PrometheusOperator云原生监控:基于operator部署的资源内部链路分析
假设有个需求:需要将node-exporter的指标暴露到k8s集群外部。如果要搞清楚这个问题,并实现这个需求,需要对通过operator部署的资源、内部链路有一定的了解才可以。所以,本篇要做这方面的一个分享。

分布式云场景下的多集群监控方案最佳实践
杨濡溪,腾讯云后台开发工程师,目前主要负责腾讯云 Prometheus 监控服务、TKE集群巡检等技术研发工作。
杨鹏,腾讯云后台开发工程师,曾负责腾讯云专有云后台技术研发工作,目前主要负责腾讯云 Prometheus 监控服务、TKE集群后台技术研发工作。
引言
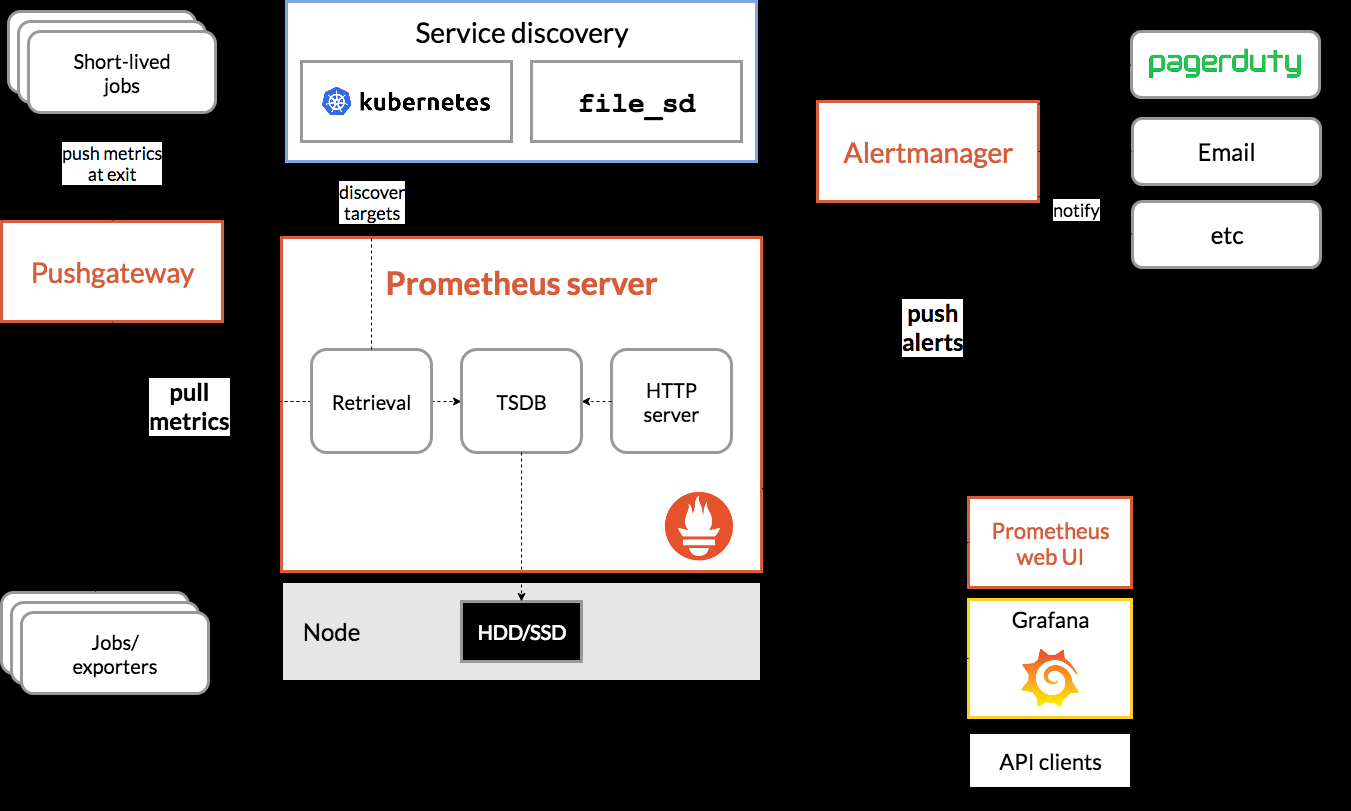
Prometheus 作为云原生时代最流行的监控组件,已然成为社区监控事实上的标准,但是在多集群,大集群等场景下,只使用 Prometheus 是远远不够的;单集群场景下我们一般主要关注指标采集、存储、告警、可视化等基础监控能力,随着集群规模的
基于腾讯云Lighthouse自建Grafana和Prometheus服务
Kubernetes 是一种强大的容器编排系统,它使您能够轻松地部署、管理和扩展容器化应用程序。在监控和可视化方面,Grafana 和 Prometheus 是两个非常有用的工具。本文将引导读者朋友们在 Kubernetes 集群上安装和配置 Grafana 和 Prometheus。
Prometheus的架构原理,如何使用其进行监控告警配置实现?
在现代IT架构中,监控和告警是非常重要的一环。随着云计算、大数据、容器等技术的普及,服务数量也呈爆炸式增长,管理这些服务的健康状态和性能指标变得更加困难。Prometheus是一个开源的监控和告警系统,已经被广泛应用于生产环境中。
Prometheus 二进制文件与操作系统或架构不兼容
确保你下载的二进制文件与系统的架构相匹配(例如,x86_64, arm64 等)。
云服务器指标采集
● 选择Node_exporter作为指标采集器,因其成熟社区以及腾讯云云监控默认指标维度、粒度都不够;

