前言
在 Python 中,包是组织代码的重要方式,它使得代码的管理和复用变得更加高效和简洁。本文详细讲解了 Python 包的概念和使用以及如何利用第三方包扩展 Python 的功能和特性。
本篇文章参考:黑马程序员
一、自定义包
1. 什么是Python包?
思考:在Python编程中,通过导入外部模块可以扩展代码的功能。但是,如果Python的模块过多,可能会造成一定的混乱,我们应该如何管理呢?
答:可使用Python包的结构和管理方式来有效组织和管理这些模块。
Python包(Package)是一种组织和管理Python模块的方式。
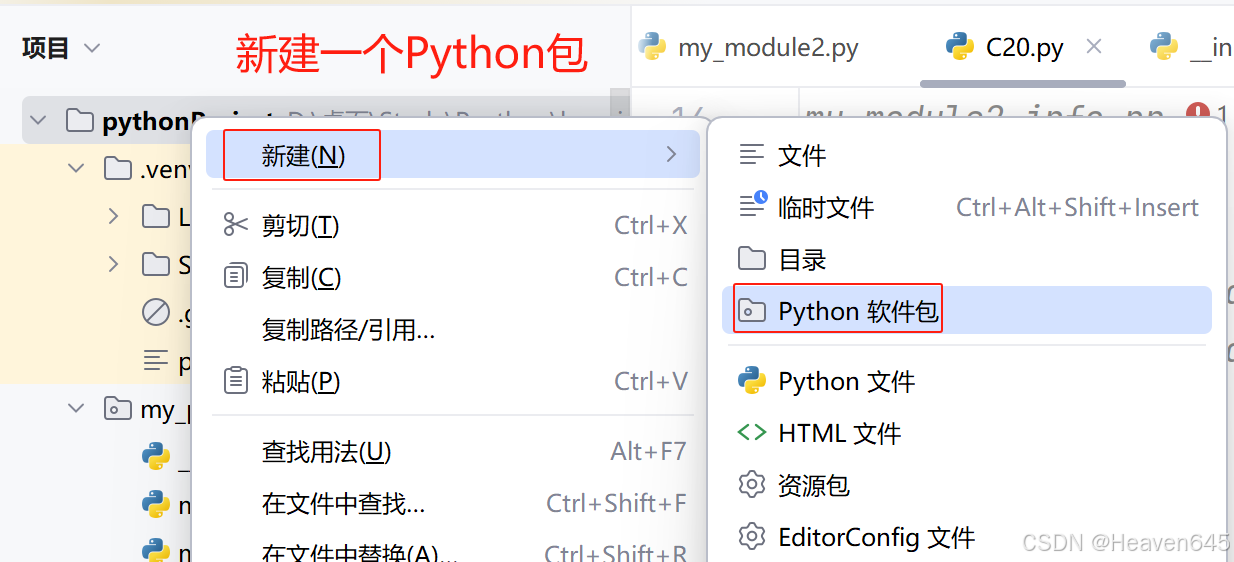
2. 目录结构
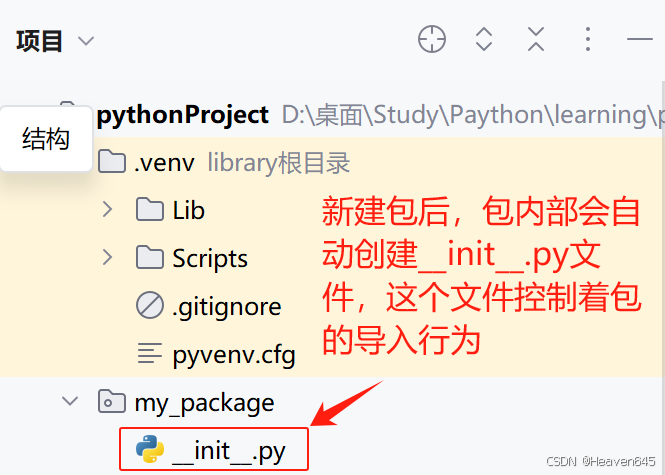
一个Python包实际上是一个包含多个模块的目录。包的目录下必须包含一个特殊的文件,通常是__init__.py,这个文件可以是空的,也可以包含初始化代码,用于标识该文件夹是Python的包,而非普通的文件夹。
3. 导入方式
通过点号.语法来导入特定的模块或子包。
方式一: import 包名
.模块名 包名.模块名.目标方式二: from 包名 import 模块名 模块名.目标方式三: from 包名.模块名 import 目标 目标方式四: from 包名.模块名 import * 模块名.目标
例如:
新建一个my_package包,并在包下定义两个模块my_module1.py和my_module1.py。
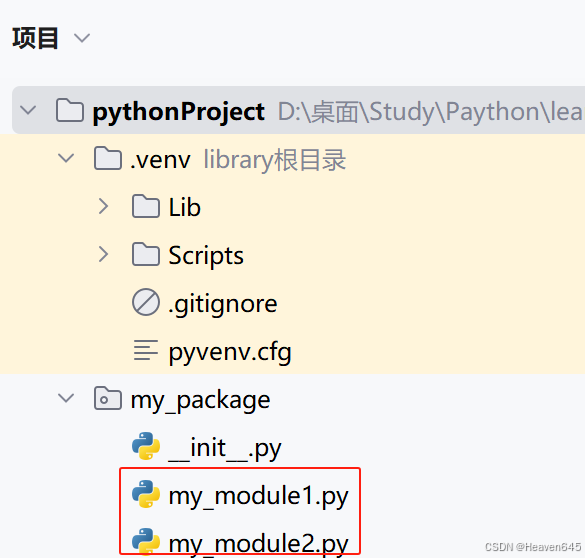
在模块my_module1.py输入如下代码:
def info_print1():
print("我是模块1的功能函数代码")在模块my_module2.py输入如下代码:
def info_print2():
print("我是模块2的功能函数代码")导入自定义的包中的模块并使用:
""" 方式一: import 包名.模块名 包名.模块名.目标 """ import my_package.my_module1 import my_package.my_module2
my_package.my_module1.info_print1()
