1.简介
前边宏哥拖拽有提到那个反爬虫机制,加了各种参数,以及加载js脚本文件还是有问题,偶尔宏哥好像发现了解决问题的办法,看到了黎明的曙光,宏哥就说试一下看看行不行,万一实现了。结果宏哥试了结果真的OK啊,但是宏哥第一次运行可以,后边就不行了,然后将编辑器关闭重启,再次运行又可以,宏哥猜测可能是缓冲问题吧,但是具体原因还是没有查到。所以就加更一篇来记录是如何解决的。而且最近有一些爬虫用户私信给宏哥留言:在使用 playwright 的时候,提到 playwright 默认是用无痕模式打开的浏览器,很多网站会有反爬机制,使用无痕模式打开的时候功能无法正常使用。问宏哥有没有好的办法。宏哥答复暂时也没有好办法,也不知道宏哥这种解决方法会不会帮到他们,或者对他们有参考价值。
2.启动浏览器的模式
playwright 提供了 launch_persistent_context 启动浏览器的方法,可以非无痕模式启动浏览器。
无痕模式启动浏览器适合做自动化测试的人员
非无痕模式启动浏览器适合一些爬虫用户人员
2.1无痕模式启动浏览器
launch()方法是无痕模式启动浏览器。
参考代码如下:
# coding=utf-8🔥1.先设置编码,utf-8可支持中英文,如上,一般放在第一行
2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2023-10-10
@author: 北京-宏哥 QQ交流群:705269076
公众号:北京宏哥
Project: 《《最新出炉》系列初窥篇-Python+Playwright自动化测试-21-处理鼠标拖拽-番外篇
'''3.导入模块
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
page.goto("https://www.cnblogs.com/du-hong")# do .... page.pause() browser.close()</code></pre></div></div><p>无痕模式启动浏览器,会在浏览器右上角出现“无痕模式”,如下图所示:</p><figure class=""><div class="rno-markdown-img-url" style="text-align:center"><div class="rno-markdown-img-url-inner" style="width:100%"><div style="width:100%"><img src="https://cdn.static.attains.cn/app/developer-bbs/upload/1723053368270451909.png" /></div></div></div></figure><h5 id="7ihd5" name="2.2%E9%9D%9E%E6%97%A0%E7%97%95%E6%A8%A1%E5%BC%8F%E5%90%AF%E5%8A%A8%E6%B5%8F%E8%A7%88%E5%99%A8">2.2非无痕模式启动浏览器</h5><p>如果网站被识别或者被监测无痕模式不能使用,那么可以用 launch_persistent_context()方法非无痕模式启动浏览器。</p><p>相关参数说明:</p><ul class="ul-level-0"><li>user_data_dir : 用户数据目录,此参数是必须的,可以自定义一个目录</li><li>accept_downloads: 接收下载事件</li><li>headless: 是否设置无头模式</li><li>channel: 指定浏览器类型,默认chromium</li></ul><p><strong>参考代码如下:</strong></p><div class="rno-markdown-code"><div class="rno-markdown-code-toolbar"><div class="rno-markdown-code-toolbar-info"><div class="rno-markdown-code-toolbar-item is-type"><span class="is-m-hidden">代码语言:</span>javascript</div></div><div class="rno-markdown-code-toolbar-opt"><div class="rno-markdown-code-toolbar-copy"><i class="icon-copy"></i><span class="is-m-hidden">复制</span></div></div></div><div class="developer-code-block"><pre class="prism-token token line-numbers language-javascript"><code class="language-javascript" style="margin-left:0"># coding=utf-8🔥1.先设置编码,utf-8可支持中英文,如上,一般放在第一行
2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2023-10-10
@author: 北京-宏哥 QQ交流群:705269076
公众号:北京宏哥
Project: 《《最新出炉》系列初窥篇-Python+Playwright自动化测试-21-处理鼠标拖拽-番外篇
'''3.导入模块
