- Colab是google最近推出的一项Python在线编程的免费服务, 有了它,不学Python编程的理由又少了一个
- Colab环境已经集成了流行的深度学习框架Tensorflow,并附赠了一个虚拟机(
40GB硬盘+2*2.30GHZCPU+12.72GB内存),如果在国内无法访问google的服务又不想访问外国网站, 可以考虑微软推出的 notebook - Colab的操作类似于jupyter notebook
- Colab如同使用 Google 文档或表格一样存储在 Google云端硬盘中,并且可以共享
1. Colab 执行终端命令
google为我们提供的Colab服务绑定一个Ubuntu虚拟机(40GB硬盘+2*2.30GHZ CPU+12.72GB内存), 我们只要在Colab中输入以
!开头的终端命令即可
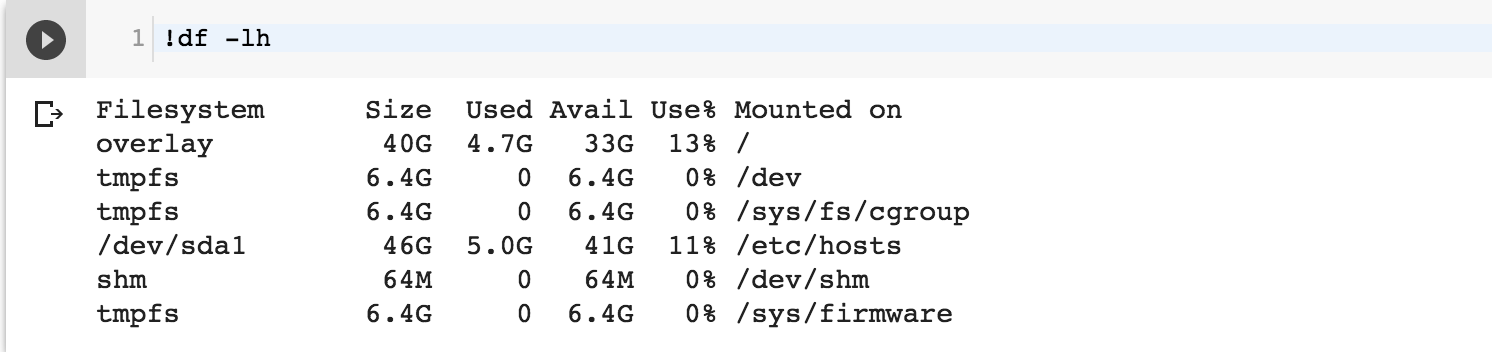
- 查看虚拟机硬盘容量
!df -lh
- 查看cpu配置
!cat /proc/cpuinfo | grep model\ name

查看内存容量!cat /proc/meminfo | grep MemTotal

- 安装python依赖包
代码语言:javascript
复制
# 安装requests, 爬虫必备
!pip install requests
# 安装 lxml, 解析xpath语法
!pip install lxml- 安装 git
代码语言:javascript
复制