my_package.my_module2.info_print2()
输出结果:
我是模块1的功能函数代码
我是模块2的功能函数代码
"""
方式二:
from 包名 import 模块名
模块名.目标
"""
from my_package import my_module1
from my_package import my_module2
my_module1.info_print1()
my_module2.info_print2()输出结果:
我是模块1的功能函数代码
我是模块2的功能函数代码
"""
方式三:
from 包名.模块名 import 目标
目标
"""
from my_package.my_module1 import info_print1
from my_package.my_module2 import info_print2
info_print1()
info_print2()输出结果:
我是模块1的功能函数代码
我是模块2的功能函数代码
"""
方式四:
from 包名.模块名 import *
模块名.目标
"""
from my_package import *
my_module1.info_print1()
my_module2.info_print2()输出结果:
我是模块1的功能函数代码
我是模块2的功能函数代码
4. all变量
通过在 init.py中定义 all变量,可控制 import * 能够导入的内容。
在模块 init.py中输入如下代码:
all=['my_module1']通过all变量控制import*
from my_package import *
my_module1.info_print1()
my_module2.info_print2() # my_module1没有被包含在 all 中,会报错输出结果:
我是模块1的功能函数代码
NameError: name 'my_module2' is not defined. Did you mean: 'my_module1'?
注意:
all变量针对的是from 包名.模块名 import *这种导入方式,对import xxx这种导入方式无效。
二、第三方包
1. 什么是第三方包?
