大家好,又见面了,我是你们的朋友全栈君。
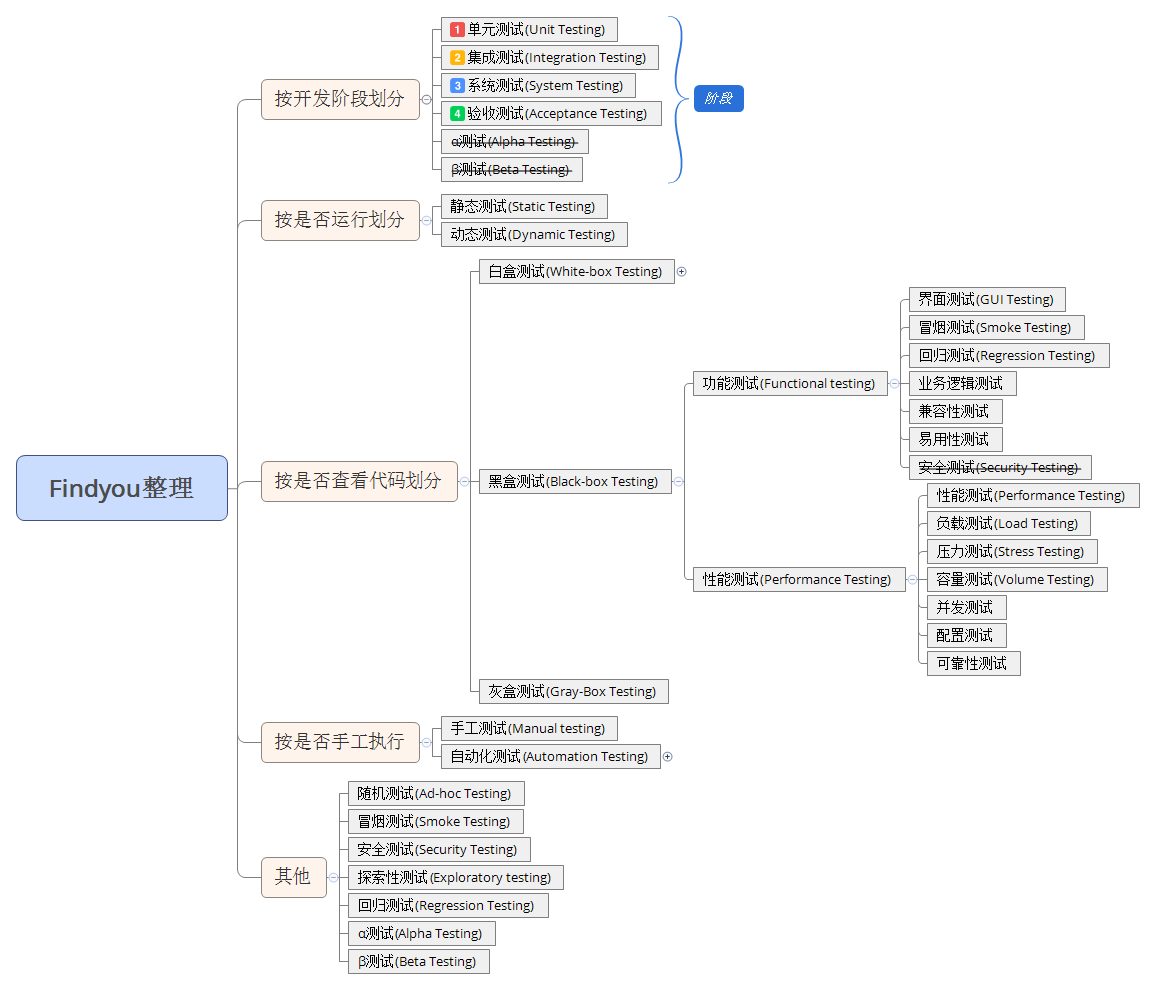
1.软件测试级别?
单元测试:单元测试是对软件组成单元进行测试。其目的是检验软件基本组成单位的正确性。测试的对象是软件设计的最小单位:模块。Findyou又称为模块测试,一个单元测试是用于判断某个特定条件(或者场景)下某个特定函数的行为。(测试内容:模块接口测试、局部数据结构测试、路径测试、错误处理测试、边界测试)
集成测试:(集成测试也称联合测试、组装测试,将程序模块采用适当的集成策略组装起来,对系统的接口及集成后的功能进行正确性检测的测试工作。主要目的是检查软件单位之间的接口是否正确。方法是测试片段的组合,并最终扩展进程,将您的模块与其他组的模块一起测试。最后,将构成进程的所有模块一起测试。测试内容:模块之间数据传输、模块之间功能冲突、模块组装功能正确性、全局数据结构、单模块缺陷对系统的影响
系统测试:将软件系统看成是一个系统的测试。包括对功能、性能以及软件所运行的软硬件环境进行测试。系统测试的目的是对最终软件系统进行全面的测试,确保最终软件系统满足产品需求并且遵循系统设计。测试内容:功能、界面、可靠性、易用性、性能、兼容性、安全性等
验收测试:验收测试是部署软件之前的最后一个测试操作。它是技术测试的最后一个阶段,也称为交付测试。总结验收测试的目的是确保软件准备就绪,按照项目合同、任务书、双方约定的验收依据文档,向软件购买都展示该软件系统满足原始需求。验收测试的目的是确保软件准备就绪,并且可以让最终用户将其用于执行软件的既定功能和任务,即软件的功能和性能如同用户所合理期待的那样。测试内容:同系统测试(功能…各类文档等)
2.软件测试类型?
功能测试:也叫黑盒测试,功能测试指测试软件各个功能模块是否正确,逻辑是否正确。对测试对象的功能测试应侧重于所有可直接追踪到用例或业务功能和业务规则的测试需求。这种测试的目标是核实数据的接收、处理和检索是否正确,以及业务规则的实施是否恰当。此类测试基于黑盒技术,该技术通过图形用户界面(GUI) 与应用程序进行交互,并对交互的输出或结果进行分析,以此来核实应用程序及其内部进程。功能测试的主要参考为类似于功能说明书之类的文档。
性能测试:指验证软件的性能可以满足系统规格给定的指定要求的性能指标。性能测试是一个比较大的范围,可以进一步衍生出负载测试、强度测试、压力测试、稳定性测试。通过自动化测试工具模拟多种正常、异常、峰值条件,对系统各项性能指标测试
配置测试:用硬件来测试软件运行情况,1.软件在不同主机上运行的情况(Apple和Dell)2.在不同组件上运行情况(开发的拨号程序要测试不同厂商生产的Moden上运行情况)3.不同的外设、接口、内存的运行情况
强度测试:强度测试是一种性能测试,他在系统资源特别低的情况下软件系统运行情况。这类测试往往可以书写系统要求的软硬件水平要求。实施和执行此类测试的目的是找出因资源不足或资源争用而导致的错误。如果内存或磁盘空间不足,测试对象就可能会表现出一些在正常条件下并不明显的缺陷。而其他缺陷则可能由于争用共享资源(如数据库锁或网络带宽)而造成的。强度测试还可用于确定测试对象能够处理的最大工作量。
负载测试:通过在被测系统上不断加压,直到性能指标达到极限,例如“响应时间”超过预定指标或都某种资源已经达到饱和状态。负载测试是一种性能测试指数据在超负荷环境中运行,程序是否能够承担。在这种测试中,将使测试对象承担不同的工作量,以评测和评估测试对象在不同工作量条件下的性能行为,以及持续正常运行的能力。负载测试的目标是确定并确保系统在超出最大预期工作量的情况下仍能正常运行。此外,负载测试还要评估性能特征,例如,响应时间、事务处理速率和其他与时间相关的方面。
压力测试:压力测试方法测试系统在一定饱和状态下,例如cpu、内存在饱和使用情况下,系统能够处理的会话能力,以及系统是否会出现错误。测试出系统所能承受的最大极限。是指系统在极限下的压力情况,系统在什么样的压力下会导致系统得到失效,无法正常运行。100个用户连续访问1小时可以看做是压力测试,连续访问10小时可以认为是负载测试
稳定性测试:压力测试方法测试系统在一定饱和状态下,例如cpu、内存在饱和使用情况下,系统能够处理的会话能力,以及系统是否会出现错误。一般是稍大于业务量的一个负载,对系统进行的一个持续的,长时间的测试,比如24*3,连续3天的施加压力,确定系统在较长运行时间的情况下,系统的稳定性情况
网络测试:wifi、4G、3G、不同运营商网络测试、
UI界面测试:UI测试指测试用户界面的风格是否满足客户要求,文字是否正确,页面美工是否好看,文字,图片组合是否完美,背景是否美观,操作是否友好等等。
分辨率测试:测试在不同分辨率下,界面的美观程度,分为800*600,1024*768,1152*864,1280*768,1280*1024,1200*1600大小字体下测试。一个好的软件要有一个极佳的分辨率,而在其他分辨率下也都能可以运行。
安装测试:安装测试有两个目的。第一个目的是确保该软件在正常情况和异常情况的不同条件下: 例如,进行首次安装、升级、完整的或自定义的安装_都能进行安装。异常情况包括磁盘空间不足、缺少目录创建权限等。第二个目的是核实软件在安装后可立即正常运行。这通常是指运行大量为功能测试制定的测试。
内存测试:CPU测试、响应时间测试、唤醒率测试等,都属于性能测试。还有强度测试、容量测试、基准测试等。
文档测试:文档测试是检验样品用户文档的完整性、正确性、一致性、易理解性、易浏览性。包括用户手册、使用说明、用户帮助文档等
可靠性测试:这个主要是硬件方面的,比如高低温测试、防水防尘等测试
安全测试:对产品进行检验以验证产品符合安全需求定义和产品质量标准的过程。可确保只有具备系统访问权限的用户才能访问应用程序,而且只能通过相应的网管、关来访问。比如输入管理员账户,检查其密码是否容易猜取,或者可以从数据库中获得?
兼容测试:检查软件在不同软件、硬件平台是否可以正常运行。 主要查看在不同操作系统、浏览器、数据库、不同版本是否正常运行、向前兼容和向后兼容、、数据共享兼容
浏览器兼容性测试:测试软件在不同产商的浏览器下是否能够正确显示与运行、比如测试IE,Natscape浏览器
操作系统兼容性:测试软件在不同操作系统下是否能够正确显示与运行;比如测试WINDOWS98,WINDOWS 2000,WINDOWS XP,LINU, UNIX下是否可以运行这套软件?
硬件兼容性
测试与硬件密切相关的软件产品与其他硬件产品的兼容性,比如该软件是少在并口设备中的,测试同时使用其他并口设备,系统是否可以正确使用。比如在INTER,舒龙CPU芯片下系统是否能够正常运行?
