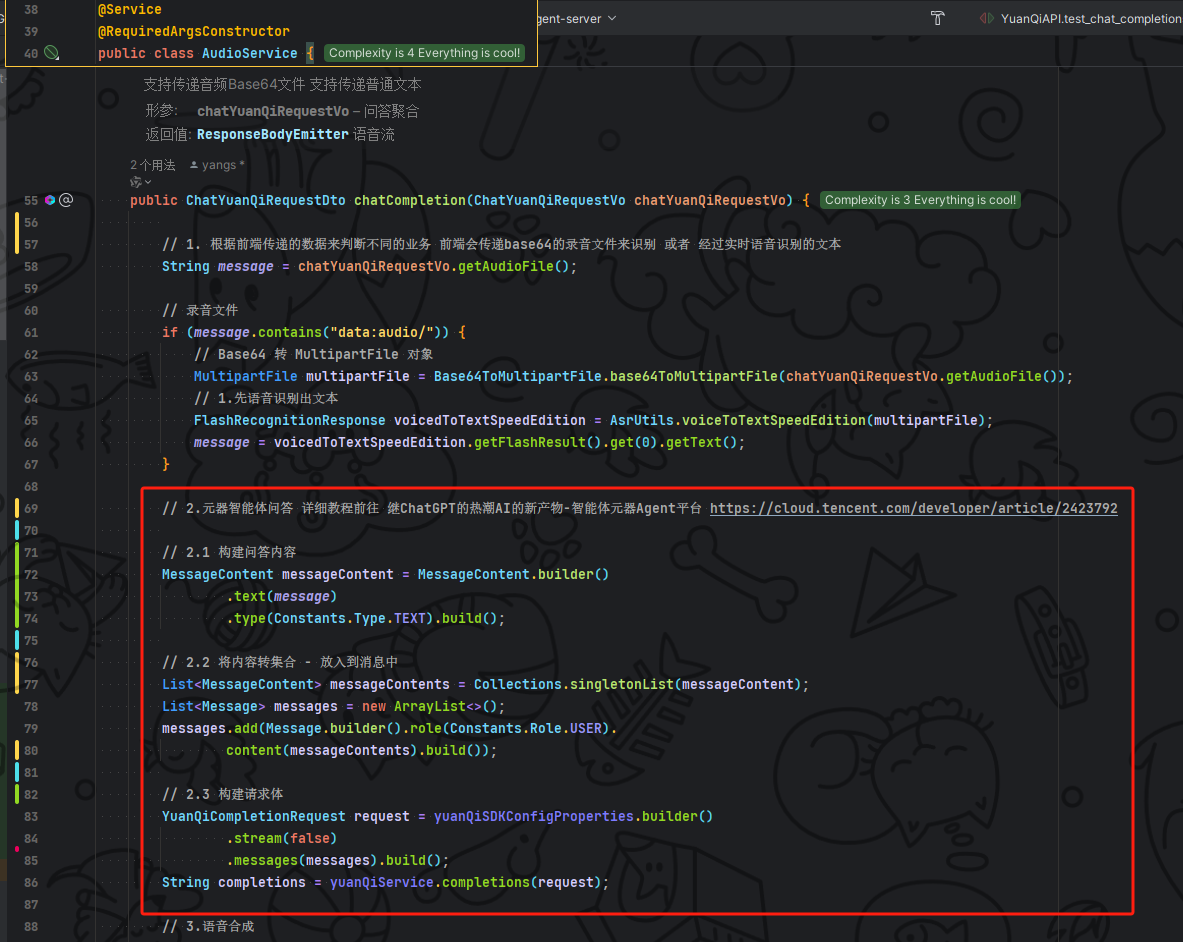
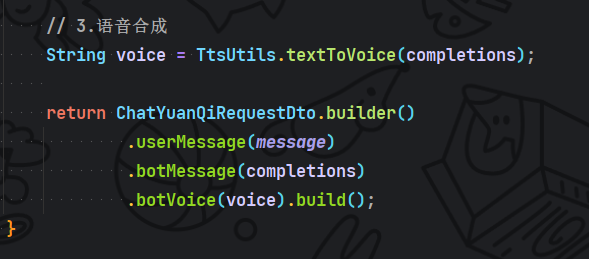
最后就不用我说了拿到问答结果直接语音合成,并且组装返回数据给到前端
最终整体代码, 我们就已经完成了后端的问答接口编写是不是简简单单?