# 将获取的数据同步到github仓库
!apt install git2. 用Colab编写在线爬虫,并在线展示成果
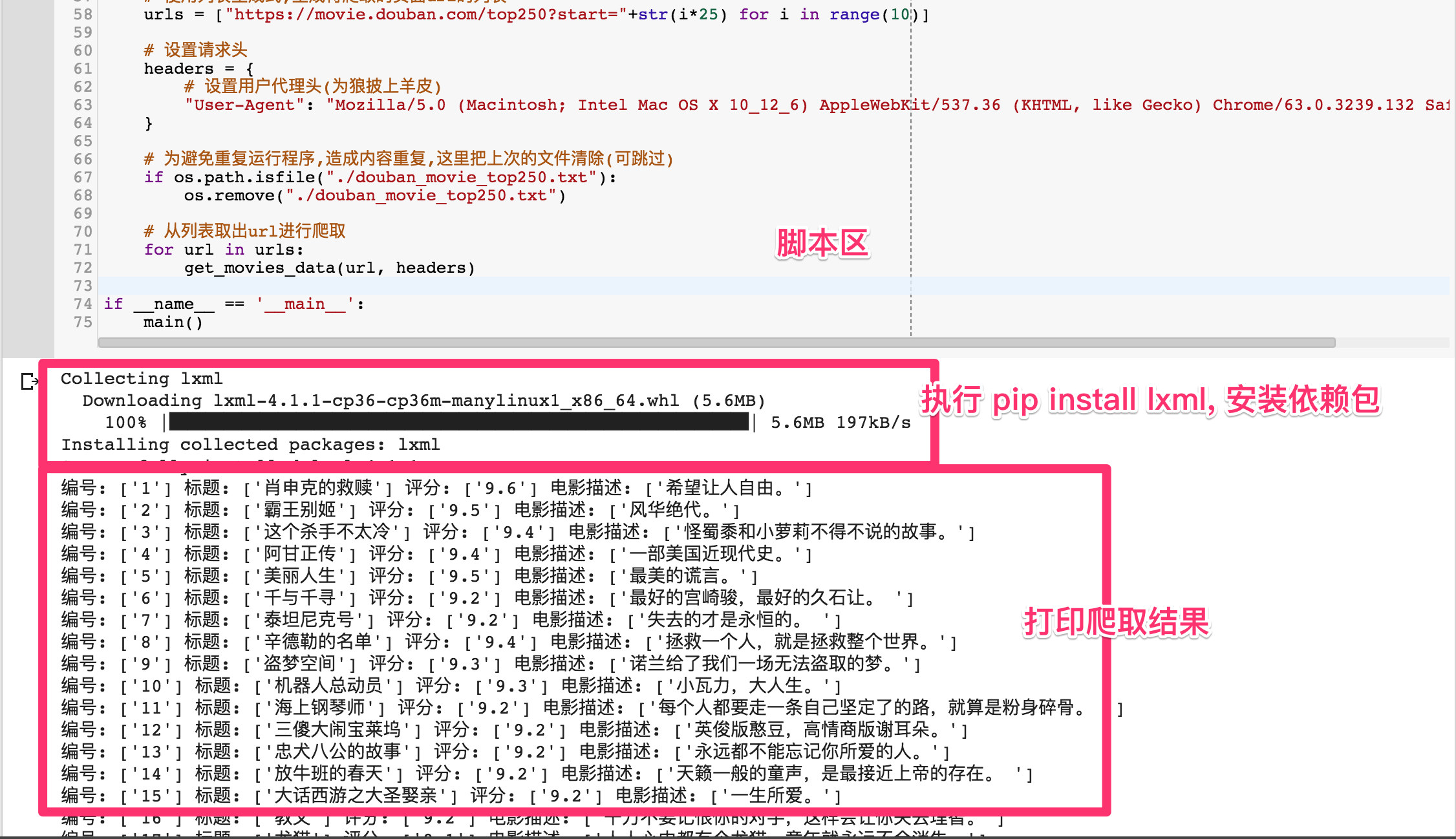
代码语言:javascript
复制
!pip install lxml import os import requests from lxml import etree负责下载电影海报
def download_img(db_id, title, img_addr, headers):
# 如果不存在图片文件夹,则自动创建 if os.path.exists("./Top250_movie_images/"): pass else: os.makedirs("./Top250_movie_images/") # 获取图片二进制数据 image_data = requests.get(img_addr, headers=headers).content # 设置海报存存储的路径和名称 image_path = "./Top250_movie_images/" + db_id[0] + "_" + title[0] + '.jpg' # 存储海报图片 with open(image_path, "wb+") as f: f.write(image_data)根据url获取数据,并打印到屏幕上,并保存为文件
def get_movies_data(url, headers):
