在看书的时候,书上的项目提到了这个网站,于是尝试了一下不看书上的源代码自己实现这个爬取功能,巩固一下。
效果展示
源代码
代码的实现过程很简单,就是将网站的HTML文件下载下来,然后通过bs4解析,select()获取漫画的存放漫画的<img>元素并得到src属性定位到漫画的资源地址。然后通过wb二进制写入从漫画资源地址获取的文件信息。这样就完成了漫画的下载。
但是这样只能完成首页第一张图片的下载。
那么如何下载多张漫画呢?
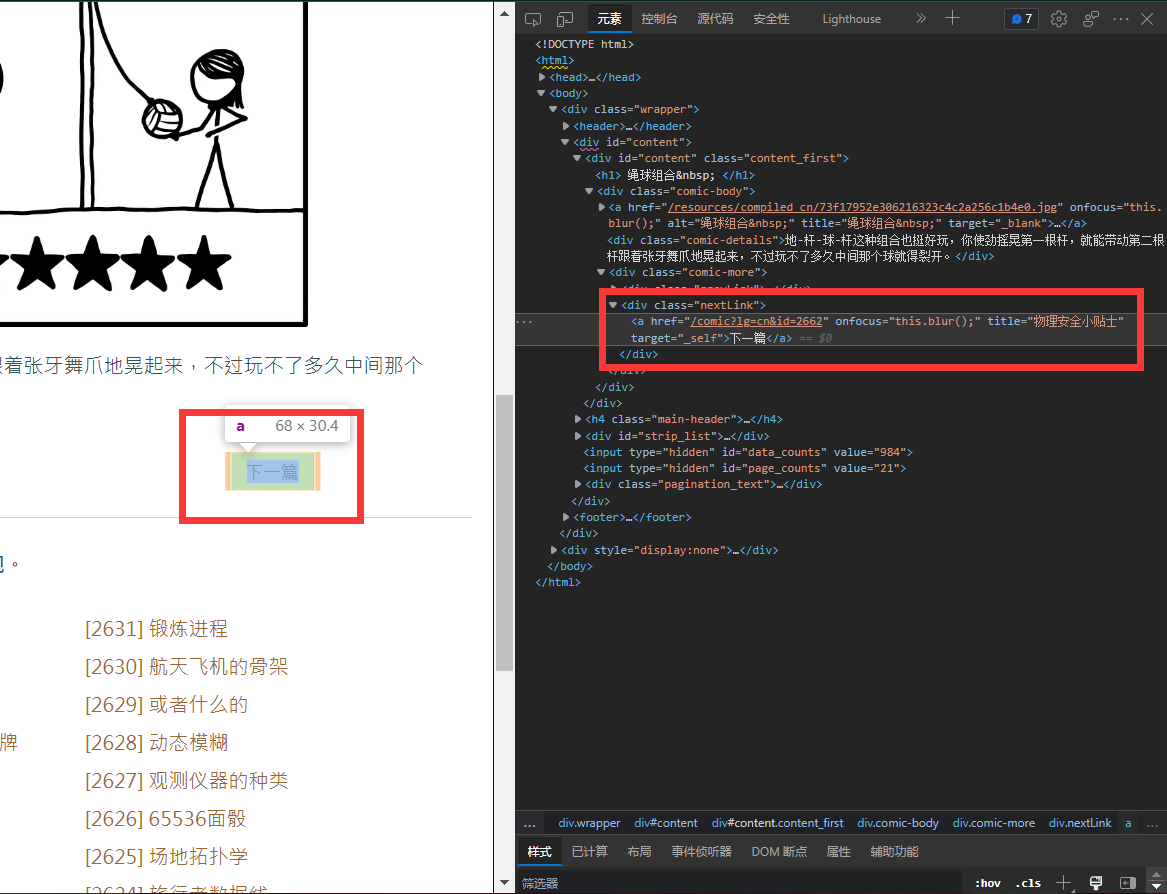
我们进入网页,发现了下一篇按钮,选中然后检查元素,同理可以定位下一篇漫画的资源地址。
btn = parser.select('.nextLink > a[title]')
next = btn[0].get('href')获取该元素的下一篇漫画的URL,然后同上下载漫画即可。
最后用循环来获取想要下载的漫画篇数。
import requests import bs4def next_page(url):
file = open('1.html', encoding='utf-8')
parser = bs4.BeautifulSoup(file.read(), 'html.parser')
btn = parser.select('.nextLink > a[title]')
next = btn[0].get('href')
nextURL = url + next
return nextURLurl = 'https://xkcd.in/'
link = url
num = eval(input("请输入你需要下载的页数:"))
print("正在下载中......")for i in range(0, num):
# 获取该网页的HTML文件
web_req = requests.get(link)
html_file = open('1.html', 'wb')
for chunk in web_req.iter_content(10000):
html_file.write(chunk)html_file.close() # 获取该网页HTML文件的img标签 html = open('1.html', encoding='utf-8') soup = bs4.BeautifulSoup(html.read(), 'html.parser') elems = soup.select('img[title]') # 获取图片的资源地址 payload = elems[0].get('src') title = elems[0].get('title') # 重组url定位到图片的地址 src = url + payload img_req = requests.get(src) file_ad = 'img/' + title.replace("?", "") + '.jpg' jpg = open(file_ad, 'wb') for chunk in img_req.iter_content(10000): jpg.write(chunk) print("正在下载:" + title) link = url link = next_page(link) html.close() jpg.close()
print("下载成功!")