一、前言
此系列将写一个系列给大家介绍腾讯云上的业务安全产品,希望加深大家对于腾讯业务安全产品的了解和熟悉,使用。
随着互联网业务的发展,各行各业都涉及业务安全问题:
- 金融中涉及的主要业务安全问题包括账号安全、资金安全、洗钱、骗贷、老赖逾期问题、金融黑中介、薅羊毛等;
- 社交中面临的主要业务安全问题包括账号安全(盗号、恶意注册、养号)、诈骗、恶意引流、色情恐怖政治等;
- 游戏中则是外挂、盗号、内容类(诈骗引流低俗辱骂色情恐怖)、工作室打金等。
业务安全是一个不断对抗的过程,腾讯业务安全是基于腾讯20年黑灰产的对抗经验和领先技术打造而成的标准化风控模型,目前已在金融、电商、政务等多个行业落地应用,并覆盖金融领域超过80%的标杆客户。
目前互联网上的数据呈现爆炸式增长,图片、视频、发文、聊天等互动内容已经成为人们表达感情、日常工作不可或缺的部分。这些日益增长的内容中也充斥着各种不可控的风险因素,比如不雅不良评论、垃圾广告、违法违规交易/宣传、低俗不文明等垃圾内容。目前天御内容安全主要有下面四种场景:
- 图片内容安全
- 文本内容安全
- 音频内容安全
- 视频内容安全
图片内容安全(Image Moderation System,IMS)能精准识别涉黄、涉恐、涉政等有害内容,支持配置图片黑名单,打击自定义的违规类型。识别结果分为正常、可疑与违规三部分,建议放行正常的图片,人工审查可疑的图片,屏蔽违规的图片,节省人力成本,提高审核效率。
