
新智元报道
编辑:alan
【新智元导读】大模型的新考验来了!近日,来自卡内基梅隆大学的研究人员发布了评估LLM多模态Web代理性能的基准测试。
大模型(LLM)的多模态和Agent能力被做成基准测试了!
以后哪个LLM再掌握不了多模态,干不了Agent,都不好意思出门了。
近日,来自卡内基梅隆大学(CMU)的研究人员发布了一个评估多模态Web代理性能的基准测试。

论文地址:https://arxiv.org/pdf/2401.13649.pdf
代码和任务集:https://github.com/web-arena-x/visualwebarena
多模态和代理都是AI的发展趋势,我们之前也报道过很多相关工作,
比如帮助人类处理网上购物、会议等日常任务,比如帮助人类考试「作弊」,还有近来风头正盛的AI机器人,也是人类在物理世界的代理。
而为了训练AI掌握这项能力,研究人员花费了很多心血,比如联合世界各地的著名实验室,共享机器人的训练和操作数据,比如开发了对应于真实世界的模拟器用来训练Agent。
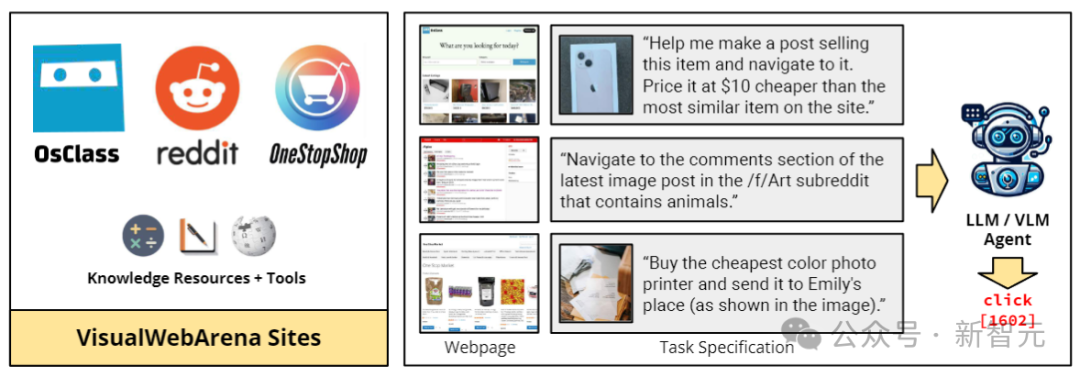
而这次,CMU的研究人员带来了LLM的考试标准,VisualWebArena。