对远程http服务的拨测体验
过程是这样的,需要与合作方数据进行交互(肯定是不允许直接连对方数据源的),对方提供了两台server,后端同事在server上面作了proxy搭建了桥接的应用(两台server没有公网ip,通过一个超级难用的堡垒机明御进行管理)。两台server挂在在了负载均衡slb上对外提供http服务(环境为阿里云环境)。项目马上要上线了,然后就面临一个问题,如何监控这个桥接程序的健康状态呢?想到了几种方式:
Prometheus实战篇:Prometheus监控mongodb
https://github.com/percona/grafana-dashboards/blob/main/dashboards/MongoDB/MongoDB_Instances_Overview.json

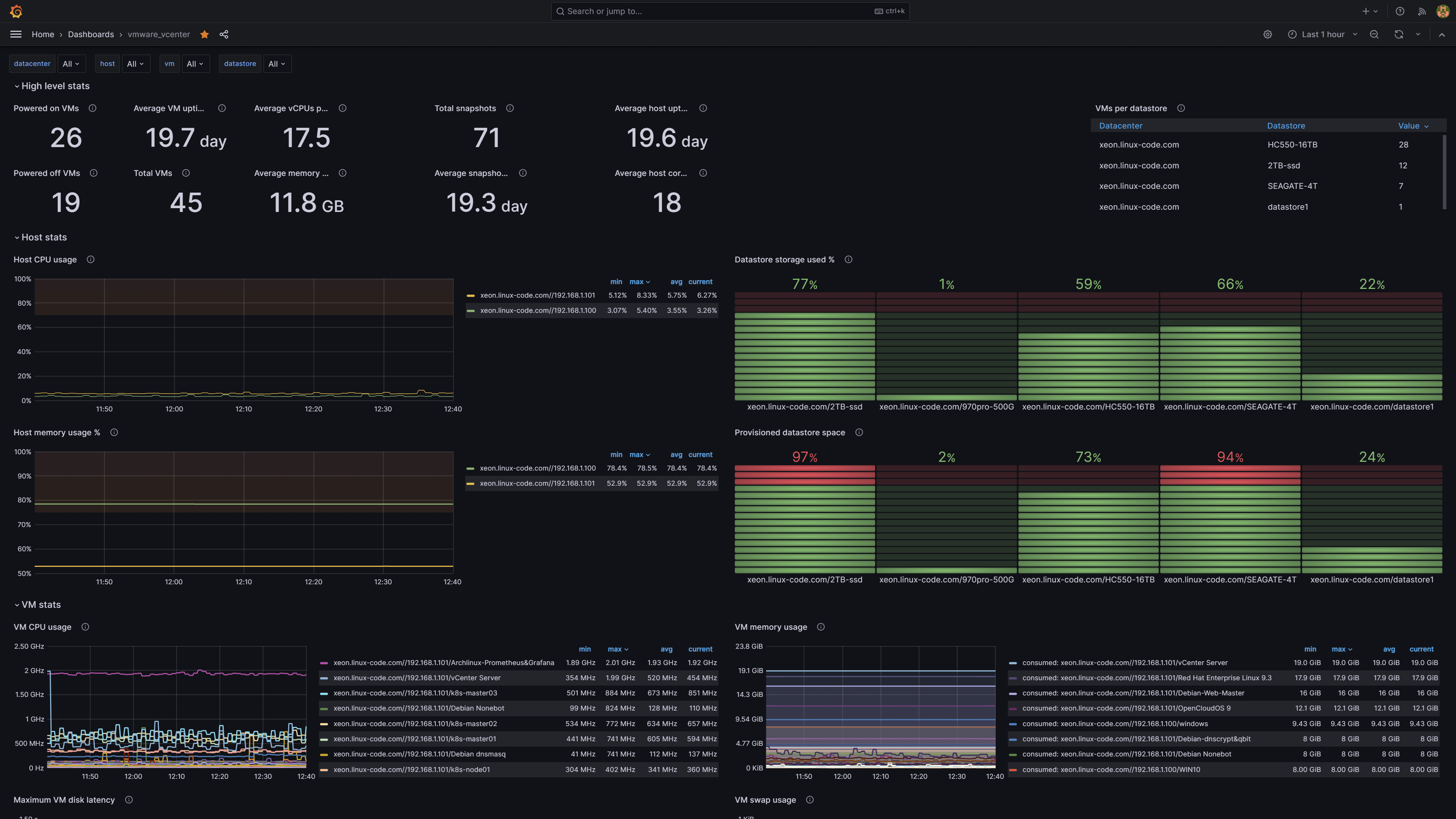
基于Prometheus&Grafana监控vmware vcenter集群 - 使用vmware_exporter进行数据采集
prometheus已经采集到从vmware_exporter服务的metrics数据源,接下来你怎么在grafana自定义监控面板都可以,符合prometheus的函数表达式语法即可。