文本内容安全(Text Moderation System,TMS)服务使用了深度学习技术,可有效识别涉黄、涉政、涉恐等有害内容,支持用户配置词库,打击自定义的违规文本。通过 API 接口,能检测内容的危险等级,对于高危部分直接过滤,可疑部分人工复审,从而节省审核人力,释放业务风险。
音频内容安全(Audio Moderation System,AMS)能自动检测音频,识别音频中的涉黄、涉恐、涉政、谩骂、低俗等违规内容,并支持自定义黑名单热词,打击自定义的违规音频内容。用户可通过 API 获取检测的标签、违规内容及置信度,直接使用信置信度高的结果和人工复审置信度低的结果,从而降低人工成本,提高审核效率。
二、内容安全产品特性
2分钟带你认识腾讯云 T-Sec 天御 内容安全
https://cloud.tencent.com/edu/learning/course-2321-33927
腾讯云官网进入内容安全页面
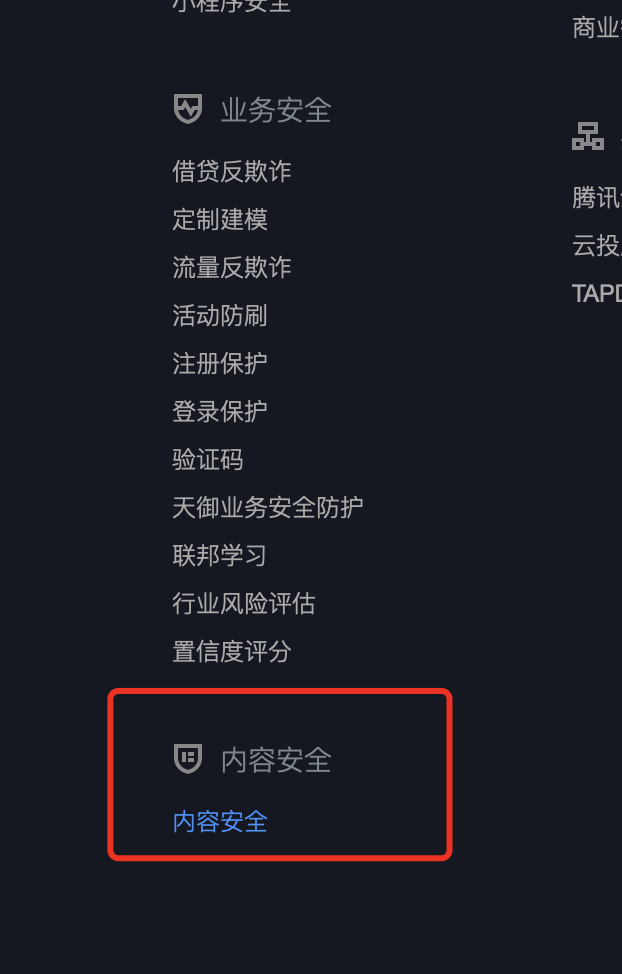
- 图片内容安全特性
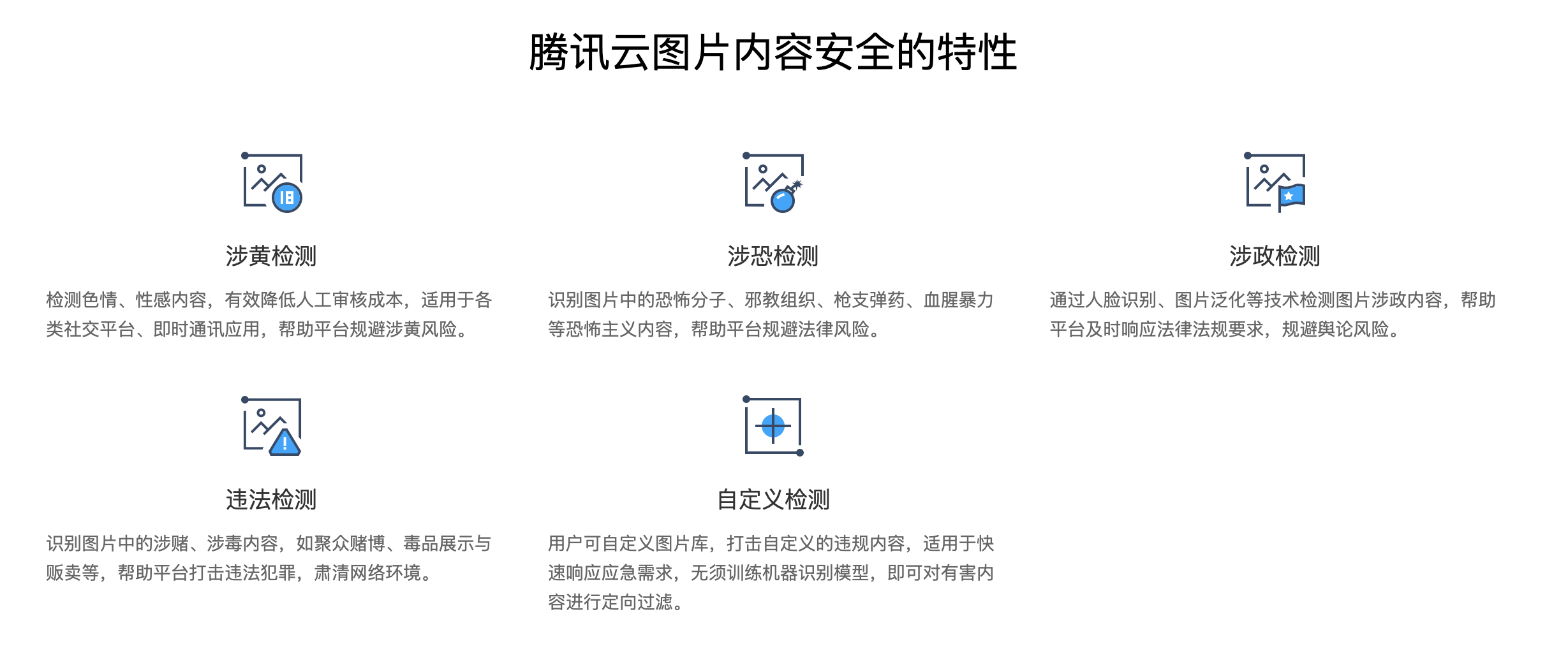
- 文本内容安全特性
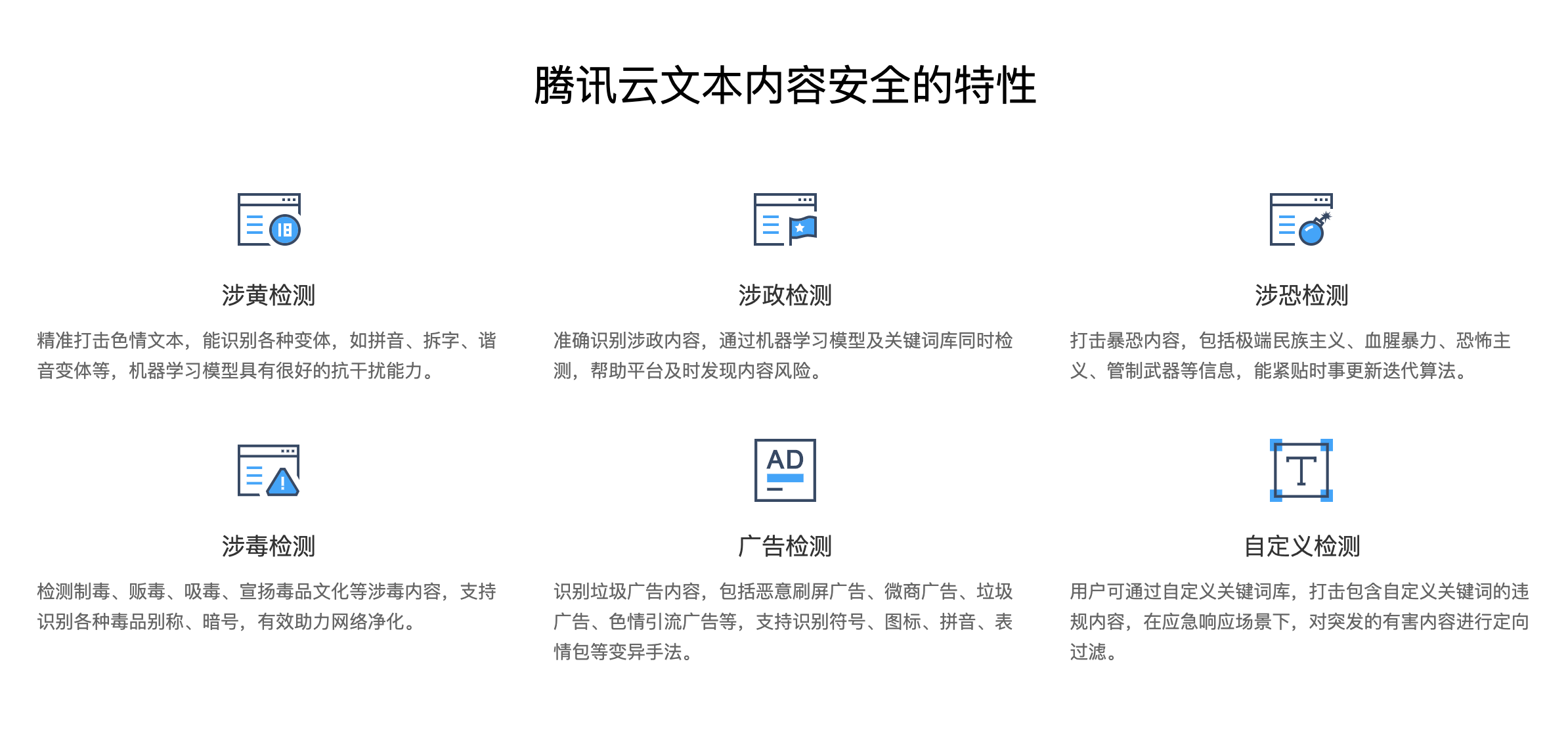
- 音频内容安全特性
三、文本内容安全现状
不良不雅评论,违规违法交易严重影响主营业务的健康发展 。面对此类问题,企业主该如何解决呢?
