前言
欢迎各位小伙伴一起继续学习,我们上期和大家简单的介绍了一下JupyterLab的使用,从今天开始我们就要正式开始pandas的学习了。我们尽量不长篇大论,争取每篇文章介绍几个知识点,主要还是需要各位小伙伴一起动手实践一下。
为了和大家能使用同样的数据进行学习,建议大家可以从国家统计局的网站上进行下载。
网站:国家数据 (stats.gov.cn)
如何加载数据
当我们有了数据后,如何读取它里面的内容呢
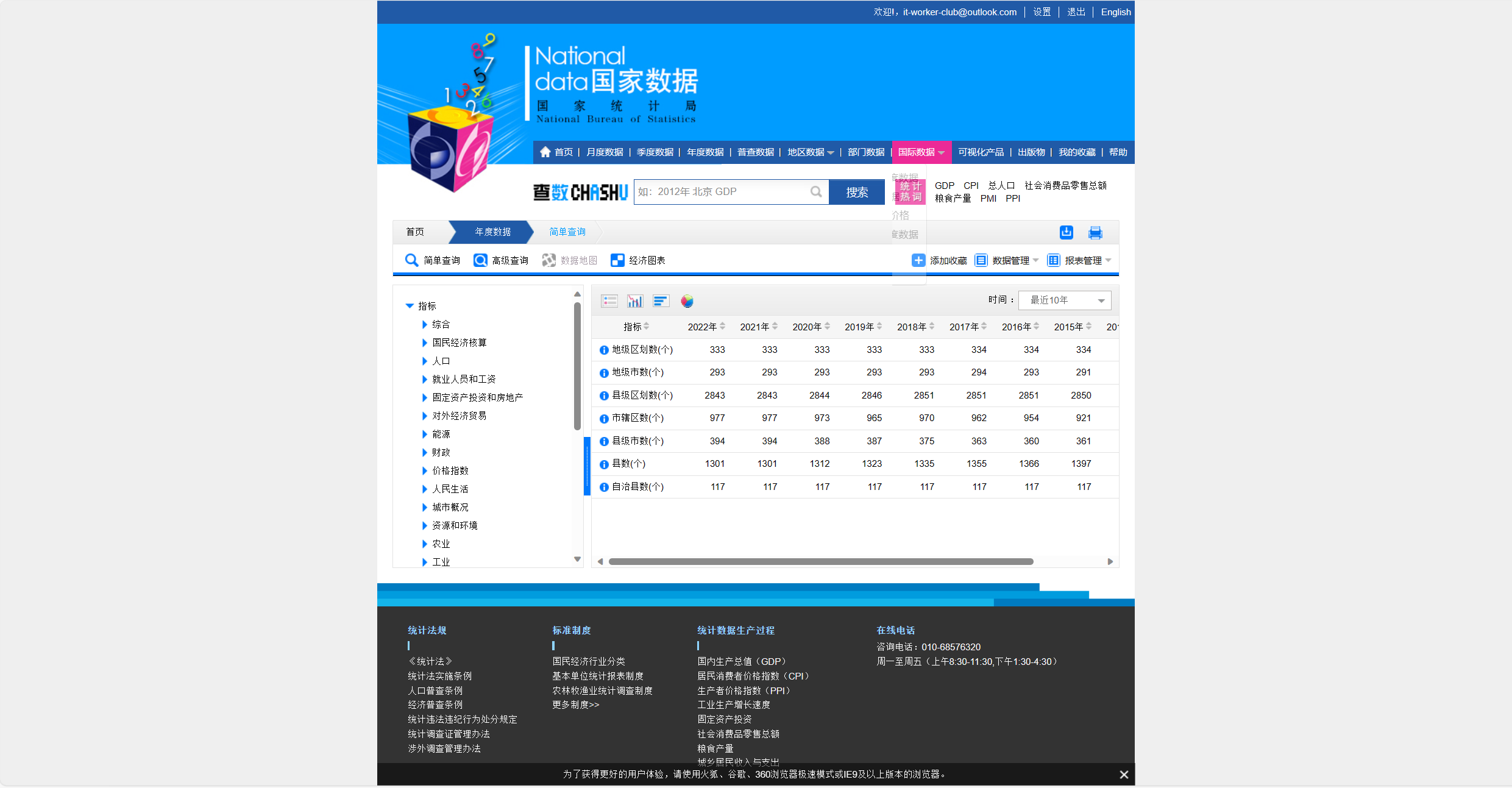
我们在根目录下创建一个data的文件夹,用来保存我们的数据,本次演示使用的数据集是行政区划