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch_persistent_context( # 指定本机用户缓存地址 user_data_dir=f"C:\\Users\\DELL\\Desktop\\Chrome\\test", # 接收下载事件 accept_downloads=True, # 设置 GUI 模式 headless=False, bypass_csp=True, slow_mo=1000, channel="chrome" ) page = browser.new_page() page.goto("https://www.cnblogs.com/du-hong") # do .... page.pause() browser.close()</code></pre></div></div><p>宏哥发现以上代码运行后,会多出一个空白页。如下图所示:</p><figure class=""><div class="rno-markdown-img-url" style="text-align:center"><div class="rno-markdown-img-url-inner" style="width:100%"><div style="width:100%"><img src="https://cdn.static.attains.cn/app/developer-bbs/upload/1723053368595418124.png" /></div></div></div></figure><p>进入launch_persistent_context方法,发现是因为使用launch_persistent_context方法会自动打开一个tab标签页,后面代码browser.new_page()重新打开了一个新的page对象。所以才会多一个空白页。</p><p>解决办法很简单,去掉browser.new_page()代码即可。直接用默认打开发tab标签页对象。</p><p><strong>参考代码如下:</strong></p><div class="rno-markdown-code"><div class="rno-markdown-code-toolbar"><div class="rno-markdown-code-toolbar-info"><div class="rno-markdown-code-toolbar-item is-type"><span class="is-m-hidden">代码语言:</span>javascript</div></div><div class="rno-markdown-code-toolbar-opt"><div class="rno-markdown-code-toolbar-copy"><i class="icon-copy"></i><span class="is-m-hidden">复制</span></div></div></div><div class="developer-code-block"><pre class="prism-token token line-numbers language-javascript"><code class="language-javascript" style="margin-left:0"># coding=utf-8🔥1.先设置编码,utf-8可支持中英文,如上,一般放在第一行
2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2023-10-10
@author: 北京-宏哥 QQ交流群:705269076
公众号:北京宏哥
Project: 《《最新出炉》系列初窥篇-Python+Playwright自动化测试-21-处理鼠标拖拽-番外篇
'''3.导入模块
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch_persistent_context( # 指定本机用户缓存地址 user_data_dir=f"C:\\Users\\DELL\\Desktop\\Chrome\\test", # 接收下载事件 accept_downloads=True, # 设置 GUI 模式 headless=False, bypass_csp=True, slow_mo=1000, channel="chrome" ) page = browser.pages[0] page.goto("https://www.cnblogs.com/du-hong") # do .... page.pause() browser.close()</code></pre></div></div><p><strong>运行代码,如下图所示:</strong></p><figure class=""><div class="rno-markdown-img-url" style="text-align:center"><div class="rno-markdown-img-url-inner" style="width:100%"><div style="width:100%"><img src="https://cdn.static.attains.cn/app/developer-bbs/upload/1723053369023786418.png" /></div></div></div></figure><h4 id="dcjqu" name="3.%E9%A1%B9%E7%9B%AE%E5%AE%9E%E6%88%98">3.项目实战</h4><p>这里宏哥还用之前的那个实例进行演示,也就是在文章最后提到反爬虫的那篇文章的例子:携程旅行,手机号查单页面的一个滑动,进行项目实战。