# 获取页面的响应内容 db_response = requests.get(url, headers=headers) # 将获得的源码转换为etree db_reponse_etree = etree.HTML(db_response.content) # 提取所有电影数据 db_movie_items = db_reponse_etree.xpath('//*[@id="content"]/div/div[1]/ol/li/div[@class="item"]') # 遍历电影数据列表, for db_movie_item in db_movie_items: # 这里用到了xpath的知识 db_id = db_movie_item.xpath('div[@class="pic"]/em/text()') db_title = db_movie_item.xpath('div[@class="info"]/div[@class="hd"]/a/span[1]/text()') db_score = db_movie_item.xpath('div[@class="info"]/div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()') db_desc = db_movie_item.xpath('div[@class="info"]/div[@class="bd"]/p[@class="quote"]/span[@class="inq"]/text()') db_img_addr = db_movie_item.xpath('div[@class="pic"]/a/img/@src') print("编号:",db_id,"标题:",db_title, "评分:",db_score,"电影描述:", db_desc) # a表示追加模式, b表示以二进制方式写入, + 表示如果文件不存在则自动创建 with open("./douban_movie_top250.txt", "ab+") as f: tmp_data = "编号:"+str(db_id)+"标题:"+str(db_title)+"评分:"+str(db_score)+"电影描述:"+ str(db_desc)+"\n" f.write(tmp_data.encode("utf-8")) db_img_addr = str(db_img_addr[0].replace("\'", "")) download_img(db_id, db_title, db_img_addr, headers)def main():
# 使用列表生成式,生成待爬取的页面url的列表
urls = ["https://movie.douban.com/top250?start="+str(i*25) for i in range(10)]# 设置请求头 headers = { # 设置用户代理头(为狼披上羊皮) "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36", } # 为避免重复运行程序,造成内容重复,这里把上次的文件清除(可跳过) if