目录
- 前言
- 准备工作
- 爬虫
- 分析网页信息
- 利用正则表达式抓取有有用信息
- 简单的清洗数据
- 存储数据
- 网页模板制作
- 表格化展示爬虫得到的数据
- echarts数据可视化
- wordcloud词云展示
- 最终成品展示
前言
之前一直对爬虫有兴趣,但是一直没有真正静下心来去好好学习过,这一段时间跟着b站上的一个教程做了自己人生中第一个爬虫程序,还是很有成就感的。
准备工作
1. 我们爬取一个网站首先要具备以下这些知识,否则实际操作起来还是比较困难的,比如说h5,正则表达式,基础的数据结构,python的基本语法知识。 2. 我们安装完python环境以及编译器之后,需要引入我们所需要的的模块
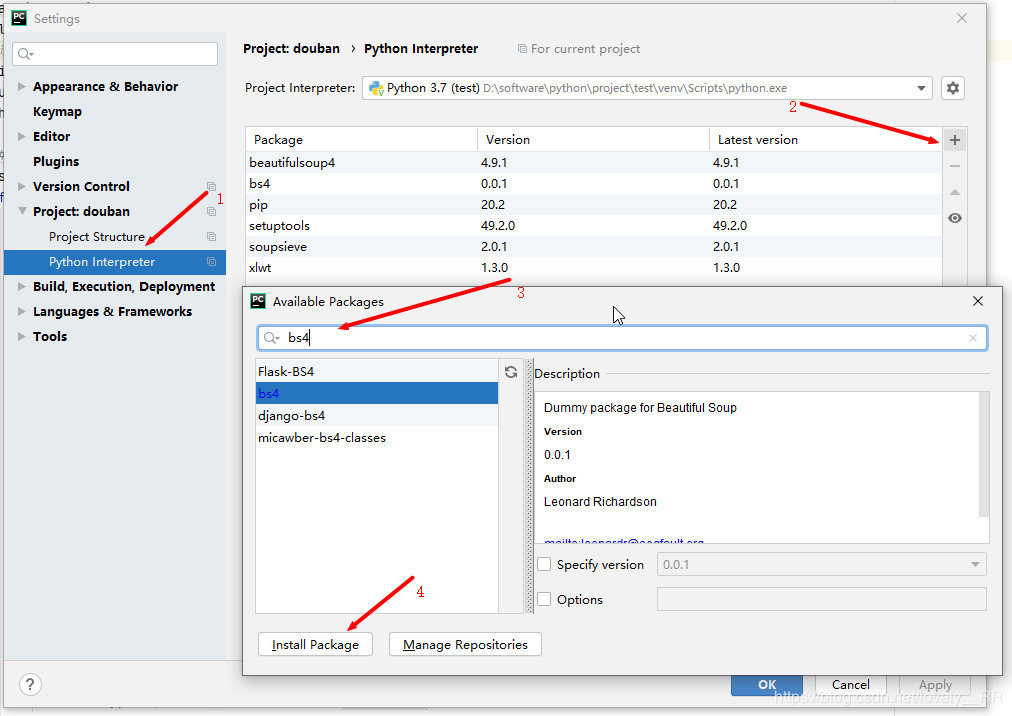
按照这个步骤将我们所需要的的模块安装完成即可。 本次所需要的的模块有:
bs4:主要用来分析网页信息结构 xlwt:主要负责Excel表格的读写操作 flask:web开发微框架 jinja2:模板引擎 wordcloud:主要用来实现词云展示 #如果出现安装不成功,可以往博客下面看,有解决方案 matplotlib:绘图,数据可视化 jieba:将句子进行分词
爬虫
分析网页信息
既然要爬取网站信息,那么我们首先要先看懂网站的URL地址,这样才能方便我们爬取相关信息。我们先分析他的URL地址:

URL地址格式基本就是:
https://movie.douban.com/top250?start=(这里我们需要添加参数)
于是我们便可以先尝试先利用URL先爬取整个HTML页面
import urllib.request,urllib.error,urllib.parse #制定URL
#爬取指定页面的数据
def askURL(url):#这里的URL可以换成上面的URL地址进行测试
head={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36"} #设置请求头,模拟浏览器向服务器发请求,并且让服务器知道我们浏览器的版本
req=urllib.request.Request(url=url,headers=head)
response=urllib.request.urlopen(req) #接收服务器发回来的响应
html=response.read().decode("utf-8") #解析响应
print(html)
return html利用正则表达式抓取有有用信息
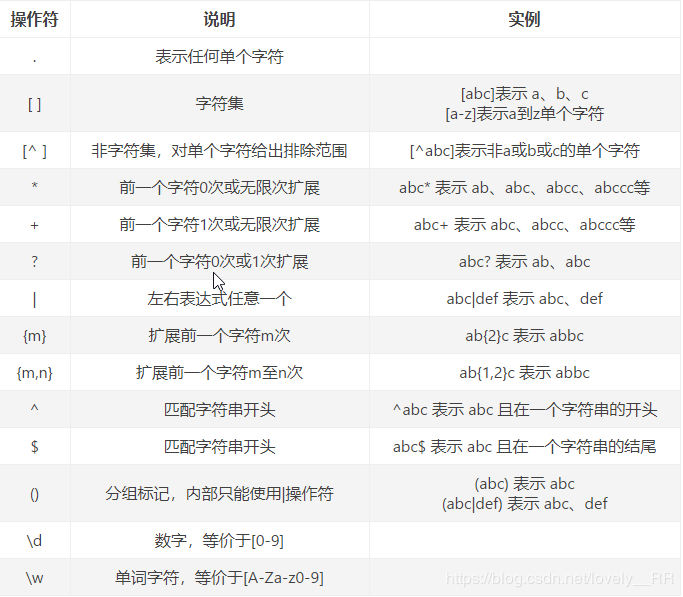
我们首先先认识一些基础的正则符号
其次我们再来简单分析一下我们的网页结构信息
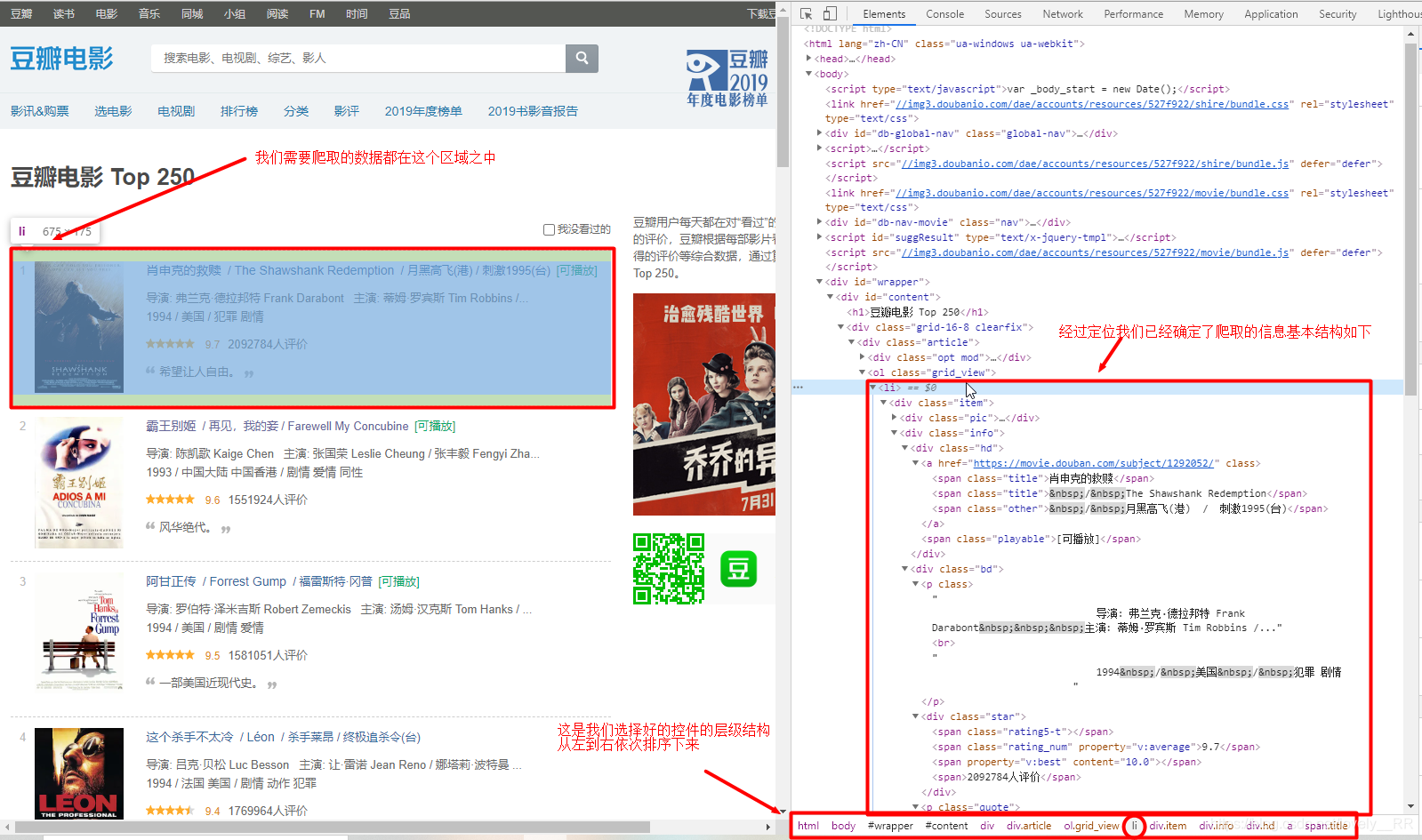
我们可以清楚的看到我们所需要的的信息都是存储在各式各样的标签之中,所以这时候就需要我们的正则表达式来对我们所需要的的信息进行提取。 举一个例子:

比如说我们现在要爬取影片详情的链接,那么我们就需要制定正则表达式的规则,让这个规则区帮助我们从整个html页面中找我们所需要的的信息。
#影片详情链接规则
findlink=re.compile(r'<a href="(.*?)">') #创建正则表达式对象,表示规则(字符串的模式)
#这里我们可以先复制这个红色框中的内容过来,然后用(.*)来替换我们所需要的爬取的内容这个电影信息的正则表达式爬取规则
import re #正则表达式,进行文字匹配
#影片详情链接规则
findlink=re.compile(r'<a href="(.*?)">') #创建正则表达式对象,表示规则(字符串的模式)
#影片图片
