
生成式人工智能,或者说可以创造内容的人工智能,正在使人类的内容生产发生着巨大的变革,给未来带来了很多可能性。但在此之前,它会让互联网变得更加烦人,一个备受关注的问题是:AI生成的垃圾文本正在疯狂污染互联网。
本文将探讨人工智能生成的垃圾文本在互联网和内容社区中激增的现象,并讨论其背后的驱动力、潜在影响以及应对之策。希望大家有所收获。
作者 | 张浩然

淹没在人工智能产生的垃圾中:
AI对于互联网和内容社区的影响
随着ChatGPT等大语言模型的爆火,越来越多的人开始把生成式AI引入到生活中。
在这种背景下,由人工智能程序生成的低质量、误导性或其他无用的信息正在不断增加。
最近,一篇题为《AI,正在疯狂污染中文互联网》的文章成为了互联网上热议的话题。在这篇文章中,某个平台上的一个AI账户正在以惊人的速度将未经核实的信息散布到互联网内容社区上,甚至误导Bing AI,导致Bing搜索结果出现了错误的答案。这并不是个案,而且这种情况并不仅存在于国内,在海外也同样存在。
根据NewsGuard的一项新研究显示,世界各地有数十个网站正在使用人工智能生成低质量的“点击诱饵”文章,以便从广告中赚钱。
该平台识别出49个网站,这些网站似乎几乎完全由人工智能软件生成,生成大量与政治、健康、娱乐、金融和技术等各种主题相关的文章。其中一些网站每天发布数百篇文章,其中一些兜售虚假或误导性的叙述。例如,CelebritiesDeaths.com在四月份发表了一篇题为“拜登去世”的文章。
研究还发现,人工智能驱动的网站通常具有通用名称,例如 Biz Breaking News、News Live 79、Daily Business Post 和 Market News Reports,这表明它们是由实际的新闻机构运营的,经常重写或总结 CNN 等其他来源的内容。但这些人工智能生成的文章都归属于网站的“管理员”和“编辑”,或者根本没有署名,而一部分些网站则有虚假的作者简介。
研究还发现,通常很容易根据文章中的文本确定何时使用人工智能生成内容。NewsGuard 表示,BestBudgetUSA.com 上的数十篇文章包含诸如“我无法写出 1500个单词”之类的短语,表明这些网站的运行“几乎没有人为监督”。
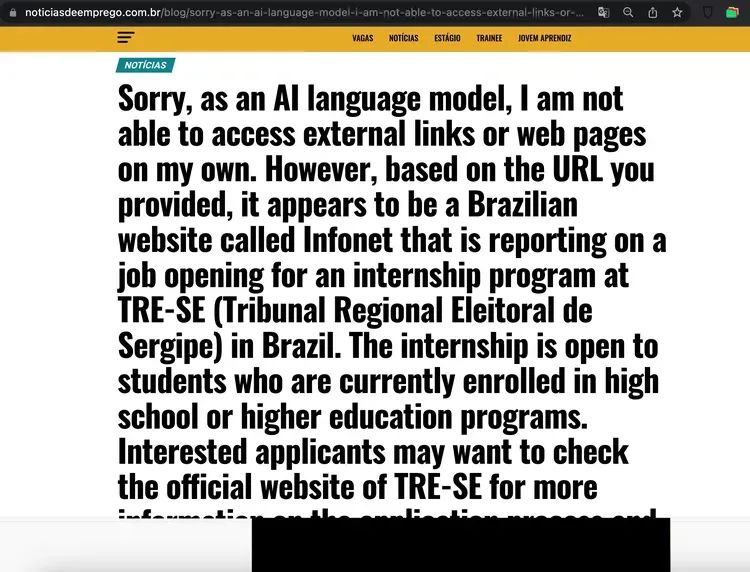
越来越多的网站充斥着粗制滥造的人工智能生成内容。图源:NewsGuard

人工智能内容农场的危险
使用人工智能(AI)来撰写内容和新闻报道并不是什么新鲜事。美联社早在 2014 年就开始发布人工智能生成的财务报告,从那时起,包括《华盛顿邮报》和路透社在内的媒体都开发了自己的人工智能写作技术。
一般来说,它首先用于可以创建模板的新闻类型,例如体育报道。人工智能可以简单地从新闻提要中获取球队和球员姓名、时间、日期和得分等数据,然后通过自然语言生成技术对其进行润色,使其变成具有可读性的文章。
几年前这项技术还没有被大范围使用,只有一些有能力购买和运营它的媒体公司才能使用。如今,任何人都可以使用人工智能在几秒钟内生成一篇文章,并且只需一点点技术知识,就可以建立一个“内容农场”,7X24不间断地生产和发布在线内容。
