杨濡溪,腾讯云后台开发工程师,目前主要负责腾讯云 Prometheus 监控服务、TKE集群巡检等技术研发工作。
杨鹏,腾讯云后台开发工程师,曾负责腾讯云专有云后台技术研发工作,目前主要负责腾讯云 Prometheus 监控服务、TKE集群后台技术研发工作。
引言
Prometheus 作为云原生时代最流行的监控组件,已然成为社区监控事实上的标准,但是在多集群,大集群等场景下,只使用 Prometheus 是远远不够的;单集群场景下我们一般主要关注指标采集、存储、告警、可视化等基础监控能力,随着集群规模的增大,监控系统的弹性以及可扩展性成为首要解决的痛点问题,为此社区诞生了 Thanos、Cortex、Prometheus 联邦等一系列成熟的解决方案,我们也通过自研的 Kvass 解决方案,通过将服务发现与采集过程分离,以及自研的任务分片算法,无侵入式的支持采集任务横向扩展,满足大规模集群场景下的采集和监控需求。在分布式云场景下,用户集群往往采用混合多云多集群的部署架构,集群的地理位置更加分散,网络环境更加复杂,为此我们也在寻找一种新的方案来统一解决此类问题。本文以腾讯云跨账号集群统一监控为例,介绍分布式云下的多集群监控方案的最佳实践。
多集群监控的挑战
在分布式云计算场景中,往往会出现用户集群不在一个云厂商平台管理,在同一个平台的集群也许也会在不同账号下维护。这种跨云厂商跨账号的 Kubernetes 集群场景,需要实现统一的监控、数据聚合查询、告警以及可视化的能力。
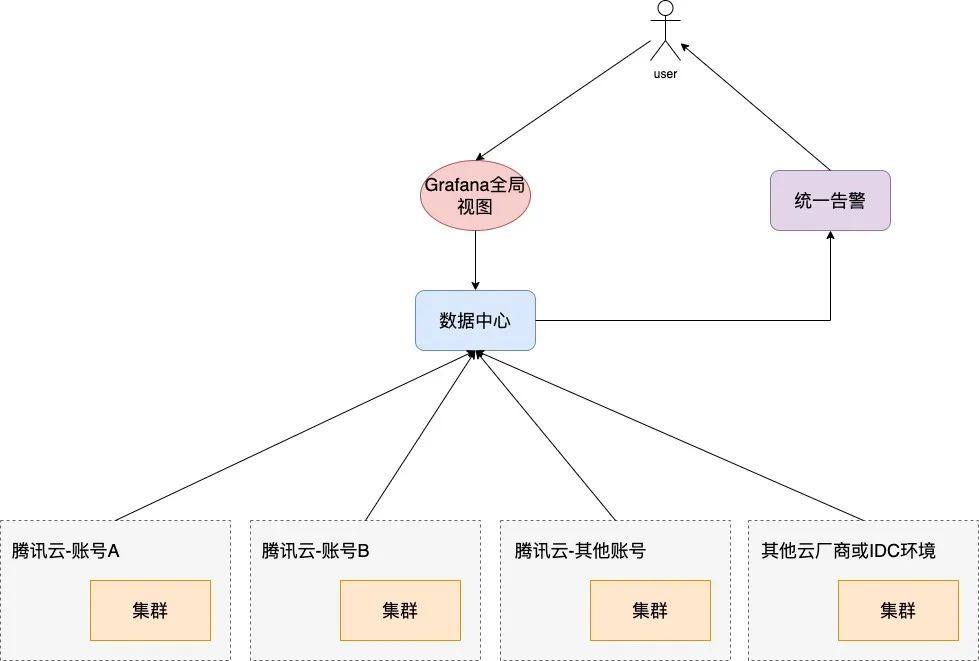
从单集群演进到多集群乃至分布式云监控场景监控方案,我们面临着如下挑战:
- 单集群监控场景中监控资源的弹性伸缩的问题 在集群初始规模较小的情况下,我们部署一个单机版的 Prometheus+Grafana 实例就可以完成指标的采集、存储、告警、聚合以及图表展示。随着业务发展集群规模不断增长,逐渐发展成为百万甚至千万级别 Series 数据量,就会慢慢开始出现 Prometheus 资源过载的情况,过多的监控指标会造成 Prometheus 实例出现 OOM。