我们可以点击右上角的下载图标进行下载
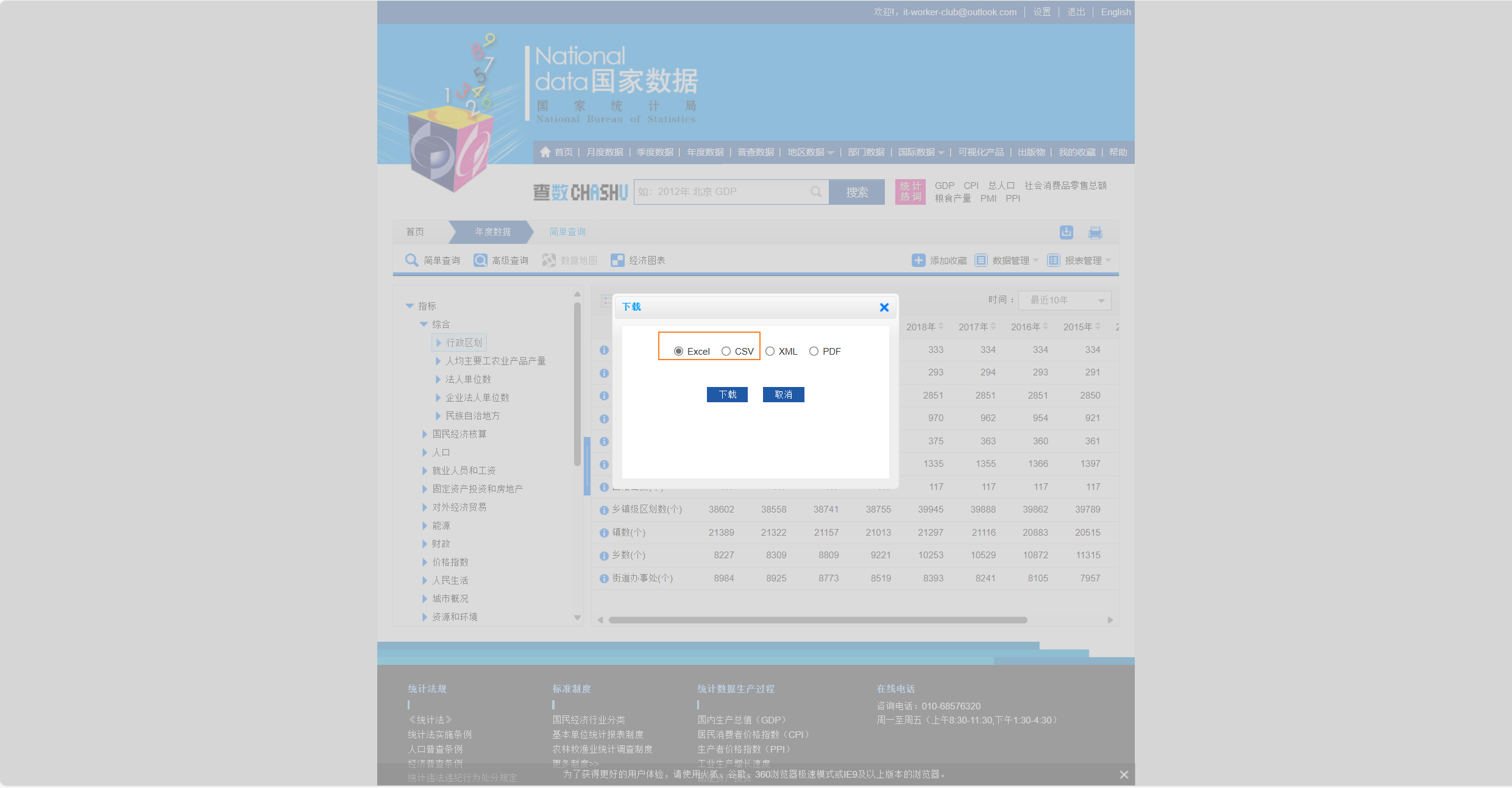
为了演示,我们下载Excel和CSV这两种格式的数据,并保存在data目录下。
我们可以将自己下载好的文件直接拖拽过来即可。
我们新建一个day01的目录用来保存我们的notebook
选择默认的即可
我们为了能使用pandas,我们需要通过pip 进行安装,在notebook中安装,还是比较方便的,只需输入以下内容
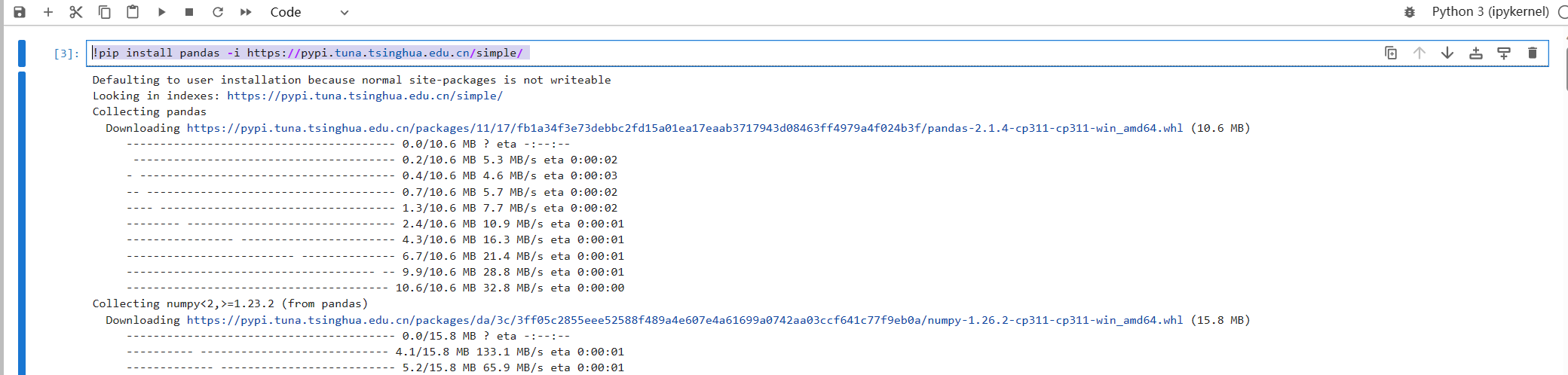
!pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple/ 这里和我们平时安装基本一样,唯一的却别就是在命令行前面多了一个感叹号
后面我们执行其他命令时,这个感叹号都是必须的。
导入pandas
import pandas as pd
运行结束后,单元格的前面会出现一个编号,你的和我的不一样也没关系。
加载数据
df = pd.read_csv("../data/年度数据.csv", encoding="utf-8", sep="\t")这里我们读取的是CSV文件,路径使用的是相对路径,由于这个csv并不是用逗号分隔的,而是用tab(制表符)分隔的,因此我们使用sep="\t"这个参数。

数据加载好后,我们再看看具体都写了些什么,产看很简单,只需要在单元格中输入我们之前定义好的变量df然后shift+回车即可。
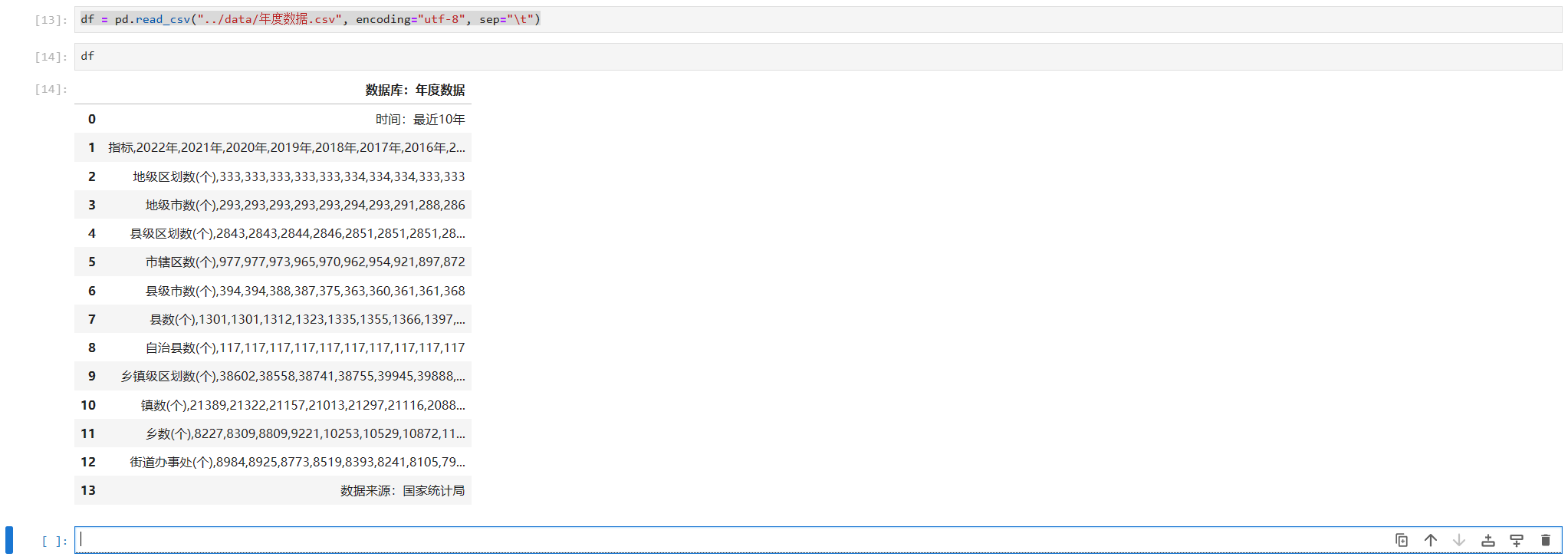
我们可以看到数据被很好的展示出来了。
我再试试读取excel格式的那个数据
df2 = pd.read_excel("../data/年度数据.xls")但是当你运行时,会发现报错,主要是因为,我们读取的excel格式比较老了,需要安装另一个库对他进行解析
