一、大模型技术方向 - 大模型训练 / 大模型应用
大模型技术 分为两个方向 :
- 训练大模型 : 少数实力强的公司做这件事 , 如 OpenAI 训练 ChatGPT 大模型 , 百度训练 文心一言 大模型 , 这种技术岗位很少全世界也就几千个 , 技术难度很高 ;
- 大模型应用 : 使用 别人训练好的大模型 , 建立自己的应用 ;
- 开发在各个平台上使用的 AI 应用 , 如 : 将 GPT 大模型集成到自己的应用中 ; 如 : Android 应用 , Python 应用 中 ;
- 几乎所有的开发者都要学会 大模型应用 开发 , 其本质就是调用第三方库 ;
- 在上一篇博客 【AI 大模型】OpenAI 接口调用 ① ( 安装 openai 软件包 | 查看 openai 软件包版本 | PyCharm 中开发 Python 程序调用 OpenAI 接口 ) 中 , 就是开发了一个应用 , 集成了 OpenAI 的软件包 , 可以调用 OpenAI 接口使用大模型的功能 ;
二、大模型应用 - 业务架构
1、AI Embedded 模式
应用程序 是 传统应用 , 大模型被嵌入到现有的应用程序或服务中 , 作为一个组成部分 , 仅在其中的某个环节 , 使用了 AI 大模型技术 ;
AI Embedded 模式下 , 大模型通常被用来 提升 现有应用的智能化程度 , 以改善 用户体验 或 增加功能 ;
下图中 , 仅在蓝色部分 , 使用了 AI 功能 , 其它应用都是普通功能 ;
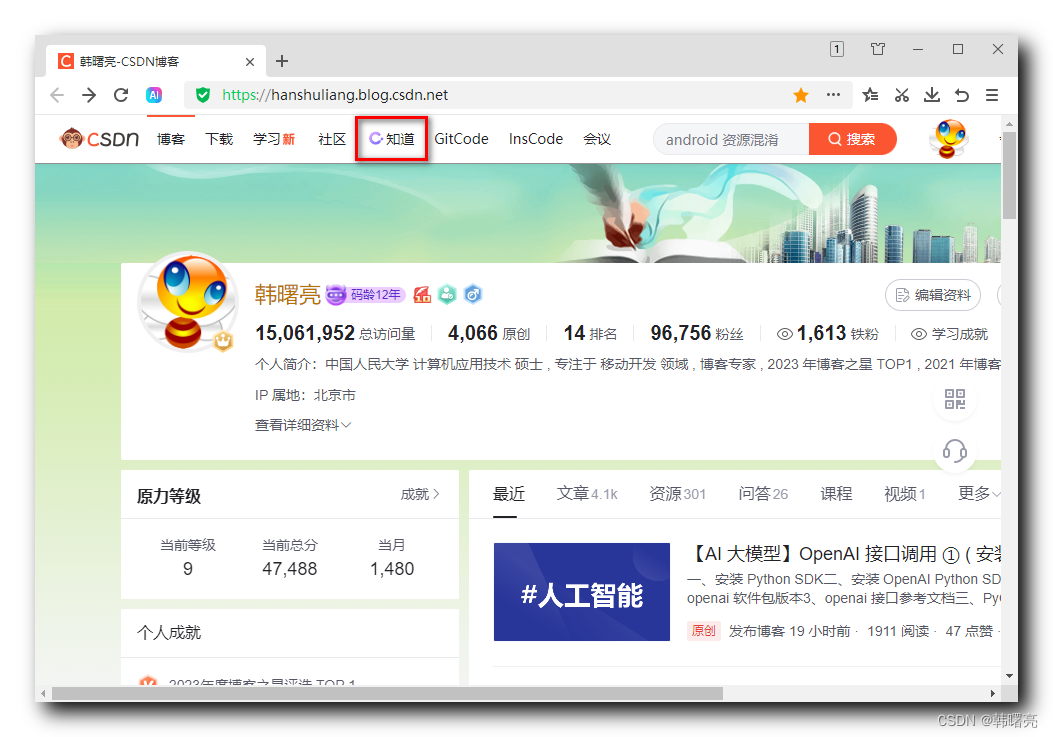
以 CSDN 博客网站为例 , 该网站是一个传统的 Web 网站应用 , 在顶部导航栏有一个 " C 知道 " 链接按钮 ,
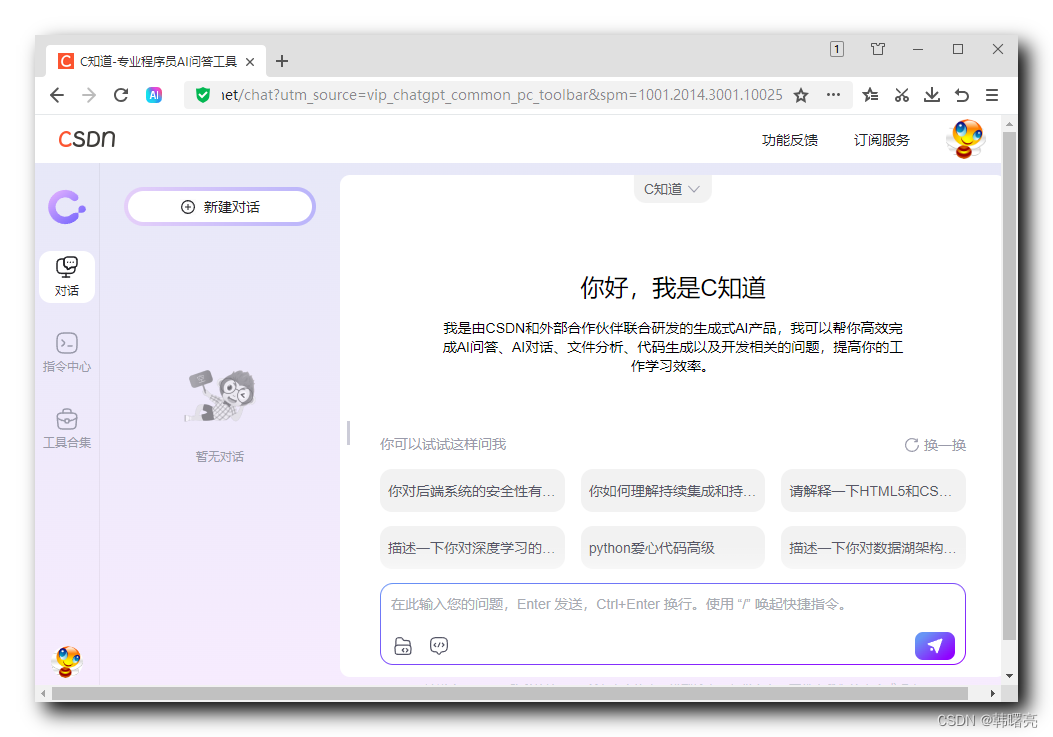
点击 " C 知道 " 按钮 , 跳转到 GPT 大模型对话界面 , 这种应用就是 在传统应用中 , 嵌入了 GPT 大模型应用 , 仅仅是在某个环节中使用了大模型 ;