- 多集群监控场景中的数据聚合问题 在大规模集群的前提下,我们还需要同时监控多个集群,问题1中提到的性能问题同样存在,更重要的是,如何把所有集群的数据写入到一个统一的存储,并且告警&聚合规则的计算是基于全局数据,以此来实现多集群数据的聚合。
- 分布式云场景中跨云厂商跨账号的统一监控问题 跨云厂商跨账号本质就意味着是多集群,在多集群的场景里需要解决的是,怎么打破平台、账号的边界,解决多云网络、配置统一下发管理的问题。
传统的分布式云监控方案
针对分布式云的场景,常规的做法是以平台为维度进行监控,以用户集群分布在腾讯云、友商云、自建 IDC 的场景来分析,这样复杂的场景至少需要部署维护3套监控系统,暂且不考虑在生产环境中从零开始搭建一套 Prometheus+Grafana 的监控告警系统需要投入的精力,仅考虑后续的维护和使用也面临很多问题:
- 维护复杂度高 每一次要新增一份数据采集配置或告警策略,需要在3套系统中重复一样的操作,并需要时刻保持配置的一致性,某个环节的疏漏都可能导致最终效果的差异,例如腾讯云的集群资源过载正常发出告警,某个 IDC 自建集群因为告警策略未及时更新,导致告警未触发。在实际的场景中,这样的跨多个云厂商的环境,每个云环境下一套监控系统是远远不够的,还会需要按照账号维度来细分,所以管理维护复杂程度大大提高。
- 资源管理难 资源如何维持在合理水位,不同云环境下集群规模不一样,对应需要的资源不一样,每次新增集群监控采集,都需要评估是否需要扩容。
- 统一数据查询、展示以及告警能力缺失 监控数据无法统一展示,不能从全局出发,分析资源使用情况。
TMP+TDCC 实现分布式云下多集群监控方案
在传统方案中的种种问题是由于没有一个统一的监控管理平台导致的,我们使用的解决方案是腾讯云 Prometheus 服务(以下简称 TMP 服务)+云原生分布式云中心(以下简称 TDCC 服务),通过将不同账号、不同云厂商或者 IDC 环境下的集群注册到 TDCC 中进行控制面的统一管理,然后通过 TMP 实现分布式云环境下多账号下集群的数据面采集:
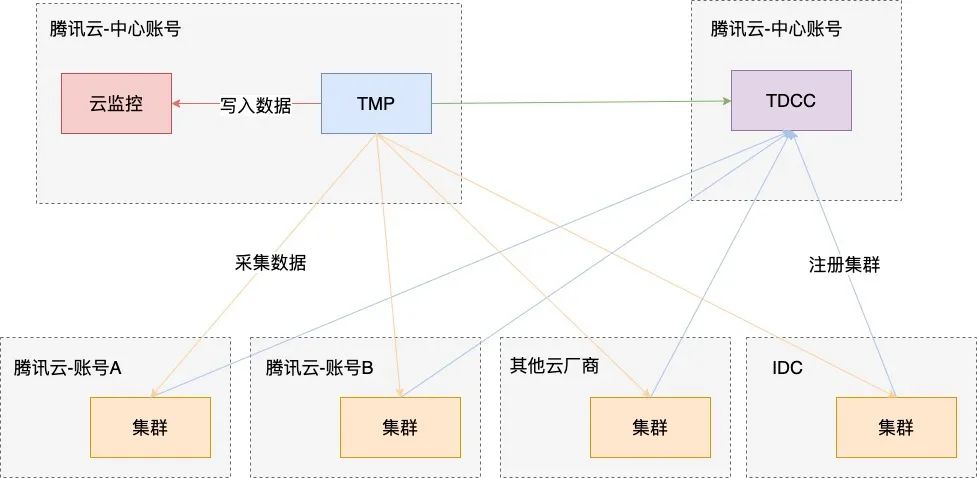
TMP 服务满足可扩展,高可用且兼容原生配置的诉求,支持监控腾讯云 TKE 集群、TKE Serverless 弹性集群、边缘集群以及注册集群 TDCC。
- 采集侧采用自研 Kvass 方案,兼容 Prometheus Operator 开源使用方式,将服务发现与采集过程分离,无侵入式支持采集任务横向扩容缩容,满足千万级别 series 采集需求。
- 模板功能支持一键下发采集、告警、聚合规则配置,降低配置的维护复杂度。
- 自动适配集群规模,小集群使用小规格采集组件,大集群使用大规格组件,从小集群逐渐发展为大集群的情况会自动进行采集组件的规格升配。
- 自监控系统与自动恢复机制,支持组件异常后的重新拉起,不可用采集分片上的 Targets 自动转移能力。
- 存储侧支持水平伸缩、多副本高可用、多租户、长期存储,并对 Prometheus TSDB 进行深度优化。
- 在可视化方面,与 Grafana Labs 合作开发,深度集成 Prometheus,高度集成云监控 Grafana 插件补充可视化能力,支持角色鉴权与五十余种云产品监控数据。
TDCC 是腾讯面向多云多集群场景的应用管理平台,支持用户将云原生化的应用扩展到分布式云,全局视角统一管理和运维分布式云资源。
- 无需用户自行搭建及运维,通过 Kubernetes 一站式接入和管理集群、服务器、主机、智能设备,不管是运行在公有云、私用云还是边缘云,都将拥有一致的控制平面,实现云网融合、云边协同。
- 以应用为中心整合应用镜像、流量、存储的资源,覆盖应用的交付、管理、调度、容灾、运维全生命周期,集合丰富的云服务和产品,助力业务应用扩展到分布式云,全局视角统一管理和运维,轻松地将应用服务发布至全球,一次部署处处运行。
- 全面兼容云原生标准,原生 Kubernetes 各类资源都可以通过 TDCC 分布式云中心进行分发和管理。
通过对比可以看出 TMP+TDCC 实现的监控方案具有绝对的优势:
对比项 | 传统分布式云集群监控 | TMP+TDCC 分布式云集群监控 |
|---|---|---|
架构 | 每个 K8s 集群部署一套 Prometheus | 全局只部署一套 Prometheus |
Grafana 数据源 | 多个 | 一个 |
资源弹性伸缩 | 依赖人工介入 | 自研方案支持横向自动扩缩容 |
配置管理复杂度 | 高 | 低 |
与监控集群耦合性 | 高,需要侵入要监控的集群 | 低,对要监控的集群侵入性极低 |
使用场景 | 仅集群内部指标场景 | 支持多集群维度场景使用,具有全局视角 |
- 在传统观念分布式云集群监控场景中,用户为每个集群单独部署 Prometheus 监控组件。日常的运维中,不仅要同时维护多个 Prometheus 监控组件,还需要在日常运维中,频繁切换不同的数据源,如果需要将不同的集群之间数据进行整合处理起来也是更加复杂。
- TMP+TDCC 分布式云集群监控由于全局只部署一套 Prometheus,它可以轻松解决上面的问题。
- 通过多集群聚合汇总出来的监控指标,不仅可以绘制出来全局视角的监控面板、方便日常的运维工作,还可以进行多集群的统一告警。
技术方案与原理介绍
方案
首先,用户在多个腾讯云账号中选择一个账号作为中心账号,创建一个 TMP 监控实例,并且在该账号下开启 TDCC HUB 集群,然后将其他账号下的集群、其他云厂商下的集群、云下 IDC 的自建 K8s 集群统一注册到该账号下的 TDCC HUB 集群中。在前面创建的 TMP 实例中关联所有要监控的注册集群,就可以实现一套监控系统去采集所有集群的指标,历史数据统一存储。待数据正常采集后,使用 TMP 实例绑定的 Grafana 来展示数据,可以查询到所有集群的指标,不用切换 Grafana 或切换数据源。关于告警和聚合的使用,会在后面章节详细介绍。
架构
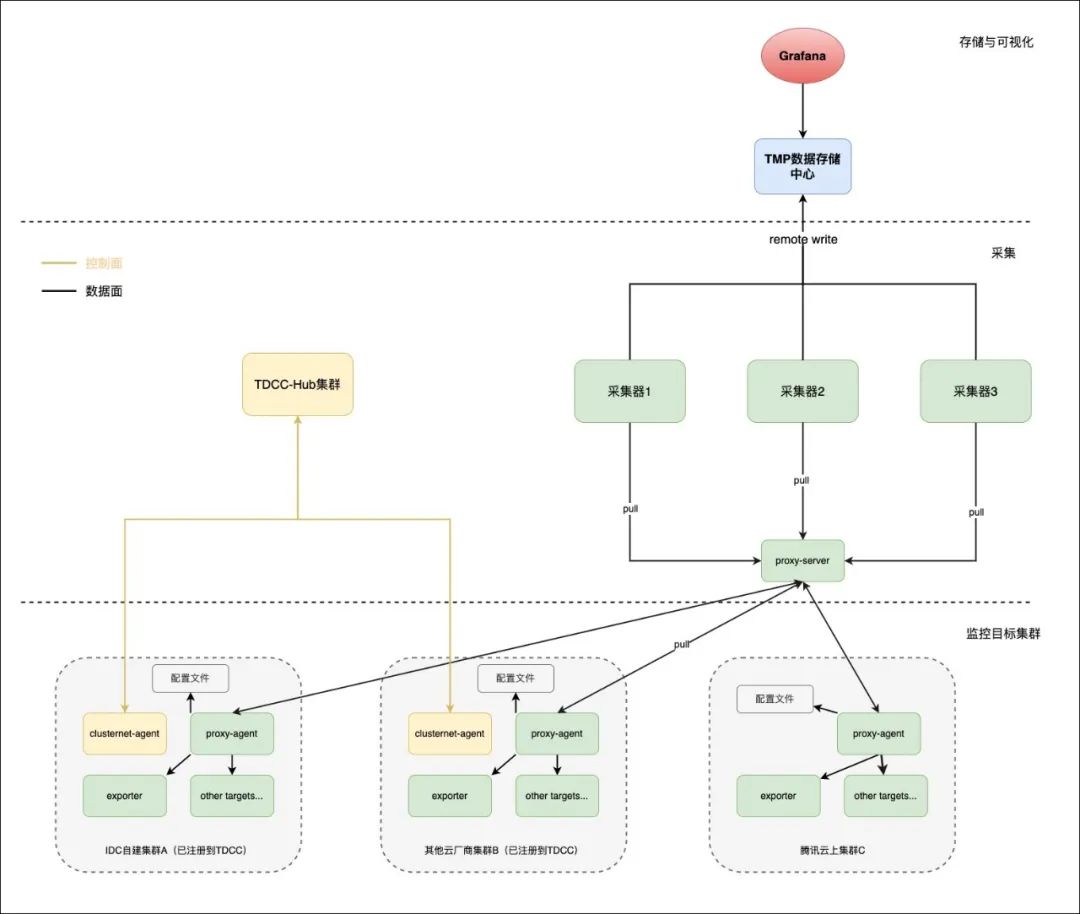
关联注册集群走公网还是内网