并发测试:并发测试方法通过模拟用户并发访问,测试多用户并发访问同一个应用、同一个模块或者数据记录时是否存在死锁或其者他性能问题。也就是说,这种测试关注点是多个用户同时(并发)对一个模块或操作进行加压。
3.测试方法:动态测试、静态测试;黑盒测试、白盒测试、灰盒测试。
、黑盒测试方法:
1>等价类划分:等价类划分是将系统的输入域划分为若干部分,然后从每个部分选取少量代表性数据进行测试。等价类可以划分为有效等价类和无效等价类,设计测试用例的时候要考虑这两种等价类。
2>边界值分析法:边界值分析法是对等价类划分的一种补充,因为大多数错误都在输入输出的边界上。边界值分析就是假定大多数错误出现在输入条件的边界上,如果边界附件取值不会导致程序出错,
那其他取值出错的可能性也就很小。
边界值分析法是通过优先选择不同等价类间的边界值覆盖有效等价类和无效等价类来更有效的进行测试,因此该方法要和等价类划分法结合使用。
3>错误猜测法:错误猜测法主要是针对系统对于错误操作时对于操作的处理法的猜测法,从而设计测试用例
3、白盒测试方法:
1>语句覆盖:就是设计若干个测试用例,运行被测程序,使得每一个可执行语句至少执行一次。
2>判定覆盖:使设计的测试用例保证程序中每个判断的每个取值分支至少经历一次。
3>条件覆盖:条件覆盖是指选择足够的测试用例,使得运行这些测试用例时,判定中每个条件的所有可能结果至少出现一次,但未必能覆盖全部分支
4>判定条件覆盖:判定-条件覆盖就是设计足够的测试用例,使得判断中每个条件的所有可能取值至少执行一次,同时每个判断的所有可能判断结果至少执行,即要求各个判断的所有可能的条件取值组合至少执行一次。
5>条件组合覆盖:在白盒测试法中,选择足够的测试用例,使所有判定中各条件判断结果的所有组合至少出现一次,满足这种覆盖标准成为条件组合覆盖。
6>路径覆盖:是每条可能执行到的路径至少执行一次
灰盒测试 定义:介于黑、白盒测试之间的,关注输出对于输入的正确性,同时也关注内部表现
静态测试 1,静态测试是指无需执行被测程序,而是通过评审软件文档或代码,度量程序静态复杂度,检查软件是否符合编程标准,借以发现编写的程序的不足之处,减少错误出现的概率
动态测试 1,动态测试是指通过运行被测程序,检查运行结果和预期结果的差异,并分析运行效率,正确性和健壮性等
2,静态(看外观)和动态(发动车走一段路)可以用买车来说明
手工测试 由专门的测试人员从用户视角来验证软件是否满足设计要求的行为。 更适用针对深度的测试和强调主观判断的测试 比如:众包测试和探索式测试
自动化测试 1.适用单独的测试工具软件控制测试的自动化执行以及对预期和结果进行自动检查。
2.手工测试和自动化测试的区别?
手动测试:优点:易发现缺陷、容易实施、灵活性 缺点:覆盖量低、重复测试效率低、可靠性低、人力资源依赖
自动化测试:优点:高效率,速度快、高复用性、覆盖率高、准确可靠、不知疲劳 缺点:机械发现缺陷率低、一次性投入大
安全测试
安全测试是在IT软件产品的生命周期中,特别是产品开发基本完成到发布阶段,对产品进行检验以验证产品符合安全需求定义和产品质量标准的过程 。
Findyou觉现在对安全知识的普及,大家意识都提上来了。比如现在越来越多的不支持HTTP协议,转用HTTPS等。
探索性测试
探索性测试可以是一种测试思维技术。它没有很多实际的测试方法、技术和工具,但是却是所有测试人员都应该掌握的一种测试思维方式。探索性强调测试人员的主观能动性,抛弃繁杂的测试计划和测试用例设计过程,强调在碰到问题时及时改变测试策略
随机测试
随机测试主要是根据测试者的经验对软件进行功能和性能抽查。
根据测试说明书执行用例测试的重要补充手段,是保证测试覆盖完整性的有效方式和过程。
随机测试主要是对被测软件的一些重要功能进行复测,也包括测试那些当前的测试用例(TestCase)没有覆盖到的部分。
冒烟测试
关于冒烟测试,就是开发人员在个人版本的软件上执行目前的冒烟测试项目,确定新的程序代码不出故障。冒烟测试目的是确认软件基本功能正常,现基本执行对象为测试人员,在正规测试一个新版本之前,投入较少的人力和时间验证基本功能,通过则测试准入。
α测试
α测试是由一个用户在开发环境下进行的测试,也可以是公司内部的用户在模拟实际操作环境下进行的测试。α测试的目的是评价软件产品的FLURPS(即功能、局域化、可使用性、可靠性、性能和支持)。
大型通用软件,在正式发布前,通常需要执行Alpha和Beta测试。α测试不能由程序员或测试员完成。
β测试
Beta测试是一种验收测试。Beta测试由软件的最终用户们在一个或多个客房场所进行。
4.alpha测试和beta测试的区别
1、测试时间不同:
Beta测试是软件产品完成了功能测试和系统测试之后,产品发布之前所进行的软件测试活动,它是技术测试的最后一个阶段。
alpha测试简称“α测试”,可以从软件产品编码结束之时开始,或在模块(子系统)测试完成之后开始,也可以在确认测试过程中产品达到一定的稳定和可靠程度之后再开始。
2、测试的目的不同:
α测试的目的是评价软件产品的(即功能、局域化、可用性、可靠性、性能和支持)。尤其注重产品的界面和特色。α测试即为非正式验收测试。
Beta测试是一种验收测试,通过了验收测试,产品就会进入发布阶段。
测试人员及场所不同:
α测试是由一个用户在开发环境下进行的测试,也可以是公司内部的用户在模拟实际操作环境下进行的受控测试,α测试不能由程序员或测试员完成。α测试发现的错误,可以在测试现场立刻反馈给开发人员,由开发人员及时分析和处理。
Beta测试由软件的最终用户们在一个或多个客户场所进行。开发者通常不在Beta测试的现场,因Beta测试是软件在开发者不能控制的环境中的“真实”应用。
5.测试设计方法:
等价类划分、边界值、因果图划分、正交、场景、随机、错误推断、测试大纲
等价类划分法: : 1:有效等价类: 2:无效等价类:
案例:比如一个登陆输入框,规定只能输入中文,同时长度为6-10,
通过等价类设计测试用例:
测试用例中重要的三步: 输入 操作 预计结果 如果与预期结果不符合就是bug
有效等价类: 输入:输入长度为6的中文,输入的为王小明,这就是有效等价类
无效等价类:
1: 输入长度为4的中文,输入位小名,点击登录,预计结果长度不符合要求
2: 输入长度为6,但是是英文的,点击登录,预计结果 请输入中文
3: 输入长度为4,而且不是中文的,是数字,1234,点击登录,预计结果请输入中文并且长度为6-10位
4:输入长度为12而且不是中文的,比如qwertyuiopas,点击登录,预计结果请输入中文并且长度为6-10位
二:边界值法:
应用场景:边界值往往和等价类划分法一起使用,形成一套更为完善的测试方案,找到有效数据和无效数据的分界点,
注解边界值一般和有效等价类划分法配合使用:
案例:比如一个登陆输入框,规定只能输入中文,同时长度为6-10,
上面输入框的边界的:如果固定大于等于6,并且小于等于10,
那左边界就是 5和 6
右边界是:10 和 11
测试用例:
1:输入的为王小明,这就是有效等价类和边界值的结合使用
2:输入小名,这就是边界值为5,同时有效等价类
3:输入欧阳致远家,这就是边界值10,同时等价类有效
4:输入欧阳致远啦啦,这就是边界值为11,同时有效等价类
三:因果图及判定表法:
应用场景:在一个界面中有多个控件,如果控件之间有组合关系或者限制关系,不同的控件组合会产生不同的输入结果,为了弄清楚不同的输入组合会产生咋样的输出结果,可以使用因果图及判定表法:
判断是儿童还是青年还是成年人:
条件1:年龄 age
条件2:身高height
条件3:体重weight
输入年龄5,体重80公斤,身高170,查无此人
输入提高80,身高170,输入年龄20,成年人
输入年龄5,体重30,身高60,小孩
四:正交表:
应用场景:在一个界面中有多个控件,每个控件有多个取值,测试时考虑不同的控件不同取值之间的多种组合,但组合数量巨大(>20种,20种以下一般考虑判定表因果图),没有必要全部测试,如何从所有的组合中挑选最少、最优的组合进行测试,可以使用正交排列法。
正交表的测试思想特点:
1)使用每个控件的每个取值参与组合的次数是基本相等的(均匀的)
2)在所有的组合数据中,选取数据时,应该均匀的选取,而不能从局部选取。
3)如果时间允许,尽可能的多测一些组合
正交表:主要针对一个输入框里面可能有多个值,而且数量巨大
年龄 体重 省 市 县
比如:输入年龄 18,体重45,山西 大同 阳高
五:测试大纲法
适用场合:程序包含多个窗口,每个窗口中又有多个功能,这些功能之间又有一定的联系。为了梳理清楚窗口之间以及窗口不同功能之间的联系,使用测试大纲法。
六:场景法
适用场合:大多数的业务比较复杂的软件系统都适合使用场景法(便于将各个功能点串起来,便于形成完整的业务感觉)是一种基于软件业务的测试方法,把自己当成最终用户,尽可能的模拟用户在使用此软件的操作
案例:
场景一:比如买东西:输入袜子,点击查询,出现列表,点击七匹狼,点击进入详情,点击加入购物车,点击去购物车结算,点击收获地址,点击支付,支付成功
场景二:比如买东西:输入袜子,点击查询,出现列表,点击七匹狼,点击进入详情,点击加入购物车,点击去购物车结算,点击收获地址,点击取消支付
七: 错误推断法
基于经验和直觉推测程序中所有可能存在的各种错误 , 从而有针对性的设 计测试用例的方法
在进行灰盒测试的时候经常用到此方法
八:随机测试
随意测试,不考虑任何用例和需求,完全站在一个用户或者的角度对产品进行使用。
适用场景:
1) 所有之前设定的用例已经 执行完毕
2)海量的条件组合无法一遍 历的时候
6.软件测试风险:
测试人员:业务不熟、人员变动、疲态、同化效应、定位效应
测试材料:需求变更、质量标准不一样、测试用例或测试数据设计不充分
测试环境:测试软件版本不统一、软件环境不统一、硬件环境不统一、硬件不到位
测试时间:测试时间不足、测试时间延长
测试方法:错误或缺失测试方法、场景缺失、测试用例实施不充分
7.自动化测试软件作用(重点):
一:jmeter: 纯java编写负载功能测试和性能测试开源工具, 支持接口自动化测试,录制、抓包、可进行压力测试(增加线程,考验服务器最大支持访问数)、弱网测试、添加请求、添加断言,查看断言、结果树,聚合报告,分析测试报告等
聚合报告参数详解: 1. Label:每个 JMeter 的 element(例如 HTTP Request)都有一个 Name 属性,这里显示的就是 Name 属性的值 2. Samples:请求数——表示这次测试中一共发出了多少个请求,如果模拟10个用户,每个用户迭代10次,那么这里显示100 3. Average:平均响应时间——默认情况下是单个 Request 的平均响应时间 4. Median:中位数,也就是 50% 用户的响应时间 5. 90% Line:90% 用户的响应时间 6. Min:最小响应时间 7. Max:最大响应时间 8. Error%:错误率——错误请求数/请求总数 9. Throughput:吞吐量——默认情况下表示每秒完成的请求数(Request per Second) 10. KB/Sec:每秒从服务器端接收到的数据量,相当于LoadRunner中的Throughput/Sec
二:ant: 将软件编译、测试、部署等步骤联系在一起加以自动化的一个工具,并生成测试报告并发送