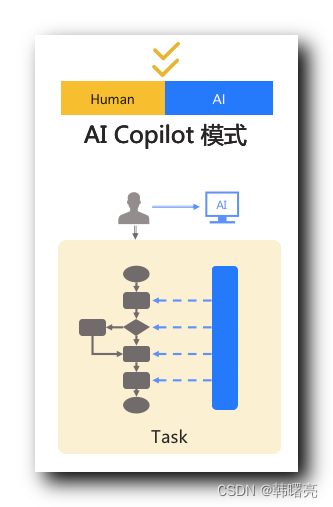
2、AI Copilot 模式
在业务中相当于 副驾驶 / 助理 ,
AI 大模型是用户的 合作伙伴 , 协助用户完成某件任务 ,
具有高度的智能化水平 , 如 : 自主性 和 决策能力 ,
可以根据 环境和任务情境 主动作出 决策和行动 ;
微软 Copilot 就是一个典型的 AI Copilot应用 , 其集成在 WIndows 11 系统中 , 作为侧边栏工具 ;
- 微软 Copilot 地址 : https://copilot.microsoft.com/
微软 Copilot 能够
- 理解用户的语言
- 执行用户的指令
- 预测用户的需求
从而在多个业务场景中 为用户提供 智能辅助 ;
3、AI Agent 模式
AI Agent 模式 中 , AI 大模型 被设计为一种独立的代理系统 , 能够代表用户 执行任务 或 处理事务 , 具有高度自治能力 ;
AI Agent 模式 中 , AI 的操作占比远高于用户操作 ;
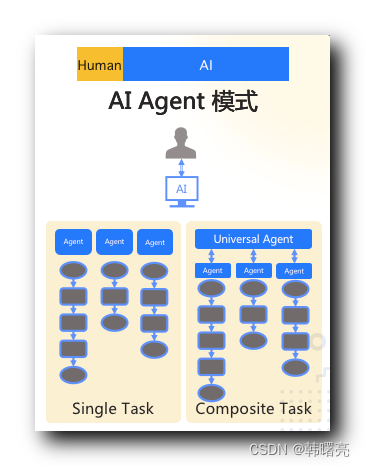
AI Agent 模式 目前没有案例应用 , 架构比较超前 ;
军事领域大有作为 , 可能已经研发成功并使用了 , 如 : 无人机集群 自动扫描 , 自动发现 , 自动跟随 , 自动瞄准 , 自动投弹 ;
三、大模型应用 - 技术架构
1、提示词 技术架构
传统的 ChatGPT 和 文心一言 的用法 ,
用户发一句 " 提示词 Prompt " , 大模型 回一句 " 输出结果 " ;
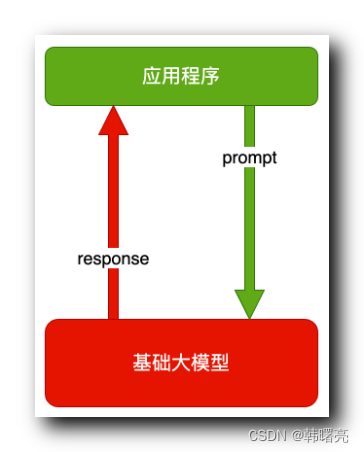
这是在 AI 大模型的基础上 , 套了一层对话应用的壳 ;
其本质是调用 GPT 大模型的解码器 , 输入参数是 " 提示词 Prompt " , 得到的结果是 解码器 针对提示词 以及综合 训练的大模型向量数据 根据概率生成的 " 输出结果 " ;