一种方法是投入人力加大审核力度,此种方式的特点如下:
- 垃圾评论占比较小,人力逐条审核容易漏审
- UGC评论数据规模巨大,每日多达数十亿、百亿等,人力成本太高
- 审核人员的招聘成本,管理成本较高
另外一种方式是招聘专业的AI工程师自建识别模型,此种方式特点如下:
- AI工程师非常昂贵
- 内容安全一般不属于主营业务,投入较少
- 识别模型的效果受限于样本规模和样本质量,在数据标注上需要持续投入
最后一种途径是购买保险:将内容安全问题交给专业的公司来解决,从而实现“四两拨千斤”。
四、文本内容安全现有解决方案
当前识别此类垃圾内容的主流方法有:关键词过滤模式、关键词文法过滤模式、在打标数据上训练垃圾识别模型的机器学习模式,或融合关键词与机器学习的混合模式,其特点分析如下:
- 基于关键词过滤模式:该模式的优点是立竿见影生效快,但是由于分词歧义问题导致误杀,对未登录的case泛化能力弱,词库的维护成本高
- 基于关键词文法的过滤模式:由于考虑了关键词的上下文,此种方式相比关键词过滤拥有了一定的消歧义能力,但是关键词文法需要人工总结归纳,再加上上下文不易枚举,使得人力成本成倍上升,于此同时随着变种不断涌现,从变种中挖掘拦截文法,人力成本不可控
- 静态机器学习模型或融合了关键词文法过滤的混合模式:由于模型是静态的,上线之后,应对不了变种问题,使得模型很快失灵
新变种不断涌现,会快速绕过当前垃圾识别方法,使得当前的方法“失灵”,各公司不得不投入大量人力研究变种,归纳拦截策略或标注新样本,于此同时每个业务平台上的垃圾内容存在较大差异,同一垃圾类型,客户的尺度也存在较大差别。在节约人力成本的条件下,如何解决此类对抗性的问题,并做到客户级的个性化定制,成为困扰业界一大难题。腾讯云天御分别从:
- Active learning方式挖掘高质量语料,降低人工审核量
- 打造数据闭环降低研发运维投入
- KV分布式存储实现GB级模型秒级更新
- T+1滚动式升级模型对抗变种
等四大维度搭建内容安全完整解决方案。
五、天御文本内容方案
5.1 UGC分类
天御把UGC评论文本类型分为6大类:
- 不良
- 不雅
- 违法违规:UGC中含有违法违规词汇,或法律禁止网上交易的内容
- 广告:为第三方导流的合法广告,其尺度因平台业务类型而异
- 低俗不文明:骂人,爆粗口等
- 正常
5.2 UGC特点及天御应对策略

图1可以看出互联网UGC主要特点如下:
- 规模巨大,天御通过研发可弹性部署的高并发算法引擎来应对每日上百亿的垃圾评论拦截请求
