关注公众号,发现CV技术之美
本篇文章分享论文『Uniform Masking: Enabling MAE Pre-training for Pyramid-based Vision Transformers with Locality』,南理工&上海AI Lab提出Uniform Masking,为基于金字塔结构的视觉Transformer进行MAE预训练!
详细信息如下:

- 论文链接:https://arxiv.org/abs/2205.10063
- 项目链接:https://github.com/implus/UM-MAE
01
摘要
Masked AutoEncoder(MAE)最近通过一种优雅的非对称编码器-解码器设计引领了视觉自监督领域的发展趋势,该设计显著优化了预训练的效率和微调精度。值得注意的是,非对称结构的成功依赖于视觉Transformer(ViT)的“全局”特性,ViT的自注意机制基于离散图像块的任意子集。
然而,目前尚不清楚如何在MAE预训练中采用基于金字塔的高级ViT(如PVT、Swin),因为它们通常在“局部”窗口中引入操作,因此很难处理部分视觉token的随机序列。在本文中,我们提出了统一掩蔽(Uniform Masking,UM)策略,成功地实现了基于金字塔的具有局部性的VIT的MAE预训练(简称“UM-MAE”)。
具体而言,UM包括一个统一采样(Uniform Sampling,US),它从每个2×2网格中严格采样1个随机patch,然后是一个二次掩蔽(Secondary Masking,SM),它将已采样区域的一部分(通常为25%)随机掩蔽为可学习token。US在多个非重叠的局部窗口中保留了等效元素,从而顺利支持流行的基于金字塔的VIT;由于本文的方法减少了阻碍语义学习的像素恢复预任务的难度,因此SM设计用于更好的可转移视觉表示。作者证明了,UM-MAE显著提高了预训练的效率,在下游任务中保持有竞争力甚至更好的微调性能。
02
Motivation