示例说明 : ChatGPT 一问一答 , 在 GPT 大模型上套了一层聊天的壳 ;
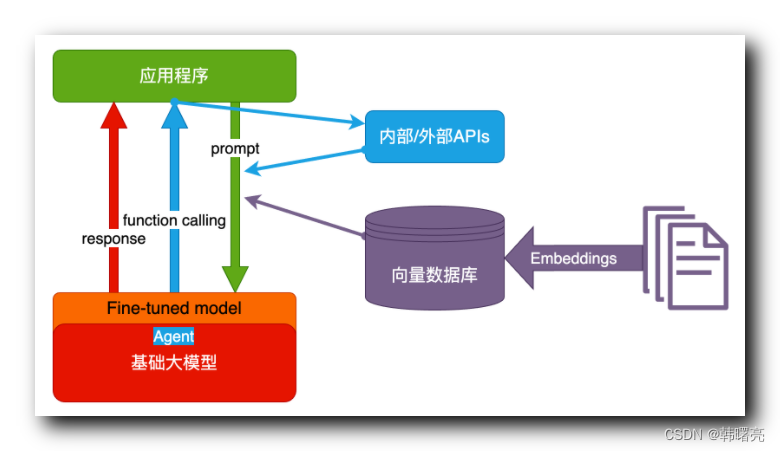
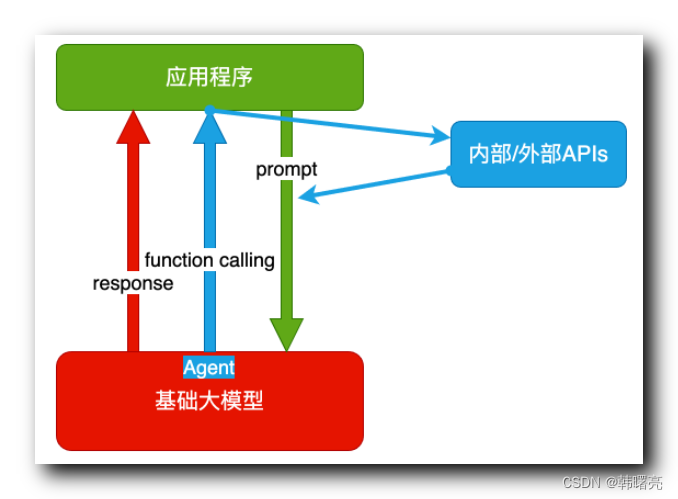
2、Agent + Function Calling 技术架构
Agent + Function Calling 技术架构 的 主体是一个应用程序 , 就不再是春对话方式了 , 应用程序还必须提供对应的 函数 API , 以供 AI 大模型 回调该 API 功能 ;
Agent 表示 AI 主动提出的要求 , Agent 代理程序具有一定的 自主性 和 决策能力 ;
Function Calling 表示 AI 根据提出的要求 , 自动执行的函数 , 这个 函数 API 功能 ,
- 可以是 应用程序提供的 ;
- 也可以是 AI 大模型内置的 ;
该技术架构的工作流程如下 :
- 首先 , 用户的 应用程序 中 输入 " 提示词 " ;
- 然后 , 进行函数调用 , AI 大模型分析 提示词 , 发现需要调用 " 应用程序 " 的 API , 这是 大模型 " 回调 " 应用 / 大模型 的功能 ;
- 调用 API 功能完毕后 , 继续看是否满足 " 提示词 " 的要求 , 不满足的话继续进行 函数调用 , 直到满足为止继续执行下一步 ;
- 最后 , 输出符合 " 提示词 " 要求的 文本结果 ;
Agent + Function Calling 技术架构 使用非常广泛 , 可以 将自己开发的应用功能嵌入到 AI 大模型中 , 将复杂的 逻辑 分解成 更小的 / 可管理的 部分 , 每个部分通过调用 不同的函数 实现 ;
3、RAG 技术架构
" RAG = Embeddings + Vector Database " 技术架构 ;