findImgsrc=re.compile(r'<img.* src="(.*?)"',re.S) #re.S让换行符包括在字符中
#影片片名
findTitle=re.compile(r'<span class="title">(.*)</span>')
#影片评分
findRating=re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
#影片评价人数
findNum=re.compile(r'<span>(\d*)人评价</span>')
#影片概况
findContent=re.compile(r'<span class="inq">(.*)</span>')
#找到影片的相关内容
findBd=re.compile(r'<p class="">(.*?)</p>',re.S)简单的清洗数据
因为我们爬取完的数据可能存在部分换行符,以及各种符号的差异,所以我们简单的用字符串替换的方法进行清洗,并且将数据存储到一个列表之中。
from bs4 import BeautifulSoup #网页解析,获取数据
#爬取网页
def getData(baseurl):
datalist=[]
# 2.逐一解析数据
for i in range(0,10):
url=baseurl+str(i*25)
html=askURL(url)
#逐一解析数据
soup=BeautifulSoup(html,"html.parser")
for item in soup.find_all("div",class_="item"): #查找符合要求的字符串,形成列表
#print(item) #测试;查看电影item全部信息
data=[] #保存一部电影的全部信息
item=str(item)
link=re.findall(findlink,item)[0] #re库通过正则表达式查找指定字符串
data.append(link) #添加影片链接
img = re.findall(findImgsrc,item)
data.append(img) #添加影片图片
title=re.findall(findTitle,item)
if(len(title)==2):
data.append(title[0]) #添加影片中文名
otitle=title[1].replace("\xa0/\xa0","") #去掉外文电影名中的\符号
data.append(otitle) #添加影片外文名
else:
data.append(title)
data.append(" ")
rating=re.findall(findRating,item)[0]
data.append(rating) #添加影片评分
num = re.findall(findNum, item)[0]
#print(type(num))
data.append(num) #添加影片评分人数
content=re.findall(findContent,item)
if len(content)!=0:
content=content[0].replace("。","")
data.append(content) #添加影片概述
else:
data.append(" ")
bd=re.findall(findBd,item)[0]
bd=re.sub("<br(\s+)?/>(\s+)?"," ",bd) #去掉</br>
bd=re.sub("/"," ",bd)
data.append(bd.strip()) #添加影片详情
datalist.append(data)
#print(datalist)