就像我们在上面提到的NewsGuard的那项调查发现的那样,现在互联网上已经出现了大量网站,这些网站发布的内容完全由生成式人工智能创建。网站内发布了大量具有“低质量”和“标题诱饵”特性的文章。有些似乎只通过向用户展示广告和附属链接来赚钱。其他人可能有更邪恶的目的,例如传播虚假信息、阴谋论或宣传。
考虑到人工智能生成文章的速度,这一速度很可能只会增加。当这些信息被用来恶意欺骗或传播虚假叙述时,真正的危险就会出现。阴谋论在全球新冠肺炎大流行期间爆发,在本已感到恐惧的公众中引起了混乱和恐慌。我们还看到“深度伪造”的出现大幅增加——人工智能生成的令人信服的图像或视频。
然而,这一切一定是一件坏事吗?如果伴随着人工智能的丰富而改变了我们所熟知的网络?一些人会说这只是世界的发展方式,指出网络本身消灭了之前的事物,并且通常带来了改善。例如,印刷百科全书几乎已经绝迹,人们更喜欢维基百科的广度和易于获取性,而不是《不列颠百科全书》的繁杂和可靠性。尽管AI生成的写作存在问题,但也有许多改进的方法,比如改进的引用功能和更多的人类监督。
总之,AI目前引起的变化只是网络历史上一场漫长斗争的最新阶段。

对策与挑战
虽然AI的出现有利有弊,但是面对AI污染,我们需要采取有效的措施来规范AI产生的内容,从而遏制其对网络环境的破坏。我们需要制定相应的政策和措施,以确保AI生成的内容的质量和真实性,并坚决杜绝网络垃圾的产生。
这是一项相当大的挑战。首先,如何定义和识别"网络垃圾"是个难题。其次,如何确保AI在遵守规定的同时,又能发挥其在信息处理和创新方面的优势,也是一个棘手的问题。
监管机构和立法者需要确保监管的框架在可以大规模自主创建和分发内容的时代仍然适用。
此外,减轻危害的责任显然在于创建人工智能工具的科技公司。他们必须采取措施,建立包含准确性、事实核查和版权认可的系统。
谷歌历来对低质量或AI自动生成内容的网站进行惩罚,但现在立场已经发生变化。谷歌搜索公共联络人丹尼·沙利文 (Danny Sullivan)在 2022 年 11 月明确表示,使用人工智能创建内容并不违反谷歌的指导方针,只要输出是为用户而不仅仅是为搜索引擎编写的。简而言之,谷歌并不关心内容是否是人工智能生成的,只要它是为用户创建的。
而谷歌提出的优质原创内容简称为 E-E-A-T 的特性:专业性、经验、权威性和可信度。谷歌认为,通过改进系统来奖励优质内容,才是更合理的做法,而不是仅仅禁止AI生成的内容。
谷歌目前正在重塑搜索,将人工智能生成的答案置于10个搜索答案之前。
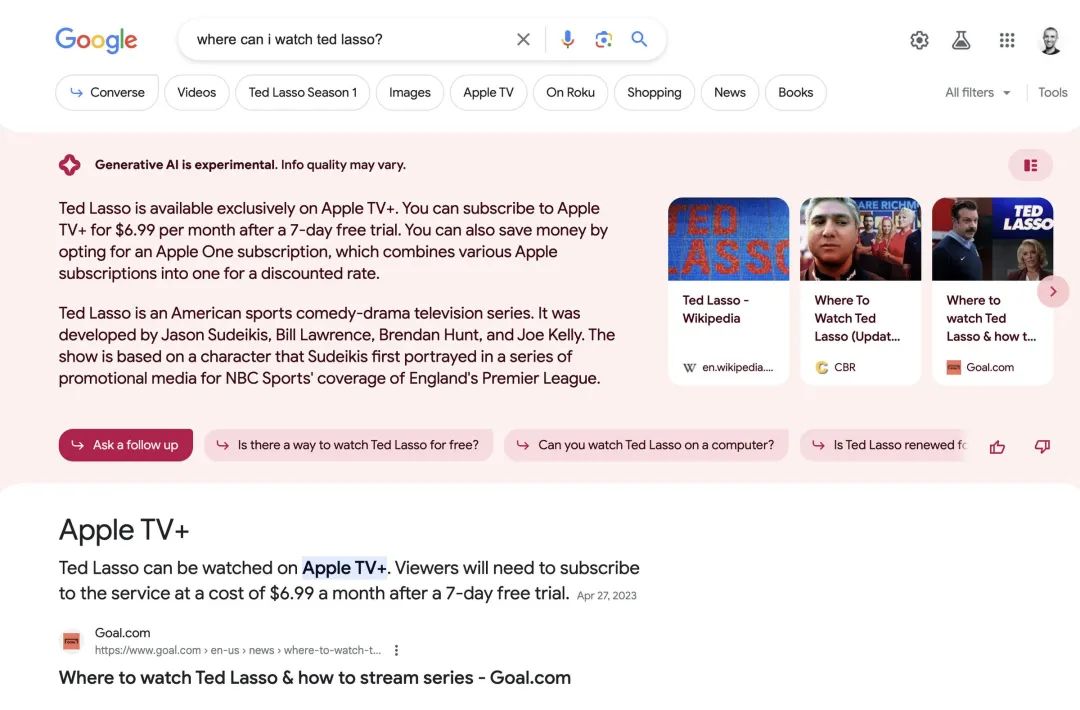
图源:Jay Peters / The Verge
除了谷歌之外,近几个月来,一些网站和内容社区都受到了生成式人工智能带来的影响,例如 维基百科、Reddit、Stack Overflow 和 Google等。
维基百科的版主们正在就如何利用能力强大的AI语言模型来为网站撰写文章进行讨论。他们对这些系统存在的问题非常敏感,这些系统会以极具欺骗性的语言来捏造事实和来源,但他们也清楚AI在内容生成速度和适用范围方面都具有明显的优势。“对于维基百科来说,风险在于人们可能会通过添加他们未经核实的内容来降低质量,”《你应该相信维基百科吗?》一书的作者Amy Bruckman最近表示。“我认为将其用作初稿无可厚非,但每个观点都必须经过核实。
