2022年7月21日,大家都被一则新闻刷屏了。
经查实,滴滴全球股份有限公司违反《网络安全法》《数据安全法》《个人信息保护法》的违法违规行为事实清楚、证据确凿、情节严重、性质恶劣。
7月21日,国家互联网信息办公室依据《网络安全法》《数据安全法》《个人信息保护法》《行政处罚法》等法律法规,对滴滴全球股份有限公司处人民币80.26亿元罚款,对滴滴全球股份有限公司董事长兼CEO程维、总裁柳青各处人民币100万元罚款。
这已经不是数据安全的问题第一次出现在公众面前,作为数据从业者,我们也应该意识到数据安全的重要性。
而在大数据生态,基于Hadoop的技术架构虽然日渐成熟,但是由于组件众多,实现统一的安全管控的难度巨大。为了图省事,相信还有大部分企业的Hadoop集群依然处于“裸奔”的状态,只要连上网络,知道账号密码,就可以畅通无阻的访问数据。这些其实都存在着巨大隐患。
所以,在大数据安全的治理上,我们需要做的工作还有很多。
本文将通过数据安全的意义,数据安全知识体系,大数据安全实践,Kerberos 认证,Apache Ranger实践,数据加密六个部分来介绍。
本文将介绍大数据安全的理论与实践经验,特别是实践部分,如果这些工作都还没有做的话,建议逐步开展,数据治理是一个长期的过程,不管是数据安全还是之前我们一直在学习的元数据管理与数据质量等等问题,都需要不断的完善。
一、数据安全的意义
在谈数据安全的意义之前,我们先来看一下滴滴本次到底有哪些违法行为。
问:滴滴公司存在哪些违法违规行为?
答:经查明,滴滴公司共存在16项违法事实,归纳起来主要是8个方面。一是违法收集用户手机相册中的截图信息1196.39万条;二是过度收集用户剪切板信息、应用列表信息83.23亿条;三是过度收集乘客人脸识别信息1.07亿条、年龄段信息5350.92万条、职业信息1633.56万条、亲情关系信息138.29万条、“家”和“公司”打车地址信息1.53亿条;四是过度收集乘客评价代驾服务时、App后台运行时、手机连接桔视记录仪设备时的精准位置(经纬度)信息1.67亿条;五是过度收集司机学历信息14.29万条,以明文形式存储司机身份证号信息5780.26万条;六是在未明确告知乘客情况下分析乘客出行意图信息539.76亿条、常驻城市信息15.38亿条、异地商务/异地旅游信息3.04亿条;七是在乘客使用顺风车服务时频繁索取无关的“电话权限”;八是未准确、清晰说明用户设备信息等19项个人信息处理目的。
除了一些明显有违法行为的操作以外,这里特别注意的一点就是 明文形式存储司机身份证号信息5780.26万条。很明显,在敏感信息的存储上,未进行加密处理。
数据安全意义重大 伴随着互联网的迅猛发展和数字经济的快速推进,全球数据呈现爆发增长、海量集聚的特点,对经济发展、社会治理、 国家管理、人民生活都产生了重大影响。数据作为前沿技术开发、隐私安全保护的重要内容,让数据安全的重要性提到 了前所未有的高度。保障数据安全不仅涉及到公民个人隐私,还涉及到企业长远发展和国家安全。 事实上,数字信息化发展一直伴随着安全问题。

近几年来《数据安全法》《个人信息保护法》相继出台,也表明了数据安全的重要性越来越高。

对数据安全缺乏管控将会引起一系列的问题。
大数据遭受异常流量攻击
大数据所存储的数据非常巨大,往往采用分布式的方式进行存储,而正是由于这种存储方式,存储的路径视图相对清晰,而数据量过大,导致数据保护,相对简单,黑客较为轻易利用相关漏洞,实施不法操作,造成安全问题。
大数据信息泄露风险
大数据平台的信息泄露风险在对大数据进行数据采集和信息挖掘的时候,要注重用户隐私数据的安全问题,在不泄露用户隐私数据的前提下进行数据挖掘。
大数据传输过程中的安全隐患
数据生命周期安全问题。伴随着大数据传输技术和应用的快速发展,在大数据传输生命周期的各个阶段、各个环节,越来越多的安全隐患逐渐暴露出来。
个人隐私安全问题。在现有隐私保护法规不健全、隐私保护技术不完善的条件下,互联网上的个人隐私泄露失去管控。
二、数据安全知识体系
《中华人民共和国数据安全法》中第三条,给出了数据安全的定义,**是指通过采取必要措施,确保数据处于有效保护和合法利用的状态,以及具备保障持续安全状态的能力。要保证数据处理的全过程安全,数据处理,包括数据的收集、存储、使用、加工、传输、提供、公开等。
在《DAMA数据管理知识体系指南》中也对数据安全管理给出了具体的定义:定义、规划、开发、执行安全策略和和规程,以提供对数据和信息资产的适当验证、授权、访问、审计
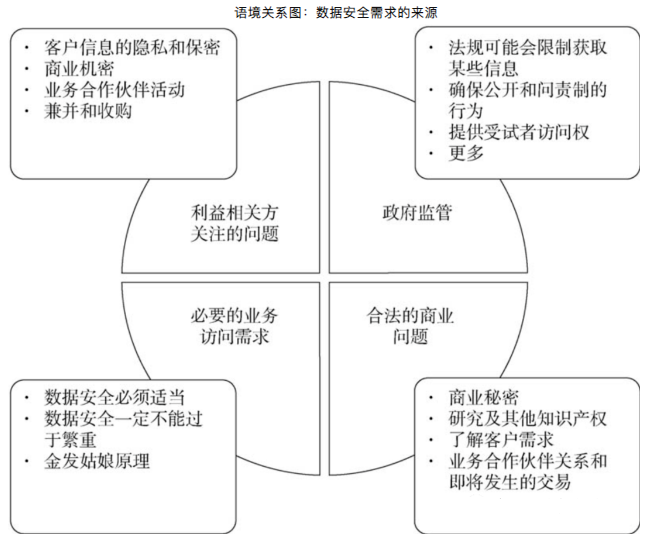
数据安全如何开展呢?有以下一个步骤:
- 1.识别敏感数据资产并分 级分类
- 2.在整个企业中查找敏感 数据
- 3.确定保护每项资产的方 法
- 4.识别信息与业务流程如 何交互