自监督学习(SSL)使用辅助任务从大规模未标记数据中挖掘自己的监督,并学习可转移到下游任务的表示。SSL首先通过GPT和BERT的“屏蔽自动编码”解决方案在自然语言处理(NLP)领域显示出巨大的潜力。这些技术通过学习基于可用上下文预测删除的数据部分,革新了NLP的范式。
受BERT成功的启发,视觉界最近对模仿其公式(即masked autoencoding)进行图像理解引起了极大的兴趣。MAE中最有影响力的设计之一是非对称编码器-解码器结构。与接收整个patch token序列的解码器部分不同,编码器部分仅将可见图像patch(通常仅占总patch的25%)作为输入。有趣的是,这种设计不仅显著降低了训练前的复杂性,而且还获得了优异的微调性能。
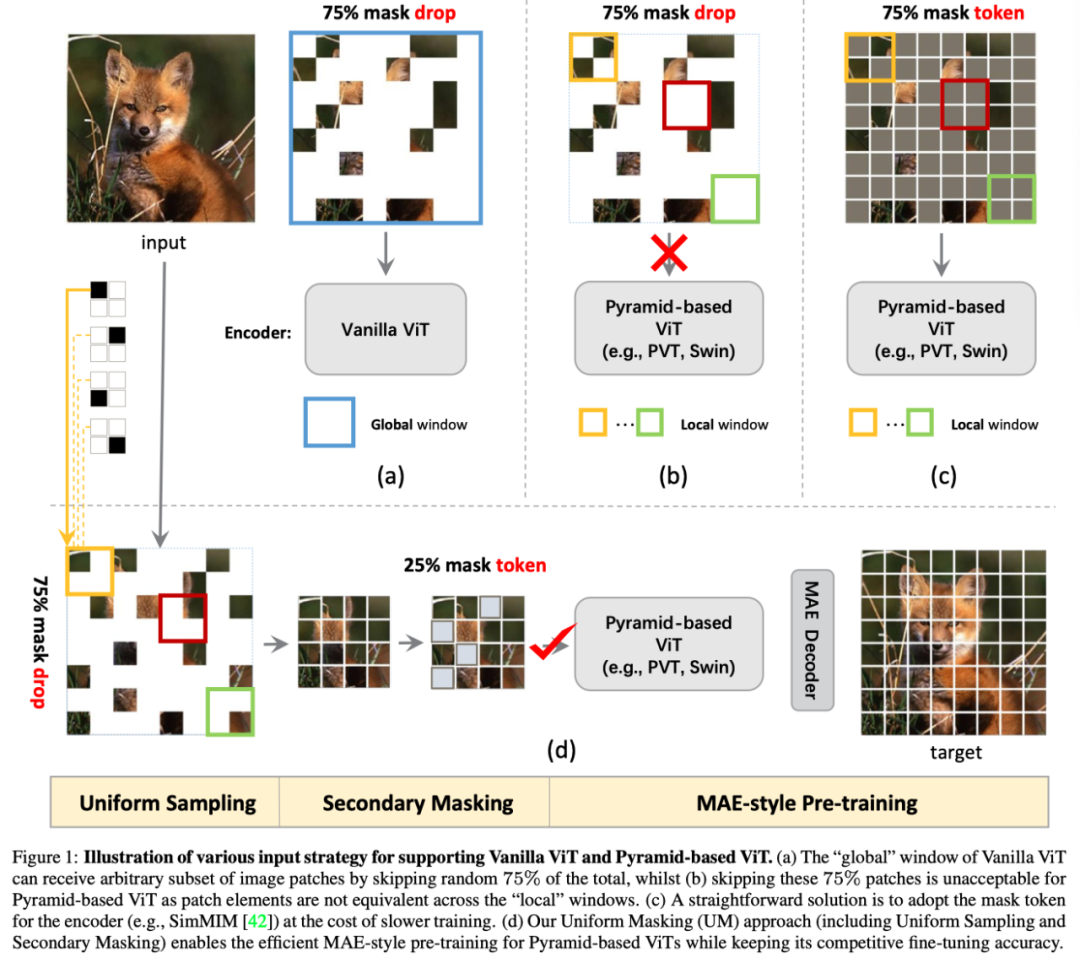
值得注意的是,非对称结构的成功应用依赖于Vanilla Vision Transformer(ViT)的“全局”特性,其自注意机制可以对离散图像块的任意子集进行推理(如上图(a))。然而,ViT的“全局”特征是一把双刃剑:当将ViT转移到具有相当大输入分辨率的下游视觉任务时,由于全局自注意的二次复杂性,其大内存需求对现代GPU来说是一个挑战。
尽管ViTDet试图在微调过程中部分限制某些ViT块的局部、窗口式自注意,但考虑到预训练和微调阶段之间的信息流可以任意不同,最优架构仍未知。因此,为了解决上述问题,基于金字塔的ViT可以是首选结构,因为通过自然引入局部窗口操作,它们更便于存储,并且它们已经证明了在转移到下游视觉任务方面的巨大兼容性和先进性。
然而,目前尚不清楚如何使用有效的不对称结构对基于金字塔的VIT进行有效的预训练,因为它们通常在“局部”窗口中进行操作。具体而言,每个局部窗口中可见元素的数量通常不相等,这妨碍了基于窗口的操作的有效并行计算(见上图(b))。一个折衷的解决方案是按照SimMIM中的召回掉下来的patch,如上图(c)所示。因此,由于编码器具有相当大的计算和存储复杂性,因此降低了效率。