三:jenkins: Jenkins是一个开源CI服务器,基于Web访问,jenkins是基于Java开发的一种持续集成工具,用于监控持续重复的工作,能实时监控集成中存在的错误,提供详细的日志文件和提醒功能,还能用图表的形式形象地展示项目构建的趋势和稳定性,拥有大量的插件:这些插件极大的扩展了Jenkins的功能,持续集成工具,所有工作都是自动完成的,无需太多的人工干预,有利于减少重复过程以节省时间和工作量;
四:monkey:它是Android SDK系统自带一个命令行工具,可以运行在模拟器里或者真是设备中运行。向系统发送伪随机的用户事件流,实现对正在开发的应用程序进行稳定性测试。
五:charles: 1.抓包(http、https):设置手机HTTP代理、https charles也需要证书
2.弱网测试:通过Throttle Settings(网络控制)、Enable Throttling(启用设置)、Throttle preset(通过预设网络值来拟定网络)、设置网络带宽值等
3.网络请求的截取并动态修改:
4.压力测试:通过右键点击链接,Repeat Advanced(重复),选择Iterations(重复次数)Concurrency(并发数)
5.数据替换:通过链接右键点击Map Local(本地位置)进入设置,选择替换数据文件,替换即可
六:selenium :web自动化测试框架(测试浏览器兼容性的自动化)selenium不支持桌面软件自动化测试。软件测试报告,和用例管理只能依赖第三方插件unittest优点:兼容更多的平台( Windows、Linux 、 Macintosh等)以及浏览器(火狐,IE,谷歌等)
定位元素方式:id、name、class_name、tagname、link_text、partial_link_text、xpath、css_selector
强制等待:sleep()强制等待,不管你浏览器是否加载完,程序都得等待
显示等待:WebDriverWait,配合该类的until()和until_not()方法,就能够根据判断条件而进行灵活地等待了.它主要的意思就是:程序每隔多久查看一次,如果条件成立了,则执行下一步,否则继续等待,直到超过设置的最长时间,然后抛出TimeoutException
隐式等待:implicitly_wait(),整个driver周期有效,如果在规定时间内网页加载完成,则执行下一步,否则一直等到时间截止
七:appium:开源测试自动化框架,可用于原生,混合和移动Web应用程序测试
两大组件:
一:Appium Server就是Appium的服务端——一个web接口服务,使用Node.js实现。
二:Appium Desktop是一款适用于Mac,Windows和Linux的开源应用程序,提供Appium自动化服务器的强大功能。
Appium GUI是Appium desktop的前身。 也就是把Appium server封装成了一个图形界面,降低了使用门槛。
因为Appium是一个C/S结构,有了服务端的肯定还有客户端,Appium Clients就是客户端,它会给服务端Appium Server发送请求会话来执行自动化任务。
Appium-desktop主界面包含三个菜单:
Simple
- host:设置Appium server的ip地址,本地调试可以将ip地址修改为127.0.0.1
- port:设置端口号,默认是4723不用修改
- start server:启动 Appium server
Advanced:高级参数配置修改,主要是Android和iOS设备,log路径等相关信息的配置。
Presets:将Advanced中的一些配置信息作为预设配置。
八:pytest:pytest是一个全功能的Python测试框架,
优点:
- 1、简单灵活,容易上手,文档丰富;
- 2、支持参数化,可以细粒度地控制要测试的测试用例;
- 3、能够支持简单的单元测试和复杂的功能测试,还可以用来做selenium/appnium等自动化测试、接口自动化测试(pytest+requests);
- 4、pytest具有很多第三方插件,并且可以自定义扩展,比较好用的如pytest-selenium(集成selenium)、pytest-html(完美html测试报告生成)、pytest-rerunfailures(失败case重复执行)、pytest-xdist(多CPU分发)等;
- 5、测试用例的skip和xfail处理;
- 6、可以很好的和CI工具结合,例如jenkins
编写规则:
- 测试文件以test_开头(以_test结尾也可以)
- 测试类以Test开头,并且不能带有 init 方法
- 测试函数以test_开头
- 断言使用基本的assert即可
# -*- coding:utf-8 -*- import pytest@pytest.fixture(scope='function')
def setup_function(request):
def teardown_function():
print("teardown_function called.")
request.addfinalizer(teardown_function) # 此内嵌函数做teardown工作
print('setup_function called.')@pytest.fixture(scope='module')
def setup_module(request):
def teardown_module():
print("teardown_module called.")
request.addfinalizer(teardown_module)
print('setup_module called.')@pytest.mark.website
def test_1(setup_function):
print('Test_1 called.')def test_2(setup_module):
print('Test_2 called.')
def test_3(setup_module):
print('Test_3 called.')
assert 2==1+1 # 通过assert断言确认测试结果是否符合预期
fixture的scope参数
scope参数有四种,分别是’function’,’module’,’class’,’session’,默认为function。
- function:每个test都运行,默认是function的scope
- class:每个class的所有test只运行一次
- module:每个module的所有test只运行一次
- session:每个session只运行一次
setup和teardown操作
- setup,在测试函数或类之前执行,完成准备工作,例如数据库链接、测试数据、打开文件等
- teardown,在测试函数或类之后执行,完成收尾工作,例如断开数据库链接、回收内存资源等
- 备注:也可以通过在fixture函数中通过yield实现setup和teardown功能
九:unitest: unittest单元测试框架不仅可以适用于单元测试,还可以适用WEB自动化测试用例的开发与执行,该测试框架可组织执行测试用例,并且提供了丰富的断言方法,判断测试用例是否通过,最终生成测试结果
unittest.TestCase:TestCase类,所有测试用例类继承的基本类: class BaiduTest(unittest.TestCase)
unittest.main():将一个单元测试模块变为可直接运行的测试脚本,main()方法使用TestLoader类来搜索所有包含在该模块中以“test”命名开头的测试方法并自动执行他们。
unittest.TestSuite():unittest框架的TestSuite()类是用来创建测试套件的。
unittest.TextTextRunner():unittest框架的TextTextRunner()类,通过该类下面的run()方法来运行suite所组装的测试用例。
unittest.defaultTestLoader(): defaultTestLoader()类,通过该类下面的discover()方法可自动更具测试目录start_dir匹配查找测试用例文件(test*.py),并将查找到的测试用例组装到测试套件,因此可以直接通过run()方法执行discover。用法如下:discover=unittest.defaultTestLoader.discover(test_dir, pattern=’test_*.py’)
unittest.skip():装饰器,当运行用例时,有些用例可能不想执行等,可用装饰器暂时屏蔽该条测试用例。一种常见的用法就是比如说想调试某一个测试用例,想先屏蔽其他用例就可以用装饰器屏蔽。
TestCase类的属性:
setUp():setUp()方法用于测试用例执行前的初始化工作。如测试用例中需要访问数据库,可以在setUp中建立数据库连接并进行初始化。如测试用例需要登录web,可以先实例化浏览器。
tearDown():tearDown()方法用于测试用例执行之后的善后工作。如关闭数据库连接。关闭浏览器。
assert*():一些断言方法:在执行测试用例的过程中,最终用例是否执行通过,是通过判断测试得到的实际结果和预期结果是否相等决定的。
TestSuite类的属性:
addTest(): addTest()方法是将测试用例添加到测试套件中,是将test_baidu模块下的BaiduTest类下的test_baidu测试用例添加到测试套件。 suite = unittest.TestSuite() suite.addTest(test_baidu.BaiduTest(‘test_baidu’))
TextTextRunner的属性:
run(): run()方法是运行测试套件的测试用例,入参为suite测试套件: runner = unittest.TextTestRunner() runner.run(suite)
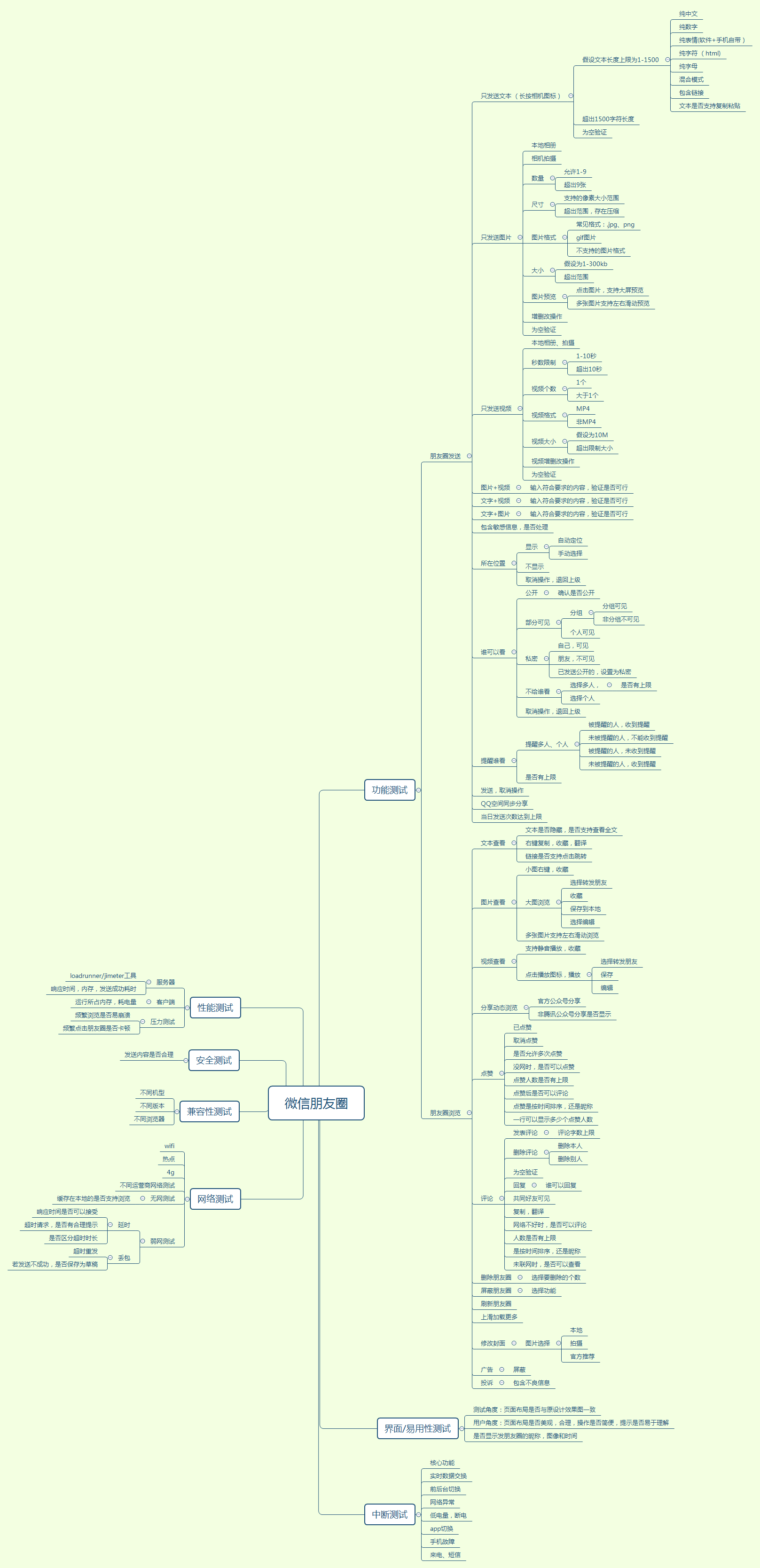
微信朋友圈测试用例:
8.po模型?
selenium自动用例脚本,相似功能地方,代码基本都是一样的,界面元素换个查找方式,把原来的使用 xpath方式,改为使用 id 查找,需要对每个用例脚本都要改,虽然几个用例看不出什么工作量,但是重复findElement的代码,已经让我们感到了代码的笨重。如果某些定位发生了改变,我们就得贯穿整个测试代码进行调整元素定位,这样就会导致我们的脚本在后期,难以维护。
因此通过Page Object Model 我们可以创建更加健壮代码,并减少或者消除重复的测试代码,从而也能够提高代码的可读性,减少编写脚本的工作量。Page Object Model的实现,就是通过分离测试对象和测试脚本的抽象来实现的。简单来说就是代码的封装,将测试方法进行封装对外暴露方法实现调用,在调用界面直接调用某个方法输入具体元素值以及内容。
9.Bug的生命周期?新建,提交,确认,分配,修复,验证,关闭
10.软件开发过程中的角色分工?(测试的主要工作)
测试配合开发等进行需求分析和讨论,根据需求说明书指定《项目测试计划》,编写测试用例,建立测试环境。
测试负责新产品测试,原有产品的升级测试,负责软件问题解决过程跟踪,软件开发文档、开发工作的规范化,管理开发部 门的产品文档,制作用户手册、操作手册,产品上限测试,监督软件开发过程执行,提高软件质量。
11.缺陷(bug)等级分类?
