这是我个人练习的小项目。基于koa2-iview+less定制。用于个人对播放器的复习。现已集成于个人网站上了。后端基于koa2+mongodb,写一套增删改查接口就可以了。
很想把这篇文章独立为一个后端篇。事实上业务处理仍然离不开前端。而且前端的工作量是大大多于后端的。
本文涉及以下要点:
- 后端增删改查流程实现
- 上传解压逻辑及错误处理
- 前后端解析歌词文件
Audios数据模型
通过上一票文章,可以知道,作为单个的音乐数据,必须要拥有以下特性:
- 标题(title)
- 演唱者(singer)
- 链接(resource_url)
- 封面图(cover_url)
- 歌词(lrc)
- 顶(like)/踩(dislike)
在model层新建一个Audio model:
// /mongodb/audio.js /** * 音乐文件管理 */import mongoose from '../utils/mongoose'
const fileSchema = new mongoose.Schema({
type :String , // 保留字段,文件分类
title :String , // 文件名称
size:Number , // 保留字段,文件大小
resource_url :String , // 文件在项目服务器的存储路径
cover_url :String , // 封面文件在项目服务器的存储路径
lrc :String , // 文件在项目服务器的存储路径
singer:String,//歌手
createAt: { // 上传时间
type: Date,
default: Date.now()
},
})
export default mongoose.model("Audio", fileSchema)
上传的文件操作
作为网站用户总是觉得,这么多东西一个个传实,对于开发来说,重复地写同一个逻辑最烦了。不如把文件压缩为为一个zip文件,那该是多么轻松的事情。于是衍生出以下业务逻辑:
- 上传一个zip包
- 标准的zip包包括:歌词(.lrc)/歌曲(.mp3/ogg/…)/封面图(img)
- 后端执行解压到指定文件夹
- 对以上三者分别进行校验,歌曲和封面返回链接地址,歌词返回解析后到文档内容
- 歌曲名作为title,
首先先把管理界面写好吧!
注意:此功能取决于服务器带宽。

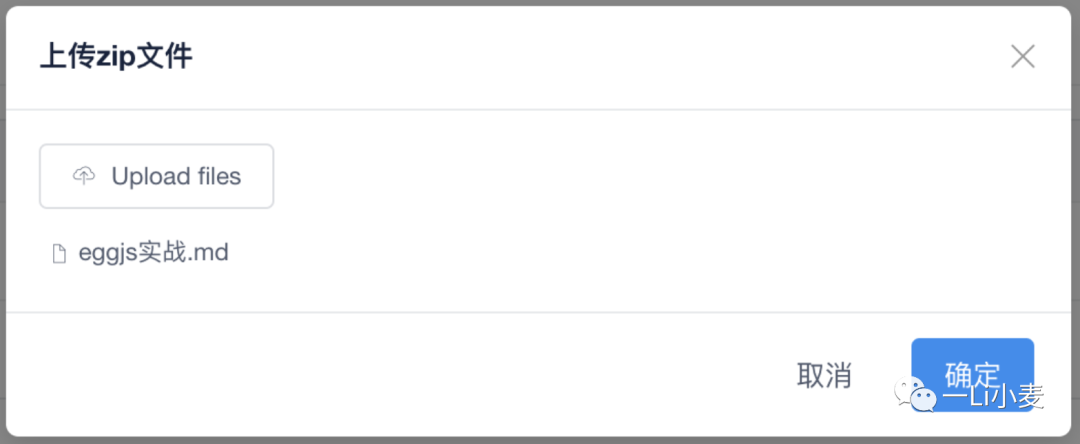
上传
前端组装了一个formdata:{file:binary},后端用的是koa-multer接受。对于form data请求,koa-body-parser无法判读。
// config/uploadAudio.js import multer from 'koa-multer'const storage = multer.diskStorage({
destination:'audios',
filename(ctx, file, cb) {
const fileName = Date.now()+'_'+parseInt(Math.random()*10000,0)+'.'+file.originalname.split(".")[file.originalname.split(".").length-1];
cb(null,fileName);
}
});const multerConfig = multer({storage});
export default multerConfig;
在router.js中,给接口加入以下逻辑:
// router.js
import uploadAudioConfig from '../config/uploadAudio'
// 上传歌曲zip