os.path.isfile("./douban_movie_top250.txt"): os.remove("./douban_movie_top250.txt") # 从列表取出url进行爬取 for url in urls: get_movies_data(url, headers)
if name == 'main':
main()
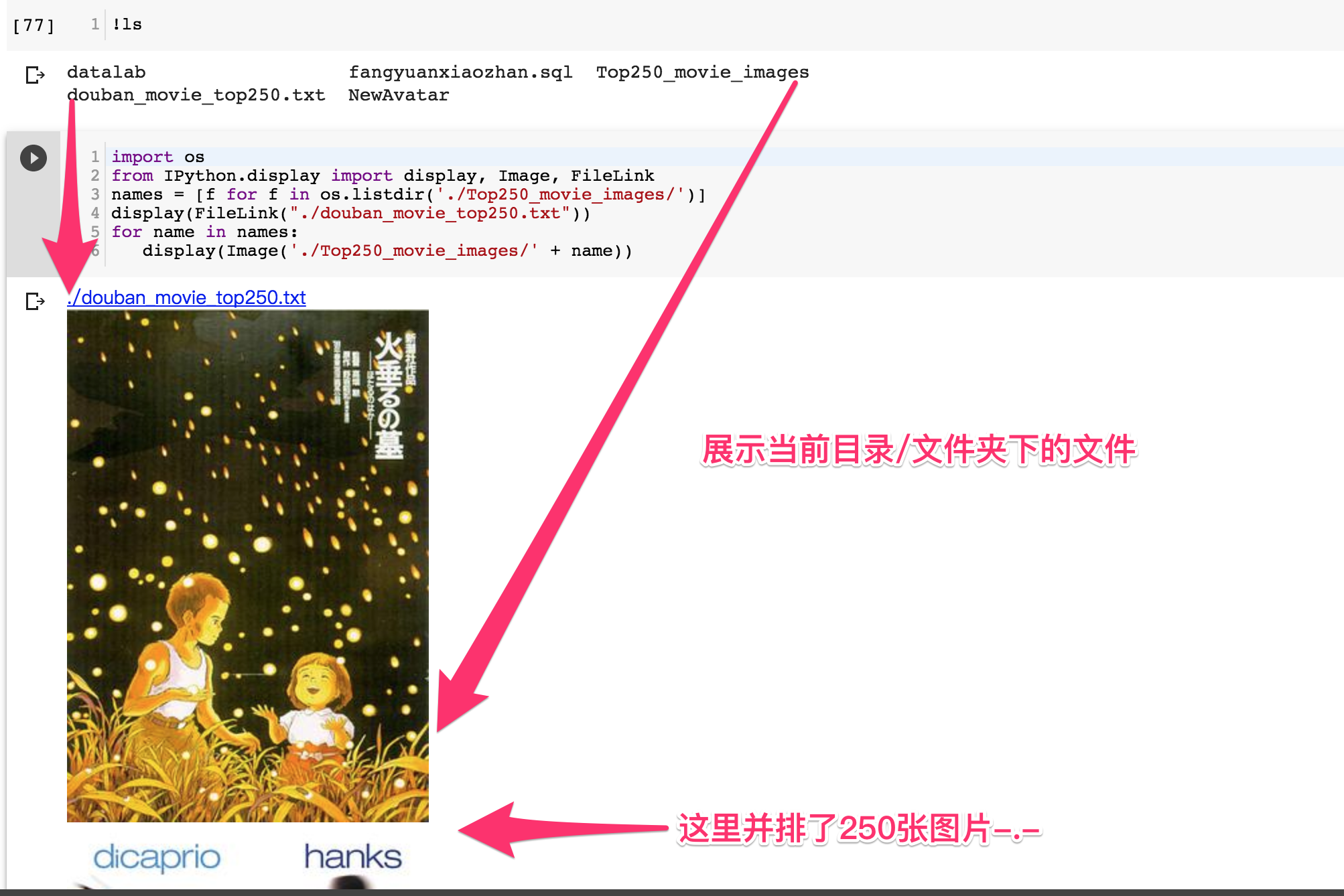
代码语言:javascript
复制
import os
from IPython.display import display, Image, FileLink
names = [f for f in os.listdir('./Top250_movie_images/')]
display(FileLink("./douban_movie_top250.txt"))
for name in names:
display(Image('./Top250_movie_images/' + name))3.在线机器学习,决策树案例 - 泰坦尼克乘客存活状况
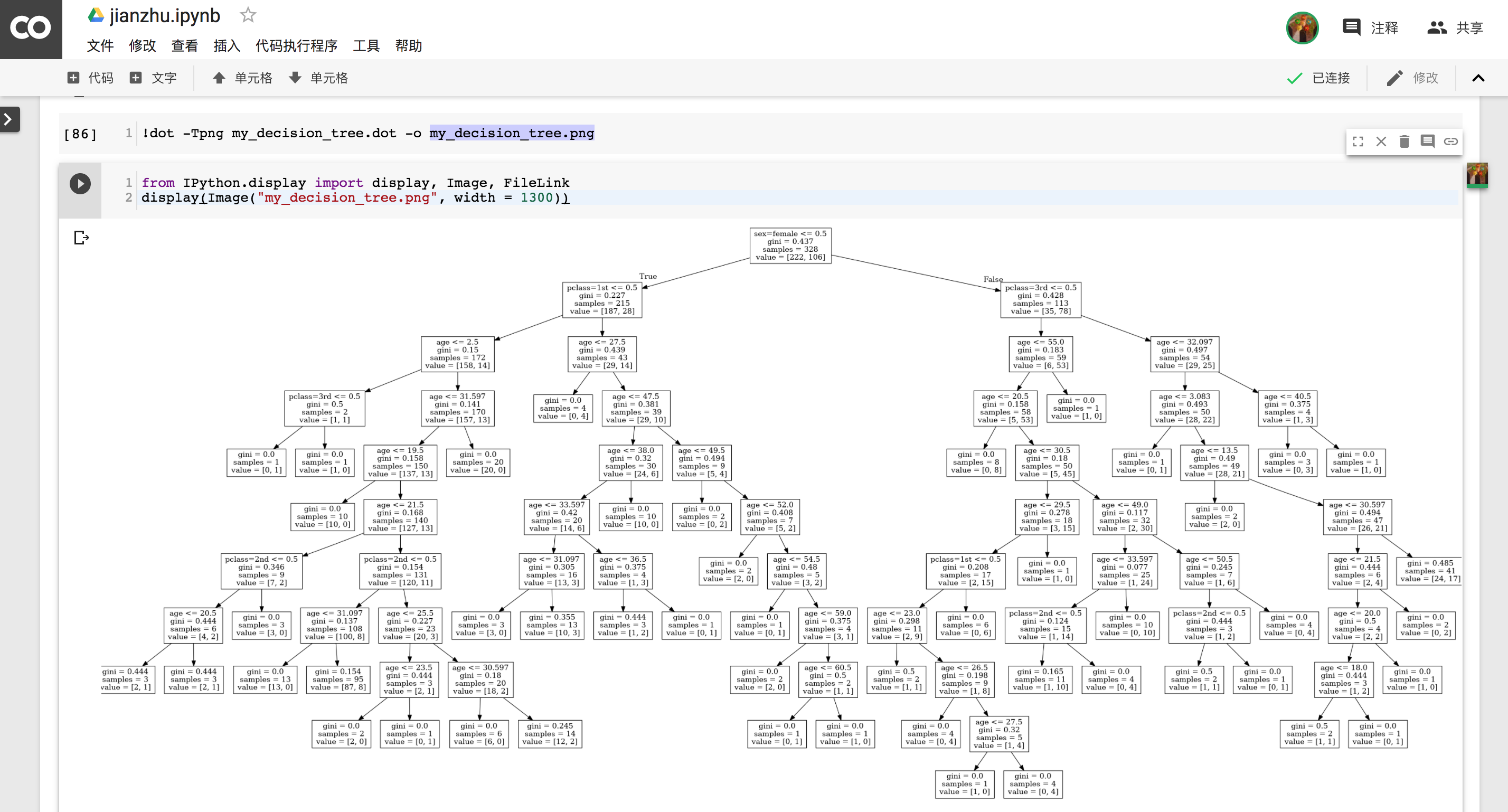
4. 在线学习Python编程
推荐一: 菜鸟教程
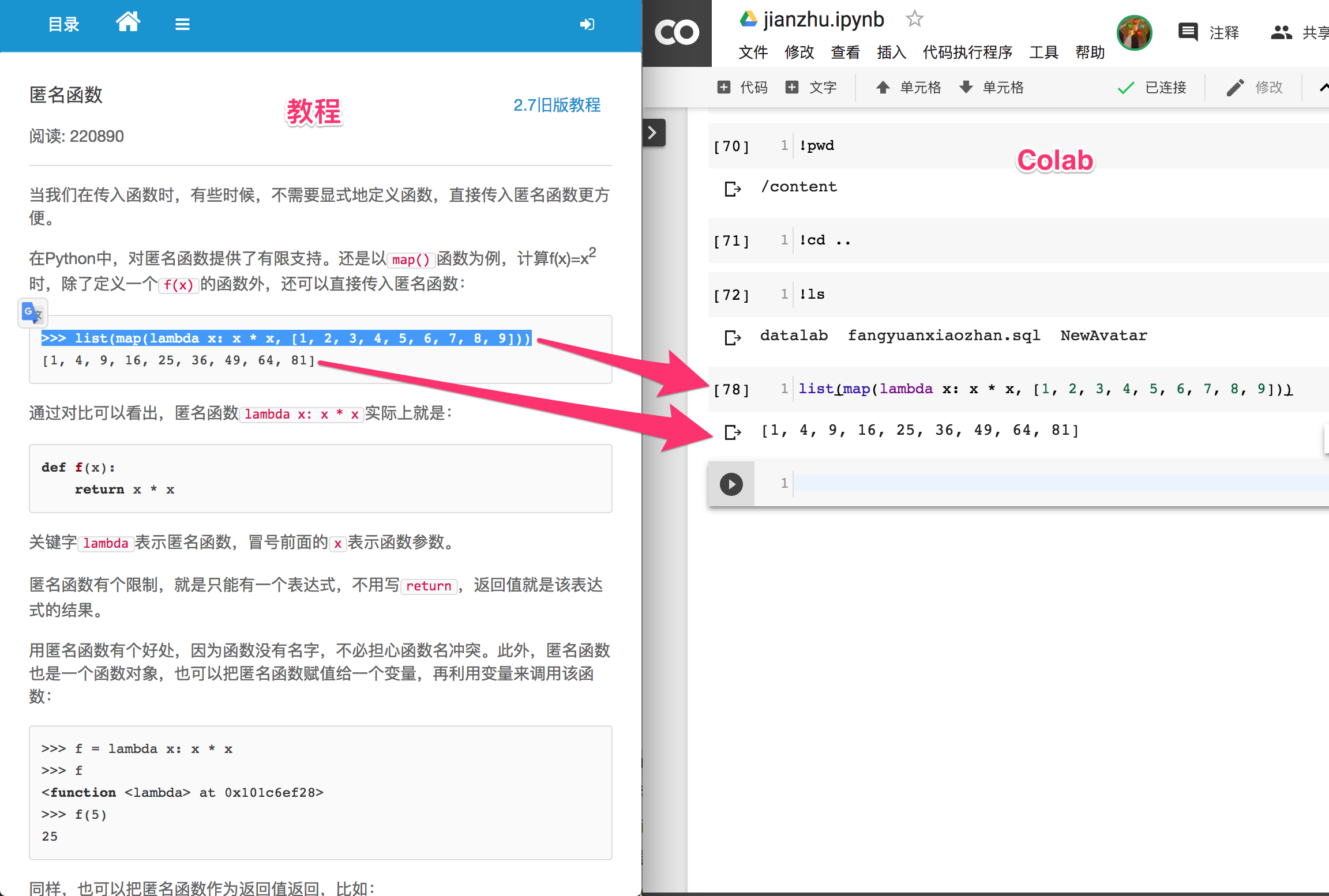
推荐二: 廖雪峰的官方网站
5.保存当前Colab文件
- Colab文件和Google的在线文档一个性质,不需要保存!