致命:测试过程死机、系统崩溃、数据跌势、功能没有实现
严重:导致软件功能不稳定、功能实现错误、流程错误
一般:校验错误、罕见故障、错别字,不影响功能,影响体验
低级:没影响的小问题
12.使用bugzilla缺陷管理工具对软件缺陷(BUG)跟踪的管理的流程?
答:1) 测试人员或开发人员发现bug后,判断属于哪个模块的问题,填写bug报告后,系统会自动通过Email通知项目组长或直接通知开发者。
2) 经验证无误后,修改状态为VERIFIED(已证实).待整个产品发布后,修改为CLOSED(关闭)
3) 还有问题,REOPENED(重新打开),状态重新变为“New”,并发邮件通知。
4) 项目组长根据具体情况,重新分配给bug所属的开发者。
5) 若是,进行处理,断言并给出解决方法。(可创建补丁附件及补充说明)
6) 开发者收到Email信息后,判断是否为自己的修改范围。
7) 若不是,重新分配给项目组长或应该分配的开发者。
8) 测试人员查询开发者已修改的bug,进行重新测试。确认无误后,关闭该bug。
13.缺陷报告由哪些组成?(测试报告,测试用例)
缺陷编号、日期、缺陷标题、 缺陷优先程度、缺陷所属模块、缺陷所属版本、执行流程、预计结果、输出结果、缺陷分析、缺陷所属开发 人员、缺陷描述缺陷有限等级等。提高质量:要有效的发现 Bug 需参考需求以及详细设计等前期文档设计出高效的测试用例,然后严格执行测试用例,对发现的问题要充分确认肯定,然后再向外发布如此才能提高提交 Bug 的质量。
测试报告:项目说明 测试依据 人员及进度 测试概要 测试环境 测试用例 测试方法 覆盖分析 需求覆盖 测试覆盖
14.如何设计测试用例?
测试用例(Test Case)是为某个特殊目标而编制的一组测试输入、执行条件以及预期结果,以便测试某个程序路径或核实是否满足某个特定需求。检验是否满足客户需求;度量测试人员的工作量;展现测试用例的思路。
测试用例包含:
用例编号 唯一的编号。
用例标题 当前测试用例的用途
测试背景 这个用例属于哪个项目
前置条件 用例执行前应该满足哪些条件
重要级别 定义优先级,分为高低级别
测试数据 具体输入内容
测试步骤 每步做些什么
预期结果 需求文档要求结果
实际结果 实际输出结果
备注
测试用例编写流程:需求分析–》提取测试点–》测试用例编写–》测试用例评审
测试用例常用设计方法:等价类划分法、 边界值分析法、因果图法、场景法、正交表、测试大纲法、错误推断法、随机测试
15.测试计划编写:
编写测试计: 测试环境准备、 第一次功能测试、 性能测试、 回归测试、 测试报告总结
1. 测试目标:根据xxx需求,提炼测试功能点、制定测试策略、评估测试 风险,预估编写测试用例、执行功能测试和回归测试的工作量,进行人员和进度 安排。
2. 测试范围:功能模块:(需要结合实际情况)
3. 测试策略:对需求中的功能改进进行完整测试,并根据应用场景和并发数考虑兼容性和性能测试方案。 并需要指定出测试工具
3.1 功能测试:见测试用例表
3.2 性能测试
3.3 系统兼容性测试
4. 测试资源
4.1 人员安排
4.2 测试环境
4.3 bug管理
5试进度安排:任务 时间 执行人员 工作量
5.2输出文档:测试计划、测试报告
6测试验收标准:1.完成所有类型测试 ,没有影响到用户业务使用的bug ,bug数量少于一定数量 , 功能业务,性能指标符合需求
6.2 产品上线标准:产品 checkelist
1. 已按照交互文档、需求文档完全的实现需求;
2. 符合交互稿的交互设计规范、符合视觉要求,已经通过设计评审;
3. 允许遗留可能会对用户正常使用造成一定影响的正常级缺陷,但应在发布前告知项目组,并经风险评估同意发布后方可发布
7. 风险说明
主要包括三个方面:1.测试范围风险 (测试遗漏,需求变更)、2.测试进度风险(预估量不准确,测试人员变动,其他业务工作,)、3.产品质量风险(代码质量,测试人员能力)
16.软件测试的原则:
1.测试软件存在缺陷。证明测试对象是有缺陷的。
2.测试尽早介入,缺陷发现越早,修复成本越小。
3.不可进行穷尽测试(无意义测试)。
4.缺陷集群性(2/8原则)80%的缺陷发现在20%的模块中。
5.杀虫剂悖论,如果一直使用相同的测试方法或手段,可能无法发现新的bug。
6.测试环境的特殊新,测试活动依赖测试内容,不同的行业,测试活动的开展都有所不同,比如测试技术、测试工具的选择,测试流程都不尽相同,所以软件测试的活动开展依赖于所测试的内容
7.不存在缺陷谬论,软件测试不仅是找出缺陷,同时也需要确认软件是否满足需求。
17.简述集成测试的环境?
1.硬件环境: 集成测试时,要尽可能的考虑用户使用的实际环境;当实际环境难以达到的时候,模拟环境考虑到与实际环境之间 可能存在的差异。
2.操作系统环境:考虑到不同的操作系统版本,对于可能使用的操作系统环境,要尽可能的测试到。
3.数据库环境:数据库的选择合乎实际情况。容量,性能,版本等多方面考虑。
4.网络环境:一般的网络环境可以使用以太网、wifi、3G、4G。
18.集成测试通常都有那些策略?
大爆炸集成
2、自顶向下集成
3、自底向上集成
4、三明治集成适应于大部分软件开发项目
5、基干集成
6、分层集成
7、基于功能的集成
8、基于消息的集成
9、基于风险的集成
10、基于进度的集成
19.测试策略:
功能测试,性能测试,压力测试,容量测试,安全性测试,GUI测试,可用性测试,安装测试,配置测试,
异常测试,备份测试,健壮性测试,文档测试,在线帮助测试,网络测试,稳定性测试
在:正常情况下测试;非正常情况下测试;边界测试;非法,极端测试;
20.什么是测试脚本?
测试脚本是为了进行自动化测试而编写的脚本,测试脚本的编写必须对应相应的测试用例
测试脚本是一段代码不假。但是这段代码可能是为了执行某一条,或很多条测试用例而写的。也有可能 ,本身就是一条用例。
用例本身并不局限,在基于功能。脚本和用例没有并列的可比性。脚本可能是用例,也可能是执行用例用的功能。用例也可能是脚本。
21.软件产品质量特性是什么? ?
功能性:适应性、准确性、互操作性、依从性、安全性。
可使用性:易理解性、易学习性、易操作性。
效率:时间特性、资源特性。
可维护性:易分析性、易变更性、稳定性、易测试性。
可移植性: 适应性、易安装性、遵循性、易替换性。
22. 一台客户端有三百个客户与三百个客户端有三百个客户对服务器施压,有什么区别?
300个用户在一个客户端上,会占用客户机更多的资源,而影响测试的结果。线程之间可能发生干扰,而产生一些异常。300个用户在一个客户端上,需要更大的带宽。
IP地址的问题,可能需要使用IP Spoof来绕过服务器对于单一IP地址最大连接数的限制。
所有用户在一个客户端上,不必考虑分布式管理的问题;而用户分布在不同的客户端上,需要考虑使用控制器来整体调配不同客户机上的用户。同时,还需要给予相应的权限配置和防火墙设置。
23.使用QTP做功能测试,录制脚本的时候,要验证多个用户的登录情况/查询情况,如何操作?
分析用户登录的基本情况,得出一组数据,通过性测试/失败性测试的都有(根据TC来设计这些数据),然后录制登录的脚本,将关键的数据参数化,修改脚本,对代码进行加强,调试脚本。
QTP中的action主要是用来管理代码的,Action的作用 1)用Action可以对步骤集进行分组 2)步骤重组,然后被整体调用 3)拥有自己的sheet 4)组合有相同需求的步骤,整体操作 5)具有独立的对象仓库
24.TestDirector有些什么功能,如何对软件测试过程进行管理?
管理测试需求,测试计划以及缺陷跟踪分析,主要有五个模块:1.服务测试管理器、2.需求管理器、3.测试实验室、4.缺陷管理器、5.测试计划 保证各阶段之间顺畅的信息流,完全基于Web。
业务分析员:定义应用程序需求和测试目标
QA测试员:运用手动和自动测试,报告执行测试结果,输入缺陷
开发人员:数据库查看和解决缺陷
测试经理和项目经理:设计测试计划,开发测试案例
产品经理:决定是否准备发布应用
25.测试自动化和自动化测试的区别?
什么是测试自动化:这是一种让测试过程脱离人工的一次变革。对于控制成本,控制质量,回溯质量和减少测试周期都有积极影响的一种研发过程。
什么是自动化测试:通过将测试执行部分部分或者全部交由机器执行的一种测试,叫做自动化测试。这种测试不需要人的实时参与。同时这种测试在小规模应用时会比手动测试昂贵许多。
自动化测试可以看作测试自动化的一部分。
一个自动化工程师,会比较专注于测试工具的研发。最主要的是这个工程师会从成本的角度去考虑问题。这一点比较像PM。他所做的一切是为了减少自己或者团队的工作量,尽可能的将重复的,有规律可循的工作代码化,自动化。
一个自动化测试工程师,会比较专注于测试代码的开发,以及测试结果的分析。对于被测设备本身非常感兴趣。他们比较倾向于一种完美主义者,追求的是高质量而经常忽略成本。这一点更像开发人员。
26.公司的测试环境?
开发环境:开发环境是程序猿们专门用于开发的服务器,配置可以比较随意, 为了开发调试方便,一般打开全部错误报告。
测试环境:一般是克隆一份生产环境的配置,一个程序在测试环境工作不正常,那么肯定不能把它发布到生产机上。
生产环境:是指正式提供对外服务的,一般会关掉错误报告,打开错误日志。可以理解为包含所有的功能的环境,任何项目所使用的环境都以这个为基础,然后根据客户的个性化需求来做调整或者修改。
三个环境也可以说是系统开发的三个阶段:开发->测试->上线,其中生产环境也就是通常说的真实环境。
UAT环境:UAT,(User Acceptance Test),用户接受度测试 即验收测试,所以UAT环境主要是用来作为客户体验的环境。
仿真环境:顾名思义是和真正使用的环境一样的环境(即已经出售给客户的系统所在环境,也成为商用环境),所有的配置,页面展示等都应该和商家正在使用的一样,差别只在环境的性能方面。
27.公司做安全测试是怎么进行的?