- 对抗性:新变种很容易绕过当前防控策略,腾讯云天御通过异常识别(基于Active Learning)为垃圾识别挖掘变种语料,大大节约人工审核量;垃圾识别会每隔一段时间拉取异常识别历史记录(已被人工审核),训练出最新的垃圾识别模型,为异常识别和垃圾识别构建一个数据环路,使得模型随着垃圾内容的变异而升级,有效解决了对抗性问题,大大降低研发投入;再将每一个客户的模型表格化,每一行追加上客户信息,实现不同客户之间的模型隔离,模型按行分布式存储使得在秒级实现多模型自动批量上线,大大降低系统维护成本。
- 防控尺度因业务类型而异,天御会针对每一种业务类型针对性的训练模型,从而实现模型的个性化定制
5.3 天御UGC过滤系统架构

从图2看出腾讯云天御UGC过滤垃圾评论的系统架构主要分为四层:
- 底层数据层
- 核心能力层
- 拒绝类型;拒绝策略层
- 客户层
其中核心能力层包括4大模块:
1. 异常识别,目的是从各种异常类型中发掘最新变种,异常识别所做的工作见图3:
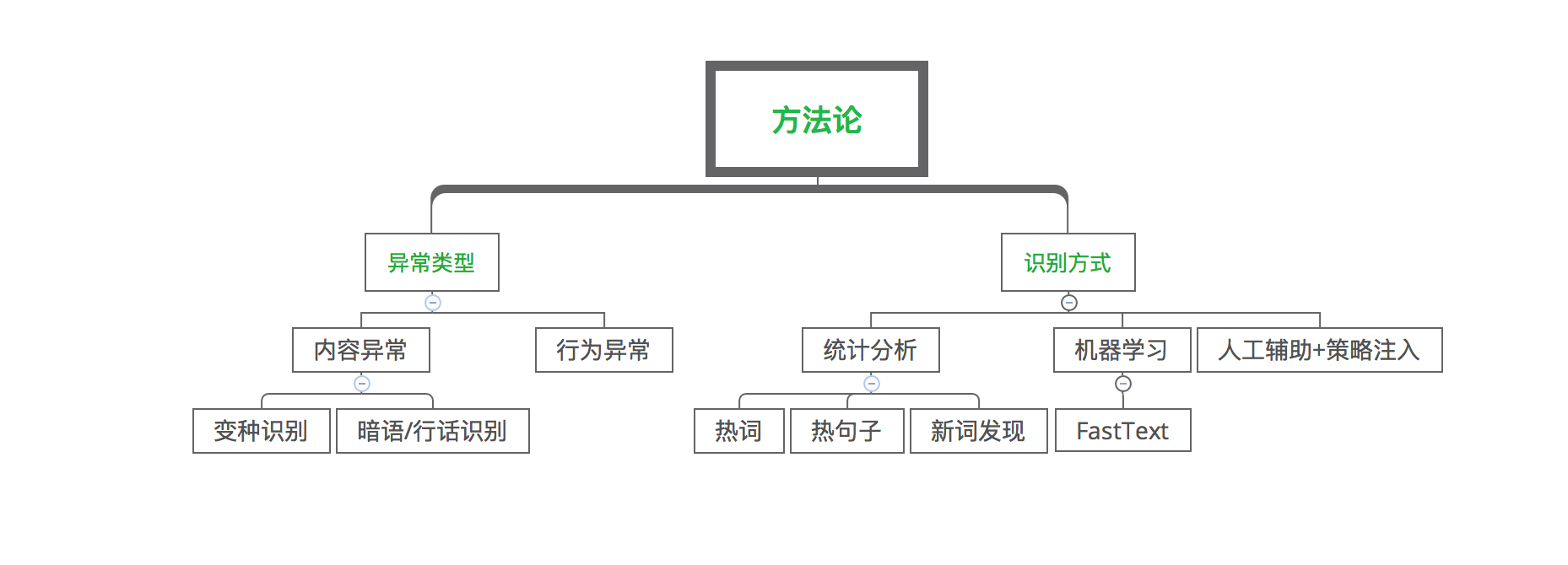
图3中异常类型主要分为内容异常和行为异常,常见的内容异常主要包括变种和行话/暗语,而行为异常表现为同一个人在不同地方发布相同内容,或同一内容被不同人转发等。异常识别的手段主要是通过统计分析发现变种词汇,变种表达等;有些变种是在内容里相间插入特殊符号,其语言构成和正常文本有区别,可通过机器学习的方式来发掘此类变种;对于可疑的内容一般通过人工辅助+策略注入来确定是否为变种。
2. 打标平台,提供数据打标、算法效果每日抽检等等。主要功能分为:
- 多人协同:目的是为了提升打标效率,会把一份数据分割成多分由多人完成打标
- 抽样策略,由于UGC评论规模巨大,不论是抽取样本还是每日抽检算法效果,需要不同的抽样策略,最终实现少量样本覆盖全部case
- 审核策略,分为单人初审、多人投票式的盲审,客户拦截效果评估等等,此块保证数据的打标质量
3. 模型平台,含模型训练和模型上线,具体包括:
- partition策略,不同的客户、不同的业务场景,其防控尺度均不相同,需要针对性训练,模型平台会一次性训练多达上千个模型。partition策略起着分割数据,标识模型的作用
- 特征工程:含有特征提取、特征选择,特征变换等,特征变换如各类账号,数字,表情符号归一化操作等等
- 模型训练
- KV分布式化,其作用是提升上线效率,支撑弹性部署,降低人工干预度
- 评估策略,其作用是评估模型效果,判断模型是否可以上线,主要的手段是封闭测试
- 更新策略,模型支持T+N滚动式更新,具体流程详见下图