如下图所示:</p><figure class=""><div class="rno-markdown-img-url" style="text-align:center"><div class="rno-markdown-img-url-inner" style="width:100%"><div style="width:100%"><img src="https://cdn.static.attains.cn/app/developer-bbs/upload/1723053369587961344.png" /></div></div></div></figure><h5 id="apqa2" name="3.1%E4%BB%A3%E7%A0%81%E8%AE%BE%E8%AE%A1">3.1代码设计</h5><p>参考前边提到的方法进行代码设计如下:</p><figure class=""><div class="rno-markdown-img-url" style="text-align:center"><div class="rno-markdown-img-url-inner" style="width:100%"><div style="width:100%"><img src="https://cdn.static.attains.cn/app/developer-bbs/upload/1723053369901708251.png" /></div></div></div></figure><h5 id="c90qe" name="3.2%E5%8F%82%E8%80%83%E4%BB%A3%E7%A0%81">3.2参考代码</h5><div class="rno-markdown-code"><div class="rno-markdown-code-toolbar"><div class="rno-markdown-code-toolbar-info"><div class="rno-markdown-code-toolbar-item is-type"><span class="is-m-hidden">代码语言:</span>javascript</div></div><div class="rno-markdown-code-toolbar-opt"><div class="rno-markdown-code-toolbar-copy"><i class="icon-copy"></i><span class="is-m-hidden">复制</span></div></div></div><div class="developer-code-block"><pre class="prism-token token line-numbers language-javascript"><code class="language-javascript" style="margin-left:0"># coding=utf-8🔥1.先设置编码,utf-8可支持中英文,如上,一般放在第一行
2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2023-10-10
@author: 北京-宏哥 QQ交流群:705269076
公众号:北京宏哥
Project: 《《最新出炉》系列初窥篇-Python+Playwright自动化测试-21-处理鼠标拖拽-番外篇
'''3.导入模块
from playwright.sync_api import Playwright, sync_playwright, expect
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch_persistent_context(
# 指定本机用户缓存地址
user_data_dir=f"C:\Users\DELL\Desktop\Chrome\test",
# 接收下载事件
accept_downloads=True,
# 设置 GUI 模式
headless=False,
bypass_csp=True,
slow_mo=1000,
channel="chrome"
)
page = browser.pages[0]
page.goto("https://passport.ctrip.com/user/member/fastOrder")
page.wait_for_timeout(2000)
#获取拖动按钮位置并拖动 //*[@id="slider"]/div[1]/div[2]
dropbutton=page.locator("//*[@id='slider']/div[1]/div[2]")
box=dropbutton.bounding_box()
page.mouse.move(box['x']+box['width']/2,box['y']+box[ 'height']/2)
page.mouse.down()
mov_x=box['x']+box['width']/2+280
page.mouse.move(mov_x,box['y']+box[ 'height']/2)
page.mouse.up()
page.wait_for_timeout(3000)
browser.close()
with sync_playwright() as playwright:
run(playwright)
3.3运行代码
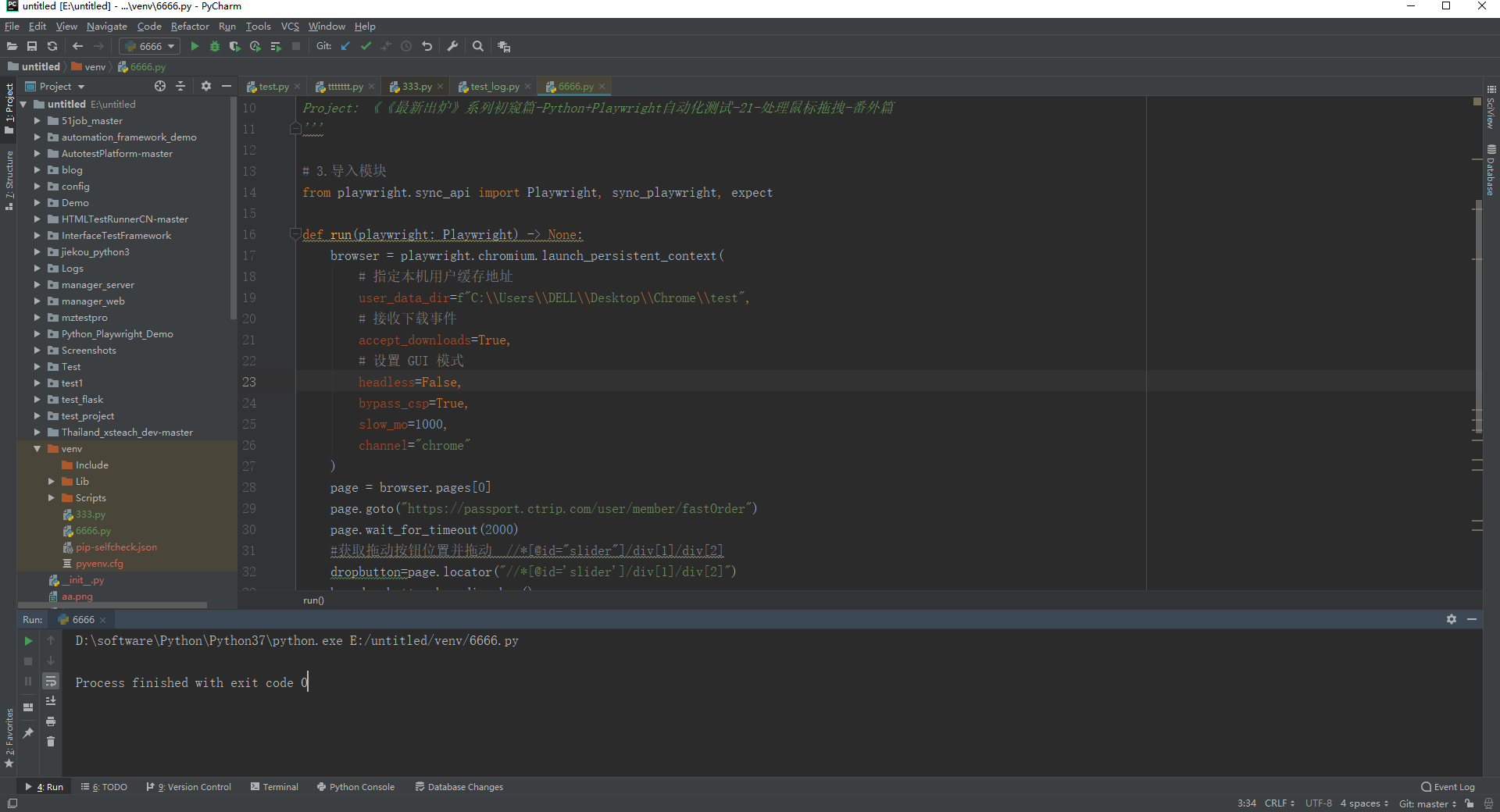
1.运行代码,右键Run'Test',控制台输出,如下图所示:
2.运行代码后电脑端的浏览器的动作(可以清楚地的看到滑动后,出现“校验成功,通过”的字样,而不是之前出现的那种反爬虫机制,又弹出选字校验)。如下图所示:

好了,到此大功告成,问题就解决了。
4.小结
1. launch_persistent_context创建的浏览器对象,为什么无法使用browser.new_context()创建上下文?