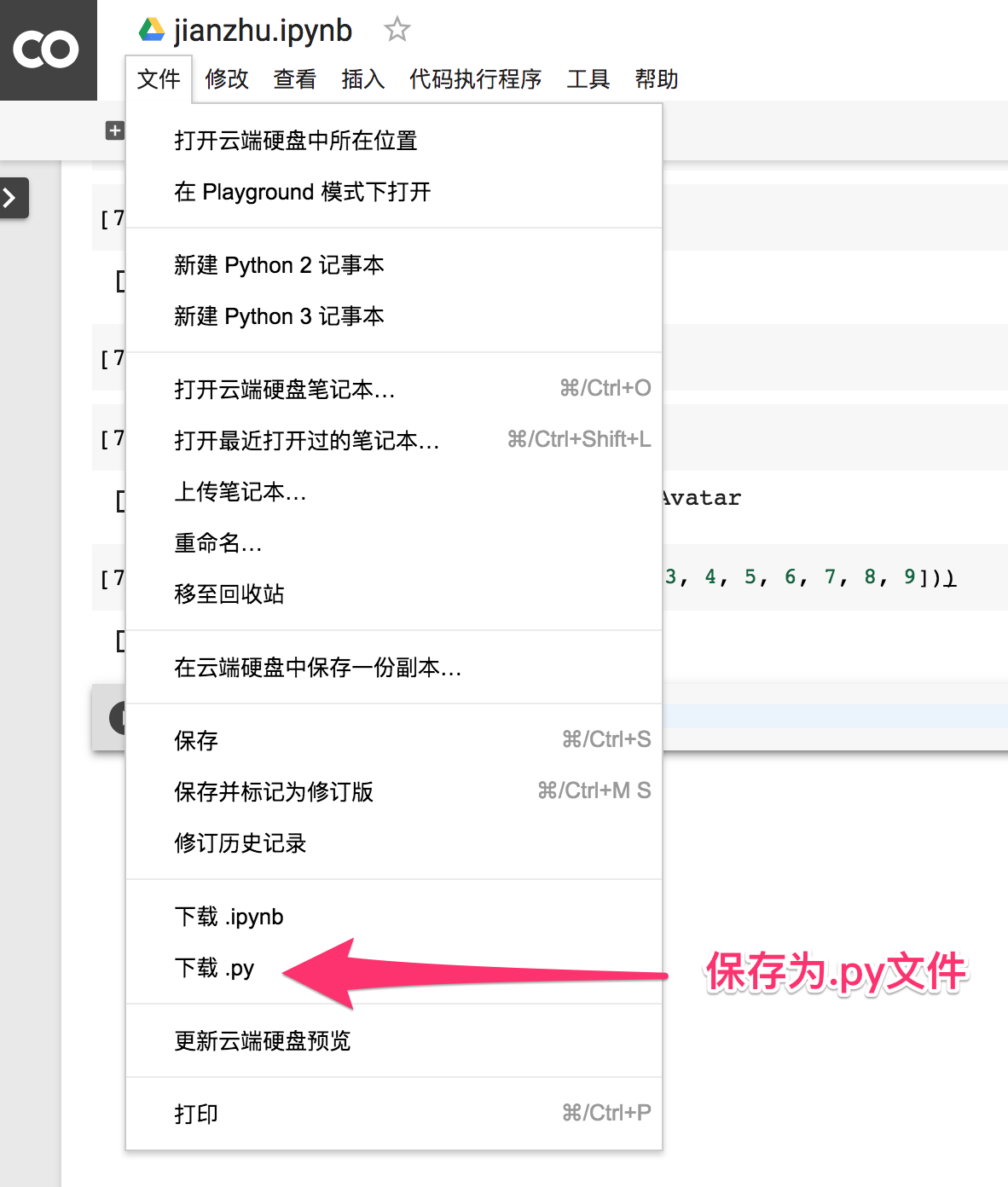
6. 将当前的Colab转换为python标准文件,并保存到本地
7. 共享Colab程序
Colab资源可以以链接方式共享给其他人, 其他人可以直接在线运行, 观看效果
小技巧:
- 如何获取在线环境的公网地址: Python3获取本机公网ip(爬虫法)
- 如何与在线环境进行文件互传: 通过Github仓库进行数据同步是不错的选择!