通过前面的学习我们知道,包可以包含多个Python模块,而每个模块又内含多个的功能。因此,我们可以将一个包视为一组相关功能的集合。
在 Python 中,第三方包指的是由社区或个人开发并发布的,不是 Python 标准库的包。这些包可以为开发者提供各种额外的功能和特性,从而扩展 Python 的基本功能,如:
领域 | 常用包 |
|---|---|
科学计算 | NumPy |
数据分析 | Pandas |
大数据计算 | PySpark、Apache Flink |
图形可视化 | Matplotlib、Pyecharts |
人工智能 | TensorFlow |
这些第三方的包,极大的丰富了Python的生态,提高了开发效率。但是由于是第三方,所以Python没有内置,我们需要安装它们才可导入使用。
2. 安装第三方包
①pip安装
命令格式:
pip install 包名称
Win+R 打开运行对话框,在对话框中输入cmd并回车进入命令提示符。
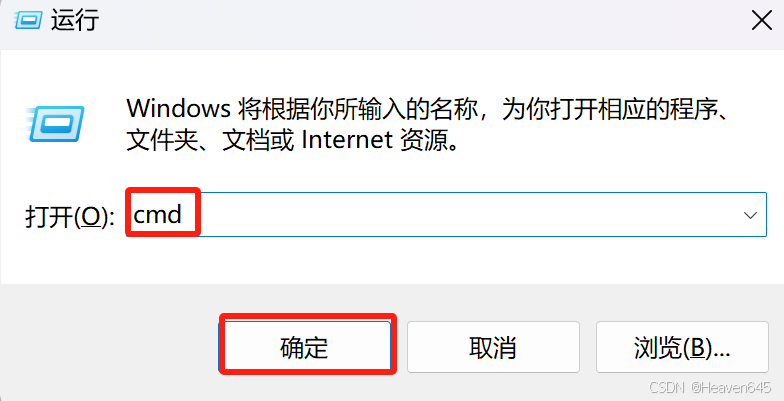
