前言
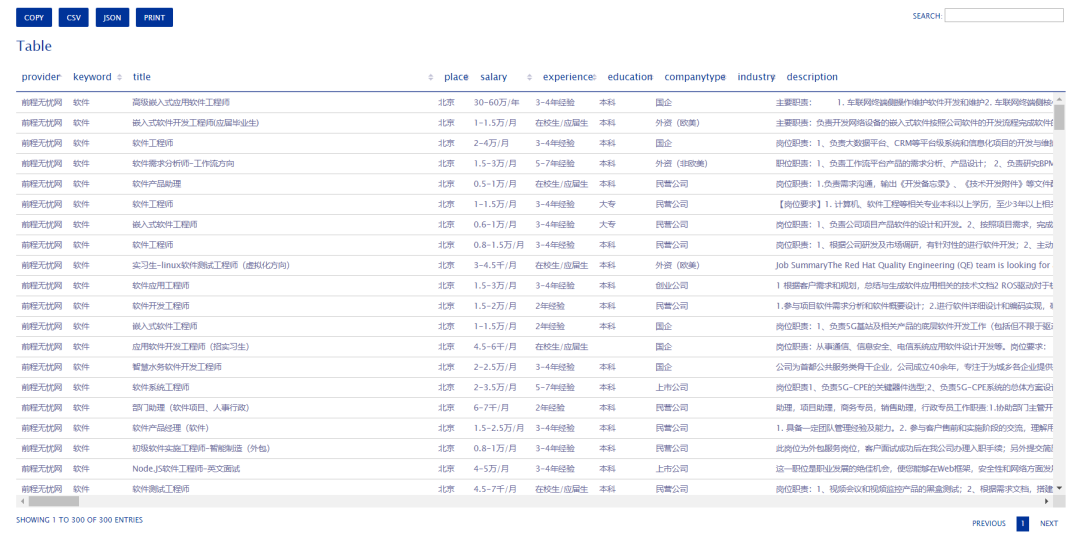
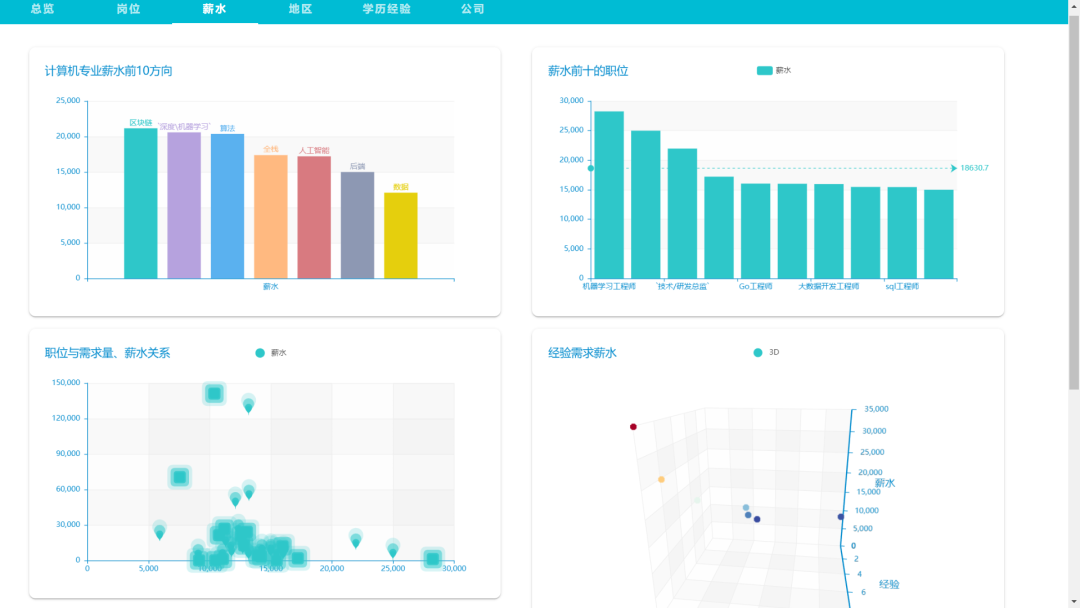
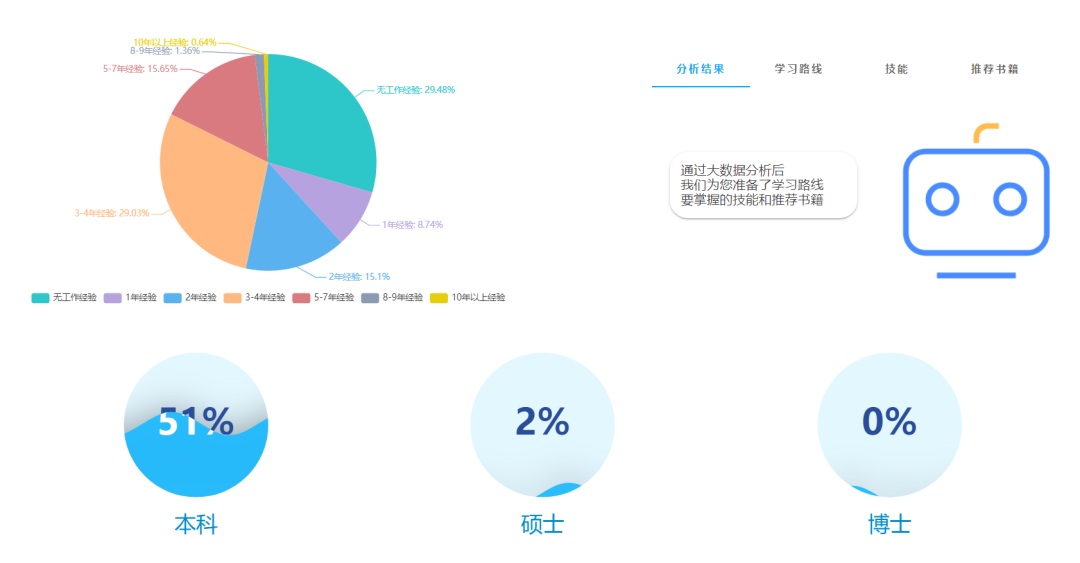
基于数据技术的互联网行业招聘信息聚合系统,本系统以Python为核心,依托web展示,所有功能在网页就可以完成操作,爬虫、分析、可视化、互动独立成模块,互通有无。具体依托python的丰富库实现,爬虫使用Requests爬取,使用lxml、beautifulsoup4解析。