这里就要注意,在数据安全中有几个关键的词语,就是访问,审计,分级分类,监控,加密。
下面我用一些通俗的语言解释一下~
访问指的是,对于谁可以访问数据应该是有一定机制的,而且安全性应该非常的高,不应该是简单的账号密码就能解决的。
审计指的是,对于数据的使用,应该是有记录的,不能是用完了也不知道是谁用了。
分级分类这个不搞数据安全的可能想不到,但是数据量大了以后,不可能所有数据都用一个规范去管理的。分级分类也更专业更高效。
监控报警机制就更为重要,当出现了问题的时候,应该第一时间就发现问题所在。
加密是一个大的概念,对于敏感信息的处理,加密是一种手段,但不仅仅是加密那么简单。如何加密、解密,并保持高的处理性能,这是我们需要解决的问题。
三、大数据安全实践
每一个数据框架的出现都会考虑数据安全的问题,Hadoop的安全问题不是一个新的概念,而是一个老生常谈的问题。
结合数据安全的理论知识,Hadoop安全可以总结为五点核心问题:
安全认证
任何用户都可以伪装成为其他合法用户,访问其在HDFS上的数据,获取MapReduce产生的结果,从而存在恶意攻击者假冒身份,篡改HDFS上他人的数据,提交恶意作业破坏系统、修改节点服务器的状态等隐患。
权限控制
用户只要得知数据块的 Block ID 后,可以不经过 NameNode 的身份认证和服务授权,直接访问相应 DataNode,读取 DataNode 节点上的数据或者将文件写入 DataNode 节点。
关键行为审计
默认hadoop缺乏审计机制。
静态加密
默认情况下Hadoop 在对集群HDFS 系统上的文件没有存储保护,所有数据均是明文存储在HDFS中,超级管理员可以不经过用户允许直接查看和修改用户在云端保存的文件,这就很容易造成数据泄露。
动态加密
默认情况下Hadoop集群各节点之间,客户端与服务器之间数据明文传输,使得用户隐私数据、系统敏感信息极易在传输的过程被窃取。
对此Hadoop其实做了一系列的治理工作。

Doug Cutting 和 Mike Cafarella 最初为 Nutch 项目开发 Hadoop 时并没有考虑安全因素,这是众所周知的事实。因为 Hadoop 的最初用例都是围绕着如何管理大量的公共 web 数据,无需考虑保密性。按照 Hadoop 最初的设想,它假定集群总是处于可信的环境中,由可信用户使用的相互协作的可信计算机组成。
最初的 Hadoop 中并没有安全模型,它不对用户或服务进行验证,也没有数据隐私。因为 Hadoop 被设计成在分布式的设备集群上执行代码,任何人都能提交代码并得到执行。尽管在较早的版本中实现了审计和授权控制(HDFS 文件许可),然而这种访问控制很容易避开,因为任何用户只需要做一个命令行切换就可以模拟成其他任何用户。这种模拟行为非常普遍,大多数用户都会这么干,所以这一已有的安全控制其实没起到什么作用。
Hadoop 社区意识到他们需要更加健壮的安全控制,决定重点解决认证问题,选择 Kerberos 作为 Hadoop 的认证机制。
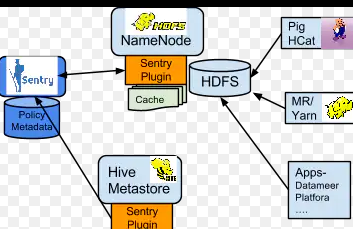
不久之后Cloudera公司发布的一个Hadoop开源组件,Apache Sentry。Sentry解决了细粒度访问控制,以及基于角色的管理。这是对权限管理的进一步加强,对Hive表可控制权限到列,对HDFS文件也可做具体权限控制。Apache Sentry目前已经成为退休项目了。
Hortonworks公司也发布了Apache Ranger。其提供了细粒度级Hive列级别的权限控制,并支持与Kerberos 集成。

除此以外,其他的组件也含有了一部分数据安全的功能。比如:
Apache Falcon:Apache Falcon是一个开源的hadoop数据生命周期管理框架, 它提供了数据源 (Feed) 的管理服务,如生命周期管理,备份,存档到云等,通过Web UI可以很容易地配置这些预定义的策略, 能够大大简化hadoop集群的数据流管理。
Apache Atlas:是一个可伸缩和可扩展的元数据管理工具与大数据治理服务,它为Hadoop集群提供了包括数据分类、集中策略引擎、数据血缘、安全和生命周期管理在内的元数据治理核心能力。
但是敏感信息处理的问题还是没有得到解决。
Apache Hadoop 2.9.1版本正式提出了HDFS 透明加密的概念,详见http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/TransparentEncryption.html