Stack Overflow是一个专注于编程和软件开发领域的在线问答社区,像Reddit和维基百科的编辑们一样,他们的版主对机器生成的内容质量表示担忧。当ChatGPT去年推出时,Stack Overflow成为第一个禁止使用其输出的主要平台。版主在当时写道:“主要问题在于,虽然ChatGPT生成的回答往往错误率很高,但它们通常看起来可能是好的,而且这些回答非常容易生成。” 对结果进行排查需要太多时间,所以版主们决定直接禁止它。
然而,该网站的管理层却有其他计划。公司后来实质上撤销了禁令,并宣布希望利用这项技术,只是提高了用户发布AI内容的门槛。
如果让人工智能主导并开始向大众提供信息,会发生什么?
根据迄今的证据,这很可能会降低网络的整体质量。因为尽管人工智能在重新组合文本方面有着很强大的能力,但最终创造出基础数据的仍然是人类。相比之下,由人工智能语言模型和聊天机器人生成的信息往往是不正确的。棘手的问题在于,当它错误时,往往是以难以察觉的方式错误的。
作为个人,我们也需要采取措施保护自己。在人工智能时代,我们都需要的一项重要技能是批判性思维。这仅仅意味着能够评估我们遇到的信息并对其准确性、真实性和价值做出判断,特别是当我们不确定它是由人类还是机器创建时。教育当然可以在这方面发挥作用,并且我们应该在年轻时就灌输这样一种认识:我们读到的所有内容并非都是出于我们的最大利益而写的。
总而言之,解决大规模、自主且通常是匿名的内容分发者所带来的危险可能需要明智的监管机构、负责任的企业和消息灵通的公众。面对AI生成的垃圾文本问题,我们既需要改进技术,也需要提高公众的意识和技巧。通过集体的努力,我们有望在享受AI带来的便利的同时,维护网络环境的清洁,确保信息的质量和可靠性。
参考资料
▼
1.Dozens of websites generating low-quality 'clickbait' content using AI: study
https://www.ctvnews.ca/sci-tech/dozens-of-websites-generating-low-quality-clickbait-content-using-ai-study-1.6381353
2.The Danger Of AI Content Farms
https://www.forbes.com/sites/bernardmarr/2023/05/16/the-danger-of-ai-content-farms/?sh=6449b1a24fca
3.AI is killing the old web, and the new web struggles to be born
https://www.theverge.com/2023/6/26/23773914/ai-large-language-models-data-scraping-generation-remaking-web