VisualWebArena由一组基于Web的多样化和复杂的任务组成,这些任务评估自主多模式代理的各种功能:
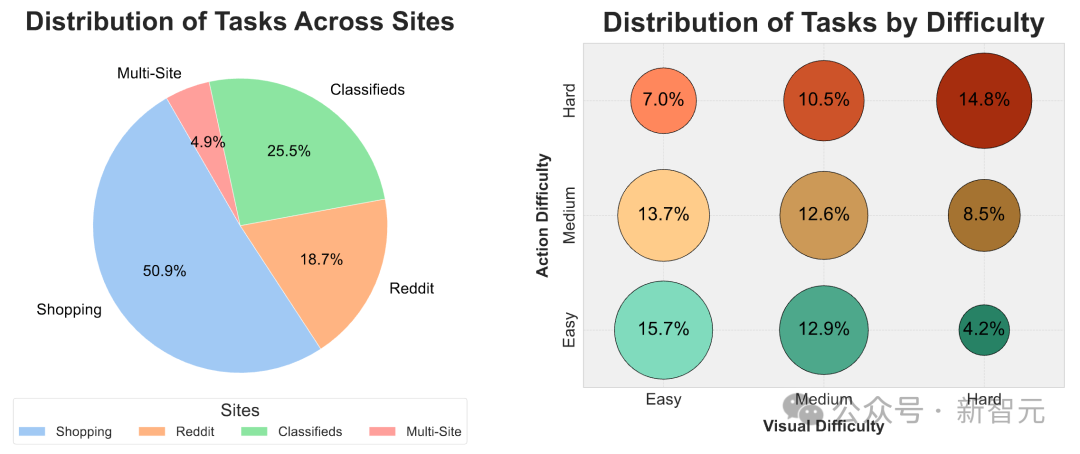
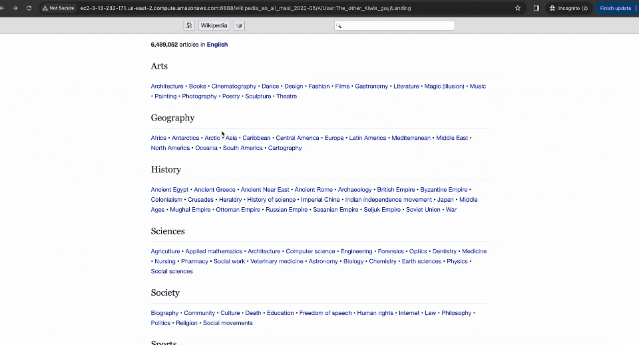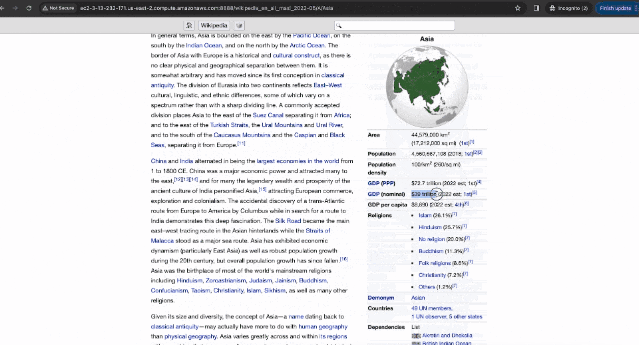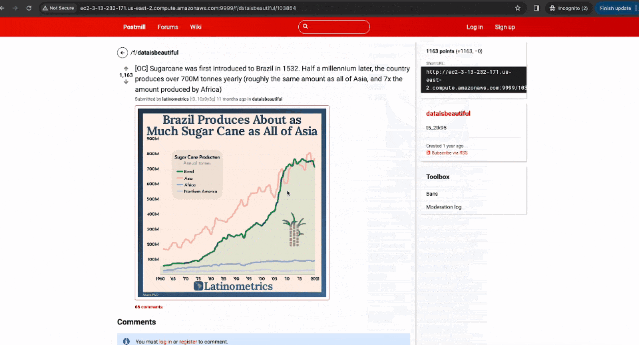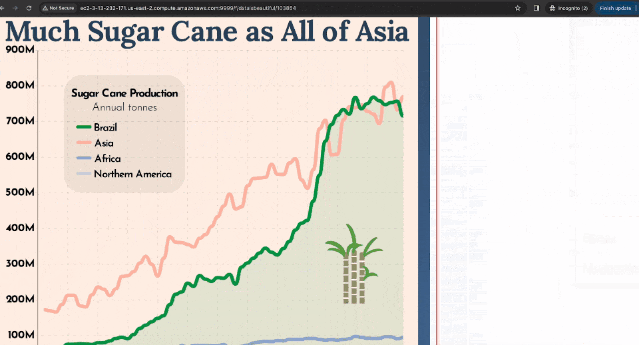
如上图所示,这个基准测试中引入了910个新任务,这些任务来自于分类广告、购物和Reddit网站上。
分类网站是一个新环境(具有真实世界的数据),而购物和Reddit网站与WebArena中使用的网站相同。
为了执行这个基准测试,代理(LLM)需要准确处理图像文本输入,解释自然语言指令,并在网站上执行操作以实现用户定义的目标。
比如在维基百科中搜索:
在Reddit上搜索、浏览和评论:
在交易网站上查阅和咨询想要购买的商品,同时小手一抖,给个五星:
比如一条龙完成线上购物:
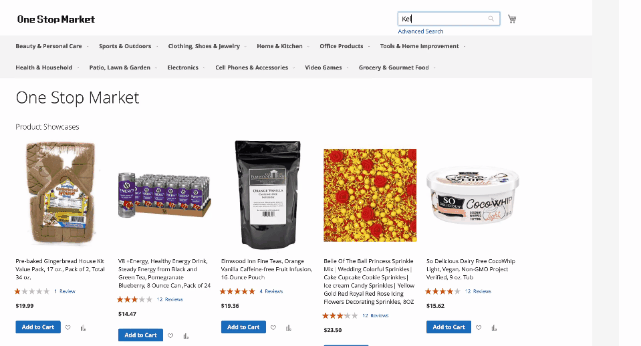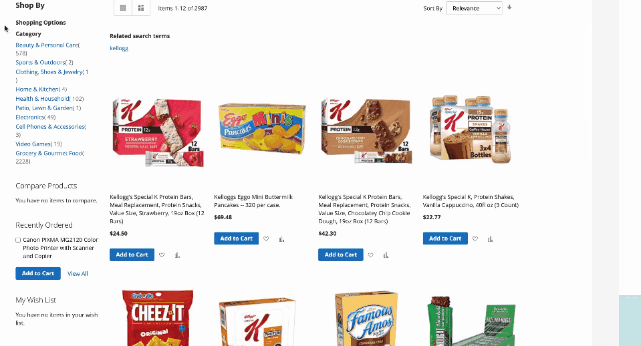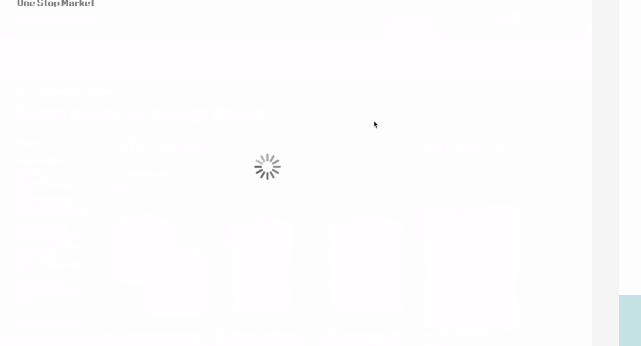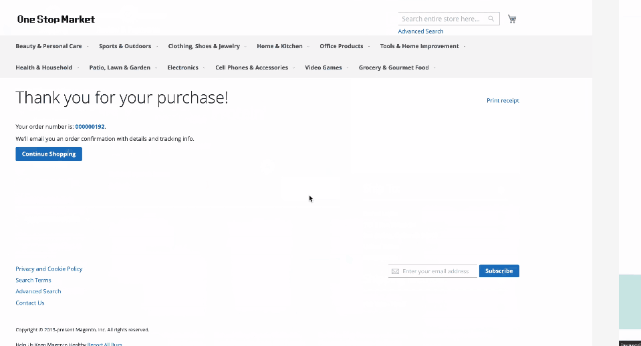