概念如下:HDFS实现透明的,端到端(transparent, end-to-end)的加密。配置以后,从特殊HDFS目录读取和写入的数据将透明地加密和解密,而不需要更改用户应用程序代码。这种加密也是端到端的,这意味着数据只能由客户端来进行加密和解密。HDFS从不存储或访问未加密数据或未加密数据加密密钥,这满足了加密的两个典型要求:静态加密(at-rest encryption)(指永久介质(如磁盘)上的数据)和传输中的加密(in-transit encryption)(如数据通过网络传输时)。
透明加密安全好用,但是对集群压力大,很多不需要加密的数据做加密处理,其实是一种资源浪费。
所以在部分公司也采用了方案就是针对Hive表的字段加密的方式。一个表具备几十个字段,需要做保护的可能只有其中一两个,通过提供一个UDF,在数据入Hive表时,在需要加密的字段上调用,UDF对上层透明,可实现数据保护。在数据需要解密的时候,同样提供UDF用于解密,调用即可得到明文。
而且加密解密对于性能的影响巨大,特别是Flink为主的实时计算框架稳定以后,数据的实时性提高。单纯的HDFS全量加密显然不能满足需求了,所以对于加密方式的研究也不能停止。
篇幅有限,下面我们对Kerberos,Apache Ranger和加密方式进行一个基本的介绍。
更详细的教程,请关注 大数据流动 ,后续将会持续更新~
四、Kerberos 认证
Kerberos 是一种身份认证协议,被广泛运用在大数据生态中,甚至可以说是大数据身份认证的事实标准。
Kerberos协议本质上是一种计算机网络授权协议,用于在非安全的网络环境下对个人通信进行加密认证。Kerberos协议认证过程的实现不依赖于主机操作系统的认证,不需要基于主机地址的信任,不要求网络上所有主机的物理安全,并且是以假定网络上传送的数据包可以被任意的读取、修改和插入数据为前提设计的。
简而言之,如果你要去请求服务,你要获取2个票据,1个叫许可票据,1个叫服务票据,去服务器请求服务之前,你必须拥有服务票据,但是你要去请求服务票据的时候,你又必须携带许可票据,拿到了这2个票据,你才能够有资格去真实服务器上去请求服务。
Kerberos 的核心就是加密 Ticket 。Kerberos 主要由三个部分组成:Key Distribution Center (即KDC)、Client 和 Service。
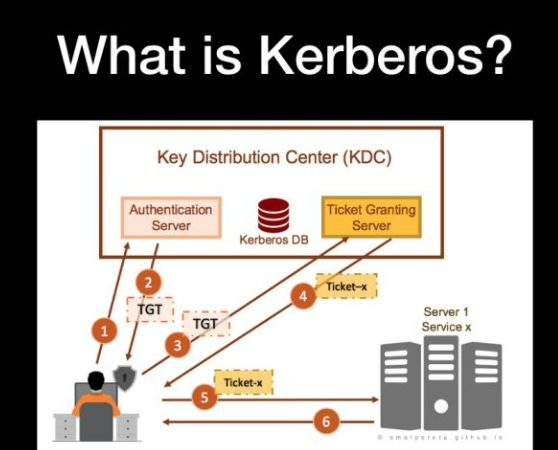
听起来有些繁琐,通俗解释一下。
首先要有一个Ticket,才能够申请访问权限,随后不同的Ticket还具有不同的权限。
我们实战一下,就更好理解了。
Kerberos部署
Kerberos需要部署服务端和客户端。
主节点安装服务:
yum install krb5-server -y其他子节点安装krb5-devel、krb5-workstation :
yum install krb5-devel krb5-workstation -y服务端包含三个配置文件:
有三个配置文件可以做对应的修改:
/etc/krb5.conf/var/kerberos/krb5kdc/kdc.conf
/var/kerberos/krb5kdc/kadm5.acl
创建Kerberos数据库
kdb5_util create -r localhost -s-r指定配置的realm领域名
启动服务
chkconfig --level 35 krb5kdc on
chkconfig --level 35 kadmin on
systemctl start krb5kdc
systemctl start kadmin创建Kerberos管理员
kadmin.local -q "addprinc admin/admin"测试Kerberos
kadmin.local -q "list_principals"
kadmin.local -q "addprinc dy"
kinit dy
klist
kinit -R
kdestroy
kadmin.local -q "delprinc dy"如果需要与CDH集成,要将Kerberos的凭据信息导入进来。
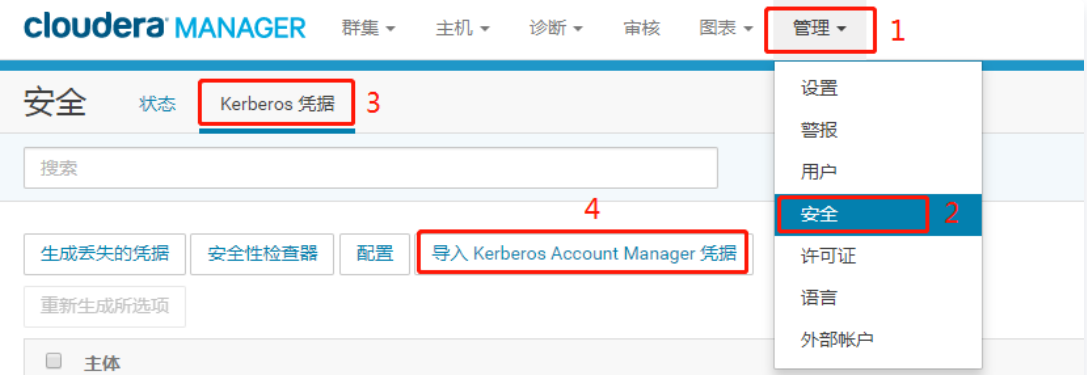
用户身份认证独立于HDFS之外,也就说HDFS并不负责用户身份合法性检查,但HDFS会通过相关接口来获取相关的用户身份,然后用于后续的权限管理。用户是否合法,完全取决于集群使用认证体系。目前社区支持两种身份认证,即简单认证(Simple)和Kerberos。模式由hadoop.security.authentication属性指定,默认simple。
simple 认证
基于客户端所在的Linux/Unix系统的登录用户名来进行认证。只要用户能正常登录就认证成功。客户端与NameNode交互时,会将用户的登录账号(通过类似whoami的命令来获取)作为合法用户名传递至Namenode。 这意味着使用不同的账号登录到同一个客户端,会产生不同的用户名,故在多租户条件这种认证会导致权限混淆;同时恶意用户也可以伪造其他人的用户名非法获得相应的权限,对数据安全造成极大的隐患。线上生产环境一般不会使用。