输入pip install 包名称即可通过网络快速安装第三方包。
例如,安装NumPy包:
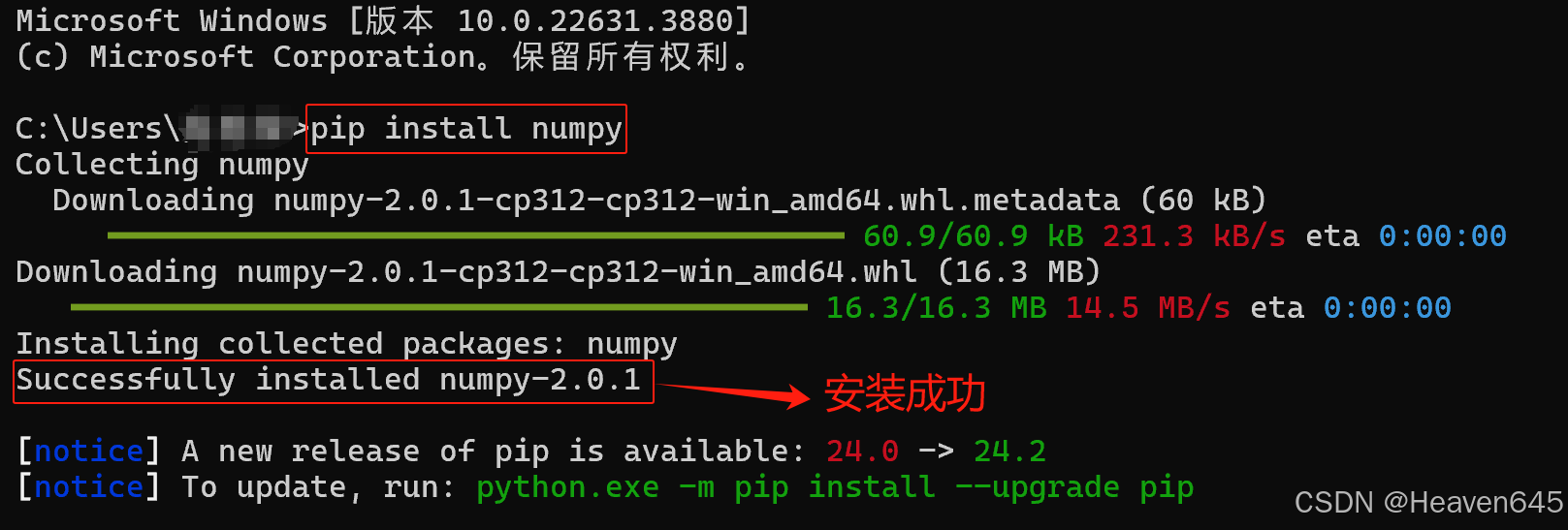
由于pip是连接的国外的网站进行包的下载,所以有时候下载速度很慢。
我们可以通过如下命令,让其连接国内的网站进行包的安装:
命令格式:
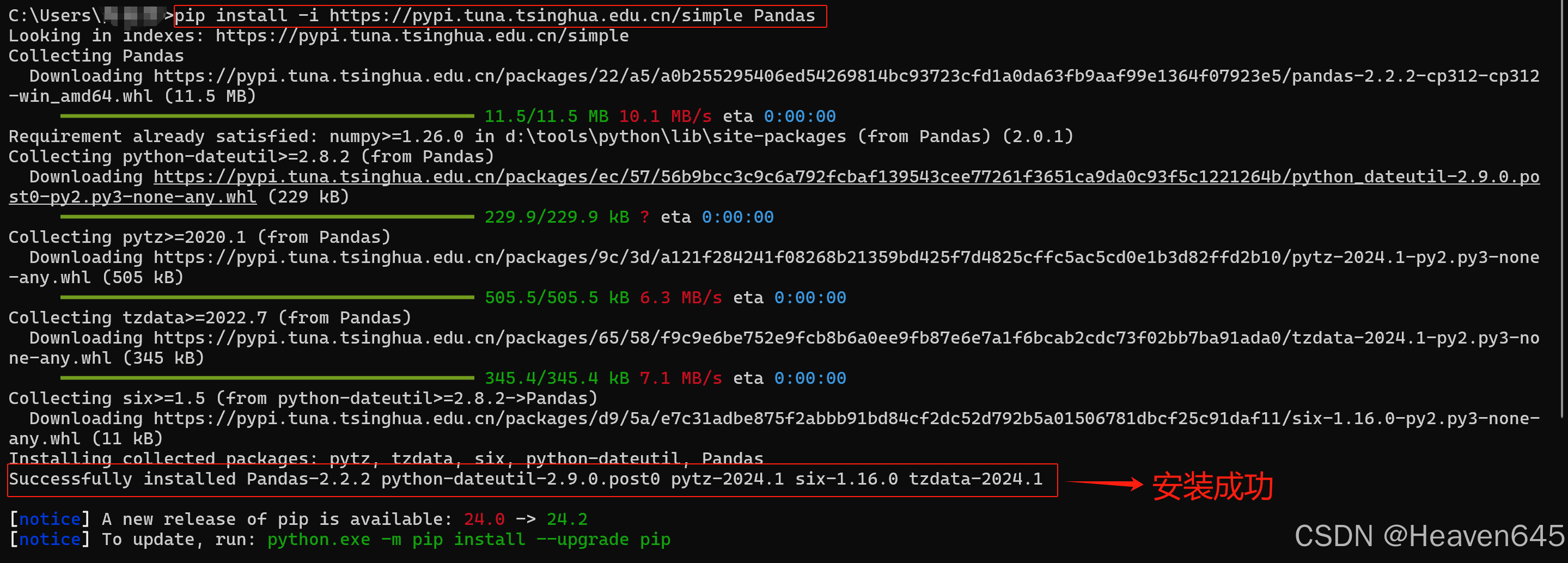
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 包名称
https://pypi.tuna.tsinghua.edu.cn/simple 是清华大学提供的一个网站,可供pip程序下载第三方包。
例如,安装Pandas包:
②Pycharm安装
PyCharm也提供了安装第三方包的功能。
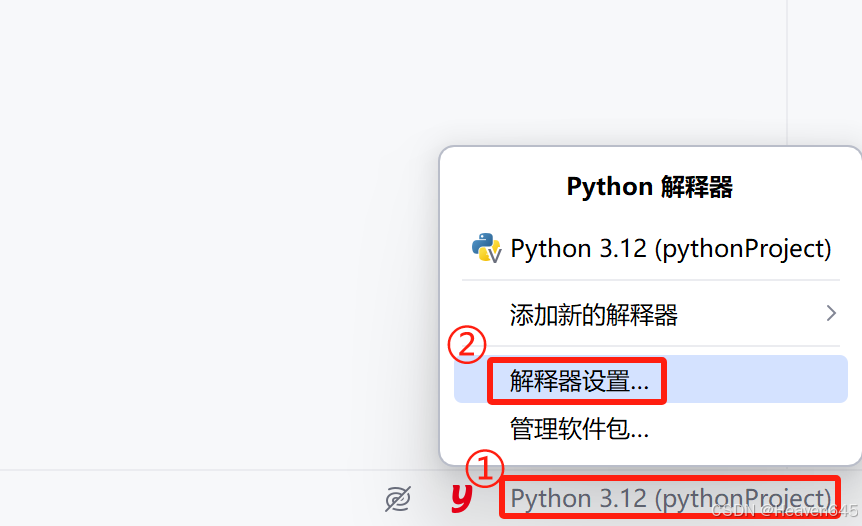
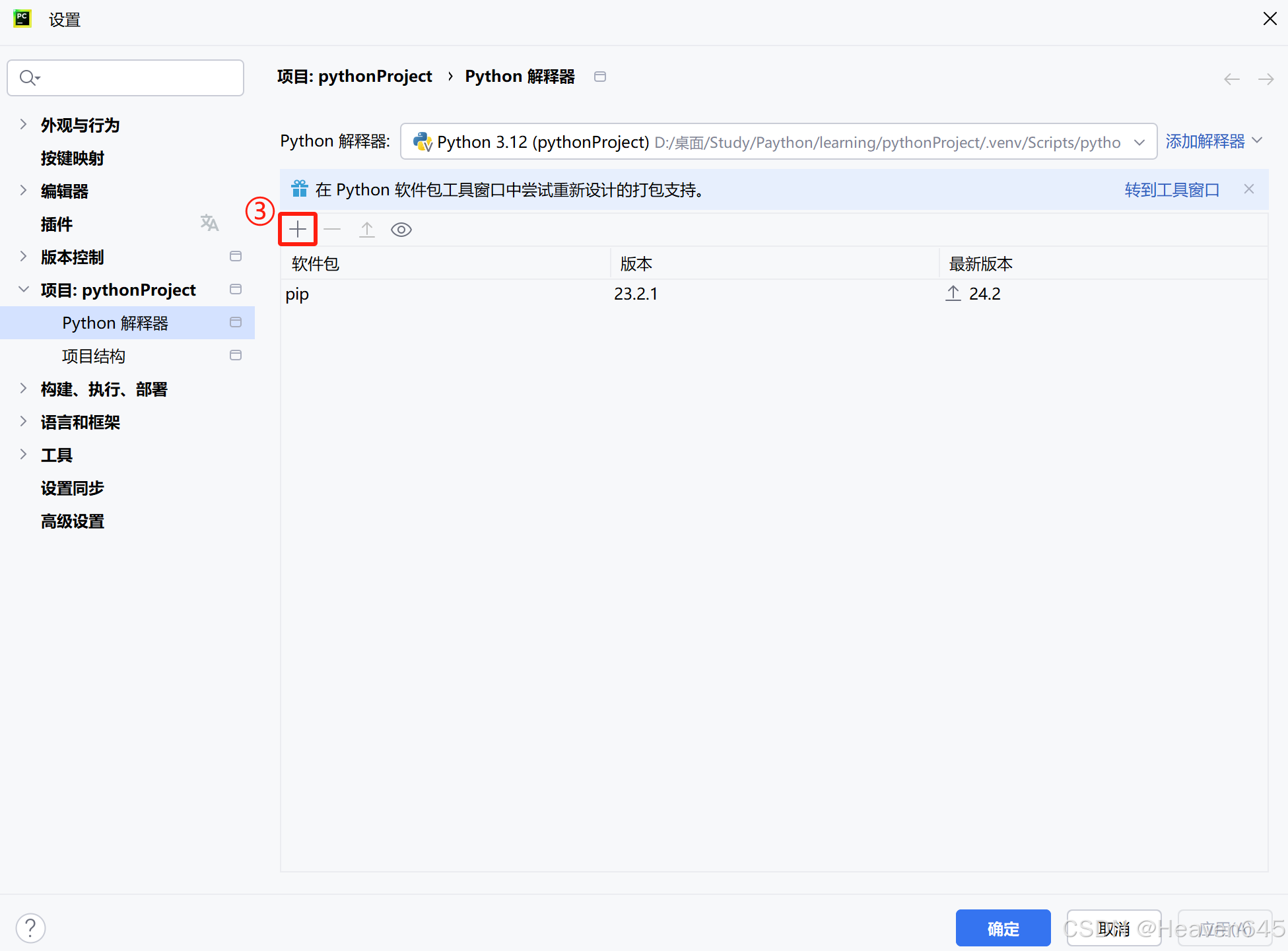