使用numpy、pandas分析数据,使用pyecharts做可视化,使用Flask进行web后台建设。数据通过csv、MySQL、配置文件来进行存储互通。
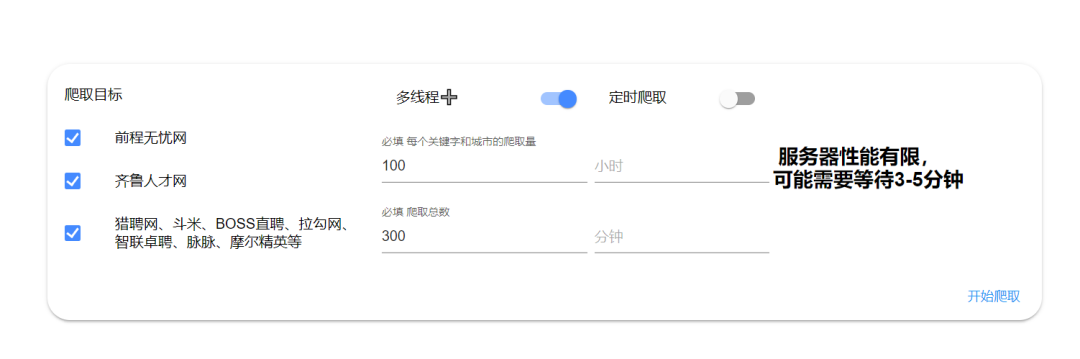
为了拓展功能编写了定时器,微信推送,为了适应团队合作编写了函数注册器,参数迭代器。爬虫数据来自前程无忧、齐鲁人才网、猎聘网、拉勾网等等网站,需要的基本数据一应俱全。
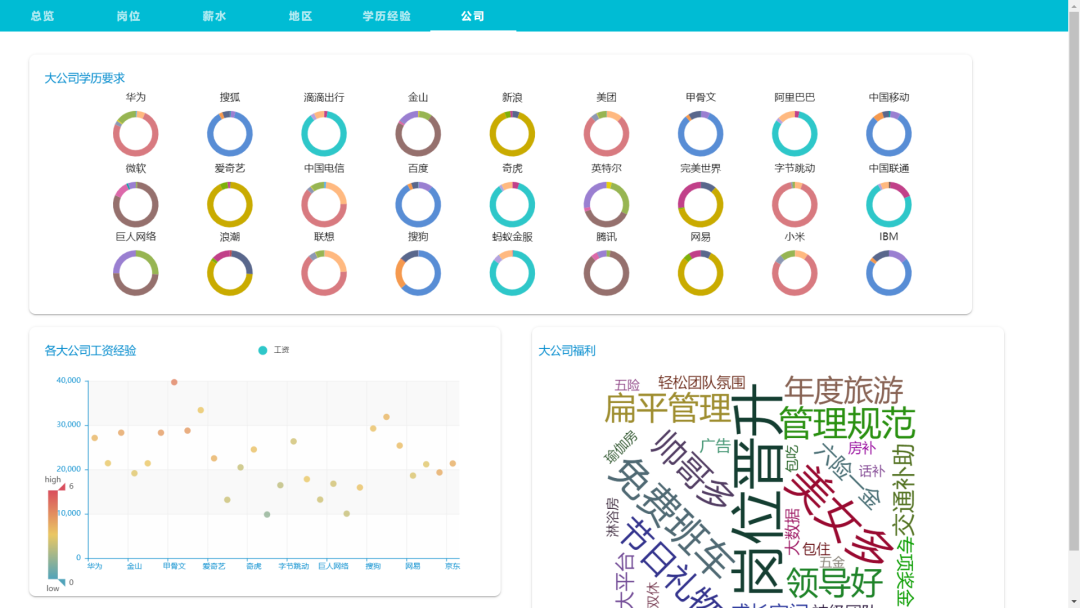
展示

环境
- Windows \ Linux
- Python 3.6 : numpy , pandas , Requests , pyecharts , lxml , PyMySQL