return datalist</code></pre></div></div><h3 id="7e8fp" name="%E5%AD%98%E5%82%A8%E6%95%B0%E6%8D%AE">存储数据</h3><p><strong>1.</strong> 首先我们先介绍一下如何存储在Excel中
这里我们就需要用到xlwt这个模块,主要创建Excel文件对象,以及sheet工作对象,之后将我们爬取的数据写进sheet对象之中即可。
代码语言:javascript复制#3.保存数据
def saveData(datalist,savepath):
book = xlwt.Workbook(encoding="utf-8") # 创建workbook对象
sheet = book.add_sheet("豆瓣电影top250",cell_overwrite_ok=True) # 创建工作表
col=("电影详情链接","图片链接","影片中文名","影片外文名","评分","评分人数","概况","相关信息")
for i in range(0, 8):
sheet.write(0,i,col[i]) #列名
print("save")
for i in range(1,251):
print("第%d条数据" % i)
for j in range(0,8):
sheet.write(i,j,datalist[i-1][j])
book.save(savepath)
Excel数据展示
 在这里插入图片描述
在这里插入图片描述2. 我们将数据存储在SQLite数据库之中
这个SQLite数据库是python自带的,对于初学者,使用起来十分的方便。
我们先尝试连接SQLite数据库。
 在这里插入图片描述
在这里插入图片描述 在这里插入图片描述
在这里插入图片描述
这样我们便能成功连接上SQLite数据库了。
代码语言:javascript复制#初始化数据库并建立相应的数据表
def init_db(dbpath):#代表我们所要创建的数据库的名称
sql='''
create table movie250 #创建数据表
(
id integer primary key autoincrement,
info_link text,
pic_link text,
cname varchar,
ename varchar,
score numeric ,
rated numeric ,
instroduction text,
info text
)
''' #创建数据表
conn=sqlite3.connect(dbpath)
cursor=conn.cursor()
cursor.execute(sql)
conn.commit()
conn.close()
#将我们爬取到的数据插入到相应的数据表之中
def saveDataDB(datalist,dbpath):
init_db(dbpath)
conn=sqlite3.connect(dbpath)
curser=conn.cursor();
for data in datalist:
for index in range(len(data)):
if index == 4 or index == 5:
continue
data[index]=str(data[index]) #这句话大家可以删了试试,有的会出现list无法转换到str类型的错误,也是博主遇到的一个小bug
data[index] = '"' + data[index] + '"'
sql = '''
insert into movie250 (