新的基准测试引入的任务需要视觉理解,能够评估基于Web的环境中自主代理的视觉和推理技能。
为了评估VisualWebArena的性能,研究人员在WebArena的功能评估范式中引入了新的基于视觉的评估指标。

上图展示了几个评估示例,通过运行基于执行的测试,可以全面评估开放式视觉基础任务上代理轨迹的正确性。
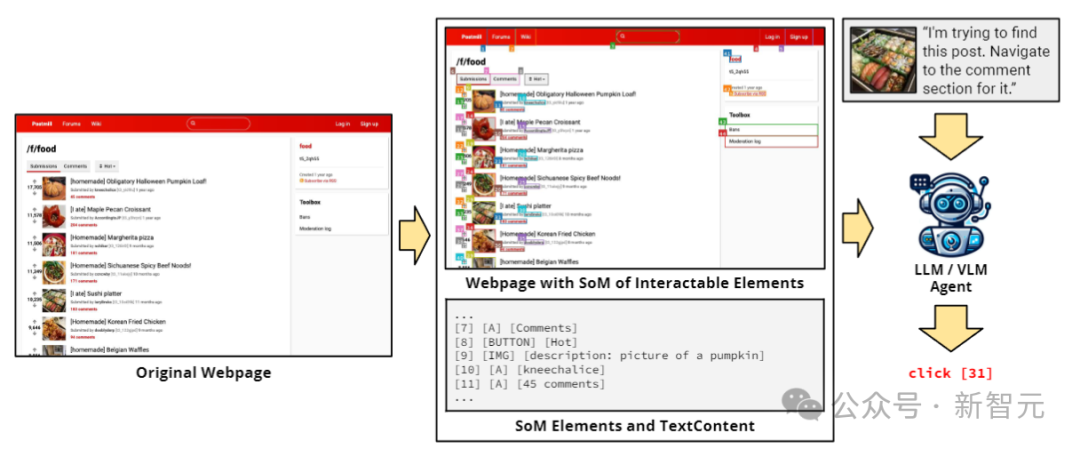
受Set-of-Mark提示的启发,研究人员使用JavaScript自动注释网页上的每个可交互元素来执行初始预处理步骤,包含边界框和唯一ID。
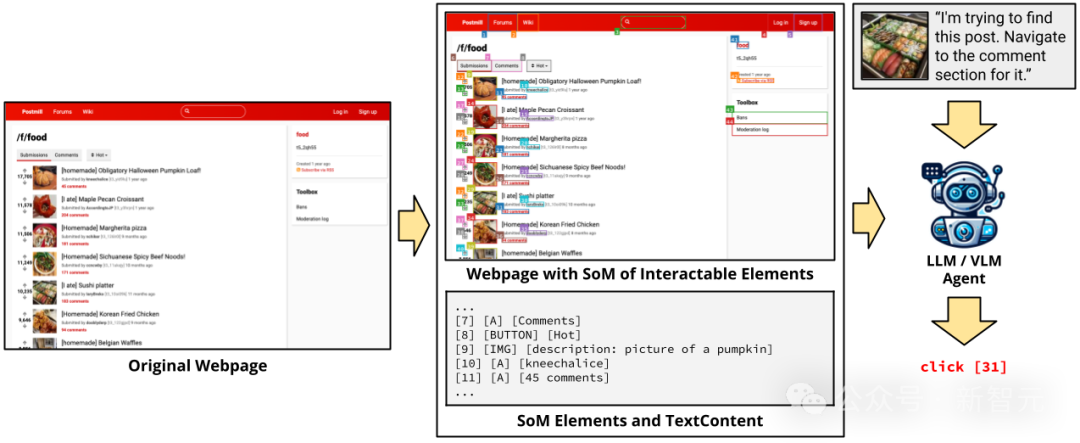
如上图所示,使用包含边界框和ID的带注释屏幕截图,以及SoM的文本表示形式,作为多模态模型的输入。
下图的结果表明,SoM表示提高了可导航性,并在VisualWebArena上实现了更高的成功率。
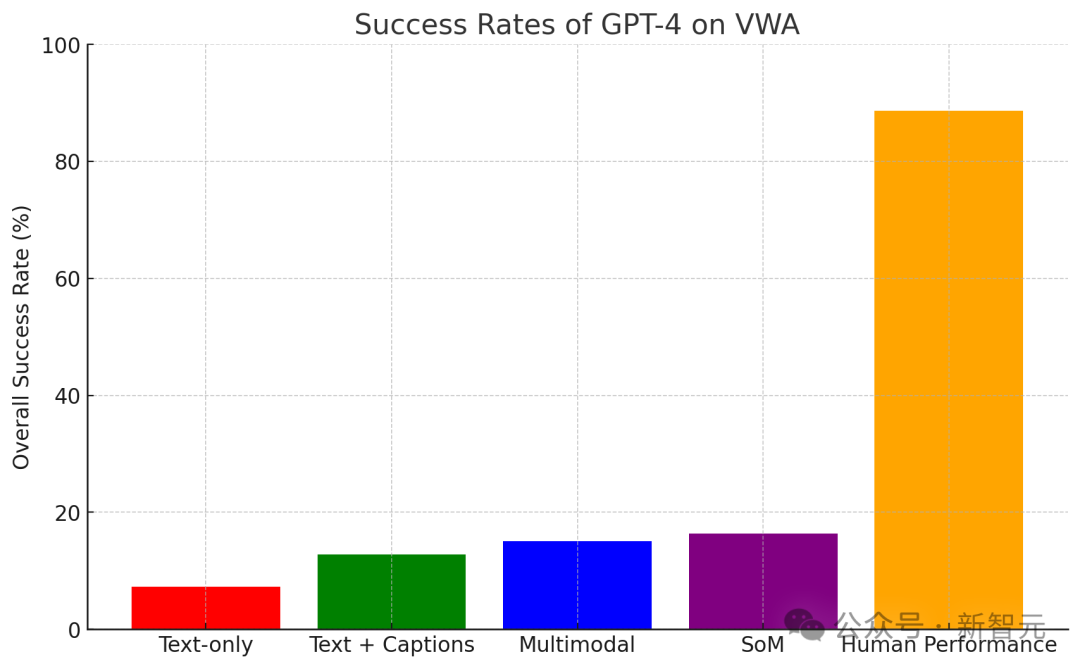
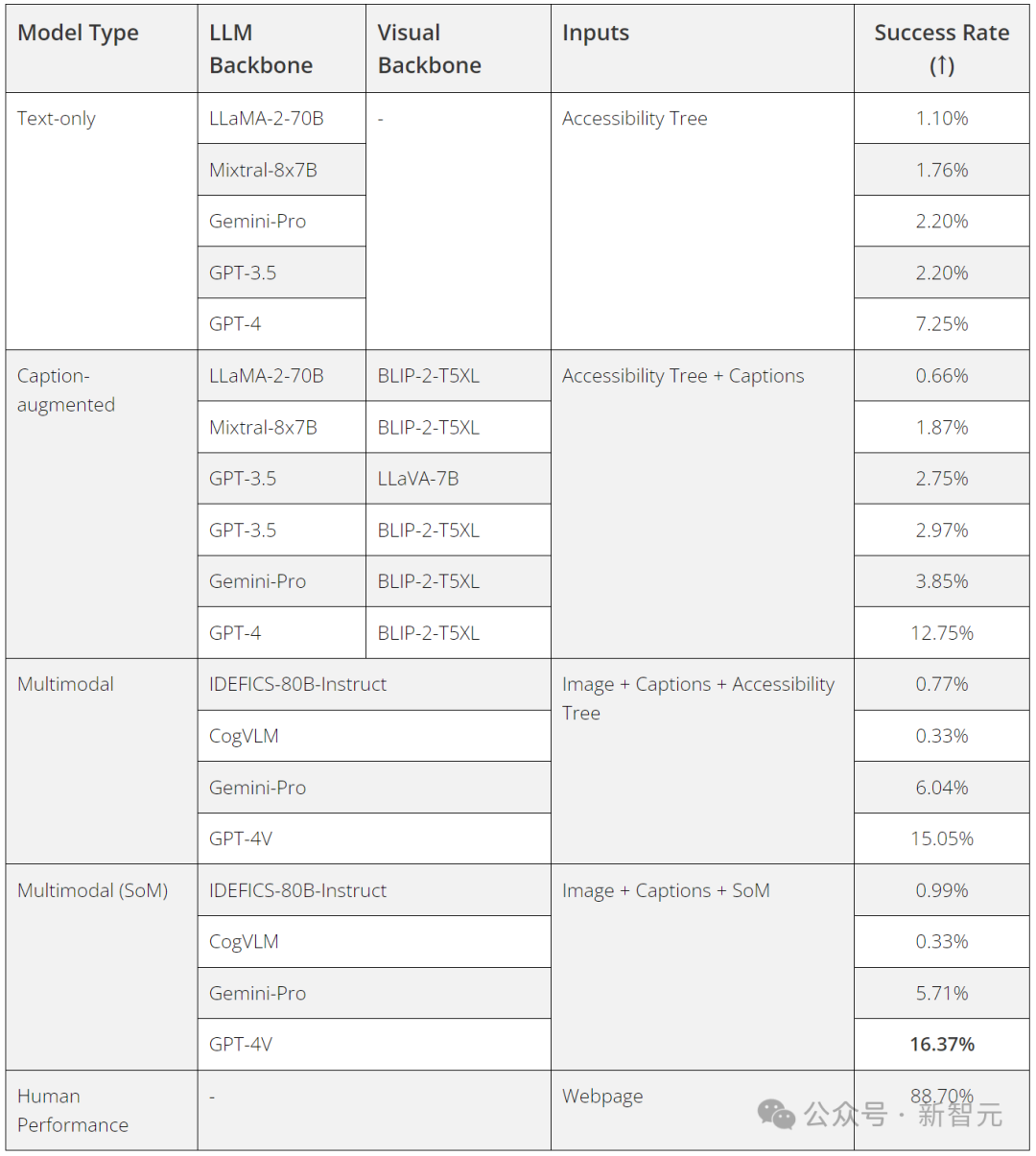