- MySQL 8.0.11
- Chrome(内核版本60以上)
安装
- 运行 install_package.bat(出错管理员权限下尝试)
- 修改mysql配置 位于/analysis/analysis_main.py 系统本身有一个可视化的配置文件,即您不需要再导入数据进行分析,如果想重新分析,需要导入数据库数据还需按照数据库字段修改input_data.py内容
- 将js.7z 解压放在/static 目录下
- 运行 server.py 来运行web服务器
- 使用Chrome访问 http://127.0.0.1
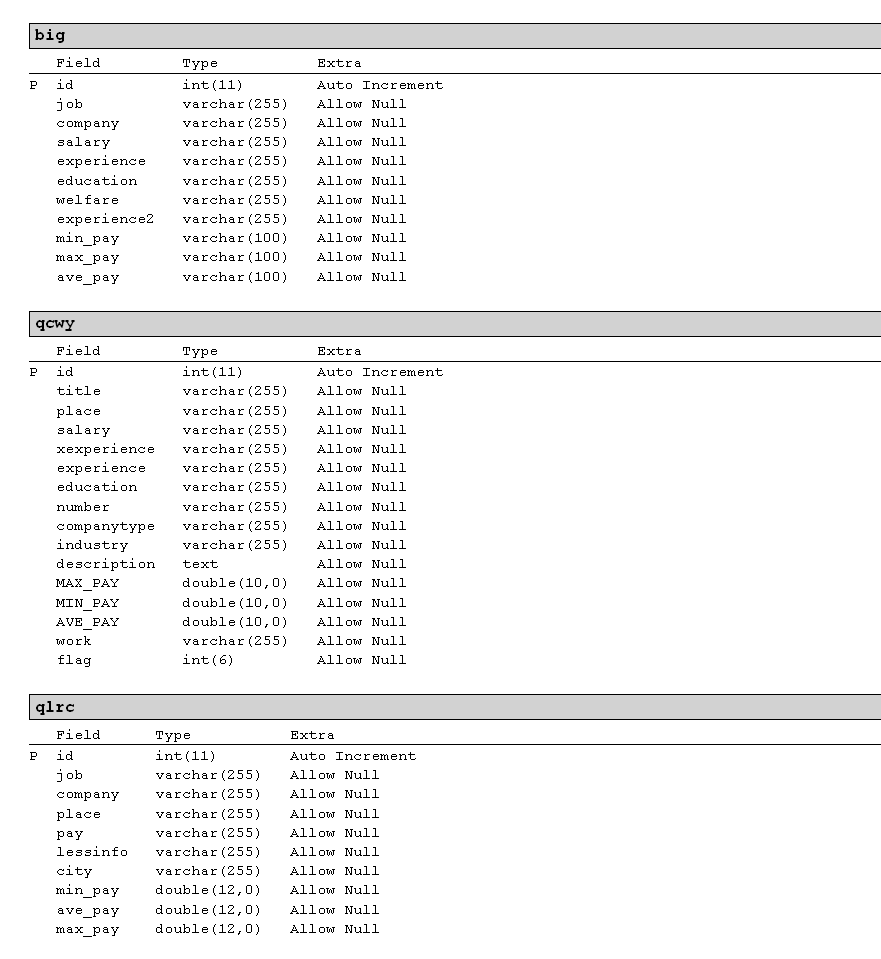
数据库字段
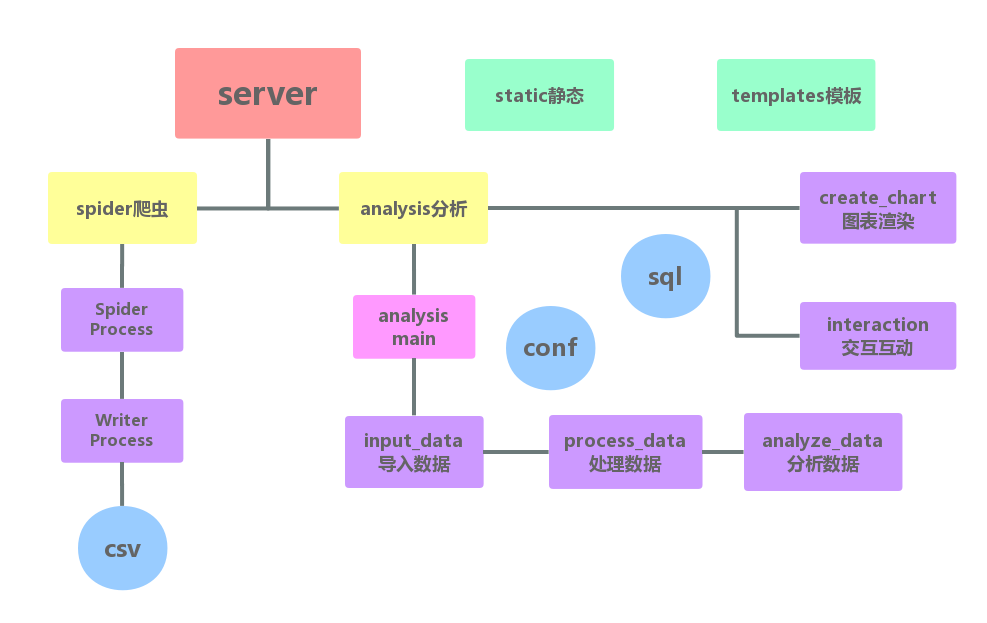
架构
系统大致结构如下图,spider目录存放爬虫代码,analysis目录承担了导入、分析、渲染图表、交互等功能,data目录存放原始数据,conf目录存放图表、mysql配置文件。导入处理分析入口统一由analysis_main控制,由server调用,其他功能直接由server调用,所有功能在主页就可以启动。

源码获取
公众号(Python研究者)后台回复暗号:聚合系统 就能获取。