因为launch_persistent_context字面上意思就已经是一个context上下文对象了,所以无法创建上下文,只能创建page对象。
2.user_data_dir路径参数的作用什么?
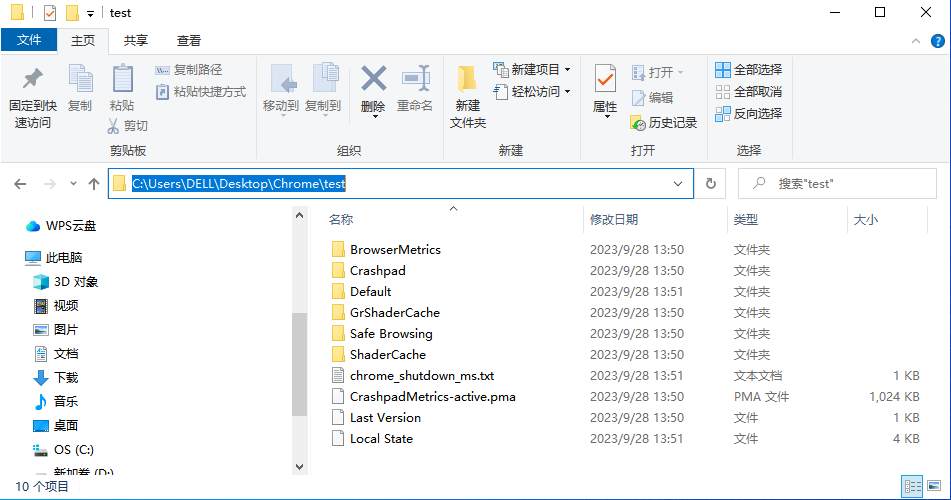
user_data_dir是指定浏览器启动的用户数据缓存目录,当指定一个新的目录时,启动浏览器会发现自动生成缓存文件。打开C:\Users\DELL\Desktop\Chrome\test目录会看到加载的浏览器缓存文件。如下图所示:
3.user_data_dir能不能记住用户登录的状态?
user_data_dir就是你自己定义的打开浏览器保存的用户数据,包含了用户的cookies,所以你只要登录过,就会自动保存。
所以你只要代码打开网站,如果不能通过代码自动登录(可能有一些验证码什么的),你可以断点后手工去登录一次,也会记住cookies。下次代码再打开就不需要登录了。
4.为什么按你的教程,我这个网站就无法保持登录?
能不能保持登录状态,主要看你网站的cookies有效期,有些网站关闭浏览器后就失效了,比如一些银行的网站,你只要关闭浏览器窗口,下次就需要再次登录。
简单来说一句话:你手工去操作一次,关闭浏览器,再打开还要不要登录,如果关闭浏览器需要再次登录,那代码也没法做到保持登录。
有些博客网站,你登录一次,cookies几个月都有效,这种就可以利用缓存的cookies保持登录。
5.为什么网上其他教程user_data_dir写chrome的安装目录?
其实没必要非要写chrome的安装目录"C:\Users{getpass.getuser()}\AppData\Local\Google\Chrome\UserData"。
如果你写的是系统默认安装目录的用户数据,那你本地浏览器打开后,执行代码就会报错。所以不推荐!
6.默认启动的是chromium浏览器,能不能换成其他的浏览器?
可以通过"channel"参数指定浏览器,可以支持chromium系列:chromium、chrome、chrome-beta、msedge。
7.如何设置窗口最大化?
添加args=['--start-maximized']和no_viewport=True两个参数设置窗口最大化。
browser = p.chromium.launch_persistent_context(
# 指定本机用户缓存地址
user_data_dir=f"D:\chrome_userx\yoyo",
# 接收下载事件
accept_downloads=True,
# 设置 GUI 模式
headless=False,
bypass_csp=True,
slow_mo=1000,
channel="chrome",
args=['--start-maximized'],
no_viewport=True
)或者使用viewport={'width':1920,'height':1080}设置屏幕分辨率
browser = p.chromium.launch_persistent_context(
# 指定本机用户缓存地址
user_data_dir=f"D:\chrome_userx\yoyo",
# 接收下载事件
accept_downloads=True,
# 设置 GUI 模式
headless=False,
bypass_csp=True,
slow_mo=1000,
channel="chrome",
viewport={'width': 1920, 'height': 1080}
)我正在参与2023腾讯技术创作特训营第二期有奖征文,瓜分万元奖池和键盘手表