研究人员对几个最先进的LLM和基于VLM提示的代理进行了基准测试,发现所有现有的模型都明显低于人类的表现。
尽管多模态模型通常会提高VisualWebArena的性能,但仍有很大的差距需要弥合。
VisualWebArena
为了确保可重复性、真实性和确定性,VisualWebArena框架中的所有网站都可作为独立的开源Web应用程序使用。
网站中可用的文本和视觉内容是从现实世界获取的,而代码则基于现实世界应用程序中常用的开源框架。
环境和智能体可以建模为部分可观察的马尔可夫决策过程(POMDP):E =(S,A,Ω,T),其中S表示状态集,A表示行动集,Ω表示观测值集。
转移函数定义为T:S × A → S,状态之间的确定性转换以动作为条件。在每个时间步骤t中,环境都处于某种状态s(比如特定页面),并具有部分观察o∈ Ω。
代理以o为条件发出操作a ∈ A,这将导致新状态s ∈ S,以及结果页面的新部分观察o ∈ Ω。
操作可以是在网页上执行的操作,也可以只是信息搜索任务的字符串输出。
最后,定义奖励函数R :S × A → {0, 1}来衡量任务执行的成功。在VisualWebArena中,如果状态转换与任务目标的期望一致(即目标已实现),则奖励函数在最后一步返回1,否则返回0。