router.post('/audios/upload',uploadAudioConfig.single('file'),uploadAudio)
这时后你上传的文件都会更新到audios目录下。
文件操作封装
如果我想优雅地使用async await进行文件操作,自己实现一个文件读取库就至关重要了。
解压缩
在uploadAudio业务处理层,你已经可以通过ctx.req.file拿到上传的文件了。它是这样的:
const file=ctx.req.file;
console.log(file);
有了路径,就开始给他解压缩!现在开始,准备好上传模板:
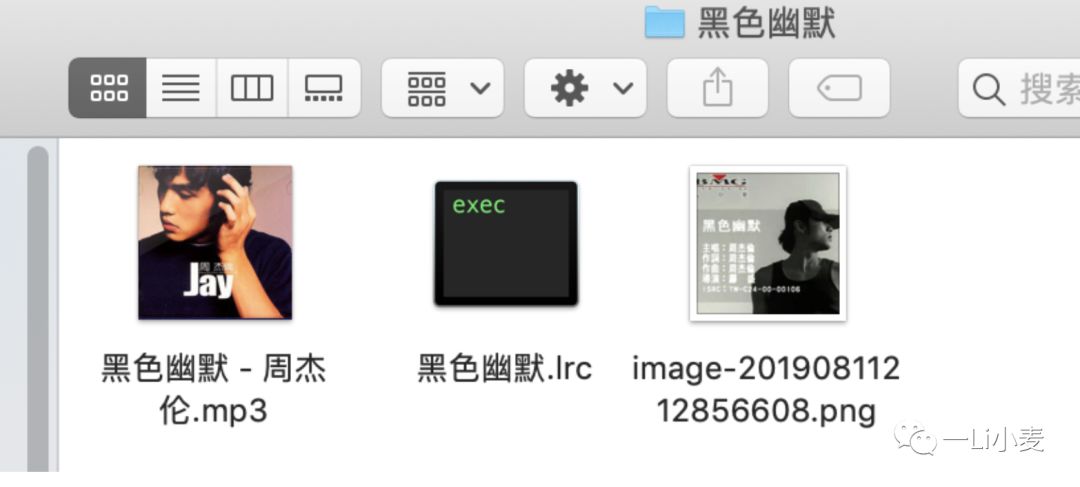
解压缩用的是:node-unzip-2。写一个流解压逻辑:
/*
* 解压文件
* */
export const unzipFile = (filePath, targetPath) => {
return new Promise(resolve => {
const stream = fs.createReadStream(filePath);
stream.pipe(unzip.Extract({ path: targetPath }));
stream.on('error', err => {
resolve({
success: false,
data: err
})
});
stream.on('end', () => {
resolve({
success: true
})
});
})
}有了它,就可以用一行命令解压到指定文件夹:
const unzipRes = await unzipFile(file.path, _root); if(unzipRes.success){ // 删除解压包 await rm(file.path); let root = `${_root}/${file.originalname.split('.')[0]}`;var pa = fs.readdirSync(root); // 需要存进数据库的信息: let body={ title:file.originalname.split('.')[0].split('-')[1], like:0, dislike:0, singer:file.originalname.split('.')[0].split('-')[0], } // 循环遍历当前的文件以及文件夹 for (let i = 0; i < pa.length; i++) { let ele = pa[i]; let url = root + "/" + ele; var info = fs.statSync(url); if (!info.isDirectory()) { let format = ele.split('.')[1]; switch (format) { case 'mp3': console.log('mp3', url) body.resource_url=url; break; case 'png'||'jpg': console.log('png', url) body.cover_url=url; break; case 'txt': console.log('txt', url); // console.log(info); let data = fs.readFileSync(url,'utf-8'); body.lrc=data; default: break; } } } await new Audios(body).save(); ctx.body = setResponseData(SUCCESS_CODE, SUCCESS_MSG); }else{ ctx.body = setResponseData(ERROR_CODE, '解压失败'); }</code></pre></div></div><p>挺好。