info_link,pic_link,cname,ename,score,rated,instroduction,info)
values(%s)''' % ",".join(data)
print(sql)
curser.execute(sql)
conn.commit()
curser.close()
conn.close()
数据库数据展示:
 在这里插入图片描述
在这里插入图片描述网页模板制作
这里我挑选的是模板之家提供的模板seo营销推广公司响应式网站模板,但是下载是要付费的,刚好群里这些资源都已经提供了,所以可以拿来直接用。资源在下面
链接:https://pan.baidu.com/s/1EHS9jvByALEYY80uB5a8oA
提取码:fwfs
打开之后就是这样的一个样式
 在这里插入图片描述
在这里插入图片描述
之后我们来创建一个flask程序
 在这里插入图片描述
在这里插入图片描述 在这里插入图片描述
在这里插入图片描述 在这里插入图片描述
在这里插入图片描述
之后我们将我们之前的网页文件导入进来
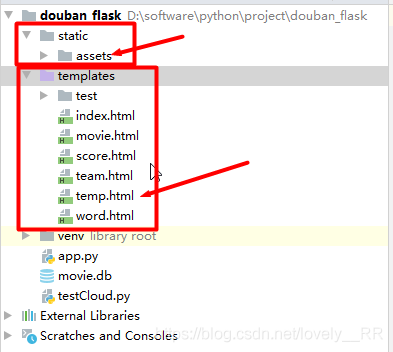 在这里插入图片描述
在这里插入图片描述
之后我们运行app.py就可以看到我们的界面了
表格化展示爬虫得到的数据
这里就像我们之前操作数据库的一样,先连接数据库,然后创建游标,之后通过游标将我们的数据取出来即可
代码语言:javascript复制@app.route('/movie')
def movie():
datalist=[]
conn=sqlite3.connect("movie.db")
cur=conn.cursor()
sql='''
select * from movie250
'''
data=cur.execute(sql)
for item in data:
datalist.append(item)
cur.close()
conn.close()
# for movie in datalist:
# print(movie[2])
#webbrowser.open(movie[2])
return render_template("movie.html",datalist=datalist)
这里面会出现一个小bug,就是展示电影图片时,一开始我们读出来的图片都是这样的,这时候是因为从来没有加载过,所以图片显示不出来,但是一共有250张图片,总不能一张一张的区点吧,所以我们还是可以通过python编写脚本来帮助我们快速打开这些图片的网页即注释掉的代码
代码语言:javascript复制for movie in datalist:
print(movie[2])
webbrowser.open(movie[2])
这样我们就能快速打开这些图片网页了。编写完成之后就是这样
 在这里插入图片描述
在这里插入图片描述echarts数据可视化
首先先提供echarts的下载地址:echarts在线定制
大家可以根据自己的需要进行定制。
下载完成之后添加到static/assets/js/echarts.min.js路径下即可。
之后我们可以先通过官方文档的一个小栗子帮助我们快速入门
注意echarts的路径要与自己项目的路径相匹配。
代码语言:javascript复制<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<!-- 引入 ECharts 文件 -->
<script src="echarts.min.js"></script>
<title>Title</title>
</head>
<body>
<!-- 为 ECharts 准备一个具备大小(宽高)的 DOM -->