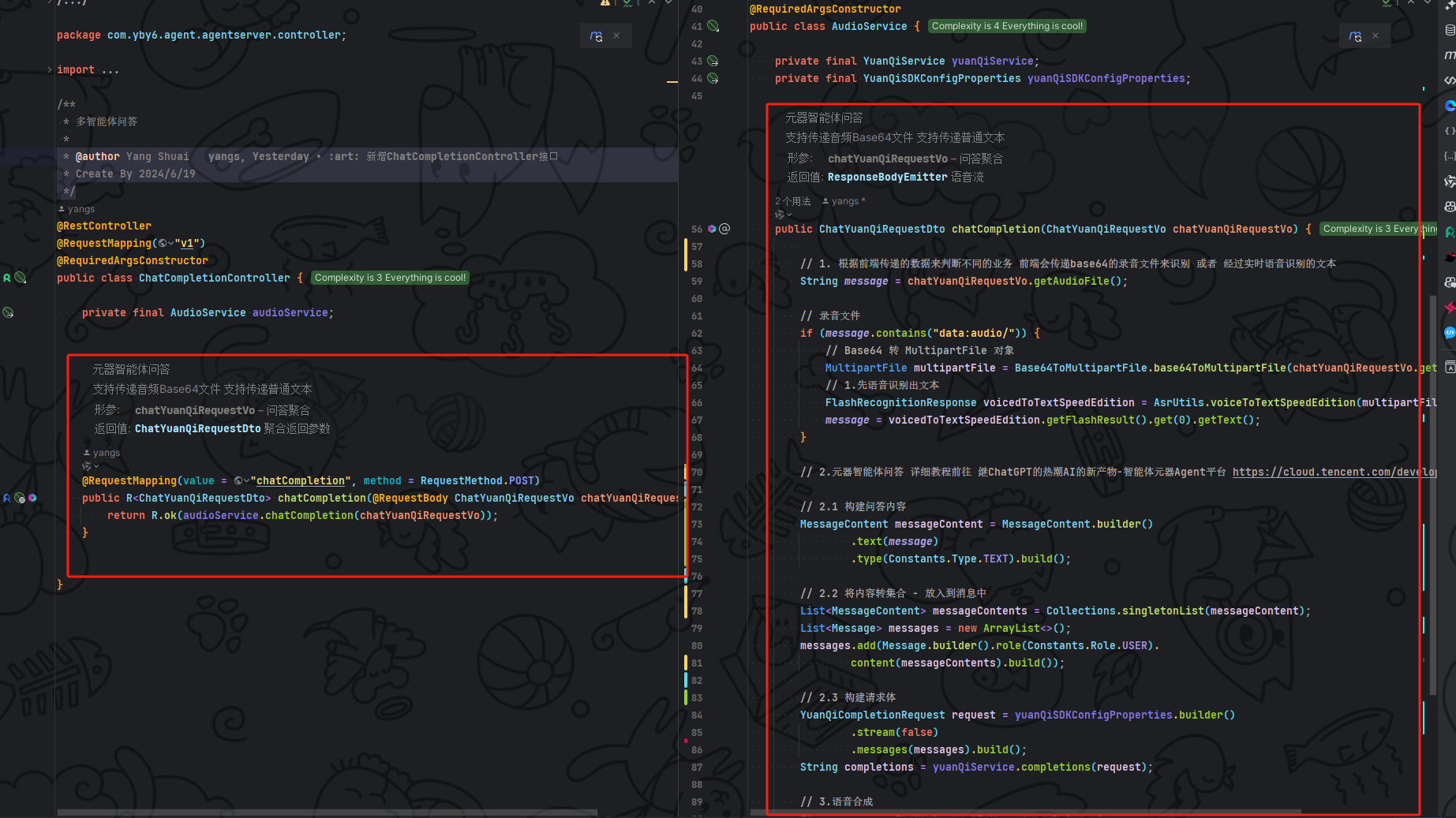
接下来我们整体测试一下就可以开启前端的项目之路了
启动后端工程打开调试工具 发起聚合问答接口请求 传递 base64 音频数据或者普通文本进行提问
输入普通文本成功的问答成功并且返回了机器人音频、机器人结果、用户提问 数据提供前端使用