接下来就是遍历文件夹下的所有文件,完成后,解压包的文件也顺带删掉</p><h5 id="15k4b" name="%E6%9F%A5%E8%AF%A2">查询</h5><div class="rno-markdown-code"><div class="rno-markdown-code-toolbar"><div class="rno-markdown-code-toolbar-info"><div class="rno-markdown-code-toolbar-item is-type"><span class="is-m-hidden">代码语言:</span>javascript</div></div><div class="rno-markdown-code-toolbar-opt"><div class="rno-markdown-code-toolbar-copy"><i class="icon-copy"></i><span class="is-m-hidden">复制</span></div></div></div><div class="developer-code-block"><pre class="prism-token token line-numbers language-javascript"><code class="language-javascript" style="margin-left:0">// 查询列表
export const getAudioList=async (ctx,next)=>{
const list = await Audios.find().sort('-createAt');
ctx.body = setResponseData(SUCCESS_CODE, SUCCESS_MSG, {data:list});
}
好像没什么可说的。
此时前端界面变成了这样:
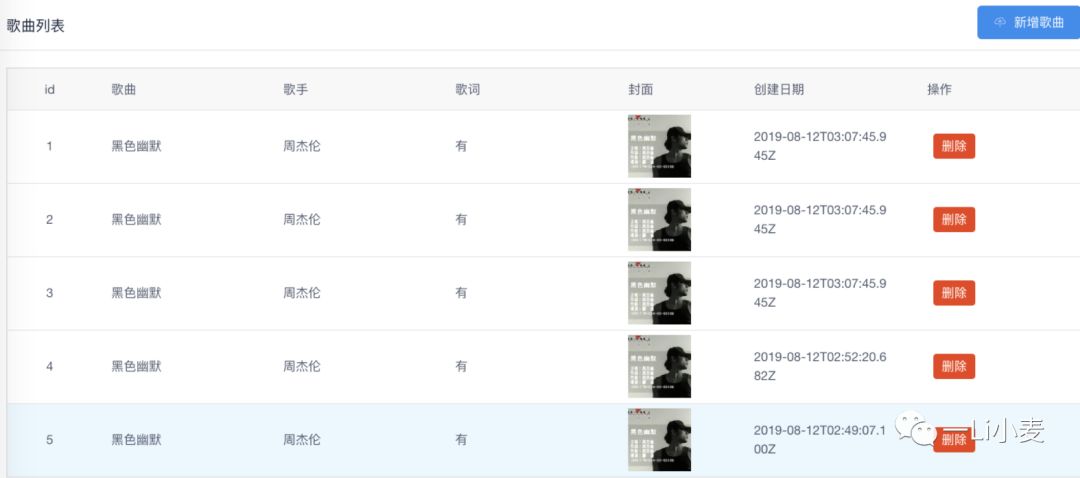
删除
根据id删除
// 删除单条歌曲
export const removeAudio=async (ctx,next)=>{
const {id}=ctx.request.body;
const audio=await Audios.find({_id:id});
const path=audio[0].resource_url.split('/')[0]+'/'+audio[0].resource_url.split('/')[1]
const remove = await removeById(Audios, id);
if (remove.success) {
// 删除文件
await rmdir(path);
ctx.body = setResponseData(SUCCESS_CODE, SUCCESS_MSG);
} else {
ctx.body = setResponseData(ERROR_CODE, ERROR_MSG);
}
}删库是比较简单的,但是还需要做一件事:删除文件。
好了,事情又回到前端了。
歌词
网上有个人开发者写的前端lrc解析插件,看了下api都感觉不舒服。索性自己实现一个。
一般标准的lyric文件是由[时间]内容的tag标签组成,如下图:
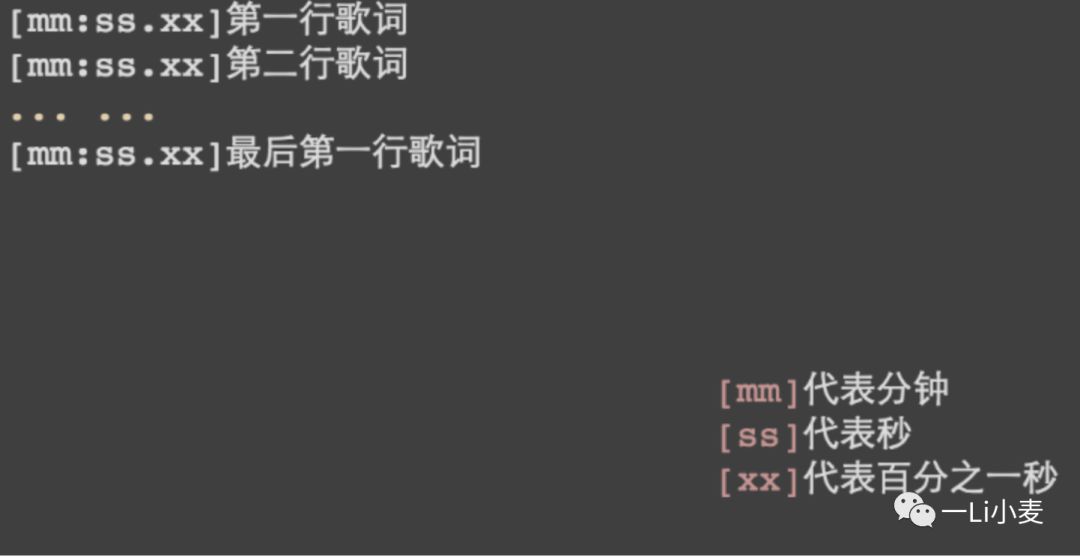
思路就是:拆分时间和歌词,组合成对象,检索对象,展示歌词。

由于篇幅原因,这里写不下太多了。
思路就是:正则读取方括号内时间内容,转化为秒。当currentTime变动时,遍历这个数组。找到与currentTime最接近的歌词段。把它作为一个状态显示出来。
以上。