比如在上图的第一个任务中,奖励函数评估订单是否正确下达到输入图像中提供的确切地址,并包含正确的项目。
观察空间
观察空间Ω以真实的Web浏览体验为模型。观察结果包括网页URL、打开的选项卡(可能是不同网站的多个选项卡)以及重点选项卡的网页内容。
在大约 25% 的任务中,目标也会涉及到图像(比如上图的第一个和第三个任务)
网页内容可以用几种不同的方式表示:
- 原始网页HTML作为文档对象模型(DOM)树,通常用于以前的自治Web代理工作。
- 网页截图,表示为RGB阵列,在之前的视觉代理工作中已经证明了有效性。
- 辅助功能树,提供了针对辅助技术优化的网页内容的结构化和简化表示,是WebArena用于其基线LLM代理的主要表示。
- 本文引入的一种新的视觉表示,灵感来自标记集(SoM)提示。对于网页上的每个可交互元素,用边界框和ID标记它,生成一个屏幕截图,允许可视化代理通过其唯一ID引用页面上的元素。
操作空间
下表总结了所有操作类型。操作的参数是当前观测值o中的唯一元素ID。

相比于预测(x, y)坐标,这种表示的一个优点是,它允许专注于高级推理而非低级控制,因为许多SOTA的VLM和LLM都没有经过明确训练,以如此精细的粒度引用元素。
对于具有可访问性树表示的代理,参数是树中的元素ID。对于SoM表示,使用当前页面中分配的唯一ID。