TMP 实例在关联注册集群(TDCC)的时候,会出现选项引导选择公网或内网采集方式,这里的选项遵循注册 HUB 时候的选项即可,在将 IDC 集群注册到 HUB 时候,如果选择了内网,那就选择内网采集,否则走公网采集。
proxy 原理分析
TMP 实例的采集组件是托管在一个 TKE Serverless 集群中,采集组件要去访问目标集群中的 Targets,比如 Pod 或 Node进行指标采集,就依赖了在上述方案中提到的 Proxy 组件,这套 Proxy 组件是多路7层代理器,支持多个 Agent 连接到一个服务端,服务端通过多个端口就实现多路代理。Server 接受 Agent 的连接请求,并保持一条复用的 TCP 长连接,用于后续代理请求到 Agent,Server 通过动态加载配置文件来指定 ID 所对应的代理端口。
内网采集
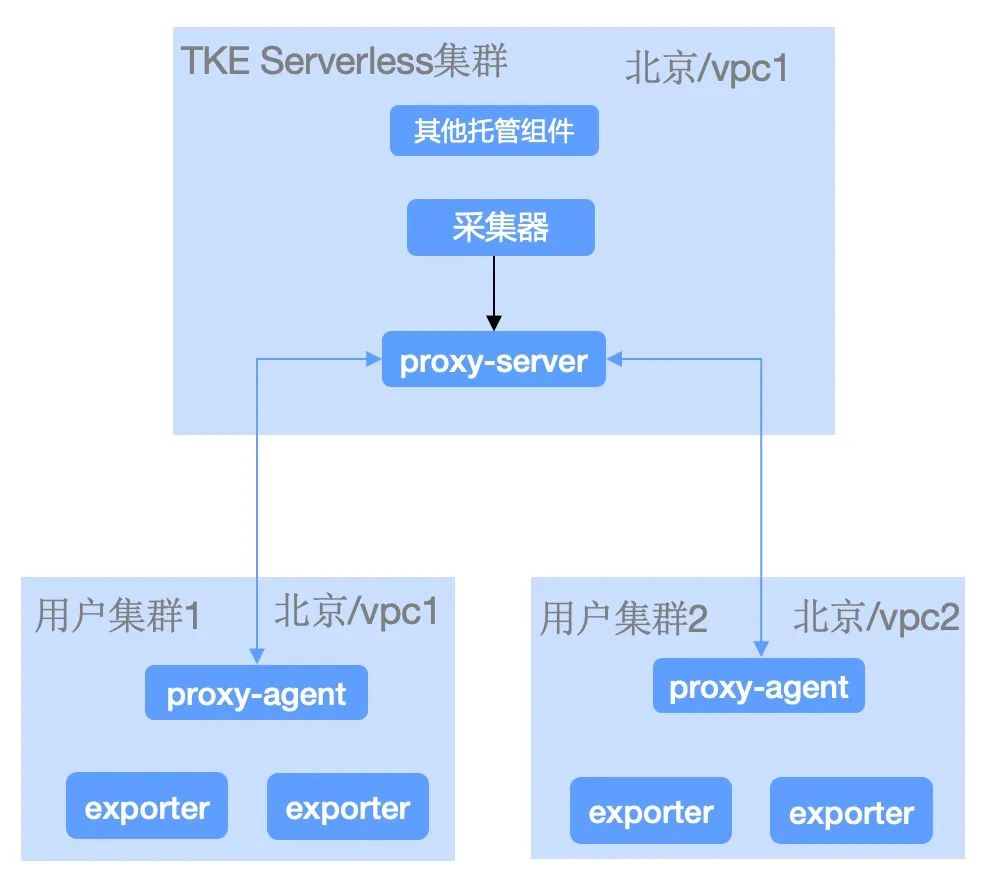
因为 Proxy 架构是 Agent 端反向请求 Server 端建立连接,所以 Server 端需要一个固定的地址下发给 Agent,通常的做法也许会选择给 Server 绑定一个内网 CLB,在上述监控方案中,底层引入 TKE Serverless 弹性容器集群服务,使用 TKE Serverless 集群固定 IP 能力替代内网 CLB,节省内网负载均衡费用。
公网采集
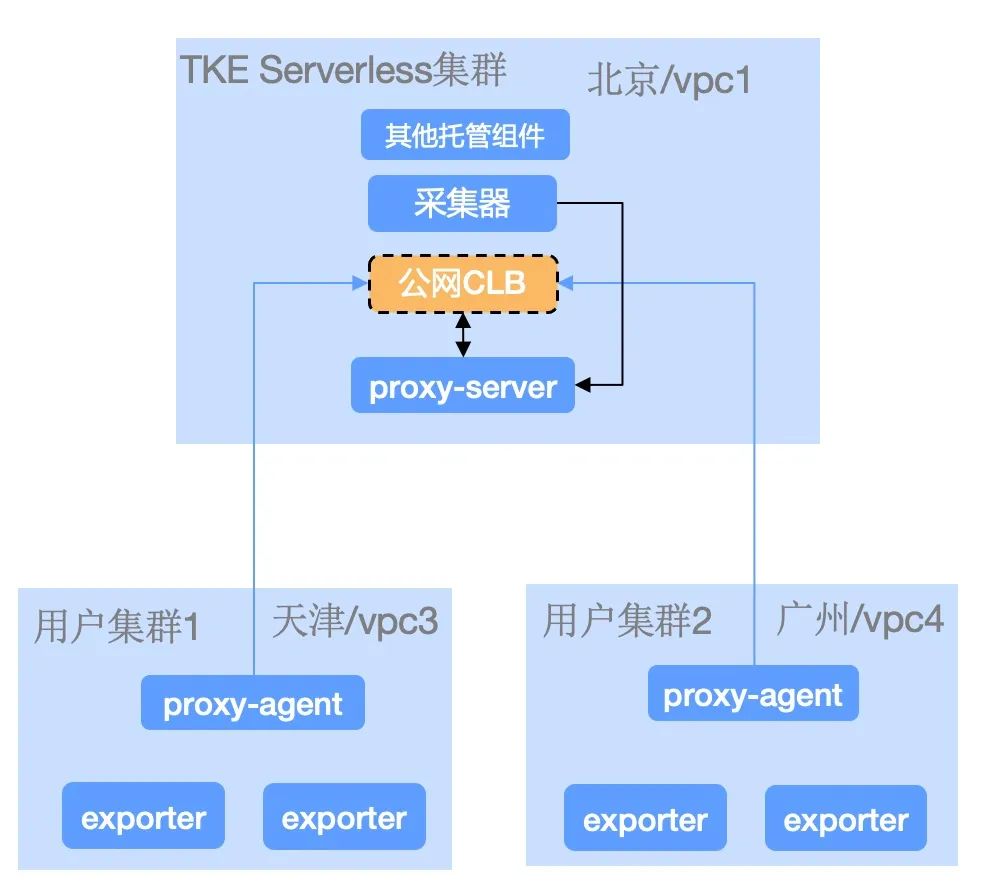
公网采集在内网采集的基础上,多了一个公网 CLB,因此,公网采集要求目标集群有访问公网的能力,否则 Proxy 连接无法建立,就无法采集指标。公网采集可以解决 TMP 实例所在 VPC 网络与目标集群网络不通的场景,但是弊端也很明显,网络质量无法保证,可能会出现偶尔的数据掉点,所以我们比较推荐使用云联网或专线等方式采集网络不通的集群。
实践路径
前提条件
目前 TDCC 还在内测中,需要先提交 内测申请 开通服务:
https://cloud.tencent.com/apply/p/897g10ltlv6
配置并开通 HUB 集群
云原生分布式云中心通过后台托管的 Hub Cluster 集群来管理其他注册进来的 Child Cluster 子集群。