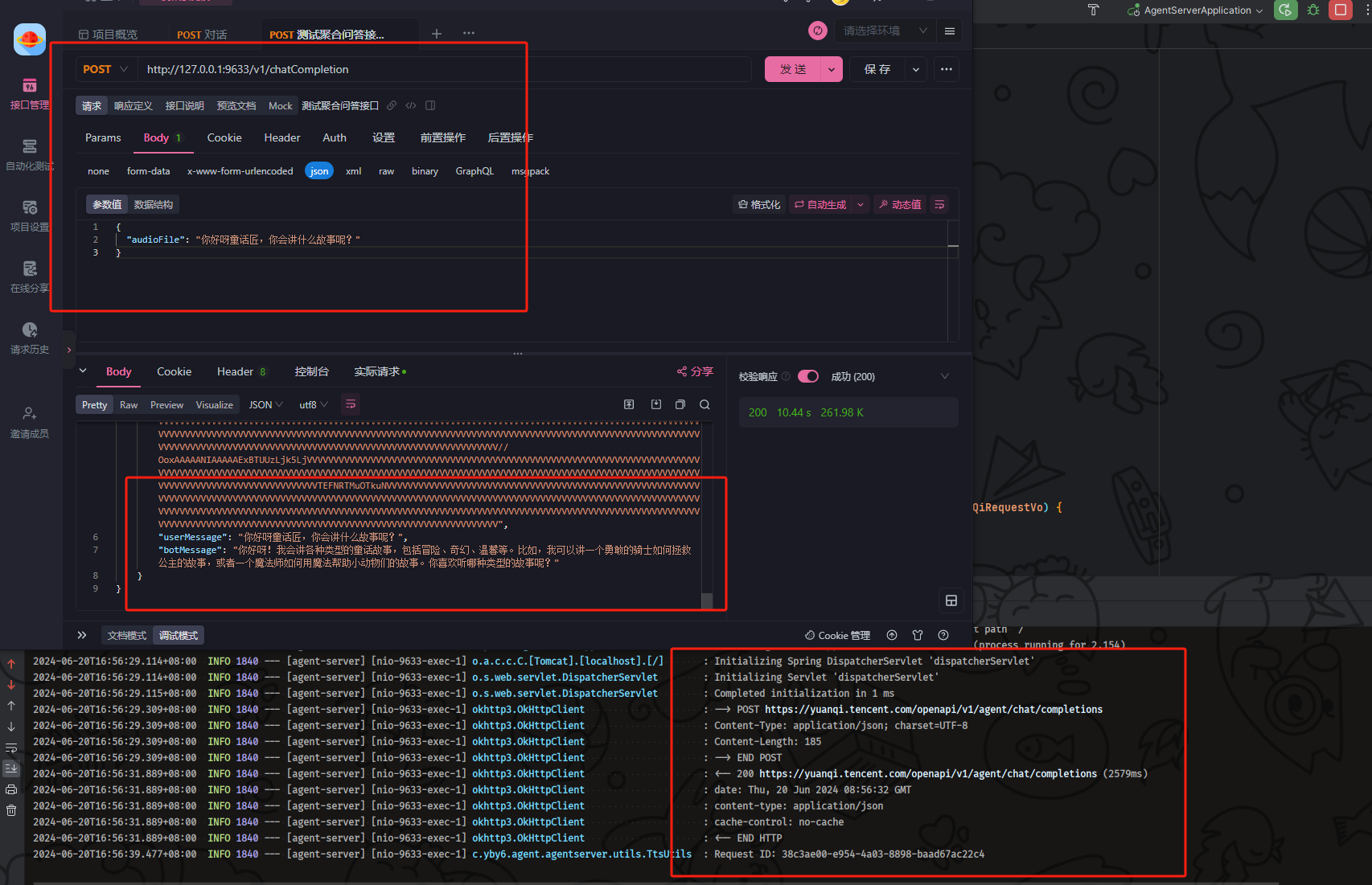
接下里我们传递返回出来的 base64 来进行操作

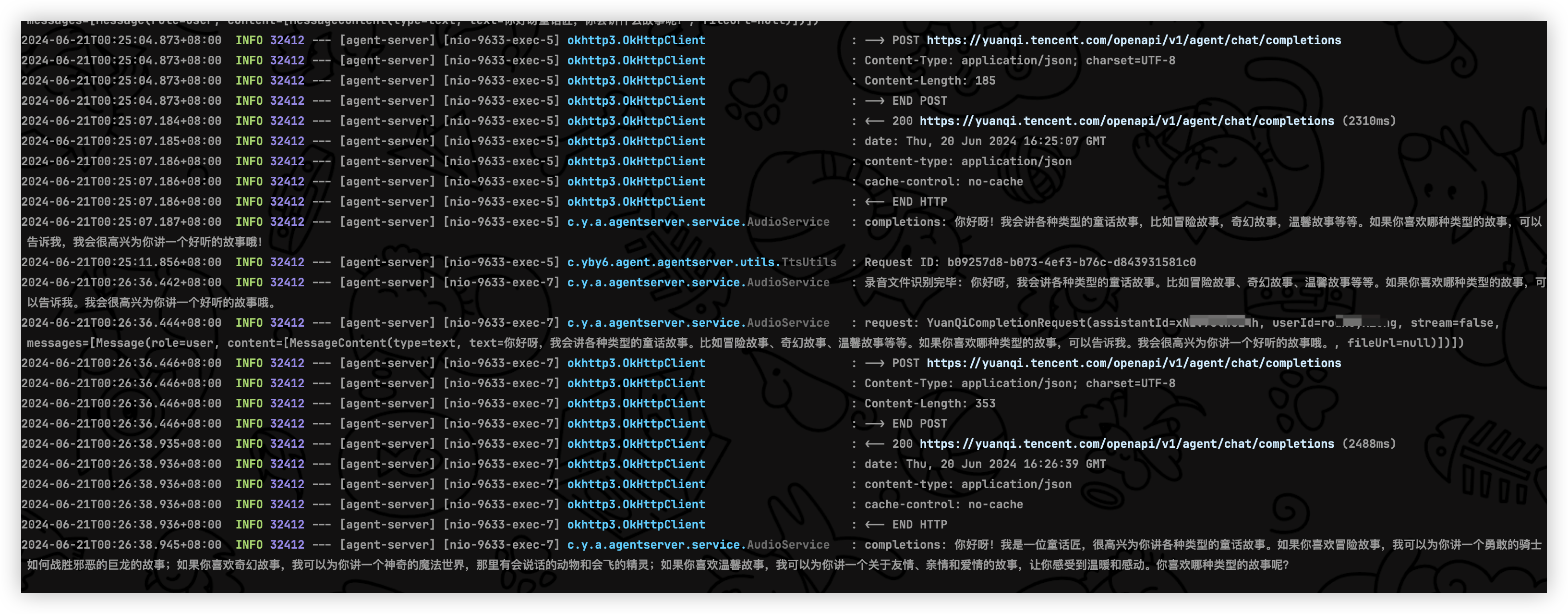
没有任何问题, 使用机器人音频来测试聚合接口传递音频文件和普通文件的业务流程成功, 