<div id="main" style="width: 600px;height:400px;"></div>
<script type="text/javascript">
// 基于准备好的dom,初始化echarts实例
var myChart = echarts.init(document.getElementById('main'));
// 指定图表的配置项和数据
var option = {
title: {
text: 'ECharts 入门示例'
},
tooltip: {},
legend: {
data:['销量']
},
xAxis: {
data: ["衬衫","羊毛衫","雪纺衫","裤子","高跟鞋","袜子"]
},
yAxis: {},
series: [{
name: '销量',
type: 'bar',
data: [5, 20, 36, 10, 10, 20]
}]
};
// 使用刚指定的配置项和数据显示图表。
myChart.setOption(option);
</script>
</body>
</html>
效果如下:
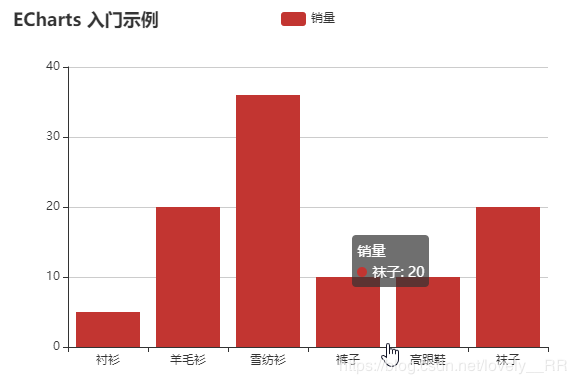 在这里插入图片描述
在这里插入图片描述
并且官方也提供了十分多的模板,我们只需要负责填充数据就可以实现这些酷炫的图表了
 在这里插入图片描述
在这里插入图片描述
接下来就是编写我们项目的图表了,我们也是选用柱状图来进行展示。展示每个评分所拥有的电影数量,所以我们就需要从数据库中提取出评分,以及相应评分所包含的电影数量。
代码语言:javascript复制@app.route('/score')
def score():
num=[]
score=[]
conn = sqlite3.connect("movie.db")
cur = conn.cursor()
sql = '''
select score,count(score) from movie250 group by score
'''
data = cur.execute(sql)
for item in data:
#num.append(item[1])
score.append(str(item[0]))
num.append(item[1])
cur.close()
conn.close()
return render_template("score.html",score=score,num=num)
这样我们只需要在HTML文件中将这两个数据填充相应的图表位置即可。
代码语言:javascript复制<script type="text/javascript">
var dom = document.getElementById("main");
var myChart = echarts.init(dom);
var app = {};
option = null;
option = {
color:['#3398DB'],
tooltip: {
trigger: 'axis',
axisPointer: {
type: 'shadow'
}
},
grid: {
left: '3%',
right:'4%',
bottom:'3%',
containLabel:true
},
xAxis: {
type: 'category',
data: {{ score|tojson }}
<!--['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun','999']-->
},
yAxis: {
type: 'value'
},
series: [{
data: {{ num }},