评估
为了评估VisualWebArena的性能,我们在WebArena的功能评估范式中引入了新的基于视觉的评估指标。这些使我们能够全面评估开放式视觉基础任务的执行轨迹的正确性。每个任务的奖励都是使用下面描述的基元手工设计的函数。

上表为分配奖励r(s,a)∈ R :S × A → {0, 1} 的各种评估指标。
基于执行的奖励原语使我们能够对多样化、现实和开放式的任务进行基准测试。
根据不同的任务场景,目标的评测可以是「完全匹配」、「必须包括」、「必须不包括」、或者「模糊匹配」。
人类表现
对比实验测量了7名大学生(熟悉网站的商业版本)在VisualWebArena任务上的成功率。
不过因为其中的一些人还协助创建了任务,为了避免数据泄露,这里确保他们不会被分配到自己创建的任务。
实验对每个模板一个任务进行采样,收集了具有代表性的230个任务。结果发现人类在这项任务上做得很好,总体成功率为88.7%。

而在剩下的11.3%的任务中,人类犯的错误通常是轻微的,例如没有正确阅读任务或错过了目标的一部分。
当然也有另一种失败模式,比如受试者在搜索5-10分钟后找不到合适的帖子并放弃,认为任务无法完成。
参考资料:
https://arxiv.org/abs/2401.13649