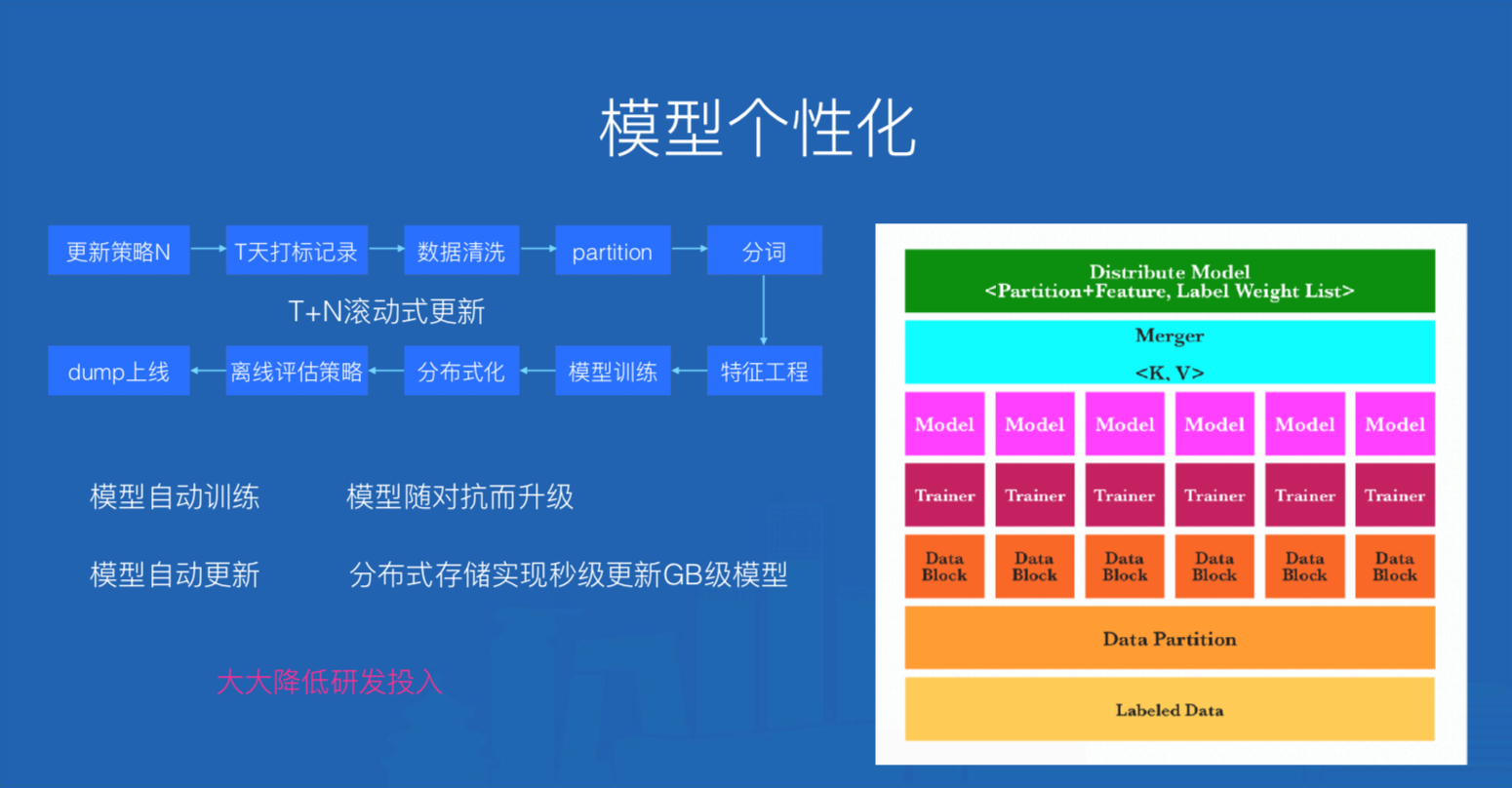
图4中“更新策略N”代表一个定时任务,N的值代表相隔多少天更新一次,T表示模型训练语料集是T天的沉淀数据。在模型训练时,一个Trainer表示一个Reducer任务,其结果是产出一个模型,Merger是将所有模型分布式KV存储的操作,并在K中注入模型ID信息【partition+feature】,V是分类标签和标签权重信息的列表。
4. 垃圾识别,其工作如下图所示:
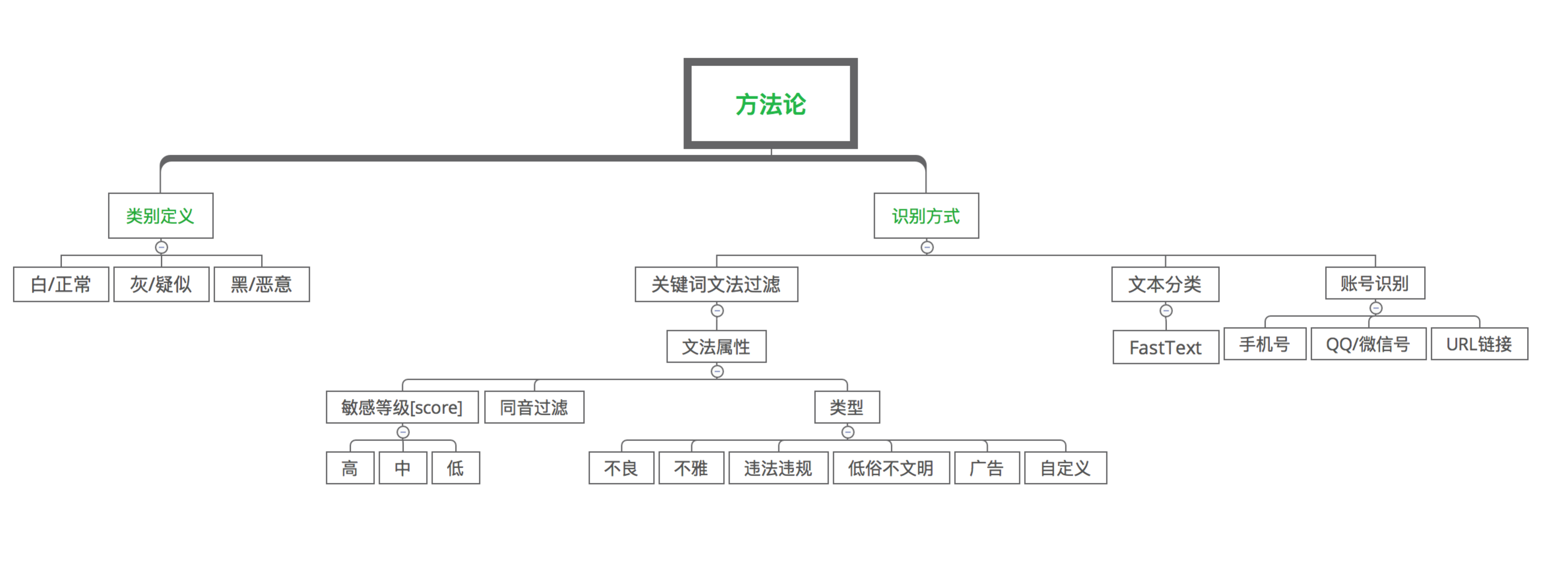
从图5可见,依据影响业务健康度的程度和客户不同类型的拒绝策略,总体上将同一类垃圾类型划分为2类或3类:
- 白:正常内容
- 灰:疑似[可选]
- 黑:恶意内容
在垃圾内容识别上腾讯云天御采用关键词文法过滤+模型动态更新的文本分类方法实现的垃圾识别系统,支持单条关键词文法上的个性化配置。
垃圾广告、违规违法交易中一般含有各类联系方式,是否含有联系方式成为垃圾识别最显著的特征。联系方式常见的有:
- 手机号
- QQ号
- 微信号
- URL链接
5.4 文本分类算法选型:FastText
FastText是Facebook开发的一款快速文本分类器,提供简单而高效的文本分类和表征学习的方法。FastText 方法包含三部分:模型架构、层次 Softmax 和 N-gram 特征。
5.4.1 FastText模型架构

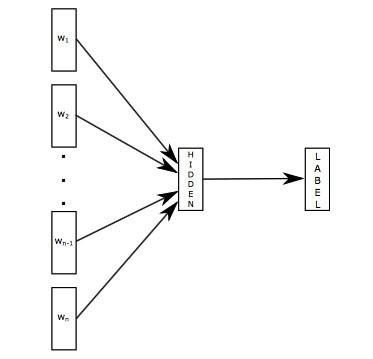
FastText 模型输入一个词的序列(一段文本或者一句话),输出这个词序列属于不同类别的概率。
序列中的词和词组组成特征向量,特征向量通过线性变换映射到中间层,中间层再映射到标签。
FastText 在预测标签时使用了非线性激活函数,但在中间层不使用非线性激活函数。
FastText 模型架构和 Word2Vec 中的 CBOW 模型很类似。不同之处在于,fastText 预测标签,而 CBOW 模型预测中间词,见下图所示:
5.4.2 FastText层次Softmax
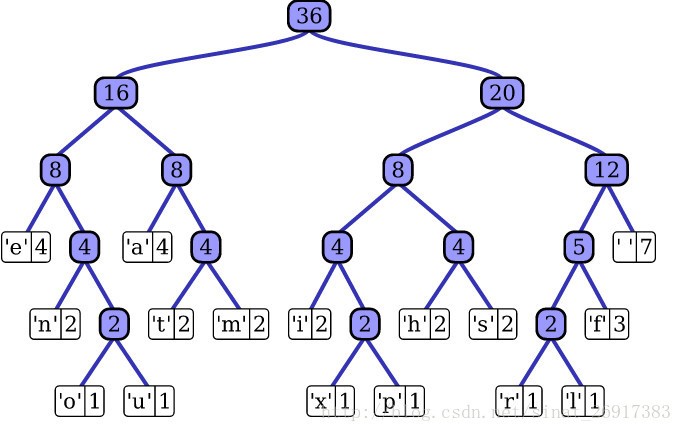
对于有大量类别的数据集,FastText使用了一个分层分类器(而非扁平式架构)。不同的类别被整合进树形结构中(想象下二叉树而非 list)。在某些文本分类任务中类别很多,计算线性分类器的复杂度高。为了改善运行时间,FastText 模型使用了层次 Softmax 技巧。层次 Softmax 技巧建立在哈弗曼编码的基础上,对标签进行编码,能够极大地缩小模型预测目标的数量。