<!--[120, 20, 150, 80, 70, 110, 130,200],-->
barWidth:'45%',
type:'bar'
}]
};
;
if (option && typeof option === "object") {
myChart.setOption(option, true);
}
</script>
这样便能显示我们的图表了。
效果如下:
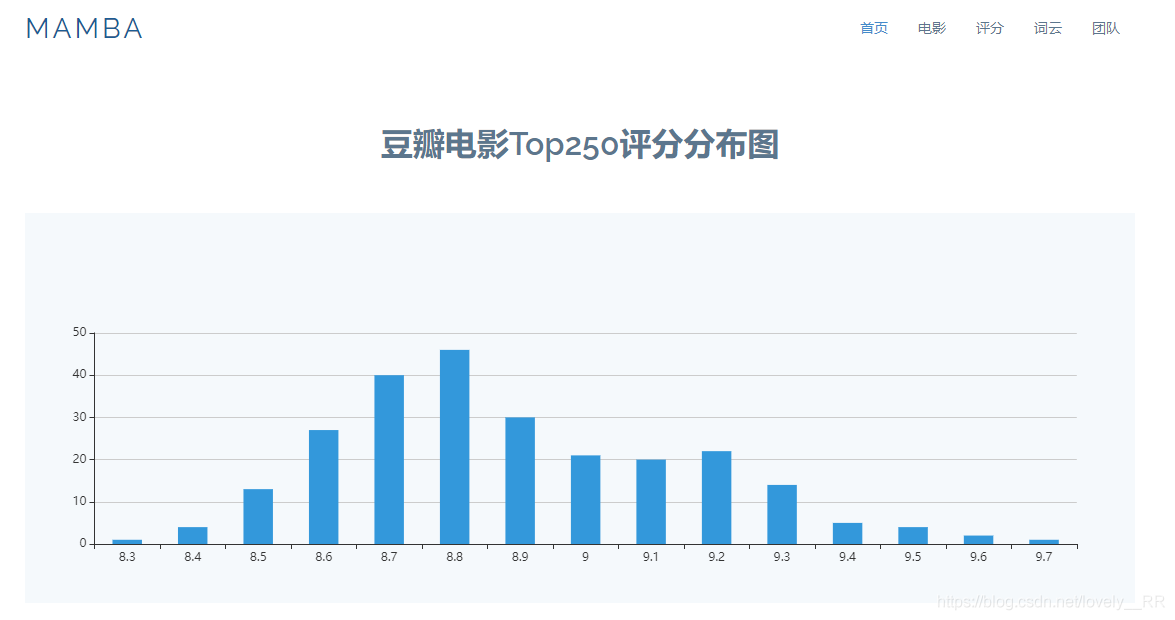 在这里插入图片描述
在这里插入图片描述wordcloud词云展示
这里如果大家添加wordcloud模块添加不上的话,可以通过这种方式进行修改
 在这里插入图片描述
在这里插入图片描述
修改这里的默认下载仓库地址
 在这里插入图片描述
在这里插入图片描述
可以修改成:
清华:
https://pypi.tuna.tsinghua.edu.cn/simple
阿里:
http://mirrors.aliyun.com/pypi/simple/
豆瓣:
http://pypi.douban.com/simple/
华中理工大学:
http://pypi.hustunique.com/
山东理工大学:
http://pypi.sdutlinux.org/
中国科学技术大学:
http://pypi.mirrors.ustc.edu.cn/
之后我们依旧照着之前的方式添加模块就行了
代码语言:javascript复制import jieba #将句子进行分词
from matplotlib import pylab as plt #绘图,数据可视化
from wordcloud import WordCloud #制作词云
from PIL import Image #图片处理
import numpy as np #矩阵运算
import sqlite3 #数据库操作
con=sqlite3.connect("movie.db")
cur=con.cursor()
sql="select instroduction from movie250"
data=cur.execute(sql)
text=""
for item in data:
text+=item[0]
#print(text)
cur.close()
con.close()
cut=jieba.cut(text)
string=",".join(cut)
print(len(string))
img =Image.open(r".\static\assets\img\123.jpg")
img_array=np.array(img) #将图片转换成数组
wc=WordCloud(
background_color="white",
mask=img_array,
font_path="STXIHEI.TTF", #字体所在位置C:\Windows\Fonts
# min_font_size=5,
# max_font_size=120
)
wc.generate_from_text(string)
#绘制图片
fig=plt.figure(1)
plt.imshow(wc)
plt.axis("off")
#plt.show() #显示生成的词云文件
#输出词云图片
plt.savefig(r".\static\assets\img\ciyun.jpg",dpi=3600) #将句子进行分词
最终成品展示
编写网页的步骤我都省略了,只保留了关键代码。所有的代码解释我都放在注释里了,并没有详细说明,如果有需要或者不懂的,可以私聊博主。
这里也贴上B站教学视频地址
 在这里插入图片描述
在这里插入图片描述