启用 kerberos认证
启用 HDFS安全性 修改下面参数
hadoop.security.authentication ---> kerberos
hadoop.security.authorization ---> true启用HBASE安全修改下面参数
hbase.security.authentication ---> kerberos
hbase.security.authorization ---> true这些都启动以后,再次访问hdfs就没有那么简单了,必须要有keytab的认证文件才可以了。
下面是一个简单的例子:
System.setProperty("java.security.krb5.conf", "D:\HDFS-test\krb5.conf");
conf=new Configuration();
conf.addResource(new Path("D:\HDFS-test\hdfs-site.xml"));
conf.set("hadoop.security.authentication", "kerberos"); //配置认证方式
conf.set("fs.default.name", "hdfs://localhost");//namenode的地址和端口
UserGroupInformation.setConfiguration(conf);
try {
UserGroupInformation.loginUserFromKeytab("hdfs/gz237-112", "D:\HDFS-test\hdfs.keytab");
} catch (IOException e) {
e.printStackTrace();
}五、Apache Ranger实践
Ranger是一个集中式安全管理框架,提供集中管理的安全策略和监控用户访问,而且它可以对hadoop生态系统上的组件如hive、hbase等进行细粒度的数据访问控制,并解决授权和审计问题。通过操作Ranger控制台,管理员可以轻松的通过配置策略来控制用户访问HDFS文件夹、HDFS文件、数据库、表、字段权限。
优点:
提供了细粒度级(hive列级别)
基于访问策略的权限模型
权限控制插件式,统一方便的策略管理
支持审计日志,可以记录各种操作的审计日志,提供统一的查询接口和界面
丰富的组件支持(HDFS,HBASE,HIVE,YARN,KAFKA,STORM)
支持和kerberos的集成
提供了Rest接口供二次开发
选择Ranger的原因
多组件支持(HDFS,HBASE,HIVE,YARN,KAFKA,STORM),基本覆盖我们现有技术栈的组件
支持审计日志,可以很好的查找到哪个用户在哪台机器上提交的任务明细,方便问题排查反馈
拥有自己的用户体系,可以去除kerberos用户体系,方便和其他系统集成,同时提供各类接口可以调用
Ranger 使用了一种基于属性的方法定义和强制实施安全策略。当与 Apache Hadoop 的数据治理解决方案和元数据仓储组件Apache Atlas一起使用时,它可以定义一种基于标签的安全服务,通过使用标签对文件和数据资产进行分类,并控制用户和用户组对一系列标签的访问。
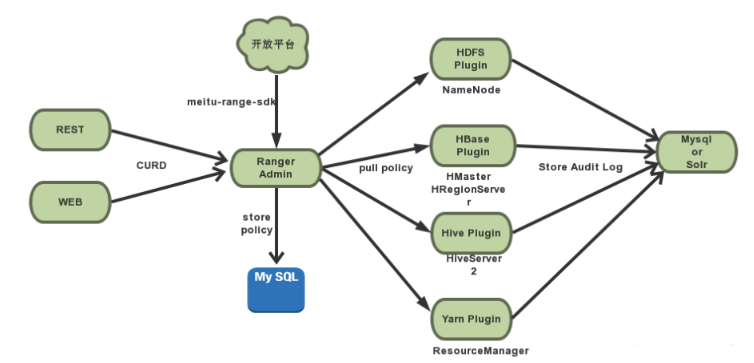
Ranger 的总体架构如下图所示,主要由以下三个组件构成:
RangerAdmin
以RESTFUL形式提供策略的增删改查接口,同时内置一个Web管理页面。
Service Plugin
嵌入到各系统执行流程中,定期从RangerAdmin拉取策略,根据策略执行访问决策树,并且记录访问审计
Ranger-SDK
对接开放平台,实现对用户、组、策略的管理
Ranger 安装部署
官网下载源码包
wget http://mirrors.tuna.tsinghua.edu.cn/apache/ranger/2.0.0/apache-ranger-2.0.0.tar.gz编译Ranger
# cd /home/apache-ranger-2.0.0
# mvn clean compile package assembly:assembly install -DskipTests -Drat.skip=true解压ranger-admin软件包
tar -zxvf ranger-2.0.0-admin.tar.gz 修改install.properties文件
# cd /home/ranger-2.0.0-SNAPSHOT-admin
vim install.properties
初始化ranger-admin