是不是很简单
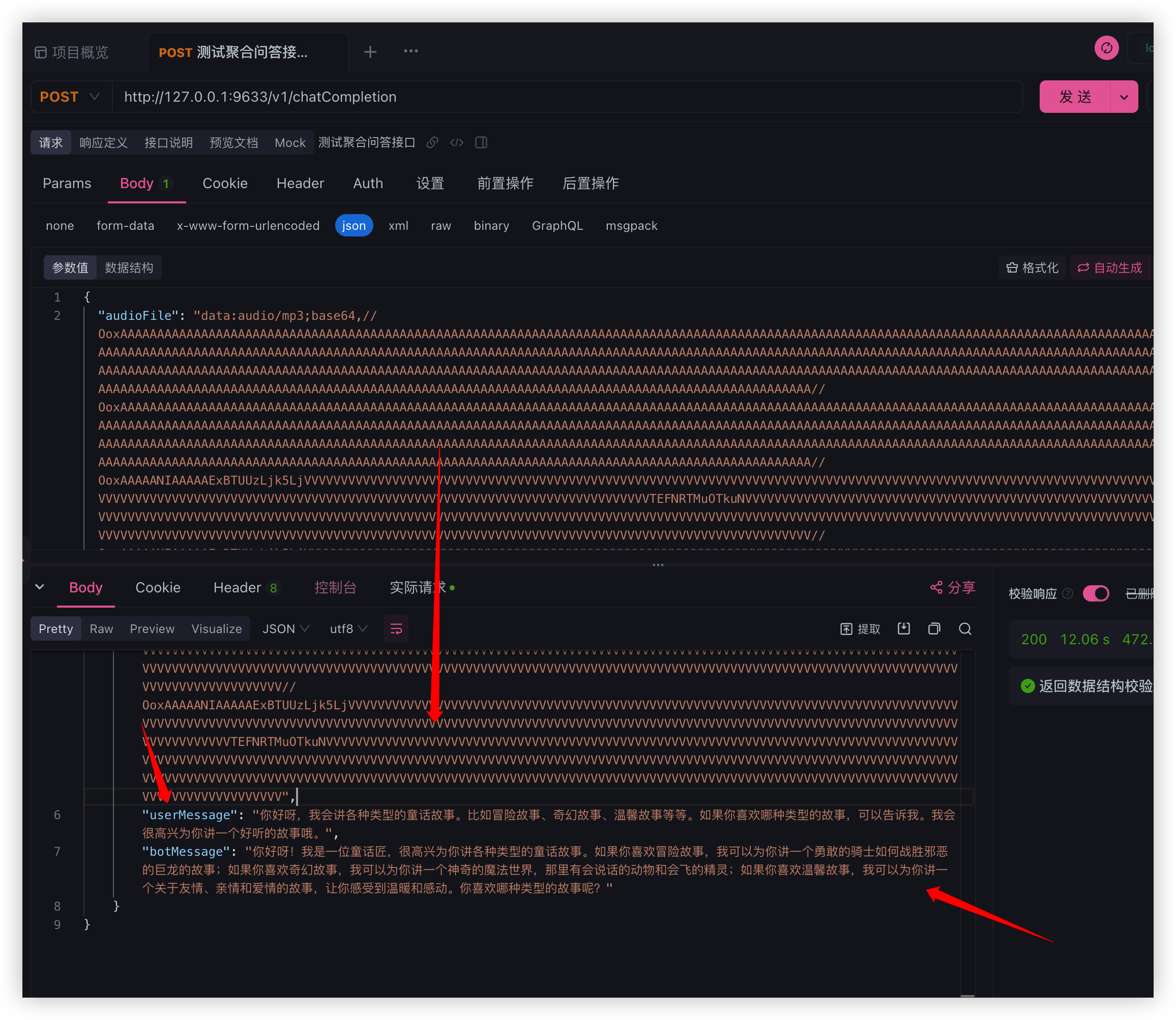
到此我们的后端工程就已经搭建完毕, 但还没完哦后面会继续扩展功能, 那么接下来就是开发前端工程了, 同学们冲冲冲啊
还没完都给我继续学
由于超出了5万字数限制, 我这里需要新开一篇文章, 第二篇才是重中之重全是功能实现别忘记了
玩转AI新声态 | 玩转TTS/ASR/YuanQI 打造自己的AI助手 第二篇
最后
本期结束咱们下次再见👋
关注我不迷路,如果本篇文章对你有所帮助,或者你有什么疑问,欢迎在评论区留言,我一般看到都会回复的。大家点赞支持一下哟 💗