软件安全性测试主要包括程序、数据库安全性测试。根据系统安全指标不同测试策略也不同。
详细的测试点:
1.跨网站脚本攻击:通过脚本语言的缺陷模拟合法用户,控制其账户,盗窃敏感数据
2.注入攻击:通过构造查询对数据库、LDAP和其他系统进行非法查询
3.恶意文件执行:在服务器上执行Shell 命令Execute,获取控制权
4.伪造跨站点请求:发起Blind 请求,模拟合法用户,要求转账等请求
5.不安全对象引用:不安全对象的引入,访问敏感文件和资源,WEB应用返回敏感文件内容
6.被破坏的认证和Session管理:验证Session token 保护措施,防止盗窃session
7.Session的失效时间限制:Session的失效时间设置是否过长,会造成访问风险
8.不安全的木马存储:过于简单的加密技术导致黑客破解编密码,隐秘信息被盗窃,验证其数据加密
9.不安全的通讯:敏感信息在不安全通道中以非加密方式传送, 敏感信息被盗窃,验证其通讯的安全性
10.URL访问限制失效:验证是否通过恶意手段访问非授权的资源链接,强行访问一些登陆网页,窃取敏感信息
11.信息泄露和不正确错误处理测试:恶意系统检测,防止黑客用获取WEB站点的具体信息的攻击手段获取详细系统信息
12.注册与登录测试:验证系统先注册后登录、验证登录用户名和密码匹配校验,密码长度及尝试登录次数,防止 非法用户登录
13.超时限制:验证WEB应用系统需要有是否超时的限制,当用户长时间不做任何操作的时候,需要重新登录才能使用
14.日志文件:验证服务器上日志是否正常工作,所有事务处理是否被记录
15.目录文件:验证WEB服务器目录访问权限或者每个目录访问时有index.htm,防止 WEB 服务器处理不适当,将整个目录暴露
16.身份验证:验证调用者身份、数据库身份、验证是否明确服务账户要求、是否强制式试用账户管理措施
17.授权:验证如何向最终用户授权、如何在数据库中授权应用程序,确定访问系统资源权限
18.会话:验证如何交换会话标识符、是否限制会话生存期、如何确保会话存储状态安全
19.配置管理:验证是否支持远程管理、是否保证配置存储安全、是否隔离管理员特权
20.备份与恢复:为了防止系统意外崩溃造成的数据丢失,验证备份与恢复功能正常实现、备份与恢复方式是否满足Web系统安全性要求
21.数据库关键数据是否进行加密存储,是否在网络中传递敏感数据
22.在登录或注册功能中是否有验证码存在,防止恶意大批量注册登录的攻击
23.Cookie文件是否进行了加密存储,防止盗用cookie内容
24.密码强度提醒:建议对密码的规则进行加强设置
25.密码内容禁止拷贝粘贴
用户身份认证安全的测试要考虑问题:
1.明确区分系统中不同用户权限
2.系统中会不会出现用户冲突
3.系统会不会因用户的权限的改变造成混乱
4.用户登陆密码是否是可见、可复制
5.系统的密码策略,通常涉及到隐私,钱财或机密性的系统必须设置高可用的密码策略。
5.是否可以通过绝对途径登陆系统(拷贝用户登陆后的链接直接进入系统)
6.用户推出系统后是否删除了所有鉴权标记,是否可以使用后退键而不通过输入口令进入系统
系统网络安全的测试要考虑问题:
1.测试采取的防护措施是否正确装配好,有关系统的补丁是否打上
2.模拟非授权攻击,看防护系统是否坚固
3.采用成熟的网络漏洞检查工具检查系统相关漏洞(即用最专业的黑客攻击工具攻击试一下,现在最常用的是 NBSI系列和 IPhacker IP )
4.采用各种木马检查工具检查系统木马情况
5.采用各种防外挂工具检查系统各组程序的客外挂漏洞
数据库安全考虑问题:
1.系统数据是否机密(比如对银行系统,这一点就特别重要,一般的网站就没有太高要求)
2.系统数据的完整性(我刚刚结束的企业实名核查服务系统中就曾存在数据的不完整,对于这个系统的功能实现有了障碍)
3.系统数据可管理性
4.系统数据的独立性
5.系统数据可备份和恢复能力(数据备份是否完整,可否恢复,恢复是否可以完整)
浏览器安全
同源策略:不同源的“document”或脚本,不能读取或者设置当前的“document”
同源定义:host(域名,或者IP),port(端口号),protocol(协议)三者一致才属于同源。
要注意的是,同源策略只是一种策略,而非实现。这个策略被用于一些特定的点来保护web的安全。
<script>,<img>,<iframe>,<link>等标签都可以跨域加载资源,不受同源策略的限制。
XMLHttpRequest,DOM,cookie受到同源策略的限制。
网站可以通过提供crossdomain.xml来允许某些源跨域访问自己的资源。
google chrome使用了多进程来隔离代码运行的环境,从而起到提高web安全的作用
Q & A
Q:cookie为什么需要同源策略?
A:cookie有同源策略是必须的,这样可以保证A网站的用户(识别)信息不会被B网站获取到
Q:XMLHttpRequest为什么需要同源策略?
A:两个例子:
(1)加入没有同源策略,某个网站的某张页面被你写入了一些js ,这些js有些ajax操作,如果某个用户访问了这张页面,你的js就可以获得用户的某些信息(cookie,本地文件等)然后通过ajax发送回你的服务器。 这就是安全问题,信息泄漏。
(2)先假设浏览器没有限制跨域,A站的xhr请求B站的一个url,那么浏览器是要带上谁家的cookie一起请求呢?(每次http请求都要带上该站下的所有cookie)显然是B家的。假设B家的网站当前用户已经登录,那么cookie里自然记录下了sessionId相关的东西以标识当前用户的身份,那么本次xhr请求很easy的通过了身份认证,然后后果就是不堪设想的。
这个就很正确,如果A可以用xhr跨站访问B,带着B的cookie自然可以通过B网站的验证,从而获取到敏感数据。所以这点是关键。
web安全测试方法:
工具扫描
目前web安全扫描器针对OSinjection, XSS、SQL injection 、OPEN redirect 、PHP File Include漏洞的检测技术已经比较成熟。
商业软件web安全扫描器:有IBM Rational Appscan、WebInspect、Acunetix WVS 、burp suite免费的扫描器:W3af 、Skipfish 根据业务资金,可以考虑购买商业扫描软件,也可以使用免费的,各有各的好处。
首页可以对网站进行大规模的扫描操作,工具扫描确认没有漏洞或者漏洞已经修复后,再进行以下手工检测。
关于越权操作的问题
例如A用户的个人资料ID为1 B用户个人资料ID为2,我通过登陆B用户,把ID修改为1 就可以查看到用户A的个人资料,这就是越权。
测试方法:通过查看URL的get参数对那些类似明显的顺序数字 进行修改,看是否能越权访问。
关于登陆安全的问题
除了SQL注入,还有找回密码功能会出现安全问题
邮箱找回密码测试方法:
先从邮箱参数修改开始,看填入用户名和自己修改的邮箱账号,看是否能收到邮箱,收到后是否能修改。
如果不能修改邮箱参数那么,我们就让它邮箱找回,接着点击邮箱内修改密码的链接,看链接的邮箱参数是否可以修改,用户名是否可以修改,加密的urlcode 是否可以逆向解密。
如果是手机找回密码功能:则测试手机收到的验证码是否是纯数字、纯字母的,如果是请修改为字母与数字的组合。
关于用开源程序的问题
关注网上你所用的开源程序的官网更新情况和安全事件。
关于上传:
1.上传文件是否有格式限制,是否可以上传exe文件;
2.上传文件是否有大小限制,上传太大的文件是否导致异常错误,上传0K的文件是否会导致异常错误,上传并不存在的文件是否会导致异常错误;
3.通过修改扩展名的方式是否可以绕过格式限制,是否可以通过压包方式绕过格式限制;
4.是否有上传空间的限制,是否可以超过空间所限制的大小,如将超过空间的大文件拆分上传是否会出现异常错误。
5.上传文件大小大于本地剩余空间大小,是否会出现异常错误。
6.关于上传是否成功的判断。上传过程中,中断。程序是否判断上传是否成功。
7.对于文件名中带有中文字符,特殊字符等的文件上传。
28.移动端测试:
Android手机和IOS手机,系统有什么区别?
1、两者运行机制不同:IOS采用的是沙盒运行机制,安卓采用的是虚拟机运行机制。
2、两者后台制度不同:IOS中任何第三方程序都不能在后台运行;安卓中任何程序都能在后台运行,直到没有内存才会关闭。
3、IOS中用于UI指令权限最高,安卓中数据处理指令权限最高。
Android:
1:使用灰盒进行功能测试
2:使用fiddler或者Charles进行抓包测试
3:兼容性测试,Android 从4.0版本的手机测试到9.0版本手机
4:各大品牌的手机都的进行测试,比如:小米小米9 小米8 小米7 小米6 note 红米系列 7红米5,华为: 华为mate20 华为mate10,华为荣耀: 荣耀10,9,8 ,vivo: x21,27,23,oppo: R7,R9,R11,三星手机: note9, 8,7 S9,8。
5:稳定性测试: 使用monkey命令进行稳定性测试
6:专项测试,使用腾讯专项测试工具进行,测试耗电量,流量,CPU占用率
7:性能测试,对app的接口进行性能测试,使用工具jmeter或者loadrunner
8:对app接口进行接口测试,使用postman或者Jmeter都行
9:如果有时间写自动化脚本
ios:
1:使用灰盒进行功能测试
2:使用fiddler或者Charles进行抓包测试
3:兼容性测试:ios版本测试从9-12,手机型号从4S测试到xmax
4:性能测试接口和安卓的是一样的所以只需要进行一次就可以了
5:专项测试:使用腾讯专项测试工具进行,测试耗电量,流量,CPU占用率
6:编写自动化脚本
29.web端测试:
前端 :
1:web也使用灰&测试方法
2:兼容性测试:IE浏览器7-12,火狐浏览器 35-最新的,谷歌浏览器,别的浏览器有时间就可以测试
3:对web端页面进行性能测试,使用jmeter或者loadrunner
后端
1:测试http接口
2:测试https接口
3:测试tcp接口
4:测试dubbo接口
5:对后台代码进行代码审核,进行白盒测试
30.软件测试模型?