考虑到线性以及多种类别的对数模型,这大大减少了训练复杂性和测试文本分类器的时间。FastText 也利用了类别(class)不均衡这个事实(一些类别出现次数比其他的更多),通过使用 Huffman 算法建立用于表征类别的树形结构。因此,频繁出现类别的树形结构的深度要比不频繁出现类别的树形结构的深度要小,这也使得进一步的计算效率更高。
5.4.3 FastText N-gram特征
常用的特征是词袋模型。但词袋模型不能考虑词之间的顺序,因此 FastText 还加入了 N-gram 特征。 “我爱她” 这句话中的词袋模型特征是 “我”,“爱”, “她”。这些特征和句子 “她 爱 我” 的特征是一样的。如果加入 2-Ngram,第一句话的特征还有 “我-爱” 和 “爱-她”,这两句话 “我 爱她” 和 “她 爱 我” 就能区别开来了。当然,为了提高效率,我们需要过滤掉低频的 N-gram。
在 fastText 中一个低维度向量与每个单词都相关。隐藏表征在不同类别所有分类器中进行共享,使得文本信息在不同类别中能够共同使用。这类表征被称为词袋(bag of words)(此处忽视词序)。在 fastText中也使用向量表征单词 n-gram来将局部词序考虑在内,这对很多文本分类问题来说十分重要。
举例来说:fastText能够学会“男孩”、“女孩”、“男人”、“女人”指代的是特定的性别,并且能够将这些数值存在相关文档中。然后,当某个程序在提出一个用户请求(假设是“我女友现在在儿?”),它能够马上在fastText生成的文档中进行查找并且理解用户想要问的是有关女性的问题。
5.4.4 FastText词向量优势
1. 适合大型数据+高效的训练速度:能够训练模型“在使用标准多核CPU的情况下10分钟内处理超过10亿个词汇”,特别是与深度模型对比,fastText能将训练时间由数天缩短到几秒钟。使用一个标准多核 CPU,得到了在10分钟内训练完超过10亿词汇量模型的结果。此外,FastText还能在五分钟内将50万个句子分成超过30万个类别。
2. 支持多语言表达:利用其语言形态结构,fastText能够被设计用来支持包括英语、德语、西班牙语、法语以及捷克语等多种语言。它还使用了一种简单高效的纳入子字信息的方式,在用于像捷克语这样词态丰富的语言时,这种方式表现得非常好,这也证明了精心设计的字符 n-gram 特征是丰富词汇表征的重要来源。FastText的性能要比时下流行的word2vec工具明显好上不少,也比其他目前最先进的词态词汇表征要好。