- 点击完成服务授权,将跳转至服务开通页面设置基本信息,该信息将用于配置 Hub 集群: 开通地域:选择 Hub Cluster 的地域,当前仅支持广州,未来会支持更多地域。 可用区:选择 Hub Cluster 的可用区。 集群网络:选择一个子网。访问 Hub Cluster 的 kube-apiserver 需要使用弹性网卡,因此需要您提供 VPC 子网。TKE 会自动在选定的子网内创建代理弹性网卡。
- 单击完成开通服务,开通过程可能持续数分钟,完成后自动进入云原生分布式云中心控制台。
注册集群
在注册集群列表页面点击注册已有集群:
选择将要注册进来的集群就近地域,点击【完成】,回到集群列表页面,点击【查看注册命令】:

可以看到自动生成的yaml,下载这份yaml保存为 agent.yaml。
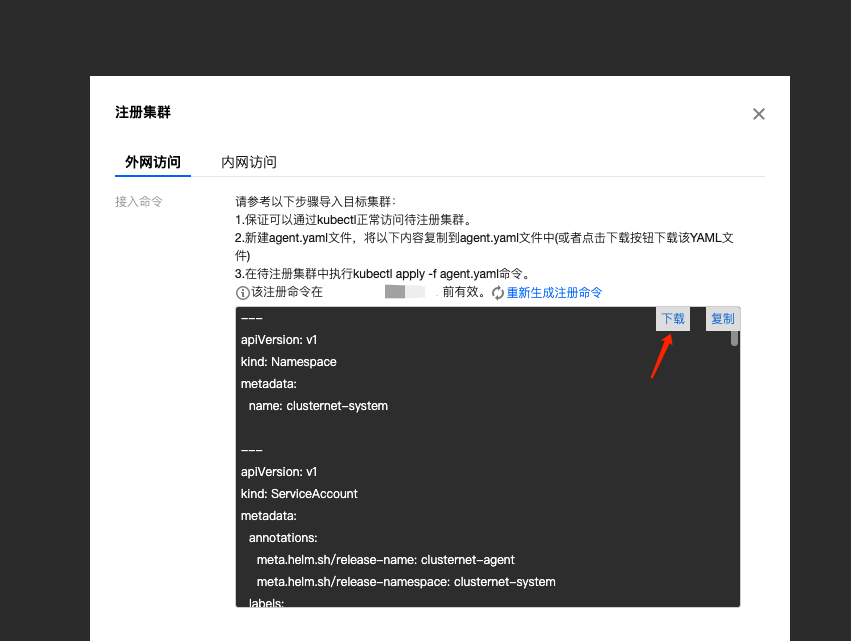
- 需要支持通过 kubectl 访问待注册集群。
- 将下载的 agent.yaml 中的内容复制到需要注册的目标集群中。
- 在集群中执行 kubectl apply -f agent.yaml 命令。
上述操作可以参考连接集群:
(https://cloud.tencent.com/document/product/457/32191)
等待注册集群状态变为运行中就代表注册成功,可以进行下一步操作:

创建 TMP 实例并关联注册集群
新建 TMP 实例,完成购买:
前往关联容器服务:
点击关联集群:
集群类型选择注册集群,选择对应的注册集群,点击确定,可以看到集群正在关联中:
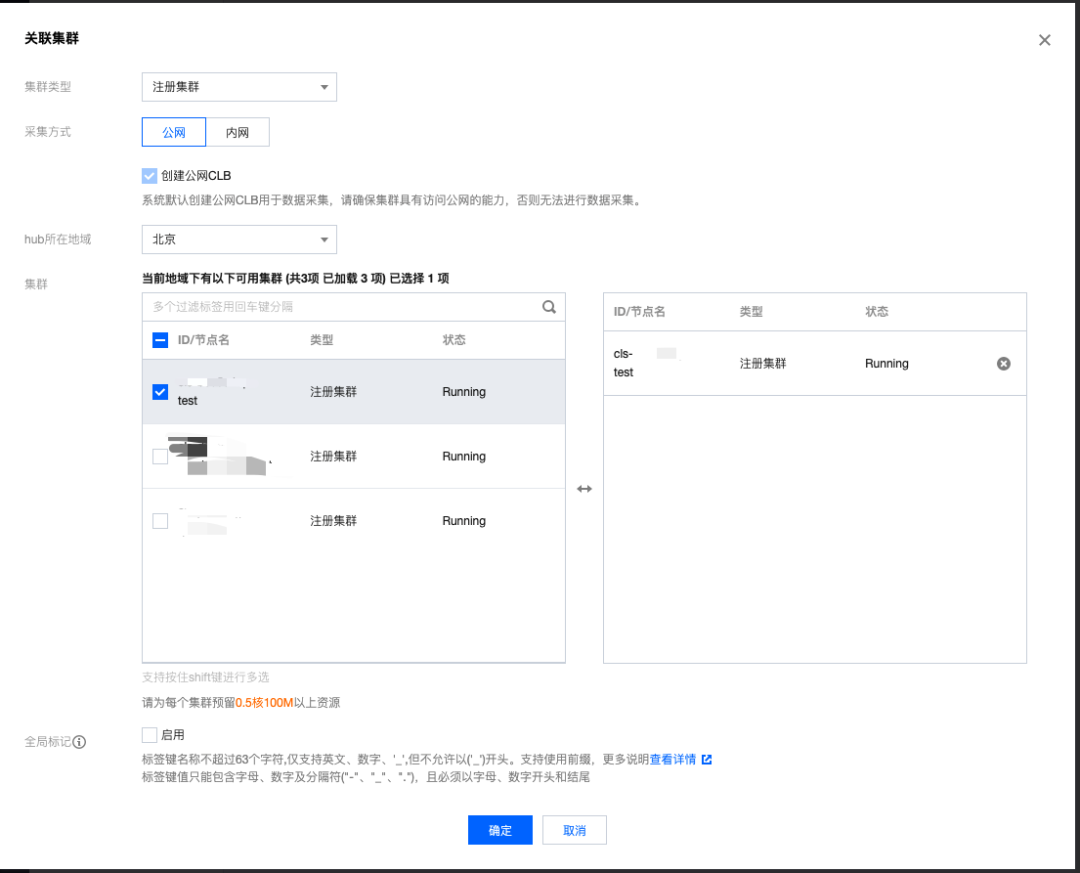
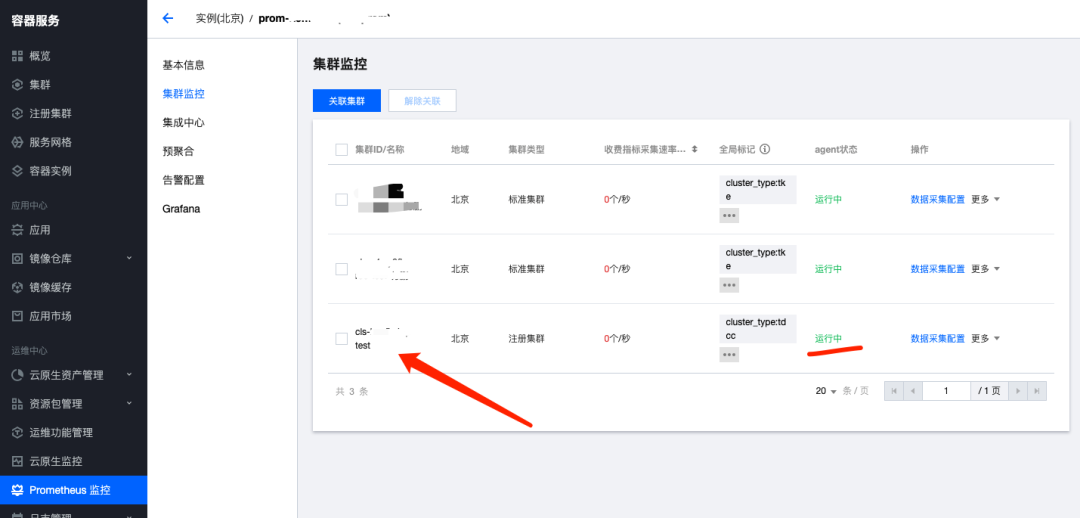
等待5-10分钟,agent 状态处于运行中,点击数据采集配置就可以进行采集的配置修改:
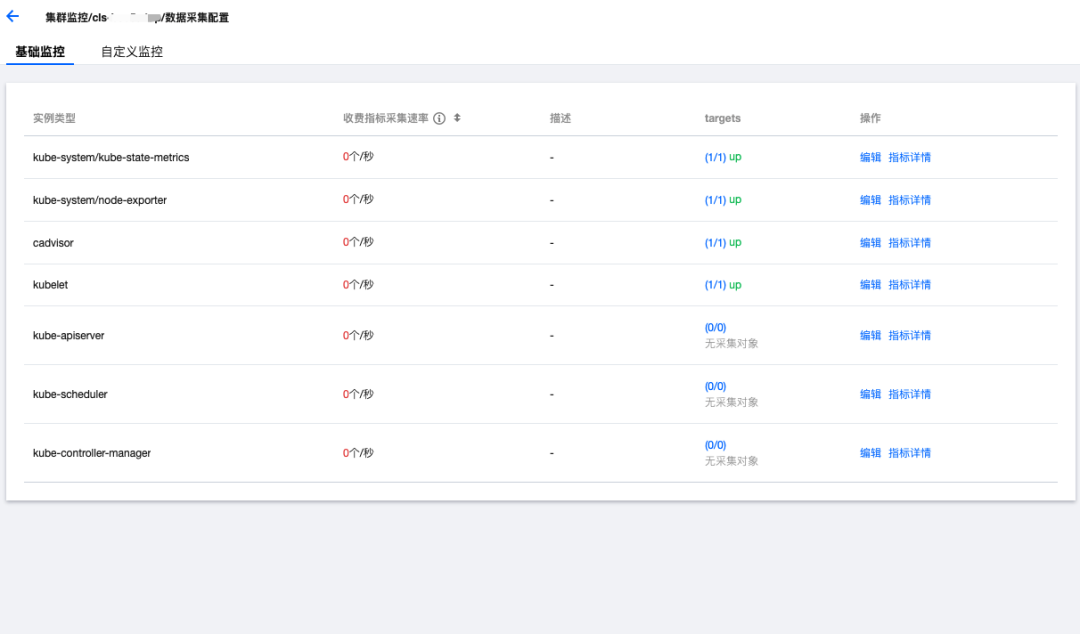