1,传统的瀑布模型
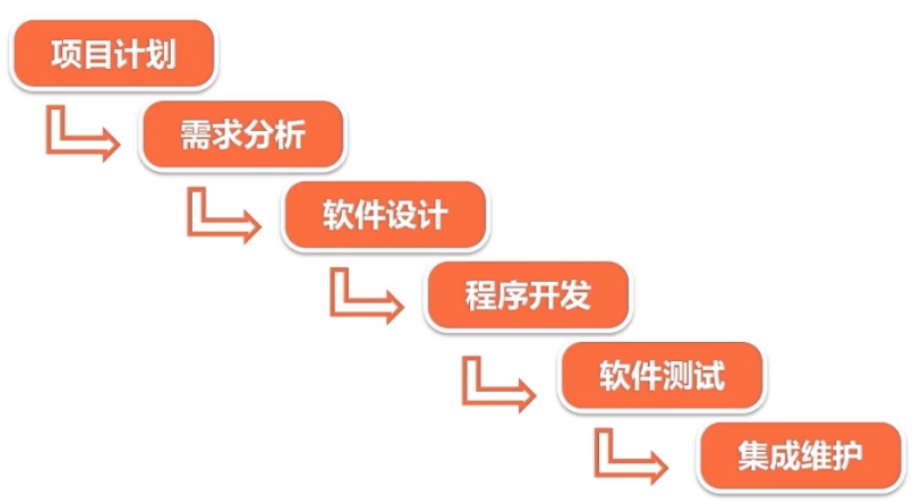
瀑布模型的优缺点

2,V模型
3,W模型
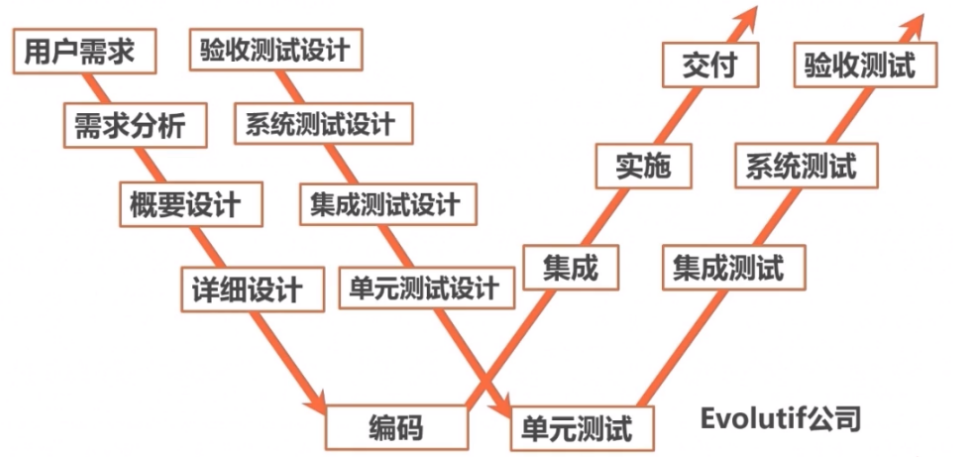
4,X模型
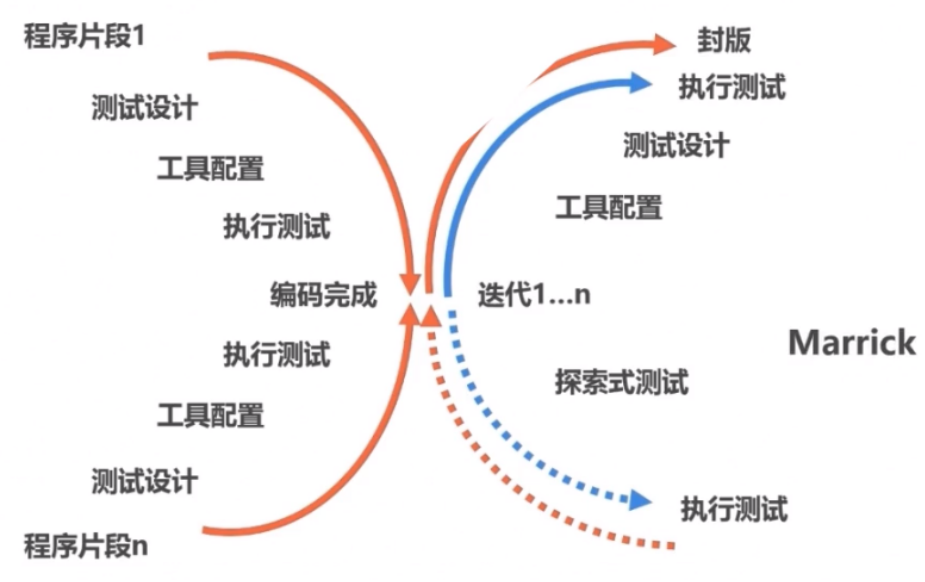
31.在Windows上运行得很慢,怎么判别是程序存在问题还是软硬件系统存在问题?
1、检查系统是否有中毒的特征 2、检查软件/硬件的配置是否符合软件的推荐标准
3、如果是C/S或者B/S结构的软件,需要检查是不是因为与服务器的连接问题或者访问问题造成的
4、确认当前的系统是否是独立,是否存在负载,无对外提供消耗CPU资源的服务,查看性能监视器,确认应用程序对CPU/内存的访问情况
32.MySQL外连接、内连接的区别?
内连接 :连接的数据表相对应的匹配字段完全相等的连接。连接关键字是 inner join
外连接:分为左外连接与右外连接、全连接。
左连接的结果集包括指定的左表全部数据与匹配的右表数据,右表中没匹配的全为空值.关键字 left join
右连接的结果集包含指定的右表全部数据与匹配的左边数据,左边中没匹配的全为空值.关键字 right join
全连接返回左右数据表的所有行.关键字 full join
33.测试通过的标准是什么?
从微观上来说,在测试计划中定义,比如系统在一定性能下平稳运行 72 小时,目前 Bug Tracking System 中,本版本中没有一般严重的 BUG,普通 BUG 的数量在 3 以下,BUG 修复 率 90%以上等等参数,然后由开发经理,测试经理,项目经理共同签字认同版本 Release。
34.测试退出标准:
单元测试退出标准
1) 单元测试用例设计已经通过评审 2) 核心代码100% 经过Code Review 3) 单元测试功能覆盖率达到100% 4) 单元测试代码行覆盖率不低于80% 5) 所有发现缺陷至少60%都纳入缺陷追踪系统且各级缺陷修复率达到标准 6) 不存在A、B类缺陷 7) C、D、E类缺陷允许存在 8) 按照单元测试用例完成了所有规定单元的测试 9) 软件单元功能与设计一致
集成测试退出标准
1) 集成测试用例设计已经通过评审 2) 所有源代码和可执行代码已经建立受控基线,纳入配置管理受控库,不经过审批不能随意更改 3) 按照集成构件计划及增量集成策略完成了整个系统的集成测试 4) 达到了测试计划中关于集成测试所规定的覆盖率的要求 5) 集成工作版本满足设计定义的各项功能、性能要求 6) 在集成测试中发现的错误已经得到修改,各级缺陷修复率达到标准 7) A、B类BUG不能存在 8) C、D类BUG允许存在,但不能超过单元测试总BUG的50%。 9) E类BUG允许存在
系统测试退出标准
1) 系统测试用例设计已经通过评审 2) 按照系统测试计划完成了系统测试 3) 系统测试的功能覆盖率达100% 4) 系统的功能和性能满足产品需求规格说明书的要求 5) 在系统测试中发现的错误已经得到修改并且各级缺陷修复率达到标准 6) 系统测试后不存在A、B、C类缺陷 7) D类缺陷允许存在,不超过总缺陷的5% 8) E类缺陷允许存在,不超过总缺陷的10% 注:这只是一套比较理想化的退出标准,但在实际工作中不可能达到这种程度,尤其是测试覆盖率和缺陷解决率不可能是100%。现在的军方标准是达到99%。对于通用软件来说就要根据公司实际情况了。
39.查看LINUX进程内存占用
1、lsof -i:端口号
2、netstat -tunlp|grep 端口号都可以查看指定端口被哪个进程占用的情况
查看所有端口、进程的使用情况:netstat -tunlp
查看某一端口的使用情况: netstat -tunlp|grep 5560
在命令行中输入 “top”
即可启动 top, top 的全屏对话模式可分为3部分:系统信息栏、命令输入栏、进程列表栏。
第一部分 — 最上部的 系统信息栏 :
第一行(top):“00:11:04”为系统当前时刻;“3:35”为系统启动后到现在的运作时间;
“2 users”为当前登录到系统的用户,更确切的说是登录到用户的终端数 — 同一个用户同一时间对系统多个终端的连接将被视为多个用户连接到系统,这里的用户数也将表现为终端的数目;
“load average”为当前系统负载的平均值,后面的三个值分别为1分钟前、5分钟前、15分钟前进程的平均数,一般的可以认为这个数值超过 CPU 数目时,CPU 将比较吃力的负载当前系统所包含的进程;
第二行(Tasks):
“59 total”为当前系统进程总数;
“1 running”为当前运行中的进程数;
“58 sleeping”为当前处于等待状态中的进程数;
“0 stoped”为被停止的系统进程数;
“0 zombie”为被复原的进程数;
第三行(Cpus):分别表示了 CPU 当前的使用率;
第四行(Mem):分别表示了内存总量、当前使用量、空闲内存量、以及缓冲使用中的内存量;
35.数据库:mysql语句
大型数据库 Oracle Db2 中型数据库 sqlserver 小型数据库 mysql 微型数据库 sqlite
增:Insert into 表名 value 值
删:Delect from 表名 where 值
改:Update 表名 set 字段=字段 where 字段;
查:Select * from 表名
自增 auto_increment 主键 primary key 非空 not null 唯一 unique 默认值 default 外键 foreign key
-
# 查看所有的数据库: SHOW DATABASES ; -
# 创建一个数据库: CREATE DATABASE k; -
# 删除一个数据库: DROP DATABASE k; -
# 使用这个数据库 USE k;
表
-
# 查看所有的表 SHOW TABLES ; -
# 创建一个表 CREATE TABLE n(id INT, name VARCHAR(10)); -
CREATE TABLE m(id INT, name VARCHAR(10), PRIMARY KEY (id), FOREIGN KEY (id) REFERENCES n(id), UNIQUE (name)); -
CREATE TABLE m(id INT, name VARCHAR(10)); -
# 直接将查询结果导入或复制到新创建的表 : CREATE TABLE n SELECT * FROM m; -
# 新创建的表与一个存在的表的数据结构类似: CREATE TABLE m LIKE n; -
# 临时表将在你连接MySQL期间存在。当断开连接时,MySQL将自动删除表并释放所用的空间。也可手动删除。 -
CREATE TEMPORARY TABLE l(id INT, name VARCHAR(10)); -
# 直接将查询结果导入或复制到新创建的临时表 CREATE TEMPORARY TABLE tt SELECT * FROM n; -
# 删除一个存在表 DROP TABLE IF EXISTS m; -
# 更改存在表的名称 -
ALTER TABLE n RENAME m; -
RENAME TABLE n TO m; -
# 查看表的结构(以下五条语句效果相同) -
DESC n; # 因为简单,所以建议使用 -
DESCRIBE n; -
SHOW COLUMNS IN n; -
SHOW COLUMNS FROM n; -
EXPLAIN n; -
# 查看表的创建语句 -
SHOW CREATE TABLE n;
表的结构
-
# 添加字段: ALTER TABLE n ADD age VARCHAR(2) ; -
# 删除字段: ALTER TABLE n DROP age; -
# 更改字段属性和属性:ALTER TABLE n CHANGE age a INT; -
# 只更改字段属性:ALTER TABLE n MODIFY age VARCHAR(7) ;
表的数据
-
# 增加数据 -
INSERT INTO n VALUES (1, 'tom', '23'), (2, 'john', '22'); -
INSERT INTO n SELECT * FROM n; # 把数据复制一遍重新插入 -
# 删除数据:DELETE FROM n WHERE id = 2; -
# 更改数据:UPDATE n SET name = 'tom' WHERE id = 2; -
# 数据查找 : SELECT * FROM n WHERE name LIKE '%h%'; -
# 数据排序(反序) :SELECT * FROM n ORDER BY name, id DESC ;
键
-
# 添加主键:ALTER TABLE n ADD PRIMARY KEY (id); -
# 删除主键:ALTER TABLE n DROP PRIMARY KEY ; -
# 添加外键 -
ALTER TABLE m ADD FOREIGN KEY (id) REFERENCES n(id); # 自动生成键名m_ibfk_1 -
ALTER TABLE m ADD CONSTRAINT fk_id FOREIGN KEY (id) REFERENCES n(id); # 使用定义的键名fk_id -
# 删除外键:ALTER TABLE m DROP FOREIGN KEY `fk_id`; -
# 修改外键:ALTER TABLE m DROP FOREIGN KEY `fk_id`, ADD CONSTRAINT fk_id2 FOREIGN KEY (id) REFERENCES n(id); # 删除之后从新建
联接
-
# 内联接:SELECT * FROM m INNER JOIN n ON m.id = n.id; -
# 左外联接 :SELECT * FROM m LEFT JOIN n ON m.id = n.id; -
# 右外联接:SELECT * FROM m RIGHT JOIN n ON m.id = n.id; -
# 交叉联接: SELECT * FROM m CROSS JOIN n; # 标准写法 -
# 类似全连接full join的联接用法 -
SELECT id,name FROM m -
UNION -
SELECT id,name FROM n;
函数
-
# 聚合函数 -
SELECT count(id) AS total FROM n; # 总数 -
SELECT sum(age) AS all_age FROM n; # 总和 -
SELECT avg(age) AS all_age FROM n; # 平均值 -
SELECT max(age) AS all_age FROM n; # 最大值 -
SELECT min(age) AS all_age FROM n; # 最小值 -
# 数学函数 -
SELECT abs(-5); # 绝对值 -
SELECT bin(15), oct(15), hex(15); # 二进制,八进制,十六进制 -
SELECT pi(); # 圆周率3.141593 -
SELECT ceil(5.5); # 大于x的最小整数值6 -
SELECT floor(5.5); # 小于x的最大整数值5 -
SELECT greatest(3,1,4,1,5,9,2,6); # 返回集合中最大的值9 -
SELECT least(3,1,4,1,5,9,2,6); # 返回集合中最小的值1 -
SELECT mod(5,3); # 余数2 -
SELECT rand(); # 返回0到1内的随机值,每次不一样 -
SELECT rand(5); # 提供一个参数(种子)使RAND()随机数生成器生成一个指定的值。 -
SELECT round(1415.1415); # 四舍五入1415 -
SELECT round(1415.1415, 3); # 四舍五入三位数1415.142 -
SELECT round(1415.1415, -1); # 四舍五入整数位数1420 -
SELECT truncate(1415.1415, 3); # 截短为3位小数1415.141 -
SELECT truncate(1415.1415, -1); # 截短为-1位小数1410 -
SELECT sign(-5); # 符号的值负数-1 -
SELECT sign(5); # 符号的值正数1 -
SELECT sqrt(9); # 平方根3 -
SELECT sqrt(9); # 平方根3 -
# 字符串函数 -
SELECT concat('a', 'p', 'p', 'le'); # 连接字符串-apple -
SELECT concat_ws(',', 'a', 'p', 'p', 'le'); # 连接用','分割字符串-a,p,p,le -
SELECT insert('chinese', 3, 2, 'IN'); # 将字符串'chinese'从3位置开始的2个字符替换为'IN'-chINese -
SELECT left('chinese', 4); # 返回字符串'chinese'左边的4个字符-chin -
SELECT right('chinese', 3); # 返回字符串'chinese'右边的3个字符-ese -
SELECT substring('chinese', 3); # 返回字符串'chinese'第三个字符之后的子字符串-inese -
SELECT substring('chinese', -3); # 返回字符串'chinese'倒数第三个字符之后的子字符串-ese -
SELECT substring('chinese', 3, 2); # 返回字符串'chinese'第三个字符之后的两个字符-in -