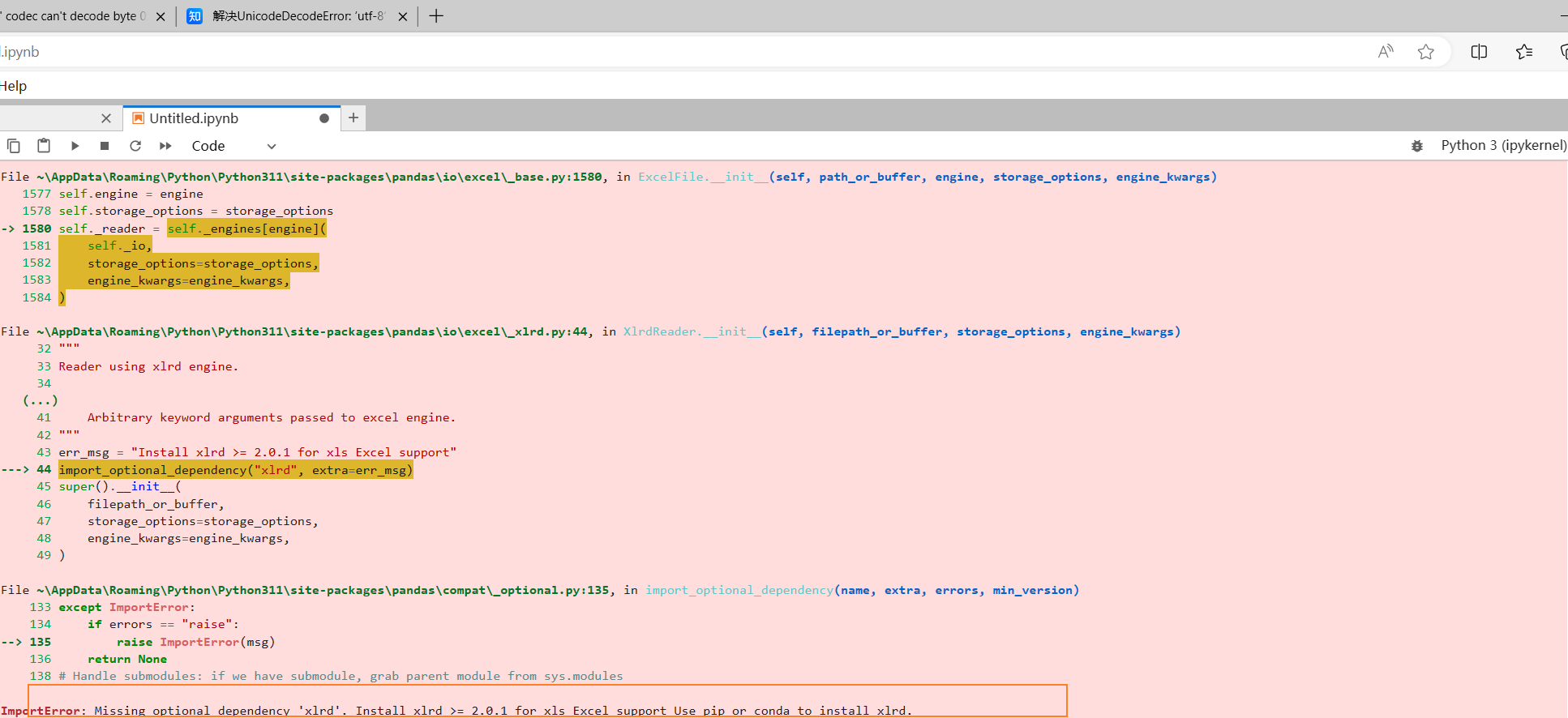
!pip install xlrd -i https://pypi.tuna.tsinghua.edu.cn/simple/ 
再次运行看看效果
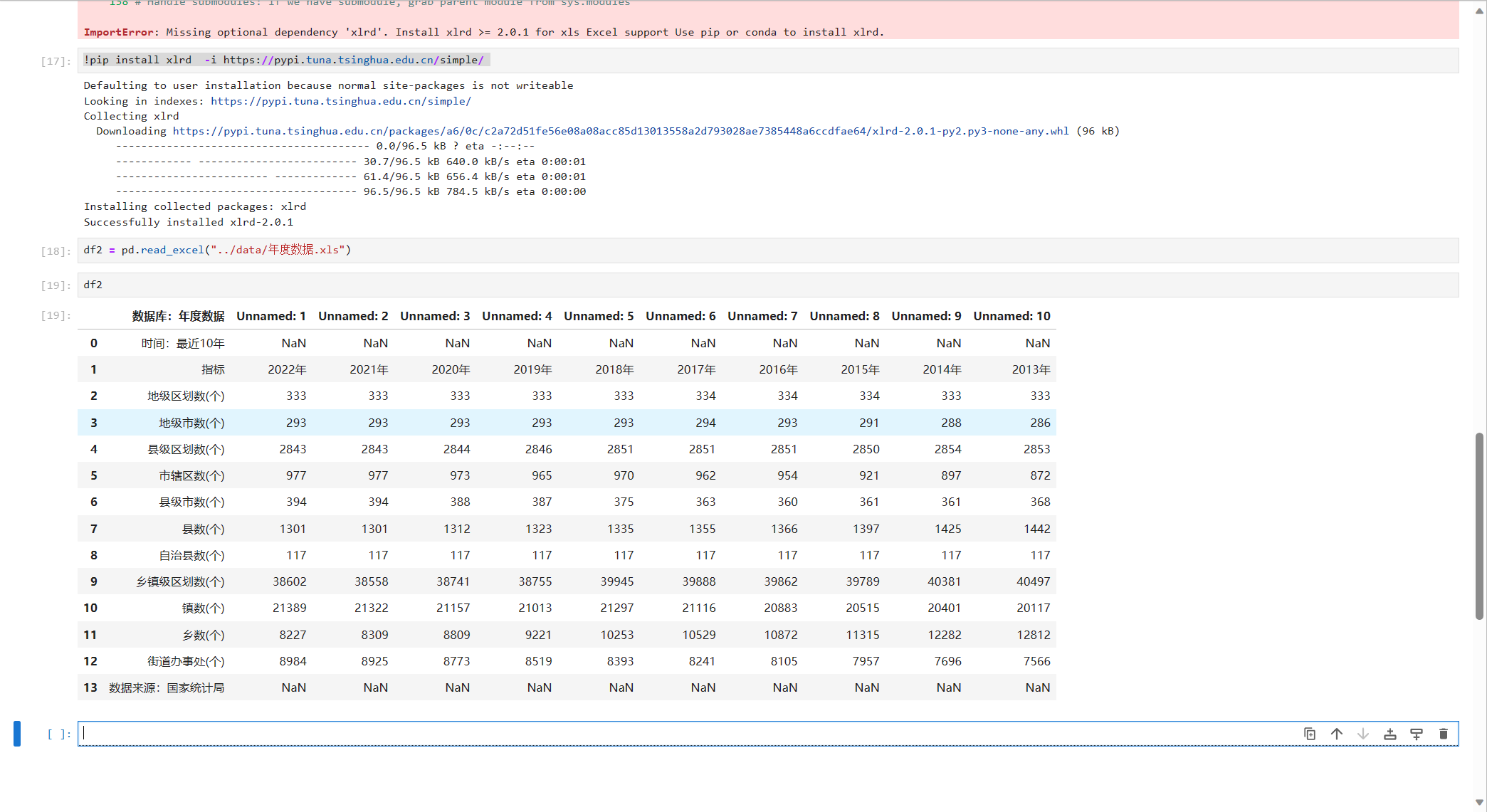
很好,数据也被正常的显示出来了。
结尾
好了今天的内容就是这些,我们介绍了如何安装pandas这个库,以及如何读取csv和xls文件。
赶快动手实践一下吧,我是Tango,一个热爱分享技术的程序猿,我们下期见。
我正在参与2023腾讯技术创作特训营第四期有奖征文,快来和我瓜分大奖!