RAG 全称 Retrieval-Augmented Generation , 检索增强生成 , 是 结合 " Embeddings 嵌入 " 和 " Vector Database 向量数据库 " 的 技术架构 , 该架构用于 自然语言处理领域 的 信息检索 和 生成任务 ;
Embeddings 嵌入 是 把文字转为 容易计算的 编码向量 ;
Embeddings 嵌入 的 具体操作就是 将 词语或文本 映射到 高维向量空间 的技术 , 高维向量空间 被设计成能够 捕捉 词语或文本 之间的语义关系 , 语言处理模型 能够更好地 理解和处理 自然语言的含义 ;
向量数据库 Vector Database 是一种 专门用于 存储和检索 向量数据 的 数据库系统 , 可以通过 特定的 数据结构和算法 加速 向量之间的 比较和匹配过程 ;
具体的 RAG 技术架构 的执行流程 :
- 首先 , 用户输入 " 提示词 " 后 ,
- 然后 , AI 大模型 拿到 " 提示词 " 之后 , 先到 " 向量数据库 " 中 , 检索所有可能与该 " 提示词 " 相关的知识 ,
- 最后 , 将
- " 提示词 "
- 根据 " 提示词 " 从 向量数据库 中 检索出来的知识
一起 传递给 AI 大模型 , 相当于将 " 检索出来的知识 " 追加到了提示词中 , 后面 的 AI 大模型 执行 就相当于 Agent + Function Calling 技术架构 的执行过程 ;

4、Fine-tuning 微调 技术架构
Fine-tuning 技术架构 , 是在一个已有的 AI 大模型基础上 , 进行微调操作 ;
- 首先 , 要 预训练模型 , 初期要有一个已经 训练好的 GPT 大模型 ;
- 然后 , 将 预训练模型 应用到特定的任务上 , 每个任务要有
- 输入数据格式
- 输出要求
- 评估指标
- 最后 , 验证数据集评估模型性能 , 如果对结果不满意 , 持续进行 超参数调整 和 Fine-tuning 策略的优化 , 直到得到满意结果为止 ;
该技术架构是 AI 大模型最全面的技术架构 ;