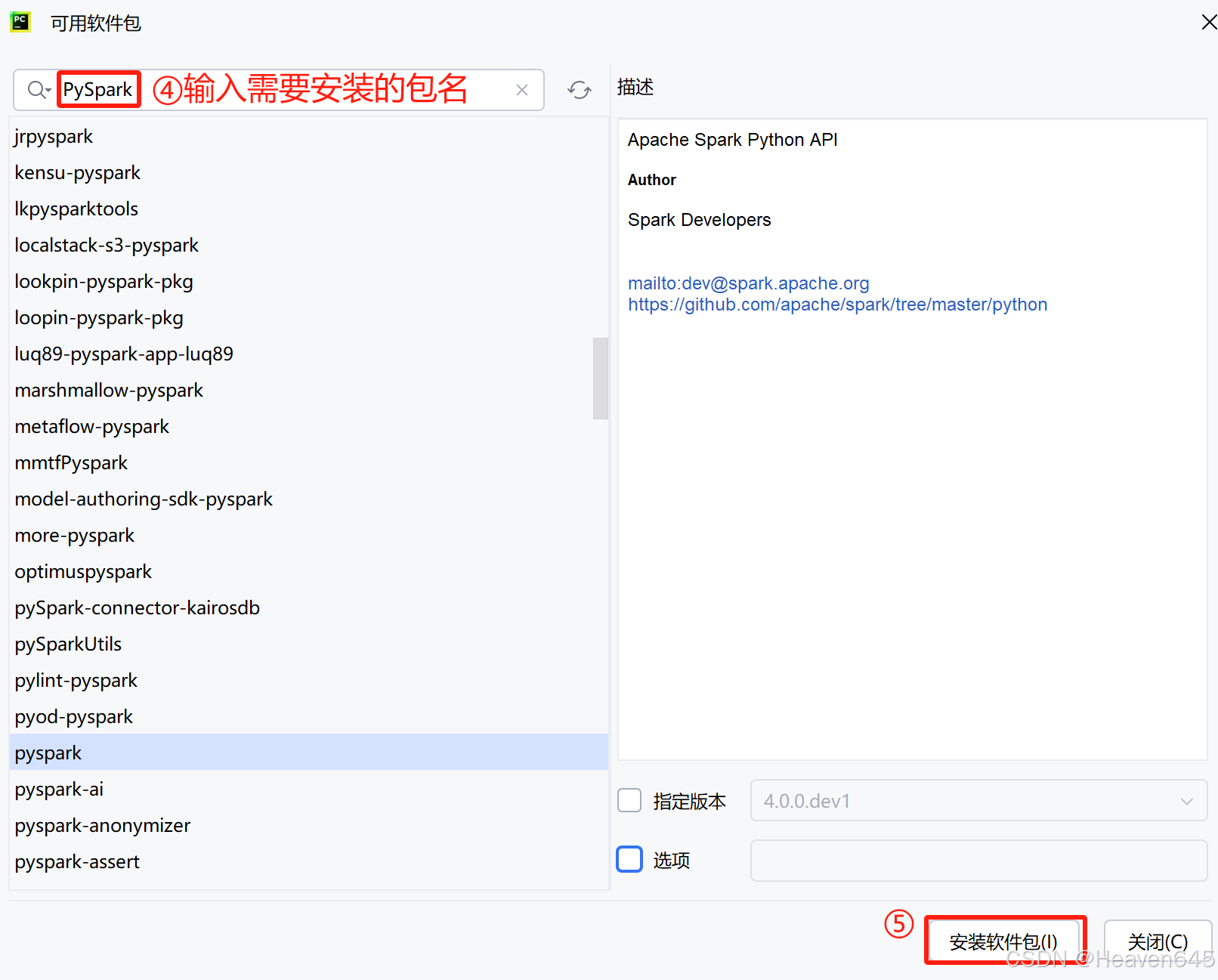
如果下载速度很慢,可其连接国内的网站(https://pypi.tuna.tsinghua.edu.cn/simple)进行包的安装。
【例题】

str_util.py:
# 字符串相关工具
def str_reverse(s):
"""
功能:将字符串反转
:param s:将被反转的字符串
:return:反转后的字符串
"""
return s[::-1]字符串相关工具
def substr(s,x,y):
"""
功能:按照给定下标完成给定字符串的切片
:param s:即将被切片的字符串
:param x:切片的开始下标
:param y:切片的结束下标
:return:切片完成后的字符串
"""
return s[x:y]测试功能
if name == 'main':
print(str_reverse("Hello"))
print(substr("Python",1,3))
输出结果:
olleH
yt
file_util.py:
# 文件处理相关工具
def print_file_info(file_name):
"""
功能:将给定路径的文件内容输出到控制台中
:param file_name:即将读取的文件路径
:return:None
"""
f1=None #设置初始值
try:
f1=open(file_name,"r",encoding="UTF-8")
content=f1.read()
print("文件全部内容如下:")
print(content)
except Exception as e:
print(f"程序出现异常,原因为{e}")
finally:
# 如果f1为None,执行f1.close()会引发AttributeError异常
# 因此设置判断 if f1: 确保在关闭文件之前,f1 确实指向一个非 None 的有效文件对象,避免潜在的错误。
if f1: # 如果变量为None,表示False,不会执行f1.close()
f1.close()def append_to_file(file_name, data):
"""
功能:将指定的数据追加到指定的文件中
:param file_name:指定的文件路径
:param data:指定的数据
:return:None
"""
f2=open(file_name,"a",encoding="UTF-8")
f2.write(data)
f2.write("\n")
f2.close()
if name == 'main':
print_file_info("D:/test.txt")
append_to_file("D:/test.txt", "Hello Python!!!")
append_to_file("D:/test.txt", "Hello World!!!")
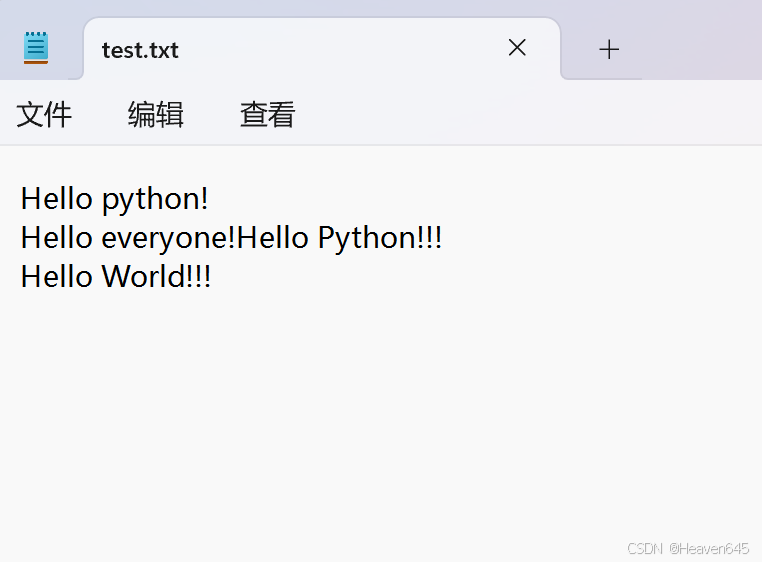
新建一个test.txt文本文件并输入如下内容:
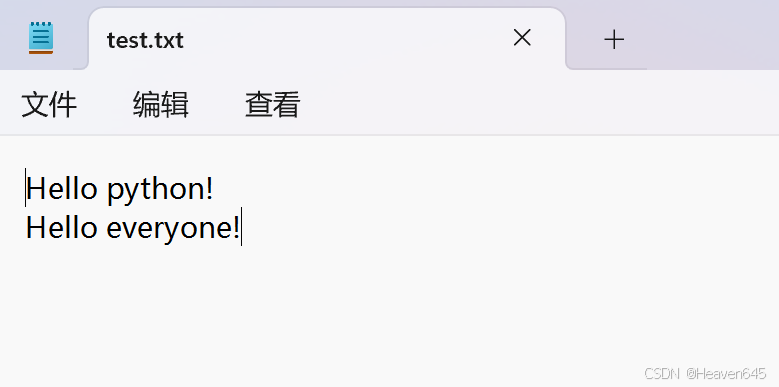
输出结果:
文件全部内容如下:
Hello python!
Hello everyone!