# cd /home/ranger-2.0.0-SNAPSHOT-adminvi setup.sh
./setup.sh
启动ranger-admin
# ranger-admin start 启动地址为http://locahost:6080,登录界面用户名和密码为:admin/admin
随后需要进行一些插件的安装:

随后就可以进行一些授权的操作了。
六、数据加密
6.1 Hadoop加密
HDFS支持原生静态加密,属于应用层加密。该方法中,数据被发送和到达存储位置之前,在应用层被加密。这种方法运行在操作系统层之上。
HDFS中,需要加密的目录被分解成若干加密区(encryption zone);
加密区中的每个文件都被使用唯一的数据加密密钥(data encryprion key,DEK)进行加密;
明文DEK不是永久的,而是用一个名为加密区密钥(encryption zone key,EZK)的区域级加密密钥,将DEK加密成加密DEK(encrypted DEK,EDEK);
EDEK作为指定文件NameNode元数据中的扩展属性永久存在。
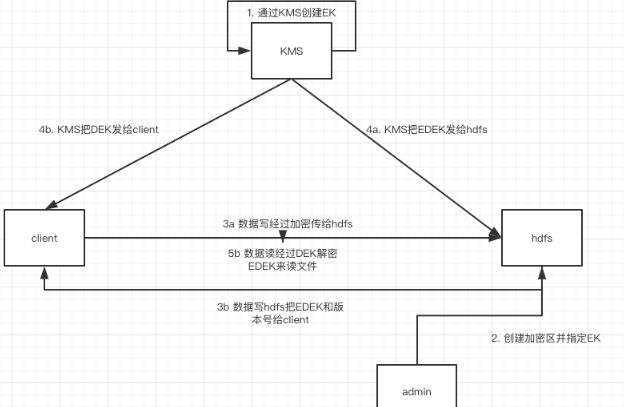
除了hdfs和client客户端之外,还有一个重要的出场角色是KMS。
KMS(key management server)密钥管理服务器,是一个在hadoop-common工程里,独立于hdfs的组件,它相当于一个管理密钥的服务器有自己的dao层和后端数据库,用来作为发放透明加密密钥的第三方。
KMS的密钥由特定权限的用户管理,权限也是独立于hdfs的,特权用户登陆后通过命令来创建密钥。
hadoop key create [keyName]
初始化加密区
这一步需要hdfs的特殊用户登陆操作,特殊用户首先创建要加密的加密区
hadoop fs -mkdir /data-encrypt
把这一目录的权限赋给普通用户hive
hadoop fs -chown hive:hive /data-encrypt
然后使用生成的密钥创建加密区
hdfs crypto -createZone -keyName [keyName] -path /data-encrypt 用户使用hdfs时,存到加密区的数据都会以数据块形式存储到hdfs节点的meta文件中,打开后是一堆乱码,而客户端用指令hadoop fs -cat还是get指令得到的都是明文,这就是端对端加密。我们可以通过以下方式得到加密文件的数据块。
hdfs fsck /data-encrypt -files -blocks -locations
6.2 字段加密与加密算法
前文也提到过,如果要想提高性能,并且支持更多灵活的组件,还是要使用字段级的加密方式。
我们先来了解一下常见的加密知识。
什么是数据加密 ?
数据加密 的基本过程,就是对原来为 明文 的文件或数据按 某种算法 进行处理,使其成为 不可读 的一段代码,通常称为 “密文”。通过这样的途径,来达到 保护数据 不被 非法人窃取、阅读的目的。
解密
加密 的 逆过程 为 解密,即将该 编码信息 转化为其 原来数据 的过程。
对称加密 和 非对称加密
加密算法分 对称加密 和 非对称加密,其中对称加密算法的加密与解密 密钥相同,非对称加密算法的加密密钥与解密 密钥不同,此外,还有一类 不需要密钥 的 散列算法。
常见的 对称加密 算法主要有
DES、3DES、AES等。 常见的 非对称算法 主要有RSA、DSA等。 常见的 散列算法 主要有SHA-1、MD5等。
直接学习原理比较晦涩,下面我们选几个常见的实战一下。
AES加密算法
高级加密标准(AES,Advanced Encryption Standard)为最常见的对称加密算法。
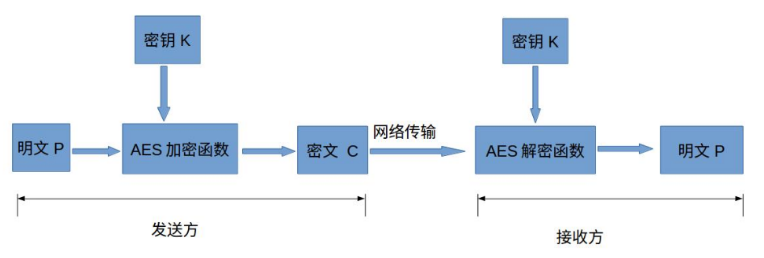
- 明文P
没有经过加密的数据。
- 密钥K
用来加密明文的密码,在对称加密算法中,加密与解密的密钥是相同的。
- AES加密函数
加密函数为E,则 C = E(K, P),其中P为明文,K为密钥,C为密文。也就是说,把明文P和密钥K作为加密函数的参数输入,则加密函数E会输出密文C。
- 密文C
经加密函数处理后的数据
- AES解密函数
设AES解密函数为D,则 P = D(K, C),其中C为密文,K为密钥,P为明文。也就是说,把密文C和密钥K作为解密函数的参数输入,则解密函数会输出明文P。
对称加密算法加密和解密用到的密钥是相同的,这种加密方式加密速度非常快,适合经常发送数据的场合。缺点是密钥的传输比较麻烦。
实际中,一般是通过RSA加密AES的密钥,传输到接收方,接收方解密得到AES密钥,然后发送方和接收方用AES密钥来通信。
Java版AES实现:
import javax.crypto.Cipher; import javax.crypto.KeyGenerator; import javax.crypto.SecretKey; import javax.crypto.spec.SecretKeySpec; import java.nio.file.Files; import java.nio.file.Path; import java.nio.file.Paths; import java.security.SecureRandom; import java.util.Base64;public class AESUtil {
private static final String ALGORITHM = "AES";//密钥的存放位置 private String keyUrl = "D:/aes.key"; /** * 生成密钥 * @return * @throws Exception */ private SecretKey geneKey() throws Exception { //获取一个密钥生成器实例 KeyGenerator keyGenerator = KeyGenerator.getInstance(ALGORITHM); SecureRandom random = SecureRandom.getInstance("SHA1PRNG"); random.setSeed("123456".getBytes());//设置加密用的种子,密钥,这个可不操作,固定了的话每次出来的密钥时一样的 keyGenerator.init(random); SecretKey secretKey = keyGenerator.generateKey(); //把上面的密钥存起来 Path keyPath = Paths.get(keyUrl); Files.write(keyPath, secretKey.getEncoded()); return secretKey; } /** * 读取存储的密钥 * @param keyPath * @return * @throws Exception */ private SecretKey readKey(Path keyPath) throws Exception { //读取存起来的密钥 byte[] keyBytes = Files.readAllBytes(keyPath); SecretKeySpec keySpec = new SecretKeySpec(keyBytes, ALGORITHM); return keySpec; } /** * 加密 */ public String encrypt(String encryptStr) throws Exception { //1、指定算法、获取Cipher对象 Cipher cipher = Cipher.getInstance(ALGORITHM);//算法是AES //2、生成/读取用于加解密的密钥 SecretKey secretKey = this.geneKey(); //3、用指定的密钥初始化Cipher对象,指定是加密模式,还是解密模式 cipher.init(Cipher.ENCRYPT_MODE, secretKey); //4、更新需要加密的内容 cipher.update(encryptStr.getBytes()); //5、进行最终的加解密操作 byte[] result = cipher.doFinal();//加密后的字节数组 //也可以把4、5步组合到一起,但是如果保留了4步,同时又是如下这样使用的话,加密的内容将是之前update传递的内容和doFinal传递的内容的和。// byte[] result = cipher.doFinal(content.getBytes());
String base64Result = Base64.getEncoder().encodeToString(result);//对加密后的字节数组进行Base64编码
return base64Result;