SELECT trim(' chinese '); # 切割字符串' chinese '两边的空字符-'chinese' -
SELECT ltrim(' chinese '); # 切割字符串' chinese '两边的空字符-'chinese ' -
SELECT rtrim(' chinese '); # 切割字符串' chinese '两边的空字符-' chinese' -
SELECT repeat('boy', 3); # 重复字符'boy'三次-'boyboyboy' -
SELECT reverse('chinese'); # 反向排序-'esenihc' -
SELECT length('chinese'); # 返回字符串的长度-7 -
SELECT upper('chINese'), lower('chINese'); # 大写小写 CHINESE chinese -
SELECT ucase('chINese'), lcase('chINese'); # 大写小写 CHINESE chinese -
SELECT position('i' IN 'chinese'); # 返回'i'在'chinese'的第一个位置-3 -
SELECT position('e' IN 'chinese'); # 返回'i'在'chinese'的第一个位置-5 -
SELECT strcmp('abc', 'abd'); # 比较字符串,第一个参数小于第二个返回负数- -1 -
SELECT strcmp('abc', 'abb'); # 比较字符串,第一个参数大于第二个返回正数- 1 -
# 时间函数 -
SELECT current_date, current_time, now(); # 2018-01-13 12:33:43 2018-01-13 12:33:43 -
SELECT hour(current_time), minute(current_time), second(current_time); # 12 31 34 -
SELECT year(current_date), month(current_date), week(current_date); # 2018 1 1 -
SELECT quarter(current_date); # 1 -
SELECT monthname(current_date), dayname(current_date); # January Saturday -
SELECT dayofweek(current_date), dayofmonth(current_date), dayofyear(current_date); # 7 13 13 -
# 控制流函数 -
SELECT if(3>2, 't', 'f'), if(3<2, 't', 'f'); # t f -
SELECT ifnull(NULL, 't'), ifnull(2, 't'); # t 2 -
SELECT isnull(1), isnull(1/0); # 0 1 是null返回1,不是null返回0 -
SELECT nullif('a', 'a'), nullif('a', 'b'); # null a 参数相同或成立返回null,不同或不成立则返回第一个参数 -
SELECT CASE 2 -
WHEN 1 THEN 'first' -
WHEN 2 THEN 'second' -
WHEN 3 THEN 'third' -
ELSE 'other' -
END ; # second -
# 系统信息函数 -
SELECT database(); # 当前数据库名-test -
SELECT connection_id(); # 当前用户id-306 -
SELECT user(); # 当前用户-root@localhost -
SELECT version(); # 当前mysql版本
36.Linux命令:
mv 移动文件夹 source 更新 tar -vxzf 解压 cd /home 进入 ‘/ home’ 目录’ cd .. 返回上一级目录 cd ../.. 返回上两级目录 cd 进入个人的主目录 cd ~user1 进入个人的主目录 cd – 返回上次所在的目录 pwd 显示工作路径 ls 查看目录中的文件
vi 编辑
wq 编辑保存 ls -F 查看目录中的文件 ls -l 显示文件和目录的详细资料 ls -a 显示隐藏文件 ls *[0-9]* 显示包含数字的文件名和目录名 tree 显示文件和目录由根目录开始的树形结构 lstree 显示文件和目录由根目录开始的树形结构 mkdir dir1 创建一个叫做 ‘dir1′ 的目录’ mkdir dir1 dir2 同时创建两个目录 mkdir -p /tmp/dir1/dir2 创建一个目录树 rm -f file1 删除一个叫做 ‘file1′ 的文件’ rmdir dir1 删除一个叫做 ‘dir1′ 的目录’ rm -rf dir1 删除一个叫做 ‘dir1’ 的目录并同时删除其内容 rm -rf dir1 dir2 同时删除两个目录及它们的内容 mv dir1 new_dir 重命名/移动 一个目录 cp file1 file2 复制一个文件 cp dir/* . 复制一个目录下的所有文件到当前工作目录 cp -a /tmp/dir1 . 复制一个目录到当前工作目录 cp -a dir1 dir2 复制一个目录 ln -s file1 lnk1 创建一个指向文件或目录的软链接 ln file1 lnk1 创建一个指向文件或目录的物理链接 文件搜索 find / -name file1 从 ‘/’ 开始进入根文件系统搜索文件和目录 find / -user user1 搜索属于用户 ‘user1’ 的文件和目录 find /home/user1 -name \*.bin 在目录 ‘/ home/user1′ 中搜索带有’.bin’ 结尾的文件 find /usr/bin -type f -atime +100 搜索在过去100天内未被使用过的执行文件 find /usr/bin -type f -mtime -10 搜索在10天内被创建或者修改过的文件 find / -name \*.rpm -exec chmod 755 ‘{}’ \; 搜索以 ‘.rpm’ 结尾的文件并定义其权限 find / -xdev -name \*.rpm 搜索以 ‘.rpm’ 结尾的文件,忽略光驱、捷盘等可移动设备 locate \*.ps 寻找以 ‘.ps’ 结尾的文件 – 先运行 ‘updatedb’ 命令 whereis halt 显示一个二进制文件、源码或man的位置 which halt 显示一个二进制文件或可执行文件的完整路径
37.adb命令:
adb 使用的端口号,5037
adb devices , 获取设备列表及设备状态
adb get-state , 获取设备的状态
adb install 用于安装
adb uninstall 用于卸载
adb push 命令将PC机上的文件推到 DLT-RK3288 机器上
adb pull 命令将DLT-RK3288机器上的文件拉到PC机上
ls, cd, rm, mkdir, touch, pwd, cp, mv, ifconfig, netstat, ping, ps, top等,进入adb shell即可执行,与linux相似
打印默认日志数据adb logcat
需要打印日志详细时间的简单数据adb logcat -v time
需要打印级别为Error的信息adb logcat *:E
- adb help, 列出所有的选项说明及子命令
- adb devices , 获取设备列表及设备状态
- adb get-state , 获取设备的状态,设备的状态有 3 钟,
device,offline,unknown,其中device:设备正常连接,offline:连接出现异常,设备无响应,unknown:没有连接设备 - adb kill-server , adb start-server , 结束 adb 服务, 启动 adb 服务,通常两个命令一起用,设备状态异常时使用 kill-server,然后运行 start-server 进行重启服务
- adb logcat , 打印 Android 的系统日志 adb logcat -c,清除日志
- adb bugreport , 打印dumpsys、dumpstate、logcat的输出,也是用于分析错误,输出比较多,建议重定向到一个文件中,如adb bugreport > d:\bugreport.log
- adb install , 安装应用,adb install -r 重新安装
- adb uninstall , 卸载应用,后面跟的参数是
应用的包名,请区别于apk 文件名 - adb pull , 将 Android 设备上的文件或者文件夹复制到本地,如例如复制 Sdcard 下的 pull.txt 文件到 D 盘:adb pull sdcard/pull.txt d:\,重命名:adb pull sdcard/pull.txt d:\rename.txt
- adb push , 推送本地文件至 Android 设备,如推送 D 盘下的 push.txt 至 Sdcard:adb push d:\push.txt sdcard/ sdcard 后面的斜杠不能少
- adb reboot , 重启 Android 设备, adb reboot recovery,重启到Recovery界面 adb reboot bootloader,重启到bootloader界面
- adb root , adb remount,可以直接已这两个命令获取 root 权限,并挂载系统文件系统为可读写状态
- adb get-serialno,返回设备序列号SN值 adb get-product,获取设备的ID
- adb forward tcp:5555 tcp:8000,做为主机向模拟器或设备的请求端口
- adb shell,进入设备shell
- adb shell pm list package,列出所有的应用的包名
- adb shell screencap -p /sdcard/screen.png ,截屏,保存至 sdcard 目录
- adb shell screenrecord sdcard/record.mp4,执行命令后操作手机,ctrl + c 结束录制,录制结果保存至 sdcard
- adb shell wm size,获取设备分辨率
- adb shell pm dump 包名,列出指定应用的 dump 信息
- adb shell pm path 包名, 列出对应包名的 .apk 位置
- adb shell monkey –p 程序包 –v 测试次数 ,比如“adb shell monkey –p com.htc.Weather –v 20000”意思是对com.htc.Weather 这个程序包单独进行一次20000次的monkey测试,其中程序包名称可以在串口终端这句命令获得:ls data/data 显示所有程序包
- adb shell ps | grep [process],找出对应的进程pid adb shell dumpsys meminfo [pid],根据进程pid查看进程占用的内存 或者 adb shell dumpsys meminfo<package_name>,package_name 也可以换成程序的pid,pid可以通过 adb shell top | grep app_name 来查找
- adb shell ps, 查看当前终端中的进程信息
- ls // 查看目录
- date // 打印或设置当前系统时间
- cat /proc/meminfo // 查看内存信息
- cat /proc/cpuinfo // 查看CPU信息
抓取App报错的log日志:
按住win+r打开cmd,cd到安装adb的目录下,然后输入指令:adb logcat -v time > D:\\logcat.log(可以换成其他磁盘) ,输入完成之后敲击回车,这个时候在D盘下会生成一个logcat日志并且将近期的崩溃记录到这个日志当中。Ctrl+C以结束截取操作。
1.adb logcat *:V 不过滤地输出所有调试信息,显示所有日志信息
1.adb logcat *:D Debug来表达调试信息,能输出Debug、Info、Warning、Error级别的Log信息。
1.adb logcat *:I Info来表达一些信息,能输出Info、Warning、Error级别的Log信息。
1.adb logcat *:W Warning表示警告,查找崩溃问题一般用:能输出Warning、Error级别的Log信息
2.adb logcat *:E Error表示出现错误,能输出Error级别的Log信息。
40.Monkey命令
查看设备的链接情况:adb devices
手机里面的软件随机点击:adb shell monkey 1000
查看包名(-s只查找系统包名,-3只查看第三方包,-f输出包和包相关联的文件,-e只输出启用的包,-i只输出包和安装信息,-u只输出包和未安装包信息,都不加显示所有,):adb shell pm list packages -s
启动一个指定包名:adb shell monkey -p com.dyhoa.school 1000
操作日志:adb shell monkey -p com.tencent.mobileqq -v -v 100
1 参数: -p 用于约束限制,用此参数指定一个或多个包(Package,即App)。指定包之后,monkey将只允许系统启动指定的APP,如果不指定包,将允许系统启动设备中的所有APP.