下图展示了新关联集群默认添加的 Job,包括节点、cadvisor、kube-state-metrics 等基础采集:
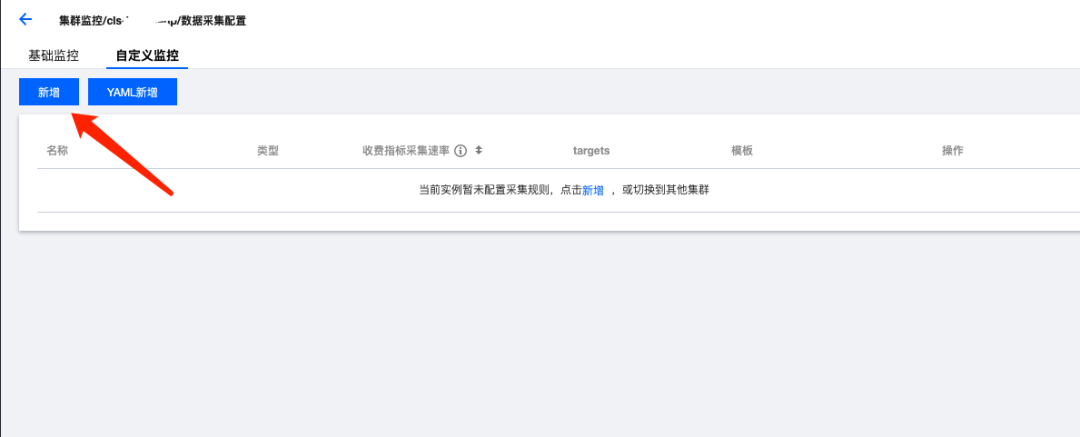
若您有自定义 Job,可以进入自定义监控,点击新增,配置自定义指标的采集:

保存后,等待一个采集周期(若未指定,默认为15s)就可以看到指标数据的采集:
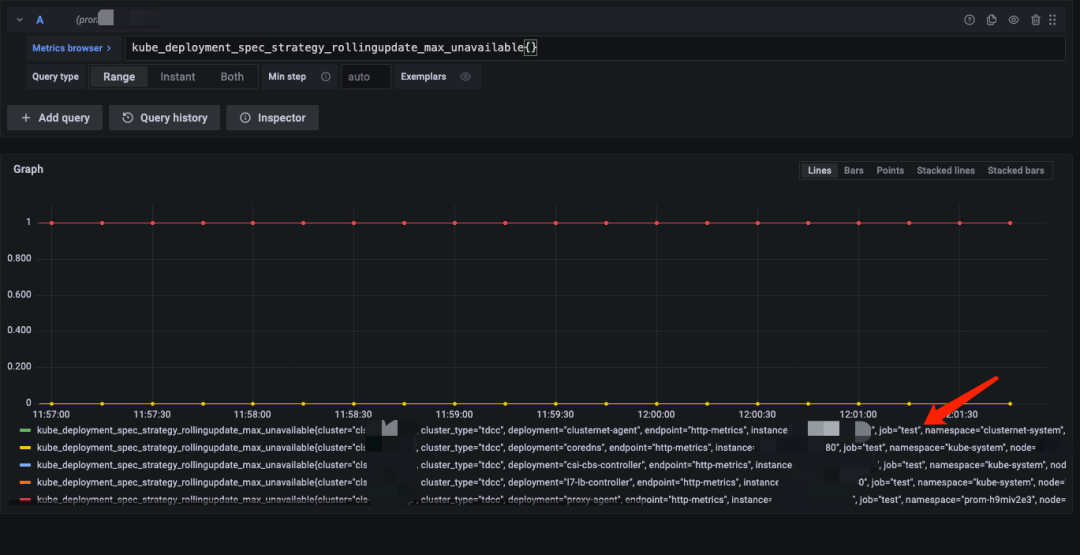
打开 Grafana 查询刚刚新增 Job 的指标,可以看到数据已经收集上来,接下来就可以基于这些指标配置业务自定义监控面板:
告警
TMP 既支持对单个集群进行告警配置,也支持对多个集群进行统一告警。在触发告警的时候可以对告警信息进行收敛,避免同时触发大量告警信息造成告警淹没。在告警渠道中不仅支持腾讯云的告警渠道(微信、电话、短信、邮件、企业微信等等),也支持对接用户自定义 Webhook 和自建 Alertmanager 服务。
单集群告警
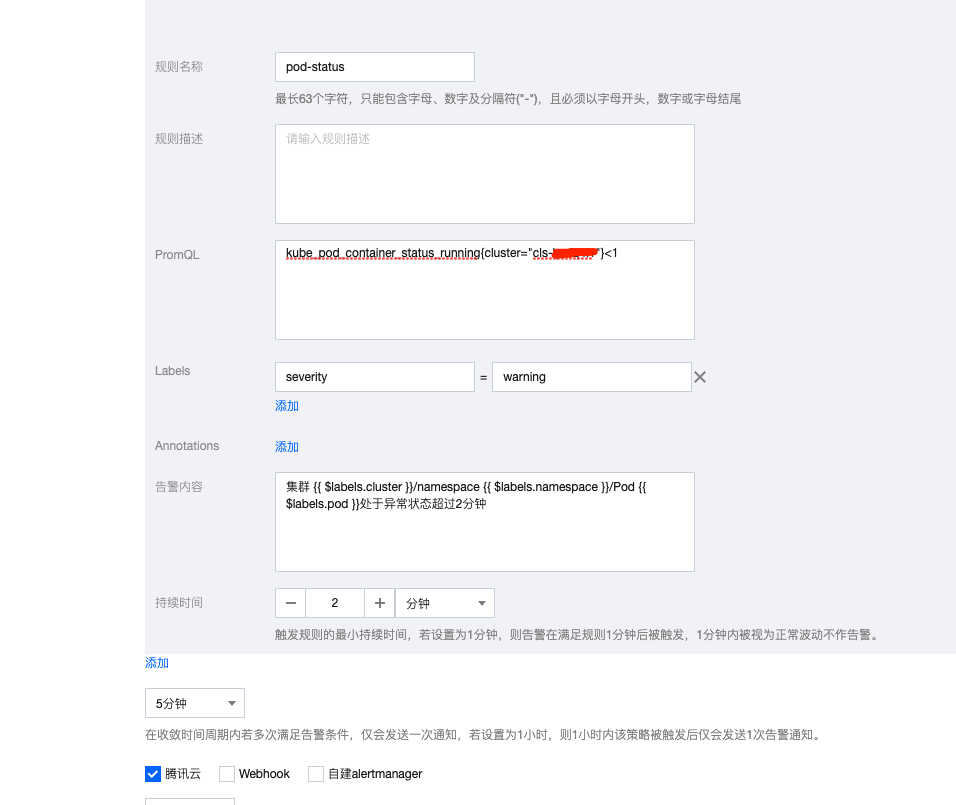
当前策略演示的是单集群监控中 pod 状态异常持续时间为两分钟的时候,发出告警:
模拟触发告警:将集群中 test-nginx 的镜像 tag 改为一个不存在的 tag,这时 pod 会处于 pending 状态:

结果符合预期:

因为对告警进行了收敛,五分钟后收到第二次告警消息。
多集群的统一告警
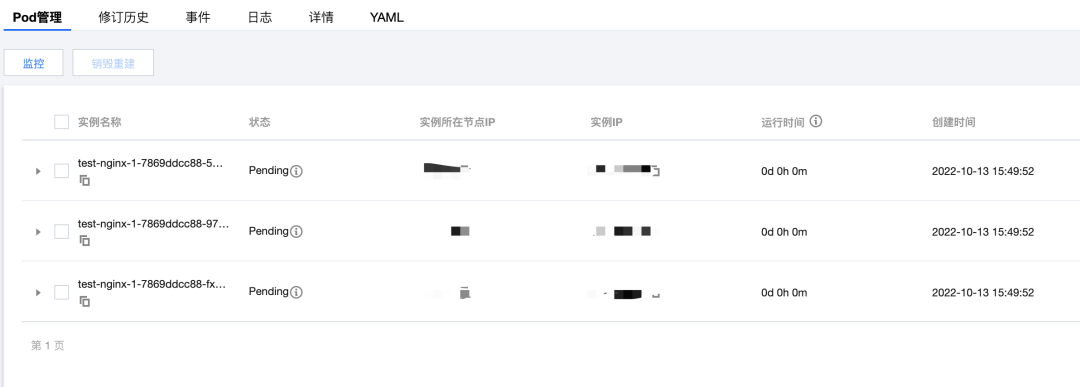
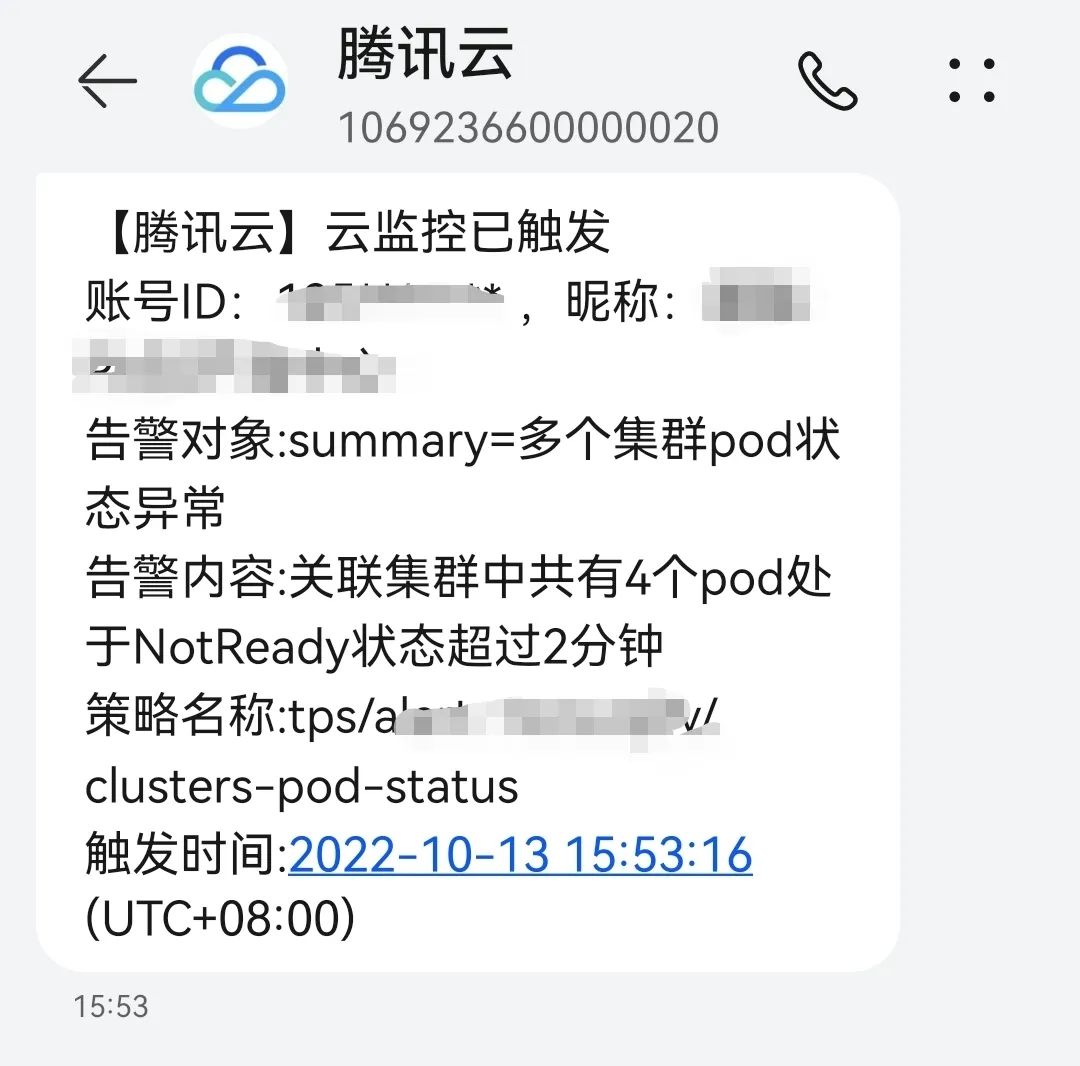
当前策略演示的是多集群中只要有 pod 状态异常总数大于3且持续时间为两分钟的时候,就发出告警:

在另外一个集群中创建个 test-nginx-1,让其副本数为3并且处于 pending 状态。这时,两个集群中共有四个 pod 处于 pending 状态:
结果符合预期:
聚合查询
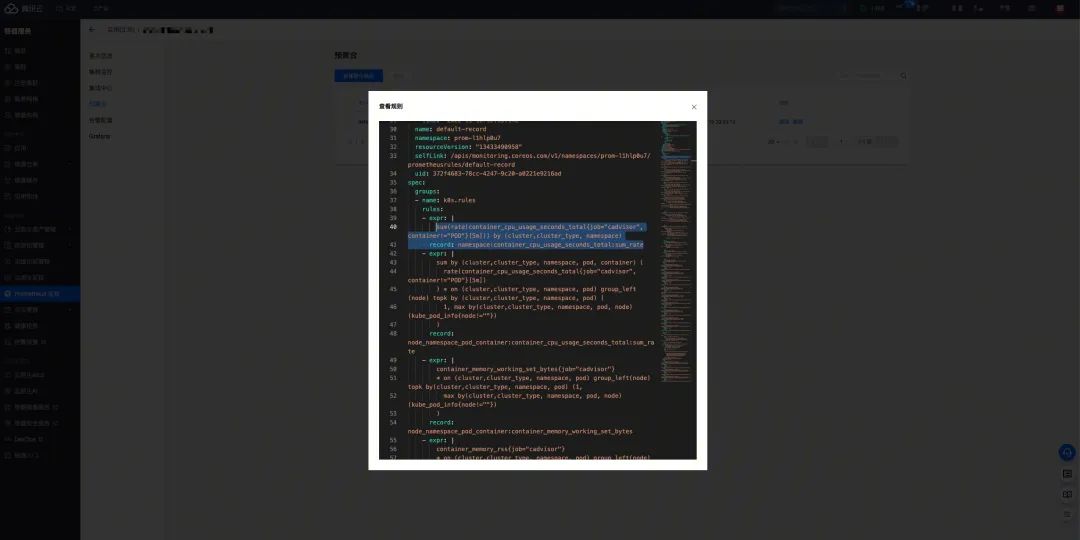