}/** * 解密 */ public String decrpyt(String desrpytStr) throws Exception { Cipher cipher = Cipher.getInstance(ALGORITHM); Path keyPath = Paths.get(keyUrl); SecretKey secretKey = this.readKey(keyPath); cipher.init(Cipher.DECRYPT_MODE, secretKey); byte[] encodedBytes = Base64.getDecoder().decode(desrpytStr.getBytes()); byte[] result = cipher.doFinal(encodedBytes);//对加密后的字节数组进行解密 return new String(result); } public static void main(String[] args) throws Exception { AESUtil aesUtil = new AESUtil(); String enctyptStr = aesUtil.encrypt("bigdata"); System.err.println(enctyptStr); String decrpytStr = aesUtil.decrpyt(enctyptStr); System.err.println(decrpytStr); }
}
RSA加密算法
RSA加密算法是目前应用最广泛的公钥加密算法。RSA加密算法是1978年提出的。经过多年的分析和研究,在众多的公开密钥加密算法中,RSA加密算法最受推崇,它也被推荐为公开密钥数据加密标准。
RSA 加密算法 基于一个十分简单的数论事实:将两个大 素数 相乘十分容易,但想要对其乘积进行 因式分解 却极其困难,因此可以将 乘积 公开作为 加密密钥。
RSA加密算法是非对称加密算法,非对称加密算法的加密和解密用的密钥是不同的,这种加密方式是用数学上的难解问题构造的,通常加密解密的速度比较慢,适合偶尔发送数据的场合。优点是密钥传输方便。常见的非对称加密算法为RSA、ECC和EIGamal。
Java版RSA实现:
import java.io.UnsupportedEncodingException;
import java.security.*;
import java.security.spec.InvalidKeySpecException;
import java.security.spec.PKCS8EncodedKeySpec;
import java.security.spec.X509EncodedKeySpec;
import java.util.Base64;public static void main(String[] args) throws NoSuchAlgorithmException, InvalidKeySpecException,
InvalidKeyException, SignatureException, UnsupportedEncodingException {
// 生成秘钥
KeyPairGenerator keyGen = KeyPairGenerator.getInstance("RSA");
SecureRandom random = SecureRandom.getInstance("SHA1PRNG");
keyGen.initialize(2048, random);
KeyPair pair = keyGen.generateKeyPair();PrivateKey priv = pair.getPrivate(); PublicKey pub = pair.getPublic(); String privStr = Base64.getEncoder().encodeToString(priv.getEncoded()); String pubStr = Base64.getEncoder().encodeToString(pub.getEncoded()); // 字符串转秘钥对象 PrivateKey privKey = getPrivateKey(privStr); PublicKey pubKey = getPublicKey(pubStr); String plaintext = "私钥签名测试"; // 私钥签名 Signature rsaPrivSig = Signature.getInstance("SHA1withRSA"); rsaPrivSig.initSign(privKey); rsaPrivSig.update(plaintext.getBytes("UTF-8")); byte[] privSign = rsaPrivSig.sign(); String privSignStr = Base64.getEncoder().encodeToString(privSign); // 公钥验签 Signature rsaPubSig = Signature.getInstance("SHA1withRSA"); rsaPubSig.initVerify(pubKey); rsaPubSig.update(plaintext.getBytes("UTF-8")); boolean verifies = rsaPubSig.verify(Base64.getDecoder().decode(privSignStr)); System.out.println("signature verifies: " + verifies); }</code></pre></div></div><h5 id="37ebs" name="MD5%E5%8A%A0%E5%AF%86%E7%AE%97%E6%B3%95">MD5加密算法</h5><p>MD5是一种数据散列处理算法。