为了成功地对具有局部性的基于金字塔的VIT进行MAE预训练(即采用有效的不对称结构),在本文中,作者提出了包含均匀采样(US)和二次掩蔽(SM)的均匀掩蔽(UM)策略。如上图(d)所示,作者首先从每个2×2网格中严格采样1个随机patch,使图像下降75%。与完全随机的MAE下降75%相比,US更容易泄漏语义线索,因为其抽样patch的分布比MAE的随机抽样(RS)更均匀,这减少了像素恢复预任务的难度,并阻碍了表征学习。
因此,作者进一步引入SM,以随机地将已经采样的区域中的一部分(相对较小,例如25%)屏蔽为共享的、可学习的token。最后,在原始图像分辨率四分之一的情况下,将均匀采样的patch与二次掩蔽的token重新组织为紧凑的2D输入,以便依次通过基于金字塔的ViT编码器和MAE解码器来重建原始图像像素。
03
方法
作者提出使用统一掩蔽(UM)来支持基于金字塔的VIT的MAE预训练。UM是一种简单的两阶段策略,它将密集图像token转换为稀疏图像token,但在空间上保持其均匀分布。它包括两个阶段,包括均匀抽样(US)和二次掩蔽(SM),这两个阶段共同保证了自监督学习表示的效率和质量。
3.1 Uniform Sampling
如上图(d)所示,作者首先执行均匀采样(US),即使用均匀约束对25%的可见图像块进行采样。与MAE相似,剩下75%的屏蔽patch被丢弃,并且不会参与编码器的前馈过程。下面以具有代表性的基于金字塔的VIT(PVT和Swin)为例,详细阐述了US如何使均匀分布的稀疏补丁与这些具有局部性的架构兼容。
Compatibility with PVT
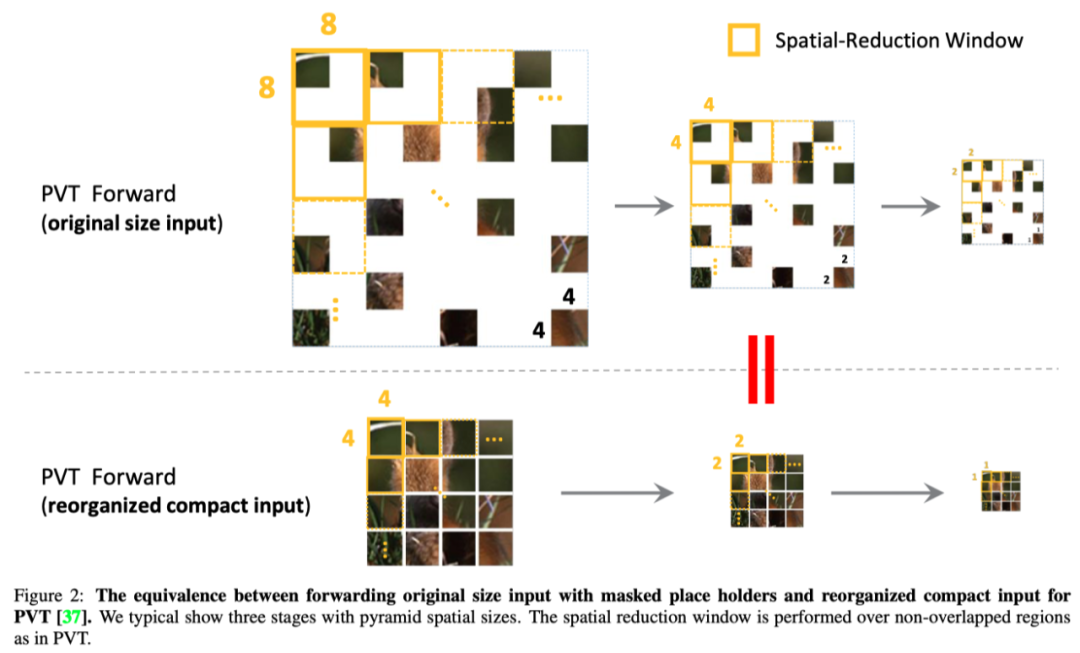
如上图所示,PVT引入了空间缩减窗口(SRW),以降低原始自注意块的复杂性,该块在每个特征对上建立关系。SRW中的信息将被聚合,以相当小的比例呈现key和value。在上图中,从均匀采样patch的输入图像开始,作者展示了PVT的前三个阶段,并将其典型的空间缩减超参数依次标记为{8,4,2}。masked patch被视为原始图像/特征空间中的空白占位符。
