1. 背景
ELKB(Elasticsearch、Logstash、Kibana、Beat的组合)是一套开源的分布式日志管理方案。凭借其闭环的日志处理流程、高效的检索性能、线性的扩展能力、较低的运维成本等特点,ELKB在最近几年迅速崛起,成为实时日志处理开源领域的首要选择。本文先向大家初步介绍ELK生态及其应用场景,后续会更多的介绍我们在ELK方面的工作。
2. 用户需求
在日志处理方面,用户经常遇到如下需求:
- 运维同学希望分析分布式环境下的错误日志,使用关键字搜索实时定位问题? 问题:逐台机器grep日志的方案,在分布式环境中变得十分痛苦;使用传统的大数据解决方案(Hadoop生态)可以解决日志集中管理的问题,但通过MR、SparkSQL等方式支持grep操作的使用成本高,且时效性差,一般延时在数小时甚至天级。
- 业务同学需要了解最新的请求量、请求延时、错误率等,运营同学需要实时获取业务运营状态? 问题:可使用Hadoop生态 + 分析型数据库(OLAP)等配合完成日志的清洗、分析工作,但这种方案不仅时效性差,引入多套系统加剧了维护成本。
ELKB生态正是为满足以上日志分析需求而诞生的。
3. ELKB的架构
ELKB是一套开源的、闭环的分布式日志管理方案,覆盖日志从采集,到清洗、存储、分析、可视化等全流程。在实际应用场景中,ELKB的常见部署架构如下:
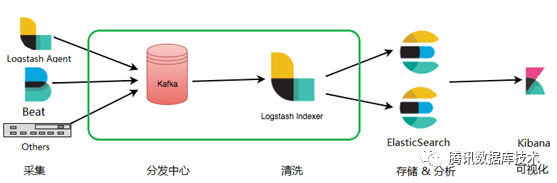
其中,每个组件的功能如下: Beat:非常轻量的Agent,部署于业务机器上,用于实时采集产生的数据传递给下游。
- 由于Beat的出现,原ELK生态被改称为ELKB生态。
- Elastic官方提供了非常丰富的Beat种类,可用于采集文件、抓取网络包、获取探针数据等各种数据形式,用户也可以非常容易的扩展Beat抓取自定义的数据源。
- 通常使用FileBeat抓取机器上的日志数据,单个FileBeat可以采集同机器上的多各不同格式的日志源发往多个不同的下游,且FileBeat使用的CPU、内存资源可限制。
Logstash:一个集日志采集、清洗功能于一身的模块。
- Logstash Agent:使用Logstash模块的日志采集功能。它可以作为日志采集的Agent,支持几乎任何类型的日志,包括系统日志、错误日志和自定义应用程序日志。
- Logstash Indexer:使用Logstash模块的清洗功能。它可以利用正则从日志中抽取信息,把日志从文本形式转化为结构化 或 半结构化数据,并发送给Elasticsearch。
Elasticsearch:一个构建于Apache Lucene搜索引擎 基础上的弹性分布式系统,非常容易进行集群扩展,提供全文搜索和分析型数据库能力。
- Elasticsearch最早用于站内搜索,根据关键词搜索网站内部的所有网页,类似网站内部的谷歌、百度。一个知名的应用场景为github的站内搜索功能,同领域的竞争者是老大哥Solr。
- 凭借对Elasticsearch 的周边生态以及目标市场的精准把握,Elastic公司现在已经把主要目标市场转移到了日志数据的收集、存储、分析及监控,并发展出ELKB生态,成为开源日志处理领域的引领者。
- 也有少量用户把Elasticsearch作为文档型数据库领域,功能类似MongoDB。
Kibana:一个基于Web的图形界面,用于搜索、分析和可视化Elasticsearch中的日志数据。
- 它依赖Elasticsearch强大的分析检索能力,提供非常丰富的图形分析能力(折线图、饼图、地图等),帮助用户更形象、直观的分析数据。
备注:
- 由于Logstash功能太过复杂,不适合作为Agent部署在业务机器上,ES5.X之后这部分功能逐渐被更轻量Beat所取代。
- 为了简化系统架构、降低维护成本,ES5.x之后,Elastic公司开始把数据清洗功能逐渐融入Elasticsearch中,在单一解析规则场景下性能可提高10x 。
- 对于同一份日志有其他消费需求(备份、离线分析)时, 通常需要引入Kafka作为日志的分发中心,供其他需求消费数据;而对于纯粹的日志分析、检索需求,可以省略上图中绿色框内的部分,使用下面非常简化的架构。

4. 典型应用场景
ELKB主要目标市场在日志领域,典型的应用场景如下:
- 模糊搜索:从业务机器上实时采集日志,存储到Elasticsearch中,通过模糊搜索等能力定位问题。主要依赖Elasticsearch提供的全文检索能力,支持秒级的实时性需求。 具体场景:使用错误日志、慢日志进行问题定位等。
- 结构化及分析:从业务机器上实时采集日志,然后使用Logstash 或 Elasticsearch进行数据清洗,存储于Elasticsearch中;借助于Elasticsearch强大的分析能力,用户可以通过Kibana进行灵活的可视化分析。 具体场景:使用业务日志、审计日志、交易数据对业务状态进行分析等。
ELKB不适合的场景如下:
- 海量数据的离线处理:对于时效性要求不高、日志总容量巨大(PB级以上)的场景,不建议使用ELKB做处理,此种情况下,Hadoop生态性价比更高。
5. 团队工作简介
目前我们主要使用ELK支持如下两类场景: 时序数据处理:我们基于Elasticsearch进行研发,支持时序数据模型,满足用户对高写入吞吐、高并发查询、低存储成本等能力的需求,并且提供数据降精度、权限、冷热数据管理等高级功能特性。相比于InfluxDB(DB-Engines时序数据库排名第一),我们的写入吞吐提高30%(单机20w/s),去除了对写入数据的种种限制,查询并发提高将近4倍(单机2w qps),且提供更丰富的分析能力。 日志处理:我们通过交互式日志接入、自动化采集上报、调优日志解析/分析性能等方面,优化日志处理闭环,提供一个简单高效的日志平台。另外,通过研发监控告警、数据导出、权限、日志管理等功能特性,丰富日志分析能力,辅助用户充分挖掘日志价值。 后续我们会逐步展开介绍我们的工作内容,希望大家多多关注。