3. FastText专注于文本分类,在许多标准问题上实现当下最好的表现(例如文本倾向性分析或标签预测)。FastText与基于深度学习方法对比,比word2vec更考虑了相似性,比如 fastText 的词嵌入学习能够考虑 english-born 和 british-born 之间有相同的后缀,但 word2vec 却不能。
5.5 数据闭环
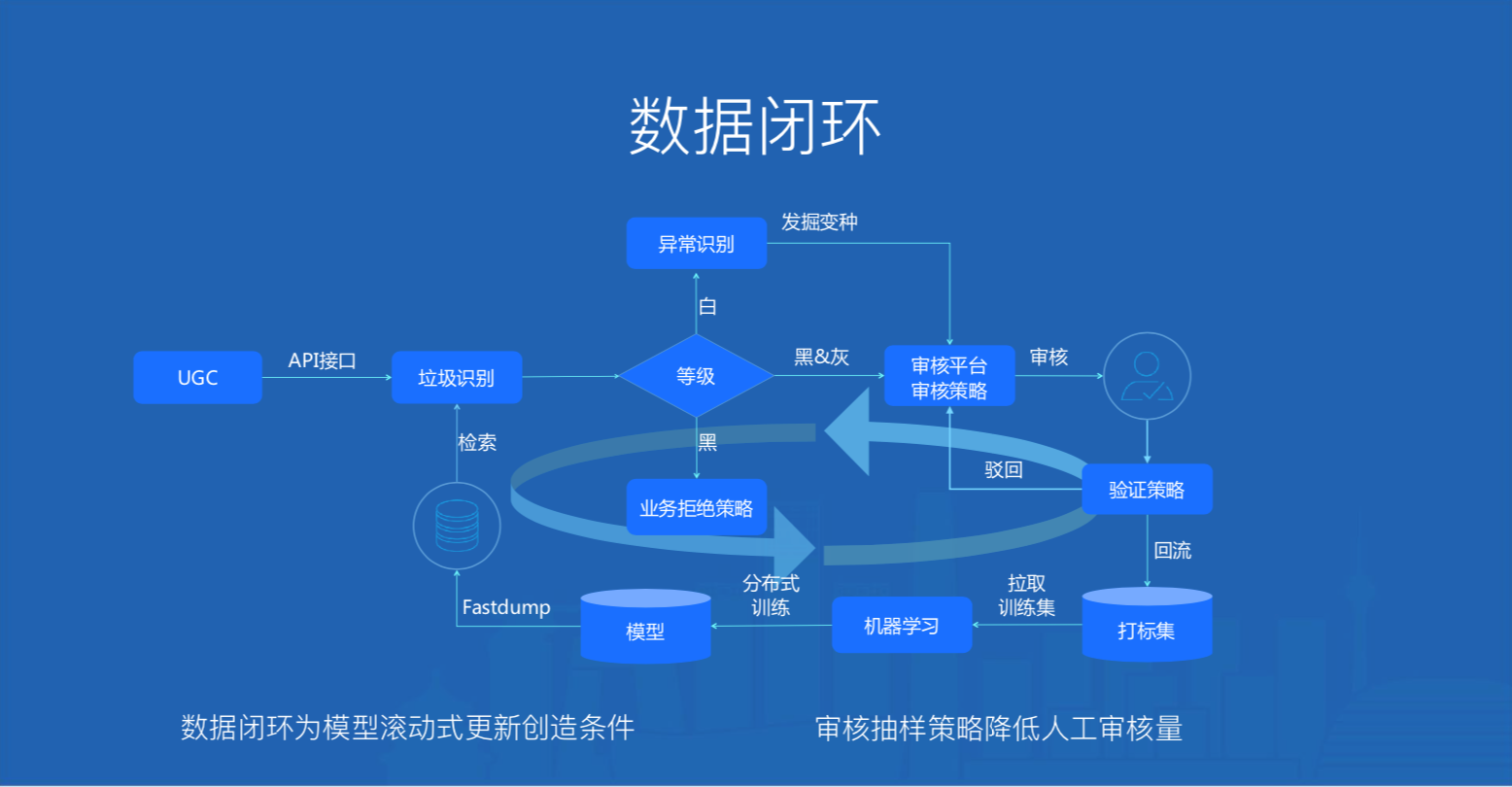
腾讯云天御在垃圾识别、异常识别和人工审核构建一个数据闭环:
- 人工审核沉淀的数据为垃圾识别提供训练语料,由于每天都有数据被打标,为垃圾识别T+1滚动式更新模型创造了条件
- 每日抽检被识别为黑的部分,作为统计算法效果的审核样本,于此同时将不能识别的最新变种交给异常识别来发掘
- 审核平台的审核抽样策略挖掘最能反映总体的小量样本,覆盖尽可能多的case,大大降低人工审核量
六、总结-思考
6.1 系统指标

- 封闭测试准确率、召回率、准确度用来衡量样本的打标质量
- 测试集上的准确率和召回率用来衡量模型的质量
- 抽样准确率用来衡量算法线上效果
- 进审量、人效、审核平均延时直接决定着人力审核成本
- 盲审抽样率、盲审一致率体现数据打标人员对数据标注的标准理解深度
6.2 天御的表现

6.3 思考
文本内容对甲方来说:
- 非主营业务,对此块的重视程度不够
- 业务价值不易衡量,员工投入其中其职业发展受限
- 业务数据规模巨大,投入产出不划算
- 预算偏少,不雅、不良评论、违法违规容易触及法律红线,严重影响主营业务
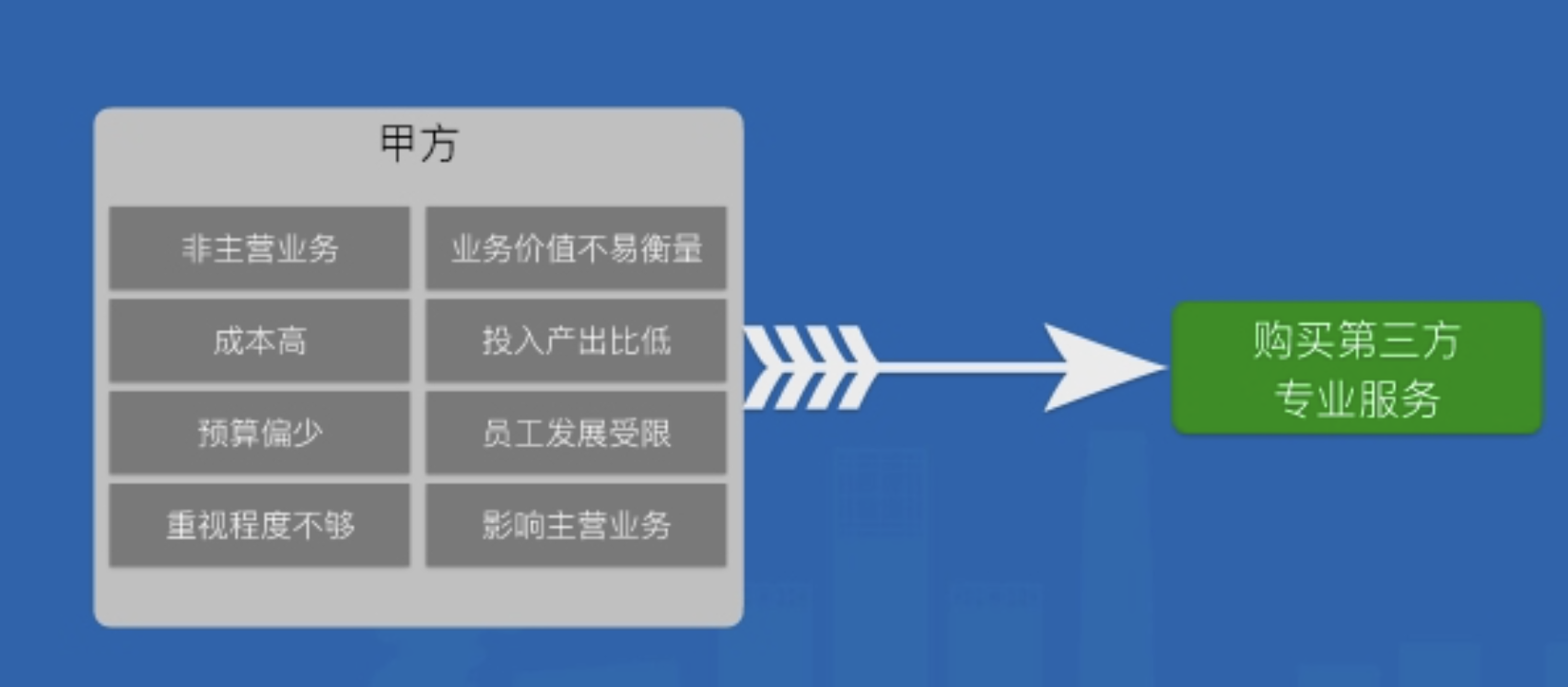
综上,未来内容安全一条便宜省心的趋势,选择行业成熟的解决方案,可以实现业务健康发展的同时,确保内容安全。
七、使用常见问题和案例
根据数据分析,大家接入内容安全过程中主要的常见问题是:客户接入和产品问题
7.1 客户接入
1、接口文档
音频:https://cloud.tencent.com/document/product/1219/46477 图片:https://cloud.tencent.com/document/api/669/34503 文本:https://cloud.tencent.com/document/product/1124/46976
2、怎么查看腾讯云账号信息,获取UIN与APPID
使用腾讯云账号登录账号信息控制台: https://console.cloud.tencent.com/developer
3、怎么获取调用接口的SecretId和SecretKey?