作者证明,对于PVT,通过同时将原始可见输入重组为其紧凑形式,并相应地将空间缩减窗口(即{4,2,1})的边缘大小减半,两条管道上相应的局部窗口之间的有效元素是等效的。因此,US与PVT兼容,当使用重组的紧凑2D图像作为输入时,对于编码器部分,输入元素减少了75%。
Compatibility with Swin
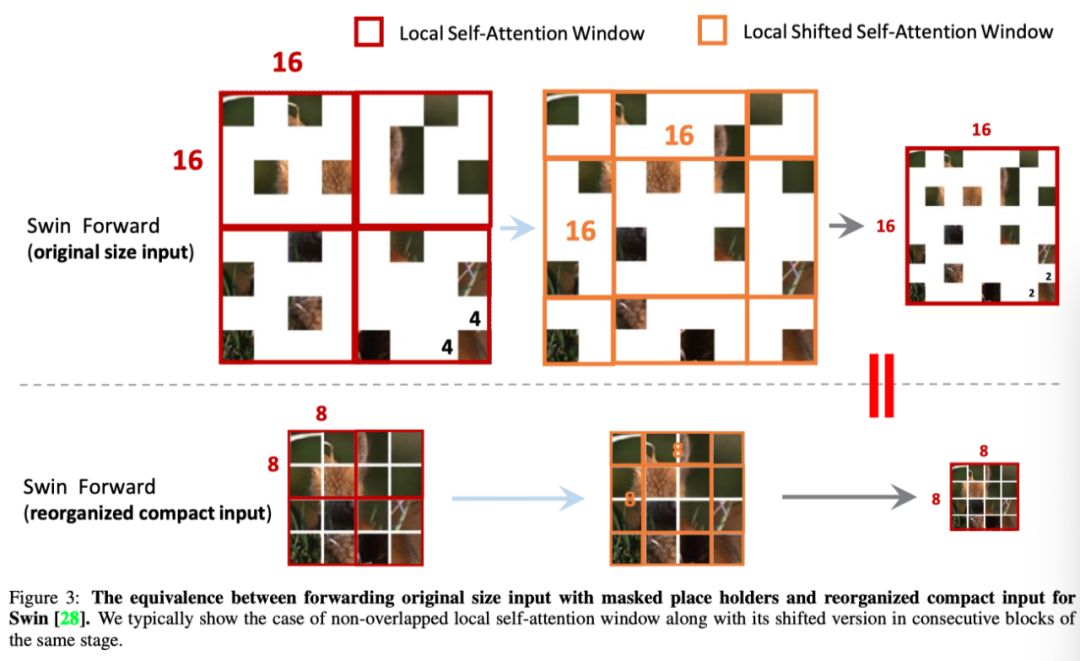
Swin与PVT有两个主要区别:(1)局部自注意窗口(LSAW)的大小通常在各个阶段固定;(2)它在连续块中具有局部自注意窗口(SLSAW)的移位版本,这引入了相邻非重叠窗口之间的连接。
基于这些差异,作者推断Swin在预训练对窗口大小和输入图像比例的选择有更多的限制:当考虑移位偏移量为
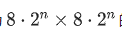
的移位情况时,窗口(和输入图像)大小为
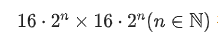
有必要确保等效性,如上图所示。在上述约束条件下,有效元素在两条管道上相应的(移动的)局部窗口之间等效,类似于PVT。
3.2 Secondary Masking
与MAE中采用的随机采样相比,均匀采样(US)对均匀分布在2D空间上的图像块进行采样,使其与具有代表性的基于金字塔的VIT兼容。然而,通过相邻的低级别图像统计数据为像素重建提供捷径,潜在地降低自监督任务的挑战性。这已经在MAE中得到证明,在MAE中,一种称为“网格化抽样”的类似抽样策略在很大程度上阻碍了表示质量。

为了解决US带来的退化问题,作者进一步提出了二次掩蔽(SM)策略,该策略在已经采样的可见patch中执行二次随机掩蔽,如上图(c)至(d)所示。与完全丢弃屏蔽patch的US阶段不同,SM通过使用共享屏蔽token来保持屏蔽patch,以确保基于金字塔的VIT与位置的兼容性。因此,简单的操作增加了语义恢复预任务的难度,该任务将网络的重点放在学习不完整视觉环境中的高质量表示,而不严重依赖相邻的低级别像素。