</p><p>数据散列处理是指Hash一类的处理,算法有<em style="font-style:italic">md5</em>, <em style="font-style:italic">sha1</em>, <em style="font-style:italic">sha-256</em>以及更高位数的散列算法。它有个显著特征是雪崩效应,原文稍有改变,算出来的值就会完全不同。Hash是一种摘要算法,同一种hash算法,针对不同的输入,输出的位数是固定的,所以hash存在碰撞的可能。在用于数据加密的时候,如果存在<em style="font-style:italic">hash碰撞</em>,就会导致数据丢失,一个明文会覆盖另一个明文。</p><p>MD5的Java实现例子:</p><div class="rno-markdown-code"><div class="rno-markdown-code-toolbar"><div class="rno-markdown-code-toolbar-info"><div class="rno-markdown-code-toolbar-item is-type"><span class="is-m-hidden">代码语言:</span>javascript</div></div><div class="rno-markdown-code-toolbar-opt"><div class="rno-markdown-code-toolbar-copy"><i class="icon-copy"></i><span class="is-m-hidden">复制</span></div></div></div><div class="developer-code-block"><pre class="prism-token token line-numbers language-javascript"><code class="language-javascript" style="margin-left:0">public class MD5 {public final static String encode(String str) {
return encodeMd5(str);}
private final static String encodeMd5(String s) {
char hexDigits[] = { '0', '1', '2', '3', '4', '5', '6', '7', '8', '9','A', 'B', 'C', 'D', 'E', 'F' };
try {
byte[] btInput = s.getBytes();MessageDigest mdInst = MessageDigest.getInstance("MD5");
mdInst.update(btInput);
byte[] md = mdInst.digest();
int j = md.length;
char str[] = new char[j * 2];
int k = 0;
for (int i = 0; i < j; i++) {
byte byte0 = md[i];str[k++] = hexDigits[byte0 >>> 4 & 0xf];
str[k++] = hexDigits[byte0 & 0xf];
}
return new String(str);
} catch (Exception e) {
e.printStackTrace();return null;
}
}
public static void main(String agrs[]) {
String md2 = encode("123456");System.out.println(md2);
}
}
说了半天还没有一个结论,由于散列的不可逆,导致如果需要还原明文,它的代价就非常大,映射表的维护是极其麻烦的事情,而且备份和安全性都不好处理。
而非对称加密的性能很差,非对称加密适合对密钥的保护。
而敏感信息的加密还是使用对称加密算法比较好,在AES加密里,我们可以把加密解密放在UDF里,只需做好秘钥Key的管理即可。
未完待续~