使用腾讯云账号登录云API密钥管理控制台: https://console.cloud.tencent.com/cam/capi 如没有,点击新建一个即可

4、内容安全服务接入指引:
( 内容仅针对文本和图片 ) 用户在腾讯云官网-控制台(内容安全链接),图片内容安全/文本内容安全界面内即可免费领取试用包、购买正式包。 https://console.cloud.tencent.com/cms 字体颜色或背景 开通服务后,可先使用API在线工具调试接口(地区选择广州)
批量测试和正式接入可参考在线工具中的Demo使用SDK接入或自行实现HTTP请求调用API(推荐使用SDK)。 SDK下载地址:https://cloud.tencent.com/document/product/669/34502 Java路径: tencentcloud-sdk-java-master\src\main\java\com\tencentcloudapi\cms 其他路径:内容安全命名为CMS,可在SDK内搜索对应文件名 调用数据可在内容安全控制台查看(最新数据为T-1天)
7.2 常见产品问题
1、主账号权限错误 返回参数code:10001
{ "Response":{ "RequestID":"b*****-*****-****-****-******af", "Businesscode": 0, "Error":{ "code":"UnauthorizedOpertion.Unauthorized", "Message":"未开通权限" } } "retcode":10001, "retmsg":"未开通权限" } 未开通内容安全服务,需要主账号去控制台开通测试包或者购买服务包
2、主账号已经开通了内容安全的服务,子账号需要调用服务需要授权?
如果是子账号要使用,需要主账号给权限QcloudCMSFullAccess https://console.cloud.tencent.com/cam/policy
3、为什么控制台没有数据?
需要确认登录的账号是否和调用接口的账号一致。 主账号与子账号,以及子账号之间的控制台数据独立。 控制台数据(t+1),今天的数据次日才可以查看。
4、是否可以自行添加违规词、自行新增恶意类型?
对于漏过(人审违规机审正常)的词,目前可以通过加入到自定义词库中实现打击。 恶意类型目前不支持新增。
5、图片接口支持哪些图片格式?对图片大小、分辨率有限制吗?
3.0接口 格式:常见的图片格式如PNG、JPG、JPEG、WEBP、GIF等都支持。 大小:目前无硬性限制,建议4M以内,图片分辨率大于200200,小于10002000。 4.0接口 格式:常见的图片格式如PNG、JPG、JPEG、WEBP、GIF等都支持。 大小:目前无硬性限制,建议4M以内,图片分辨率,小于1000*2000。
6、图片识别接口返回”多媒体文件链接下载源错误”是什么原因?
图片链接可以打开,但由于图片太太或者偶发的网络不稳定等原因导致下载失败
7、天御视频接口量级是按照什么计算?
按照视频总时长计算; 默认1s/帧,如客户截帧频率较密,会提前消耗完套餐包。
8、读取视频多久会超时?
3s,读取不到视频的头,就会超时
9、如图片下载全部会显示‘多媒体下载链接错误’是什么原因?
需要调整为域名使用,下载会拒绝直接使用ip的链接
10、内容线是否支持离线SDK?
不支持。
11、4.0接口图片Biztype字段是否客户可以自己设定?
可以的;Biztype 是我们这边要配置后,才会产生的,可以是英文、数字下划线来组合; 如果客户方需要配置什么格式的在配置前通知,一旦配置后,就无法更改。
12、4.0接口图片Review字段是否可以每个标签都输出?
不可以,只有机审后有分数输出的标签才会输出;如广告,二维码则不会输出。
13、音频审核类型中‘点播音频’和直播音频的区别是什么?
点播音频是基于文件的,直播音频是基于直播流。
14、视频审核-是否支持多个视频同时审核?
支持,最多支持40个视频同时审核。
15、视频审核Callback url 是否有callback失败后recall的逻辑?
没有。如果需要高可用,可用taskid 再查一遍。
16、缓冲队列最多可以支持多少个视频排队验证?
排队没有验证。同时审核数量是 40个。
17、是否有小视频插队逻辑?
是的。默认情况下,小视频不用排队。
18、如要检测视频中的音频,是要接一个接口还是两个接口?
一个接口就可以了,但是需要区分API请求地址和数据标识(如:audio、video)
19、是否有支持批量图片检测的接口吗?目前试单张检测的接口
没有,需要客户方自己写脚本去测试。
八、服务保证指标SLA
8.1 内容安全服务承诺99.9%的业务可用性。 (1)业务可用性 = 图片内容安全服务周期内业务可用时间 / 图片内容安全服务周期内服务总时间。 (2)失败请求: 因图片内容安全系统故障导致正常的请求未到达图片内容安全服务端的请求。 (3)有效的总请求:图片内容安全服务端接收到的所有请求视为有效的总请求。 (4)错误率 =(每分钟失败请求数 / 每分钟有效总请求数)x 100%。 (5)不可用时间:图片内容安全服务在1分钟内的错误率大于0.01%的,计为该分钟内服务不可用。服务连续1分钟以上不可用的,计为一次故障事件。以下情况不纳入业务不可用时间计算:
- 日常系统维护时间。
- 由客户原因、第三方原因或不可抗力导致的不可用时间。
(6)服务不可用分钟数:服务周期内累计故障事件的持续时间分钟数之和
参考:https://blog.csdn.net/weixin_34235371/article/details/89158495