论文:
https://arxiv.org/abs/2312.13964
代码:(文末点击阅读原文可直达,欢迎 star)
https://github.com/open-mmlab/PIA
网站:
https://pi-animator.github.io/
在线应用:
https://openxlab.org.cn/apps/detail/zhangyiming/PiaPia
个性化生成技术已经能够让我们可以生成自定义的内容、风格的图像,我们进一步希望给这些生成的精美的个性化图像加上动态。然而这一目标存在两大难点,第一,生成的视频难以还原用户输入图像的细节;第二,生成的视频无法按照用户需要用文本提示词精确控制。
针对这两大难点,PIA 应运而生,PIA 能够还原图像细节、高度响应提示词内容的视频。

方法简介
PIA(Personalized Image Animator)是文本驱动的个性化图生视频模型,它可被插入不同的文生图底模中以生成不同风格、内容的视频。
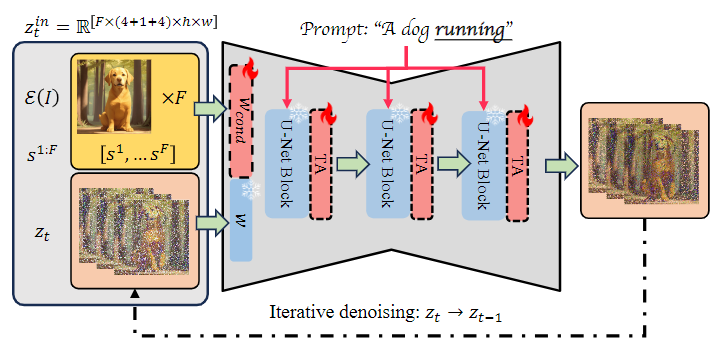
框架图如下,用户输入的图像会与帧间相似度结合通过条件模块,接着在 UNet 中参与 Cross-Attention 计算以实现根据文本为输入图像添加动效。
它的核心是条件模块与帧间相似度(图中黄色部分),借助这样的设计,PIA 可以生成还原图像细节、高度响应提示词内容的视频。
应用介绍
文本控制动效生成
PIA 可以为你制作你喜欢的人物的表情包。通过不同的文本提示词,可以为人物添加不同的表情、动效。

动效幅度控制
PIA 可以控制生成视频中动效的幅度。通过帧间相似度的设计,可以实现不同幅度动效的生成。

风格迁移
PIA 还能够为你的图像生成不同风格的视频。PIA 可以适应各种风格的底模型,将模型风格迁移到生成的视频中。
