在现代IT架构中,监控和告警是非常重要的一环。随着云计算、大数据、容器等技术的普及,服务数量也呈爆炸式增长,管理这些服务的健康状态和性能指标变得更加困难。Prometheus是一个开源的监控和告警系统,已经被广泛应用于生产环境中。
本文将详细介绍Prometheus的架构原理以及如何使用其进行监控告警配置实现。
Prometheus概述
Prometheus是由SoundCloud公司于2012年开发的一款基于时间序列数据库的监控告警系统。其主要目标是通过收集各个节点的时间序列数据,对系统的健康状态进行监控,并在必要时发出告警。
Prometheus具有以下特点:
- 开源、免费:Prometheus是一款开源产品,可以任意下载和使用,不需要支付任何许可费用。
- 多维度的数据模型:Prometheus使用多维数据模型,可以更好地描述复杂的系统,并捕获任意维度的数据。
- 灵活的查询语言:PromQL是一种非常灵活的查询语言,可以操作复杂的时间序列数据,并支持聚合、计算和筛选等操作。
- 高效的存储:Prometheus通过使用自主开发的TSDB数据库,可以快速高效地存储和查询时间序列数据。
- 多种语言支持:Prometheus提供多种客户端库,支持流行的编程语言(如Go、Java、Python等),方便用户进行数据采集和上报。
Prometheus架构原理
下面是Prometheus的架构示意图:
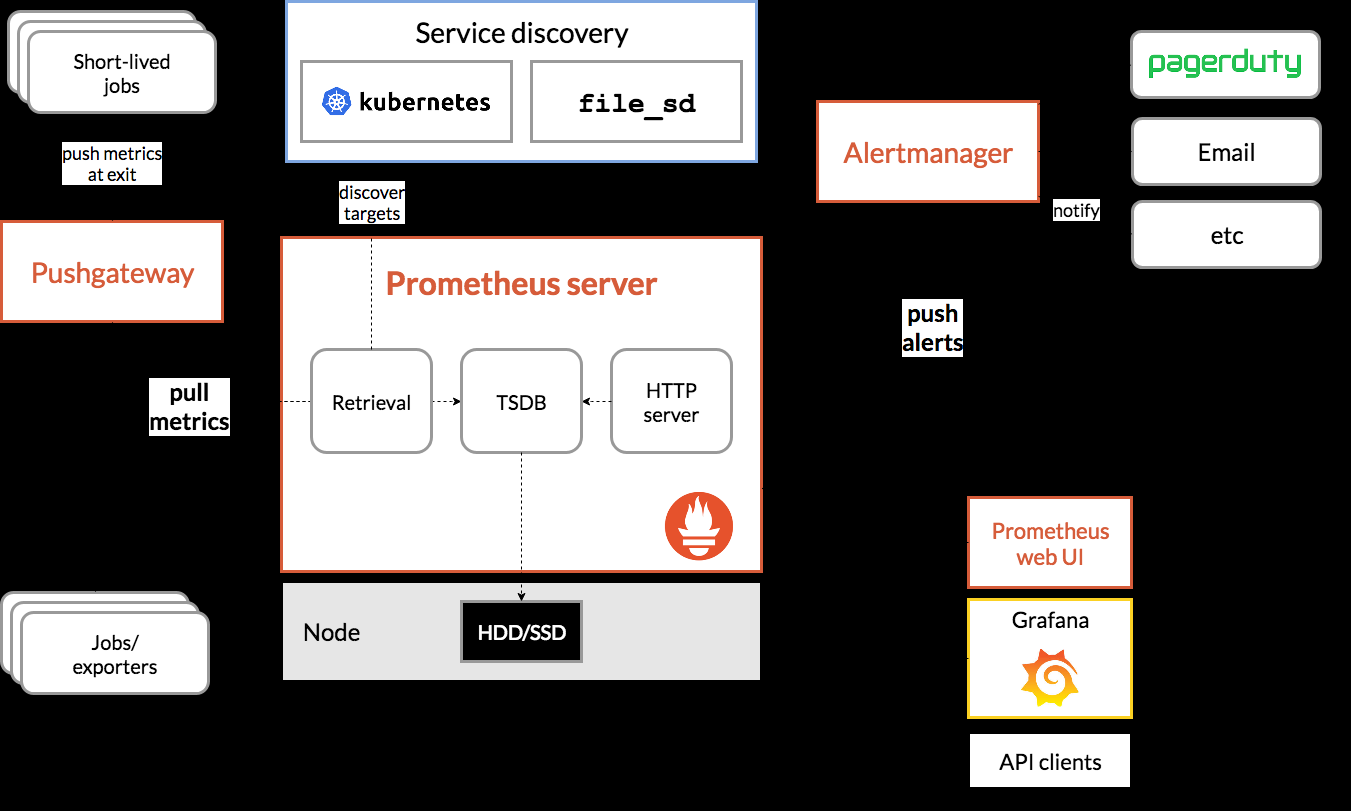
Prometheus采用Push模式或Pull模式的方式来采集监控数据,也可以通过服务发现机制来自动发现目标节点。收集到的数据被存储在本地的时间序列数据库中,并通过PromQL查询语言进行分析和操作。
组件说明
- Prometheus Server:核心组件,负责从各个Exporter中抓取指标数据,并写入本地的时间序列数据库。同时,也负责处理查询请求和产生告警。
- Exporter:用于将各类服务的指标数据暴露出来,以便Prometheus Server进行采集。Exporter通常由各个客户端库提供,也可以使用第三方Exporter。
- Client Libraries:提供多种编程语言的客户端库,用于采集应用程序的指标数据并上报到Prometheus Server。
- Pushgateway:Push模式的推送网关,用于接收短周期的任务指标数据,如批处理作业等。由于这类任务在Prometheus内部存储中没有对应的时间序列,所以需要使用Pushgateway进行中转。
- Alertmanager:负责接收来自Prometheus的告警信息,并根据用户定义的告警规则进行筛选和处理。
数据模型
Prometheus采用多维的时间序列数据模型,数据被描述为名称-值-时间戳的三元组。其中名称通常表示一种指标(Metric),例如CPU使用率、内存占用等;值表示指标的具体值;时间戳表示采集时间。
PromQL提供了丰富的操作符和函数,可以对时间序列数据进行聚合、计算和筛选等操作。例如,可以使用sum()函数对某个指标进行求和,avg()函数求平均数,而topk()函数可以找到某个指标排名前几的节点。
监控告警配置实现
下面将介绍如何使用Prometheus进行监控告警配置实现,包括以下几个步骤:
- 安装Prometheus
- 配置Exporter
- 配置告警规则
- 启动Alertmanager
安装Prometheus
Prometheus可以从官方网站下载并安装,也可以使用预先构建的Docker镜像。这里以二进制方式安装为例,具体步骤如下:
- 访问Prometheus官网,选择合适的版本并下载。
- 解压下载的文件,并将prometheus和promtool可执行文件复制到系统路径下。
例如,在Linux系统下可以使用以下命令进行安装:
wget https://github.com/prometheus/prometheus/releases/download/v2.32.1/prometheus-2.32.1.linux-amd64.tar.gz
tar zxvf prometheus-2.32.1.linux-amd64.tar.gz
cd prometheus-2.32.1.linux-amd64/
cp prometheus /usr/local/bin
cp promtool /usr/local/bin配置Exporter
Prometheus支持多种数据源的采集,包括HTTP、JMX、SNMP等。在这里我们以使用Node Exporter来监控主机指标为例,配置步骤如下:
- 下载并安装Node Exporter,可以从其官方网站进行下载。
- 启动Node Exporter,并将其暴露出去(如使用docker,则需要将暴露端口映射到宿主机上)。
- 在Prometheus的配置文件中添加相应的job配置,用于定时拉去Node Exporter提供的指标数据。
具体的job配置如下:
- job_name: 'node_exporter'
scrape_interval: 5s
static_configs:
- targets: ['localhost:9100'] # 监控节点的地址和端口配置告警规则
Prometheus的告警规则由Alertmanager进行处理,其规则语言形式为YAML格式。每条规则由多个匹配条件和一个告警操作组成,例如:
groups:
- name: example
rules:
- alert: HighUsage
expr: node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes < 0.2
for: 5m
labels:
severity: warning
annotations:
summary: "High memory usage"
description: "{{ $labels.instance }} has high memory usage."上述规则表示,如果监控节点的可用内存低于总内存的20%,则发出一条告警,并持续5分钟。告警级别为warning,同时在告警消息中指定了相应的描述信息。
启动Alertmanager
最后需要启动Alertmanager,并将其配置文件中的地址配置为Prometheus Server的地址。例如:
route:
receiver: 'slack-webhook'
group_wait: 30s
group_interval: 5m
repeat_interval: 8h
receivers:
- name: 'slack-webhook'
webhook_configs:
- url: 'https://hooks.slack.com/services/T00000000/B00000000/XXXXXXXXXXXXXXXXXXXXXXXX'
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal:
- alertname在上述示例中,Alertmanager的告警将通过Slack Webhook进行发送。具体的webhook地址需要从Slack官网获得。同时,通过inhibit_rules配置可以实现告警抑制的功能,避免低级别告警干扰高级别告警。
结论
本文详细介绍了Prometheus的架构原理与监控告警配置实现。Prometheus具有多维度数据模型、灵活的查询语言、高效的存储和多种语言支持等特点,已经成为监控告警领域中的重要工具之一。通过本文的学习,读者可以掌握基本的Prometheus使用方法,并在实际场景中进行监控告警配置实现。