3.3 UM-MAE Pipeline with Pyramid-based ViT
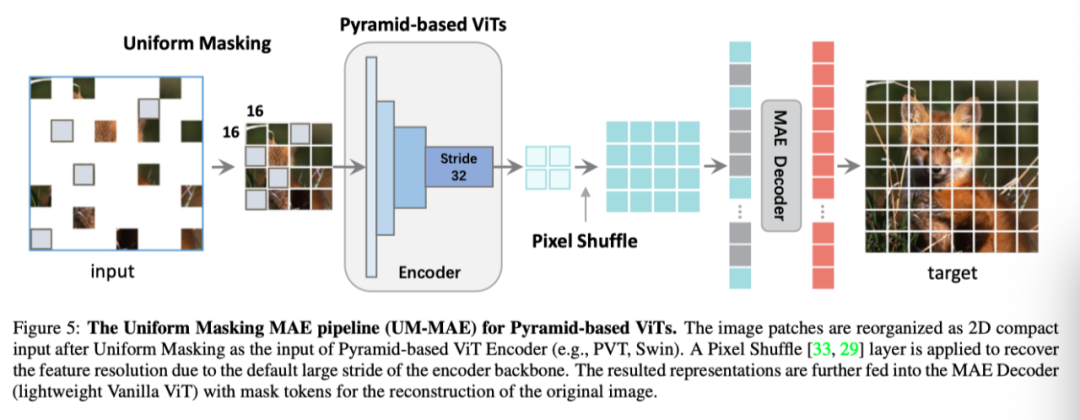
上图展示了本文的方法在应用于典型的基于金字塔的ViT(如PVT和SWN)时的详细不对称设计(即MAE风格的pipeline)。为了便于区分,作者将本文的方法命名为UM-MAE,并将其主要组成部分描述如下。
Encoder
我们遵循MAE的结构,其中操作单元为16×16图像块。执行提出的统一掩蔽以获得紧凑的、重新组织的2D输入(包括可见patch和掩蔽token)。它以缩小的比例(即全部patch的25%)作为编码器的输入。每个掩码token是一个共享的、学习到的嵌入向量。然而,分层VIT通常有四个阶段,总步长为32,这使得16×16单位最终成为亚像素。因此,在将学习到的表示反馈给解码器之前,采用亚像素卷积(即Pytorch中的PixelShuffle操作符)来恢复其分辨率。
Decoder
解码部分与MAE类似。解码器的输入是包括来自UM的编码patch和masked token。所有token都添加了位置嵌入,解码器的结构参考了MAE中采用的轻量级Vanilla ViT。
Reconstruction Target
作者通过预测均匀掩蔽期间每个丢弃的patch的像素值(MAE中的归一化版本)来重建输入。在解码器的最后一层上应用线性投影,其元素数量等于patch中像素值的数量。损失函数为均方误差(MSE),仅对丢弃的patch进行计算。
04
实验
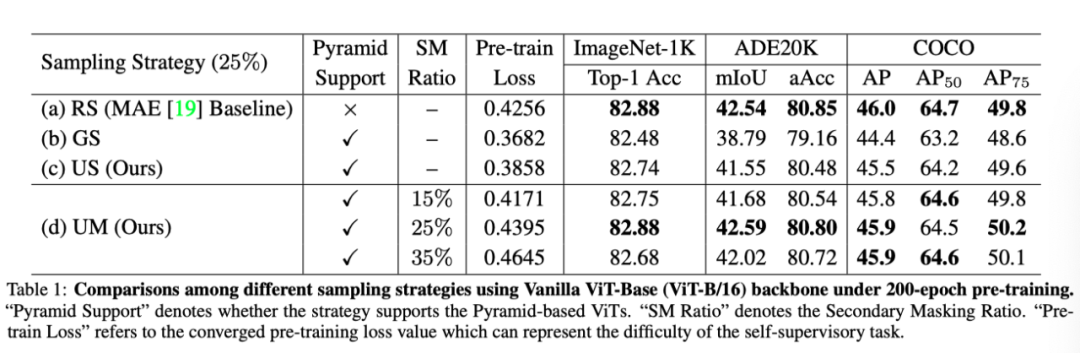
基于Vanilla ViT,提出的SM比率为25%的UM与RS(MAE基线)一样具有竞争力,而其他变体会导致微调期间的性能下降。(a)、(b)、(c)的结果表明,分布越均匀,预训练任务越简单,迁移能力越差。本文提出的UM(SM比率为25%)实现了最佳的权衡。