由于多个集群数据存放在一起,常用的查询语句频繁的查询会增大 Prometheus 的负载压力,并且反馈耗时随着数据的增加而延长。我们根据 Prometheus 的聚合规则,将常用的指标进行了预聚合,减少了查询时 Prometheus 的压力,以及反馈的耗时。在 TMP 服务中关联集群后会默认创建一份聚合规则:

规则详情:
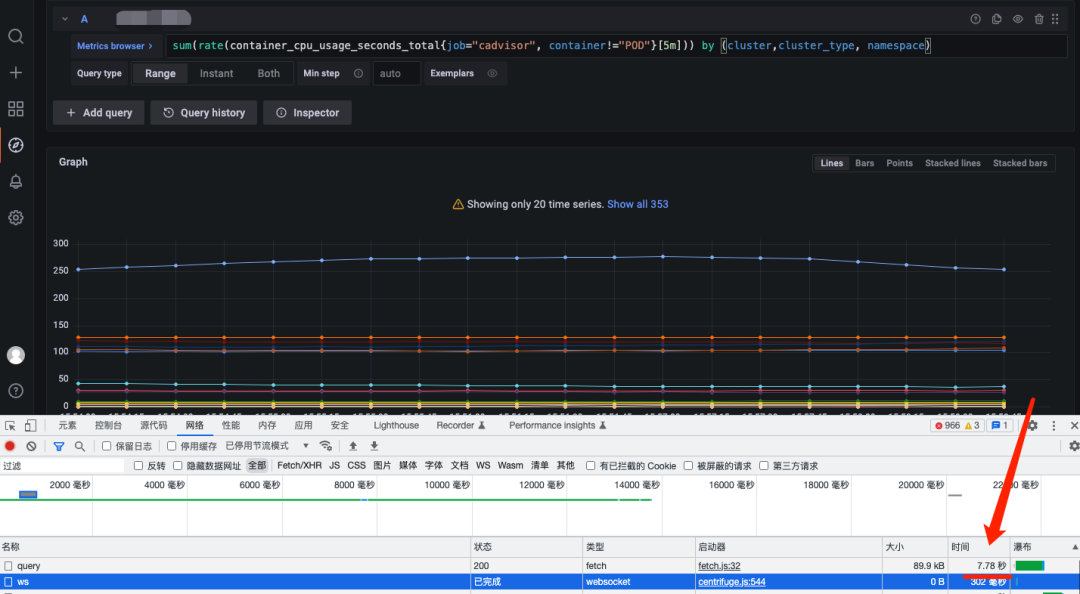
通过一个例子来说明,这里需要查询所有命名空间下 CPU 使用时间,直接使用原始 promql 查询,耗时需要7.78秒: sum(rate(container_cpu_usage_seconds_total{job="cadvisor", container!="POD"}[5m])) by (cluster,cluster_type, namespace)
当使用预聚合出来的指标查询,仅需要533毫秒:

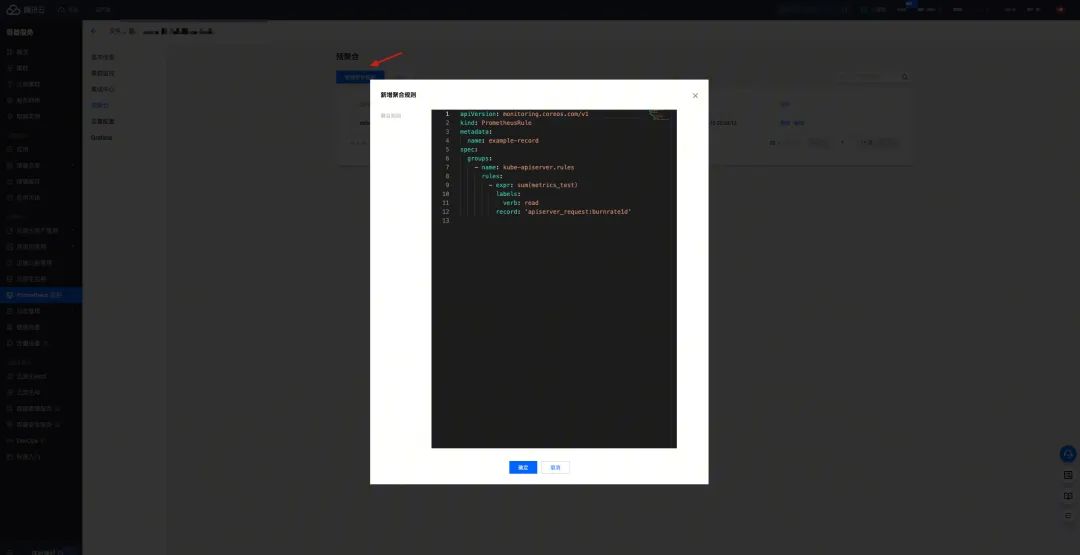
通过聚合规则优化查询对于数据量大的实例尤为重要,最直观的表现就是打开 Grafana 面板 loading 耗时,越快速对于使用者来说体验更好。除了默认提供的配置,我们也可以在控制台添加新的自定义聚合规则,支持原生配置方式,灵活便捷:
指标数据量
从采集端的角度出发,每加入一个新集群对已有集群的监控没有影响,底层组件托管在 TKE Serverless 集群,支持横向自动扩容。从存储端的角度考虑,我们建议所有集群总的数据量不超过450w。
总结
使用 TMP + TDCC 结合的多集群监控方案,能够充分满足分布式云场景下跨云厂商跨账号的监控需求,兼容开源生态丰富多样的应用组件,在使用过程中帮助业务快速发现和定位问题,为使用者提供免搭建的高效运维能力,减少开发及运维成本。本文以腾讯云多账号的场景为例,介绍了分布式云下的多集群监控方案的最佳实践,您也可以在实践路径中,使用其他云厂商或 IDC 环境中的 K8s 集群进行尝试。

腾讯云原生
11.1-11.30大促活动持续进行中!
扫描下方图片二维码进入会场抢优惠!