* 指定一个包: adb shell monkey -p cn.emoney.acg 10
* 指定多个包:adb shell monkey -p cn.emoney.acg –p cn.emoney.wea -p cn.emoney.acg 100
* 不指定包:adb shell monkey 100
2 参数: -v用于指定反馈信息级别(信息级别就是日志的详细程度),总共分3个级别,分别对应的参数如下表所示:
日志级别 0
示例 adb shell monkey -p cn.emoney.acg –v 100
说明缺省值,仅提供启动提示、测试完成和最终结果等少量信息
日志级别1
示例 adb shell monkey -p cn.emoney.acg –v -v 100
说明提供较为详细的日志,包括每个发送到Activity的事件信息
日志级别 2
示例 adb shell monkey -p cn.emoney.acg –v -v –v 100
说明最详细的日志,包括了测试中选中/未选中的Activity信息
3 参数: -s
用于指定伪随机数生成器的seed值,如果seed相同,则两次Monkey测试所产生的事件序列也相同的。
Monkey 测试1:adb shell monkey -p cn.emoney.acg -s 10 100
Monkey 测试2:adb shell monkey -p cn.emoney.acg –s 10 100
两次测试的效果是相同的,因为模拟的用户操作序列(每次操作按照一定的先后顺序所组成的一系列操作,即一个序列)是一样的。
4 参数: –throttle<毫秒>用于指定用户操作(即事件)间的时延,单位是毫秒;
adb shell monkey -p cn.emoney.acg –throttle 5000 100
5 参数: –ignore-crashes 用于指定当应用程序崩溃时(Force& Close错误),Monkey是否停止运行。如果使用此参数,即使应用程序崩溃,Monkey依然会发送事件,直到事件计数完成。
adb shell monkey -p cn.emoney.acg –ignore-crashes 1000 测试过程中即使程序崩溃,Monkey依然会继续发送事件直到事件数目达到1000为止
adb shell monkey -p cn.emoney.acg 1000 测试过程中,如果acg程序崩溃,Monkey将会停止运行
6 参数: –ignore-timeouts 用于指定当应用程序发生ANR(Application No Responding)错误时,Monkey是否停止运行。如果使用此参数,即使应用程序发生ANR错误,Monkey依然会发送事件,直到事件计数完成。
adb shellmonkey -p cn.emoney.acg –ignore-timeouts 1000
7 参数: –ignore-security-exceptions 用于指定当应用程序发生许可错误时(如证书许可,网络许可等),Monkey是否停止运行。如果使用此参数,即使应用程序发生许可错误,Monkey依然会发送事件,直到事件计数完成。
adb shellmonkey -p cn.emoney.acg –ignore-security-exception 1000
8 参数: –kill-process-after-error 用于指定当应用程序发生错误时,是否停止其运行。如果指定此参数,当应用程序发生错误时,应用程序停止运行并保持在当前状态。应用程序仅是静止在发生错误时的状态,系统并不会结束该应用程序的进程
adb shellmonkey -p cn.emoney.acg –kill-process-after-error 1000
9 参数: –monitor-native-crashes 用于指定是否监视并报告应用程序发生崩溃的本地代码。
adb shellmonkey -p cn.emoney.acg –monitor-native-crashes 1000
10 参数: –pct-{+事件类别}{+事件类别百分比}用于指定每种类别事件的数目百分比(在Monkey事件序列中,该类事件数目占总事件数目的百分比) 示例: –pct-touch{+百分比} 调整触摸事件的百分比(触摸事件是一个down-up事件,它发生在屏幕上的某单一位置)
adb shell monkey -p cn.emoney.acg –pct-touch 10 1000 –pct-motion {+百分比} 调整动作事件的百分比(动作事件由屏幕上某处的一个down事件、一系列的伪随件机事和一个up事件组成)
adb shell monkey -p cn.emoney.acg –pct-motion 20 1000 –pct-trackball {+百分比} 调整轨迹事件的百分比(轨迹事件由一个或几个随机的移动组成,有时还伴随有点击)
adb shell monkey -p cn.emoney.acg –pct-trackball 30 1000 –pct-nav {+百分比}
调整“基本”导航事件的百分比(导航事件由来自方向输入设备的up/down/left/right组成)
adb shell monkey -p cn.emoney.acg –pct-nav 40 1000 –pct-majornav {+百分比} 调整“主要”导航事件的百分比(这些导航事件通常引发图形界面中的动作,如:5-way键盘的中间按键、回退按键、菜单按键)
adb shell monkey -p cn.emoney.acg –pct-majornav 50 1000
七、输出monkeylog
跑monkey的时候或者想抓程序log导出时,有时会提示:cannot create D:monkeytest.txt: read-only file system
为什么有时候可以有时候不可以?
后来发现跟使用使用习惯不一样,一会是先进入adb shell 再用命令,一会是直接命令进入。
进入adb shell后再用命令就会失败~
正确方法:退出shell或者执行命令时先不要进shell
C:\Documents and Settings\Administrator>adb shell monkey -p 包名 -v 300 >e:\text.txt
进入adb shell后就相当于进入linux的root下面,没有权限在里面创建文件~
48.保证测试的覆盖率 ?
测试需求分析分两步:
1、测试需求的获取 需求的来源:
显式需求:1.原始需求说明书 2.产品规格书 3.软件需求文档 4.有无继承性文档 5.经验库 6.通用的协议规范
隐式需求:用户的主观感受,市场的主流观点,专业人士的评价分析
2,需求的分析,产生测试需求文档
将不同的需求来源划分成一个个需求点,针对每一点进行测试分析:界定测试范围,利用各种测试设计的方法产生测试点
在测试方法方面,可做如下注意:
其一,分析出口入口。从入口分析,将可能出现的环境,条件,操作等内容分类组合,然后根据各位测试达人的方法进行整合,逐一验证。从出口分析,将可能出现的结果进行统计,根据结果的不同追根溯源,再找到不同的操作以及条件等内容,统计成文档,逐一验证。
其二,多种测试手法的学习和使用。大家可能更多的关心测试方法,但是具体操作的手法也是需要注意的。毕竟测试方法比较容易找到,各位达人都很熟悉。如果将每个人不同的测试手法总结出来并在自己的测试实施中加以使用,可能会收到意想不到的成果。
二、当测试需求分析完成,并且形成文档后,要进行测试需求评审,保证需求的准确性以及完整性。
三、测试需求完成以后,可以根据测试需求设计测试用例。
要保证测试用例能够全面覆盖测试需求,要包含所有的情况。
测试用例设计上划分为单功能测试用例和测试场景设计,单功能测试覆盖的需求中的功能点,测试场景覆盖需求中的业务逻辑。
在设计测试用例的时候,可以使用多种测试用例设计方法。
●首先进行等价类划分,包括输入条件和输出条件的等价类划分,合理设置有效等价类和无效等价类,这是减少工作量和提高测试效率最有效的方法。
●必须使用边界值分析,经验表明,这种方法设计出的用例能发现很多程序错误。
●可以使用错误推测法追加一些测试用例,这需要依靠您的智慧和经验。
●对照程序逻辑检查已设计出的测试用例的逻辑覆盖度,如果没有达到覆盖标准应当再补充足够的测试用例。
●如果程序的功能说明中含有输入条件的组合情况,一开始就可选因果图和判定表驱动法。
●对于参数配置类的软件,要用正交试验法选择较少的组合方式达到最佳效果。
●对于业务流清晰的系统,可以利用场景法贯穿整个测试方案过程,在案例中综合使用各种测试方法。
当测试用例设计完成后,要组织测试用例的评审,这样可以吸取别人的意见,减少遗漏,补全测试用例。
四、测试用例编写完成后,就是测试执行
1.测试用例执行100%覆盖。2.在测试执行过程中,要继续对测试用例补充完善,确保提高测试覆盖率。
五、在整个测试过程中,需求都是不可能不变的,所以要及时的更新测试需求、测试用例。
六、要将测试需求、测试用例以及发现的bug关联起来,便于管理和跟踪,同时也便于查看覆盖率。
49.测试用例评审?
1. 评审就是对测试用例进行检查
2. 评审类型:同行评审、小组评审、部门评审、三方评审
3. 评审目的:发现测试用例不足,方便测试人员改进测试用例,提高测试质量
4. 评审过程:循环执行 “测试用例评审–》改进测试用例”
50.做好测试(用例)计划的关键?
1.明确测试计划
2.明确测试内容、测试过程、测试目的
3.测试范围与测试内容高度覆盖
4.测试结果的直观性、准确性
5.测试开始与结束时间
6.测试方法与测试工具的实用性
7.测试文档与测试软件
8.采用评审和更新机制
9.保证测试计划满足实际需求
51.完整的测试组成?
1.测试设计:需求分解,细化执行测试过程,为每个测试过程选择合适的测试用例
2.测试计划:根据需求和性能指标说明,定制相应测试计划,安排测试测试人员,测试内容,测试时间以及测试需要的资源
4.测试执行:建立自动化测试,对发现bug跟踪管理,按步骤测试(单元测试,集成测试,系统测试,验收测试)
5.测试评估:结合量化测试覆盖域以及bug跟踪,对软件质量,开发进度,工作效率等综合评价
52.所有的软件缺陷都可修复吗,都要修复吗?
理论上软件的缺陷是可修复的,不过有的修复成本比较高,不能追求软件的完美,根据风险来确定是否修复缺陷
1.没有足够的时间,在项目中没有足够时间修改缺陷可能会引出其他缺陷,导致项目的推迟
2.有些缺陷只在特殊环境下出现,这种缺陷处于项目的利益考虑可以放在以后版本中进行修复升级
3.不是缺陷的缺陷。缺陷的是否修改应该由测试人员、项目经理、程序员共同讨论决定,以确保项目的正常运行
发布者:全栈程序员栈长,转载请注明出处:https://javaforall.cn/139581.html原文链接:https://javaforall.cn