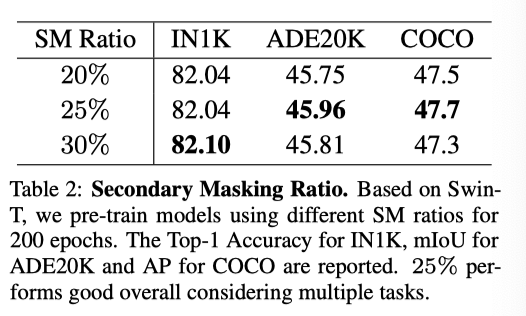
如上表所示,综合考虑性能在多个下游任务中,基于金字塔的ViT的SM比率的最佳选择是25%,与标准ViT相同。因此,在以下实验中,该比率默认为25%。

上图展示了不同预训练epoch数量,对实验结果的影响。
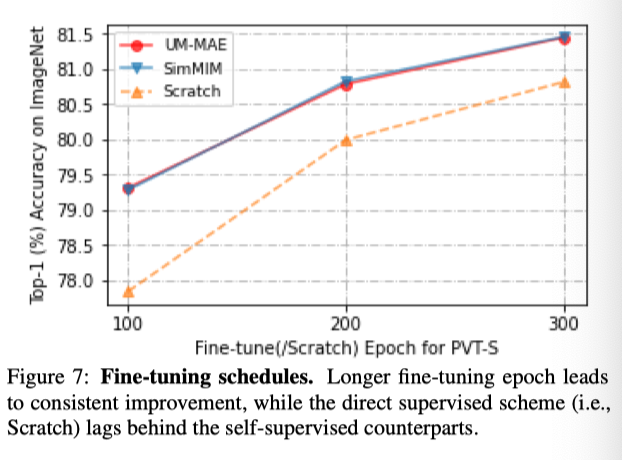
上图展示了不同微调epoch数量,对实验结果的影响。
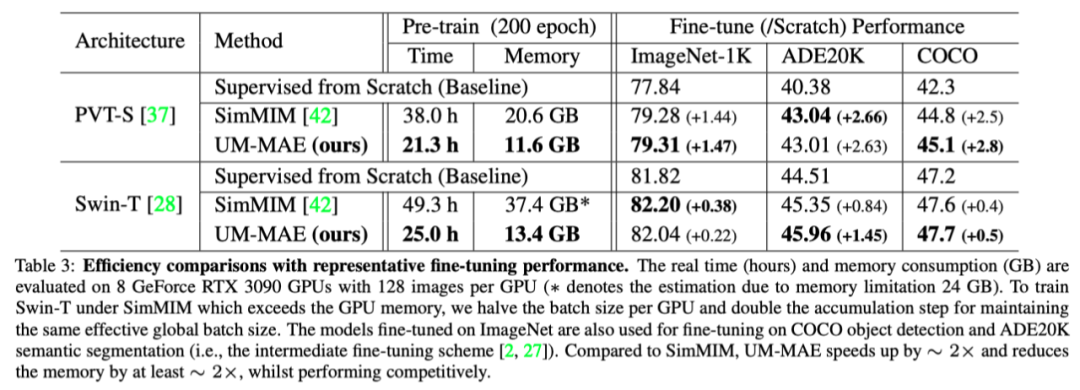
与基于金字塔的自监督VIT的SimMIM框架相比,所提出的UM-MAE的核心优势是内存和运行时效率。在上表中,作者根据PVT-S和SWN-T对200个epoch的预训练进行了清晰的比较。
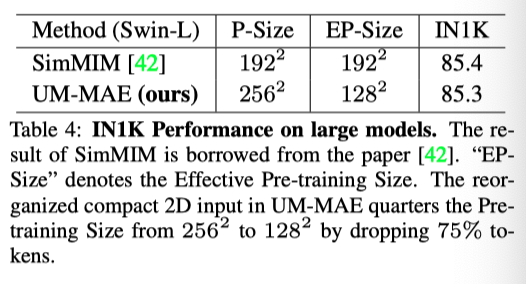
上表报告了大模型的Top-1精度,表明本文的UM-MAE在大型模型上保持了竞争力。
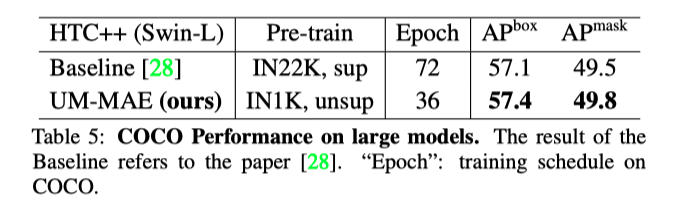
上表表明,仅在IN1K中,在UM-MAE下自监督的预训练主干甚至可以超过在IN22K中监督的主干,只使用了baseline的一半训练时间。

在上图中,我们观察到它们都大致恢复了接近原始图像的语义细节,而SimMIM的结果有时可能过于平滑,例如青蛙的长腿。
05
总结
在本文中,作者提出了一种新的统一掩蔽(UM)策略UM-MAE,该策略包含统一采样(US)和二次掩蔽(SM)步骤,成功地为基于金字塔的局部视觉Transformer进行MAE预训练。与现有备选方案SimMIM相比,UM-MAE显著提高了基于金字塔的VIT在内存和运行时方面的预训练效率,但保持了具有竞争力的微调性能。此外,作者还讨论了在MIM框架下Vanilla ViT和金字塔型ViT之间不同行为的一些实证结果。
参考资料
[1]https://arxiv.org/abs/2205.10063 [2]https://github.com/implus/UM-MAE